SDSI 2014 Proposal
Below is the text of our proposal to the Stanford Data Science Initiative, 2014. This page is linked from the project wiki page
Stanford Data Science Initiative 2014
PI Risa Wechsler with Phil Marshall, Matthew R. Becker, and Sam Skillman (KIPAC)
Mapping out the Universe has been a fundamental goal of science for millennia. We are currently in a renaissance of data-rich astronomy, where the smallest, deepest surveys of the Universe probe galaxies over 90% of the Universe’s history. Additionally, the largest surveys have observed tens of millions of galaxies over large fractions of the sky. The next decade will see the start of the Large Synoptic Survey Telescope (LSST), which will map out 10 billion galaxies over half the sky. This survey will produce additional rich datasets on the positions and properties of galaxies, including the impact of the mass distribution of the Universe on these galaxies. The combination of these datasets with sophisticated statistical methods will allow us to create the most accurate maps of the Universe to date. While mapping the Universe has intrinsic interest, it is also scientifically fundamental because it links some of the biggest questions in modern astrophysics and cosmology: What is the Universe made of, and why is it accelerating? What happened in the first second after the Big Bang to seed all of the structure? How do the initial seeds of structure form and grow to produce our own Galaxy?
While we increasingly have a large amount of data from which to learn, our statistical tools are not sophisticated enough to take full advantage of the richness of the datasets that are becoming available. To date, we have been limited to simple, more easily separable problems, e.g. trying to understand how galaxies form while fixing the parameters which determine the structure of our Universe on its largest scales, or studying the Universe at its largest scales by fixing the parameters which determine its structure at the smallest scales. However, at the level of accuracy to which we aspire, the inference of the full set of model parameters is not an intrinsically separable problem.
Our proposed work is to take the first step in this joint inference problem. We will start to use all of the information available on the positions and properties of galaxies in order to jointly constrain the full set of model parameters which describes our Universe. These parameters are currently divided into the largescale, cosmological parameters and the smallscale, galaxy parameters. At present these parameter sets are studied separately via various statistical estimators that involve combining the individual galaxies’ measurements en masse binning, averaging etc before inferring the global parameters from these summary statistics. We propose to explore the alternative to this kind of simple, and very lossy, compression: hierarchical inference of the cosmological and galaxy population (hyper)parameters, after explicit marginalization of parameters describing individual galaxies. This will allow us to explore more detailed models of galaxies, and make higher fidelity predictions about specific physical effects, and may dramatically increase our constraining power. In practice, tackling big data in cosmology in this way will (eventually) involve handling models with billions of parameters, constrained by petabytes of data. If they can be made to work, these techniques may also have significant applications outside of cosmology. Although galaxies trace the matter distribution, they make up a small fraction of the total mass in the Universe, which is dominated by dark matter. Some of the most important information about the distribution of mass in the Universe comes from gravitational lensing, which provides a direct probe of the projected mass density. Conversely, many cosmological measurements in the Universe, such as type Ia supernova luminosity distances, strong lens time delay distances, or the masses of galaxy clusters, are contaminated by the combined gravitational lensing effects of all the massive objects along the line of sight. To account for them with maximal accuracy, we need to be able to predict these weak lensing effects at any given point on the sky, with sufficient angular resolution to capture even low mass galaxies close to the optical axis. In summary, we propose to map the universe by assigning a plausible mass distribution to every galaxy along the line of sight, drawn from a conditional PDF whose hyper-parameters have been inferred from all the observables available, including weak lensing effects and galaxy photometry.
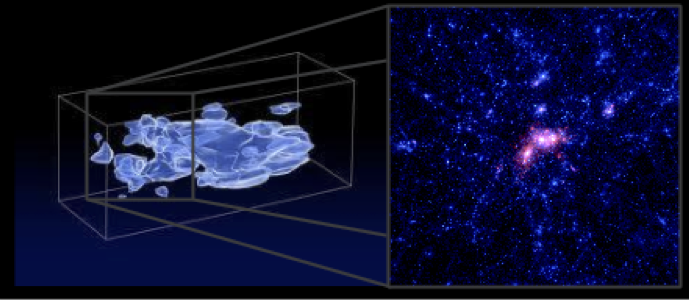 Figure 1: (Left) Mass map from the COSMOS survey (about 1/20000 of the sky), derived using currently available techniques from weak lensing by Massey et al (2007). (Zoom inset) A mass map from a simulation, showing what we expect to find in just a small subset of the volume depicted on the left, and how much more information is available if techniques can be improved (Figure made by Sam Skillman, based on the Dark Sky Simulation).
Figure 1: (Left) Mass map from the COSMOS survey (about 1/20000 of the sky), derived using currently available techniques from weak lensing by Massey et al (2007). (Zoom inset) A mass map from a simulation, showing what we expect to find in just a small subset of the volume depicted on the left, and how much more information is available if techniques can be improved (Figure made by Sam Skillman, based on the Dark Sky Simulation).
LSST will measure 10 billion galaxies, and provide colors and brightnesses of them all. These parameters will be used to infer the photometric redshift, stellar mass, size, and other galaxy properties. The massive galaxies in the foreground will distort the images of the ones in the background (by “gravitational lensing”), which means that we can learn the masses of their dark matter halos, from the many measured shapes of weakly lensed background galaxies. We can expect all these measurements to be available in catalogs produced by the LSST project (and its science collaborations), characterised by a small number of posterior samples. At 100 samples per galaxy we would analyze a trillion samples in all. Other data will also be available for various subsets of these galaxies, including spectroscopic surveys giving approximate distances to the galaxies and surveys in other wavelengths provide further information about the populations of stars in each of the galaxies. As opposed to drastically increasing the volume of data to be analyzed, this additional information will demand additional model sophistication and complexity in the form of more correlations between model parameters. Our best current physical models of the Universe predict accurately the dark matter which forms the scaffolding upon which galaxies are built. On the other hand, we observe the luminous components of galaxies (e.g., stars, gas, molecules, etc.). By fully modeling both the luminous components of the galaxies, and the the dark components as inferred through our hierarchical model applied to gravitational lensing, we should be able to break the internal degeneracies in our models.
Our goal is to make a three-dimensional map of all the mass in the observable universe, in a selfconsistent inference of the hyper-parameters that describe our cosmological world model and the connection between dark and baryonic matter in galaxies and clusters.
Part 1. How might we make such a map? Our current paradigm for galaxy formation posits that all galaxies form at the centers of gravitational bound clumps of dark matter called “halos”. In the simplest possible model for all the mass in the universe, we imagine galaxies residing in spherically symmetric dark matter halos with self-similar radial density profiles. Each of these objects could be characterised by a small number of parameters: halo mass Mh, stellar mass M*, redshift z, and so on. Even in the simplest version of this simple model (Figure 2), we are led to consider several billion parameters to describe all the galaxies in our survey. This model is hierarchical in nature: the parameters of galaxies and their halos are linked by conditional probability distributions governed by hyper-parameters. We have some information about the approximate form of these distributions, from previous “stacking” analyses, but would seek to learn their hyper-parameters from the survey data.
 Figure 2: Probabilistic graphical model for a simplified version of the cosmological mass reconstruction inference problem. Hyper-parameters come in two types: cosmology (violet) or galaxy evolution (red). The abundance of galaxies as a function of their halo mass Mh and redshift z (the “mass function”) depends on cosmology, and is shown in green. The conditional PDF capturing the halo massstellar mass (MhM*) relation, and also the halo occupation model, is shown in orange/red. Both foreground (lensing) and background (lensed) galaxies are assumed to be drawn from this same global model; the foreground objects affect the observed shapes of the background galaxies (epsilon) by weak gravitational lensing (blue). Observed quantities are shown shaded gray (with uncertainties left off for clarity): the shapes of background galaxies, and the colors and brightnesses (phi) of both the foreground and background galaxies.
Figure 2: Probabilistic graphical model for a simplified version of the cosmological mass reconstruction inference problem. Hyper-parameters come in two types: cosmology (violet) or galaxy evolution (red). The abundance of galaxies as a function of their halo mass Mh and redshift z (the “mass function”) depends on cosmology, and is shown in green. The conditional PDF capturing the halo massstellar mass (MhM*) relation, and also the halo occupation model, is shown in orange/red. Both foreground (lensing) and background (lensed) galaxies are assumed to be drawn from this same global model; the foreground objects affect the observed shapes of the background galaxies (epsilon) by weak gravitational lensing (blue). Observed quantities are shown shaded gray (with uncertainties left off for clarity): the shapes of background galaxies, and the colors and brightnesses (phi) of both the foreground and background galaxies.
We will begin by investigating importance sampling, as in, for example, Busha et al (2012). The amount of weak lensing information provided from each line of sight is very small, indicating that the shifts and skews introduced by the importance weights will be slight. While this would seem promising, the number of required conditional PDF evaluations will still be very high, making hyperparameter space exploration potentially challenging. Implementation and testing of this model on raytraced mock catalogs generated from large volume of Nbody simulations would comprise the bulk of the initial phase of the proposed work. We will need a suite of large simulated catalogs of galaxy observables (including brightnesses, colors, positions, and measured weak lensing distortions) from which we can define training and validation sets. Each mock dataset will contain around 20 million noisy shear measurements. A typical test model for the hierarchical inference might involve 1 million massive galaxies, each with a handful of parameters describing its dark matter halo, and then another handful of hyperparameters to capture the properties of the population.
Applications: Even with the simplest “spherical cow” model described above, we will be able to use its posterior predictive distributions along particular lines of sight in order to account for line of sight weak lensing effects and improve the accuracy of:
- Cluster mass measurements
- Strong lens time delay distance measurement
- Mass maps based on cosmic shear As an initial test case, applying the model to the publicly available data in the COSMOS field (Massey et al 2007, Leauthaud et al 2012) will enable us to:
- Remake the COSMOS 3D mass map at the highest possible resolution
- Infer galaxy-halo connections beyond simple scaling relations with log normal scatter, investigating the forms of the conditional PDFs.
Part 2: Next Steps. More flexible models of the distribution of dark matter in and between galaxies will be explored, building on the framework arising from Part 1. Possibilities include dictionaries of simulated halos built from the simulations themselves and organised via tree structures, or Gaussian process density fields. Extending the model to larger scales, and including the position information as constraints on cosmology as well, would, if technologically feasible, allow a selfconsistent analysis of all LSST’s dark energy probes.
Beyond the 10 billion galaxies that we will 12 use in our analysis, we must rely on very large cosmological simulations, discretized into ~10 computational elements, generating Petabytes of data. These simulations are run on the world’s fastest supercomputers, and provide a backbone upon which to develop our theories of galaxy formation and evolution. We hope to foster cross-talk between high performance computing and data science, combining machine learning with very large, tightly coupled simulation output. In practice, the best way to achieve long term goals such as these, or even just to improve upon the analysis we will attempt, is to enable others to do better science.We will distribute all our products and code as we develop them in open fashion. We have recently developed novel techniques for making some of the largest datasets (10s of TB) accessible to and usable by the public, and have applied them to a selection of spatially sorted simulated datasets (see http://darksky.stanford.edu). We will extend this approach to the observational datasets in this proposal and look forward to collaborating with others in the SDSI to explore applicability in their datasets, enabling a broader set of the community to test ideas with rapid turnaround time.
Example customers in the cosmology and astrophysics community include:
- The broad community that is currently focused on systematics in cosmology, for example, the dark energy scientists engaged in the DES and LSST surveys. We envision specific applications of our datasets and techniques to strong lensing, weak lensing, galaxy clusters, and galaxy clustering. * Researchers modeling shear with other methods, for example using Gaussian processes instead of a model for the underlying dark matter halos.
- The broader galaxy formation community. This community has fewer accuracy requirements than the precision cosmology community, but is still in its infancy in using large datasets in large statistical inference problems.
In addition, we will invite participation from the broader data science community at Stanford and beyond. In order to achieve both of these goals, we will break down barriers to entry, using small test data sets and easily accessible data formats. By the end of the first year of the proposed work, we plan to release a simple version of our mock galaxy catalog, containing “observed” galaxy properties such as ra, dec, z, stellar mass and ellipticity similar to what would be output by an LSST pipeline, to both the astronomy community and the local SDSI community. We will also release catalogs and maps describing the corresponding “true” underlying properties of the mass distribution and its galaxies. We will engage astronomers along with computer science and statistics researchers to apply different methods to address this inference challenge.