The focus of this project is toharvest tweets from Melbourne on the MRC and undertake a variety of social media data analytics scenarios that explore liveability of Melbourne and importantly how the Twitter data can be used alongside/compared with/augment the data available within the AURIN platform to improve our knowledge of the liveability of Melbourne
This project is a Cloud-based solution that exploits a multitude of virtual machines (VMs) across the MRC for harvesting tweets through the Twitter APIs (using both the Streaming and the Search API interfaces).
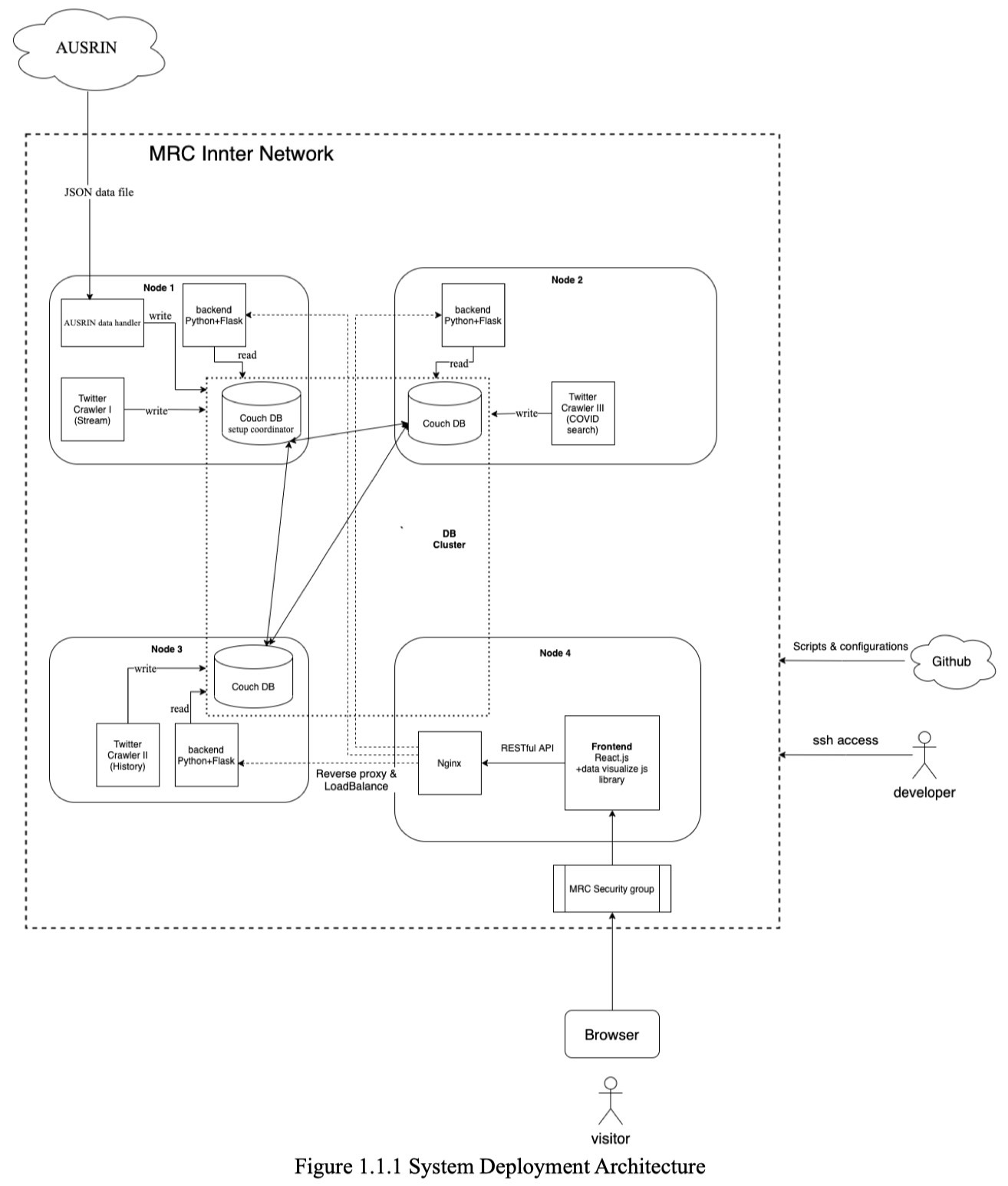
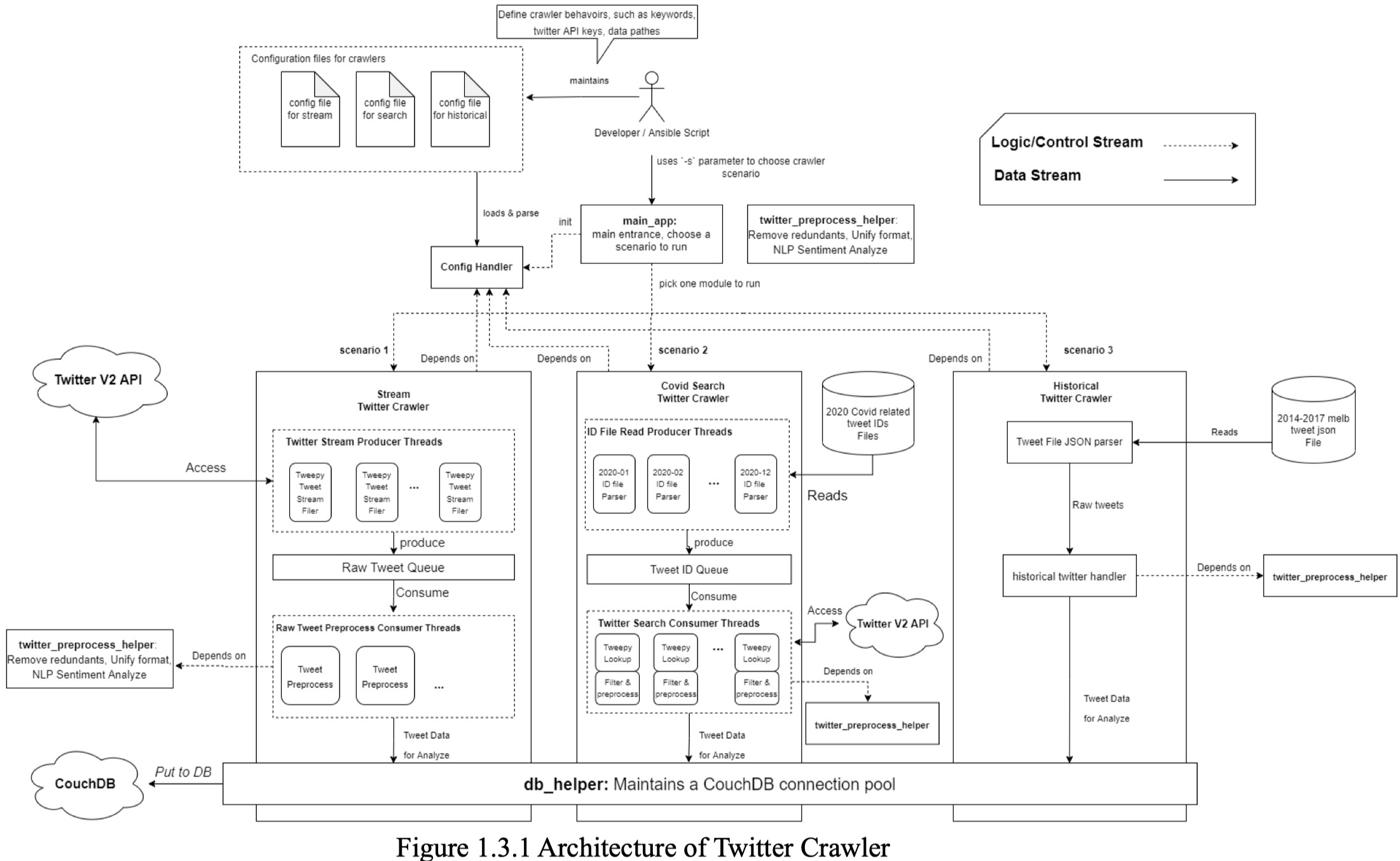
We have produce a solution that can be run (in principle) across any node of the MRC to harvest and store tweets and scale up/down as required. The solution includes multiple Twitter harvesting applications for Melbourne, These harvesting application running on the MRC together with an associated CouchDB database containing the amalgamated collection of Tweets. The CouchDB setup is based on a cluster setup.
- Python + Flask
- Tweepy
- CouchDB
- React.js
- Docker
- Nginx
- NLTK + TextBlob
34/40
You will get your individual scores thru Canvas in due course:
The report seems a bit rushed in places: AUSRIN, Innter Network, As is shown in Figure 1.1 (not 1.1.1) etc etc. The architecture itself looks fine and it was good that you had a 3 node couchDB cluster. Nice that you have a Restful API. (Not sure why you showed the openRC.sh file in your report or the Cloud dashboard). The discussion of the pros and cons of MRC is ok, but you could have provided more insights based on your practical experiences of using it. The multi-functional Twitter crawler was quite complex but good that you did more than just used the search/stream API in a basic way as most teams did. The parsing of tweets to get location data is not impossible, but it is certainly more difficult. Nice idea to use external data to help with your scenarios (old CV19 data etc). The Ansible work was extensive and generally well done, however your dynamic deployment using Ansible focused on the deployment of the entire system and not just the deployment of the additional resources needed for horizontal scaling, e.g. the harvester and code for processing of tweets and adding them to your couchDB database. Ideally you would have used a dictionary of terms as opposed to including them directly in the config files, e.g. key-word-list: covid, coronavirus etc. You might have looked at topic modelling since the emergence of terms would have helped, e.g. you might have also found CV19 or pandemic etc. That said, at least you had it in config files and not directly hardcoded in your Twitter harvester as many did. Looks like only 4 of your made commits to the git repo. It is good practice for everyone to be doing this. The front end was ok, but a but static/clunky in places (noting that this is a Cloud course and not an HCI course). Overall this was a very nice attempt.
Cheers, R. Prof. Richard O. Sinnott
MIT License
Copyright (c) 2022 COMP90024-2022 Group 52
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.