An alternative to ORM's such as Entity Framework, offers database mapping for your existing CLR objects with minimal effort. CodexMicroORM excels at performance and flexibility as we explain further below.
Product not a fit for you? Feel free to visit and learn about data integration and ORM concepts through our blog and product updates.
Refer to our recent article that covers recent updates in the 0.5 release.
Why build a new ORM framework? After all, Entity Framework, nHibernate and plenty of others exist and are mature. I have seen complaints expressed by many, though: they can be "heavy," "bloated" and as much as we'd like them to be "unobtrusive" - sometimes they are.
Wouldn't it be nice if we could simply use our existing POCO (plain-old C# objects) and have them become ORM-aware? That's the ultimate design goal of CodexMicroORM: to give a similar vibe to what we got with "LINQ to Objects" several years ago. (Recall: that turned anything that was IEnumerable<T> into a fully LINQ-enabled list source - which opened up a whole new world of possibility!)
CodexMicroORM (aka "CEF" or "Codex Entity Framework") isn't necessarily going to do everything that other, larger ORM frameworks can do - that's the "micro" aspect. We'll leave some work to the framework user, favoring performance much of the time. That said, we do aim for simplicity as I hope the demo application illustrates. As one example, we can create a sample Person record in one line of code:
CEF.NewObject(new Person() { Name = "Bobby Tables", Age = 7, Gender = "M" }).DBSave();The demo project and tests show several other non-trivial use cases.
The work done with CodexMicroORM leads naturally into some related tool work, including a HybridSQL database add-on, where the goal is to remove the need to worry about object-relational mapping: as an object-oriented database, it will offer excellent in-memory performance with greater simplicity than many other alternatives. Follow this project to stay on top of details!
Diving more deeply, what does CodexMicroORM try to do better than other frameworks? What are the guiding principles that have influenced it to date? (Too much detail if you're skimming? Feel free to skip forward, but check back here from time to time as this list will be updated to reflect any new base concepts that CEF will address.)
- Entities can be any POCO object, period. Why is this important? Going database-first can sometimes lead to bad object models. Similarly, going model-first can lead to bad database (storage) design. Why not express the best format in both worlds and explain how they relate using "simple one-liners" (configuration). In CEF's case, the configuration is expressed through simple registration statements. Update: we now support declarative attributes that cover all the major bases. Attributes make sense for code generation where you're "ok" with decorating your business objects. (Where you aren't or want to do something fancy with run-time configuration, registration statements still work.)
- Entities do not need to have any special "database-centric" properties (if they don't want - many will want them). In our example model, note that Phone doesn't have a PhoneID as one example.
- Entities should be able to carry "extra" details that come from the database (aka "extended properties") - but these should be "non-obtrusive" against the bare POCO objects being used.
- Entities can be nested in what would be considered a normal object model (e.g. "IList<Person> Children" as a property on Person vs. a nullable ParentID which is a database/storage concept - but the DB way should be supported too!).
- Use convention-based approaches - but codify these conventions as global settings that describe how you prefer to work (e.g. do you not care about saving a "Last Updated By" field on records? The framework should support it, but you should be able to opt out with one line of code at startup).
- Entities can be code-gened from databases, but is not required at all.
- Code-gen properties by entity / database object should be retrievable from a logical model (e.g. Erwin document), SQL-Hero (repository supports flexible user-defined properties), or some other type of file-based storage.
- Entities shouldn't have to be contained by "contexts" like you see in EF: they really can be any object graph you like! This might seem like a small deal, but it really frees you up to work with objects however you like, with some conventions-based rules.
- Can be used as a "bridge": you may have POCO objects that don't implement INotifyPropertyChanged for example (and have no desire to change this!), but you might like this feature with minimal effort in some settings - you could with CEF create dynamic objects that deliver value-add and effectively wrap select POCO objects and use them for specific/limited situations (e.g. UI binding).
- Anything beyond simple POCO is considered a service.
- Entities can (and should) have "defaults" for what services they want to have supporting them:
- Defaults can be set globally at AppDomain level.
- Defaults can be set per entity based on code, or using attributes.
- Defaults can be overridden, per instance, both opting in and out of services.
- Not every object needs every service, support the minimum overhead solution as much as possible.
- Some services might need to target .NET Framework, not .NET Standard, where the support does not exist: but this should be "ok" - if you want to use a service that relies on .NET Framework, you simply need to implement your solution there (or in a client-server scenario, you can implement a different set of services in each tier, if you like!)
- A "collection container of entities" should exist and provide an observable, concrete common generic framework collection; it's EntitySet<T> and implements IEnumerable<T>, ICollection<T> and IList<T>.
- Support .NET Standard 2.0 as much as possible - run everywhere. (ICustomTypeProvider as one example isn't there, so for WPF we have the CodexMicroORM.BindingSupport project which is net461.)
- Services can include:
- UI data-binding support (e.g. implements INotifyPropertyChanged, IDataErrorInfo, etc.) for entities and collections of entities.
- Caching (ability to plug in to really any kind of caching scheme - I like my existing DB-backed in-memory object cache but plenty of others) - again, caching is a service, how you cache can be based on a provider model. Also, caching needs can vary by object (e.g. static tables you might cache for much longer than others).
- Key management (manages concept of identity, uniqueness, key generation (SEQUENCE / IDENTITY / Guids), surrogate keys, cascading operations, etc.).
- In-memory indexing, sorting, filtering (LINQ to Objects is a given, but this is a way to make that more efficient especially when dealing with large objects).
- Validations (rather than decorate the POCO with these, keep them separate - perhaps some validations are UI-centric, others are not; leave it to the framework user to decide how much or little they want).
- Extended properties: for example, being able to retrieve from a procedure that returns extra details not strictly part of the object - useful for binding and ultimately may match a saveable object (i.e. not a completely generic bag). Ideally strong-type these additional fields for intellisense, performance, type safety, effective DB contract, etc. These by being kept separate and managed via a service means it's completely opt-in and we don't carry unneeded baggage. This is different from the ability to load sets of existing objects (e.g. Person) from arbitrary procedures as well: if the result set matches the shape of the object, that should just work out of the box with no special effort.
- Persistence and change tracking (PCT) - can identify "original values", "row states", and enough detail to serialize "differences" across process boundaries. (Update - as of 0.2.2, serialization support has been added, including the ability to send only changes over the wire.)
- Audit - manages "last updated" fields, logical deletion, etc. Things like Last Updated fields should have framework support so we don't have to worry about managing these beyond high level settings.
- Database Persistence:
- Supports stored procedure mapping such that can leverage existing SQL audit templates that do a good job of building a CRUD layer, optimistic concurrency and temporal tables "done right" (i.e. determine who deleted a record!! - not something you can do natively with SQL2016 temporal tables).
- Supports parameter mapping such that can still read and write from objects that are strictly "proc-based", where needed. (I.e. having tables behind it is not necessary).
- Understands connection management / transaction participation, etc. - see below.
- The full .Save() type of functionality for single records, isolated collections and complete object graphs.
- Support some of the nice features of CodeXFramework V1.0 including the option to bulk insert added rows, etc.
- Should be able to work with "generic data". A fair example is a DataTable - but we can offer lighter options (both in code simplicity and with performance).
- The service architecture should be "pluggable" so others can create services that plug in easily. (Core services vs. non-core.)
- Entities could come from third-parties or external libraries. This means you have no way to change modifiers, decorate them with ORM attributes, change inheritance, etc. - we should be able to leverage services like persistence, even with these.
- The life-time of services may not be a simple "using block" - e.g. UI services could last for the life of a form - give control to the developer with options. Plus, connection management should be split into a different service since sometimes this needs to be managed independently (i.e. multiple connections in a single service scope, or crossing service scopes).
- Detection of changes should be easy and allow UI's to be informed about dirty state changes. Building on this concept, we can create sophisticated framework layers that offer services not offered by many other frameworks.
- Supports proper round-tripping of values (keys assigned in DB on save show up in memory, audit dates/names assigned show up as well, etc.)
- Database access: focus is on using stored procedures. Why? Reasons:
- The "extra layer" is something I've exploited very successfully in the past - it's an interception layer that's at least "there".
- The layer is trivial to generate for CRUD, so difficulty is hard to justify (you would normally only write custom retrievals which can stand to have optimization that's easier centralized within procedures anyhow).
- The layer can value-add - optimistic concurrency, audit, etc. - controlled via declarative settings.
- There are some interesting optimization opportunities: native compiled procs, for example. Combine that with in-memory tables where it makes sense, and - just wow.
- The layer can support non-tabular entities - e.g. flattened procedures that interact with multiple tables, or cross-db situations, etc.
- This is just one flavor of database access - the provider interface means it'd be possible to integrate other ways, perhaps even a LINQ to SQL layer (a roadmap item). As of 0.2, CEF only supports MS SQL.
- Databases - need to support the possibility of different objects being sourced/saved to different databases and/or servers and/or schemas. Use of schemas is a useful organizational (and security) tool. (Needs control type-by-type in registration process.)
- Use parallelism where possible, and make it as thread-safe as possible for framework users. (See the benchmarks below to see how profoundly bad many existing popular ORM's are in this regard!)
- As a rule, the framework will trade higher memory use for better performance. We do have some data structures that can appear to hog memory, but I've taken the time to ensure that when service scopes are disposed, memory is released as expected. Benchmarking also shows a linear performance characteristic, whereas EF is non-linear.
- Expect fewer "sanity checks" than you might get out of some ORM's - again, favoring performance heavily. As one example, we're going to trust you to do things like enable MultipleActiveResultSets on your connections when doing parallel operations (although in this example, we do check for this for some internal parallel operations). Again, the "micro" means light-weight, within reason.
- Registration process should support multiple code gens - for example you could generate 3 different registration methods for 3 different databases.
- All of the setup code we see should be generated from models: be it a database, or even an ERD. The end goal is you identify some logical model you want to work with, map it (visually, ideally), and then plumbing is created for you - start using objects and away you go.
- Sensitive to your preferences: for example, if your standard is to use integer primary keys versus longs, we should let you do that easily. The same is true with your naming conventions (although name mapping is more of a vnext feature).
- Ability to interop with DataTable/DataView. This is not my suggested approach, but given the familiarity many have with these, we can offer some useful extension methods to support copying, merging, etc.
I'll dive deeper on the various design goals in blog postings.
The general approach of CodexMicroORM is to wrap objects - typically your POCO. Why? We make no assumptions about what services your POCO may provide. In order to have an effective framework, one handy interface we want to leverage is INotifyPropertyChanged. If your POCO do not implement this, we use a wrapper that does and use containment with your POCO - wrapping it. (Update 0.2.4: in this release we add support for IDataErrorInfo as an interface exposed by CEF wrappers - see below for an example of its usage in WPF.)
The concept of a context isn't unfamiliar to many ORM frameworks. CodexMicroORM also uses the idea of a context, but is called the service scope. A service scope is unobtrusive: it doesn't need to be generated or shaped in a particular way - it can have any object added to it, becoming "tracked."
There can be two kinds of wrappers: your own custom wrapper class that typically inherits from some other POCO and adds "framework-friendly functionality," and "infrastructure wrappers" that are more like DataTable's, except they derive from DynamicObject. The framework can use multiple flavors of these objects:
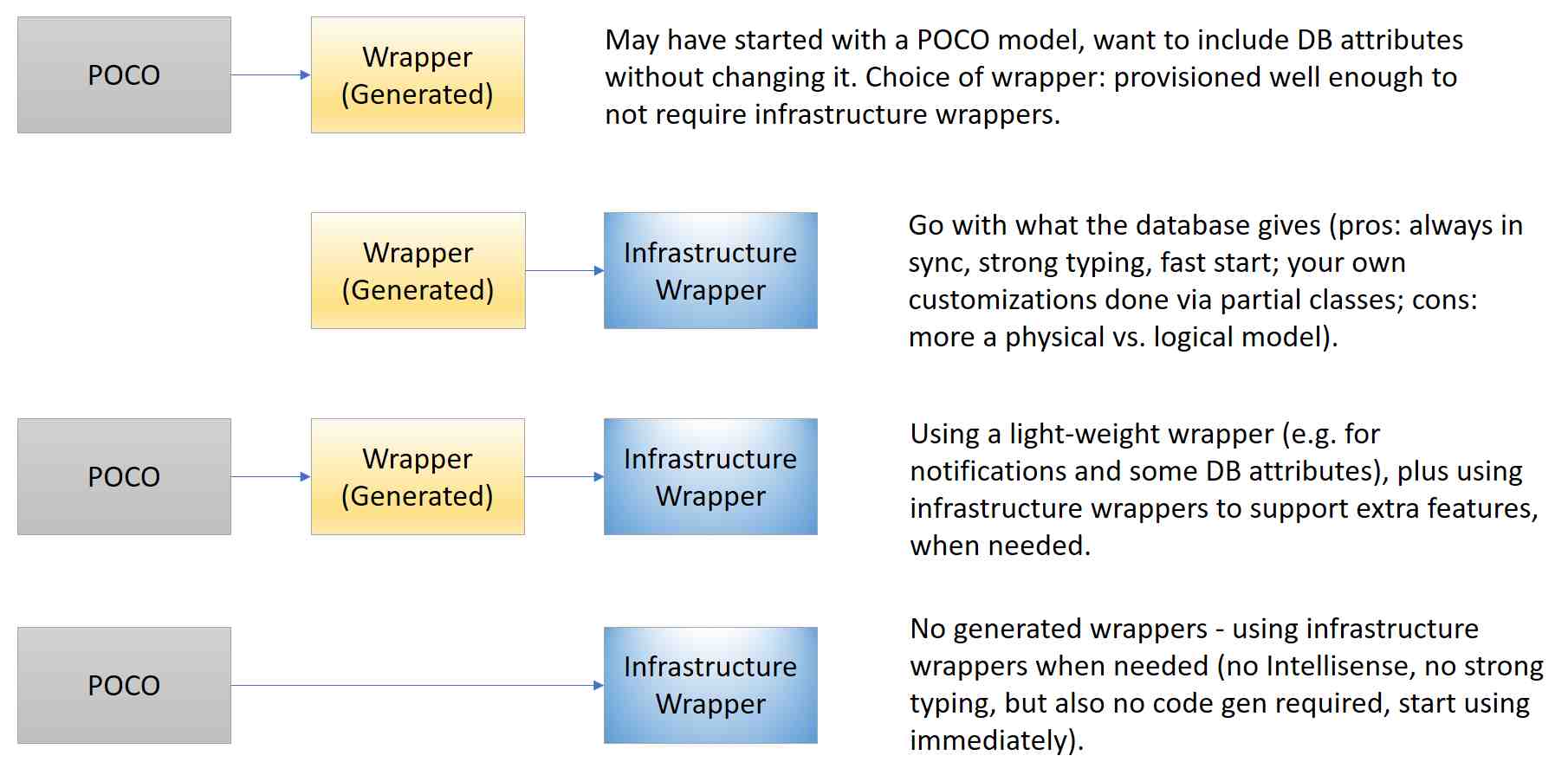
The key is flexibility: you can mix-and-match approaches even within a single app! In fact, our demo app does this by using a Person POCO, along with a PersonWrapped wrapper (theoretically code generated). The Phone POCO does not have a corresponding PhoneWrapper, but that's okay - we don't need it since the infrastructure wrapper used will be provisioned with more services than it would be if you had a wrapper (or POCO) that say implemented INotifyPropertyChanged.
In release 0.2, the main way to interact with the database is using stored procedures. As mentioned in the design goals, this is largely intentional, but it is just one way to implement data access, which is done using a provider model.
Use of stored procedures as the "data layer" is by convention: you would typically name your procedures up_[ClassName]_i (for insert), up_[ClassName]_u (for update), up_[ClassName]_d (for delete), up_[ClassName]_ByKey (retrieve by primary key). (The naming structure can be overridden based on your preferences.) Beyond CRUD, you can craft your own retrieval procedures that may map to existing class layouts - or identify completely new formats. The sample app and test cases are good places to start in understanding what's possible!
In fact, the sample WPF app demonstrates some functionality you won't find in the automated tests. For example, UI data binding is illustrated here:
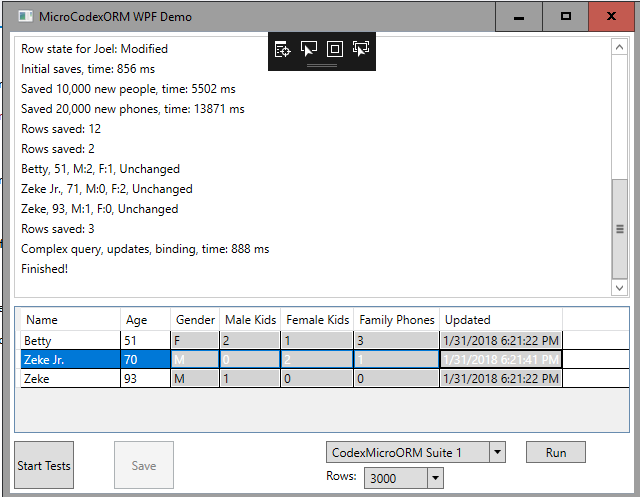
Once you've clicked on "Start Tests" and some data has been created in the database, you're able to maintain these "people" records showing in the grid: try updating a name or age and click Save. You should see the Last Updated Date column change values, and the save button itself should be enabled/disabled based on the "dirty state" (and registered validations) of the form - something that CEF makes easy using this type of pattern:
// A database retrieval using a stored procedure of arbitrary complexity, returning fundamentally "Person" data
// (some elements are computed, not stored) - which can be bound to a grid, edited, and saved...
var families = new EntitySet<Person>().DBRetrieveSummaryForParents(20);
_bindableFamilies = families.AsDynamicBindable(); // a WPF-friendly wrapper
_bindableFamilies.RowPropertyChanged += BindableFamilies_RowPropertyChanged; // Get notified about dirty state changes
Data1.ItemsSource = _bindableFamilies;
...
private void BindableFamilies_RowPropertyChanged(object sender, System.ComponentModel.PropertyChangedEventArgs e)
{
Save.IsEnabled = _bindableFamilies.IsValid; // Leverage IDataErrorInfo on all items in grid
}
private void Save_Click(object sender, RoutedEventArgs e)
{
try
{
CEF.DBSave(new DBSaveSettings() { MaxDegreeOfParallelism = 1 });
Save.IsEnabled = false;
...It's important to acknowledge what's going on here: your existing POCO may not implement INotifyPropertyChanged or IDataErrorInfo, but CEF offers it silently in a way that makes data binding easy - something not overly easy in many other frameworks. Furthermore, as of 0.2.4 we've included data validation which WPF is aware of through IDataErrorInfo. For example, the demo app has added a static validation for a person's Age:
ValidationService.RegisterCustomValidation((Person p) =>
{
if (p.Age < 0 || p.Age > 120)
{
return "Age must be between 0 and 120.";
}
return null;
}, nameof(Person.Age));Now if we enter an invalid age, the grid can easily be made to present the situation as an error:
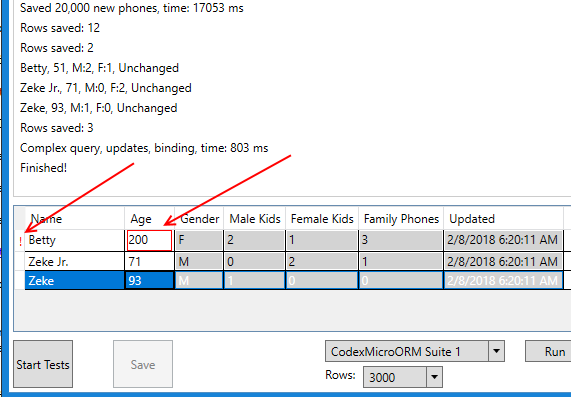
Also - keep an eye out for CodexMicroORM.OODB. This will be a NoSQL offering (in reality, more HybirdSQL) that plays nicely with CEF, offering an ultra-optimized in-memory object-oriented database with variable levels of ACID support. The idea here would be to eliminate the need for ORM altogether - there's no "relational" model to map your object model to! We'd be cutting down on architectural layers (including the entire TCP/IP stack for talking to your database - this is envisioned as an in-process database where you simply add a NETStandard2 NuGet package and voila: you've got persistence for your objects virtually anywhere!). (If you're watching our caching module, you're seeing some clues on our direction.)
I've included both a sample app (WPF) and a test project. The sample app illustrates UI data binding with framework support, along with a series of scenarios that both exercise and illustrate. We can see for example with this class:
public class Person
{
public int PersonID { get; set; }
public string Name { get; set; }
public int Age { get; set; }
public string Gender { get; set; }
public IList<Person> Kids { get; set; }
..."Kids" is an object model concept where in the database this is implemented through a ParentPersonID self-reference on the Person table. We should be able to do this:
sally.Kids.Remove(zella);
CEF.DBSave();... and expect that Zella's ParentPersonID will be nullified when it's saved by the call to DBSave(). Most of this magic happens because we've established key relationships early in the app life-cycle:
// Establish primary keys based on types (notice for Phone we don't care about the PhoneID in the object model - do in the database but mCEF handles that!)
KeyService.RegisterKey<Person>(nameof(Person.PersonID));
KeyService.RegisterKey<Phone>("PhoneID");
// Establish all the relationships we know about via database and/or object model
KeyService.RegisterRelationship<Person>(TypeChildRelationship.Create<Person>("ParentPersonID").MapsToChildProperty(nameof(Person.Kids)));
KeyService.RegisterRelationship<Person>(TypeChildRelationship.Create<Phone>().MapsToParentProperty(nameof(Phone.Owner)).MapsToChildProperty(nameof(Person.Phones)));This code is something that we can ideally eventually generate, as opposed to writing it by hand. Update (as of approximately 8/1/18): XS Tool Suite will be generally available and includes templates that support generation of C# code from existing databases, including the ability to decorate generated code with keys, relationships, defaults, and more - along with strongly-typed stored procedure wrappers and enumerations. All of that can be "applied" with one line of code: AttributeInitializer.Apply(). I'll be providing more details on this in an up-coming blog post. (The current release (0.7.3) of CEF is needed to take advantage of these new templates.)
In terms of the SQL to support these examples: a .sql script is included in both the test and demo projects. This script will create a new database called CodexMicroORMTest that includes all the necessary schema objects to support the examples. You may need to adjust the DB_SERVER constant to match your own SQL Server instance name.
The SQL that's included is a combination of hand-written stored procedures and code generated objects, including procedures (CRUD) and triggers. The code generator I've used is XS Tool Suite, but you can use whatever tool you like. The generated SQL is based on declarative settings that identify: a) what type of optimistic concurrency you need (if any), b) what kind of audit history you need (if any).
Of note, the audit history template used here has an advantage over temporal tables found in SQL 2016: you can identify who deleted records, which (unfortunately) can be quite useful! CodexMicroORM plays well with the data layer, providing support for LastUpdatedBy, LastUpdatedDate, and IsDeleted (logical delete) fields in the database. Update: I've published a blog article that gets into detail on this topic of SQL data auditing.
Update: deeper tool support has arrived with XS Tool Suite 2018 Volume 1. This version includes templates that can generate your business object layer (with settings via attributes), do your SQL data audit + CRUD procedures, and more!
In release 0.2.1, I've enhanced the WPF demo to include a benchmark suite that tests CodexMicroORM, Entity Framework, nHibernate and Dapper. I selected these other frameworks on the expectation that they've "worked out the kinks" and we should be able to judge both performance and maintainability (code size).
The methodology for testing is to construct two types of test (benchmarks 1 and 2) that can be replicated in all four frameworks. Benchmark 1 involves creating new records over multiple parent-child relationships. Benchmark 2 involves loading a set of people based on some criteria, updating them and saving them (and in some cases, their Phone data).
I assume the goal output for all frameworks is to populate and save object models that might end up being passed to different components for further processing. This implies we should have all system-assigned values present in memory by the time each test finishes. I also tried to implement the fastest solution possible by introducing parallelism where a) it improved performance, b) the framework allowed it without returning errors. I also chose solutions that resulted in the least possible "tweaking" - mostly out-of-the-box settings or patterns that might seem obvious to a relative framework newbie. I feel this is fair since if you're an expert in any of these frameworks, chances are you won't be comparing them: you'll be using the one you know best and are likely to self-adjust your coding style based on what you know works best. (Whether that's good or not for say maintainability - that's open for debate.)
For measuring code size and performance, I omit code that can be considered "initialization," "start-up only," and "code generated or ideally code generated." This includes virtually all of the SQL objects in our sample database, except for a couple of hand-written procedures (e.g. up_Person_SummaryForParents). I've excluded the size of up_Person_SummaryForParents from the code stats mainly because it can be considered general-purpose and usable by all frameworks, if needed. (For the record, it's 838 characters.)
Here are execution times, per row, for the various frameworks:
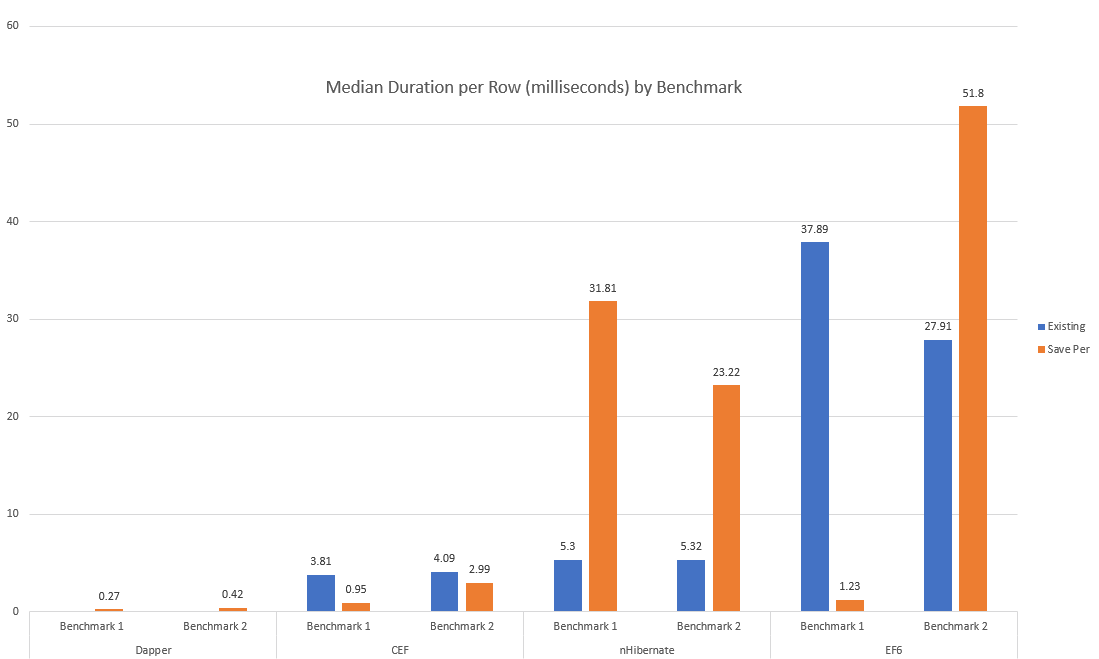
These numbers combine two tests: one with 3000 rows and one with 6000 rows. "Existing" is the case where we take an existing, pre-populated object model and try to save it, in its entirety, based on the ORM's ability to understand whether rows are added, modified or deleted. "Save Per" is a modified version where we end with the same set of rows in the database, but we're committing changes "per parent entity." I had originally intended to just test "existing" but it became evident that there's a substantial difference in the styles between frameworks. (You can use this to inform how to use these frameworks and get some understanding of their inner workings.)
Here are execution times, split based on whether we try to save 3000 or 6000 initial parent entity rows:
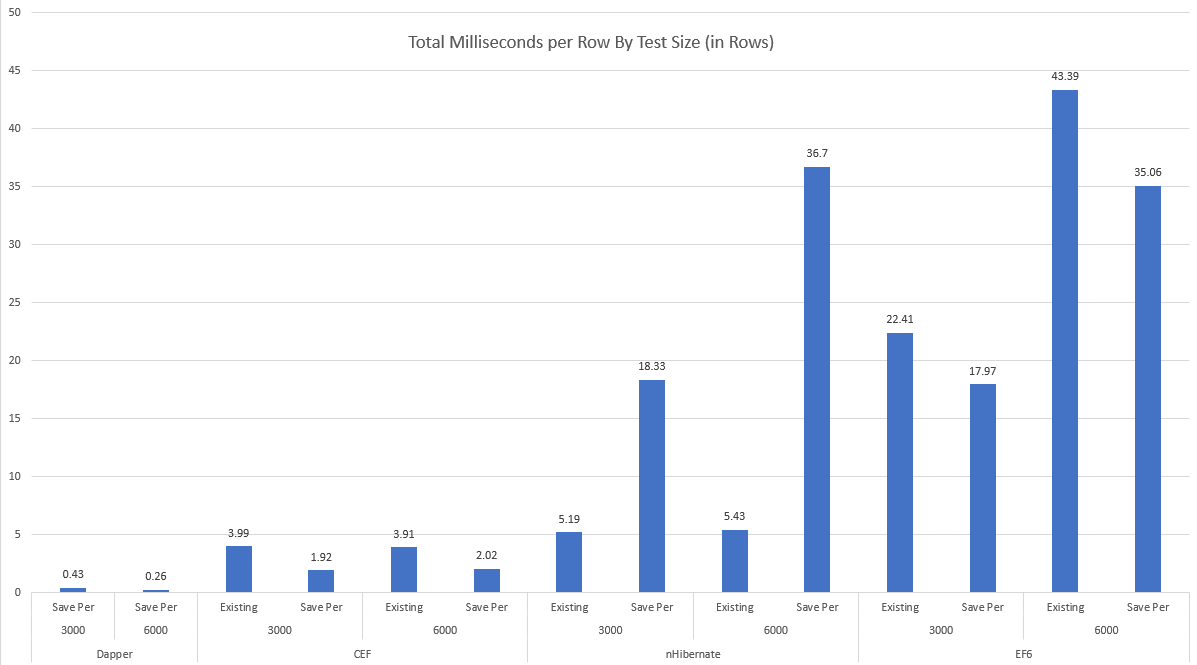
Frameworks that don't keep their performance characteristic steady when increasing the data set size are non-linear - performance is worse than O(n).
Another metric is how much code we need to write to implement the scenario, shown here:
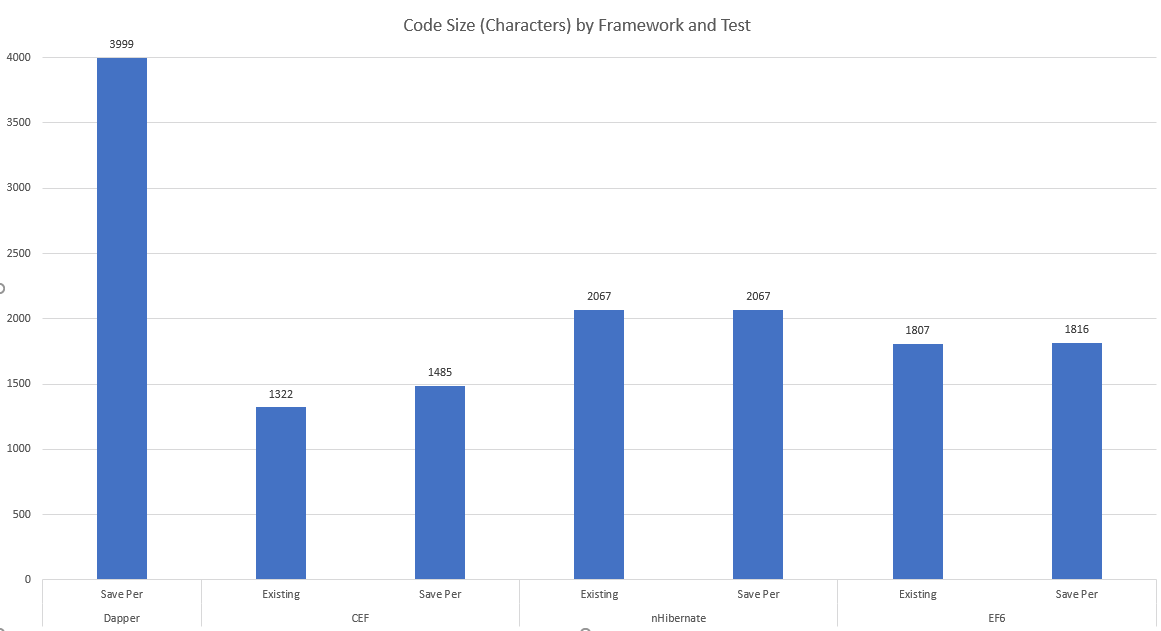
The higher the character count, the more code that was needed - a logical assumption is the complexity is higher and the maintainability is lower.
Raw performance data is available here.
The biggest concern I have with the EF results is that they're non-linear. Compare performance per row between the 3000 and 6000 row cases: the 6000 row case has nearly doubled the per row time, regardless of approach! This is not a good story for scalability.
The EF appologist might say: "you shouldn't be using it in the way you're testing it here - it's not intended for that, use a different choice like Dapper if you need extreme performance or are dealing with many rows." I'd respond by saying the purpose of the comparison is to see if there does exist a general-purpose ORM framework that has linear performance in what amounts to randomly selected scenarios. Dapper succeeds (but as I discuss below, it has its own down-sides), and so does CodexMicroORM - but both EF and nHibernate fail the test in at least one scenario.
I'm willing to be told "but you could have done things differently with framework X and it would have given much better results" - but again, the most obvious approach should be measured since if we require "deep knowledge" of the framework, chances are good we'll be cutting "bad code" for a while, until we've learned its ins-and-outs. If we could achieve good results with intuition, that would be ideal, of course.
Generally speaking, EF is not thread-safe and trying to introduce Parallel operations resulted in various errors such as "The underlying provider failed on Open" and "Object reference not set to an instance of an object", deep within the framework. There was also an example of needing some "black box knowledge" where I had to apply a .ToList() on an enumerator, otherwise it would result in an obscure error. I'm not a fan of this "it doesn't just work," although we could argue it's a minor inconvenience and most frameworks have some level of "black magic" required.
We might give extra marks to EF6 in its ability to properly interpret our LINQ expression in Benchmark 2 and thereby avoid use of the general-purpose stored procedure, up_Person_SummaryForParents. However, we might not always be so lucky: using procedures will make sense in situations where we need to use temp tables or use other SQL coding constructs to squeeze out good performance.
It might surprise you that I'm not opposed to using EF to get nice advantages such as lazy loading. CEF is light-weight and can interop with really any other framework since it's simply about wrappers and services for existing objects. So imagine being able to helicopter-drop it in (as easy as adding a NuGet package!) to solve problems where other frameworks start to feel pain: that's supported today.
Let's face it: nHibernate must deal in stylized objects, not necessarily true POCO that might pre-exist in your apps. The clearest evidence is the fact all properties must be virtual - you may or may not have implemented your existing POCO's with that trait. The counter-argument could be "but you're requiring CEF objects expose collections using interfaces such as ICollection instead of concrete types." My counter-counter argument would be, "there's no strict requirement here - but you do lose some framework 'goodness' and may need to do more 'work' to get your desired results," and "it's a common and generally good design pattern to expose things like collections using interfaces so you can hide the implementation details."
Something you might notice in the code is the nHibernate solution includes quite a bit of set-up code. I chose to use the Fluent nHibernate API, but the XML approach would have resulted in quite a bit of configuration as well. I also spent a bit of time trying to understand the ins-and-outs of the correct way to do the self-referencing relationship on Person, and borrowed the generated EF classes which match the database structure completely.
On the performance side, nHibernate scales linearly with the "save existing object model" scenario - but it does not for the "save per parent entity" case. (This would also match a case where we chose to use database transactions to commit per parent entity.) Like EF, parallelism was not kind to nHibernate and I had to avoid it generally. Another minor consideration is the fact as of today (12/31/17), nHibernate does not support NetStandard 2.0.
It became evident as I tried to implement the Dapper solution that it's not really the same style or purpose as the other ORM tools. I'd call it more of a "data access helper library" instead. Unlike the other frameworks tested, it does not track row state: it's up to you as the developer to know when to apply insert, update or delete operations against the database. This helps it achieve its excellent performance, but it's just a thin wrapper for raw ADO.Net calls.
Because of this, I didn't attempt a "populate and save all" version of tests for Dapper: it only really made sense to do the "save per parent entity" method. If we constructed a way to do a generalized "save" using Dapper, chances are good we'd lose the extreme performance benefits since we'd be applying the principles that make other frameworks slower.
Dapper although the clear winner on performance was the clear loser on code size / maintainability. Anecdotally, I also had more run-time errors to debug than other framework examples since there's no strong typing. Similarly, changes in the database schema are more likely to cause run-time errors for the same reason: no strong typing we could tie back to code generation. (Although I'm sure if I looked hard enough, someone has created templates to act as wrappers for database objects.) This in turn speaks to its nature, much as EF and nHibernate, being more highly-coupled with your database than you might want to believe (e.g. requiring ID's to support relationships, etc.).
CEF offers linear performance results and has among the smallest, most succinct code implementations. It's worth noting that you can use EF-generated classes, if you like, with CEF.
I did an extra test for CEF that I did not include for other frameworks - because it's somewhat unique to CEF out-of-the-box - the ability to save added data using BULK INSERT. That case for Benchmark 1 yielded a median time of 0.9 ms/row (both 3000 and 6000 row runs). This is the fastest way to "save an existing, full object graph" among all tests. The trade-off? You don't get PhoneID's assigned in memory at the end of saving.
Am I claiming that CEF is "perfect"? Certainly not: this is version 0.2.1 - but I'm quite confident it's positioned well to offer O(n) performance based on data set size. If you discover something slow, let me know!
Finally, I wanted to verify that CEF has no memory leaks as part of the demo program. I did this using a memory monitoring tool, issuing a snapshot / garbage collect after all CEF tests were complete:
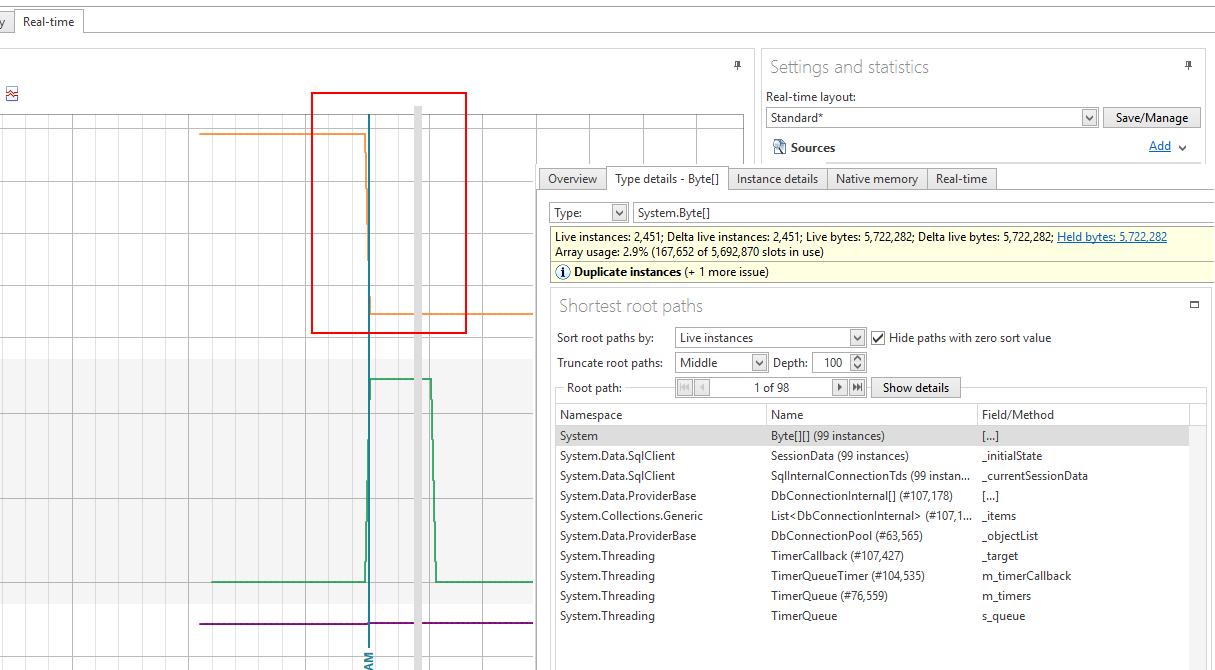
The orange line is allocated memory - within the context of the red box, this is where a collect had been issued and the orange line has dropped to near-zero. The Type Details shows us what's the largest "left over" allocated objects: mainly ADO.Net static data that we have no control over.
- Entity Framework and nHibernate forced me to adopt class structures that match the database more closely than my original POCO's do. For example, my "Phone" POCO has no PhoneID, nor should it really require it from an object model perspective: it's a storage construct (an important one, yes, but strictly speaking, it should not be forced on our object model, if we don't want it).
- Entity Framework and nHibernate both had at least one non-linear performance scenario.
- Dapper, although very fast, provided the most verbose implementation by a factor of 2x-3x.
- None of the frameworks tested (other than CodexMicroORM) natively understand the concept of "last updated by", "last updated date" fields as standardized audit fields. This results in more repetitive code.
- The pattern of "saving while populating" seems to work better than "save everything at the end" with some frameworks - but this may or may not align with your needs in each situation. For example, you may be populating an object model, passing it around, and saving it after some additional work - this would not align with "save as populate" and if we're looking for the best generalized solution, ideally it balances performance while offering different options to solve your problems.
- This demo is very simplistic. If we asked all the reviewed frameworks to do more - for example do "dirty state tracking" - we'd be going beyond performance (important but not always critical!) and looking at how the design goals of each framework are able to make you more productive. I'm confident CEF offers a compelling story when it comes to productivity! (Challenge me with suggestions @ [email protected].)
As of version 0.2.3, I've introduced a new feature that makes a big enough difference for performance that in a new benchmark, CEF beats Dapper performance by 45%! This feature is asynchronous saving and can be enabled globally:
Globals.UseAsyncSave = true;... or at a service scope level:
using (CEF.NewServiceScope(new ServiceScopeSettings() { UseAsyncSave = true }))
{... or on an individual request level:
someItem.DBSave(new DBSaveSettings() { UseAsyncSave = true });I've added a new benchmark test in the WPF demo app, implemented for both Dapper and CEF:
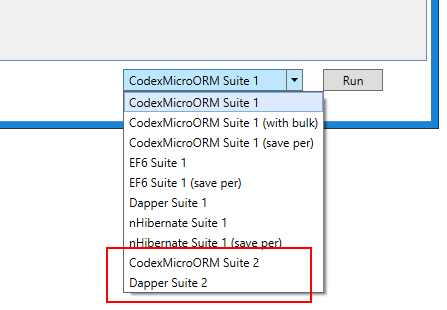
(I stuck with just these two frameworks since it's clear from the prior testing that nHibernate and Entity Framework aren't remotely competitive in terms of performance.)
The nature of this new benchmark is to work with a pre-populated set of database records, retrieving data in a loop and making a couple of updates in the process. We've also split some of the functionality into multiple methods where the parameters are restricted to ID values, like we might see in a theoretical library / API. The final results for both CEF and Dapper are verified in the database at the end. Of note:
- The Dapper implementation uses the same stored procedures that the CEF example uses to help be more apples-to-apples.
- In the Dapper implementation, I had to do some trickery to make the Person update procedure call work:
int? ppid = parent.ParentPersonID;
string gender = parent.Gender;
db.Execute("CEFTest.up_Person_u", new { RetVal = 1, Msg = "", parent.PersonID, parent.Name, parent.Age, ParentPersonID = ppid, Gender = gender, parent.LastUpdatedBy, parent.LastUpdatedDate }, commandType: CommandType.StoredProcedure);Doing the Execute() with in-line use of parent.ParentPersonID and parent.Gender results in run-time errors, and the simplest, most desirable approach of simply using "parent" as the second parameter does not work, either.
The final performance result is that Dapper's per-database-call timing averages 0.47 milliseconds, whereas CEF is 0.34 milliseconds - nearly 30% faster than Dapper. In terms of code size, CEF's implementation is 1618 characters compared to Dapper's 2629 characters - meaning CEF in this example offers a 30% performance gain with nearly 40% less code to write and maintain! Now, there are ways to achieve similar results using Dapper - by writing even more code.
CEF's implementation of async saving leverages a combination of in-memory caching and parallel operations that we can synchronize on as needed. (In fact, leaving your current connection or service scope ensures all outstanding async operations will be complete.) The use of the new MemoryFileSystemBacked caching service is something I'll cover in a future blog post, but in this particular benchmark, async saving was the clear way to "win" against Dapper.
It's also worth noting that with 0.2.3, some of the performance figures were lowered due to performance tweaks - but in 0.2.4, we gave back some performance with the addition of important new features. These types of changes will happen natually and I'm not going to redo performance comparisons after every release. (I didn't do a perfect job when evaluating the other frameworks, too, giving them a pass in some respects - e.g. did not round-trip all values, which would have increased the code size in cases).
Some may say, "benchmarks can be made to prove anything you want" - which is true, but quantitative analysis offers at least something objective, where measuring things like "features and style" is much more personal. Suffice it to say that offering great performance and advanced services is a goal and look for more goodies in up-coming releases!
I suggest doing a clone to grab the full code base. The test project has a number of important use cases, illustrating capability. The WPF demo project includes performance benchmarking, but also shows general concepts, contrasts patterns with other frameworks, and illustrates live WPF data binding.
You can include CEF in your own projects using NuGet: NuGet - Core, Nuget - Bindings.
I'll be providing further updates both here and on my site. Registering on xskrape.com has the added benefit of getting you email notifications when I release new blog articles that provide deep dives into the concepts you see here.
On-line documentation will become available, with your feedback and encouragement. In the meantime, many of the concepts will be covered through blog articles. Also, click "Watch" above to keep track of updates made here on GitHub.
Want to see even more? Share, watch, clone, blog, post links to this project - and mention it to your friends! Contribution and development is proportional to community interest! This framework will be a drop-in replacement for my "old" framework in many projects (templates to come), so will receive increasing production attention.
- 0.2.0 - December 2017 - Initial Release (binaries available on NuGet - Core, Nuget - Bindings)
- 0.2.1 - December 2017
- remove all use of Reflection GetValue/SetValue (performance)
- "preferred type" detection on retrieval
- optional GetLastUpdatedBy delegate on session scope settings
- "performance and memory fixes"
- initial benchmarks
- other minor adjustments
- 0.2.2 - January 2018
- Serialization - supports multiple serialization modes including serialization of "just changes" (has importance for over-the-wire scenarios); new test added to demonstrate serailization (SerializeDeserializeSave); watch for a blog I'll be using to cover more details about serialization and other topics
- Added support for "Shadow property values" - this is more of an advanced topic where we can leverage these to avoid updating your POCO objects with "system-assigned temporary keys" yet still retain identity like we do in earlier releases. In short, you might not care about this a lot but there could be some interesting "other applications."
- 0.2.3 - January 2018
- Async saving - easily enabled for situations that do not require immediate round-tripping of values assigned by the database, offers significant performance benefits (see above for some tangible benchmarks).
- Caching - default caching service is MemoryFileSystemBacked; offers performance benefits in a number of scenarios including mitigating slow connections. New illustrative test: MemFileCacheRetrieves. More examples will be made available in future articles.
- internal refactoring - removal of many static methods used in services in favor of interfaces that enable full "pluggability" for anyone wanting to write their own replacement service.
- 0.2.4 - February 2018
- 1:1, 1:0 mapping support, including sample database updates to illustrate ("Widget" tables) - search for RegisterPropertyGroup, RegisterOnSaveParentSave - significantly more complex object models supported as illustrated in new test (NewWidgetNewReceiptNewShipment)
- Validation service - support for required field, length validations, illegal updates, custom validations, exposure of IDataErrorInfo (showing how works with WPF data binding in demo app as well) - search for RegisterRequired, RegisterMaxLength, RegisterIllegalUpdate, RegisterCustomValidation
- Field mapper service - supports differences of OM names and storage names - search for RegisterStorageFieldName, RegisterStorageEntityName
- Defaults, schema support - search for RegisterDefault, RegisterSchema
- "Case insensitive" option for properties
- Fixes related to serialization, async save, etc.
- Testing enhancements (sandboxes, more coverage)
- 0.5.0 - March 2018
- Minor changes (e.g. access modifiers) to support the soon-to-be-released version 0.9 of ZableDB
- Internal refactoring to improve memory footprint and performance - SIGNIFICANT! - What's new in 0.5?
- 0.5.5 - April 2018
- Performance improvements, documented in a C# Corner article
- 0.6.0 - April 2018
- A number of improvements driven by ZableDB development. Details to follow in site article
- 0.6.3 - April 2018
- Updates to support C# Corner article
- 0.6.4 - May 2018
- Minor fixes, deeper support for ZableDB
- 0.6.5 - May 2018
- Addition of ResolveForArbitraryLoadOrder global setting, slight refactoring for support of ZableDB
- 0.7.0 - June 2018
- Transaction scope improvements, ICEFStorageNaming/EntityPersistedName added, DBExecuteNoResult added, LastOutputVariables added to connection scope, added DeepCopyDataView, added GetAllPreferredTypes
- Inclusion of some features of CodeXFramework V1 such as ValidateOrAssignMandatoryValue functionality (extension methods), new assembly to support v1 compatibility (CodexMicroORM.CodexV1CompatLayer)
- New XS Tool Suite templates to support code generation of entities / wrappers for CEF
- AttributeInitializer.Apply() to leverage generated code (when using attributes) to register keys, relationships, etc. with a single line of code on startup
- Minor fixes
- 0.7.1 - July 2018
- GenericSet in legacy compatibility assembly
- Individual command timeout override via settings
- 0.7.2 - July 2018
- Portable JSON support
- Minor enhancements (e.g. ToDictionary)
- 0.7.3 - July 2018
- Minor fixes/enhancements to support latest XS Tool Suite code-gen templates
- 0.7.4 - Aug 2018
- Minor fixes (type conversions, etc.) (FYI - the xskrape.com web site uses CEF)
- 0.8.0 - Aug 2018
- Fix related to varchar(max) handling; other fixes/refactorings in Keys service (update importance: high)
- Addition of: DeepLogger, new ObjectState (ModifiedPriority) to support DeleteCascadeAction.SetNull (implemented), ReconcileDataViewToEntitySet, UseNullForMissingValues (solves insert-save-update-save issue)
- 0.8.1 - Sep 2018
- Fix related to defaults
- 0.8.2 - Apr 2019
- Minor fixes
- 0.9.0 - May 2019
- Fixes related to Keys, Caching
- Introduced attribute-based caching specs, by type (declarative: template support)
- Support for automatic conversion of dates to/from UTC storage in DB layer (declarative: template support)
- Changed binding support project to have GenericBindableSet inherit from BindingList to offer wider reach for UI binding, and other improvements related to binding (testing done with Infragistics)
- New WinForm demo app / test harness - here
- 0.9.1 - May 2019
- Fixes, changes including use of AsyncLocal internally to support proper flow when using await
- 0.9.2 - August 2019
- Add: DoNotSave attribute (including template support for nested property classes), CheckDirtyItemsForRealChanges, GlobalRowActionPreview
- Minor enhancements (e.g. returning instance from Add)
- Changes: when adding to scopes, check for existence (slower but better behavior)
- Fixes: light-weight locks (race condition fix), FastCreateNoParm
- 0.9.3 - Sept 2019
- Fixes: connection scope issues
- 0.9.7 - Apr 2020
- Use netstandard2.1
- Fixes: needed to be using immutablestack for service/connection scope tracking (this is considered a critical update)
- Add: save triggers, additional helper (extension) methods, GlobalPropertiesExcludedFromDirtyCheck (Globals), DoCopyParseProperties (Globals), auto-retry logic for some operations, short supported as a key type
- Changes: SaveRows changes to improve performance & address some edge cases related to update order, DBService (and others) use Create factory vs constructor now, most exceptions exposed using CEFInvalidStateException (supporting centralized messaging)
- Introduction of nullable reference type syntax, along with elimination of warnings related to this
- Note: change in entity and procedure wrappers templates to support null reference types and improve beahvior over multiple service scopes
- Note: the BindingSupport package has been removed for now - net472 and netstandard21 do not play together and I'm not doing any non-netstandard work currently so I consider it low priority to address
- 0.9.8 - Dec 2020
- Add: RetrieveAppendChecksExisting on ServiceScope (default true, when true checks EntitySet when doing an append for an existing object with same key as being loaded - if found, skips)
- Add: CopySharedToNullifyEmptyStrings
- Add: DeepReset added to IDBProviderConnection
- Change: IsSame checks for DBNull.Value
- Fix: MSSQLConnection.IsWorking
- Add: MSSQLProcBasedProvider - various monitoring props such as DatabaseTime, DelayedTime; built-in retry logic for certain failure types (found connecting to Azure SQL)
- Change: MSSQLProcBasedProvider - Ignoring SaveRetryCount for a transactional save
- Change: DBService, added public parameterless constructor
- 0.9.9 - May 2021
- Fix: Appending to set issue with change notification fixed, other minor fixes based on issues found
- Change: Nullable ref and various warnings fixed (clean-up)
- Change: Switch to Microsoft.Data.SqlClient from System.Data.SqlClient
- Add: MustInfraWrap, ScopeLevelCache, ReconcileModifiedIgnoresValueBag
- Change: Use of more pattern matching and addressing suggestions
- Change: "all" caching supports ForList in name
- 0.9.10 - June 2021
- Add: DateOnly data type to match SQL "date" type; largely interchangeable with DateTime and addresses date conversion issues with UTC; template support added (optional, default continues to use DateTime)
- Add: Debug features available to those running from source (eg DebugStopTypeNamesWithChanges)
- Add: FlushAll (caching); Sequential/ParallelAsync helper extensions; TypeFixup
- Add: Added canUseBag param to ICEFInfraWrapper.SetValue (and require audit fields, if any, to not be bag props)
- Fix: Caching improperly handled empty collections
- Change: SetInitialProps suppresses firing prop changed as this is considered setup only
- Change: properties starting with ~ are ignored for dirty check (used internally by ZDB)
- Change: improvements in CoerceObjectType (formerly CoerceDBNullableType)
- Change: GetRowState accepts flag for ignoring extended/bag prop changes and default behavior on save is to ignore these properties for dirtiness (see: ConsiderBagPropertiesOnSave)
- Change: some stylistic changes based on warnings/suggestions
- 0.9.11 - July 2021
- Add: AddRange to EntitySet
- Add/Change: Adjustments to conversion and json serialization for DateOnly
- Fix: rare error in MSSQLCommand about trying to use a closed connection (noticed with Azure SQL)
- Change: multitarget net461 and netstandard 2.0 (for increased reach, very minor changes to accomodate, nothing is platform-specific) See for rationale.
- Add: XS Tool Suite template adjustments to include static factory methods to simplify object creation. For example what was previously 3 lines:
var ingset = new IngredientSet();
await ingset.RetrieveByKeyAsync(ingredientID);
var ing = ingset.FirstOrDefault() ?? throw new InvalidOperationException("Could not find ingredient by ID.");... can become 1 line:
var ing = (await IngredientSet.RetrieveByKeyAsync(ingredientID)).FirstOrDefault() ?? throw new InvalidOperationException("Could not find ingredient by ID.");- 0.9.12 - August 2021
- Add: AuditService.RegisterCanUseBagPropertyForAudit (canUseBag default of false caused some tests to fail, however default should be to assume biz objs will have audit fields, if specified/enabled)
- Change/Add: MemoryFileSystemBacked caching - removed use of BinaryFormatter in favor of System.Text.Json (security and performance and fact BinaryFormatter appears to be heading out the door eventually)
- Add: MemoryFileSystemBacked caching - add optional encryption for file-backed data (AES) (see: SetEncryptionKeySource)
- Fix: warnings and other minor cleanup
- 0.9.13 - November 2021
- Change (breaking): Rename of DateOnly type to OnlyDate. Why? .Net 6.0 introduces System.DateOnly. To help disambiguate, changing it here. All templates updated to new name. (Keeping CEF version since has certain advantages over System.DateOnly although may consider changing this in the future.)
- Add: GlobalSetActionPreview - similar to GlobalRowActionPreview but applies to entire set of rows being saved (both pre and post look)
- Add: DBSaveSettings.UserProperties - use of dictionary versus UserPayload (object) which is deprecated
- Add: RegisterPropertyNameTreatReadOnly / PropertyTreatAsIfReadOnlyAttribute - can be used with properties such as settable calculated values, mainly for the persistence layer to avoid (since could be computed) - use case: plain-text version of an encrypted field
- Add: CEF.SignalAppSleep/Resume - use case for mobile apps where when suspended, do not count against timeout intervals
- Add: CEF.DataAccessCallout - use case is checking MainThread.IsMainThread to do a hard stop during debugging to identify places inadvertently doing data access on a UI thread
- Add: Implement ISerializable on EntitySet and other serialization cleanup - important for debugging visualizer tooling
- Improvement: Null checking on Parallel/Sequential extension methods and other internal enhancements
- Change: Internal use of DateTime.Now changed to DateTime.UtcNow (should not have effects outside of framework)
- Change: small tweaks such as SequentialAsync ensuring work done on background thread, etc.
- 1.0.1 - February 2022
- Add: MSSQLCommand.DiscoverRetryCount - joins MSSQLProcBasedProvider.OpenRetryCount to support more resilient DB ops
- Change: Split all SQL Server specific dependencies out of the Core project, adding a new CodexMicroORM.SQLServer package which can be referenced, if you're using SQL Server (if you aren't, then no need to carry SQLClient baggage!). Namespaces are all preserved as they were, meaning code should not break, just need to include the additional package reference in your projects. Also had to change protection levels in certain cases to allow this refactoring to work. Depends on Microsoft.Data.SqlClient (4+).
- Change: default degree of parallelism for ParallelAsync changed to an algorithm that adapts based on workload (eg. using in multiple places makes "aware" of load over entire process)
- Change: ParallelAsync uses configureawait(false); achieve higher parallelism
- Fix: ParallelAsync could process specific item twice
- Fix: handle scenario of updating parent ID on child record to point at a new parent (previously could get FK error due to update-before-insert)
- 1.0.2 - May 2022
- Fix: OnlyDate Json serialization fix
- Fix: link values fix (edge case noticed during additional properties work)
- Add: EntityAdditionalProperties attribute; supported in code gen where can use POCO "additional properties" nested classes for stored procs that extend an existing entity (and infrastructure to support this feature); this can result in a better experience dealing with these types of properties, where values are not dependent on the service scope (values can be passed outside of service scope, etc.)
- Add: FastGetAllPropertiesAsDictionary
- 1.0.3 - July 2022
- Fix: Do not allow memory cache to fail with concurrency error in Cleanup (non-critical)
- Change: dependencies update
- 1.1.0 - November 2022
- Add: ExecuteWithMaxWaitAsync, DeepCopyList, DBSaveTransactional, ReconcileEntitySetToEntitySet - some extension method goodies added, minor cleanup
- Add: IndexedSet - a highly read-efficient collection that can "auto-index" itself based on linq (to object) queries run against it. Inherits from EntitySet so can be used interchangeably to a large degree. Supports both equality and range indexes. Requires adding C5 package ref. Moved this from ZDB project (pre-release) to CEF as this can be considered core plumbing with broad applicability. More details to be included here later.
- Add: net7.0 targetting
- Fix: minor fixes (e.g. some disposal cleanup, etc.)
- 1.2.0 - June 2024
- Add: Recursive option for CEF.NewObject (making an explicit opt-in, due to performance)
- Add: Retrieve Identity settings/options, including Globals.DefaultRetrievalIdentityMode, Globals.FrameworkWarningHandler, AllowRetrievalDups (addresses where default behavior could be "surprising" when doing custom queries that return duplicates of key value for entity retrieved into)
- Add: New unit tests related to IndexedSet, retrieve identity, etc.
- Change: net8.0 targeting, cleanup related to .NET Core, various updates to dependencies (latest)
- Change: Various syntax updates to support latest C# features, unit tests cleanup (some deprecated for now, see notes in DBOps.cs, 100% pass rate)
- 1.3.0 - June 2024
- Add: PoolableItemWrapper to Core - supports any object that can be pooled (useful for scenarios where you want to avoid object creation overhead)