一个基于 Flink CDC 封装的 CDC 框架
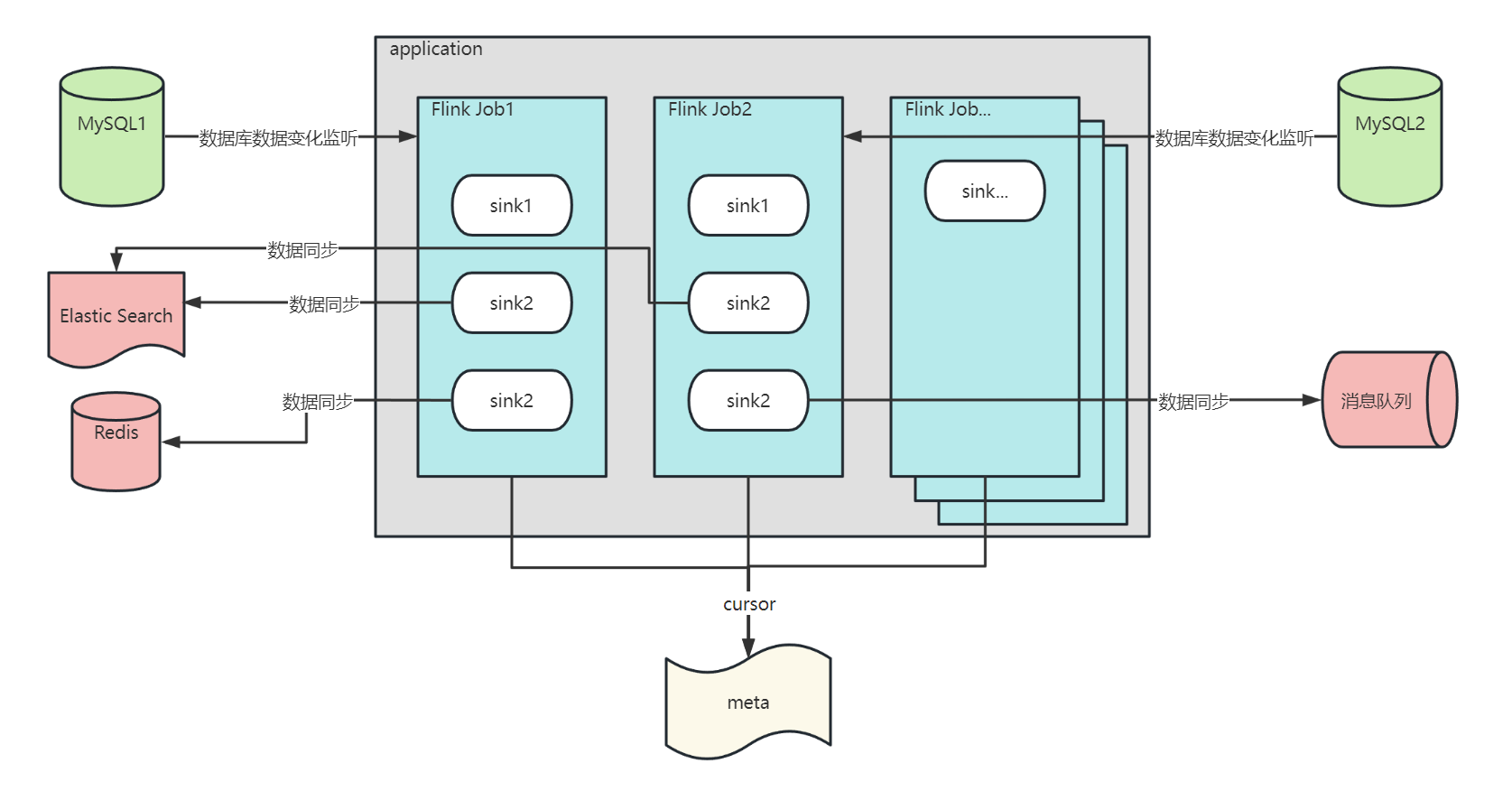
对应一个 Spring 项目
通过配置文件配置要监听的数据源,一个数据源对应一个 Flink Job,Flink Job 可以监听多个数据库和数据库表的数据变化
Flink Job 收到数据变化的结果会调用其下面的 sink,在 sink 中你可以对 增删改 事件进行自由的业务代码处理,到底是同步到 ES 中,还是 Redis 中,还是 消息队列中等等,你可以自由决定。
每个 Flink Job 都有一个自己的 cursor,他记录着每个 Flink Job 当前同步 binlog 的位置,用来在 CDC 项目重新启动是接着上一次同步的位置,继续同步数据。
# cursor 数据结构
- application2
- 端口号
- meta.dat
- flink job cursor
- flink job cursor
- application2
- 端口号
- meta.dat
- flink job cursor
- flink job cursor
cursor 持久化的方式,目前有三种:
- memory:仅持久化到内存中
- file:持久化到文件中
- zookeeper:持久化到 zookeeper 中
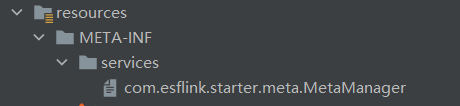
你也可以通过以下步骤自己实现持久化的方式:
- 实现
com.esflink.starter.meta.MetaManager - 通过 Java spi 的方式加入你的实现类
通过下面这 4 步你就可以轻松实现对 MySQL 的 CDC。
<dependency>
<groupId>io.github.maskvvv</groupId>
<artifactId>easy-flink-cdc-boot-starter</artifactId>
<version>1.0.1</version>
</dependency>在 resources 路径下新建一个 easy-flink.conf 文件,语法为 typesafe.config。
ourea = {
name = "ourea"
hostname = "myserver.com"
port = "3308"
databaseList = "ourea"
tableList = "ourea.company,ourea.occupation"
username = "root"
password = "1234567788"
startupMode = "INITIAL"
}
athena = {
name = "athena"
hostname = "myserver.com"
port = "3308"
databaseList = "ourea"
tableList = "ourea.sort"
username = "root"
password = "1234567788"
startupMode = "INITIAL"
}
- name:于根名保持一致,一个根名对应着一个
Flink Job,不允许重名。 - hostname:需要监听的数据库域名
- port:需要监听的数据库端口号
- databaseList:需要监听的库名,多个用
,分开 - tableList:需要监听的表名,多个用
,分开 - username:数据库账号
- password:数据库密码
- startupMode:启动方式,如果有 cursor 存在,以 cursor 中优先。
- INITIAL: 初始化快照,即全量导入后增量导入(检测更新数据写入)
- LATEST: 只进行增量导入(不读取历史变化)
- TIMESTAMP: 指定时间戳进行数据导入(大于等于指定时间错读取数据)
application.properties
easy-flink.enable=true
easy-flink.meta-model=file
# zookeeper 模式
# easy-flink.zookeeper.address=127.0.0.1:21810
# easy-flink.meta-model=zookeeper启动类
@EasyFlinkScan("com.esflink.demo.sink")
@SpringBootApplication
public class EasyFlinkCdcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(EasyFlinkCdcDemoApplication.class, args);
}
}@EasyFlinkScan 注解指定 sink 类的存放路径,可以指定多个。
@FlinkSink(value = "ourea", database = "ourea", table = "ourea.company")
public class DemoSink implements FlinkJobSink {
@Override
public void invoke(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void insert(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void update(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void delete(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void handleError(DataChangeInfo value, Context context, Throwable throwable) {
}
}FlinkJobSink 接口
这里你需要实现 FlinkJobSink 接口并按照你的需求重写对应事件的方法。
insert()、update()、delete()方法:分别对应着 增、改、删 事件invoke()方法:增、改、删 事件都会调用改方法handleError(): 用来处理方法调用时出现的异常
@FlinkSink
当然你还要通过 @FlinkSink 注解标识这是一个 sink,该注解有以下属性
value:用来指定该 sink 是属于哪个 Flink Job,必须database:用来指定接收 Flink Job 中的哪些 数据库 的数据变化,默认为 Flink Job 中指定的,选填database:用来指定接收 Flink Job 的哪些 表 的数据变化,不填则为 Flink Job 中指定的,选填
总体上来讲封装一个简单易用的 CDC 框架这个目的已经基本达到了,但是由于自己是第一次封装框架,该框架还存在着许多问题,比如:
- 框架不够模块化
- 框架类分包混乱(主要我不知道咋分)
- 框架可拓展性不高,比如自定义拓展序列化方式、自定义配置文件加载方式等
- 配置文件的加载不支持分布式特性,现在只能加载本地配置文件,后续规划支持通过 nacos-config
- 项目启动时会如果有指定 cursor,会短暂阻塞数据库,所以建议指定从库进行监听
- 自已对 Flink CDC 的了解还不够深刻,可能有些情况还没考虑到
- 不保证 crash safe,需要做好代码的幂等性
- 同步性能方面,自己没有做过海量数据同步的测试,我是大概8000条数据同步到 ES 大约几分钟吧