新闻分词系统软件是一款运行于网页端的新闻分词系统。系统可以通过机器学习,LSTM神经网络预测,在对新闻的文本进行训练后,对给定的新闻文本进行分类。比如给系统一段新闻,系统会判定这段新闻属于哪一个种类,比如科技类,时事类等。
本系统支持单条新闻标题和新闻内容的文本分类,支持xlsx和xls格式多条新闻标题和新闻内容的文本分类。
系统使用说明
步骤一 :
在NewsClassification目录下打开终端控制台,执行以下命令
cd Core
python web.py 运行效果如下为正常启动:
$ cd Core/
$ python web.py
\* Serving Flask app "web" (lazy loading)
\* Environment: production
WARNING: This is a development server. Do not use it in
a production deployment.
Use a production WSGI server instead.
\* Debug mode: off
\* Running on http://127.0.0.1:80/ (Press CTRL+C to quit)步骤二:
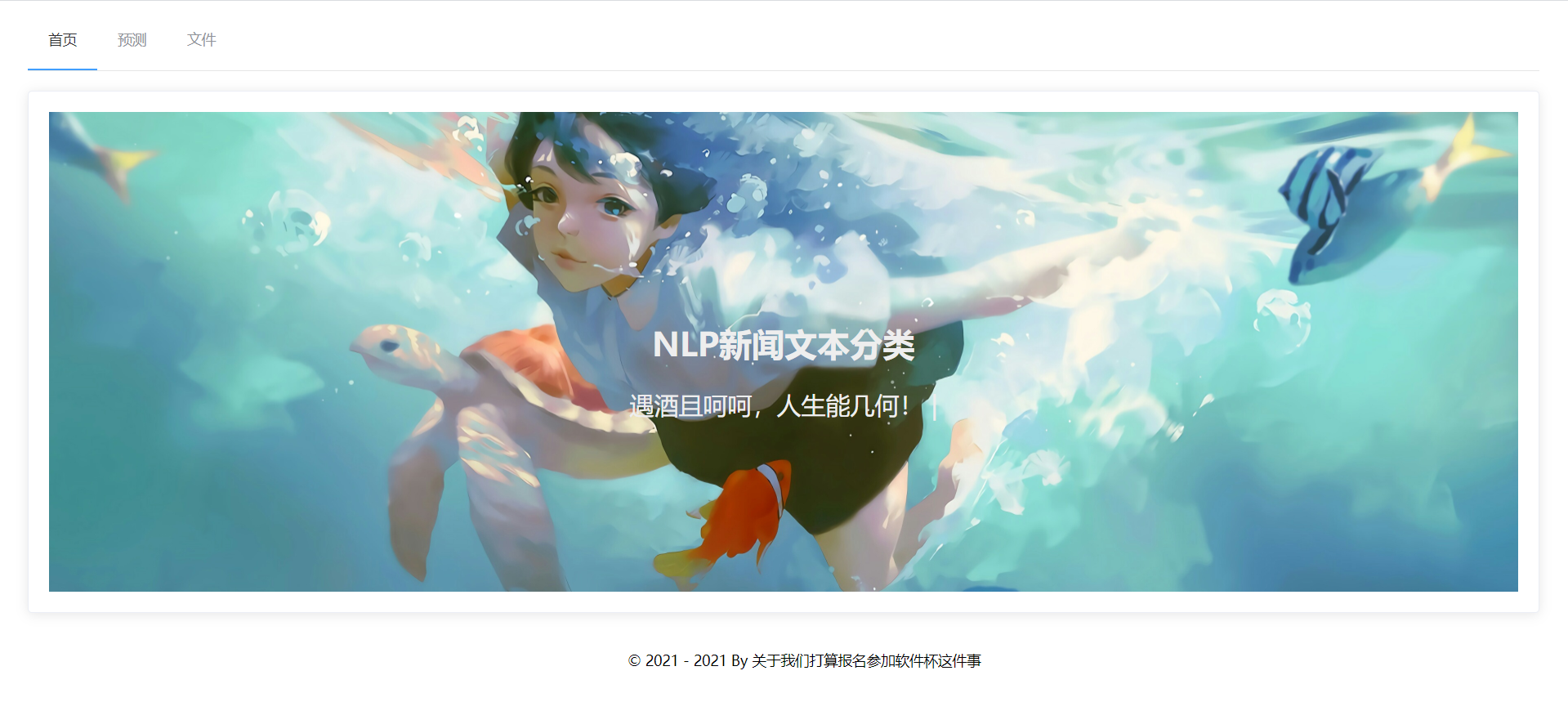
访问http://127.0.0.1:80/,显示界面如下所示:
步骤三:
在对应的预测和文本模块中,进行单条新闻文本分类预测和导入文件进行预测。如果出现问题,那么:
1)若控制台运行的时候,出现报错,一般情况是python的相关依赖缺少,在NewsClassification文件目录下执行下面命令安装相关依赖 :pip install -r requirements.txt也可以按照需求进行排查需要按照的依赖,然后用 pip install 模块名 进行安装,下面的版本是开发环境中的版本,仅供参考
xlwt==1.3.0
xlrd==1.2.0
torch==1.8.1+cpu
numpy==1.19.2
flake8==3.8.4
Flask==1.1.2
2)在web页面,若出现其它类似文字乱排列的情况,是加载问题,通过按住 ctrl+F5或者刷新页面可以解决。
3)上传文件进行处理的情况,若数据上万条数据,处理时间较长,可能会有1- 5分钟的处理时间,后台没有报错的话,这是属于正常情况。
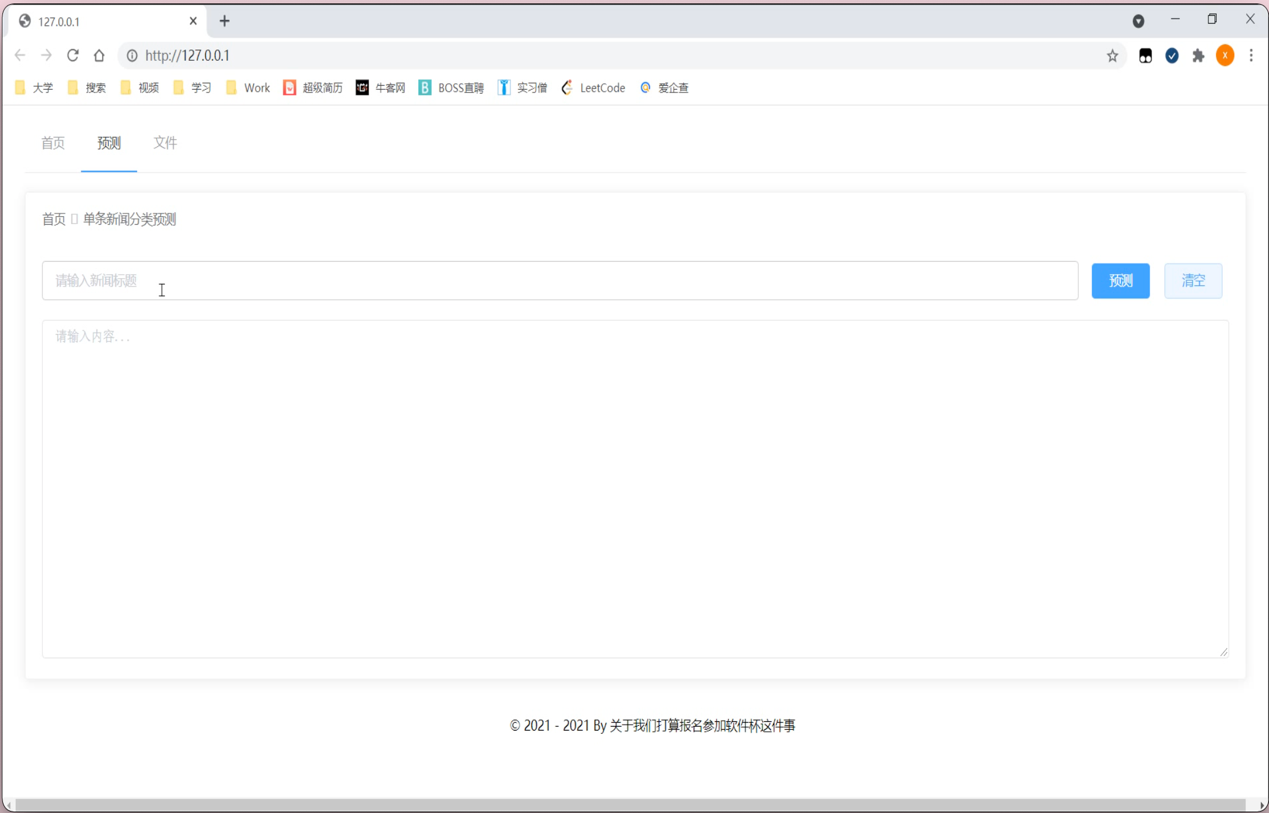
系统首页是承载了系统所有的功能模块,是系统的门面,通过首页,让用户更加直观的了解该系统的详情信息,加深用户的使用体验。使用了B/S架构,把系统假设在服务器上,通过使用网页就可以登陆系统。当前系统为最新系统,所以不需要更新升级,然后用户可以看到系统的主要菜单和主要功能,可以选取给定的文件尽心模型训练,可以选取给定的文本,让系统对这一段文本进行种类判定。可以根据实际工作需要,在界面内进行相关的操作。详情如下图所示;
如图用户可以直观的了解到发现的详细内容,并且根据实际的工作需求,在界面内进行相关的发现功能操作,节省了用户的时间,提高了用户的工作效率。点击界面内的对应按键,系统会自动弹出对应的窗口,通过点击预测按钮,详情如下图所示:
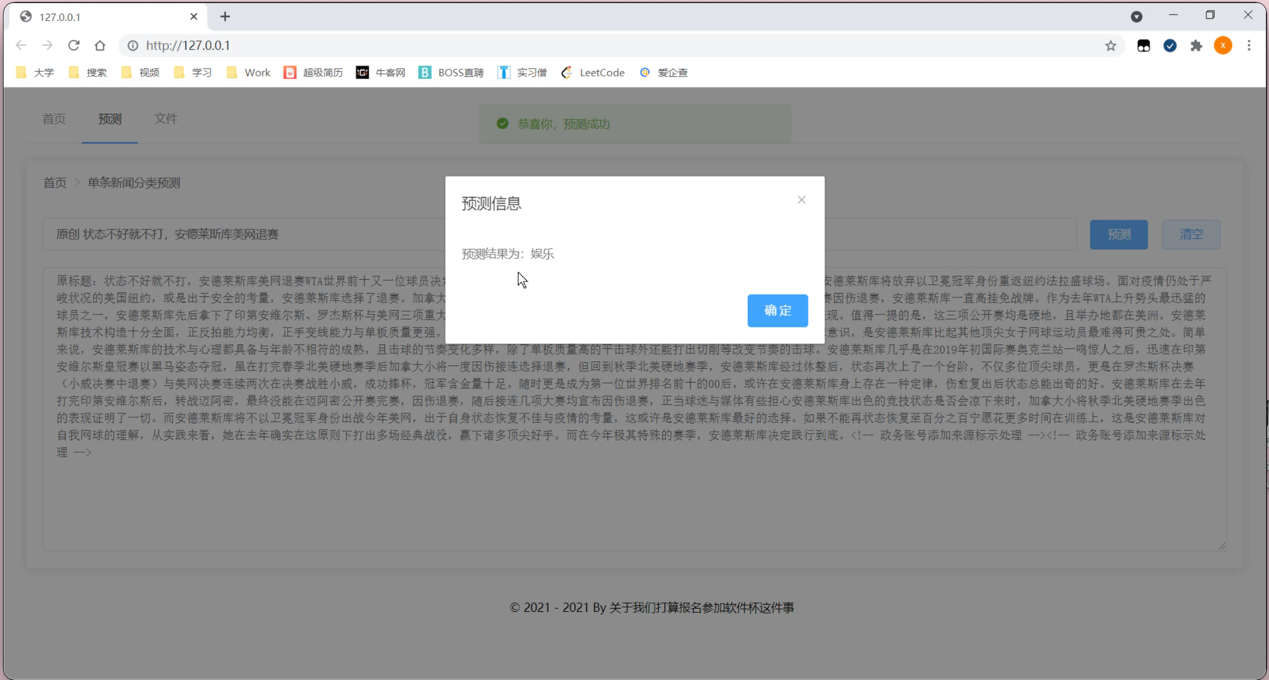
如图用户可以直观的了解到新闻预测的详细内容,并且根据实际的工作需求,在界面内进行相关的预测文本的选择操作,节省了用户的时间,提高了用户的工作效率。点击界面内的相关按键,系统会自动弹出对应的窗口,详情如下图所示:
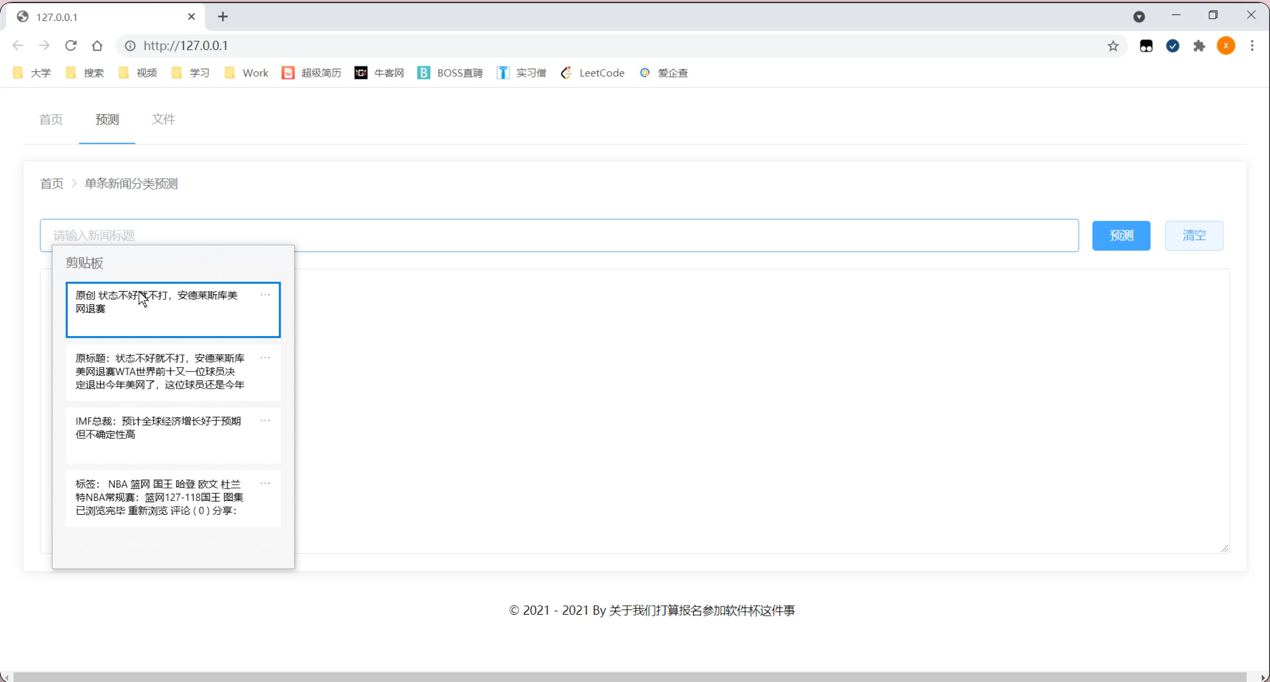
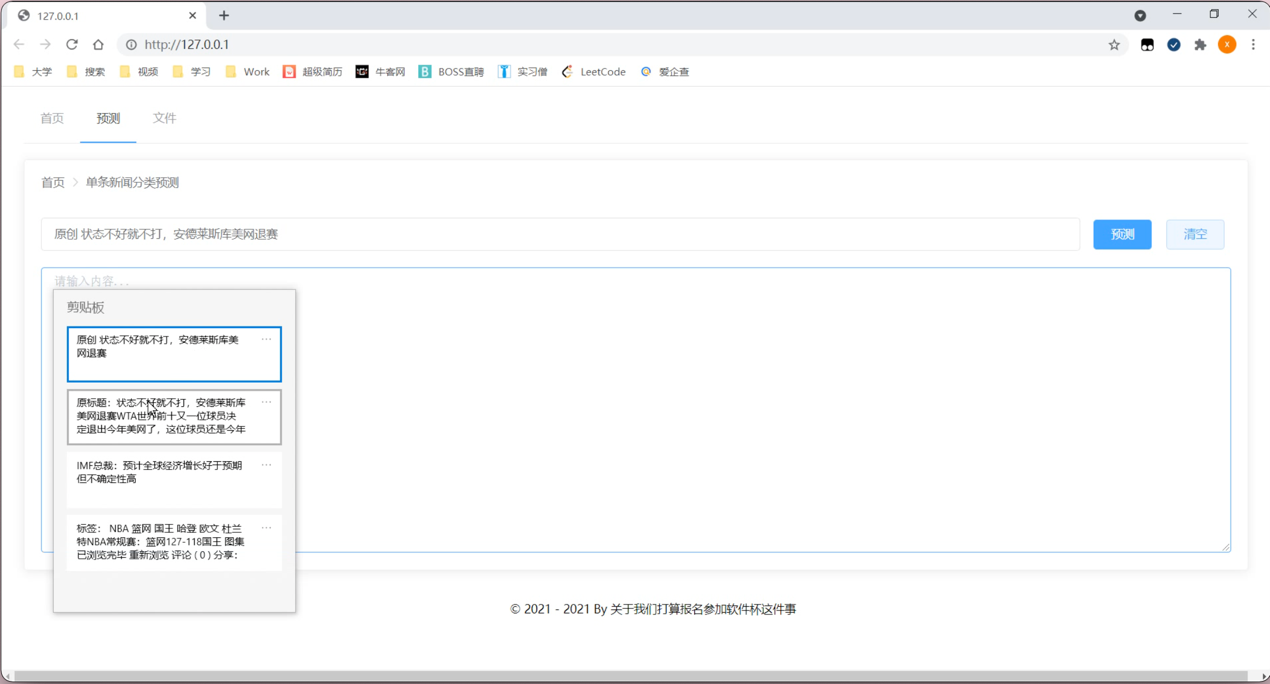
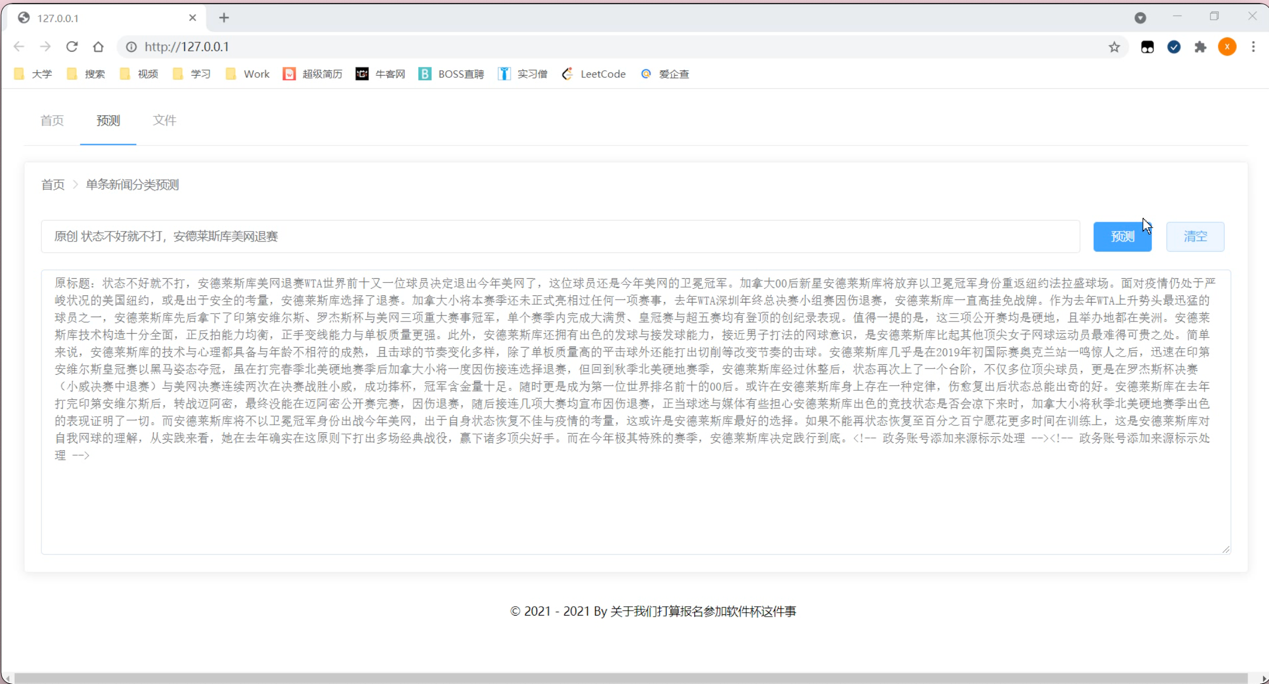
根据实际工作需求,用户能够在系统内对想要更改的内容进行清空处理。清空完成后,整个界面会回到之前的样式。能够有效的提高了用户的使用体验,节省了用户的工作时间,方便用户。根据使用系统的实际情况,点击界面内相关的按键,系统会自动弹出对应的界面,详情下图所示:
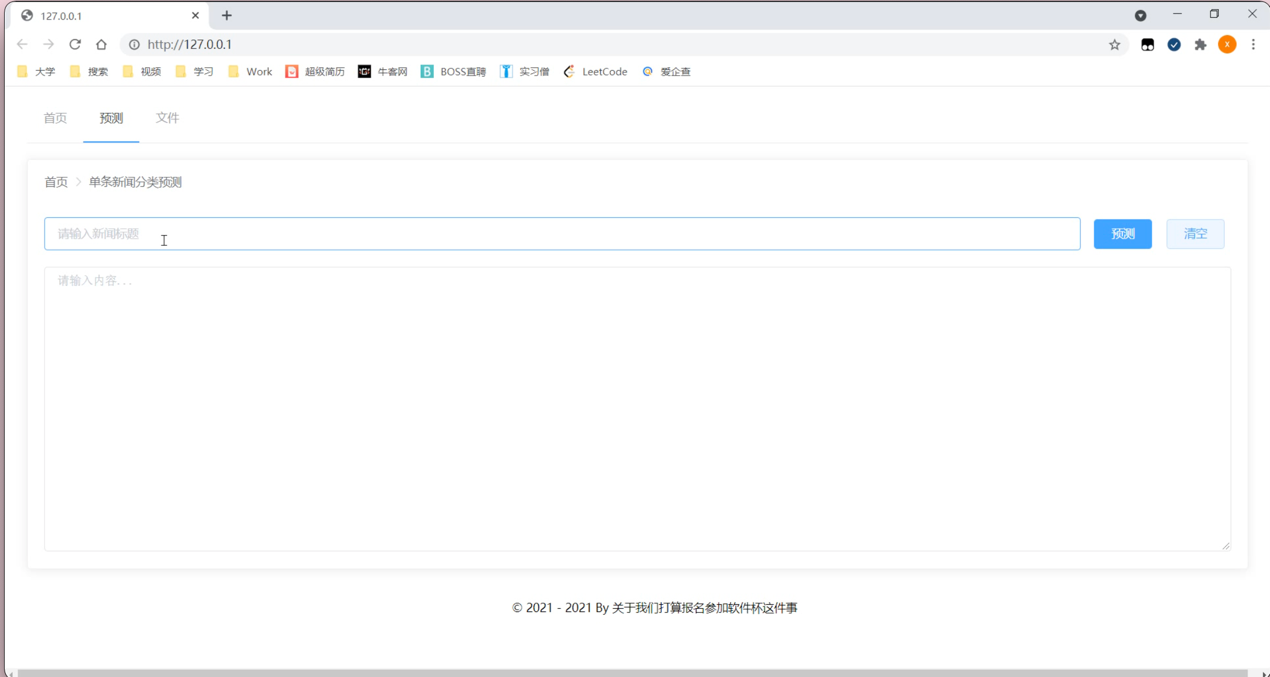
根据实际工作需求,用户能够在系统内进行选定的新闻文段的题目的选择,对系统内选定的新闻文段的内容的选择,设置完成后,能够有效的提高系统的使用率,提高了用户的使用体验,节省了用户的工作时间,根据使用系统的实际情况,点击界面内相关的按键预测,系统会自动弹出对应的界面,详情下图所示:
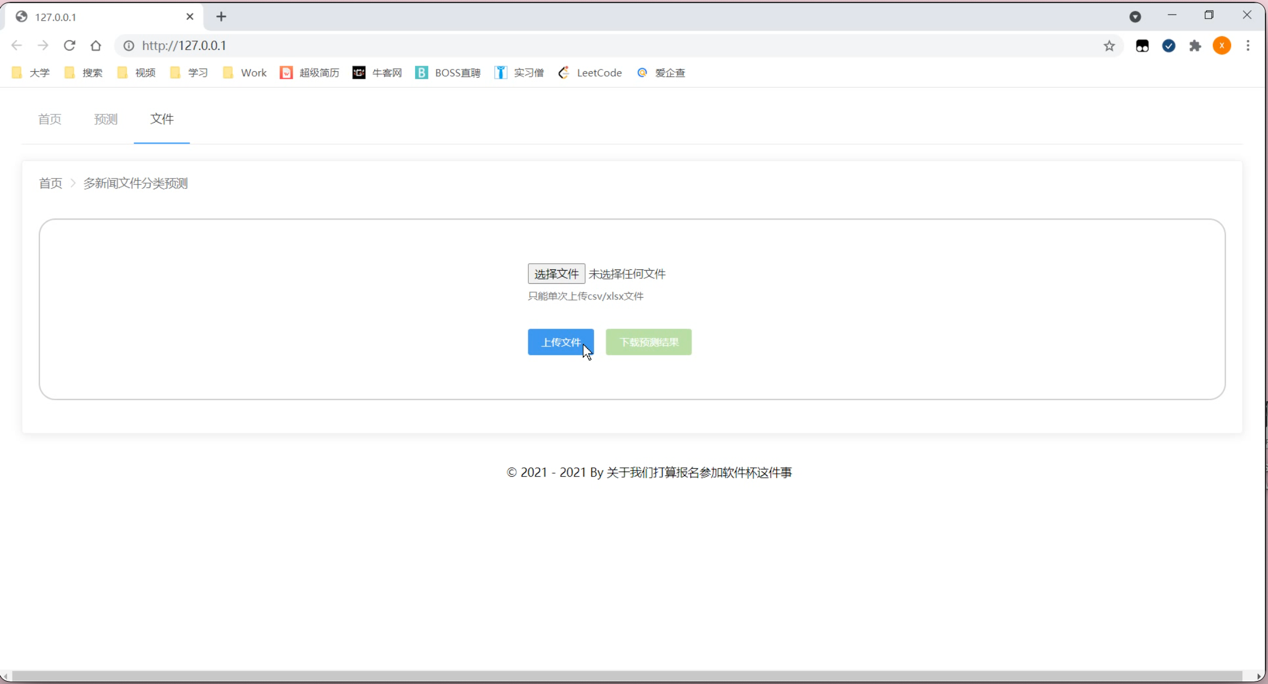
如图用户需要批量处理大量的文本,逐条复制进去并逐条查看新闻的文本文段属于什么样的分类是不可行的。这种枚举的方式获得想要进行判定的文本问段的种类,当文本的数目不多的时候是可行的,但是当文本的数目足够多的时候,显然是不可行的。所以开发了批处理功能,通过把文本集中存放在文件中,通过上传文件,对整个文件中的每一个文本进行逐一判定种类,并且根据实际的工作需求,在界面内进行相关的文件上传的可视化操作,节省了用户的时间,提高了用户的工作效率。点击界面内的对应按键,系统会自动弹出对应的窗口,详情如下图所示:
调整后的界面如下图所示:
如图用户可以在选项中批量选取一组数据,整合进入excel表格后进行上传。点击界面内的对应按键,系统会自动弹出对应的窗口,详情如下图所示:
如图用户放入对应的excel文件,进行分词处理,详情如下图所示:
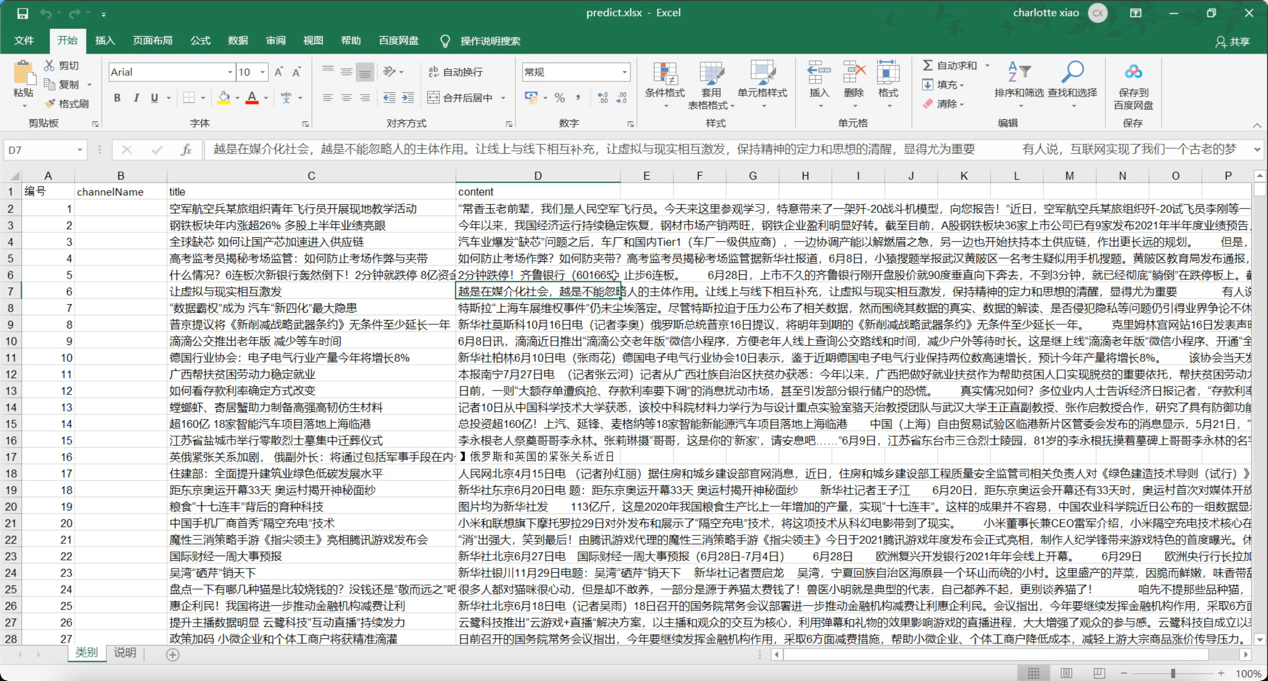
用户可以下载之前传入的文本的结果,详情如下图所示:
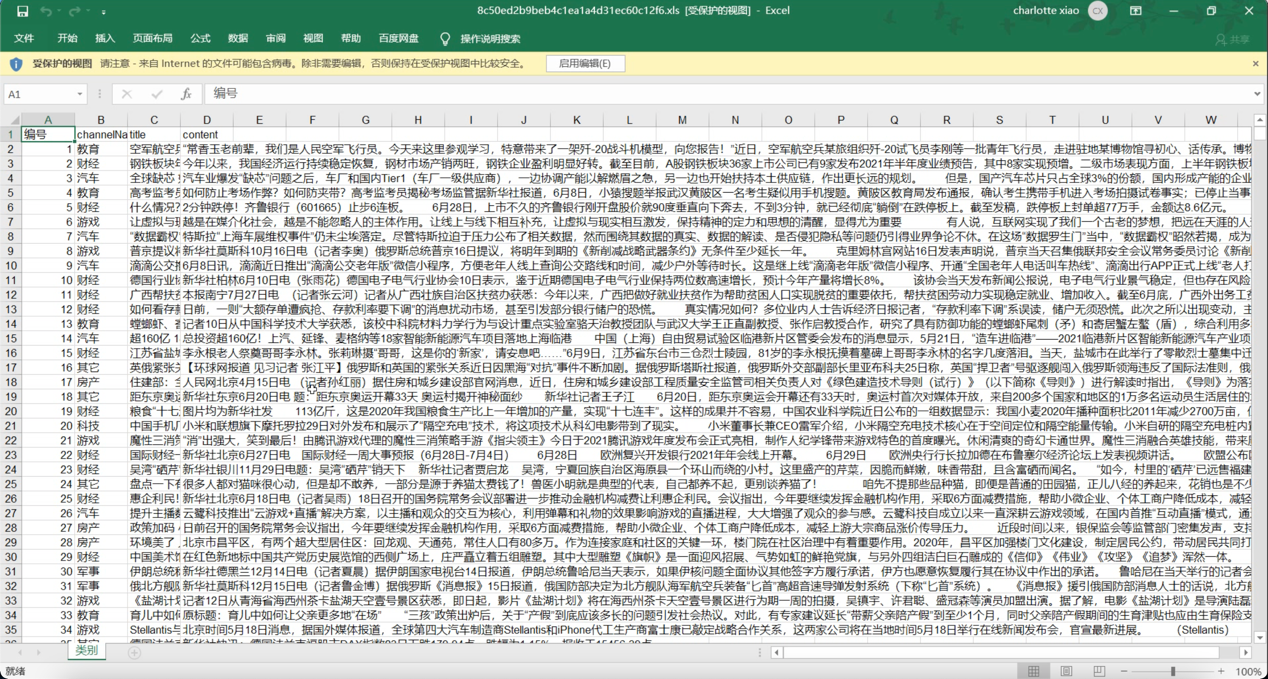
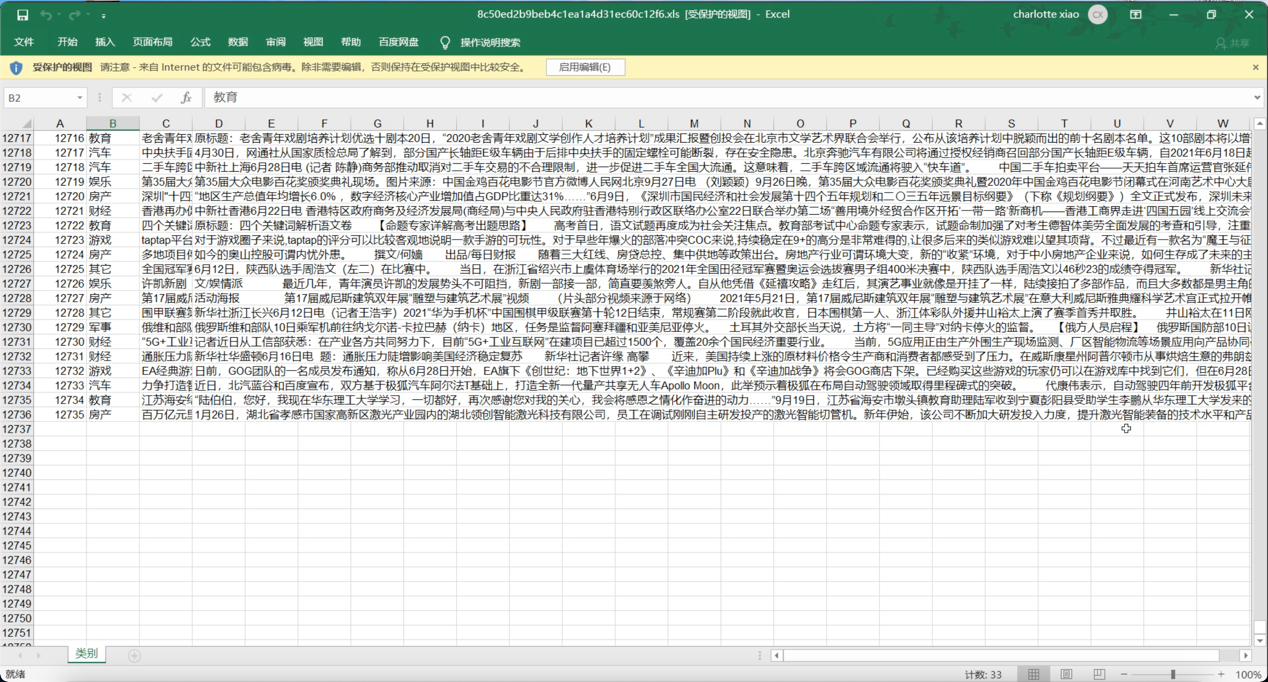
进行完文本分类之后得到表格,结构如下: