
- Introduction
- Overall
- Representations of Spoken Dialogue Models
- Training Paradigm of Spoken Dialogue Model
- Streaming, Duplex, and Interaction
- Training Resources and Evaluation
- Cite
- 2024.11.14 Release the first version of the WavChat in the github (The full paper will also be updated on the arxiv soon)! 🎉
This repository is the official repository of the WavChat: A Survey of Spoken Dialogue Models 
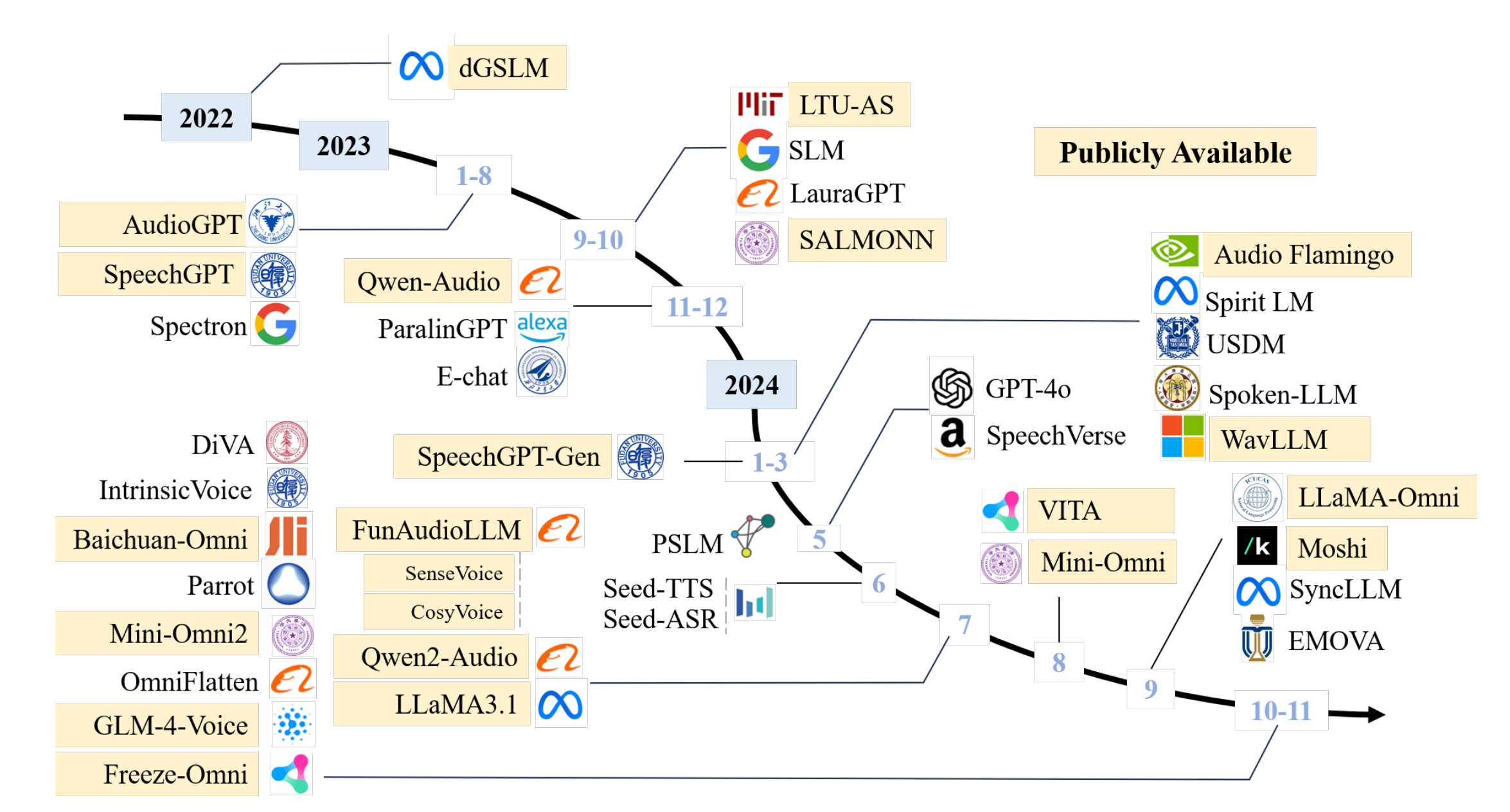
Figure 1: The timeline of existing spoken dialogue models in recent years.
Abstract
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. In the broader context of multimodal models, the speech modality offers a direct interface for human-computer interaction, enabling direct communication between AI and users. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems.

Figure 2: Orgnization of this survey.
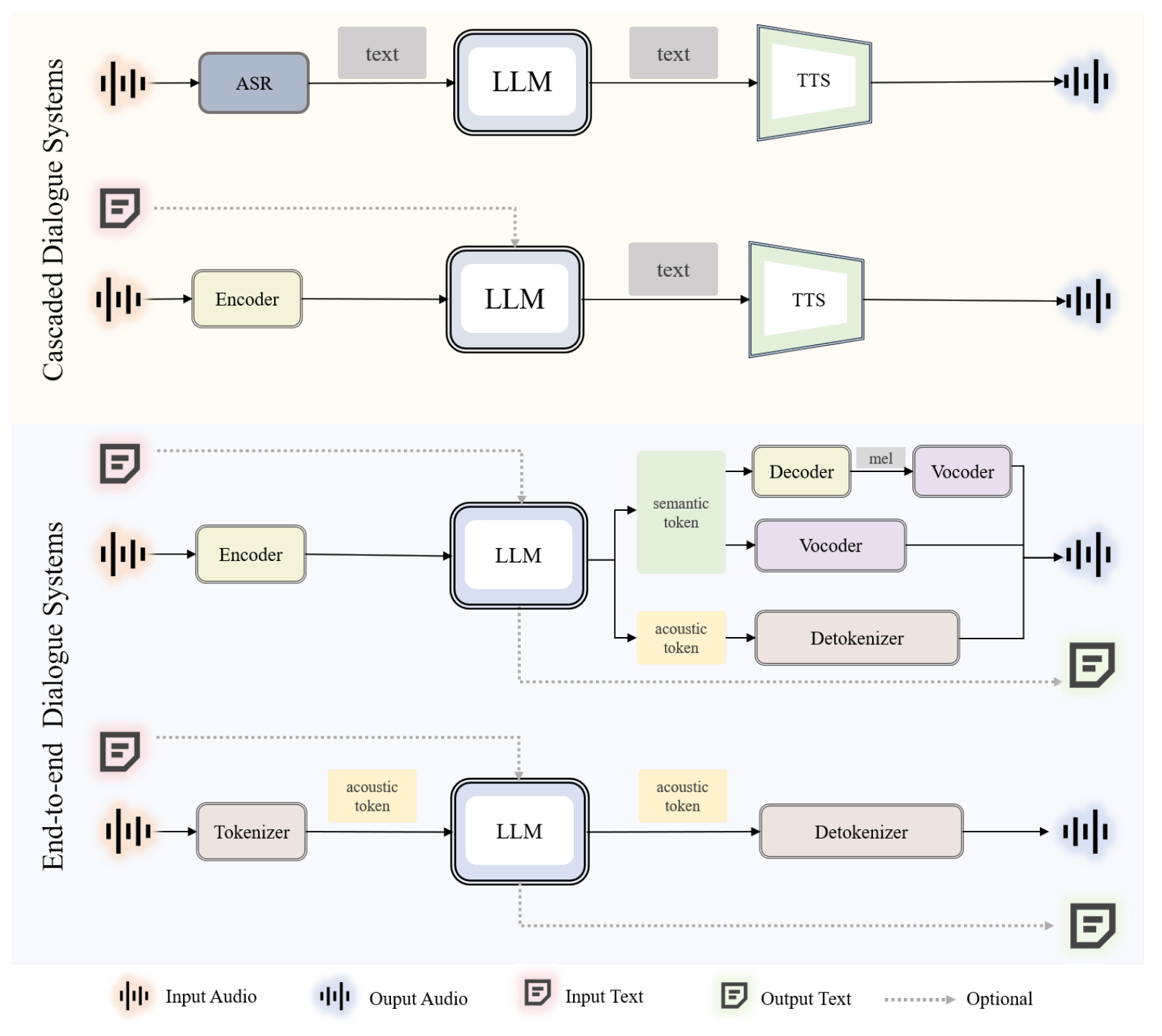
Figure 3: A general overview of current spoken dialogue systems.

Figure 4: An overview of the spoken dialogue systems' nine ideal capabilities.
Table 1: The list of publicly available speech dialogue models and their URL
In the section Representations of Spoken Dialogue Models, we provide insights into how to represent the data in a speech dialogue model for better understanding and generation of speech. The choice of representation method directly affects the model's effectiveness in processing speech signals, system performance, and range of applications. The section covers two main types of representations: semantic representations and acoustic representations.
| Advantages of the comprehension side | Performance of unify music and audio | Compression rate of speech | Convert to historical context | Emotional and acoustic information | Pipeline for post-processing | |
|---|---|---|---|---|---|---|
| Semantic | Strong | Weak | High | Easy | Less | Cascade |
| Acoustic | Weak | Strong | Low | Difficult | More | End-to-end |
And we provide a comprehensive list of publicly available codec models and their URLs.
In the Training Paradigm of Spoken Dialogue Model section, we focuse on how to adapt text-based large language models (LLMs) into dialogue systems with speech processing capabilities. The selection and design of training paradigms have a direct impact on the performance, real-time performance, and multimodal alignment of the model.
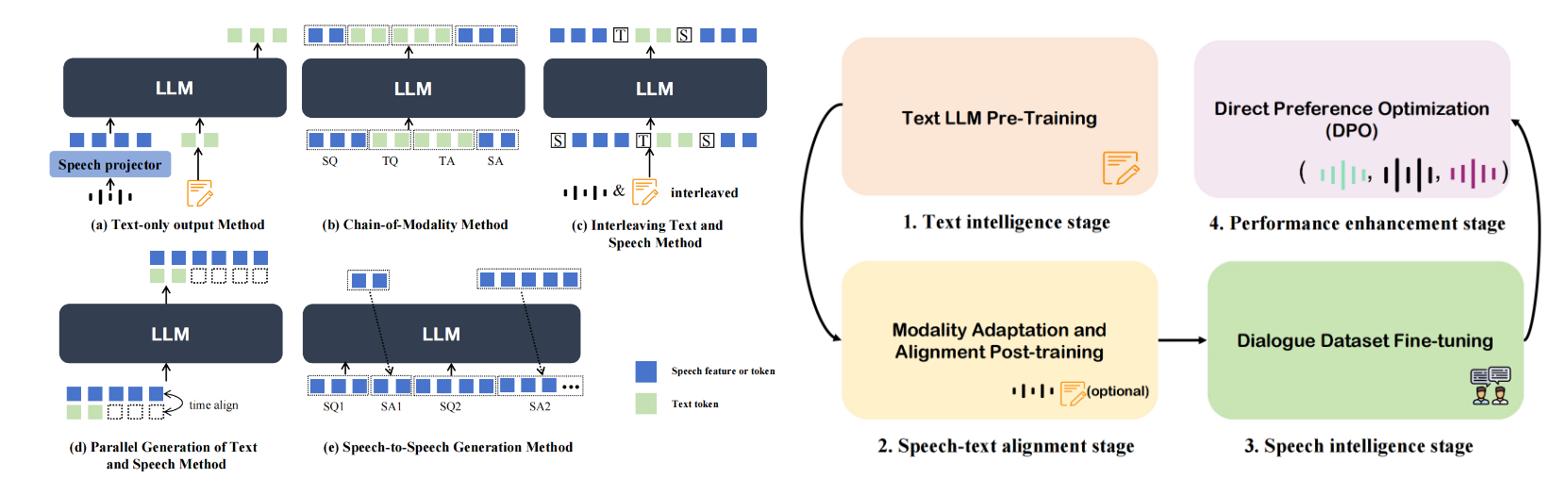
And we also comprehensively summarize an overview of the Alignment Post-training Methods.
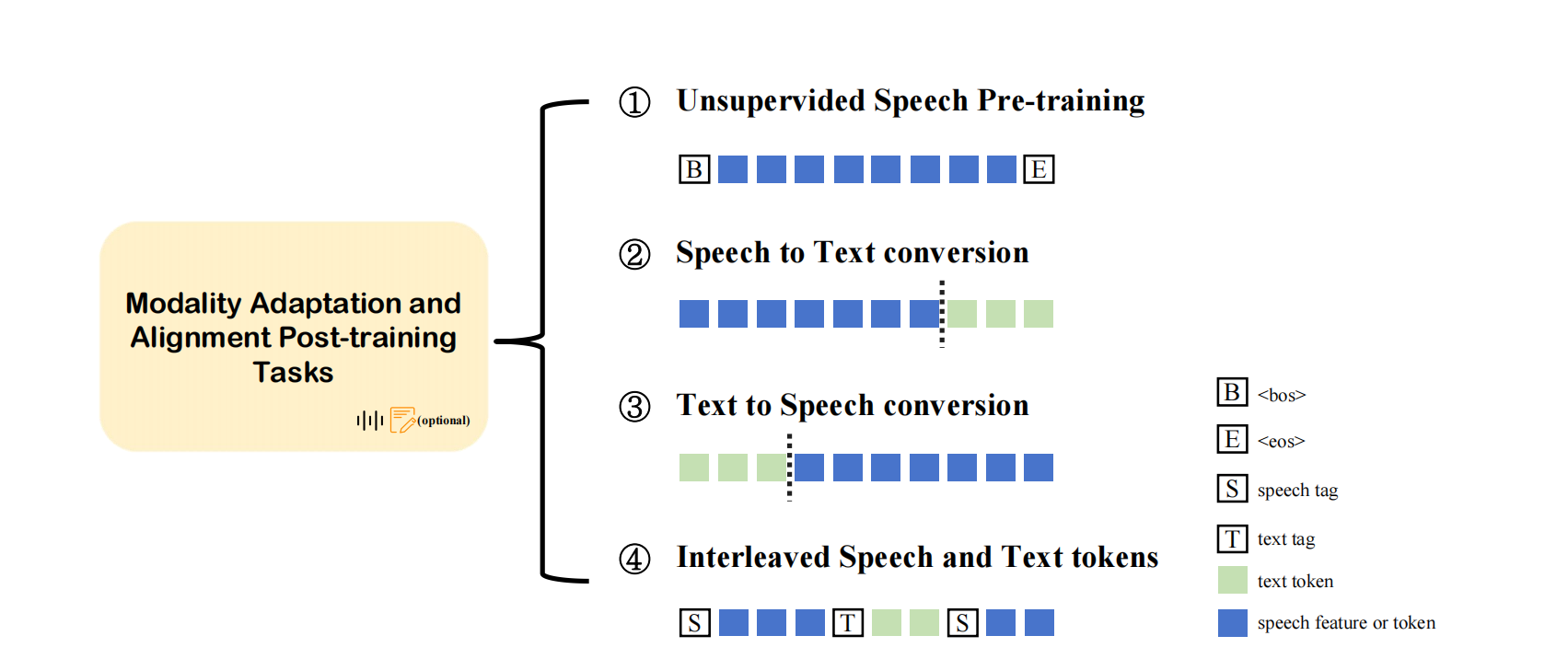
The Streaming, Duplex, and Interaction section mainly discusses the implementation of streaming processing, duplex communication, and interaction capabilities inspeech dialogue models. These features are crucial for improving the response speed, naturalness, and interactivity of the model in real-time conversations.
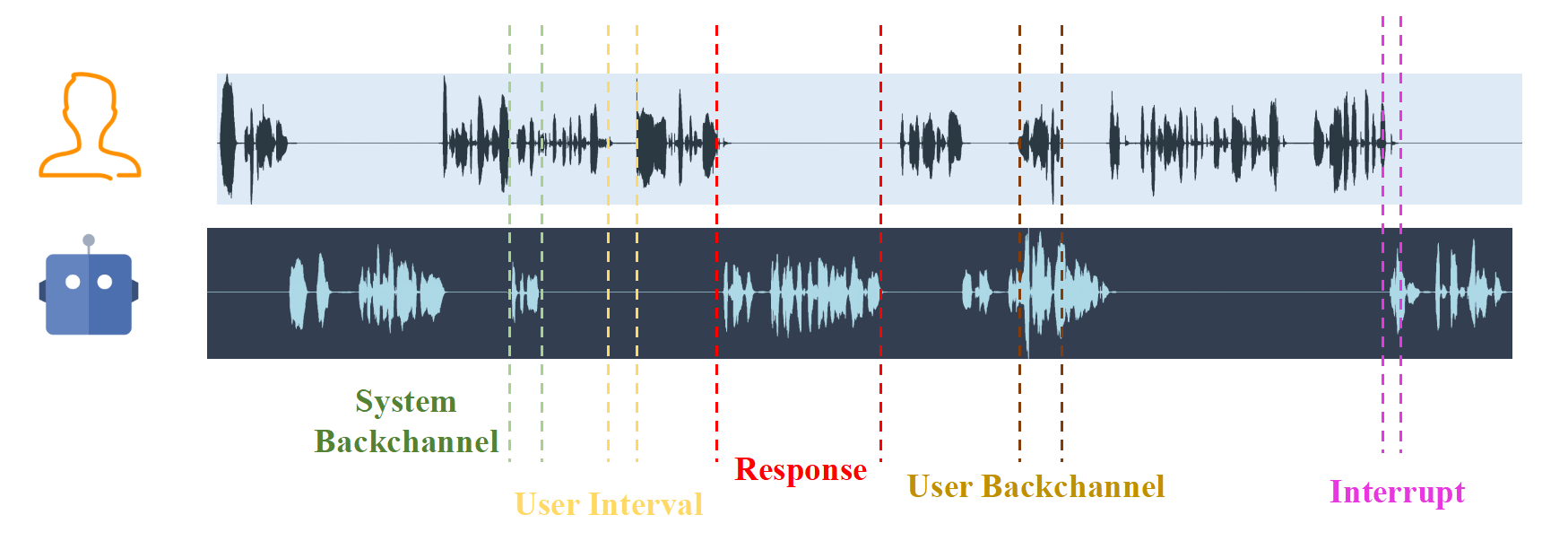
Figure 7: The Example Diagram of Duplex Interaction
| Stage | Task | Dataset | Size | URL | Modality |
|---|---|---|---|---|---|
| Modal Alignment | Mandarin ASR | AISHELL-1 | 170 hrs | Link | Text, Speech |
| Mandarin ASR | AISHELL-2 | 1k hrs | Link | Text, Speech | |
| Mandarin TTS | AISHELL-3 | 85 hrs, 88,035 utt., 218 spk. | Link | Text, Speech | |
| TTS | LibriTTS | 585 hrs | Link | Text, Speech | |
| ASR | TED-LIUM | 452 hrs | Link | Text, Speech | |
| ASR | VoxPopuli | 1.8k hrs | Link | Text, Speech | |
| ASR | Librispeech | 1,000 hrs | Link | Text, Speech | |
| ASR | MLS | 44.5k hrs | Link | Text, Speech | |
| TTS | Wenetspeech | 22.4k hrs | Link | Text, Speech | |
| ASR | Gigaspeech | 40k hrs | Link | Text, Speech | |
| ASR | VCTK | 300 hrs | Link | Text, Speech | |
| TTS | LJSpeech | 24 hrs | Link | Text, Speech | |
| ASR | Common Voice | 2,500 hrs | Link | Text, Speech | |
| Dual-Stream Processing | Instruction | Alpaca | 52,000 items | Link | Text + TTS |
| Instruction | Moss | - | Link | Text + TTS | |
| Instruction | BelleCN | - | Link | Text + TTS | |
| Dialogue | UltraChat | 1.5 million | Link | Text + TTS | |
| Instruction | Open-Orca | - | Link | Text + TTS | |
| Noise | DNS | 2425 hrs | Link | Noise data | |
| Noise | MUSAN | - | Link | Noise data | |
| Conversation Fine-Tune | Dialogue | Fisher | 964 hrs | Link | Text, Speech |
| Dialogue | GPT-Talker | - | Link | Text, Speech | |
| Instruction | INSTRUCTS2S-200K | 200k items | Link | Text + TTS | |
| Instruction | Open Hermes | 900k items | Link | Text + TTS |
Table 4: Datasets used in the various training stages
| Dataset | Size | URL | Modality |
|---|---|---|---|
| ESC-50 | 2,000 clips (5s each) | Link | Sound |
| UrbanSound8K | 8,732 clips (<=4s each) | Link | Sound |
| AudioSet | 2000k+ clips (10s each) | Link | Sound |
| TUT Acoustic Scenes 2017 | 52,630 segments | Link | Sound |
| Warblr | 10,000 clips | Link | Sound |
| FSD50K | 51,197 clips (total 108.3 hours) | Link | Sound |
| DCASE Challenge | varies annually | Link | Sound |
| IRMAS | 6,705 audio files (3s each) | Link | Music |
| FMA | 106,574 tracks | Link | Music |
| NSynth | 305,979 notes | Link | Music |
| EMOMusic | 744 songs | Link | Music |
| MedleyDB | 122 multitrack recordings | Link | Music |
| MagnaTagATune | 25,863 clips (30s each) | Link | Music |
| MUSDB | 150 songs | Link | Music |
| M4Singer | 700 songs | Link | Music |
| Jamendo | 600k songs | Link | Music |
Table 5: Music and Non-Speech Sound Datasets
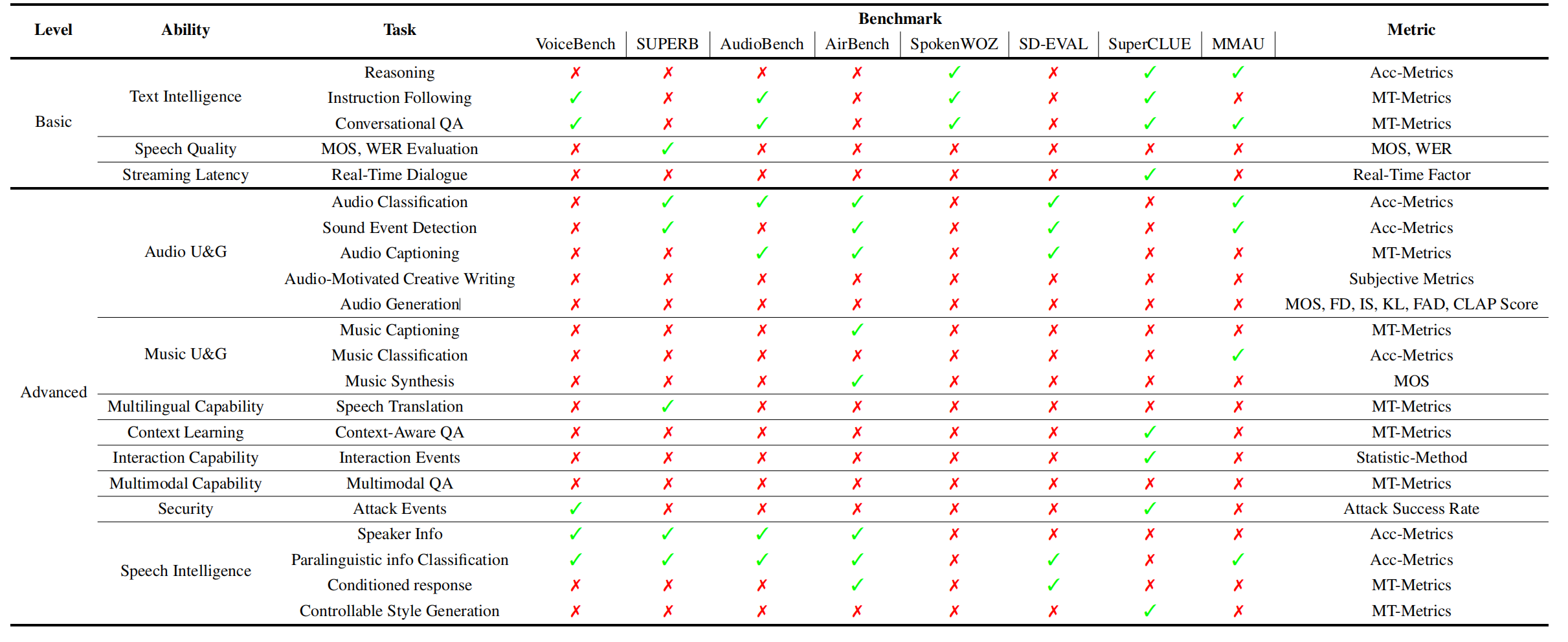
Evaluation is a crucial aspect of training and testing spoken dialogue models. In this section, we provide a comprehensive overview of the evaluation from 11 aspects. The evaluation metrics are categorized into two main types: Basic Evaluation, and Advanced Evaluation.
@article{WavChat,
title={WavChat: A Survey of Spoken Dialogue Models},
...,
}