In 2019, the world was exposed to SARS-CoV-2, creating panic that devastated the world in all aspects - socially, politically and economically - with nearly nearly 6 million deaths to date. To understand the deadly disease one must understand the morphology of SARS-CoV-2, specifically the spike glycoprotein. The spike protein fuses to the cell membrane by binding to the N terminal and entering the cell to where the virus is replicated. There have been other outbreaks of viruses with spike proteins, such as SARS and MERS. Many biological factors have lead to this global pandemic, such as the high transmissibility of the virus as well as deadly complications such as MIS-C (Multi-system Inflammatory Syndrome in Children) or multi-system organ failure induced by the cytokine storm. The Omicron variant has been shown to be highly mutable with a total of 50 point mutations - 36 of which are on the spike protein, making this one of the most transmissible variants to date.

Due to the effect SARS-CoV-2 has had on the world, an interest was taken in understanding the effects of the virus on different communities. The goal was to create a predictive model looking at a variety of factors such as vaccination status, testing, comorbidities, etc... based on this dataset from Our World in Data: Github, OWID. After initial extraction, the data was transformed using Pandas, then it was loaded into a database using Postgres, and finally the data was visualized using Tableau. The random forest machine learning model will be used to start the analysis. The model was then used to determine the impact of COVID in communities. The purpose of the research is to see if there are any factors that could contribute to large outbreaks.
The Google Slides can be found here.
- Python (sklearn, matplotlib)
- Jupyter Notebook
- Postgres SQL / SQL Alchemy
- Tableau
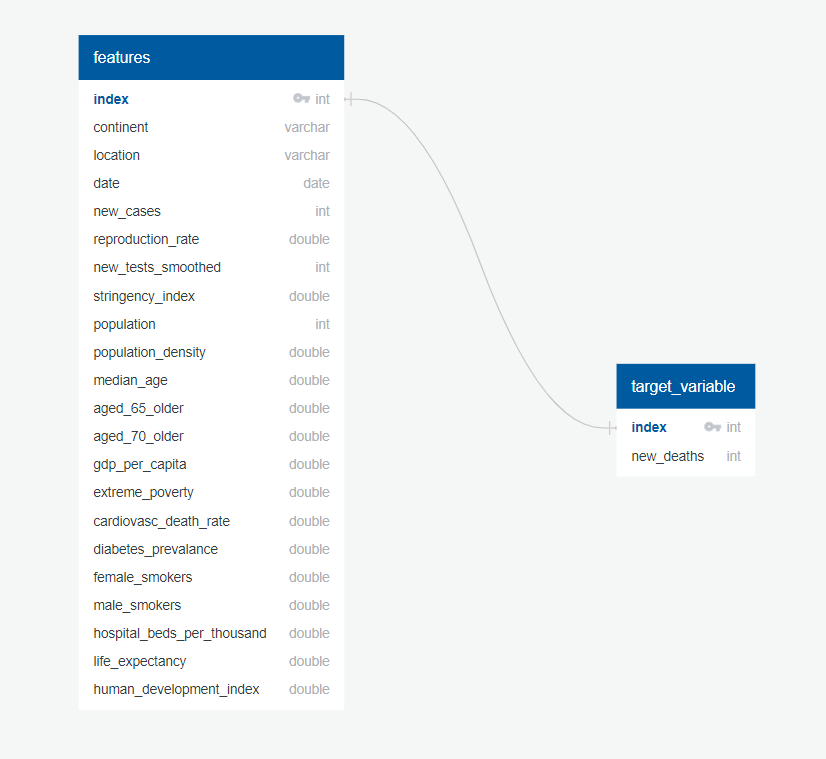
Our raw dataset contained 151,776 rows x 67 columns. Initial findings on the dataset suggest that 'date' column was not the correct datatype, and it had to be converted using pd.datetime. Null values and less populated features had to be dropped to ensure the model's efficiency & accuracy. Ultimately, the cleaned dataset contained 40,877 rows x 26 columns. Below are the detailed steps taken in cleaning the dataset.
- Remove all iso codes starting with OWID because they are aggregated rows not counted rows
- Dropping all columns that start with excess because they are mostly null columns
- Dropped all columns with less than 10k rows of data
- Dropped cumulative columns because they are aggregated columns not counting up as they go along
- Dropped all columns with less than 1/2 their rows populated
- Dropped all smooth columns
- Dropped all na rows
- Dropped iso codes as it is redundant with Location
- Removing the new_deaths column from DataFrame and setting it as X
- Using LabelEncode for Data and Location Columns
- Using the OneHotEncoder on continent
- Merging the encoded continent with our features DataFrame and dropping the continent column
- Using StandardScaler for all columns
RandomForestClassifier
For the data analysis, the initial plan was to use RandomForestClassifer to determine a country's predicted state of COVID risk. The model is to forecast a future month's number of COVID deaths based on a number of features. We used sklearn's model_selection module, imported train_test_split class and used the default setting for testing & training sizes (75/25). Only the last 3 months worth of data was analyzed when considering vaccination/booster efforts. The features are as follows:
| Features | ||
|---|---|---|
| Country | Date | New Cases |
| New Cases | Reproduction Rate | Stringency Index |
| Population | Population Density | Median Age |
| Number of Age 65+ | Number of Age 70+ | GDP per Capita |
| Extreme Poverty | Cardiovascular Health | Diabetes Prevalence |
| Female Smokers | Male Smokers | Hospital Beds per Thousand |
| Life Expectancy | Human Development Index |
Based on these features, the model will classify if a country's forecasted monthly COVID deaths is Bad, Worse or Worst. This will involve bucketing projected outcomes (e.g. >10,000 deaths - Bad, 10,000 to 50,000 deaths - Worse, 50,000 deaths - Worst)
RandomForestRegression
In the middle of the analysis, to better represent a time series data we then opted for a RandomForestRegression instead. This will keep our findings cleaner with a definite projected number per month wherein we can pinpoint environment seasonalities (vaccinations started, vaccinations availablity, boosters, re-openings, etc.). We used the same features as stated above but used the all available dates instead of looking at the last 3 months. We also experimented on New Cases as our target variable for our model, this will be insightful if we see the number of COVID deaths plateuing because of vaccination efforts, looking at New Cases instead will keep our model relevant.
Boosters & Bonus
We also experimented with using GradientBoosting, DecisionTreeRegressor, KNeighborsRegressor, LassoCV, SGDRegressor, BayesianRidge, SVR, and XGBRegressor reggression on our dataframe, alongside adding AdaBoost Regression to the top three performing models.
- Overall, many of the scores accumalated showed an accuracy score of 94% or higher. We tested 10 different regression models and used loops to tune their features in order to achieve the best results possible. The results were as follows:
-
Random Forest Regression
Training R2: 99.07%
--> Testing R2: 94.16%
-
Gradient Boosting Regression
Training R2: 97.99%
Testing R2: 94.06%
-
Decision Tree Regression
Training R2: 99.51%
Testing R2: 91.13%
-
Extreme Gradient Boosting Regression
Training R2: 97.41%
--> Testing R2: 94.56%
-
Histogram-based Gradient Boosting Regression Tree
Training R2: 95.01%
Testing R2: 94.32%
-
Regression based on k-nearest neighbors
Training R2: 100%
Testing R2: 90.12%
-
Lasso linear model with iterative fitting along a regularization path
Training R2: 18.31%
Testing R2: 16.40%
-
Stochastic Gradient Descent Regression
Training R2: 69.50%
Testing R2: 67.32%
-
Bayesian Ridge Regression
Training R2: 69.59%
Testing R2: 67.26%
-
Support Vector Machine
Training R2: 19.48%
Testing R2: 18.93%

-
Trial 1: RandomForestRegressor, AdaBoost
Testing R2: 93.58%
-
Trial 2: XGBRegressor, AdaBoost
Testing R2: 94.13%
-
Trial 3: HistGradientBoostingRegressor, AdaBoost
Testing R2: 93.35%
-
Trial 1: KNeighborsRegressor, DecisionTreeRegressor, HistGradientBoostingRegressor, LassoCV, XGBRegressor, RandomForestRegressor
Training R2: 97.03%
--> Testing R2: 94.52%
-
Trial 2: KNeighborsRegressor, RandomForestRegressor, HistGradientBoostingRegressor, LassoCV, DecisionTreeRegressor, XGBRegressor
Training R2: 95.89%
Testing R2: 93.02%
-
Trial 3: KNeighborsRegressor, RandomForestRegressor, LassoCV, DecisionTreeRegressor, HistGradientBoostingRegressor, XGBRegressor
Training R2: 95.88%
Testing R2: 93.02%
-
Trial 4: XGBRegressor, KNeighborsRegressor, RandomForestRegressor, LassoCV, DecisionTreeRegressor, HistGradientBoostingRegressor, XGBRegressor
Training R2: 96.24%
Testing R2: 93.98%
-
Trial 5: RandomForestRegressor, HistGradientBoostingRegressor, XGBRegressor
Training R2: 95.86%
Testing R2: 93.40%
-
Trial 6: HistGradientBoostingRegressor, XGBRegressor
Training R2: 93.52%
Testing R2: 93.71%
-
Trial 7: RandomForestRegressor, XGBRegressor
Training R2: 97.31%
Testing R2: 92.84%
-
Trial 8: XGBRegressor, RandomForestRegressor
Training R2: 93.35%
Testing R2: 91.33%
-
Trial 9: RandomForestRegressor, KNeighborsRegressor, XGBRegressor
Training R2: 97.63%
Testing R2: 92.07%
-
Trial 10: RandomForestRegressor, LassoCV, XGBRegressor
Training R2: 96.49%
Testing R2: 92.27%
Although the results were close, Trial 1's R2 of 94.52% fell just short of the Extreme Gradient Boosting Regressor results

Stacking_w/XGBRegressor: When stacked with another regressor, XGBRegressor results worsened from the individual accuracy of 94.55%
-
Trial 1: RandomForestRegressor, XGBRegressor
Training R2: 97.31%
Testing R2: 92.84%
-
Trial 2: KNeighborsRegressor, XGBRegressor
Training R2: 97.63%
Testing R2: 88.75%
-
Trial 3: LassoCV, XGBRegressor
Training R2: 49.24%
Testing R2: 48.95%
-
Trial 4: DecisionTreeRegressor, XGBRegressor
Training R2: 97.21%
Testing R2: 90.40%
-
Trial 5: HistGradientBoostingRegressor, XGBRegressor
Training R2: 93.52%
Testing R2: 93.71%
-
Trial 6: SVR, XGBRegressor
Training R2: 41.74%
Testing R2: 38.93%
-
Trial 7: BayesianRidge, XGBRegressor
Training R2: 72.95%
Testing R2: 73.39%
-
Trial 8: SGDRegressor, XGBRegressor
Training R2: 72.54%
Testing R2: 72.59%
-
Trial 9: GradientBoostingRegressor, XGBRegressor
Training R2: 96.11%
Testing R2: 92.63%

Stacking_w/RandomForestRegressor: When stacked with another regressor, RandomForestRegressor results worsened from the individual accuracy of 94.16%
-
Trial 1: XGBRegressor, RandomForestRegressor
Training R2: 93.35%
Testing R2: 91.33%
-
Trial 2: KNeighborsRegressor, RandomForestRegressor
Training R2: 97.63%
Testing R2: 88.75%
-
Trial 3: LassoCV, RandomForestRegressor
Training R2: 49.29%
Testing R2: 48.94%
-
Trial 4: DecisionTreeRegressor, RandomForestRegressor
Training R2: 93.32%
Testing R2: 88.35%
-
Trial 5: HistGradientBoostingRegressor, RandomForestRegressor
Training R2: 91.52%
Testing R2: 89.87%
-
Trial 6: SVR, RandomForestRegressor
Training R2: 1.64%
Testing R2: -0.91%
-
Trial 7: BayesianRidge, RandomForestRegressor
Training R2: 67.43%
Testing R2: 63.53%
-
Trial 8: SGDRegressor, RandomForestRegressor
Training R2: 62.14%
Testing R2: 61.93%
-
Trial 9: GradientBoostingRegressor, RandomForestRegressor
Training R2: 93.54%
Testing R2: 89.69%