Release 0.8.3 | Everything Everywhere All at Once Release
User login, management, authentication, roles, and permissions
User login and user level permission control is supported in mage-ai version 0.8.0 and above.
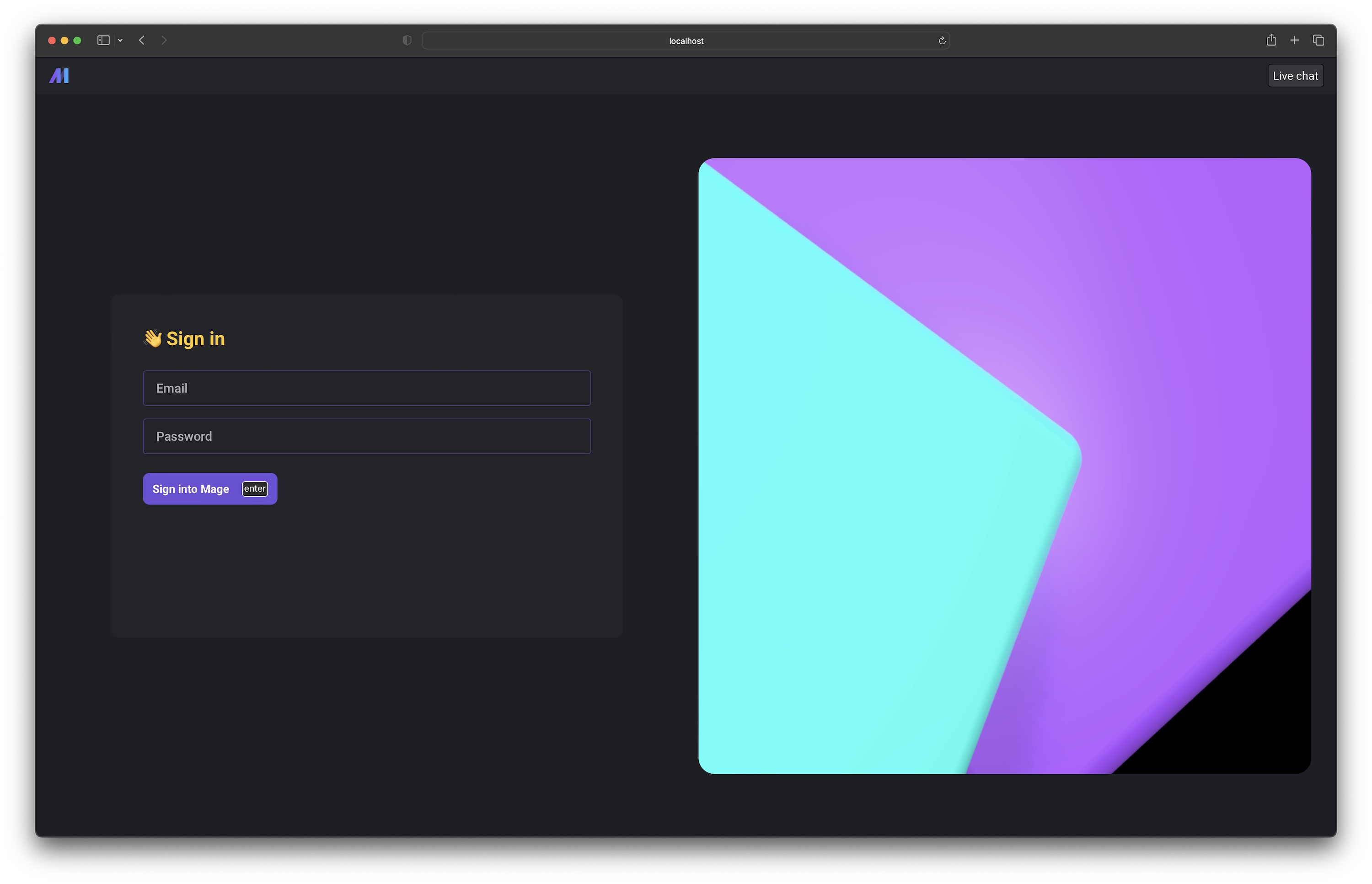
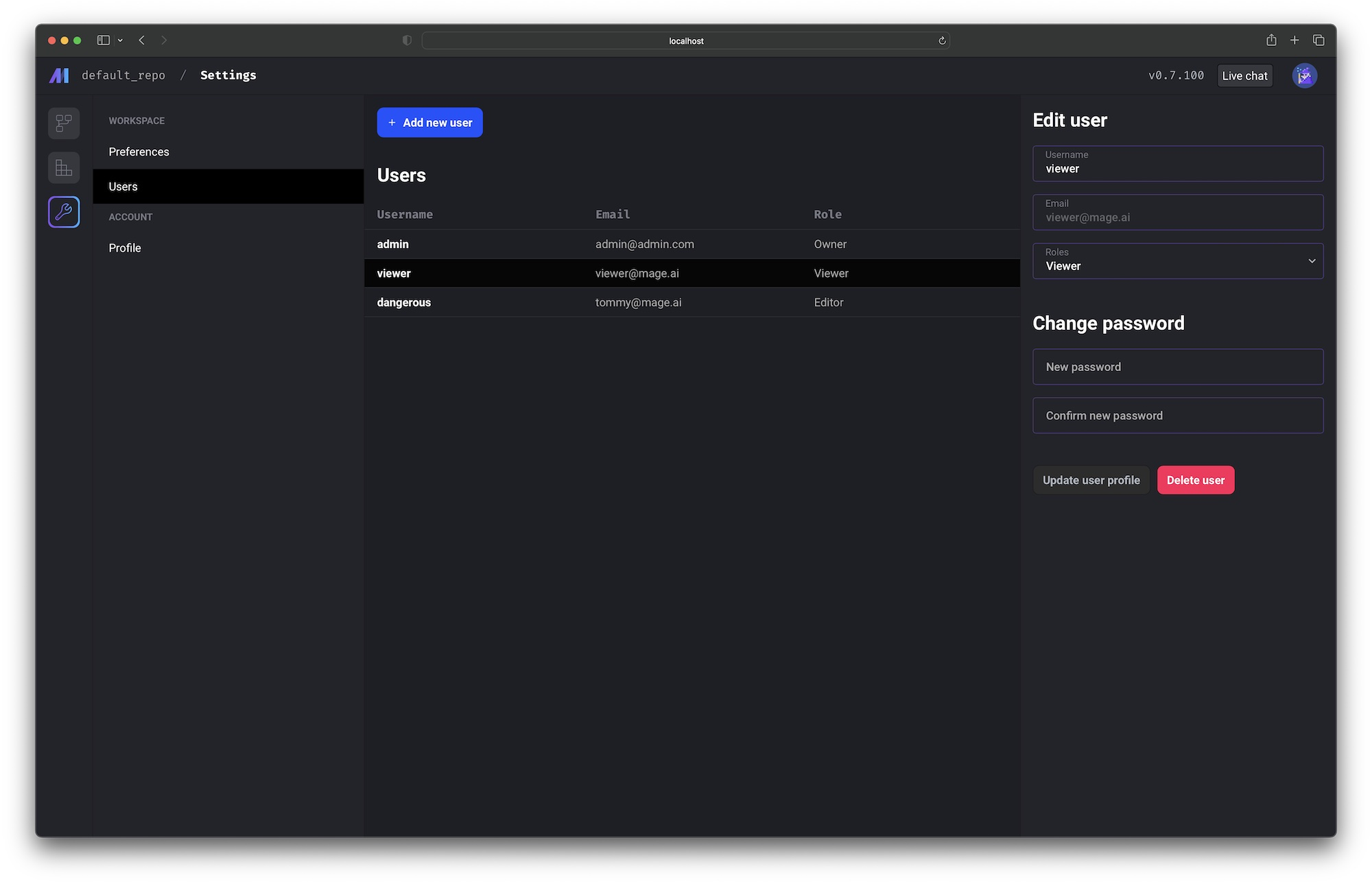
Setting the environment variable REQUIRE_USER_AUTHENTICATION to 1 to turn on user authentication.
Check out the doc to learn more about user authentication and permission control: https://docs.mage.ai/production/authentication/overview
Data integration
New sources
New destinations
Full lists of available sources and destinations can be found here:
- Sources: https://docs.mage.ai/data-integrations/overview#available-sources
- Destinations: https://docs.mage.ai/data-integrations/overview#available-destinations
Improvements on existing sources and destinations
- Update Couchbase source to support more unstructured data.
- Make all columns optional in the data integration source schema table settings UI; don’t force the checkbox to be checked and disabled.
- Batch fetch records in Facebook Ads streams to reduce number of requests.
Add connection credential secrets through the UI and store encrypted in Mage’s database
In various surfaces in Mage, you may be asked to input config for certain integrations such as cloud databases or services. In these cases, you may need to input a password or an api key, but you don’t want it to be shown in plain text. To get around this issue, we created a way to store your secrets in the Mage database.
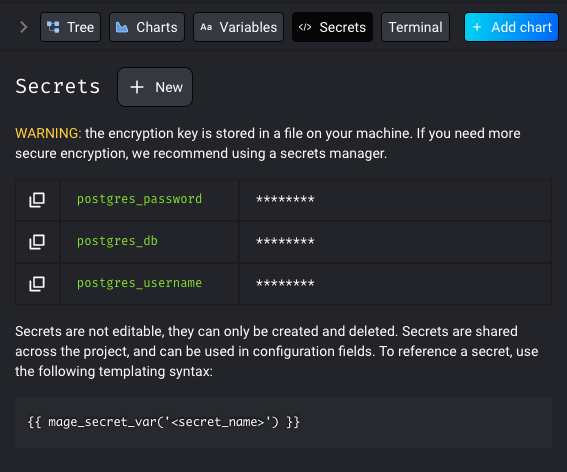
Check out the doc to learn more about secrets management in Mage: https://docs.mage.ai/development/secrets/secrets
Configure max number of concurrent block runs
Mage now supports limiting the number of concurrent block runs by customizing queue config, which helps avoid mage server being overloaded by too many block runs. User can configure the maximum number of concurrent block runs in project’s metadata.yaml via queue_config.
queue_config:
concurrency: 100Add triggers list page and terminal tab
- Add a dedicated page to show all triggers.
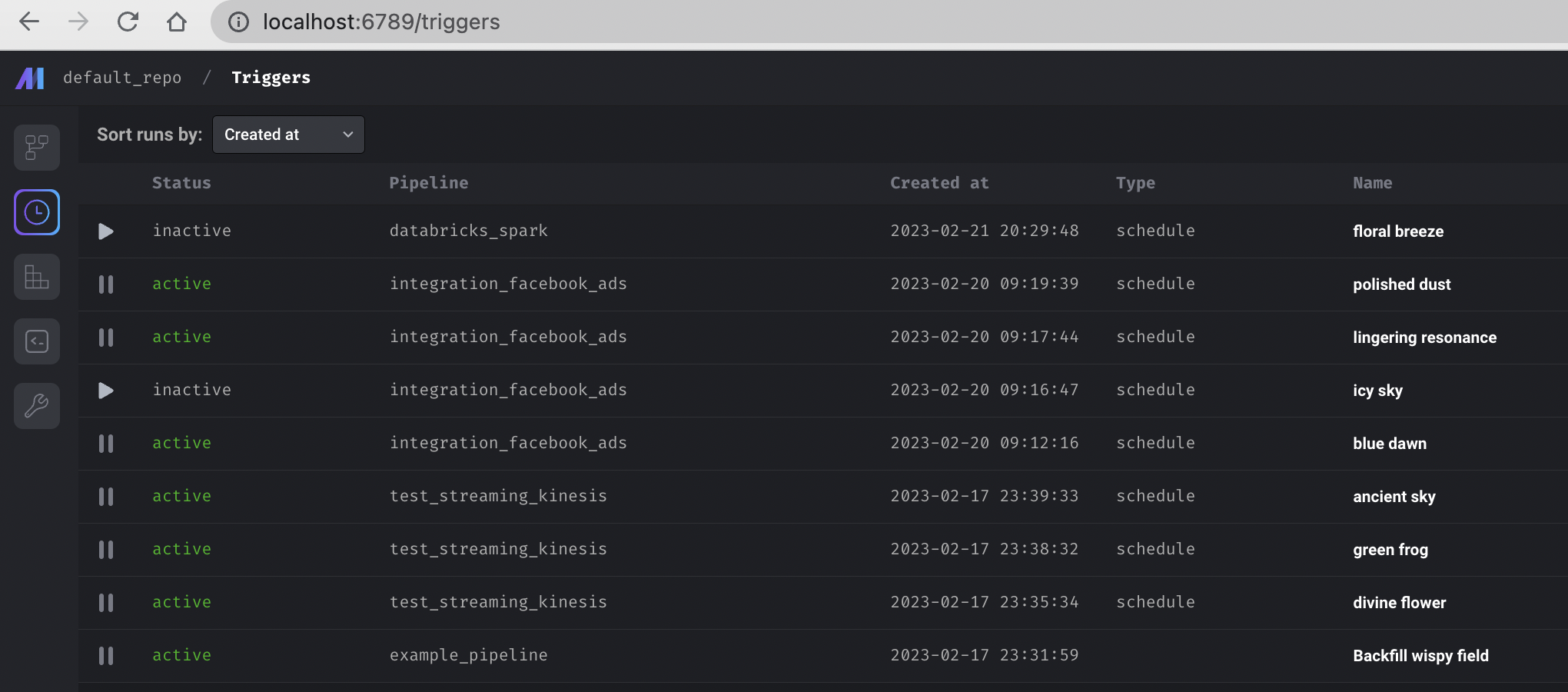
- Add a link to the terminal in the main dashboard left vertical navigation and show the terminal in the main view of the dashboard.
Support running PySpark pipeline locally
Support running PySpark pipelines locally without custom code and settings.
If you have your Spark cluster running locally, you can just build your standard batch pipeline with PySpark code same as other Python pipelines. Mage handles data passing between blocks automatically for Spark DataFrames. You can use kwargs['spark'] in Mage blocks to access the Spark session.
Other bug fixes & polish
- Add MySQL data exporter template
- Add MySQL data loader template
- Upgrade Pandas version to 1.5.3
- Improve K8s executor
- Pass environment variables to k8s job pods
- Use the same image from main mage server in k8s job pods
- Store and return sample block output for large json object
- Support SASL authentication with Confluent Cloud Kafka in streaming pipeline
View full Changelog