Author: Swarna Saraf
This project uses fastai 1.0.33 which sits on top of PyTorch 1.0. See Developer Install instructions here.
git clone https://github.com/fastai/fastai
cd fastai
tools/run-after-git-clone
pip install -e ".[dev]"
Note: fastai v1 currently supports Linux only, and requires PyTorch v1 and Python 3.6 or later.
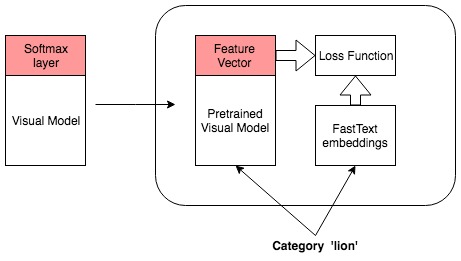
The project implements a deep visual-semantic model based on Squeezenet 1.1 architecture and trained with fastText word vectors. The model takes in image input and outputs a 300-D image feature vector. Using nmslib, an efficient cross-platform similarity search, the output feature vector is used for (1) Image To Image: Searching similar Images in model predictions, (2) Image to Text: Predicting Label for an image based on nearest fastText word vector for the label in the dataset (3) Text to Image: Predicting nearest image for an input text label based on nearest image feature vector in model predictions to the fastText word vector for the given label (zero shot).
AWA2, a benchmark dataset for transfer learning algorithms such as zero-shot learning, is used for this project. It consists of 37322 images for 50 animal categories. The images in the dataset are in JPEG format. The dataset (~13 GB) can be downloaded from here.
Here is the structure of the data:
path/
JPEGImages\
antelope\
antelope_10001.jpg
antelope_10002.jpg
...
bobcat\
bobcat_10001.jpg
bobcat_10002.jpg
...
.
.
.
...
classes.txt
trainclasses.txt
testclasses.txt
classes.txt contains names of all the 50 animal categories, one per line. trainclasses.txt contains names of 40 animal categories (one per line) to be used for training/ validation. testclasses contains names of 10 animal categories (one per line) to be used for zero-shot tests.
The images are named following {label}_{id}.jpg where the label is in classes.txt.
Train/valid sets: 30,337 images in the 40 train classes are split 90:10 to create train and valid sets.
Test set: 6985 images belonging to 10 separate classes are set aside purely for zero-shot tests.
Once the data is downloaded, scripts copy_awa2.py and move_awa2.py , available in utils folder, are used to move the data into train folder and then carve out a valid folder based on provided percentage split. The same script can be used to create a test folder with test images. The input parameters for the script need to be updated in the script itself (top section) . For running the scipts, use python command below:
python [copy_awa2.py | move_awa2.py]Note: A subset of the dataset, data_samples.zip, is provided in the repository for reference.
Jupyter notebooks VisualSemanticModels_Squeezenet1_1.ipynb and VisualSemanticModels_Resnet34.ipynb(baseline) contain the code for:
- Data Augmentation (applying pixel and coordinate transforms to data)
- Hyperparameter Search
- Model Training
- Displaying the results
- Error Analysis (Stage 1: Confusion Matrix, heatmaps. Stage 2: PCA Analysis)
- Zero shot tests
Model training is performed in two stages:
- Stage 1: A CNN model for multi-classification task is trained for accuracy. Cross entropy loss is used in this stage.
- Stage 2: A visual-semantic model is trained (by throwing away the softmax layers used in Stage 1) to output a 300-D image feature vector. Cosine similarity loss, between image feature vector (300-D model output) and fastText word vector representation for true image label, is used in this second stage.
Note: Models from Stage-1 and Stage-2 training phases for Squeezenet 1.1 (and baseline Resnet34) are provided in the repo as models.zip
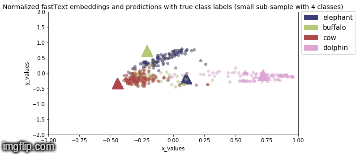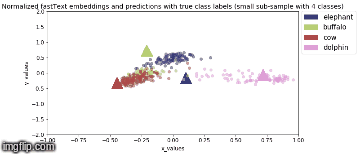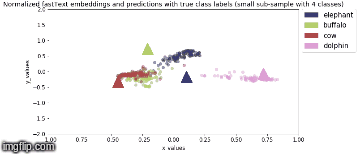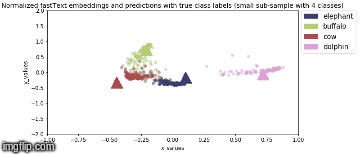
Model is saved after every epoch. PCA Analysis is done in Stage 2 where four animal categories are chosen viz., elephant, buffalo, cow, dolphin and their feature vector representation, for all valid samples, are obtained from model output.
2D Visualization of the normalized image feature vector representation for this sub-sample of the image classes along with normalized true fastText word vector representation for the same image class labels (represented by triangles) are shown below:
Stage 2a: During backbone freeze, when only custom head is trained (5 epochs)
Stage 2b: During backbone unfreeze, when whole model is fine tuned (3 epochs)
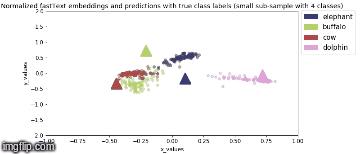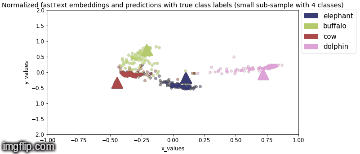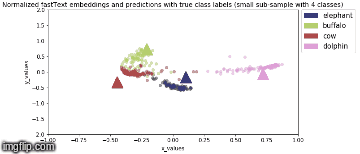
Squeezenet 1.1 based model gives higher Top-1 accuracy and uses ~6MB (7% less space) for similar training parameters as baseline Resnet34!
It is feasible to build lightweight visual-semantic models for mobile applications while meeting acceptable performance thresholds.