EDIT 3 December 2018, I receive many questions over email. I compiled the most common questions into a FAQ at the end of this readme
This repo presents a simple auto encoder for time series. It visualizes the embeddings using both PCA and tSNE. I show this on a dataset of 5000 ECG's. The model doesn't use the labels during training. Yet, the produced clusters visually separate the classes of ECG's.
People repeatedly ask me how to find patterns in time series using ML. The usual wavelet transforms and other features fail to yield results. They wonder what ML has to offer.
- For categorical data, a usual choice are techniques like PCA, tSNE.
- For images, a usual choice is convolutional auto encoders
- For time series, what is the usual choice?
- This repo implements a recurrent auto encoder
- The length of time series may vary from sample to sample. Conventional techniques only work on inputs of fixed size.
- The patterns in time series can have arbitrary time span and be non stationary. The recurrent neural network can learn patterns in arbitrary time scaling. The convolutional net, however, assumes only stationary patterns
From here on, RNN refers to our Recurrent Neural Network architecture, the Long Short-term memory Our network in AE_ts_model.py has four main blocks
- The encoder is a RNN that takes a sequence of input vectors
- The encoder to latent vector is a linear layer that maps the final hidden vector of the RNN to a latent vector
- The latent vector to decoder is a linear layer that maps the latent vector to the input vector for the decoder
- The decoder is a RNN that takes this single input vector and maps to a sequence of output vectors
An auto encoder learns the identity function, so the sequence of input and output vectors must be similar. In our case, we take a probabilistic approach. Every output is a tuple of a mean, mu and standard deviation. Let this mu and sigma parametrize a Gaussian distribution. Now we minimize the log-likelihood of the input under this distribution. We train this using backpropagation into the weights of the encoder, decoder and linear layers.
I showcase the recurrent auto encoder on a dataset of 5000 ECG's. Accurately named ECG5000 on the UCR archive. I choose ECG, because humans understand them easily. Yet, their complexity remains challenging enough for a machine learning model.
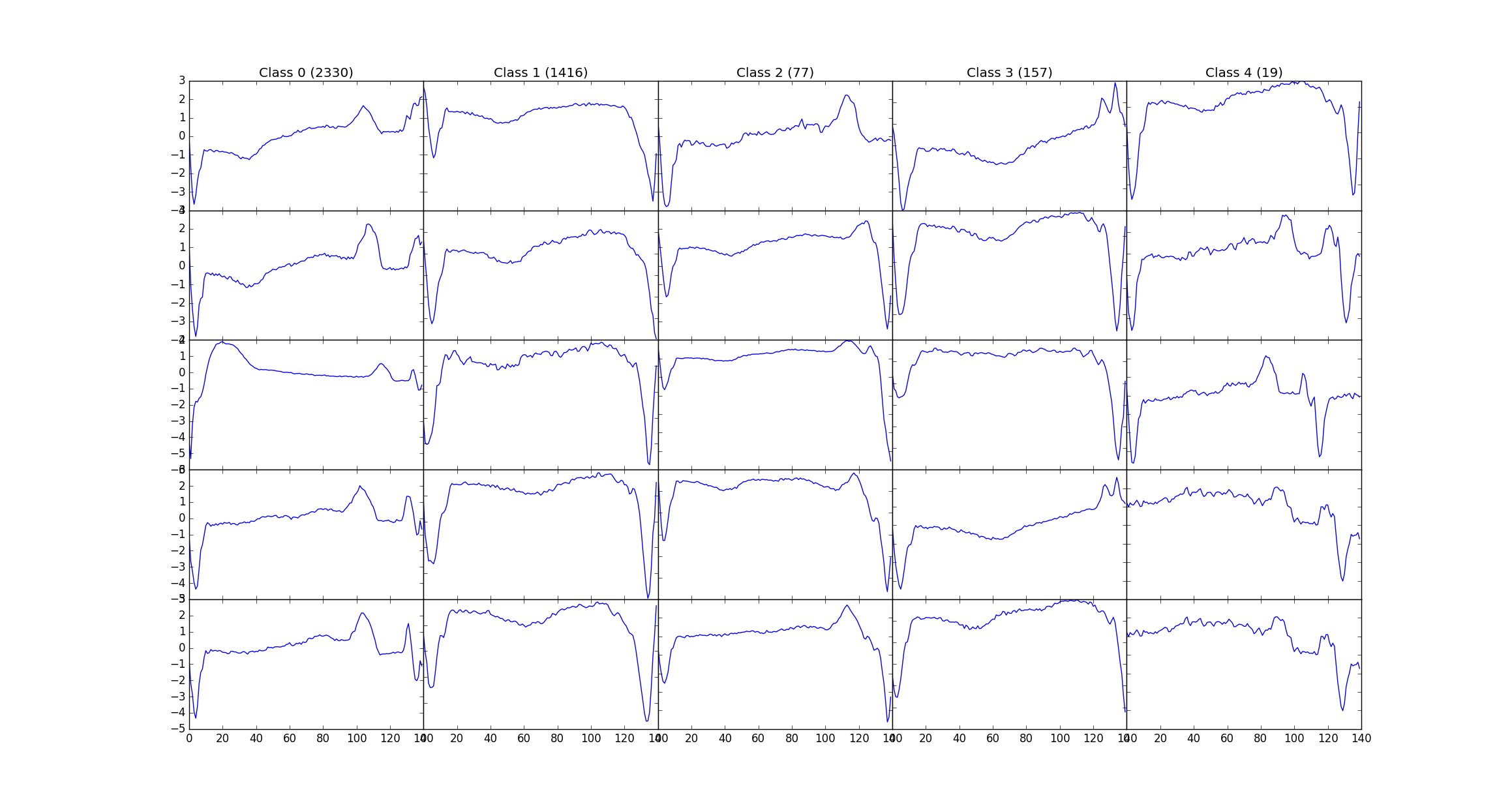
Here are some examples, each column represents another input class
We run the recurrent auto encoder with a 20D latent space. The following figure plots the latent vectors with both PCA and tSNE.

This figure shows that the latent space exhibits structure. We color the vectors with their corresponding labels. The light blue and dark blue labels obviously cluster in different parts of the space. Interestingly, the lower left corner in the tSNE shows another cluster of orange points. That might be interesting for doctors to look at. (Note that the class distributions are highly unbalanced. The orange and greeen colored data occur less frequently)
We present an auto encoder that learns structure in the time-series. Training is unsupervised. When we color the latent vectors with the actual labels, we show that the structure makes sense.
To my great joy, I receive many questions and suggestions over email. I compiled some of the commonly asked questions so you can get started quickly
-
How can I use the representations for other purposes than visualization? After training, you can fetch the representations by running
sess.run(model.z_mu, feed_dict=my_feed_dict) -
I get an import error. What versions do you use? See the
docs/requirements.txtfile for all versions -
How could I extract classes from the representations? The auto-encoder framework belongs to unsupervised learning. Hence, classes will only follow from some sort of clustering. You can apply a clustering model to the hidden representations. Or you could implement another model that naturally clusters time series, for example neural expectation maximization or simply HMM's. Moreover, if you do have supervision for your data, then I recommend you to use supervised model. For example, a linear classification model, linear dynamical systems or a normal recurrent/convolutional neural network.
-
The loss function on the latent space resembles the VAE loss function. How does your model differ from the VAE? For clarity, this question usually refers to the loss in
tf.reduce_mean(tf.square(lat_mean) + lat_var - tf.log(lat_var) - 1). I see two immediate differences with the VAE* The VAE follows from amortized inference on a latent variable model. All terms in the VAE model have a probabilistic interpretation. In contrast, our auto encoder learns according to the maximum likelihood principle. We implement this loss functions only to improve our visualization. * The VAE penalizes the KL divergence with the prior for each representation. In contrast, we penalize the KL divergence with the marginal distribution on the representations. In other words, the VAE *wants* each representation to have zero mean and unit variance; our auto encoder want all representations marginally to have zero mean and unit variance.
Please let me know if I forgot your questions in this FAQ section
As always, I am curious to any comments and questions. Reach me at [email protected]