{kind=link}
This project will include the files to create and define tables for a database with a star schema by data modeling with postgres. It also contains files to build an ETL pipeline which will allow the client to access and analyze the information that they have been collecting.
The transformation of this data (extracted by JSON logs that the clients have been collecting over some time) will allow them to analyze and to extract new relevant information which can help their decision-making process on future options regarding marketing, store availability...
Having this information available with queries is a powerful tool that will give the client plenty of flexibility.
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song's track ID. Here is an example of a filepath: "song_data/A/B/C/TRABCEI128F424C983.json" And here is an example of one of the json files: {"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations. Here is an example of a filepath: "log_data/2018/11/2018-11-12-events.json" And here is an example of a json file for these events: {"artist": "None", "auth": "Logged In", "gender": "F", "itemInSession": 0, "lastName": "Williams", "length": "227.15873", "level": "free", "location": "Klamath Falls OR", "method": "GET", "page": "Home", "registration": "1.541078e-12", "sessionId": "438", "Song": "None", "status": "200", "ts": "15465488945234", "userAgent": "Mozilla/5.0(WindowsNT,6.1;WOW641)", "userId": "53"}
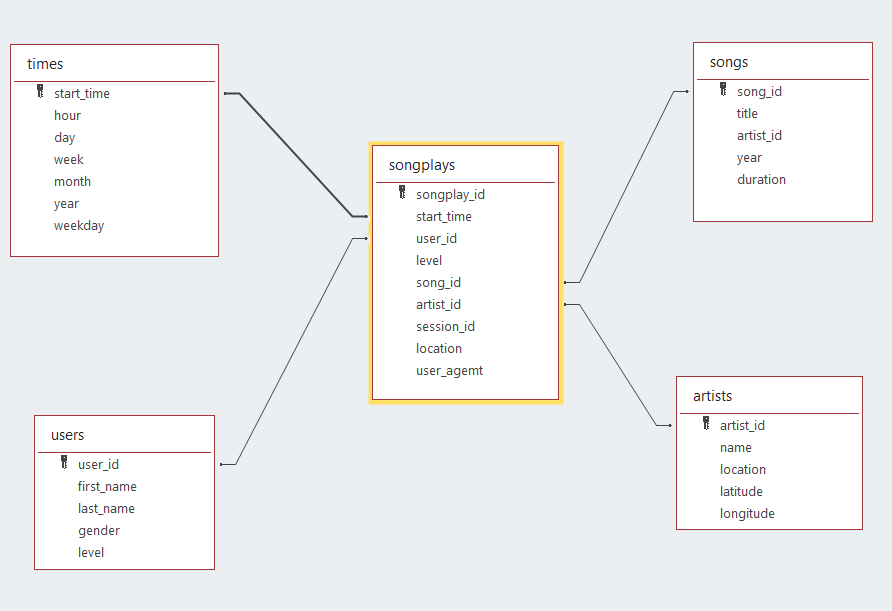
The star schema that is going to be created using this program will have the next structure:
- Fact table:
- songplays [songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent]
- Dimension tables:
- users [user_id, first_name, last_name, gender, level]
- songs [song_id, title, artist_id, year, duration]
- artist [artist_id, name, location, lattitude, longitude]
- time [start_time, hour, day, week, month, year, weekday]
This file creates the connection to the default database and in addition creates and connects to the sparkify database where our tables will contain the processed information by the ETL Pipeline which will allow us to query the information easily to analyze it (That's why before executing etl.py file you must use this to make the connection and create the tables).
These files contains the functions imported by the file create_tables.py which will allow to Drop old tables and Create new ones to and also, to Insert data into them.
It also includes a function (song_select) for the songplays table to find the userid and the songid for specific songs.
With this code we will perform the first connection to the databes and we'll test the functions previously mentioned to see if we can insert data in the tables without getting errors or if we get the desired outcome without unexpected results. For that we wil process a single file from song_data and log_data to load them into our tables.
With this file we will process all files from song_data and log_data
This file will allow us to test our results and to check if all the connections and insertions where performed correctly.
Some examples:
In case I want to test how many songs in the "songplay list" do we have in our "song list"
%sql SELECT * FROM songplays WHERE song_id != 'None' LIMIT 5;
If we want to check which are 'paid' level
%sql SELECT * FROM songplays WHERE level = 'paid';
If we want to find a specific song by its songid
%sql SELECT * FROM songs WHERE song_id = 'SOZCTXZ12AB0182364';
If we want to know which songs are from the year 2008
%sql SELECT * FROM songs WHERE year = '2008';
Udacity provided the template and the guidelines to start this project. The completion of this was made by Guillermo Garcia and the review of the program and the verification that the project followed the proper procedures was also made by my mentor from udacity.