This repository contains the code for the Lux AI Season 1 competition, hosted on Kaggle. The full write-up can be found on Kaggle's forums and is copied below.
Before beginning, we would like to thank the Lux AI and Kaggle teams for putting together a wonderful competition. Everyone was responsive, receptive to feedback, open about the development process, and, perhaps most importantly, the game was incredibly deep and fun to watch and strategize about. This is an impressive feat for Lux AI’s first competition, and we look forward to future seasons already! Furthermore, the Kaggle community contributed to excellent discussions of strategies, techniques, tutorials, and ranking algorithms on the forums and discord alike, and for that we are so grateful – we always learn so much from these competitions!
We initially took a multi-part approach to designing our agents: Liam worked on a rules-based agent, I, Isaiah, tackled reinforcement learning (RL), and Rob worked on meta-analyses of our games and top agent games to find weak spots and generally improve our understanding of the game and what was important in it. Our initial assumption, motivated by the top results in last year’s Halite competition, was that the rules-based approach would be more successful and would be where most of our efforts would lie. However, to our surprise, within the first month the RL approach began to beat the rules-based one, and seemed to be improving monotonically without any signs of plateauing, so the rules-based agent was abandoned from the August sprint onwards.
For those just looking for a high-level overview of what I did, I will present that information in the first part of this write-up. In the following sections, I’ll go over things more deeply and include the technical details about the pieces that I felt to be the most innovative and important. For those looking for the code, it is all open source and can be found on GitHub: https://github.com/IsaiahPressman/Kaggle_Lux_AI_2021, alongside our submissions over time.
Lux AI is a game where two players issue commands for their respective teams composed of workers, carts, and city tiles on a square grid, ranging in size from 12x12 to 32x32. The goal is to take control of and mine the available resources in order to build more cities which can, in turn, research new resources and build new workers and carts. Every 30 turns, there are 10 turns of night time during which units and cities must consume the resources they’ve amassed in order to burn fuel to survive, as anything which does not have enough fuel will disappear into the night. After 360 turns, the player who has the most surviving city tiles wins the game.
In reinforcement learning, an agent interacts with an environment repeatedly by taking actions at each turn and receiving rewards and new observations, and in so doing tries to learn the best sequence of actions given observations to maximize the expected sum of rewards. After many games of experience, the agent will hopefully learn which actions are good and lead to a positive reward, and which ones are bad and lead to a negative one. For this 2-player game, a reward was given at the final timestep of -1 for losing and +1 for winning the game, with a reward of 0 at all other times. A deep convolutional neural network parameterized an action policy (in other words, the strategy), which was trained using backpropagation to maximize the probability (specifically, the log-likelihood) of winning the game over losing it (since the game result was the only source of non-zero reward), and in the process of playing against itself many many times, learned to take good actions over bad ones at each step.
One important challenge for applying RL to this game is that there are a variable number of workers, carts, and cities on the board. One way to handle this problem would be to have a network control each unit separately, but I felt this would be inadequate as it would be challenging for the separate units to learn to work together in a harmonious fashion, and it is not so clear how to assign reward to the independent units to help them do so. I opted instead to have a single network which issued commands for each worker, cart, and city tile on all squares of the board simultaneously. I then used only the actions from the squares with units and cities that needed orders, thereby allowing the network to learn to coordinate an entire arbitrarily-sized fleet given only one reward signal.
Through this procedure, and starting from a random initialization, the neural network convincingly and consistently made improvements to its gameplay, learning novel strategic and tactical behavior independently and without human intervention. This process continued over the course of the competition with training overnight most nights, and the agent improved near-continuously, only plateauing somewhat in the final few weeks. At first, the agent learned to simply harvest wood and build cities near the forests. Next, it learned the importance of denying the opponent access to resources, and used a scorched earth strategy to consume all the available resources without heed for its own survival - a strategy which was enough to win the August sprint prize. However, after the rules change, (where wood regrowth was added and fuel costs were reduced to weaken swarming scorched earth strategies) it began playing more conservatively and protecting the renewable forests to maximize the resources available to it over the course of the game. Finally, by the end of the competition, the agent has become a formidable player, ruthlessly surrounding and defending the available resources – especially the valuable forests, infiltrating and stealing the opponent’s resources when given the opportunity, and waiting until the final day-night cycles to build large cities right before the game’s end. It has been very cool to watch the agent develop complex behaviours that we'd struggle to imagine implementing in a rules-based agent, especially its keen long-term strategic sense, ability to exploit small advantages, and fluid cooperation between units. Even after months of seeing it learn and play, it is still difficult to describe my sense of wonder that the agent has learned to do so much from so little signal. Such is the magic of RL.
Below is a visualisation of episode #33947998, which shows a few common patterns in the agent’s strategy. Our agent is the blue player, versus RLIAYN as red. Full credit to Liam for creating these excellent visualisations. (If the GIFs don't load, try the MP4 links)
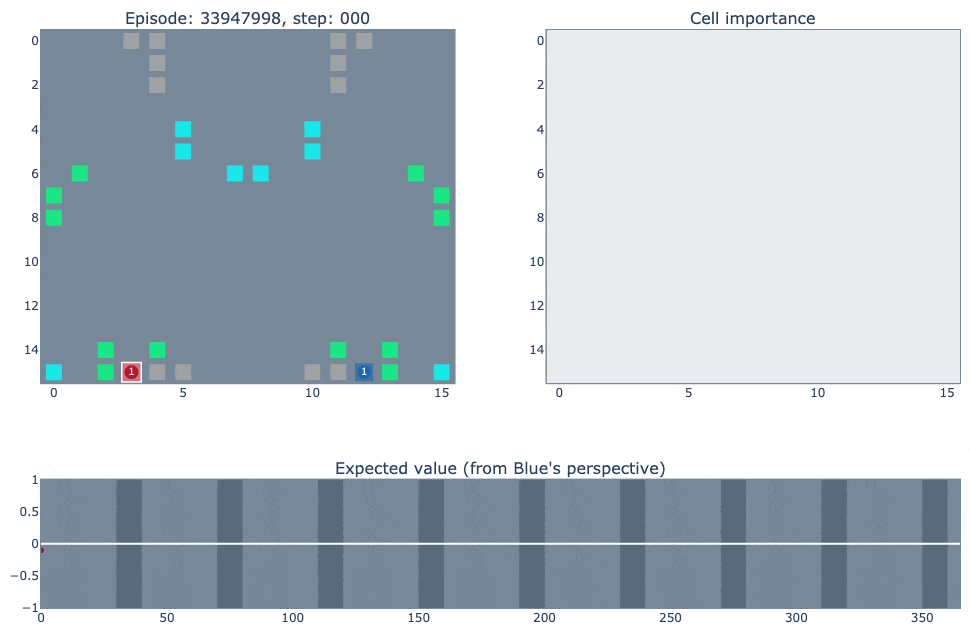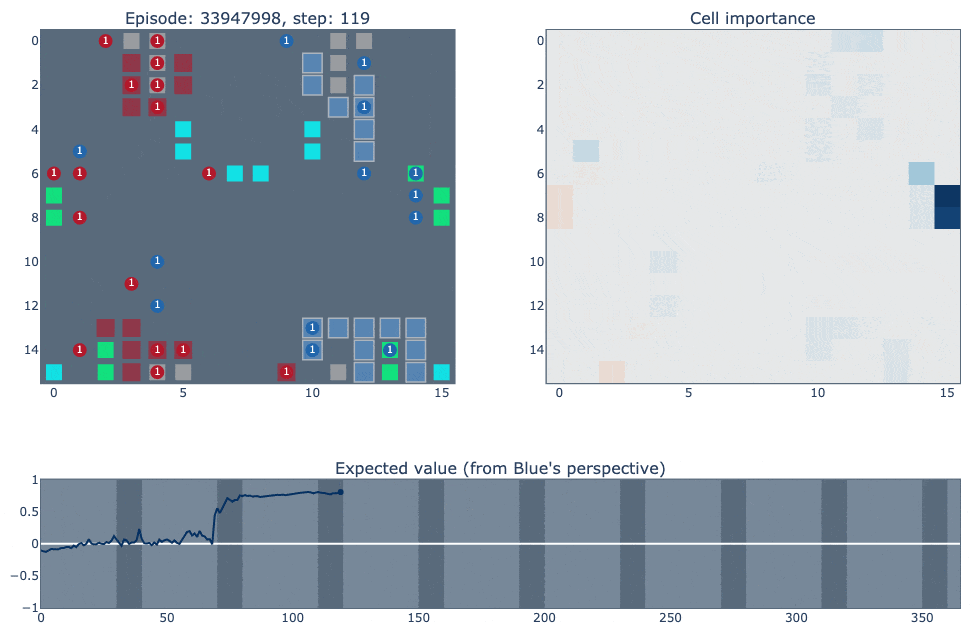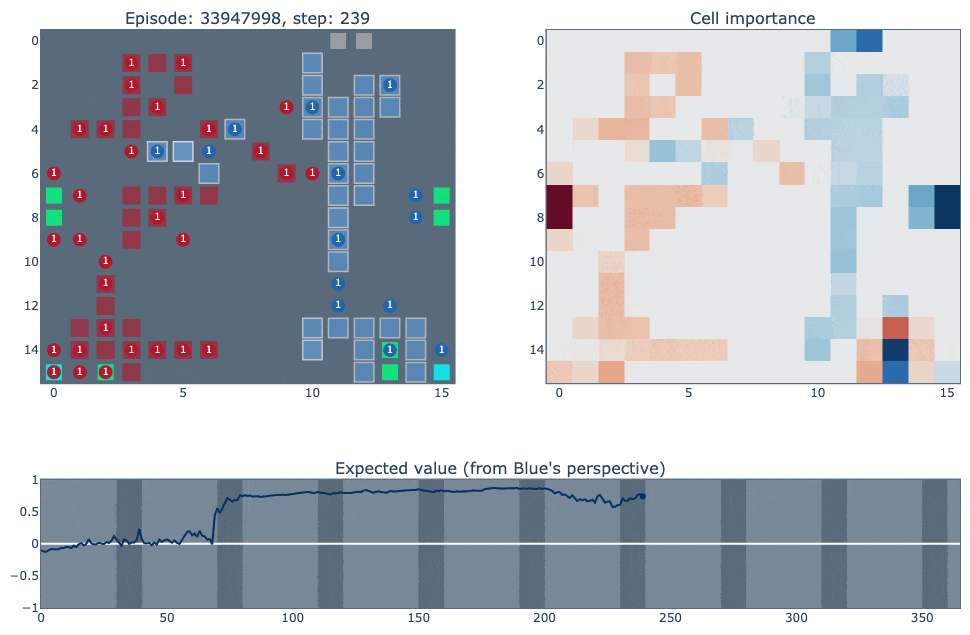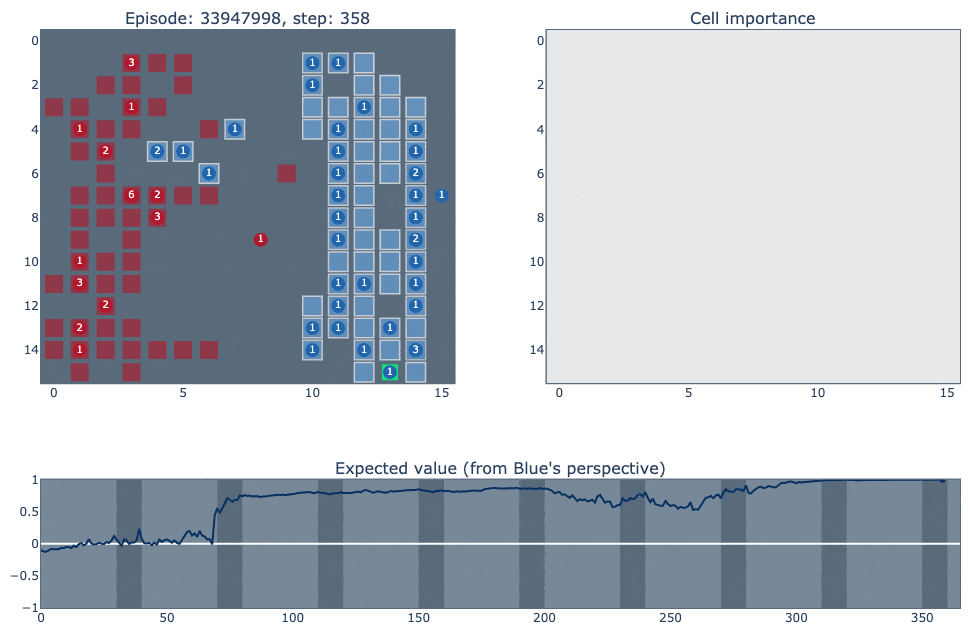
Link to MP4 (for better video control)
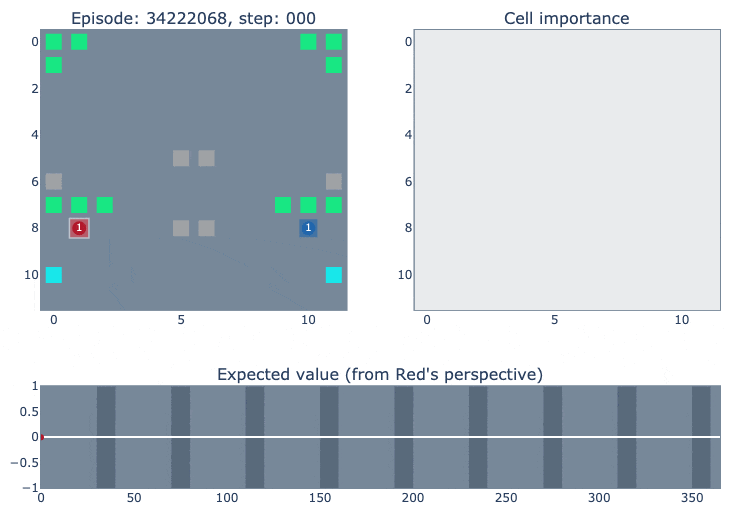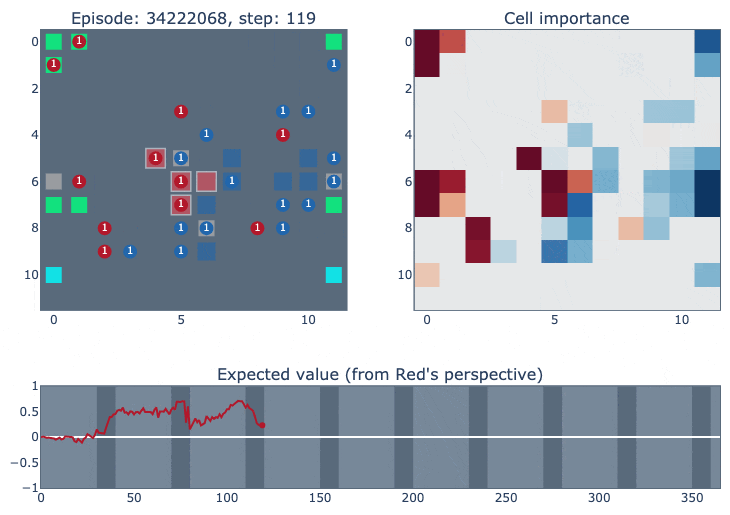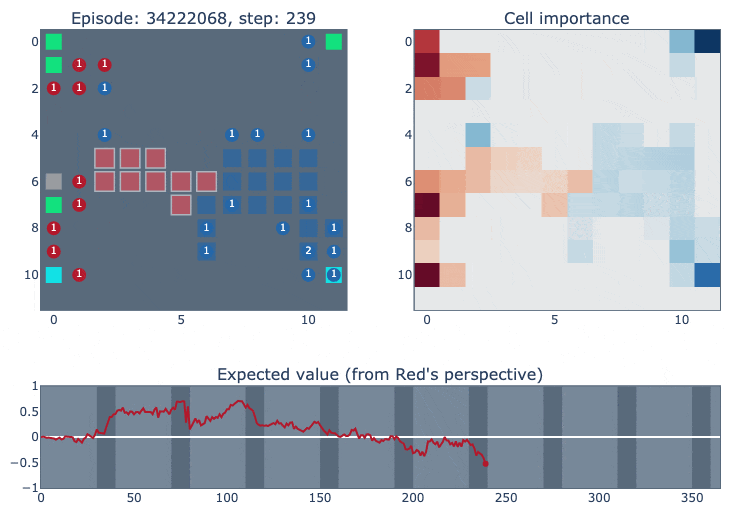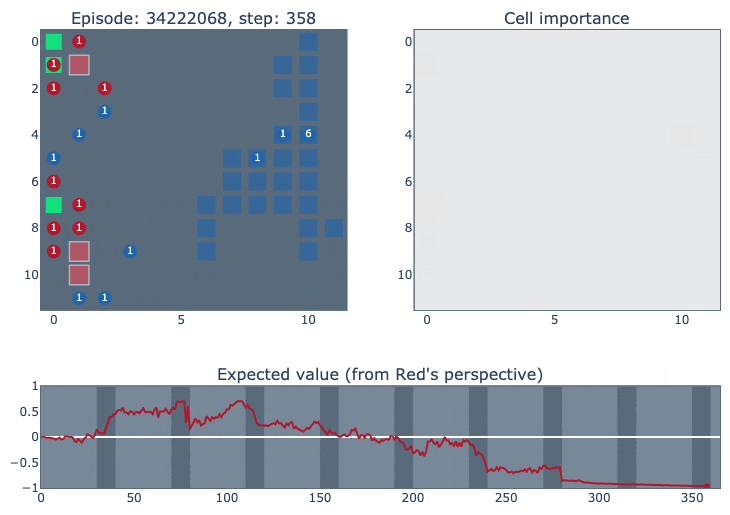
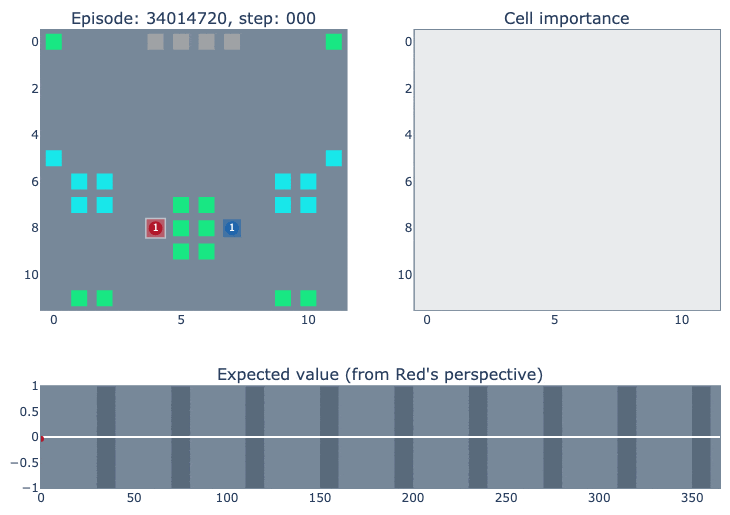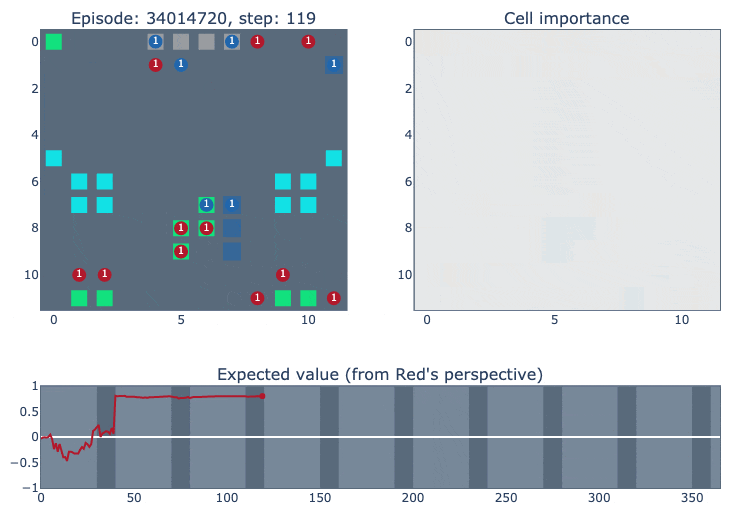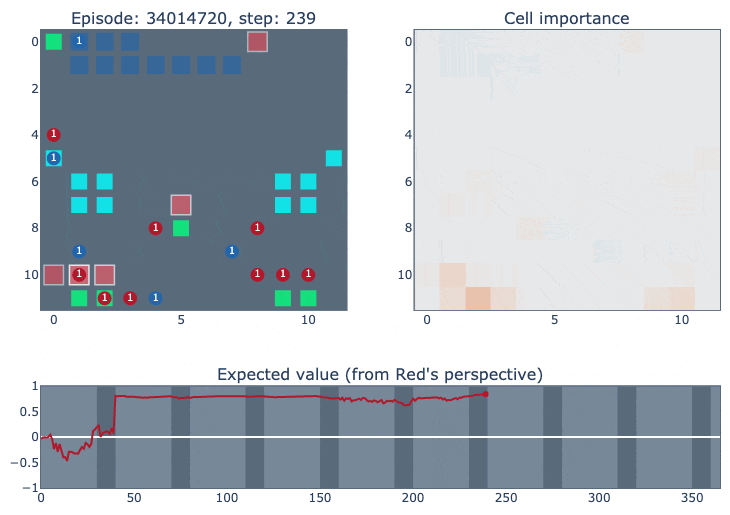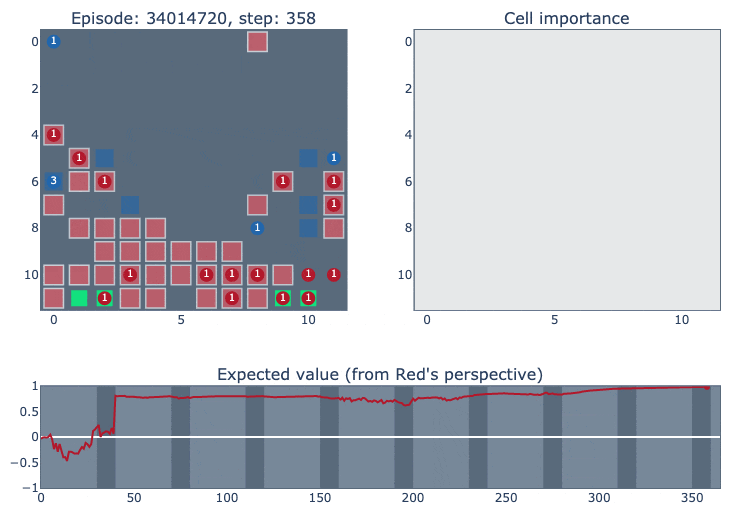
The top left of the visualisation shows a simplified version of the game state. Cities controlled by our agent (blue in this case) are highlighted according to the probability of the ‘build worker’ action: lighter means the probability is closer to one. The top right figure shows how important each cell is for the value function of each player. It was constructed by deleting the contents of each cell (resource/unit/city) and observing how much that changed the network output. The bottom figure plots the agent’s value function over time, ranging between one and minus one for an expected win or loss.
A few different observations from this match:
-
The agent invades the opponent’s area and blocks counter-attacks, and begins building an efficient long-term city structure from the mid game.
-
Between steps 200-300, the agent is aware that the blue cities surrounding the forest in the bottom right are actually harmful because they make it difficult to move wood away from the forest for city building.
-
The agent has very good forest management, keeping trees close to max capacity while skimming off wood for city building (the cell importances consistently show the two forest tiles on the map edges to be the most critical).
-
Apart from the forest tiles, the agent also places a large value on workers and cities deep in the opponent’s territory.
-
The sharp increase in the value function on step 69 appears to be due to the blue agent researching coal, although the control of coal (or uranium) doesn’t seem to be a deciding factor in the match.
The next match below (episode #34222068) is a loss which shows some of the weaknesses of the agent (we play red in this match, RLIAYN is blue).
-
The agent thinks it is winning initially, and it does seem to have some space advantages in the center of the board.
-
However, it has trouble budgeting enough fuel to keep its cities alive, and doesn’t effectively block blue from invading its side of the board.
-
From step 200 onwards, it feels like the agent gives up, with most workers standing around and not taking even basic productive actions (it’s possible that keeping some light reward shaping or training against a league of more diverse opponents could help the agent to be more resilient in situations like this).
The final match below (episode #34014720) is a clear demonstration of the agent’s focus on positional advantage (our agent is red, RLIAYN is blue). The GIF just shows the first 100 steps of the match.
-
The cell importance shows that, in the very early game, blue was expected to control the entire upper half of the map. But, when a row of blue’s cities disappeared during the first night, this allowed our agent to compete for this area (I think blue’s cities served two purposes: partly to directly block red’s units, and also to enable worker production to do more blocking).
-
Throughout the rest of the match, the agent remains very confident about victory even when it is far behind in city count.
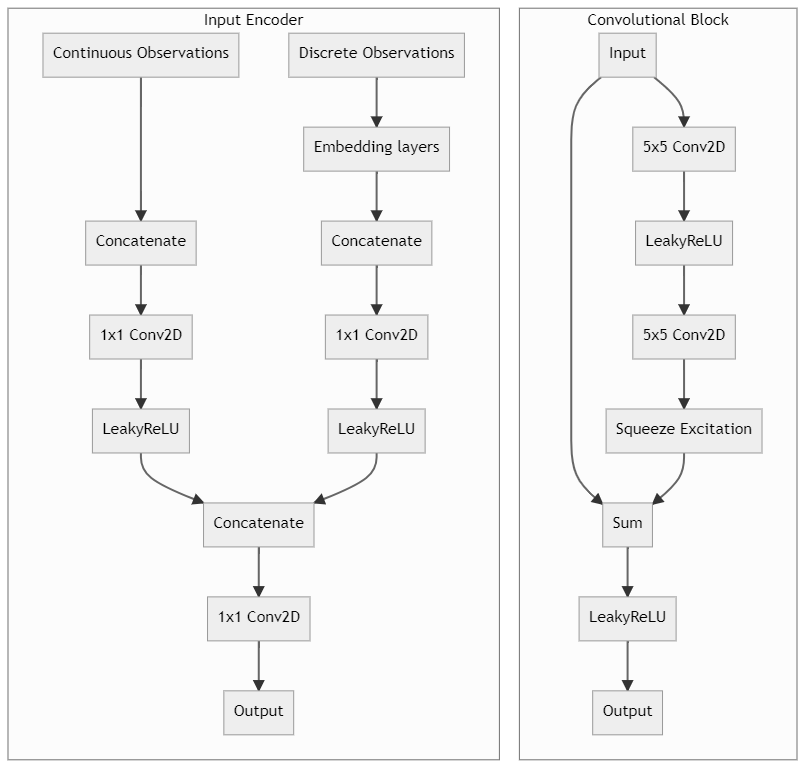
In order to handle the varying board sizes, I padded all boards with 0s to be of size 32x32, and masked the outputs after every convolutional layer to ensure that information did not leak from layer to layer along the manually padded edges. Additionally, for some global information, such as research points, I broadcasted the values to all cells of the board before processing. When encoding the board for the neural network, I used learnable 32-dimensional embedding layers to encode each of the discrete observation channels separately, followed by a concatenation, 1x1 convolutional layer to project to 128x32x32, and LeakyReLU activation. 32-dimensional embeddings were excessive for some of the features, since many had only 2 or 3 options, and were I to do things over, I would reduce the dimensionality of the embeddings for many of the discrete features. For the continuous observations, I first applied per-feature normalization, followed by a concatenation, 1x1 convolutional layer to project to 128x32x32, and LeakyReLU activation. Finally, the projected continuous and discrete embeddings were concatenated once again, followed by a final 1x1 convolution before passing the 128x32x32 tensor to the main residual network. The full list of features can be found in the code, but I’ll go over a few here:
-
Worker: A 3-dimensional discrete variable, indicating either the absence of a worker, the presence of an allied worker, or the presence of an opposing worker. (With similar features for carts and city tiles)
-
Worker cooldown: A continuous variable, indicating the remaining cooldown for the worker on that square.
-
Worker cargo wood: A continuous variable, indicating the amount of wood in the worker’s cargo on that square. There are separate features for coal and uranium cargo.
-
Worker cargo full: A 2-dimensional discrete variable which is True if a worker with a full cargo is present, and False otherwise. This allowed the network to more easily detect when a worker could stop mining.
-
City tile fuel: A continuous variable, indicating this city tile’s share of the fuel available to the city, calculated by taking the amount of fuel in the whole city divided by the number of tiles in that city. City tile cost was treated similarly.
-
Wood: A continuous variable, indicating the amount of wood on the tile. (With similar features for other resources)
-
Distance from center X: A continuous variable, indicating the distance from the center of the board along the X axis. This should allow a given worker to better orient itself on the varying board sizes.
-
Research points: A continuous variable with one channel for each team, indicating the number of research points that each team has.
-
Researched coal: A 2-dimensional discrete variable with one channel for each team, which is True if a team has researched coal and False otherwise.
-
Day night cycle: 40-dimensional discrete variable, indicating the current turn number mod 40. This allowed the network to explicitly encode every timestep within the day-night cycle using a different embedding, something which may be particularly important when a worker is trying to mine as much as possible, but needs to return to the city just before nighttime.
-
Game phase: 9-dimensional discrete variable, indicating the turn number divided by 40 and rounded down. This allowed the network to more easily condition it’s strategy on the different phases of the game. Once I added this, the network quickly developed dramatically different behaviors during the beginning, middle, and end game, and I think this feature was a crucial part of its success.
-
Board size: 4-dimensional discrete variable, indicating the board size - either 12x12, 16x16, 24x24, or 32x32. This helped the network to condition its strategy on the current board size.
The neural network body consisted of a fully convolutional ResNet architecture with squeeze-excitation layers. All residual network blocks used 128-channel 5x5 convolutions, and notably did not include any type of normalization. The network had four outputs consisting of three actor outputs - a 32x32xN-actions tensor for workers, carts and city tiles - and a critic output, which outputted a single value in [-1, 1]. The final network consisted of 24 residual blocks, plus the input encoder and output layers, for a grand total of ~20 million parameters.
For reinforcement learning, I used FAIR’s implementation of the IMPALA algorithm, with additional UPGO and TD-lambda loss terms. I also had a frozen teacher model perform inference on all states, and added a KL loss term for the current model’s policy from that of the teacher. This helped to stabilize behavior and prevent strategic cycles – both of which are problems that plague a pure self-play setup. Policy losses were computed by summing over the log probabilities of the selected actions for all units that acted in a given timestep, effectively computing the log of the joint probability of all the selected actions.
In order to speed up training and aid the agent in developing rudimentary behaviors despite the sparse win/loss reward signal, I performed reward shaping for the first 20 million steps, by awarding/penalizing points for building/losing cities and units, researching, and fueling cities, alongside winning/losing the game. After training a smaller 8-block network with the shaped reward, I then trained a 16-block and eventually 24-block on the sparse reward, with the smaller previous networks as teachers each time. All training was done on my personal PC - an 8-core/16-thread dual-GPU system.
The full action space was available to the agent with one exception: transfers. In order to discretize the action space, I decided to only allow a unit to transfer all of a given resource at once. This meant that workers had 19 available actions (no-op, 4 moves, 4 transfers for each of 3 resources, build city, pillage), carts had 17 (same as workers minus build city and pillage), and city tiles had 4 (no-op, research, build worker, build cart). Additionally, the agent was only allowed to take viable actions, with illegal actions masked by setting the logits to negative infinity. This did not reduce the available action space – the agent could always elect to take the no-op action – but did reduce the complexity of the learning task.
For overlapping units of the same type, I sampled the actions without replacement until a no-op, at which point all remaining units took the no-op action. This prevented multiple units from trying to exit a city to the same square, while not interfering with the agent’s ability to keep units inside at night. In order to compute the log-probabilities for stacked units, I computed the probability that the sampled actions until the no-op had occurred in that order.
I made a few modifications to improve test-time performance. I performed a single data augmentation by rotating the observation 180 degrees, getting the action probabilities for both the actual and rotated state, and then taking the average. I would have performed additional data augmentation, but there was not enough time as the model took 2-2.5 seconds for inference on the Kaggle servers with a batch size of 2. I did not sample actions randomly at test-time, but instead always selected the most likely action.
In addition to data augmentation, I added a few handwritten rules to aid the agent’s test-time behavior. City tiles selected build and research actions in order of the probability that the model gave to take the selected action with the selected city tile. Once there were enough build or research actions queued to reach the unit or research cap respectively, the rest of the city tiles had to select a different action. Similarly, units moved in order of the probability that the model gave to taking their selected actions. Once a unit’s move action had been queued for a given square, other units were forbidden from moving to (or staying in) the target square unless it was a city tile. Further, I added a rule to some agents that after the first night, city tiles were forbidden to take the no-op action until research was complete. This rule helped stabilize behavior against weaker agents and climb the leaderboard faster, but did not seem to have much of an effect on the agent’s final performance against other top agents. For the last few agents that we submitted, we added a tie-break assistance rule that all cities must build a cart on the final turn of the game. This rule is almost always irrelevant, but it’s amusing to see in action regardless.
This has been an amazing competition, and we are so grateful to the organizers and competitors alike for making it all happen. We are looking forward to reading many more write-ups over the coming weeks, and learning a ton as always. Good luck to all and we hope to see you in season 2!