


[arXiv] [NeurIPS2021 Proceedings]
Docs | Google Group | Tutorial | Installation | Usage | Slides | Quickstart | Open Bandit Dataset | 日本語
Table of Contents
Open Bandit Dataset is a public real-world logged bandit dataset. This dataset is provided by ZOZO, Inc., the largest fashion e-commerce company in Japan. The company uses some multi-armed bandit algorithms to recommend fashion items to users in a large-scale fashion e-commerce platform called ZOZOTOWN. The following figure presents the displayed fashion items as actions where there are three positions in the recommendation interface.

Recommended fashion items as actions in the ZOZOTOWN recommendation interface
The dataset was collected during a 7-day experiment on three “campaigns,” corresponding to all, men's, and women's items, respectively. Each campaign randomly used either the Uniform Random policy or the Bernoulli Thompson Sampling (Bernoulli TS) policy for the data collection. Open Bandit Dataset is unique in that it contains a set of multiple logged bandit datasets collected by running different policies on the same platform. This enables realistic and reproducible experimental comparisons of different OPE estimators for the first time (see Section 5 of the reference paper for the details of the evaluation of OPE protocol using Open Bandit Dataset).
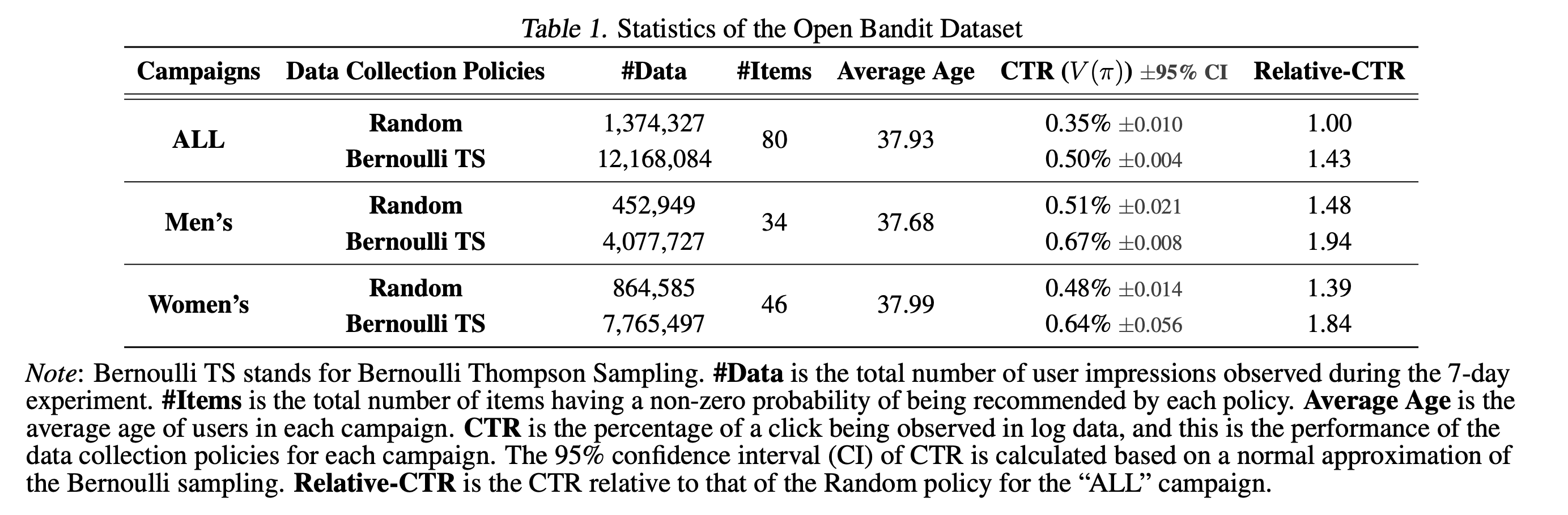
The small size version of our data is available at obd. We release the full size version of our data at https://research.zozo.com/data.html. Please download the full size version for research uses. Please also see obd/README.md for the detailed dataset description.
Open Bandit Pipeline is an open-source Python software including a series of modules for implementing dataset preprocessing, policy learning methods, and OPE estimators. Our software provides a complete, standardized experimental procedure for OPE research, ensuring that performance comparisons are fair and reproducible. It also enables fast and accurate OPE implementation through a single unified interface, simplifying the practical use of OPE.

Overview of the Open Bandit Pipeline
Open Bandit Pipeline consists of the following main modules.
- dataset module: This module provides a data loader for Open Bandit Dataset and a flexible interface for handling logged bandit data. It also provides tools to generate synthetic bandit data and transform multi-class classification data to bandit data.
- policy module: This module provides interfaces for implementing new online and offline bandit policies. It also implements several standard policy learning methods.
- simulator module: This module provides functions for conducting offline bandit simulation. This module is necessary only when you use the ReplayMethod to evaluate online bandit policies. Please refer to examples/quickstart/online.ipynb for a quickstart guide of implementing OPE of online bandit algorithms.
- ope module: This module provides generic abstract interfaces to support custom implementations so that researchers can evaluate their own estimators easily. It also implements several basic and advanced OPE estimators.
Bandit Algorithms (click to expand)
- Online
- Non-Contextual (Context-free)
- Random
- Epsilon Greedy
- Bernoulli Thompson Sampling
- Contextual (Linear)
- Linear Epsilon Greedy
- Linear Thompson Sampling
- Linear Upper Confidence Bound
- Contextual (Logistic)
- Logistic Epsilon Greedy
- Logistic Thompson Sampling
- Logistic Upper Confidence Bound
- Non-Contextual (Context-free)
- Offline (Off-Policy Learning)
- Inverse Probability Weighting (IPW) Learner
- Neural Network-based Policy Learner
OPE Estimators (click to expand)
- OPE of Online Bandit Algorithms
- OPE of Offline Bandit Algorithms
- Direct Method (DM)
- Inverse Probability Weighting (IPW)
- Self-Normalized Inverse Probability Weighting (SNIPW)
- Doubly Robust (DR)
- Switch Estimators
- More Robust Doubly Robust (MRDR)
- Doubly Robust with Optimistic Shrinkage (DRos)
- Sub-Gaussian Inverse Probability Weighting (SGIPW)
- Sub-Gaussian Doubly Robust (SGDR)
- Double Machine Learning (DML)
- OPE of Offline Slate Bandit Algorithms
- Independent Inverse Propensity Scoring (IIPS)
- Reward Interaction Inverse Propensity Scoring (RIPS)
- Cascade Doubly Robust (Cascade-DR)
- OPE of Offline Bandit Algorithms with Continuous Actions
Please refer to Section 2 and the Appendix of the reference paper for the standard formulation of OPE and the definitions of a range of OPE estimators. Note that, in addition to the above algorithms and estimators, Open Bandit Pipeline provides flexible interfaces. Therefore, researchers can easily implement their own algorithms or estimators and evaluate them with our data and pipeline. Moreover, Open Bandit Pipeline provides an interface for handling real-world logged bandit data. Thus, practitioners can combine their own real-world data with Open Bandit Pipeline and easily evaluate bandit algorithms' performance in their settings with OPE.
You can install OBP using Python's package manager pip.
pip install obp
You can also install OBP from source.
git clone https://github.com/st-tech/zr-obp
cd zr-obp
python setup.py installOpen Bandit Pipeline supports Python 3.7 or newer. See pyproject.toml for other requirements.
Here is an example of conducting OPE of the performance of IPWLearner as an evaluation policy using Direct Method (DM), Inverse Probability Weighting (IPW), Doubly Robust (DR) as OPE estimators.
# implementing OPE of the IPWLearner using synthetic bandit data
from sklearn.linear_model import LogisticRegression
# import open bandit pipeline (obp)
from obp.dataset import SyntheticBanditDataset
from obp.policy import IPWLearner
from obp.ope import (
OffPolicyEvaluation,
RegressionModel,
InverseProbabilityWeighting as IPW,
DirectMethod as DM,
DoublyRobust as DR,
)
# (1) Generate Synthetic Bandit Data
dataset = SyntheticBanditDataset(n_actions=10, reward_type="binary")
bandit_feedback_train = dataset.obtain_batch_bandit_feedback(n_rounds=1000)
bandit_feedback_test = dataset.obtain_batch_bandit_feedback(n_rounds=1000)
# (2) Off-Policy Learning
eval_policy = IPWLearner(n_actions=dataset.n_actions, base_classifier=LogisticRegression())
eval_policy.fit(
context=bandit_feedback_train["context"],
action=bandit_feedback_train["action"],
reward=bandit_feedback_train["reward"],
pscore=bandit_feedback_train["pscore"]
)
action_dist = eval_policy.predict(context=bandit_feedback_test["context"])
# (3) Off-Policy Evaluation
regression_model = RegressionModel(
n_actions=dataset.n_actions,
base_model=LogisticRegression(),
)
estimated_rewards_by_reg_model = regression_model.fit_predict(
context=bandit_feedback_test["context"],
action=bandit_feedback_test["action"],
reward=bandit_feedback_test["reward"],
)
ope = OffPolicyEvaluation(
bandit_feedback=bandit_feedback_test,
ope_estimators=[IPW(), DM(), DR()]
)
ope.visualize_off_policy_estimates(
action_dist=action_dist,
estimated_rewards_by_reg_model=estimated_rewards_by_reg_model,
)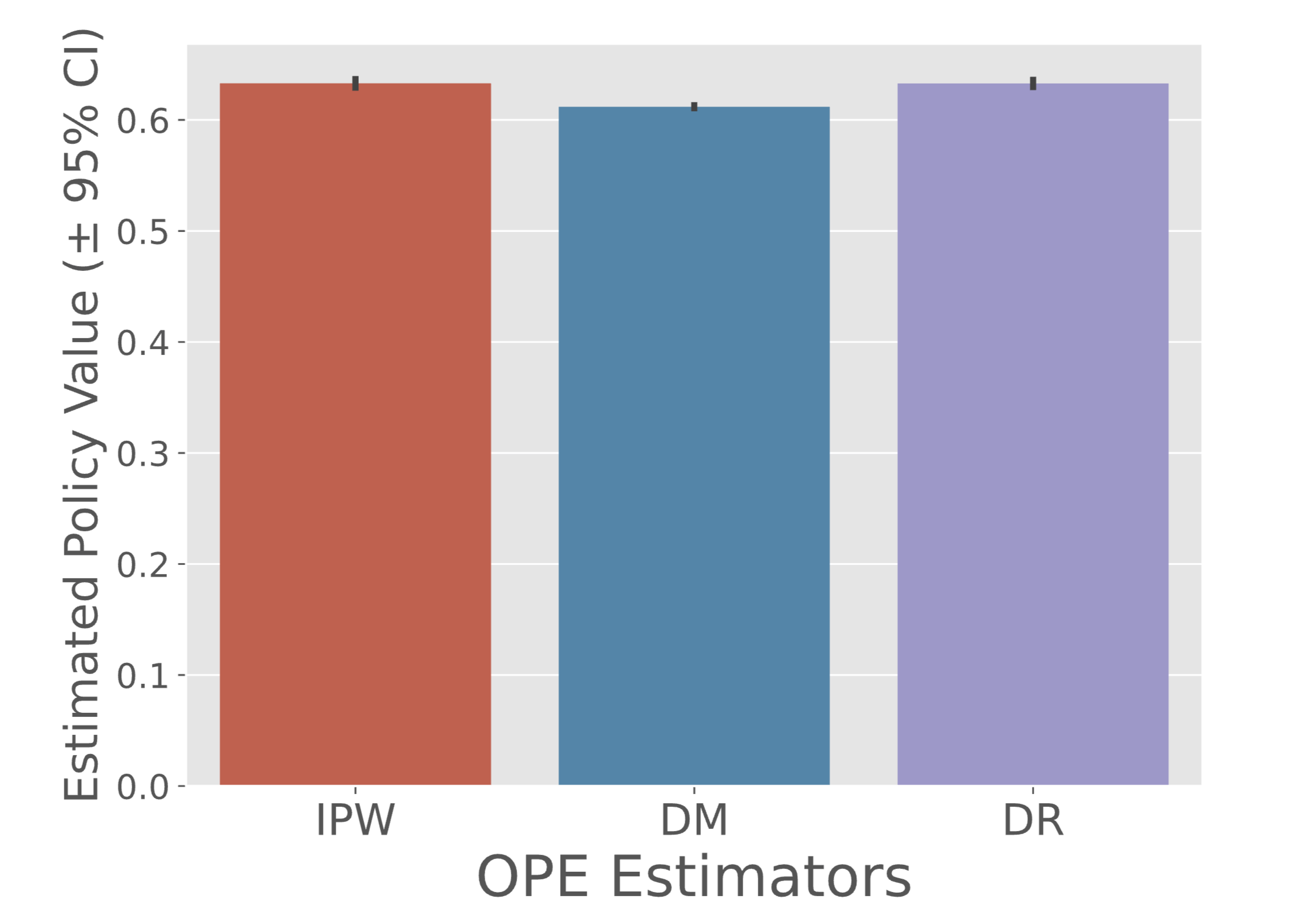
Performance of IPWLearner estimated by OPE
A formal quickstart example with synthetic bandit data is available at examples/quickstart/synthetic.ipynb. We also prepare a script to conduct the evaluation of OPE experiment with synthetic bandit data in examples/synthetic.
Researchers often use multi-class classification data to evaluate the estimation accuracy of OPE estimators. Open Bandit Pipeline facilitates this kind of OPE experiments with multi-class classification data as follows.
# implementing an experiment to evaluate the accuracy of OPE using classification data
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
# import open bandit pipeline (obp)
from obp.dataset import MultiClassToBanditReduction
from obp.ope import OffPolicyEvaluation, InverseProbabilityWeighting as IPW
# (1) Data Loading and Bandit Reduction
X, y = load_digits(return_X_y=True)
dataset = MultiClassToBanditReduction(X=X, y=y, base_classifier_b=LogisticRegression(random_state=12345))
dataset.split_train_eval(eval_size=0.7, random_state=12345)
bandit_feedback = dataset.obtain_batch_bandit_feedback(random_state=12345)
# (2) Evaluation Policy Derivation
# obtain action choice probabilities of an evaluation policy
action_dist = dataset.obtain_action_dist_by_eval_policy(base_classifier_e=RandomForestClassifier(random_state=12345))
# calculate the ground-truth performance of the evaluation policy
ground_truth = dataset.calc_ground_truth_policy_value(action_dist=action_dist)
print(ground_truth)
0.9634340222575517
# (3) Off-Policy Evaluation and Evaluation of OPE
ope = OffPolicyEvaluation(bandit_feedback=bandit_feedback, ope_estimators=[IPW()])
# evaluate the estimation performance (accuracy) of IPW by the relative estimation error (relative-ee)
relative_estimation_errors = ope.evaluate_performance_of_estimators(
ground_truth_policy_value=ground_truth,
action_dist=action_dist,
metric="relative-ee",
)
print(relative_estimation_errors)
{'ipw': 0.01827255896321327} # the accuracy of IPW in OPEA formal quickstart example with multi-class classification data is available at examples/quickstart/multiclass.ipynb. We also prepare a script to conduct the evaluation of OPE experiment with multi-class classification data in examples/multiclass.
Here is an example of conducting OPE of the performance of BernoulliTS as an evaluation policy using Inverse Probability Weighting (IPW) and logged bandit data generated by the Random policy (behavior policy) on the ZOZOTOWN platform.
# implementing OPE of the BernoulliTS policy using log data generated by the Random policy
from obp.dataset import OpenBanditDataset
from obp.policy import BernoulliTS
from obp.ope import OffPolicyEvaluation, InverseProbabilityWeighting as IPW
# (1) Data Loading and Preprocessing
dataset = OpenBanditDataset(behavior_policy='random', campaign='all')
bandit_feedback = dataset.obtain_batch_bandit_feedback()
# (2) Production Policy Replication
evaluation_policy = BernoulliTS(
n_actions=dataset.n_actions,
len_list=dataset.len_list,
is_zozotown_prior=True, # replicate the policy in the ZOZOTOWN production
campaign="all",
random_state=12345
)
action_dist = evaluation_policy.compute_batch_action_dist(
n_sim=100000, n_rounds=bandit_feedback["n_rounds"]
)
# (3) Off-Policy Evaluation
ope = OffPolicyEvaluation(bandit_feedback=bandit_feedback, ope_estimators=[IPW()])
estimated_policy_value = ope.estimate_policy_values(action_dist=action_dist)
# estimated performance of BernoulliTS relative to the ground-truth performance of Random
relative_policy_value_of_bernoulli_ts = estimated_policy_value['ipw'] / bandit_feedback['reward'].mean()
print(relative_policy_value_of_bernoulli_ts)
1.198126...A formal quickstart example with Open Bandit Dataset is available at examples/quickstart/obd.ipynb. We also prepare a script to conduct the evaluation of OPE using Open Bandit Dataset in examples/obd. Please see our documentation for the details of the evaluation of OPE protocol based on Open Bandit Dataset.
If you use our dataset and pipeline in your work, please cite our paper:
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, Yusuke Narita.
Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation
https://arxiv.org/abs/2008.07146
Bibtex:
@article{saito2020open,
title={Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation},
author={Saito, Yuta and Shunsuke, Aihara and Megumi, Matsutani and Yusuke, Narita},
journal={arXiv preprint arXiv:2008.07146},
year={2020}
}
The paper has been accepted at NeurIPS2021 Datasets and Benchmarks Track. The camera-ready version of the paper is available here.
In addition to OBP, we develop a Python package called pyIEOE, which allows practitioners to easily evaluate and compare the robustness of OPE estimators.
Please also see the following reference paper about IEOE (accepted at RecSys'21).
Yuta Saito, Takuma Udagawa, Haruka Kiyohara, Kazuki Mogi, Yusuke Narita, Kei Tateno.
Evaluating the Robustness of Off-Policy Evaluation
https://arxiv.org/abs/2108.13703
If you are interested in the Open Bandit Project, please follow its updates via the google group: https://groups.google.com/g/open-bandit-project
Any contributions to Open Bandit Pipeline are more than welcome! Please refer to CONTRIBUTING.md for general guidelines how to contribute to the project.
This project is licensed under the Apache 2.0 License - see the LICENSE file for details.
- Yuta Saito (Main Contributor; Cornell University)
- Shunsuke Aihara (ZOZO Research)
- Megumi Matsutani (ZOZO Research)
- Yusuke Narita (Hanjuku-kaso Co., Ltd. / Yale University)
- Masahiro Nomura (CyberAgent, Inc. / Hanjuku-kaso Co., Ltd.)
- Koichi Takayama (Hanjuku-kaso Co., Ltd.)
- Ryo Kuroiwa (University of Toronto / Hanjuku-kaso Co., Ltd.)
- Haruka Kiyohara (Tokyo Institute of Technology / Hanjuku-kaso Co., Ltd.)
For any question about the paper, data, and pipeline, feel free to contact: [email protected]
Papers (click to expand)
-
Alina Beygelzimer and John Langford. The offset tree for learning with partial labels. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery&Data Mining, 129–138, 2009.
-
Olivier Chapelle and Lihong Li. An empirical evaluation of thompson sampling. In Advances in Neural Information Processing Systems, 2249–2257, 2011.
-
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, 297–306, 2011.
-
Alex Strehl, John Langford, Lihong Li, and Sham M Kakade. Learning from Logged Implicit Exploration Data. In Advances in Neural Information Processing Systems, 2217–2225, 2010.
-
Doina Precup, Richard S. Sutton, and Satinder Singh. Eligibility Traces for Off-Policy Policy Evaluation. In Proceedings of the 17th International Conference on Machine Learning, 759–766. 2000.
-
Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. Doubly Robust Policy Evaluation and Optimization. Statistical Science, 29:485–511, 2014.
-
Adith Swaminathan and Thorsten Joachims. The Self-normalized Estimator for Counterfactual Learning. In Advances in Neural Information Processing Systems, 3231–3239, 2015.
-
Dhruv Kumar Mahajan, Rajeev Rastogi, Charu Tiwari, and Adway Mitra. LogUCB: An Explore-Exploit Algorithm for Comments Recommendation. In Proceedings of the 21st ACM international conference on Information and knowledge management, 6–15. 2012.
-
Lihong Li, Wei Chu, John Langford, Taesup Moon, and Xuanhui Wang. An Unbiased Offline Evaluation of Contextual Bandit Algorithms with Generalized Linear Models. In Journal of Machine Learning Research: Workshop and Conference Proceedings, volume 26, 19–36. 2012.
-
Yu-Xiang Wang, Alekh Agarwal, and Miroslav Dudik. Optimal and Adaptive Off-policy Evaluation in Contextual Bandits. In Proceedings of the 34th International Conference on Machine Learning, 3589–3597. 2017.
-
Mehrdad Farajtabar, Yinlam Chow, and Mohammad Ghavamzadeh. More Robust Doubly Robust Off-policy Evaluation. In Proceedings of the 35th International Conference on Machine Learning, 1447–1456. 2018.
-
Nathan Kallus and Masatoshi Uehara. Intrinsically Efficient, Stable, and Bounded Off-Policy Evaluation for Reinforcement Learning. In Advances in Neural Information Processing Systems. 2019.
-
Yi Su, Lequn Wang, Michele Santacatterina, and Thorsten Joachims. CAB: Continuous Adaptive Blending Estimator for Policy Evaluation and Learning. In Proceedings of the 36th International Conference on Machine Learning, 6005-6014, 2019.
-
Yi Su, Maria Dimakopoulou, Akshay Krishnamurthy, and Miroslav Dudík. Doubly Robust Off-policy Evaluation with Shrinkage. In Proceedings of the 37th International Conference on Machine Learning, 9167-9176, 2020.
-
Nathan Kallus and Angela Zhou. Policy Evaluation and Optimization with Continuous Treatments. In International Conference on Artificial Intelligence and Statistics, 1243–1251. PMLR, 2018.
-
Aman Agarwal, Soumya Basu, Tobias Schnabel, and Thorsten Joachims. Effective Evaluation using Logged Bandit Feedback from Multiple Loggers. In Proceedings of the 23rd ACM SIGKDD international conference on Knowledge discovery and data mining, 687–696, 2017.
-
Nathan Kallus, Yuta Saito, and Masatoshi Uehara. Optimal Off-Policy Evaluation from Multiple Logging Policies. In Proceedings of the 38th International Conference on Machine Learning, 5247-5256, 2021.
-
Shuai Li, Yasin Abbasi-Yadkori, Branislav Kveton, S Muthukrishnan, Vishwa Vinay, and Zheng Wen. Offline Evaluation of Ranking Policies with Click Models. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery&Data Mining, 1685–1694, 2018.
-
James McInerney, Brian Brost, Praveen Chandar, Rishabh Mehrotra, and Benjamin Carterette. Counterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery&Data Mining, 1779–1788, 2020.
-
Yusuke Narita, Shota Yasui, and Kohei Yata. Debiased Off-Policy Evaluation for Recommendation Systems. In Proceedings of the Fifteenth ACM Conference on Recommender Systems, 372-379, 2021.
-
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open Graph Benchmark: Datasets for Machine Learning on Graphs. In Advances in Neural Information Processing Systems. 2020.
-
Noveen Sachdeva, Yi Su, and Thorsten Joachims. Off-policy Bandits with Deficient Support. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 965-975, 2021.
-
Yi Su, Pavithra Srinath, and Akshay Krishnamurthy. Adaptive Estimator Selection for Off-Policy Evaluation. In Proceedings of the 38th International Conference on Machine Learning, 9196-9205, 2021.
-
Haruka Kiyohara, Yuta Saito, Tatsuya Matsuhiro, Yusuke Narita, Nobuyuki Shimizu, Yasuo Yamamoto. Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 487-497, 2022.
-
Yuta Saito and Thorsten Joachims. Off-Policy Evaluation for Large Action Spaces via Embeddings. In Proceedings of the 39th International Conference on Machine Learning, 2022.
Projects (click to expand)
The Open Bandit Project is strongly inspired by Open Graph Benchmark --a collection of benchmark datasets, data loaders, and evaluators for graph machine learning: [github] [project page] [paper].