{kind=link}
In this project, the kamikaze drone tries crashing to the enemy drone. The enemy drone is static, so it can be considered as a target. Enemy drone takes some information like:
- Its current location (x, y, z)
- Enemy's static location (x, y, z)
- Its current linear velocity (vx, vy, vz)
- Its current angular velocity (w)
- Enemy's static linear velocity (vx, vy, vz)
Note that enemy can not move, but for further improvements the reinforcement model takes enemy velocity also.
Proximal policy optimisation was selected as policy optimisation technique. It is easy to implement and very efficient. Detailed information can be found in original paper of algorithm which was released by OpenAI.
Gazebo was used for simulating physical actions of drones. c++ manages all simulation operations respect to information that comes from python (rl model). This connection is provided by ROS1.
As I said earlier the simulation and topic's connection is managed with c++, because of the efficiency and fastness of c++. All the deep learning operations and training process is managed with python. Detailed scheme was given in following.
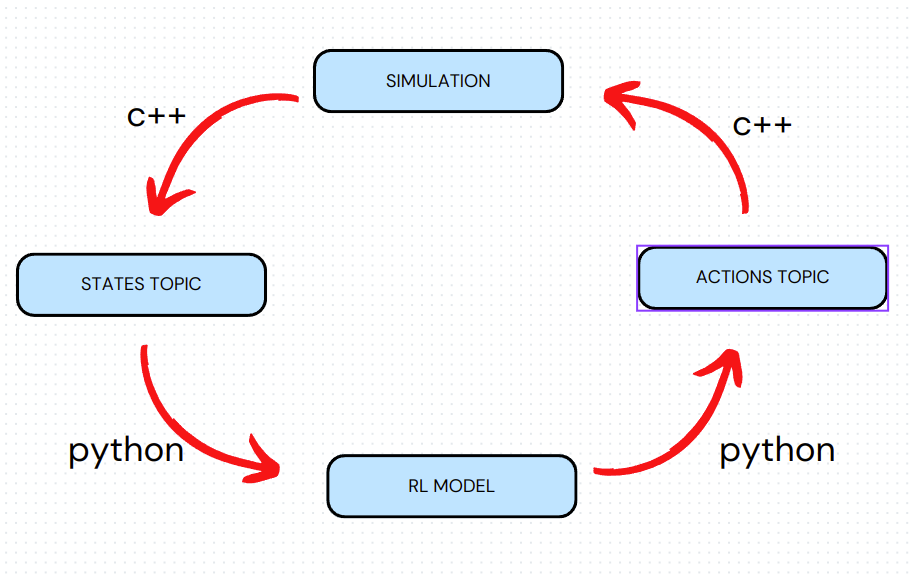
Scheme of project

After 3000 epoch training
gazebo
ros-kinetic and required dependencies
pytorch
Make necessary changes in main.py (train, test, visualize etc.). After that, run following command:
git clone https://github.com/emredo/kamikaze_drone
cd ./kamikaze_drone
catkin build ## whether catkin_make or catkin build is possible. It depends on your ros usages.
source ./build/devel/setup.bash
roslaunch simulation sim_dynamics.launch