jTessBox/kor.trainddata 를 로컬 Tesseract-OCR/tessdata 폴더에 추가한다. 이후 원하는 이미지(image_name.jpg)로 인식시킨다.
$ pytesseract -l kor "image_name.jpg"
Optical Character Recognition, 광학 문자 인식 이란 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것이다.
우리 팀은 졸업 프로젝트로 메뉴판의 메뉴를 OCR로 인식하여 그 음식의 비건 여부를 알려줄 수 있는 비건 렌즈를 제작하고자 하였다. 그리고 이를 위해 많은 OCR 툴 중 오픈 소스이고, 현재 5.0까지 Google 개발자들에 의해 꾸준히 업데이트 되어온 Tesseract를 사용하게 되었다.
하지만 Tesseract를 사용해본 결과, 뉴스 캡처와 같은 글씨는 잘 인식되지만 굴림체나 고딕체 이외의 폰트에서는 극악의 인식률을 보였다. 알파벳 각각을 하나씩 나열하는 영어와는 달리, 한글은 자음/모음을 각각 초성/중성/종성에 위치에 놓고 조합하는 방식이기 때문에 한글 인식률 자체가 그리 높지 않다고 한다. 이 모델의 인식률을 높이기 위해 새로운 폰트를 학습시키고자 하였다.
- 학습할 문장만 크롭
다른 메뉴판과 달리 유독 이런 길쭉길쭉하게 생긴 폰트로 쓰여진 한글이 잘 인식되지 않아 학습시킬 이미지로 이 메뉴판을 선택했다.

- 크롭한 이미지(jpg, png) -> TIF/TTIF 로 변환
이 때 변환된 파일의 이름은 ..exp.tif 의 형식을 반드시 지켜야 한다. 나는 한글을 학습시킬 예정이므로 파일명을 kor.long.exp0.tif 로 지정한 후 학습을 진행했다.
포맷 변환은 사이트를 이용했다.
- tif 파일로부터 box 파일 생성
box 파일이란 모듈이 문자를 정확하게 인식하기 위해 사용되는 인식 단위 하나하나에 사각형이 그려진 파일이다. box 파일 생성을 위해 Command 창에 다음과 같이 입력한다.
$ tesseract kor.long.exp0.tif kor.long.exp0 -l kor batch.nochop makebox
- box 파일 직접 수정 - jTessBoxEditor 사용
box 파일이 생성되면서 인식되는 문자에 자동으로 box가 그려지긴 하지만, 모듈이 잘못 인식한 경우 이 box의 좌표를 직접 수정해줘야 한다. 추천 방법은 jTessBoxEditor 나 CowBoxer 등이 있는데 본인은 jTessBoxEditor를 사용했다.
- 수정한 box 파일로 학습 진행
$ tesseract.exe kor.long.exp0.tif kor.long.exp0 nobatch box.train
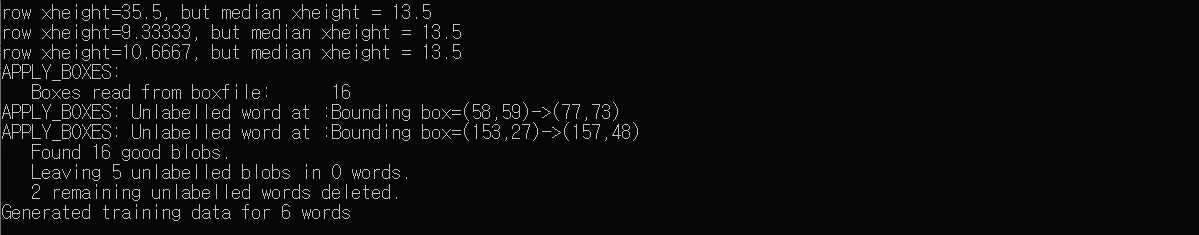
command line 에 다음과 같이 뜨며 학습이 진행된다.
6. unicharset 파일 생성
unicharset이란 Tesseract 가 출력 가능한 모든 문자들의 집합이다. cmd에 다음과 같이 입력해 폰트에 대한 unicharset을 생성한다.
$ unicharset_extractor kor.long.exp0.box
7. font_properties 파일 생성
font_properties 파일은 학습시킨 폰트의 스타일 정보를 포함하는 파일이다. 이 때 스타일 정보는 다음과 같다.
은 띄어쓰기가 없는 폰트의 이름이며 나머지 , , , , 는 0 또는 1의 플래그 값만 가진다.
$ <fontname> <italic> <bold> <fixed> <serif> <fraktur> > font_properties
내가 학습시키려는 폰트의 경우, 이탤릭체, 볼드체, 고정폭, 명조체, 블랙레터 어디에도 해당되지 않기 때문에long 0 0 0 0 0 > font_properties 를 입력했다.
8. Clustering
지금까지 학습 이미지 파일에서 문자의 윤곽 특징을 추출한 후 프로토타입을 생성하기 위해 클러스터링이 필요하다. 클러스터링을 위해 두 가지 작업을 수행한다.
1) mftraining : inttemp 파일 (윤곽 특징), pffmtable 파일 (문자별 기대되는 특징의 개수 정보) 생성
$ mftraining -F font_properties -U unicharset -O kor.unicharset kor.long.exp0.tr
2) cntraining : normproto 파일 (문자별 normalization sensitivity prototype) 생성
$ cntraining kor.long.exp0.tr

- 파일 이름 변경
unicahrset, normproto, pffmtable, inttemp, shapetable 파일의 이름 앞에 **lang.**을 붙인다.
ex) unicharset ->kor.unicharset
- 최종 학습 파일 생성
지금까지 생성한 파일들을 종합해 tessdata를 만든다.
$ combine_tessdata kor. // 이때 명령어 끝에 . 입력 필수!!

- 최종 학습 파일을 트레이닝 폴더에 넣기
완성된 학습 파일 kor.traineddata를 Tesseract-OCR > tessdata 디렉토리에 추가한다.
- 학습 시킨 이미지 다시 인식시키기
인식률이 높아졌는지를 확인하기 위해 다음과 같은 코드를 입력한다.
$ pytesseract -l kor "image_name.jpg"
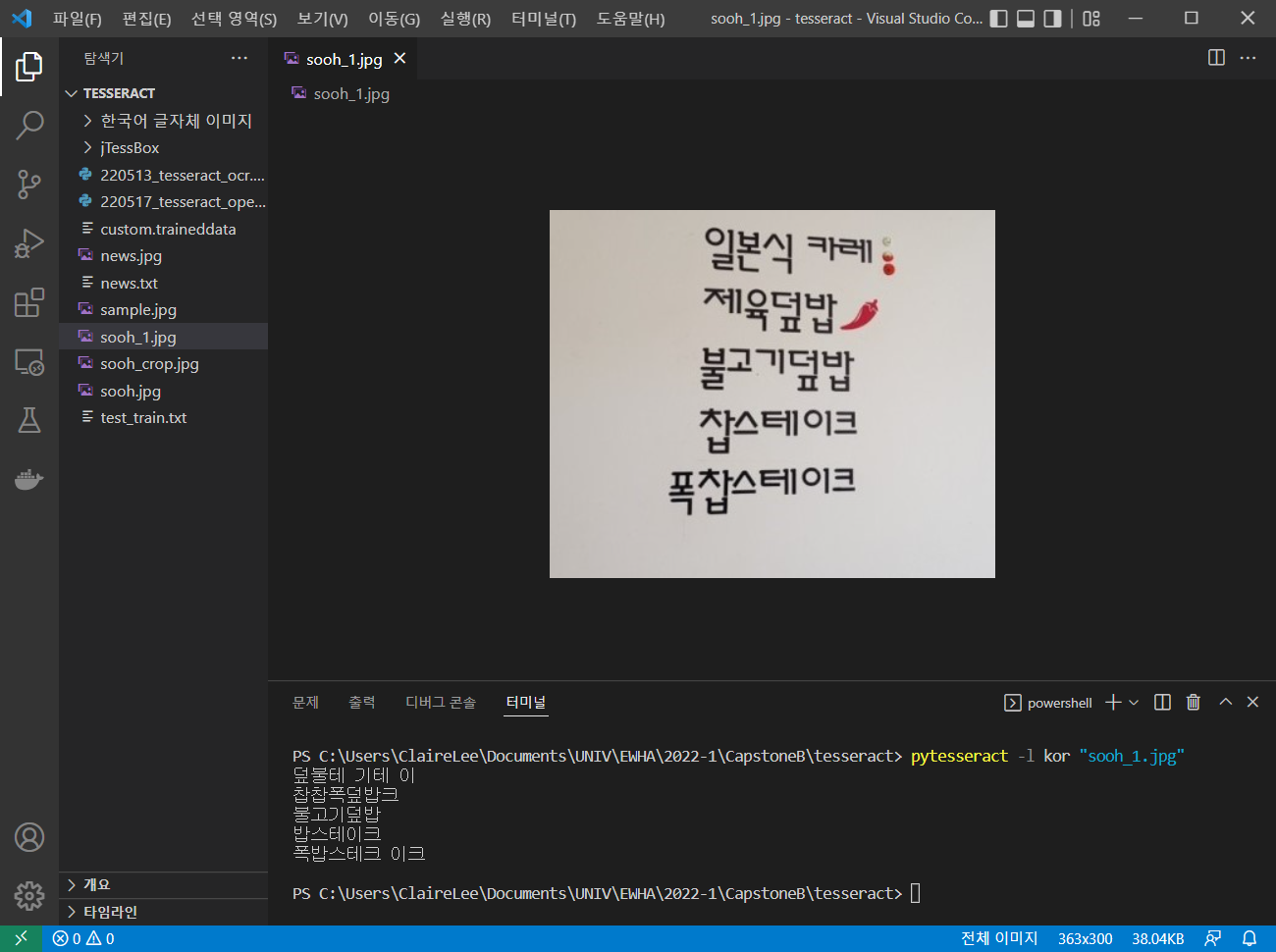
다음과 같은 결과가 나왔다.
일본식 카레 나 제육덮밥 옆의 그림이 한글로 인식된다. 또한 box 파일이 아직 부정확한지 공백이 '크'로 인식되는 것으로 보인다. 좀 더 많은 폰트를 학습시키고 모델 사용 전 OpenCV를 통한 이미지 전처리로 인식의 정확도를 좀 더 높일 예정이다.