Webhaking using by Google
this readme file use Korean sry:(
- 구글과 같은 검색엔진은 검색 연산자를 제공한다. 이 연산자를 통해서 사용자는 좀 더 쉽게 원하는 데이터를 검색할 수 있다. => 이 부분을 이용해 데이터를 찾는 기술!!!
- site 연산자를 이용하여 원하는 사이트에서만 자료를 찾을 수 있다. 다음과 같이 예시를 들 수 있다.
(원하는 검색어) site: (검색하고 싶은 사이트)
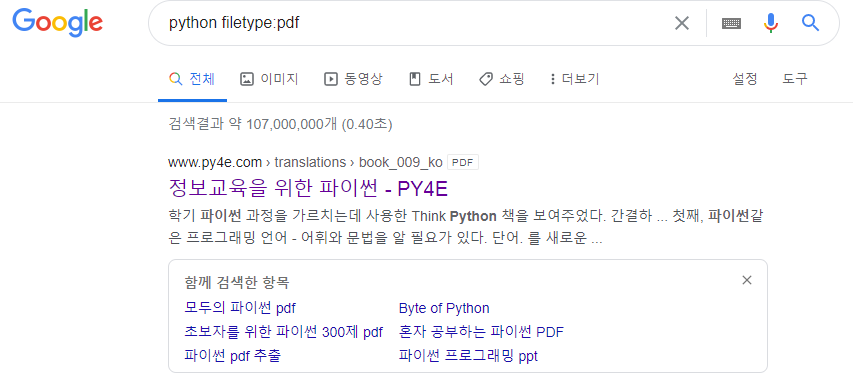
- filetype을 이용하면 원하는 파일 확장자를 찾을 수 있다. 다음과 같이 예시를 들 수 있다
(원하는 검색어) filetype:pdf
- cache 라는 연산자를 이용하여 이미 삭제된 페이지도 조회할 수 있다.
- 어떻게 이게 되는걸까? : 구글의 검색봇은 수시로 데이터를 읽어와 서버에 저장하는데 해당 페이지가 삭제되거나 이전되어도 데이터베이스에는 해당 페이지의 정보가 남아있다.
-다음과 같이 쓸 수 있다.
cache: (원하는 주소)
- 다음은 주요 검색 연산자이다 그냥 알아두자
- cache:[URL]
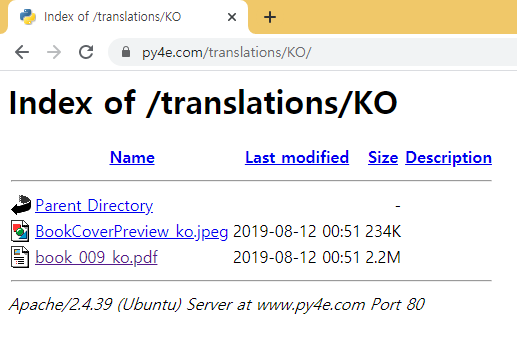
index of - Directory Listing 취약점, 즉 Directory Browsing이 Enabled 된 페이지만 찾습니다.
- index of
intitle - 타이틀 내 해당하는 문자열을 찾습니다.
- intitle:[STRING]
inurl - URL 내 해당하는 문자열을 찾습니다.
- inurl:[STRING]
site - 해당 사이트의 페이지만 찾습니다.
- site:[URL]
이외 연산자 참고 사이트
https://support.google.com/websearch/answer/2466433?hl=ko&ref_topic=3081620
- 해당 사이트를 쉽고 빠르게 찾아내어 해당 서버에 대한 정보를 빠르게 조회 및 취약점을 찾아 낼 수 있다.
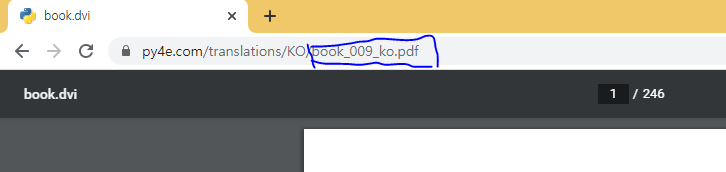
- 다음은 글쓴이가 구글 해킹을 이용해 무작위로 웹페이지에 들어가서 서버 내 파일을
뒤져보는사진이다.