![]()
A generic image detection program that uses Google's Machine Learning library, Tensorflow and a pre-trained Deep Learning Convolutional Neural Network model called Inception.
This model has been pre-trained for the ImageNet Large Visual Recognition Challenge using the data from 2012, and it can differentiate between 1,000 different classes, like Dalmatian, dishwasher etc. The program applies Transfer Learning to this existing model and re-trains it to classify a new set of images.
This is a generic setup and can be used to classify almost any kind of image. I created a small demo that classifies two image data sets - cat and dog images, and returns a prediction score denoting the possibility of it being an image of a cat or a dog.
Make sure you have Python 3 installed, then install Tensorflow on your system, and clone this repo.
In order to start the transfer learning process, a folder named training_dataset needs to be created in the root of the project folder. This folder will contain the image data sets for all the subjects, for whom the classification is to be performed.
Create the training_dataset folder and add the images for all the data sets in the following manner -
/
|
|
---- /training_dataset
| |
| |
| ---- /cat
| | cat1.jpg
| | cat2.jpg
| | ...
| |
| |
| ---- /dog
| dog1.jpg
| dog2.jpg
| ...
|
| This enables classification of images between the cat and dog data sets.
Make sure to include multiple variants of the subject (side profiles, zoomed in images etc.), the more the images, the better is the result.
Go to the project directory and run -
$ bash train.shThis script installs the Inception model and initiates the re-training process for the specified image data sets.
Once the process is complete, it will return a training accuracy somewhere between 85% - 100%.
The training summaries, retrained graphs and retrained labels will be saved in a folder named tf_files.
python3 classify.pyThis opens up the file dialog using which you can select your input file.
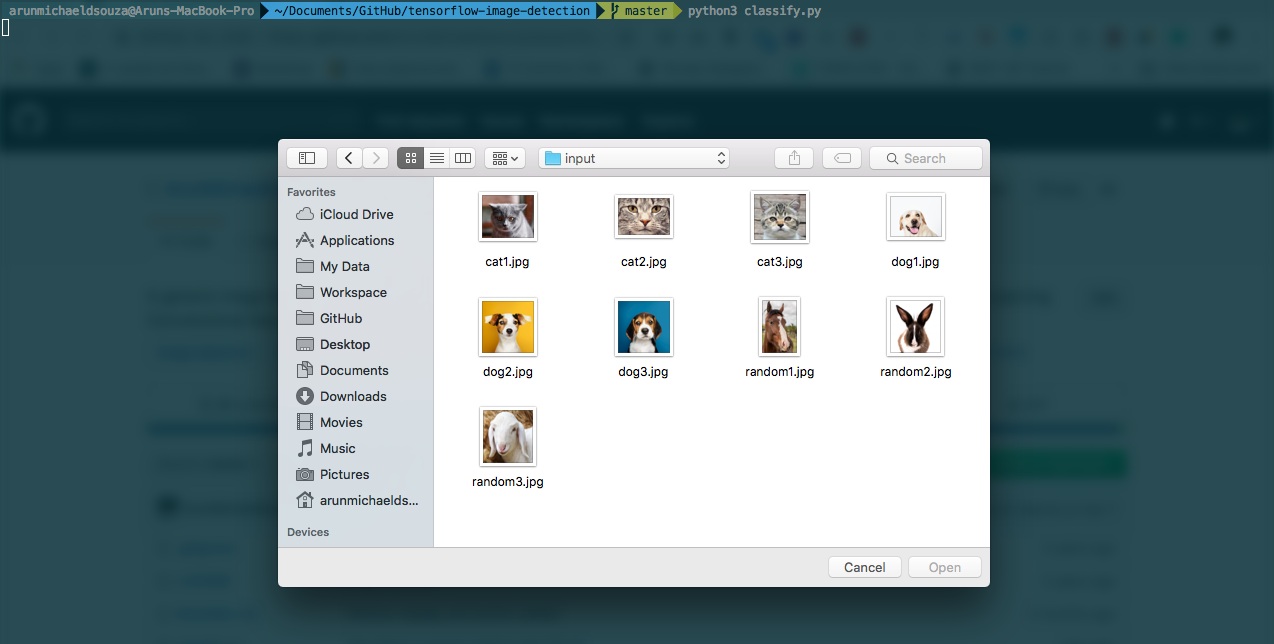
Once the input file is selected, the classifier will output the predictions for each data set. A prediction score between 0.8 to 1 is considered to be optimal.


 Arun Michael Dsouza |
 Royal Bhati |
|---|
If you'd like to help support the development of the project, please consider backing me on Patreon -

{kind=link}
{kind=link}
{kind=link}
{kind=link}
MIT License
Copyright (c) 2017 Arun Michael Dsouza
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
All training dataset and input images have been taken from freepik.com.