The City of New York would like to develop a Data Analytics platform on Azure Synapse Analytics to accomplish two primary objectives:
- Analyze how the City's financial resources are allocated and how much of the City's budget is being devoted to overtime.
- Make the data available to the interested public to show how the City’s budget is being spent on salary and overtime pay for all municipal employees.
The source data resides in Azure Data Lake and needs to be processed in a NYC data warehouse. The source datasets consist of CSV files with Employee master data and monthly payroll data entered by various City agencies.
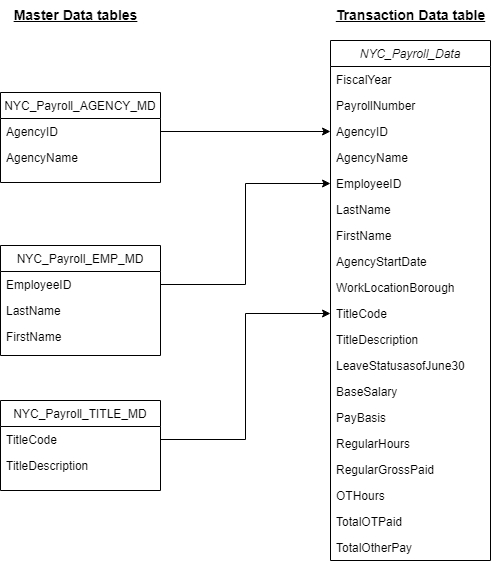
NYC Payroll DB Schema.
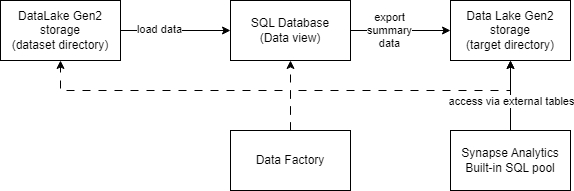
High level Pipeline Overview.