Our modern society is struggling with an unprecedented amount of online misinformation, which does harm to democracy, economics, and national security. Since 2016, Fake news has been well tuned and aligned with United states elections, and that came back to the media recently with the approach of elections, so we tried though that project, based on the highly motivation nowadays “US Election” to develop a reliable model that classifies a given news article as either fake or true. We tried to simulate the different programs made by large big companies, like google, on sources and web sites as well. Our simple models give us accuracy up to 76%.
Key Words : Bag of words, TF-IDF, Doc Vec, Naive Bayes, Logistic Regression, SVM, Random forest, MLP.
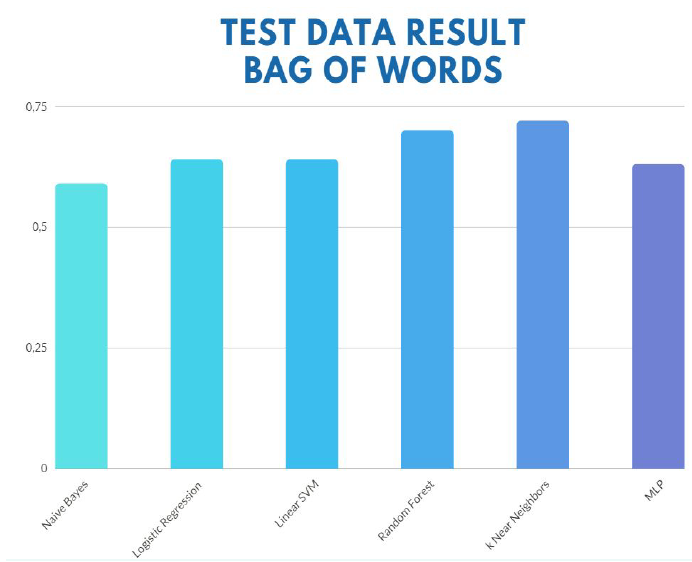
Using the Bag of words model to extract features, we observed an accuracy of 74% percent on our testing set, using k_near neighbors algorithm model.
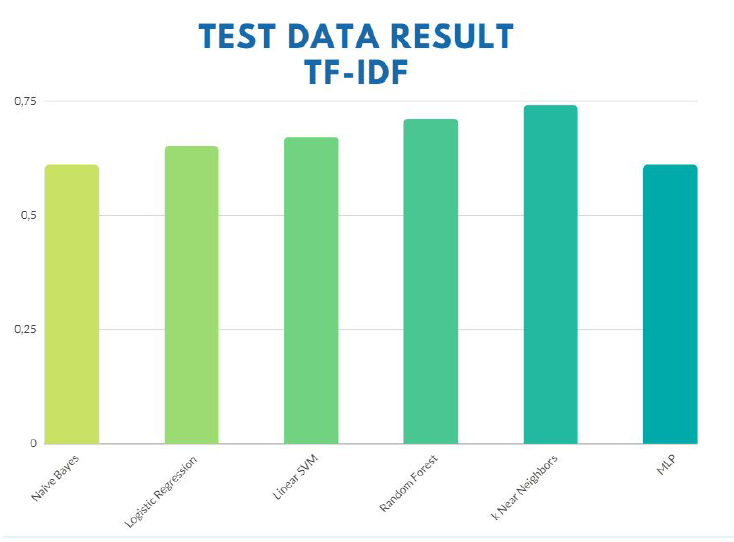
The increase in accuracy for the models made previously was foreseen, since the TF-IDF method does not equalize all the inputs (as in the bag of words method), but weights them according to their appearance in the inputs. As last time, the highest accuracy was reached by k Near Neighbors for an accuracy of 74%
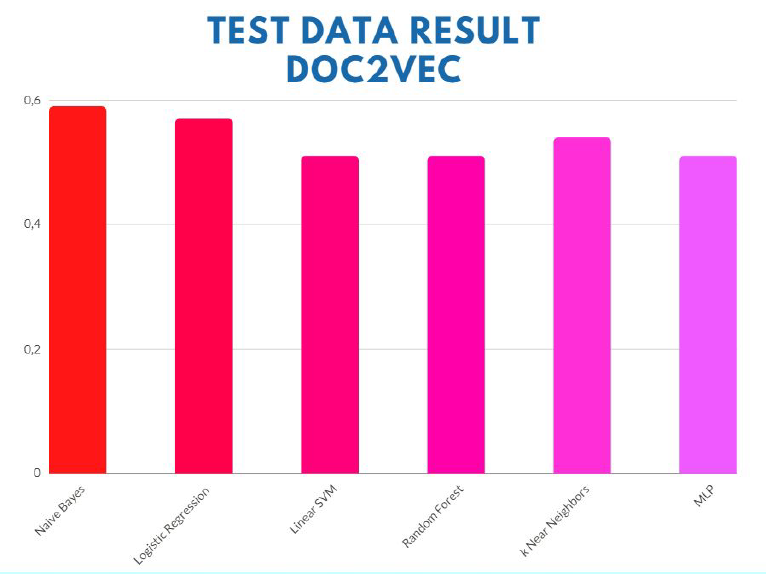
We learned that the most frequent tokens are not the most casual ones, so the context of the word that Doc2Vec takes into consideration in fitting doesn’t affect a lot, unfortunately that drops accuracy.
Preparation of Data : ==> data_process Folder
Test_NLP_Models : ==> NLP_Models Folder