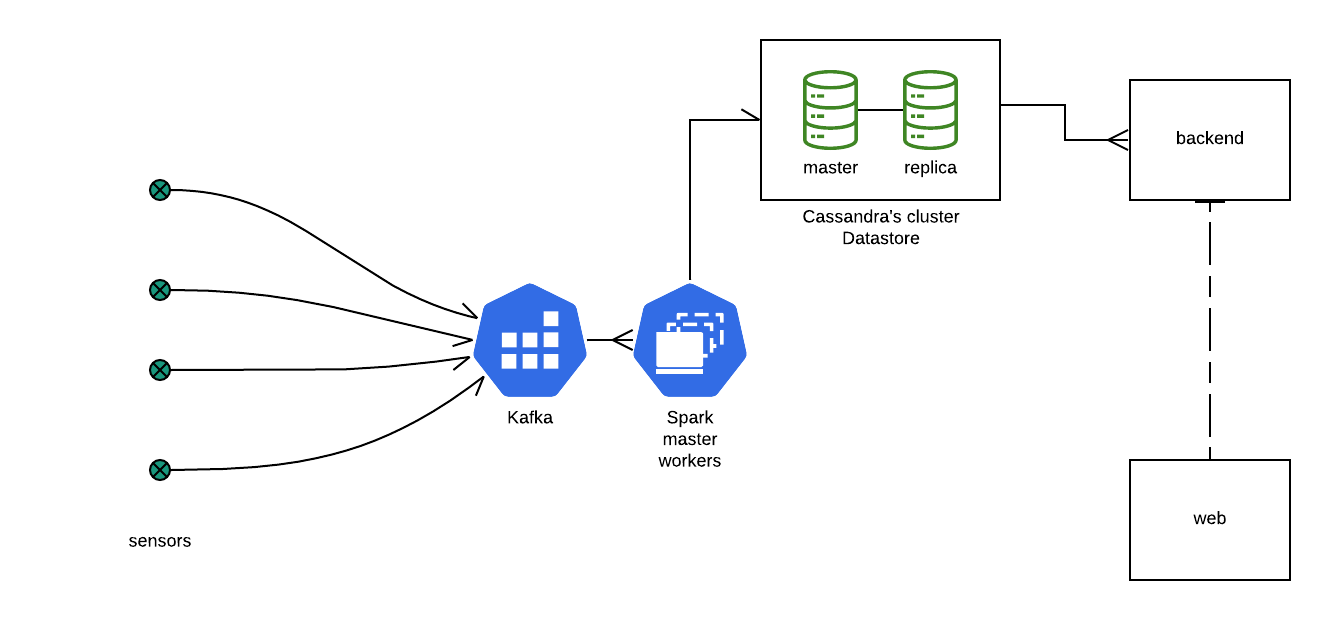
Este proyecto es una POC de cómo funcionaría un eventual sistema que monitoree sensores que van reportando un estado cada x tiempo. Los sensores reportan sus estado en ráfagas o muestras de a 10 valores, el sistema se queda con el mayor de cada muestra y lo guarda en una instancia de Cassandra. Por otro lado, hay una app que lee ese estado almacenado de los sensores y los reporta a través de una API a una web que grafica el estado de los sensores.
-
Sensores Implementación de productores de data. Se encargan de tomar el estado del sensor y enviarlo a un tópico Kafka al cual están suscriptos. Los sensores envían su estado regularmente. El estado de un sensor consta de 10 tomas, lo que llamaremos una ráfaga. de las cuales interesa tomar y almacenar la máxima toma de cada ráfaga.
-
Stack core Esta stack es la encargada de dar soporte a la infraestructura de recepción, procesamiento y almacenamiento de información. La stack está compuesta de la siguiente manera:
- Kafka Broker donde se define el tópico/cola donde los sensoners reportan su estado. Los condensa alli hasta que son consumidos. Utiliza zookeeper para coordinar el escalado de procesos distribuídos
- Spark Lee y administra los datos, y los organiza para ser procesados por el cluster Spark. Este cluster consta de tres instancias de spark. Una hace las veces de master o coordinador y dos workers donde se distribuye la carga de procesamiento.
- Cassandra Datastore utilizado para persistir la data procesada por el cluster de spark.
-
Hub Spark Job que lee los datos reportados y los procesa distribuyendo esa carga dentro del cluster. el procesamiento es el siguiente: se reciben los datos en el tópico definido en kafka. se agrupan por sensores, y se calcula el máximo de la ráfaga. y se almacena en el datastore Cassandra.
-
Backend Se conecta al datastore para leer la data sumarizada y la expone a través de API web.
- La conexión a Cassandra y la posterior interacción se realiza de manera agnóstica (sin instrucciones sql o propias del almacen de datos)
- Se últiza el concepto de Flux provisto por Spring para realizar un stream de datos hacia el cliente.
-
Web UI que grafica en un browser web los datos consolidados y expuestos en el backend
- docker 19.03+
- docker-compose 1.24 +
- java 11+
- node 10+
(Cada uno de los comandos se ejecutan desde la raíz de este proyecto)
arrancar spark y kafka + cassandra
./dc up
En http://localhost:8080/ se puede ver el estado de Spark
deployar el spark job
cd hub ; ./deploy
arrancar los productores
cd producer ; ./start-sensors
arrancar el backend que consume un stream consultado cassandra
cd backend ; ./mvnw spring-boot:run
arrancar el frontend de ejemplo
cd web ; npx npm-install-if-needed; npm start