Benchmarks
We evaluate performance with 5 widely-used standard models: VGG-16, GoogleNet (Inception-V1), ResNet-50, MobileNet, SqueezeNet and DenseNet-121, respectively. Our test bed has 6 different ARM devices, including 2 cellphones, 2 server-class processors and 2 embedded dev boards, whose specifications can be found in the following table. All results are averaged from 20 consecutive runs and measured in milliseconds.
Table1: Specifications
| Device | Processor | #CPUs @ Clock Speed | CPU Arch. | Memory (MB) | OS | SOC Power |
|---|---|---|---|---|---|---|
| Samsung S8 | Snapdragon 835 | 4 @ 2.45Ghz + 4 @ 1.90GHz | Kryo | 4GB | Android 7.0 | ~5W |
| iPhone 7 | A10 Fusion | 2 @ 2.34Ghz + 2 @ 1.05GHz | Hurricane | 2GB | iOS 11.1 | ~5W |
| Huawei D05 | Hi1616 | 2 * 32 @ 2.40GHz | Cortex-A72 | 256GB | Ubuntu 16.04 | >100W |
| Phytium FT1500A/16 | FTC660 | 16 @ 1.50GHz | Earth | 64GB | Kylin 5.0 | 35W |
| RK3399 | RK3399 | 2 @ 1.8Ghz + 4 @ 1.40GHz | Cortex-A72 | 2GB | Debian | 6.05W |
| Raspberry Pi3 | Broadcom BCM2837 | 4 @ 1.2Ghz | Cortex-A53 | 1GB | Ubuntu 16.04 | ~5W |
The VGG series models run through many unit-stride 3x3 convolution layers (operators), therefore can be perfectly accelerated by the Winograd algorithm. We use VGG-16 as reference model to evaluate our Winograd implementation performance.
Table1: Avg. inference time (ms) on Arm-based CPUs.
| Devices\Cores | 1 | 2 | 4 | 8 | GPU |
|---|---|---|---|---|---|
| Galaxy S8 | 925 | 630 | 489 | ||
| iPhone 7 | 374 | 284 | |||
| Huawei D05 | 755 | 399 | 226 | 149 | |
| Phytium FT1500A | 1769 | 1020 | 639 | 444 | |
| RK3399 | 1673 | 1420 | |||
| TensorFlow lite on iPhone7 | 905 | ||||
| ACL on RK3399 | 4103 | 1645 | |||
| TVM on RK3399 | - | 1293 | |||
| Intel Movidius* | 812 |
- Intel Movidius operates at FP16 precision.
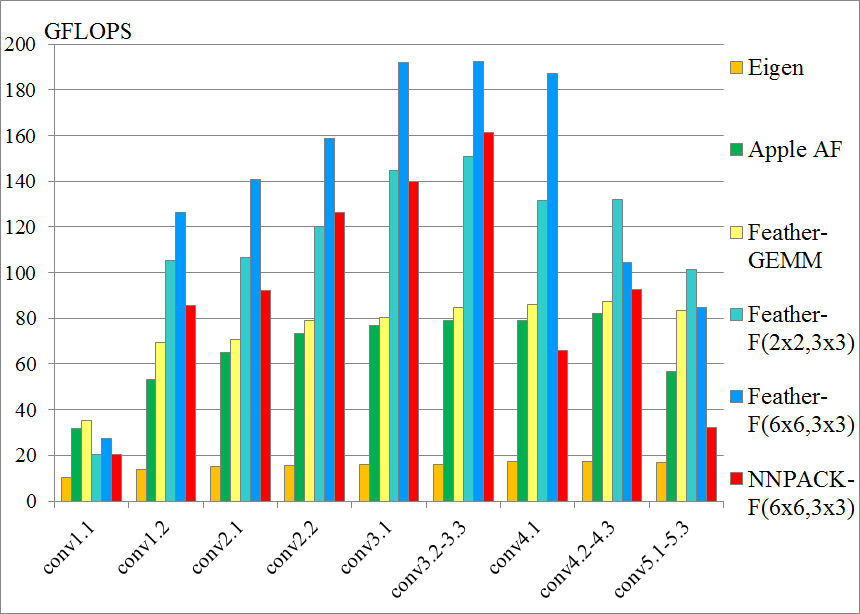
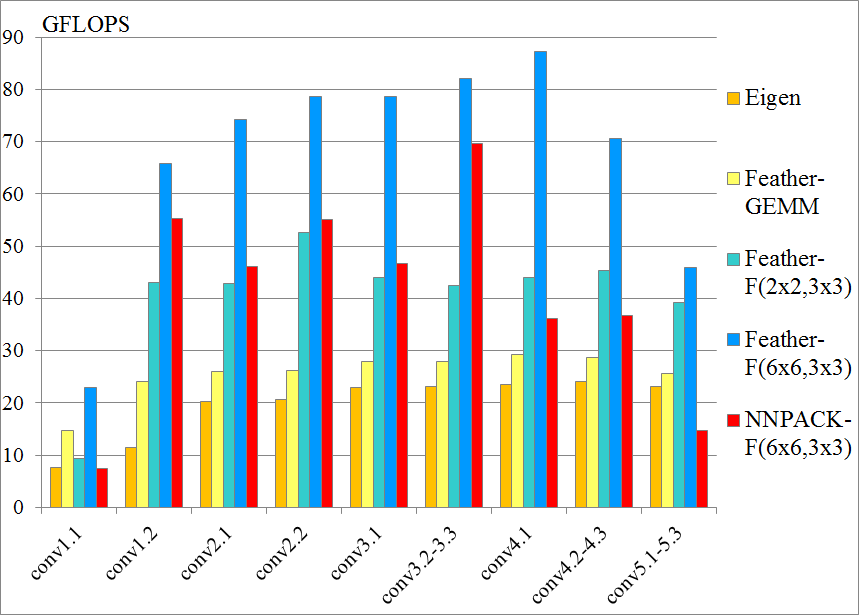
We conduct VGG-16 layer-by-layer benchmark on Samsung S8 and iPhone 7. We have tested two FeatherCNN compute patterns: IM2COL + GEMM and Winograd F(2x2,3x3)/F(6x6,3x3), against NNPACK Winograd F(6x6,3x3). We should note that the NNPACK is called by a small standalone benchmark program in order to eliminate framework overhead. It performs better than Caffe/Caffe2 integrations.
All the convolution layers use 3x3 filters with unit-stride and unit-paddings. Detailed layer configurations are as follows, where K is output channels, C is input channels, H is image height, W is image width:
VGG-16 conv layer configurations
| Layer Name | K | C | H | W |
|---|---|---|---|---|
| conv1.1 | 3 | 64 | 224 | 224 |
| conv1.2 | 64 | 64 | 224 | 224 |
| conv2.1 | 64 | 128 | 112 | 112 |
| conv2.2 | 128 | 128 | 112 | 112 |
| conv3.1 | 128 | 256 | 56 | 56 |
| conv3.2-3.3 | 256 | 256 | 56 | 56 |
| conv4.1 | 256 | 512 | 28 | 28 |
| conv4.2-4.3 | 512 | 512 | 28 | 28 |
| conv5.1-5.3 | 512 | 512 | 14 | 14 |
Performance is measured by GFLOPS, which is (2.0 * K * C * H * W * 3 * 3) / Time / 1.0e9. Note that the Winograd algorithm actually conducts less computing operations than standard algorithm, therefore the measured performance is an "effective" performance, which may exceed device compute capability.
iPhone7
Samsung Galaxy S8
We test thread scalability on a dual-socket Huawei D05 server. This server equips with 64 Cortex-A72 cores integrated in two Hi1616 SOCs. The cores are connected via token-rings on each SOC. Every two cores share their L2 cache. We are told that the L2 cache bandwidth is insufficient for two concurrent cores. Therefore, peak performance usually comes at 32 threads. We have tested our work, Caffe + OpenBLAS and Caffe2 + Eigen. The test was finished by the end of 2017, performance may change a lot after that time. The FeatherCNN speedup is calculated by dividing peak performance achieved at any thread numbers.
Average inference time (ms) - FeatherCNN-F(2x2,3x3)
| Network | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| VGG-16 | 1333 | 697 | 385 | 218 | 157 | 117 | 102 |
| GoogleNet | 333 | 210 | 154 | 125 | 126 | 151 | 230 |
| ResNet-50 | 573 | 356 | 187 | 117 | 104 | 65 | 194 |
| SqueezeNet | 149 | 79 | 44 | 28 | 29 | 35 | 67 |
| MobileNet | 124 | 70 | 42 | 36 | 34 | 52 | 76 |
| DenseNet-121 | 517 | 273 | 156 | 98 | 113 | 160 | 331 |
Average inference time (ms) - Caffe + OpenBLAS
| Network | 1 | 2 | 4 | 8 | 16 | 32 | 64 | FeatherCNN Speedup |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 3329 | 2227 | 1443 | 1108 | 1137 | 2109 | 3721 | 10.86 |
| GoogleNet | 1028 | 929 | 861 | 831 | 822 | 848 | 857 | 13.7 |
| Resnet-50 | 728 | 490 | 347 | 278 | 252 | 346 | 365 | 3.88 |
| SqueezeNet | 190 | 127 | 92 | 76 | 74 | 84 | 92 | 1.68 |
| MobileNet | 211 | 166 | 146 | 139 | 137 | 153 | 184 | 4.03 |
| DenseNet-121 | 865 | 593 | 438 | 373 | 354 | 655 | 856 | 3.08 |
Average inference time (ms) - Caffe2 + Eigen
| Network | 1 | 2 | 4 | 8 | 16 | 32 | 64 | FeatherCNN Speedup |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 3267 | 2173 | 1550 | 1310 | 1385 | 1323 | 1401 | 12.84 |
| GoogleNet | 351 | 347 | 267 | 306 | 894 | 2422 | 3938 | 4.45 |
| Resnet-50 | 869 | 549 | 374 | 262 | 149 | 355 | 724 | 2.29 |
| SqueezeNet | 91 | 65 | 55 | 87 | 221 | 628 | 723 | 1.25 |
| MobileNet | 174 | 139 | 110 | 90 | 110 | 171 | 592 | 2.65 |
As ARM has a unique big.little architecture for energy saving, to evaluate the adaptation of schduling algortihm and blocking strategies with this big.little archtecture, RK3399 is selected as an widely used embeded developing board for testing. RK3399 has 2 big cores with 1.8GHz, and 4 little cores with 1.4GHz.
FeatherCNN
| Network | 1 | 2 | 1 | 2 | 4 | all | Memory (MB) |
|---|---|---|---|---|---|---|---|
| VGG-16 | 2268 | 1620 | 6122 | 3422 | 2269 | 1932 | 904 |
| GoogleNet | 416 | 250 | 927 | 524 | 333 | 294 | 168 |
| Resnet-50 | 857 | 517 | 1834 | 1009 | 671 | 555 | 466 |
| SqueezeNet | 236 | 144 | 539 | 315 | 210 | 172 | 404 |
| MobileNet | 242 | 137 | 487 | 271 | 165 | 153 | 176 |
| DenseNet-121 | 842 | 543 | 1854 | 1050 | 686 | 543 | 111 |
| Network | 1 | 2 | 4 |
|---|---|---|---|
| [VGG16] | - | - | - |
| [GoogleNet] | 1058 | 642 | 809 |
| [Resnet-50] | 2107 | 1255 | 1540 |
| [squeezenet] | 638 | 399 | 501 |
| [mobilenet] | 451 | 275 | 206 |
| [densenet-121] | 630 | 396 | 459 |
| Network | 1 | 2 | 1 | 2 | 4 | all |
|---|---|---|---|---|---|---|
| [VGG16] | 1325 | 706 | 2540 | 1507 | 1226 | 844 |
| [GoogleNet] | 274 | 146 | 366 | 206 | 127 | 105 |
| [Resnet-50] | 480 | 266 | 759 | 417 | 261 | 215 |
| [squeezenet] | 88 | 115 | 73 | 61 | 204 | 153 |
| [mobilenet] | 156 | 87 | 211 | 116 | 68 | 56 |
| [densenet-121] | - | - | - | - | - | - |
| Network | 1 | 2 | 1 | 2 | 4 | all |
|---|---|---|---|---|---|---|
| [VGG16] | x | x | - | - | - | - |
| [GoogleNet] | x | x | - | - | - | - |
| [Resnet-50] | 1396 | 753 | 1394 | 757 | 5841 | 6108 |
| [squeezenet] | 170 | 116 | 172 | 124 | 899 | 782 |
| [mobilenet] | x | x | x | - | - | - |
| [densenet-121] | 1223 | 720 | 1189 | 727 | 10970 | 10755 |