{kind=link}
This is a implemenation of the Hidden-Markov-Model and the Viterbi algorithm. As input the program is expecting a set of files with one sentence in each line. We have an example corpus in our directory.
First, the program builds for the Hidden-Markov-Model an emission and a transition matrix one the basis of the trainings corpus.
Second, the Viterbi algotithm does it's magic. It works with the matrices based on the training corpus and predicts the tags for each word in a sentence.
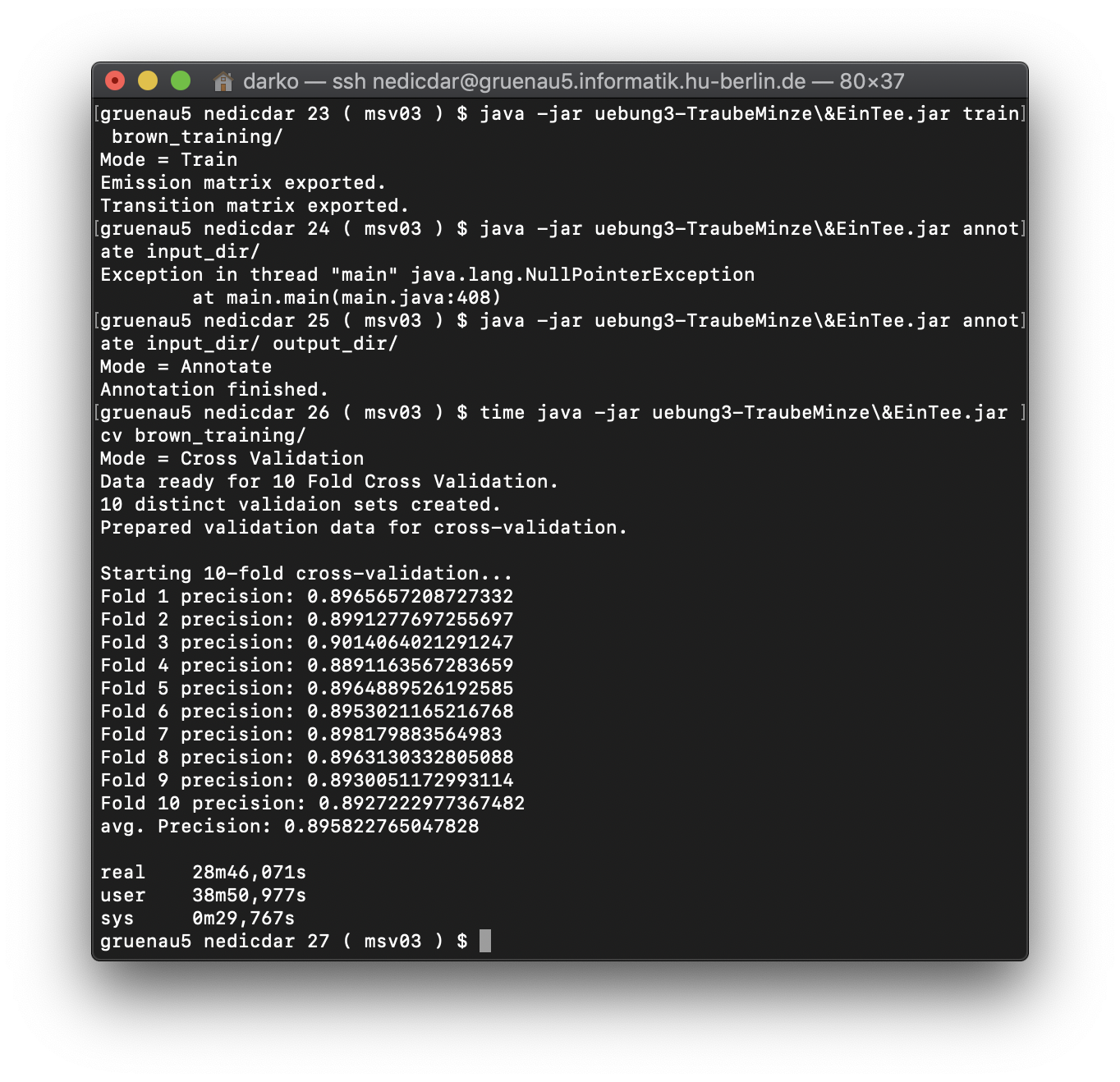
With 10-fold cross-validation on our corpus we got our precision. Our aim/task was to reach at least 66% precision.
Here is what we got:
| Fold | Precision |
|---|---|
| Fold 1 | 0.8965657208727332 |
| Fold 2 | 0.8991277697255697 |
| Fold 3 | 0.9014064021291247 |
| Fold 4 | 0.8891163567283659 |
| Fold 5 | 0.8964889526192585 |
| Fold 6 | 0.8953021165216768 |
| Fold 7 | 0.898179883564983 |
| Fold 8 | 0.8963130332805088 |
| Fold 9 | 0.8930051172993114 |
| Fold 10 | 0.8927222977367482 |
| avg. Precision | 0.895822765047828 |
|---|