scrapy-admin 是一个针对scrapy的后台管理系统,使用django框架编写,具有定时调度、周期调度和状态监控等功能。
python 3.4+
APScheduler 3.3+
Django 1.09+
pymongo 3.5+
requests 2.13+
这是一个django app,详细的安装部署方法可参考django文档,大致步骤如下:
- 新建一个django项目,并启用admin模块
- 将scrapy_admin拷贝到项目目录下
- 修改settings.py文件,在INSTALLED_APPS中添加scrapy_admin
- 修改urls文件,在urlpatterns中添加:url(r'^scrapyadmin/', include("scrapy_admin.urls"))
- 要使用状态监控和数据统计功能,需要在scrapy项目中添加MongoStateStore扩展
- 初始化数据库,启动django项目,登录管理后台
请确保scrapy已经正确部署到了scrapyd。若要使用状态监控和数据统计功能,请确保 scrapy已经添加了MongoStateStore扩展、正确设置了Mongodb数据库并在scrapy_admin/settings.py文件中填写了数据库信息。
该扩展的作用是每隔一段时间,将爬虫的状态保存到Mongodb数据库中。要启用该扩展,除了在extendtions中添加该扩展外,还需要在scrapy settings文件中设置以下几个字段:
- MONGODB_URI:Mongodb的uri地址
- MONGODB_DATABASE:Mongo数据库名称
- MONGO_STATES_COLLECTION:保存状态数据的集合的名称
- MONGO_STATES_INTERVAL:保存状态的时间间隔,以秒为单位,整数值
用于定义一个APSchulder中的cron对象,不同于一般的cron表达式,APSchulder中的cron对象对缺省值具有自动推断功能,具体参见:apscheduler.triggers.cron
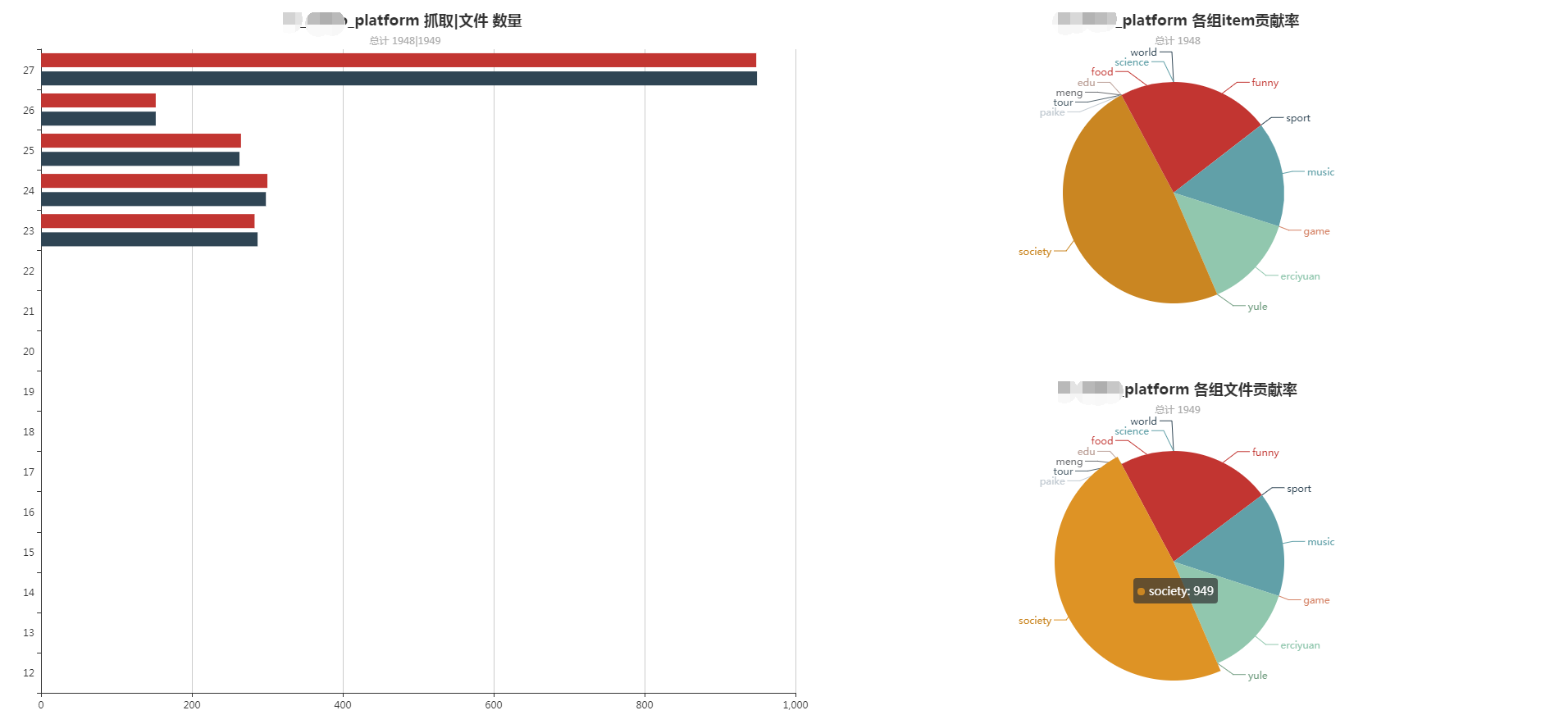
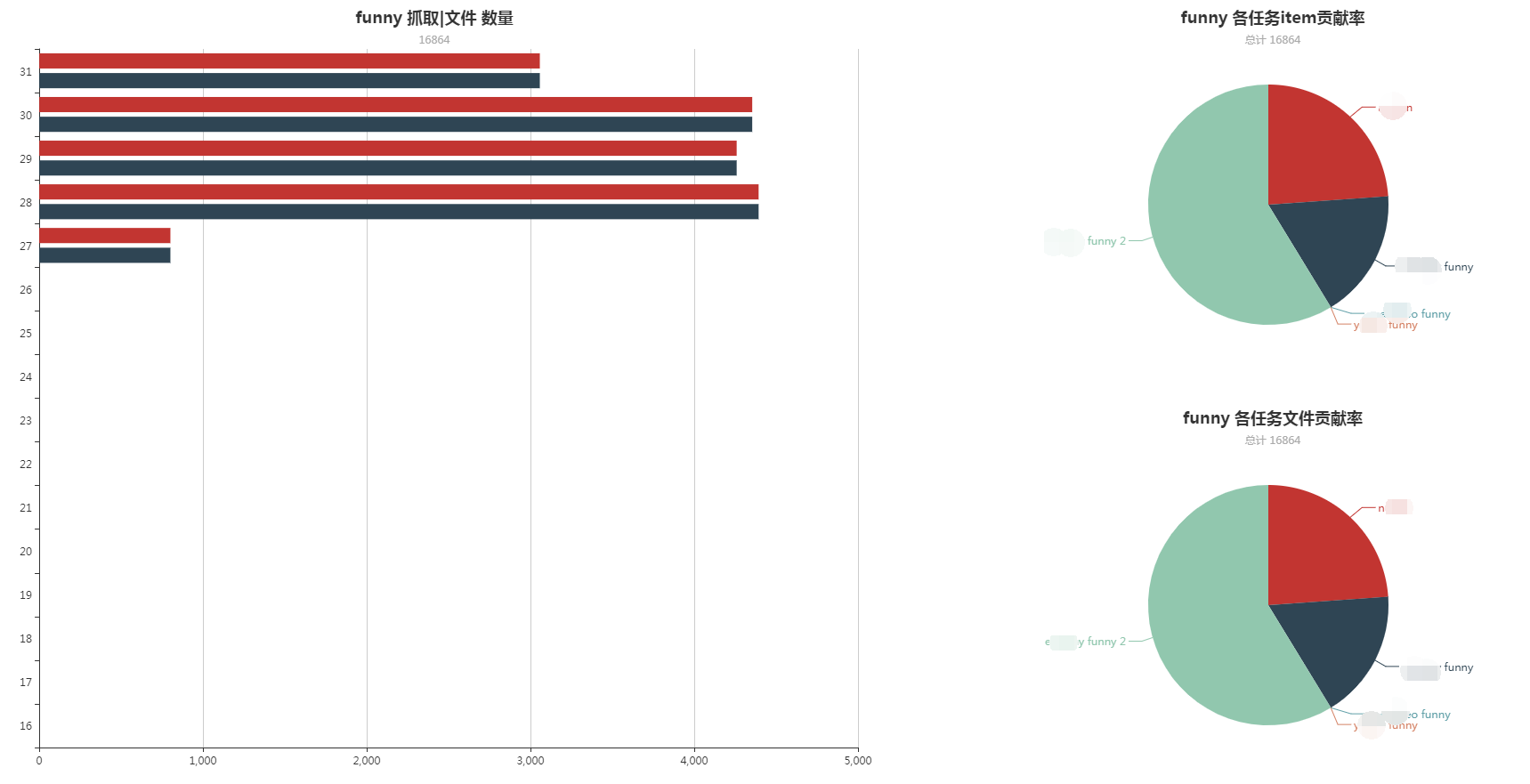
用于对任务进行分组,并对该组抓取的数据进行统计。
爬虫的一个运行实例,对应scrapyd中的job概念。job由task自动创建,不可以手动创建,但可以手动停止一个正在运行的job。job的运行状态通过查询scrapyd获得,采用了异步查询方式,因此会存在一定的延迟。
爬虫项目,对应scrapyd中的Project概念。
爬虫
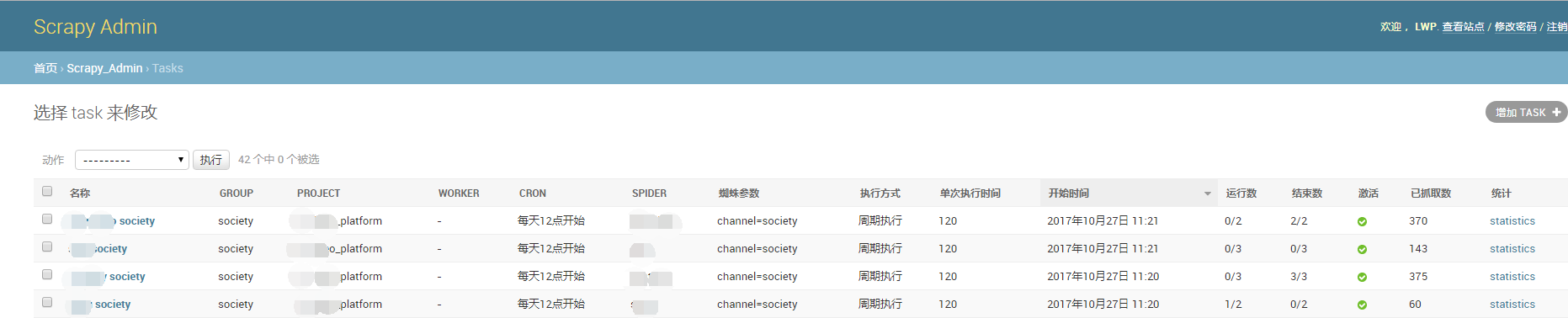
任务,用于创建定时或周期任务。
部署scrapyd的服务器节点,与Project是多对多关系。
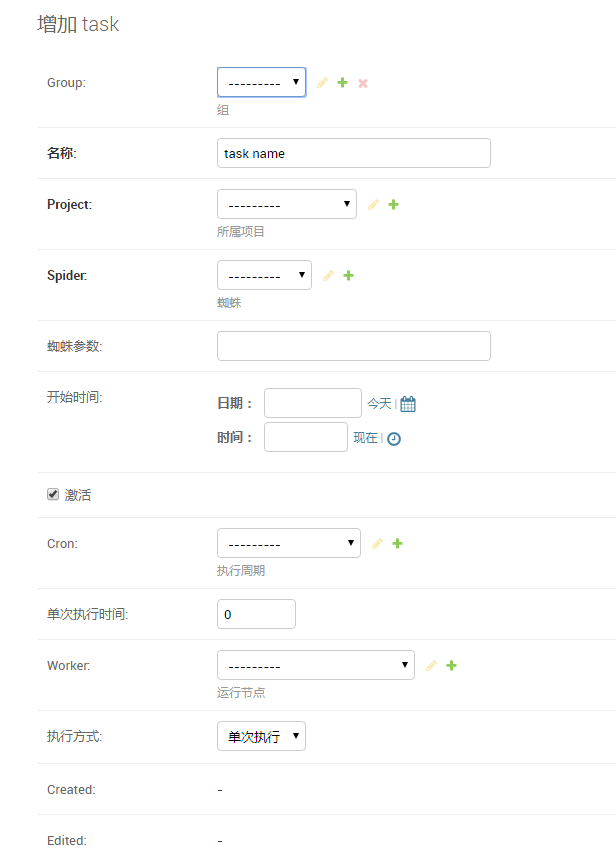
- 选择Group、Project、Spider
- 蜘蛛参数即为爬虫启动参数,格式为arg1=v1,arg2=v2
- 开始时间:当任务为定时任务(只会执行一次)时,到达开始时间,任务会开始执行。当任务为周期任务时,任务的首次执行时间不会早于开始时间。每次开始执行时候会创建j一个job。
- 单次执行时间:以分钟为单位。执行时间用完后会自动停止创建的job。0表示永远。
- Worker:任务运行的服务器节点,为空表示自动选择节点。自动选择的算法是,每到执行时间,选取一个空闲率最大的节点,空闲率的计算公式为:(最大工作数-运行工作数-排队工作数)/最大工作数目。
- 当任务为激活状态时,任务才会生效。任务保存后后台定时程序才会开始。
数据图绘制使用Echart书写