| layout |
|---|
default |

An introduction to lymph, a framework for Python services
by Max Brauer
Hi, and thanks for being here. I'd like to introduce you to lymph and Python services. This introduction explains how to write and run services with lymph. We explore lymph's capabilities and tooling by progressively creating a little cluster, service by service. It is very much hands-on and example-driven. Worry not, we have prepared a playground in a vagrant box.
The vagrant box provisions with all tooling and code ready for your perusal. It has both ZooKeeper(for service discovery) and RabbitMQ(as an event system) running inside. Services and lymph's tooling can be explored within pre-configured tmux sessions.
The only prerequisites are vagrant and ansible on your host machine.
Getting your hand's dirty is a matter of:
git clone [email protected]:mamachanko/import-lymph.git
cd import-lymph
vagrant up && vagrant sshYou will be prompted for your root password half-way through vagrant up
because we use NFS to share files. If on Ubuntu(or somewhere else) you may have
to install packages to support NFS.
Once inside the box, the motd
contains more information. You can replay all the examples shown in this
introduction. Here's a little teaser:
Let's go ahead then!
Lymph is a framework for writing services in Python. With lymph you can write services with almost no boilerplate, easily run, test and configure them. But let's introduce ourselves first.
We're Delivery Hero, a holding of online food-ordering services. We're located in Berlin. We operate in 34 countries and growing.
Let me explain the concept of online food-ordering to those who're unfamiliar with it. However, I seriously doubt this is news to anyone. The concept is simple:
- get hungry
- go online
- search for restaurants
- compile your order
- pay online
- wait for delivery
Basically, it's E-commerce with very grumpy customers and an emphasis on fast fulfillment.
How's this introduction structured? Let's briefly go over the topics:
- We're going to explain where we're coming from and why we have given birth to a(nother) framework
- We'll look at code as fast possible
- We'll run services and progressively add new services to explore forms of communication and the tooling of lymph
- We'll give you a brief overview of further features and talk about how lymph does things under the hood
- We'll touch on similar technology and see how it relates to lymph (Nameko in particular)
- We'll talk future plans for lymph and its ecosystem
- That's it :)
Before we go ahead, here's a little disclaimer. For the sake of this introduction, we assume that you're familiar with the concept of services. We assume you're familiar with monoliths. We assume that you are familiar with when and why to use either and even more so when not. We will not discuss the differences between the two. We won't talk about whether services will save your development teams or your business. Neither will we talk about the cloud, Docker, whether to call it "microservices" ...
Yet, what we're going to talk about is lymph. By the end of this introduction you should be able understand what lymph can and cannot do and why that's cool. If I achieved that I succeeded.
Around two years ago "we wanted services in Python and not worry". In fact, this statement expresses three desires: services, Python and comfort. The first two need to be justified. The remaining one yielded lymph.
We wanted services because our big Django monolith hurt a lot. We weren't moving fast at all. We've had trouble finding rhythm for a growing number of teams and developers. Teams were blocked by other teams. The code base was a big bowl of legacy spaghetti. We've had issues scaling. Basically, what comes to mind is the textbook situation: "my monolith hurts, I want services". The idea of a service-oriented architecture became increasingly reasonable and attractive to us.
Yet, why did we want to stick to Python? Well, to begin with, we like Python a lot. We've had a good amount of experience running it in Production. And we wanted all developers to stay productive.
Lastly, we didn't want to worry. As a developer you shouldn't have to worry about how to run your service, how register it, how to discover other service or how to serialize anything to send it over the wire. At that time there was nothing that fit our needs. We wanted some very specific things:
- Running and testing services should be easy.
- Developers shouldn't have to worry about registering and discovering services.
- You don't have to serialize data for sending it over the wire. Neither do you want to manually deserialize it.
- Requesting remote services should be almost like in-process calls.
- Developers shouldn't have to deal with event loops nor know about any transport mechanism.
- Configuring services should be straightforward and flexible.
- Scaling should be easy, but transparent to clients.
- Services should speak HTTP.
- We don't want boilerplate if it can be avoided.
To sum things up, we wanted as little in the way as possible between developers and functionality they want to serve.
You might say "hey, use nameko". But Nameko has not come to our attention until few months ago. Neither was it mature enough to be adopted way back then. Later though, we're going to talk technologies similar to Nameko and lymph.
Taking all these things into consideration, rolling our own thing was very reasonable. And to not suspend any further, say hello to lymph. Hopefully, you're itching to see what a service looks like in lymph.
We'll break the ice by running and playing around with services. We'll slowly
progress through lymph's features, service by service. This is a good time to
boot the vagrant box: vagrant up.
This
is what a simple greeting service looks like in lymph. Its interface is one RPC
method called greet which takes a name, prints it, emits an event(containing
the name in the body) and returns a greeting for the given name.
import lymph
class Greeting(lymph.Interface):
@lymph.rpc()
def greet(self, name):
print('Saying hi to %s' % name)
self.emit('greeted', {'name': name})
return u'Hi, %s!' % nameAll we need to do to make things happen is to inherit from lymph.Interface
and decorate RPC methods with @lymph.rpc(). Lastly, we've got the interface's
emit() function to our disposal which dispatches events in the event system.
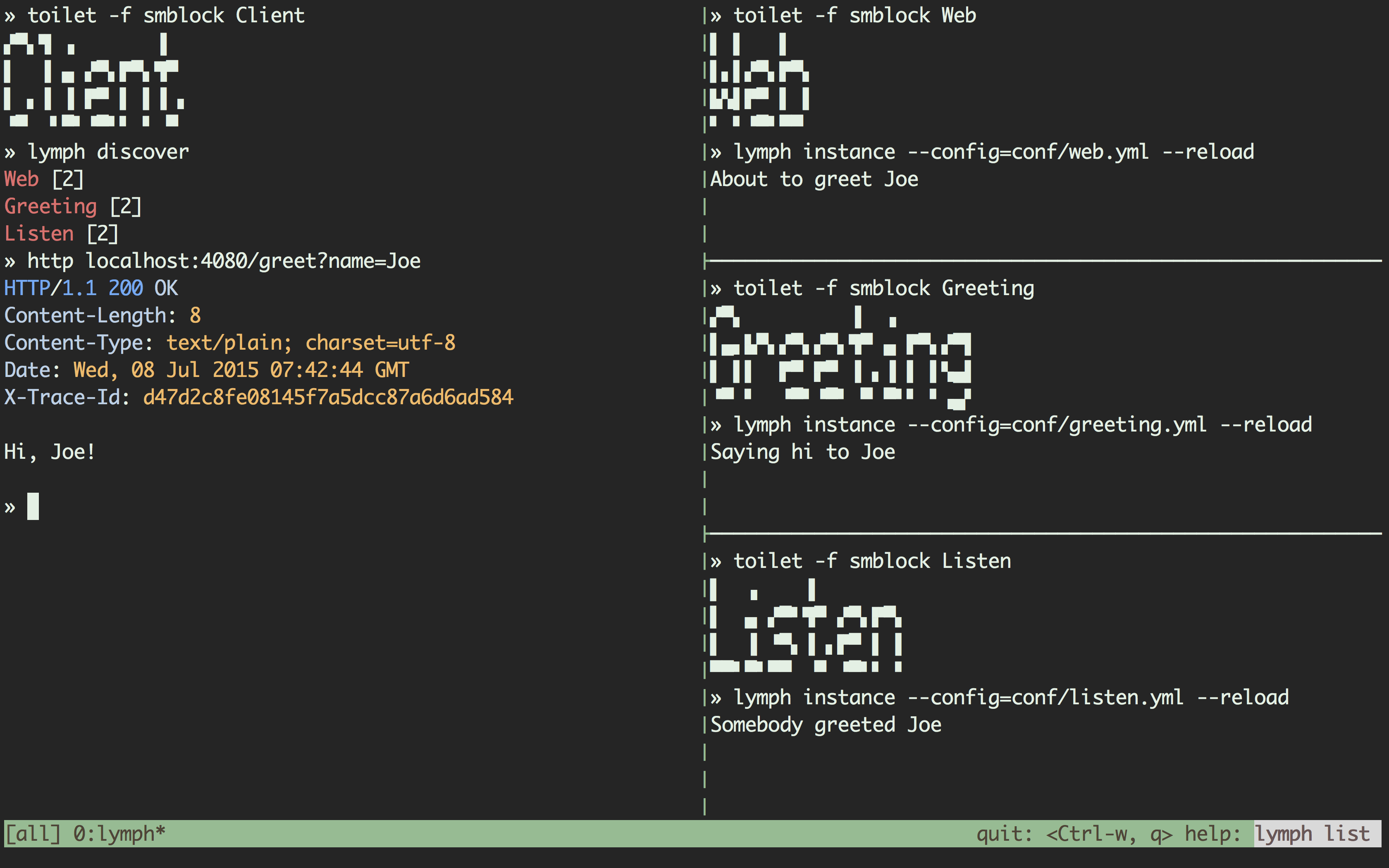
Let's jump on the shell and play with it. Within our vagrant box, this will start a tmux session and run an instance of the Greeting service:
» mux start greetingWhat you see is a tmux session with two panes. On the right-hand side you
see the greeting service being run with lymph's instance command. On the
left-hand side you see a plain shell on which we'll explore lymph's tooling.
If you're lazy and don't want to continue reading this section nor try things
yourself here's a screencast:

Every time you want to run an instance of a service you need to point lymph to
its configuration. The configuration tells lymph about the interface's name and
where it can import it from. Since lymph imports the interface at runtime, the
module needs to be on the PYTHONPATH. We can make this happen with export PYTHONPATH=services in our example. But worry not, the tmuxinator sessions
take care of it for you. Our service's configuration looks like
this:
interfaces:
Greeting:
class: greeting:GreetingThe lymph instance command receives the path to this file.
One of the first things we considered when building lymph was the tooling. We think we managed to get some very nice tooling built around it to make development of services easier.
So what tooling is available? lymph list will tell us.
» lymph list
node Run a node service that manages a group of processes on the same machine.
shell Open an interactive Python shell locally or remotely.
help Display help information about lymph.
instance Run a single service instance (one process).
list List available commands.
inspect Describes the RPC interface of a service
request Send a request message to some service and output the reply.
discover Show available services.
subscribe Prints events to stdout.
tail Stream the logs of one or more services.
emit Manually emits an event.You see there's plenty of commands available to interact with services. Worry not, we'll explore them one by one.
To begin with we'll assert that an instance of the echo service is running.
That's what lymph's discover command is for:
» lymph discover
Greeting [1]As you can see, one instance is running indeed (Greeting [1]). But what did
just happen? When the service started in the right-hand panel it registered
itself with ZooKeeper by providing its name and address. When we ran the
discovery command found that entry. If we stopped the service, it'd unregister
itself and the discovery command would say that no instances are running.
Let's pretend we don't know what the greeting service has to offer. We'd like to find out about its interface though:
» lymph inspect Greeting
RPC interface of Greeting
Returns a greeting for a provided name
rpc Greeting.greet(name)
rpc lymph.get_metrics()
rpc lymph.inspect()
Returns a description of all available rpc methods of this service
rpc lymph.ping(payload)
rpc lymph.status()We see that the interface of the greeting service is composed of inherited
methods(from lymph.Interface) and our greet method. Let's exercise the
greet method. We'll use lymph's request command. Therefore, we have to
provide the service name, the name of the method and the body of the request as
valid JSON. What we expect to see is the Greeting service to return a Greeting
but it should also print it and emit an event.
» lymph request Greeting.greet '{"name": "Flynne"}'
u'Hi, Flynne!'The response to the RPC request is 'Hi, Flynne!'. It's as expected and the
service printed the name. But what exactly did just happen? When we issued the
request lymph did the following:
- it looked up the address of the greeting service instance in ZooKeeper
- serialized the request body with MessagePack
- sent it over the wire via ZeroMQ
- the service received the request
- the service deserialized the request using MessagePack
- the service performed the heavy computation to produce the desired greeting for Flynne
- an event is being emitted to the event system about which we will find out more with the next service
- the response was once again serialized(MessagePack) and sent back(ZeroMQ) to the requestee
- the requestee(our shell client) deseria... and printed
Whoi! That's a lot. This is where lymph lives up to this introduction's claim. This is all the glue that lymph is.
Here's a visualisation of what happened. The purple clipboard is synonymous
with ZooKeeper as the service registry and the Greeting service instance is
the red speech bubble:
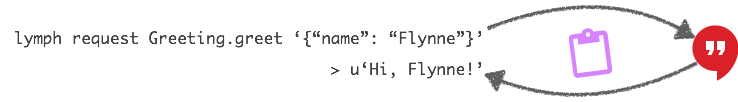
Our single service is rather boring though. It's also pretty lonely. Nobody listens to its events. Here comes a listener.
The listen
service
listens to greeting's events. Again, it's a lymph service(we inherit from
lymph.Interface). However, there's nothing but one method which consumes
greeted events. It simply prints the greeted name contained in the event's
body. Every time an event of this type occurs exactly one instance of the listen
service will consume it.
import lymph
class Listen(lymph.Interface):
@lymph.event('greeted')
def on_greeted(self, event):
print('Somebody greeted %s' % event['name'])The listen service's configuration is no different from the one before.
Let's exercise our services combination. This time round, though, we'll run two instances of the greeting service and one instance of the listen service:
» mux start greeting-listenAgain, we see a tmux session. On the right you find two instances of the greeting service followed by an instance of the listen service.
Here's the screencast:

We should find them registered correctly.
» lymph discover
Greeting [2]
Listen [1]And, indeed, they list correctly. Remember, this comes from Zookeeper.
Let's emit a greeted event in the event system to assert whether the listen
service listens to it. We'll use lymph's emit command. We're expecting the
listen service to print the name field from the event body.
» lymph emit greeted '{"name": "Flynne"}'
Nice. That worked. The listen service printed as expected. But what did just
happen exactly? Our shell client serialized the event body using MessagePack and
published it to RabbitMQ with the greeted event type. Then it returned. The
listen service on the other hand is subscribed to these events in RabbitMQ.
Once we published it consumed the event, deserialized it and processed it. As
an outcome it printed.
If there were several instances of the listen service only one of them would've consumed the event. That's singlecast. Lymph can also broadcast to all instances of a service.
Keep in mind that if another service would've subscribed to this event as well,
one instance of it would've also consumed the event. Yet, only one instance of
each subscribed service. That's the pub-sub communication pattern. Also, we
could emit any random event and our shell client would return, e.g. lymph emit hi '{}'. Publishers don't know about subscribers or if they exist at all.
Returning to our example, when we do RPC requests we expect the greeting instances to respond in round-robin fashion while the listen instance should react to all occurring events.
» lymph request Greeting.greet '{"name": "Flynne"}'
u'Hi, Flynne!'(do this repeatedly, until both greeting instances have responded)
As you see, our expectations are met. Lymph takes care of picking one of the instances from Zookeeper. That's client-side load-balancing.
Here's a visualisation of the services' interaction. Again, ZooKeeper is synonymous with the purple clipboard, the Greeting service instances are the red speech bubbles and the Listen service instance is the green headset:
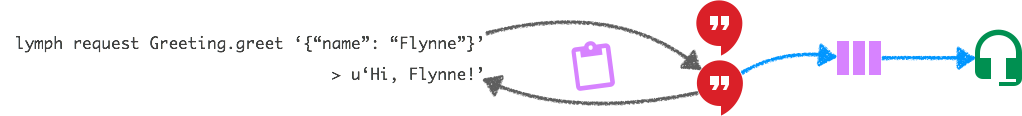
If we were to run several instances of the listen services, each event would be consumed by exactly one instance. However, lymph allows to broadcast events as mentioned above.
Finally, since it's 2015, no talk would be complete without talking about HTTP. Let's add a web service to the mix. Let's say we wanted to expose the greeting functionality via an HTTP API. Lymph has a class for that.
This
is the Web service. It subclasses lymph's WebServiceInterface. In this case
we're not exposing RPC methods, emitting not listening to events. However, we
configure a Werkzeug URL map as a class attribute. We've added one endpoint and
a handler for it: /greet. The handler receives a Werkzeug request object.
Web services are very powerful as they expose our services' capabilities to the world in the internet's language: HTTP.
from lymph.web.interfaces import WebServiceInterface
from werkzeug.routing import Map, Rule
from werkzeug.wrappers import Response
class Web(WebServiceInterface):
url_map = Map([
Rule('/greet', endpoint='greet'),
])
def greet(self, request):
"""
handles:
/greet?name=<name>
"""
name = request.args['name']
print('About to greet %s' % name)
greeting = self.proxy('Greeting').greet(name=name)
return Response(greeting)The greet handler expects a name to be present in the query string. It calls
the Greeting service via the self.proxy, returns the result in the
response and it prints.
Mind, that we're not validating the request method nor anything else.
Run it or it didn't happen, they say. We'll bring up an instance of each of services now.
Once more, the web service's configuration is no different from the ones we looked at before.
» mux start allHere's the screencast:

On the right you can see an instance of every service: web, greeting and listen. Once again, they should have registered correctly:
» lymph discover
Web [1]
Greeting [1]
Listen [1]Let's hit our web service and see how the request penetrates our service
landscape. We should see all service print something. The web service is
listening at the default port 4080. We're using httpie to exercise the
request:
» http localhost:4080/greet?name=Flynne
HTTP/1.1 200 OK
Content-Length: 8
Content-Type: text/plain; charset=utf-8
Date: Wed, 08 Jul 2015 20:51:30 GMT
X-Trace-Id: 3adc102707f745239efb2837c1877f59
Hi, Flynne!
The response looks good and all services should have performed accordingly.

Yet, when developing locally you seldomly want to run all of your services
within different shells or tmux panels. Lymph has its own development server
which wraps around any number of services with any number of instances. It's
called lymph node. We'll have to configure which services to run and how
many instances of each in .lymph.yml:
instances:
Web:
command: lymph instance --config=conf/web.yml
numprocesses: 2
Greeting:
command: lymph instance --config=conf/greeting.yml
numprocesses: 3
Listen:
command: lymph instance --config=conf/listen.yml
numprocesses: 4
sockets:
Web:
port: 4080(Since we run several instances of our web service we have to configure a shared socket for it.)
Mind, that in our case command specifies lymph instances but this could also
be any other service you need, e.g. Redis.
Let's bring them all up.
» mux start allHere's the screencast:

Once more, we find ourselves inside a tmux session with lymph node running in
the top-right pane. Below that you see lymph tail running which allows us to
follow the logs of any number of services. But first, let's check how many
instances are running:
» lymph discover
Web [2]
Greeting [3]
Listen [4]That's a good number. Once we feed a request into the cluster we should see print statements and logs appearing.
» http localhost:4080/greet?name=Flynne
HTTP/1.1 200 OK
Content-Length: 8
Content-Type: text/plain; charset=utf-8
Date: Wed, 08 Jul 2015 20:51:30 GMT
X-Trace-Id: 3adc102707f745239efb2837c1877f59
Hi, Flynne!
Within the node pane we should the see following haiku-esque sequence of print
statements:
» lymph node
About to greet Flynne
Saying hi to Flynne
Somebody greeted FlynneHere's a visualisation of what's going on within our service cluster. The
symbols should be self-explanatory:
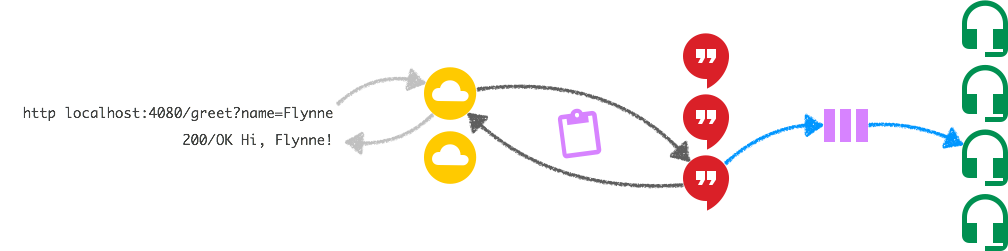
Within the tail pane though, there's a lot going on. You would find an even
bigger mess the more services and instances you run and the more intricate
your patterns of communication become. Sometimes you wonder "where did my
request go?". Lymph helps you though with trace_ids. Every request that
appears in our cluster which doesn't have a trace id assigned yet gets one.
Trace ids are forwarded with every RPC and event.
We are able to correlate all log statements in our cluster to that one HTTP
request. In fact the web service returns the trace id in the X-Trace-Id
header. If you check the logs within the tail pane you should see that all logs
can be correlated with that trace id. And indeed we see the same trace_id
across our service instances for every incoming request. Here are the logs:
[tcp://127.0.0.1:37589][a4673a399d] [INFO] 2015-07-18 11:17:34,646 [INFO] lymph.web.interfaces: GET /greet - trace_id="04dc39a5a1a44c809ec31a2dfde62f71"
[tcp://127.0.0.1:37589][a4673a399d] [INFO] 2015-07-18 11:17:34,650 [INFO] lymph.discovery.zookeeper: lookup Greeting [u'04aab0092de567633d1e07eef008f5a4', u'778473fbdbacfcad179edb4c77b663ce', u'f00b2470407f16f72bdf85f95f5dd965'] - trace_id="04dc39a5a1a44c809ec31a2dfde62f71"
[tcp://127.0.0.1:56546][f00b247040] [INFO] 2015-07-18 11:17:34,681 [INFO] lymph.core.rpc: Greeting.greet source=tcp://127.0.0.1:37589 - trace_id="04dc39a5a1a44c809ec31a2dfde62f71"
[tcp://127.0.0.1:37589][a4673a399d] [INFO] 2015-07-18 11:17:34,713 [INFO] lymph.web.wsgi_server: client=127.0.0.1 - - "GET /greet?name=Flynne HTTP/1.1" status=200 length=174 duration=0.066961 (seconds) - trace_id="04dc39a5a1a44c809ec31a2dfde62f71"
[tcp://127.0.0.1:56546][f00b247040] [INFO] 2015-07-18 11:17:34,728 [INFO] lymph.core.rpc: subject=Greeting.greet duration=0.044457 (seconds) - trace_id="04dc39a5a1a44c809ec31a2dfde62f71"
We've covered most of the available tooling. You should have a pretty good idea how to interact with your services now.
There's one command we haven't tried yet. That's lymph subscribe. It is being
left to the reader as an exercise.
Let's talk about features which go beyond CLI tooling. Testing services is
crucial for development. Have a look at our services
tests to
get an idea of lymph testing utilities. The tests showcase how you would tests
these three varieties of services. You can run the tests with:
PYTHONPATH=services nosetests --with-lymphEarlier, we have mentioned that ease of configuration was a concern for lymph.
There's an API to deal configuration files. Its thin abstraction over the
actual YAML files but gives you the freedom to instantiate classes right from
the config. This gives you the freedom to configure services with a minimal
amount of code. Custom configuration can be processed by overriding lymph
interface's apply_config(self, config) hook.
Let's say your Service is supposed have a cache_client. This client should
be fully configurable and the ramifications of instantiating should not be the
service's concern. We could configure our service to run with a Redis like so:
(for this we assume that both redis and memcache are set in your
/etc/hosts to point to the respective IPs. That'd be 127.0.0.1 in most
cases. But redis and memcache read nicer :)
# conf/service_redis.yaml
interfaces:
Service:
class: service:Service
cache_client:
class: redis.client:StrictRedis
host: redis
port: 6379
db: 1As you can see the config contains all information we need to instantiate the
Redis client's class. Let's make use of the config API then and configure
our service in the apply_config(self, config) hook:
# service/service.py
import lymph
class Service(lymph.Interface):
def apply_config(self, config):
super(Service, self).apply_config(config)
self.cache_client = config.get_instance('cache_client')As you see it takes only one line to configure the service. Running it is a matter of pointing to the desired config file:
» lymph instance --config=conf/service_redis.ymlWe could have other instances running on top of Memcache though. Like so:
interfaces:
Service:
class: service:Service
cache_client:
class: pymemcache.client:Client
server:
- memcache
- 11211Again, you run it by pointing it to the desired config file:
» lymph instance --config=conf/service_memcache.ymlYou can also share instance of such classes over instances of your services. All service instances share the same ZooKeeper client instance by default. Or you read from environment variables.
You may want to set the stage when bringing up your service. Performing
clean-up tasks when shutting down is just as likely. Therefore you may override
the on_start(self) and on_stop(self) hooks. For the Service from the
previous section we could do:
def on_start(self):
super(Service, self).on_start()
print('started with client: %s' % self.cache_client)
def on_stop(self):
print('stopping...')
super(Service, self).on_stop()Classic RPC calls block until the response is received. A deferred RPC call mechanism is implemented in case you wish to consume the RPC response later, or simply ignore it. Lymph's RPC implementation allows to defer calls:
proxy('Greeting').greet.defer(name=u'John') # non-blockingStandard process metrics are being collected out of the box and exposed via an internal API. It is possible to collect and expose custom metrics.
Lymph has a plugin system which allows you to register code for certain hooks,
e.g. on_error, on_http_request, on_interface_installation etc. A New
Relic
and a
Sentry
plugin are shipped as built-ins. You can also register your own hooks.
Lastly, CLIs are pluggable as well. Have a look at lymph top as an example.
How does lymph do things under the hood? It isn't black magic. This section actually turned out to be much shorter than expected.
Lymph depends on Zookeeper for service registry. Zookeeper is a distributed key-value store. Once a service instance is being started it registers itself with ZooKeeper providing its address and name. Once it's being stopped it unregisters itself. When you send a request to another service, lymph gets all instances' addresses and routes the request. That means, lymph does client-side load balancing. Request round-robin over the instances of a service. The request itself is being serialized with MessagePack and send over the wire using ZeroMQ.
Lymph's pub-sub event system is powered by RabbitMQ. That means any valid topic exchange routing key is valid lymph event type. Lymph also allows to broadcast and delay events.
Every service instance is a single Python process which handles requests and events via of greenlets. Lymph uses gevent for this.
Lymph uses Werkzeug to handle everything WSGI and HTTP.
Right now it seems as if both Nameko and lymph are the only Python service frameworks that exist. This is true for the level of integration and self-contained tooling at least. Obviously, they are different frameworks by different authors having been implemented independently. Nonetheless, they do share some striking characteristics. To us, these similarities validate our assumptions. It is worth mentioning that Nameko doesn't do service registry explicitly though. Nameko achieves this by using RabbitMQ for both events and RPC. It'd be tedious to compare them both in detail but it is highly recommended to have a look at Nameko as well.
Most other similar technologies aren't either Python-specific or provide specific solutions for RPC for instance like ZeroRPC.
Things that are worth mentioning though are cocaine, spread, circuits, ...
We intend to grow the little ecosystem around lymph. While lymph will stay the core framework, we're already in the process of developing complementary libraries for writing special-purpose services, e.g. for storage and business process. Naturally, we'll open-source them once they have matured well enough.
Lastly, we'd like to mention distconfig which is a Python library for managing shared state, i.e. configuration, feature switches etc. Distconfig is intended to complement lymph.
Thank you very much for your attention! We're done. We hope you enjoyed this
little introduction. If you feel that the ice is broken we'd consider ourselves
successful. If you should have questions feel free to reach out in our IRC
channel #lymph on freenode.net. Naturally, we'd appreciate PRs and issues
on GitHub.
If you should spot any unclarity or errata within this article, you're very welcome to point them out at github.com/mamachanko/import-lymph](http://github.com/mamachanko/import-lymph).