This is the weekly coding challenge posted on Siraj Raval's youtube channel. The dataset can be found on kaggle. It was compiled by professors Ray Fisman and Sheena Iyengar from Columbia Business School, originally used for their paper “Gender Differences in Mate Selection: Evidence From a Speed Dating Experiment.” Data was gathered from participants in experimental speed dating events from 2002-2004. During the events, the attendees would have a four minute "first date" with every other participant of the opposite sex. At the end of their four minutes, participants were asked if they would like to see their date again. They were also asked to rate their date on six attributes: Attractiveness, Sincerity, Intelligence, Fun, Ambition, and Shared Interests
After finding a data dictionary for this dataset, I was able to do some much deeper data exploration. To start it is important to note that there is a class imbalancement between 'match' & 'no match' labels.
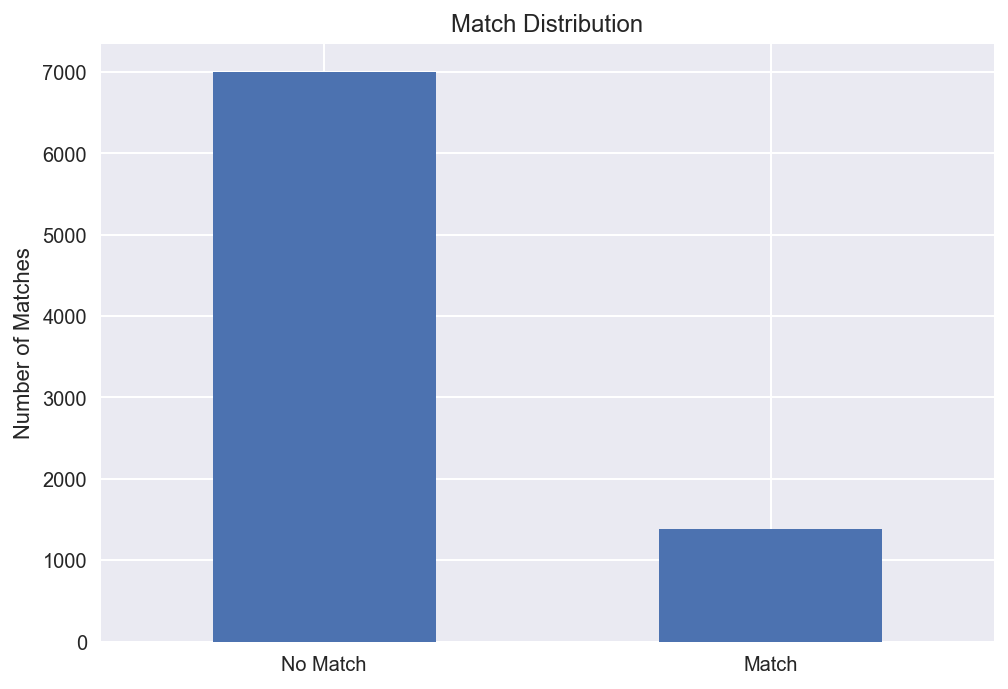
There is ~5:1 ratio therefore I ignored Accuracy as a metric and optimized Precision and Recall as the metrics.
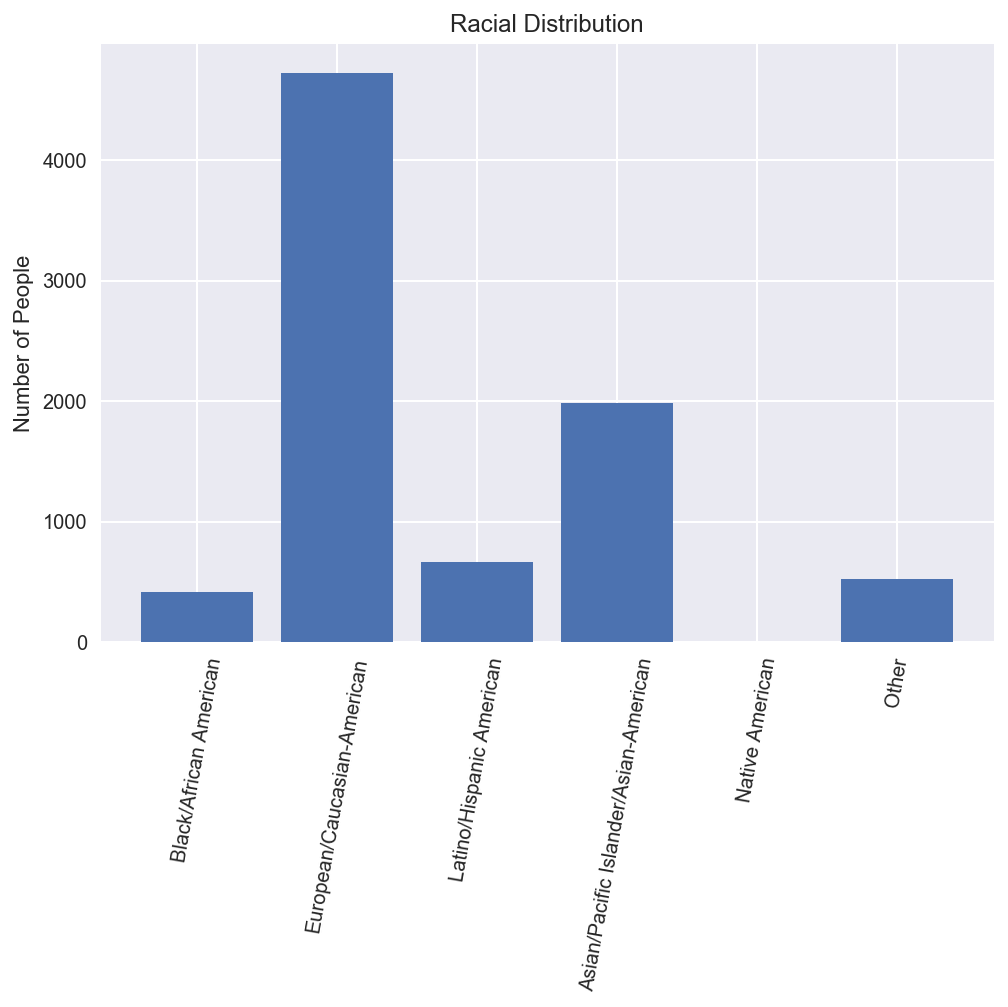
In the figure above, the racial distribution can be seen. There more European/Cauasian-Americans than all the other ethnicities put together.
Precision Score: 0.98
Recall Score: 0.20
Precision Score: 0.98
Recall Score: 0.96
Precision Score: 0.99
Recall Score: 0.95
Overall I would suggest using the SVC because it significantly cheaper when it comes to computational costs relative to the neural network. SVC is also significantly faster too.
- Numpy
- Pandas
- Matplotlib
- Seaborn
- Sklearn
- Tensorflow