Regex Checks
Automata-based analyses for regular expressions
In order to analyze control flow within regular expressions, they should be represented as an "AST extended with continuation pointers" model as is used by some reDoS analyzers and similar to the representation used in Java's regex engine. This model provides the features of a prioritized (order of alternatives matters) NFA while still providing access to the AST structure. Since this kind of automaton is just an AST with extra pointers, we should extend the current AST classes to support it and then generate it directly in the parser rather than having separate regex -> AST -> automaton phases.
For example:
-
Java regular expression:
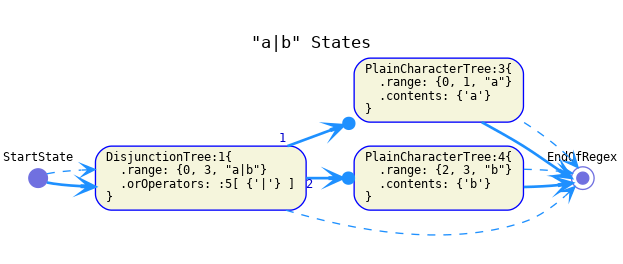
"a|b" -
AST model is:

-
Automaton:
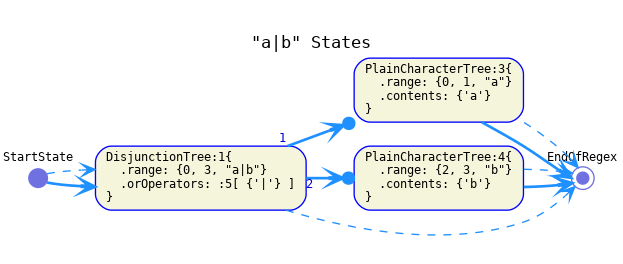
-
Legend used in the graphics of this page
To represent this, each AST class should have a member continuation that points to whichever state should be matched
after this one is matched successfully. To be able to easily and intuitively use this as an NFA, we should also add a
method successors which returns the states that can directly follow a given state. With these methods, we get the
structure of an NFA, while requiring no changes to existing rules that can simply continue using the existing structure
without changes.
For easy construction in the parser, the continuation member should be null when constructed and then set using a
setter method. However, after parsing the states should be considered immutable and the setter should not be called anymore.
To represent some aspects of Java regexen, we need synthetic states that don't correspond directly to parts of the AST.
Therefore we should introduce an interface AutomatonState such that RegexTree implements AutomatonState, all
AutomatonState s have a continuation and a list of successors (which are also AutomatonState s) and RegexTree s
have children (which are RegexTree s). The children member can also be used to simplify the implementation
BaseRegexTreeVisitor (which should still only visit RegexTree s - the synthetic states should not be visible when
iterating a regex's syntactic structure only when iterating the states of the automaton via successors and/or
continuation). The following synthetic AutomatonState s should be created:
-
StartStaterepresents the initial state of the automaton. Its continuation and successor will be theRegexTreerepresenting the whole regex. It will be accessible through theRegexParseResultobject created by the parser.
-
Branchrepresents a branch in the control flow that does not correspond to the direct use of the|operator. The difference betweenBranchandDisjunctionis that the latter corresponds directly to a syntax construct (and thus inheritsRegexTree) while the latter does not. Therefore both should implement a common interface, so they can be handled as the same thing by rules that deal with automata states.
-
EndOfRegexrepresents the end of the regex being reached successfully. It's the automaton's only accepting state. Its continuation should benull.
-
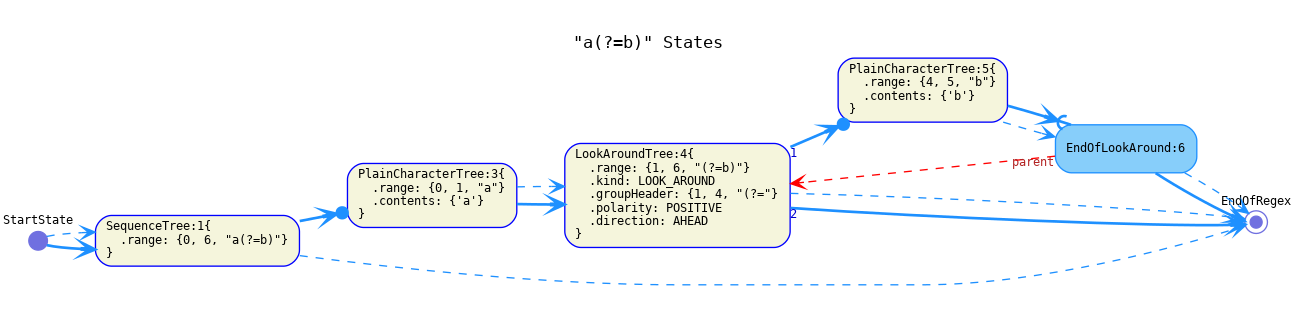
EndOfLookAroundrepresents the end of a look around group. Reaching the end of a positive look around will cause the match to continue at the point where the look around began. It should contain a reference to theLookAroundTreewhose end it represents.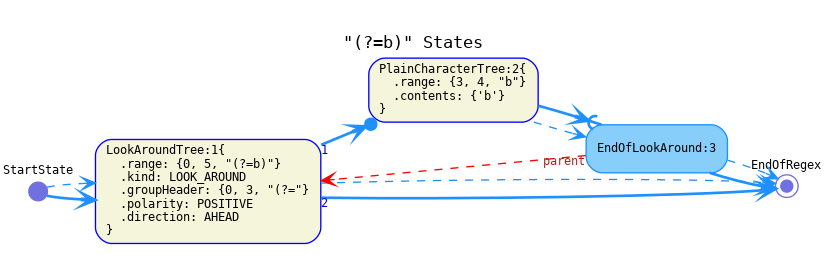
-
Negationintroduces a negated section of the automaton (created by negative lookarounds). There should be no transitions from the negated section back to the non-negated part (which makes it important thatEndOfLookAroundhas no continuation/successors).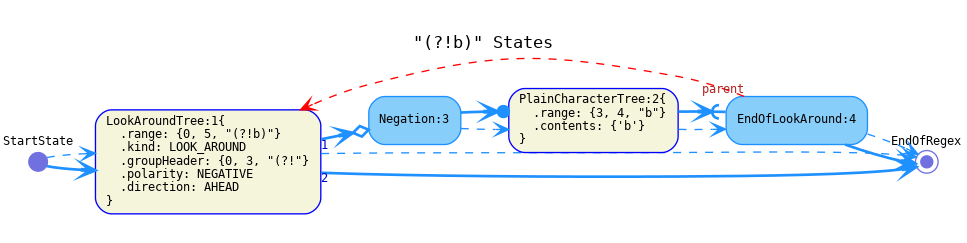
Each AutomatonState should have an transitionType to represent the type of its incoming transitions (all incoming
transitions of a state will be of the same type (and with the same label) in this representation). The following transition
types should exist:
-
Epsilonfor epsilon transitions, which are unconditional and consume no input. This is the transition type of most nodes like the bellowCapturingGroupTree,DisjunctionTreeandEndOfCapturingGroup.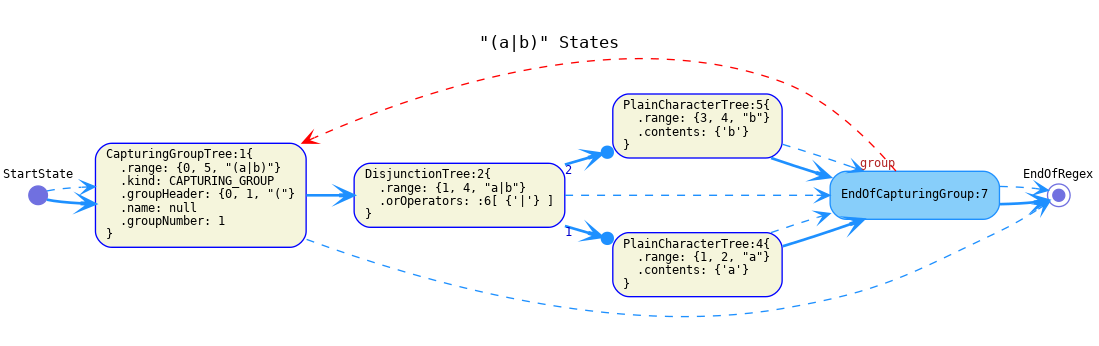
-
Characterfor transitions that consume a single character and may require a specific character or one of a set of characters (it may also be unconditional in case of.). This is the transition type of nodes that consume a single character, such asPlainCharacterTree,CharacterClassTreeetc.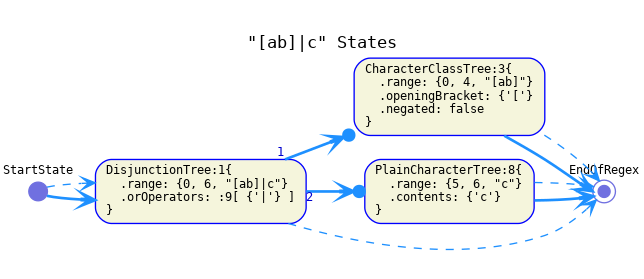
-
BackReferencewhich requires the current input to match a string saved in a capturing group and consumes an amount of input equal to the saved string's length. This is the transition type ofBackReferenceTrees.
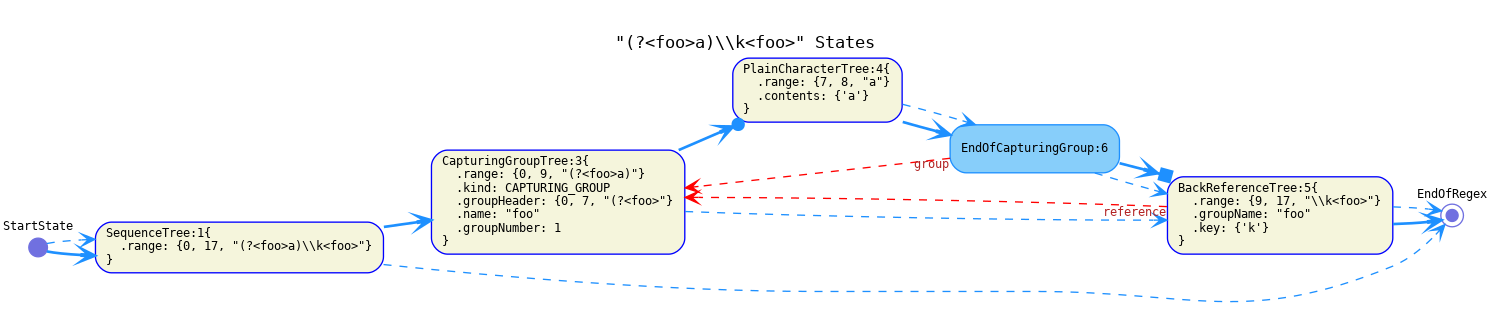
-
LookAroundBacktrackingwhich represents the fact that this transition will move back in the input. It's the transition type ofLookAroundTrees that represent look behinds and ofEndOfLookArounds that represent lookaheads.Look behind:

Look ahead:
-
Negation- the transition type ofNegationstates.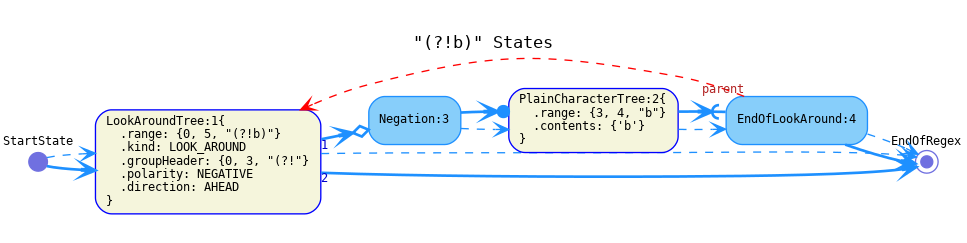
The continuations and successors of states should be set as follows by the parser:
-
Only
EndOfRegexshould havenullas its continuation and an empty list of successors. -
The
EndOfRegexstate should be the continuation of the top-level regex. For example thecontinuationof the bellowDisjunctionTree.
-
The children of a
CharacterClassTreeare ignored. Its successor is its continuation.
-
Each element in a sequence except the last element should have the following node as its continuation. The continuation of the last element should be the same as that of the sequence.

-
The successor of a sequence is its first element.
-
The continuation of a (non-lookaround) group's contents should be the same as that of the group.
-
The continuation of a lookaround's contents should be an
EndOfLookAroundstate.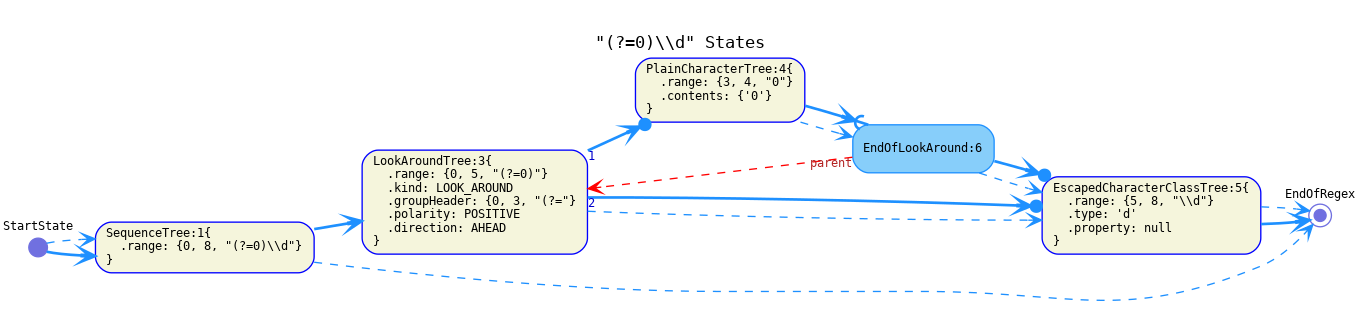
-
The continuation of an
EndOfLookAroundstate should be the same as the continuation of the correspondingLookAroundTree. -
The continuation of a disjunction's elements should be the same as the continuation of the disjunction itself.
-
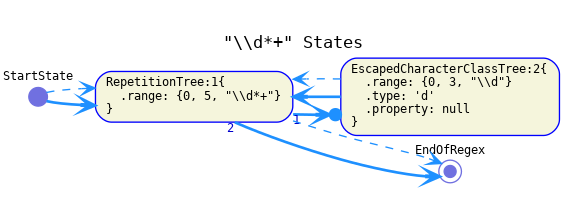
The successor of a "*" repetition should be a branch containing the body of the repetition and the continuation of the repetition as its alternatives. The continuation of its operand should be the repetition itself (not its continuation).
Greedy:

Possessive:
Reluctant:
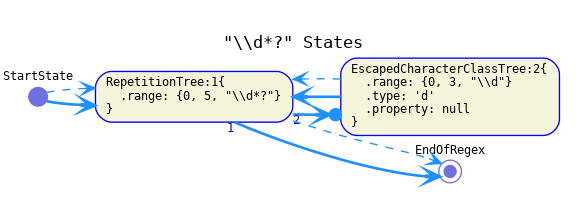
-
The successor of a "+" repetition should be its body. The continuation of its child should be a branch containing the repetition itself (not its continuation) and its successor.
Greedy:

Possessive:

Reluctant:

-
The successor of a "?" should be a branch containing the operand and the continuation of the "?". The continuation of its operand should be the same as the continuation of the optional.
Greedy:
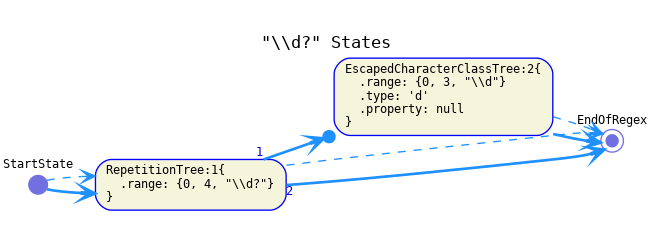
Possessive:

Reluctant:

-
{0,1}same as "?",{0,m}with m>1 or{0,}same as "*",{n,m}with n>0, m>1 or{n,}same as "+" -
{0,0}should probably only have its continuation as its successor (child unreachable) and there should be a code smell rule identifying this construct as nonsense. Or we could ignore it because nobody's going to write that.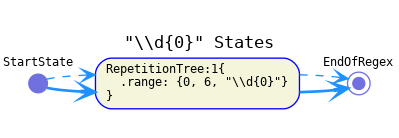
-
For greedy and possessive repetitions/options the associated branch node
-
The continuation of a branch node should be the same as the continuation of the repetition or optional node for which it was created.
-
Unless otherwise stated, the successors of each node with children should be the same as the list of its children. If it has no children, its only successor should be its continuation (note that the continuation won't be part of the successors when there are children (unless otherwise stated)).