Solr ships with all the tools and features necessary for an advanced search solution. These include the oft overlooked update request processors. They operate at the document level i.e. prior to individual field tokenisation and allow you to clean, modify and/or enrich incoming documents. Processing options include language identification, duplicate detection and HTML markup handling. Create a chain of them and you have a true document processing pipeline.
Some data sources contain documents with content fields that are dynamically populated by content from other documents. For a query to retrieve these kinds of documents, the external content needs to be retrieved and added during index time.
During index time, the processor scans incoming documents for a predefined field, topicRef for example, with a reference to one or more documents already present in the index. The referenced document(s) either contains a subsequent reference field or content that we want to add to the incoming document.
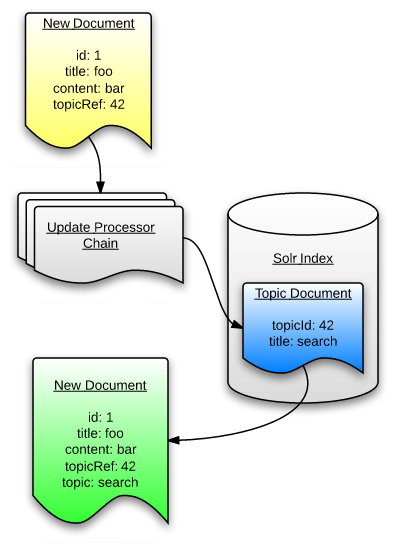
The processor retrieves any referenced documents, traverses a tree of subsequently referenced documents if necessary, and then maps the eventual leaf documents’ specified content fields to additional new fields in the incoming document.
In progress.
@sebnmuller