1、bin用来存放可执行的二进制文件。 2、include/myslam存放SLAM模块的头文件,主要是.h文件。当把包含目录设为include,引用自己的头文件时,用include”myslam/xxx.h”,这样不会跟其他库混淆。 3、src存放源代码文件,主要是.cpp文件。 4、test文件是测试SLAM库的文件,也是.cpp文件。也就是最后跑的实现程序,在这个程序中我们调用了自己写的SLAM库,所以叫test。当然这里也只有一个CMakelists.txt,因为还没有开始写 5、lib存放编译好的库文件,暂无 6、config存放配置文件,也就是需要经常修改的运行参数。这里存放在default.yaml中,暂无 7、cmake_modules第三方库的cmake文件,在使用g2o之类的库时会用到。暂无
01版本只是简单的实现了一些slam库中的类和函数。主要就是五方面:
1、Map
(1)插入地图点的指针并存储对应地图点的id
(2)插入帧的指针并存储对应帧的id
2、Frame
(1)帧的id
(2)帧的时间戳
(3)帧的Tcw
(4)帧对应的相机
(5)当前帧对应的图像(RGB和D)
(6)创建关键帧函数
(7)求某像素深度函数
(8)求帧光心空间坐标函数
(9)判断某三维点是否在帧中函数
3、MapPoints
(1)特征点的id
(2)三维空间的坐标
(3)正则化的坐标?
(4)特征描述子
(5)被特征匹配算法观测的次数
(6)在位姿估计中作为inliners的次数
(7)创建地图点函数
4、Camera
(1)相机内参K、相机外参Tcw
(2)世界坐标系、相机坐标系、图像坐标系两两转换函数
5、config
随时可以获取相机参数的函数
第二版本就是实现一个基本的VO了,最最基本的不带任何结构的VO,单纯的估计两帧之间的运动,估计成功就存起来,然后双“指针”下移,计算下面两帧的位姿。实现的是特征点法+PnP,后续可以改成光流法/直接法+ICP求T的版本。
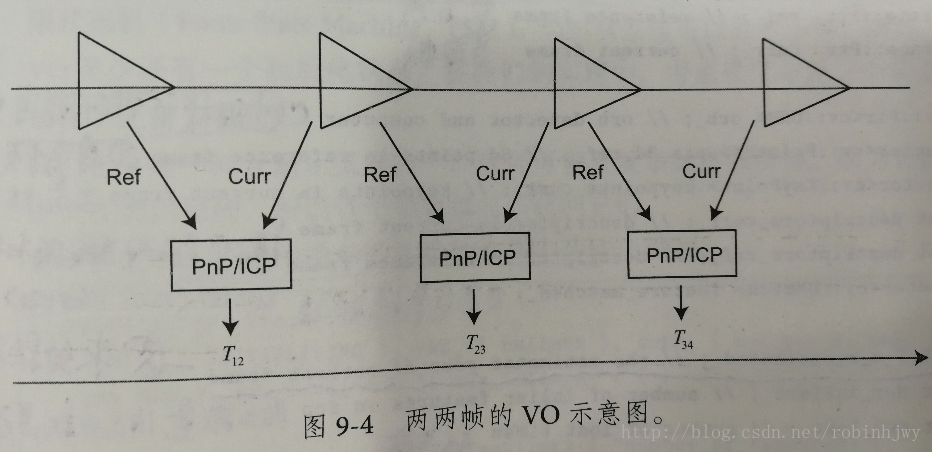

总结:
这样的VO算法,每一步都有可能失败,比如:1、图片中的特征不容易提取;2、特征点缺少深度值;3、误匹配;4、运动估计Tcw出错等等。要设计一个健壮的VO,必须要考虑到所有可能出错的地方,在checkEstimatedPose中 根据内点的数量和大小做一个简单的检测等等。
两两帧之间的视觉里程计速度和精度不理想的原因分析:1、RANSAC求解PnP。Ransac求解只采用少数的几个随机点来计算PnP,虽然能确定inlier和outlier,但是该方法容易收到噪声影响。在3d-2d存在噪声的情形下,要用RANSAC的解作为初值,再用非线性优化方法求最优值。2、这样的VO是无结果的,特征点的3D位置被当做真值来直接估计运动,实际上RGBD的深度图有误差,比如深度过近或者过远的地方。需要将特征点也一起优化。3、只考虑参考帧和当前帧的方式,位姿估计过于依赖参考帧。如果参考帧质量差,比如严重遮挡或者光照变化等,跟踪容易LOST,并且,参考帧估计不准时,还会明显的飘逸。另外,仅使用两帧数据,没有充分利用所有信息。更自然的方式是比较当前帧与地图点,这样信息更多点。我们要关注如果把当前帧和地图进行匹配,以及如何优化地图点的问题。4、两两帧VO中,特征点提取和匹配耗时太高,PnP其实很快。可以改成光流或者直接法。
在之前基础上,加入了RANSAC PnP加上迭代优化的方式估计相机位姿。
目标:因为优化位姿而不是结构,以相机为优化变量,通过最小化重投影误差来构建优化问题。自定义g2o的优化边。它只优化一个位姿,因此是一个一元边。g2o的使用:老套路,新建g2o,然后新建边 新建点 添加到optimizer里,优化optimizer.initializeOptimization();
结果:引入迭代优化后,估计结果的质量 比春错的RANSAC PnP也有明显的提高,虽然还是只用到了两两帧的数据,但是运动更精确、平稳。这就是优化的重要。但是一旦某个帧丢失,就没了,所以要用到地图点的信息。
typedef g2o::BlockSolver<g2o::BlockSolverTraits<6,2>> Block;
Block::LinearSolverType* linearSolver = new g2o::LinearSolverDense<Block::PoseMatrixType>();
Block* solver_ptr = new Block( linearSolver );
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg ( solver_ptr );
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm ( solver );
//添加顶点,一帧有一个位姿,也就是只有一个顶点
g2o::VertexSE3Expmap* pose = new g2o::VertexSE3Expmap();
pose->setId ( 0 );
pose->setEstimate ( g2o::SE3Quat (
T_c_r_estimated_.rotation_matrix(),
T_c_r_estimated_.translation()
) );
optimizer.addVertex ( pose );
// edges
//edges边有很多,每个特征点都对应一个重投影误差,也就是一条边
for ( int i=0; i<inliers.rows; i++ )
{
int index = inliers.at<int>(i,0);
// 3D -> 2D projection
EdgeProjectXYZ2UVPoseOnly* edge = new EdgeProjectXYZ2UVPoseOnly();
edge->setId(i);
edge->setVertex(0, pose);
edge->camera_ = curr_->camera_.get();
edge->point_ = Vector3d( pts3d[index].x, pts3d[index].y, pts3d[index].z );
edge->setMeasurement( Vector2d(pts2d[index].x, pts2d[index].y) );
edge->setInformation( Eigen::Matrix2d::Identity() );
optimizer.addEdge( edge );
}
//开始优化
optimizer.initializeOptimization();
//迭代次数
optimizer.optimize(10);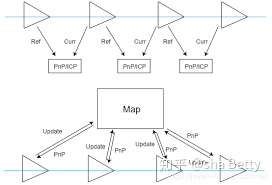
将VO匹配到的特征点放入局部地图中,并将当前帧与地图点进行匹配,计算位姿
在两两帧之间比较时,只计算了当前帧与参考帧之间的特征匹配和运动,计算之后就直接将参考帧丢掉.引入地图后,之前的每一帧都为地图贡献了一些信息,如添加新的特征点或更新旧特征点的位姿.地图中的特征点位置往往用世界坐标.因此,当前帧到来时,它与地图点之间的特征匹配与运动关系直接计算Tcw.
**优点:**我们维护了一个不断更新的地图,容错率高。地图有局部local和全局global两种。局部地图只描述附近的特征点信息,只保留离当前相机位置近的特征点,把远点丢掉。这些特征点比较可靠用来求相机的位姿。全局地图保留了slam所有的特征点,规模大。主要用来表达整个地图,主要用于回环检测和地图结果的存储。
VO比较关心的是局部地图。它是用来更新位姿的。而且单个帧与地图的特征匹配可以用一些手段进行加速。但是技术实现比较复杂。比如:在每次循环中都对地图进行增删、统计每个地图点被观测的次数进行一些策略调整等等。
1、在提取第一帧的特征点后, 将第一帧的所有特征点全部放入地图中--初始地图;
2、后续的帧,使用optimizeMap函数对地图进行优化,手段包括:删除不在视野的地图点,匹配数量减少时添加新点(可以利用三角化来更新特征点的世界坐标等)等等。
3、特征匹配代码,匹配之前,从地图中拿出一些候选点,然后将他们与当前帧的特征描述子进行匹配。
4、关键帧。后端优化的主要对象,相机运动过程中某个特殊的帧。比如每当相机经过一定间隔就保存一个关键帧。等等
**缺点:**视觉里程计能够估算局部的相机运动与特征点的位置,但是缺点也很明显:
1、易丢失:一旦丢失,要么等相机回来,要么重置
2、轨迹漂移:误差累计