| title | tags | categories | keywords | description | cover | abbrlink | date | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
设计模式-04.02-结构型-门面&组合&享元 |
|
|
设计模式,门面模式,组合模式,享元模式 |
对代理模式,门面模式,组合模式,享元模式这3个设计模式进行了比较详细的讲述。 |
5ea604e0 |
2021-07-05 09:51:58 -0700 |
-
门面模式原理和实现都特别简单,应用场景也比较明确,主要在接口设计方面使用。
-
如果你平时的工作涉及接口开发,不知道你有没有遇到关于接口粒度的问题呢?
-
为了保证接口的可复用性(或者叫通用性),我们需要将接口尽量设计得细粒度一点,职责单一一点。但是,如果接口的粒度过小,在接口的使用者开发一个业务功能时,就会导致需要调用 n 多细粒度的接口才能完成。调用者肯定会抱怨接口不好用。
-
相反,如果接口粒度设计得太大,一个接口返回 n 多数据,要做 n 多事情,就会导致接口不够通用、可复用性不好。接口不可复用,那针对不同的调用者的业务需求,我们就需要开发不同的接口来满足,这就会导致系统的接口无限膨胀。
-
那如何来解决接口的可复用性(通用性)和易用性之间的矛盾呢?通过今天对于门面模式的学习,我想你心中会有答案。
- 门面模式,也叫外观模式,英文全称是 Facade Design Pattern。在 GoF 的《设计模式》一书中,门面模式是这样定义的:
Provide a unified interface to a set of interfaces in a subsystem. Facade Pattern defines a higher-level interface that makes the subsystem easier to use.
- 翻译成中文就是:门面模式为子系统提供一组统一的接口,定义一组高层接口让子系统更易用。这个定义很简洁,我再进一步解释一下。
- 假设有一个系统 A,提供了 a、b、c、d 四个接口。系统 B 完成某个业务功能,需要调用 A 系统的 a、b、d 接口。利用门面模式,我们提供一个包裹 a、b、d 接口调用的门面接口 x,给系统 B 直接使用。
- 不知道你会不会有这样的疑问,让系统 B 直接调用 a、b、d 感觉没有太大问题呀,为什么还要提供一个包裹 a、b、d 的接口 x 呢?关于这个问题,我通过一个具体的例子来解释一下。
- 假设我们刚刚提到的系统 A 是一个后端服务器,系统 B 是 App 客户端。App 客户端通过后端服务器提供的接口来获取数据。我们知道,App 和服务器之间是通过移动网络通信的,网络通信耗时比较多,为了提高 App 的响应速度,我们要尽量减少 App 与服务器之间的网络通信次数。
- 假设,完成某个业务功能(比如显示某个页面信息)需要“依次”调用 a、b、d 三个接口,因自身业务的特点,不支持并发调用这三个接口。
- 如果我们现在发现 App 客户端的响应速度比较慢,排查之后发现,是因为过多的接口调用过多的网络通信。针对这种情况,我们就可以利用门面模式,让后端服务器提供一个包裹 a、b、d 三个接口调用的接口 x。App 客户端调用一次接口 x,来获取到所有想要的数据,将网络通信的次数从 3 次减少到 1 次,也就提高了 App 的响应速度。
- 这里举的例子只是应用门面模式的其中一个意图,也就是解决性能问题。实际上,不同的应用场景下,使用门面模式的意图也不同。接下来,我们就来看一下门面模式的各种应用场景。
-
组建一个家庭影院:
-
DVD 播放器、投影仪、自动屏幕、环绕立体声、爆米花机,要求完成使用家庭影院的功能,其过程为:
-
直接用遥控器:统筹各设备开关
-
开爆米花机
-
放下屏幕
-
开投影仪
-
开音响
-
开 DVD,选 dvd
-
去拿爆米花
-
调暗灯光
-
播放
-
观影结束后,关闭各种设备
-
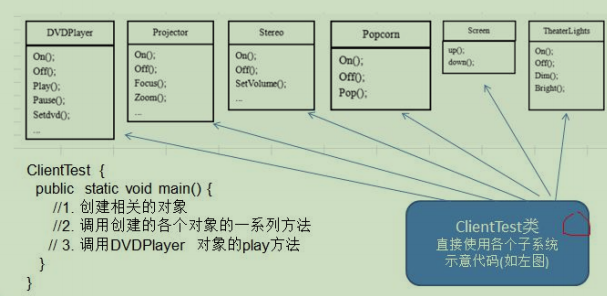
-
在 ClientTest 的 main 方法中,创建各个子系统的对象,并直接去调用子系统(对象)相关方法,会造成调用过程 混乱,没有清晰的过程 不利于在 ClientTest 中,去维护对子系统的操作
-
解决思路:定义一个高层接口,给子系统中的一组接口提供一个一致的界面(比如在高层接口提供四个方法 ready, play, pause, end ),用来访问子系统中的一群接口
-
也就是说 就是通过定义一个一致的接口(界面类),用以屏蔽内部子系统的细节,使得调用端只需跟这个接口发 生调用,而无需关心这个子系统的内部细节 => 外观模式
-
外观类(Facade): 为调用端提供统一的调用接口, 外观类知道哪些子系统负责处理请求,从而将调用端的请求代 理给适当子系统对象
-
调用者(Client): 外观接口的调用者
-
子系统的集合:指模块或者子系统,处理 Facade 对象指派的任务,他是功能的实际提供者
public class TheaterLight {
private static TheaterLight instance = new TheaterLight();
public static TheaterLight getInstance() {
return instance;
}
public void on() {
System.out.println(" TheaterLight on ");
}
public void off() {
System.out.println(" TheaterLight off ");
}
public void dim() {
System.out.println(" TheaterLight dim.. ");
}
public void bright() {
System.out.println(" TheaterLight bright.. ");
}
}public class Stereo {
private static Stereo instance = new Stereo();
public static Stereo getInstance() {
return instance;
}
public void on() {
System.out.println(" Stereo on ");
}
public void off() {
System.out.println(" Screen off ");
}
public void up() {
System.out.println(" Screen up.. ");
}
//...
}public class Screen {
private static Screen instance = new Screen();
public static Screen getInstance() {
return instance;
}
public void up() {
System.out.println(" Screen up ");
}
public void down() {
System.out.println(" Screen down ");
}
}public class Projector {
private static Projector instance = new Projector();
public static Projector getInstance() {
return instance;
}
public void on() {
System.out.println(" Projector on ");
}
public void off() {
System.out.println(" Projector ff ");
}
public void focus() {
System.out.println(" Projector is Projector ");
}
//...
}
public class Popcorn {
private static Popcorn instance = new Popcorn();
public static Popcorn getInstance() {
return instance;
}
public void on() {
System.out.println(" popcorn on ");
}
public void off() {
System.out.println(" popcorn ff ");
}
public void pop() {
System.out.println(" popcorn is poping ");
}
}
public class DVDPlayer {
//使用单例模式, 使用饿汉式
private static DVDPlayer instance = new DVDPlayer();
public static DVDPlayer getInstanc() {
return instance;
}
public void on() {
System.out.println(" dvd on ");
}
public void off() {
System.out.println(" dvd off ");
}
public void play() {
System.out.println(" dvd is playing ");
}
//....
public void pause() {
System.out.println(" dvd pause ..");
}
}
public class HomeTheaterFacade {
// 定义各个子系统对象
private TheaterLight theaterLight;
private Popcorn popcorn;
private Stereo stereo;
private Projector projector;
private Screen screen;
private DVDPlayer dVDPlayer;
// 构造器
public HomeTheaterFacade() {
super();
this.theaterLight = TheaterLight.getInstance();
this.popcorn = Popcorn.getInstance();
this.stereo = Stereo.getInstance();
this.projector = Projector.getInstance();
this.screen = Screen.getInstance();
this.dVDPlayer = DVDPlayer.getInstanc();
}
// 操作分成 4 步
public void ready() {
popcorn.on();
popcorn.pop();
screen.down();
projector.on();
stereo.on();
dVDPlayer.on();
theaterLight.dim();
}
public void play() {
dVDPlayer.play();
}
public void pause() {
dVDPlayer.pause();
}
public void end() {
popcorn.off();
theaterLight.bright();
screen.up();
projector.off();
stereo.off();
dVDPlayer.off();
}
}public class Client {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 这里直接调用。。 很麻烦
HomeTheaterFacade homeTheaterFacade = new HomeTheaterFacade();
homeTheaterFacade.ready();
homeTheaterFacade.play();
homeTheaterFacade.end();
}
}- 在 GoF 给出的定义中提到,“门面模式让子系统更加易用”,实际上,它除了解决易用性问题之外,还能解决其他很多方面的问题。关于这一点,我总结罗列了 3 个常用的应用场景,你可以参考一下,举一反三地借鉴到自己的项目中。
- 除此之外,我还要强调一下,门面模式定义中的“子系统(subsystem)”也可以有多种理解方式。它既可以是一个完整的系统,也可以是更细粒度的类或者模块。关于这一点,在下面的讲解中也会有体现。
- 门面模式可以用来封装系统的底层实现,隐藏系统的复杂性,提供一组更加简单易用、更高层的接口。比如,Linux 系统调用函数就可以看作一种“门面”。它是 Linux 操作系统暴露给开发者的一组“特殊”的编程接口,它封装了底层更基础的 Linux 内核调用。再比如,Linux 的 Shell 命令,实际上也可以看作一种门面模式的应用。它继续封装系统调用,提供更加友好、简单的命令,让我们可以直接通过执行命令来跟操作系统交互。
- 我们前面也多次讲过,设计原则、思想、模式很多都是相通的,是同一个道理不同角度的表述。实际上,从隐藏实现复杂性,提供更易用接口这个意图来看,门面模式有点类似之前讲到的迪米特法则(最少知识原则)和接口隔离原则:两个有交互的系统,只暴露有限的必要的接口。除此之外,门面模式还有点类似之前提到封装、抽象的设计思想,提供更抽象的接口,封装底层实现细节。
- 关于利用门面模式解决性能问题这一点,刚刚我们已经讲过了。我们通过将多个接口调用替换为一个门面接口调用,减少网络通信成本,提高 App 客户端的响应速度。所以,关于这点,我就不再举例说明了。我们来讨论一下这样一个问题:从代码实现的角度来看,该如何组织门面接口和非门面接口?
- 如果门面接口不多,我们完全可以将它跟非门面接口放到一块,也不需要特殊标记,当作普通接口来用即可。如果门面接口很多,我们可以在已有的接口之上,再重新抽象出一层,专门放置门面接口,从类、包的命名上跟原来的接口层做区分。如果门面接口特别多,并且很多都是跨多个子系统的,我们可以将门面接口放到一个新的子系统中。
- 关于利用门面模式来解决分布式事务问题,我们通过一个例子来解释一下。
- 在一个金融系统中,有两个业务领域模型,用户和钱包。这两个业务领域模型都对外暴露了一系列接口,比如用户的增删改查接口、钱包的增删改查接口。假设有这样一个业务场景:在用户注册的时候,我们不仅会创建用户(在数据库 User 表中),还会给用户创建一个钱包(在数据库的 Wallet 表中)。
- 对于这样一个简单的业务需求,我们可以通过依次调用用户的创建接口和钱包的创建接口来完成。但是,用户注册需要支持事务,也就是说,创建用户和钱包的两个操作,要么都成功,要么都失败,不能一个成功、一个失败。
- 要支持两个接口调用在一个事务中执行,是比较难实现的,这涉及分布式事务问题。虽然我们可以通过引入分布式事务框架或者事后补偿的机制来解决,但代码实现都比较复杂。而最简单的解决方案是,利用数据库事务或者 Spring 框架提供的事务(如果是 Java 语言的话),在一个事务中,执行创建用户和创建钱包这两个 SQL 操作。这就要求两个 SQL 操作要在一个接口中完成,所以,我们可以借鉴门面模式的思想,再设计一个包裹这两个操作的新接口,让新接口在一个事务中执行两个 SQL 操作。
- 组合模式跟我们之前讲的面向对象设计中的“组合关系(通过组合来组装两个类)”,完全是两码事。这里讲的“组合模式”,主要是用来处理树形结构数据。这里的“数据”,你可以简单理解为一组对象集合,待会我们会详细讲解。
- 正因为其应用场景的特殊性,数据必须能表示成树形结构,这也导致了这种模式在实际的项目开发中并不那么常用。但是,一旦数据满足树形结构,应用这种模式就能发挥很大的作用,能让代码变得非常简洁。
- 在 GoF 的《设计模式》一书中,组合模式是这样定义的:
Compose objects into tree structure to represent part-whole hierarchies.Composite lets client treat individual objects and compositions of objects uniformly.
-
翻译成中文就是:将一组对象组织(Compose)成树形结构,以表示一种“部分 - 整体”的层次结构。组合让客户端(在很多设计模式书籍中,“客户端”代指代码的使用者。)可以统一单个对象和组合对象的处理逻辑。接下来,对于组合模式,我举个例子来给你解释一下。
-
假设我们有这样一个需求:设计一个类来表示文件系统中的目录,能方便地实现下面这些功能:
-
动态地添加、删除某个目录下的子目录或文件;
-
统计指定目录下的文件个数;
-
统计指定目录下的文件总大小。
- 我这里给出了这个类的骨架代码,如下所示。其中的核心逻辑并未实现,你可以试着自己去补充完整,再来看我的讲解。在下面的代码实现中,我们把文件和目录统一用 FileSystemNode 类来表示,并且通过 isFile 属性来区分。
public class FileSystemNode {
private String path;
private boolean isFile;
private List<FileSystemNode> subNodes = new ArrayList<>();
public FileSystemNode(String path, boolean isFile) {
this.path = path;
this.isFile = isFile;
}
public int countNumOfFiles() {
// TODO:...
}
public long countSizeOfFiles() {
// TODO:...
}
public String getPath() {
return path;
}
public void addSubNode(FileSystemNode fileOrDir) {
subNodes.add(fileOrDir);
}
public void removeSubNode(FileSystemNode fileOrDir) {
int size = subNodes.size();
int i = 0;
for (; i < size; ++i) {
if (subNodes.get(i).getPath().equalsIgnoreCase(fileOrDir.getPath())) {
break;
}
}
if (i < size) {
subNodes.remove(i);
}
}
}想要补全其中的 countNumOfFiles() 和 countSizeOfFiles() 这两个函数,并不是件难事,实际上这就是树上的递归遍历算法。对于文件,我们直接返回文件的个数(返回 1)或大小。对于目录,我们遍历目录中每个子目录或者文件,递归计算它们的个数或大小,然后求和,就是这个目录下的文件个数和文件大小。
public int countNumOfFiles() {
if (isFile) {
return 1;
}
int numOfFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
numOfFiles += fileOrDir.countNumOfFiles();
}
return numOfFiles;
}
public long countSizeOfFiles() {
if (isFile) {
File file = new File(path);
if (!file.exists()) return 0;
return file.length();
}
long sizeofFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
sizeofFiles += fileOrDir.countSizeOfFiles();
}
return sizeofFiles;
}单纯从功能实现角度来说,上面的代码没有问题,已经实现了我们想要的功能。但是,如果我们开发的是一个大型系统,从扩展性(文件或目录可能会对应不同的操作)、业务建模(文件和目录从业务上是两个概念)、代码的可读性(文件和目录区分对待更加符合人们对业务的认知)的角度来说,我们最好对文件和目录进行区分设计,定义为 File 和 Directory 两个类。
按照这个设计思路,我们对代码进行重构。重构之后的代码如下所示:
public abstract class FileSystemNode {
protected String path;
public FileSystemNode(String path) {
this.path = path;
}
public abstract int countNumOfFiles();
public abstract long countSizeOfFiles();
public String getPath() {
return path;
}
}
public class File extends FileSystemNode {
public File(String path) {
super(path);
}
@Override
public int countNumOfFiles() {
return 1;
}
@Override
public long countSizeOfFiles() {
java.io.File file = new java.io.File(path);
if (!file.exists()) return 0;
return file.length();
}
}
public class Directory extends FileSystemNode {
private List<FileSystemNode> subNodes = new ArrayList<>();
public Directory(String path) {
super(path);
}
@Override
public int countNumOfFiles() {
int numOfFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
numOfFiles += fileOrDir.countNumOfFiles();
}
return numOfFiles;
}
@Override
public long countSizeOfFiles() {
long sizeofFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
sizeofFiles += fileOrDir.countSizeOfFiles();
}
return sizeofFiles;
}
public void addSubNode(FileSystemNode fileOrDir) {
subNodes.add(fileOrDir);
}
public void removeSubNode(FileSystemNode fileOrDir) {
int size = subNodes.size();
int i = 0;
for (; i < size; ++i) {
if (subNodes.get(i).getPath().equalsIgnoreCase(fileOrDir.getPath())) {
break;
}
}
if (i < size) {
subNodes.remove(i);
}
}
}文件和目录类都设计好了,我们来看,如何用它们来表示一个文件系统中的目录树结构。具体的代码示例如下所示:
public class Demo {
public static void main(String[] args) {
/**
* /
*
* <p>/wz/
*
* <p>/wz/a.txt
*
* <p>/wz/b.txt
*
* <p>/wz/movies/
*
* <p>/wz/movies/c.avi
*
* <p>/xzg/
*
* <p>/xzg/docs/
*
* <p>/xzg/docs/d.txt
*/
Directory fileSystemTree = new Directory("/");
Directory node_wz = new Directory("/wz/");
Directory node_xzg = new Directory("/xzg/");
fileSystemTree.addSubNode(node_wz);
fileSystemTree.addSubNode(node_xzg);
File node_wz_a = new File("/wz/a.txt");
File node_wz_b = new File("/wz/b.txt");
Directory node_wz_movies = new Directory("/wz/movies/");
node_wz.addSubNode(node_wz_a);
node_wz.addSubNode(node_wz_b);
node_wz.addSubNode(node_wz_movies);
File node_wz_movies_c = new File("/wz/movies/c.avi");
node_wz_movies.addSubNode(node_wz_movies_c);
Directory node_xzg_docs = new Directory("/xzg/docs/");
node_xzg.addSubNode(node_xzg_docs);
File node_xzg_docs_d = new File("/xzg/docs/d.txt");
node_xzg_docs.addSubNode(node_xzg_docs_d);
System.out.println("/ files num:" + fileSystemTree.countNumOfFiles());
System.out.println("/wz/ files num:" + node_wz.countNumOfFiles());
}
}- 我们对照着这个例子,再重新看一下组合模式的定义:“将一组对象(文件和目录)组织成树形结构,以表示一种‘部分 - 整体’的层次结构(目录与子目录的嵌套结构)。组合模式让客户端可以统一单个对象(文件)和组合对象(目录)的处理逻辑(递归遍历)。”
- 实际上,刚才讲的这种组合模式的设计思路,与其说是一种设计模式,倒不如说是对业务场景的一种数据结构和算法的抽象。其中,数据可以表示成树这种数据结构,业务需求可以通过在树上的递归遍历算法来实现。
- 刚刚我们讲了文件系统的例子,对于组合模式,我这里再举一个例子。搞懂了这两个例子,你基本上就算掌握了组合模式。在实际的项目中,遇到类似的可以表示成树形结构的业务场景,你只要“照葫芦画瓢”去设计就可以了。
- 假设我们在开发一个 OA 系统(办公自动化系统)。公司的组织结构包含部门和员工两种数据类型。其中,部门又可以包含子部门和员工。在数据库中的表结构如下所示:
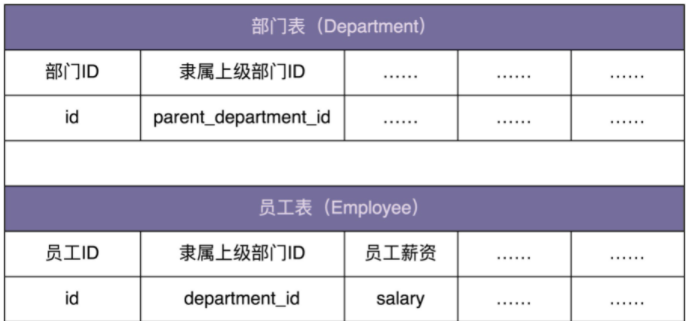
{kind=link}
- 我们希望在内存中构建整个公司的人员架构图(部门、子部门、员工的隶属关系),并且提供接口计算出部门的薪资成本(隶属于这个部门的所有员工的薪资和)。
- 部门包含子部门和员工,这是一种嵌套结构,可以表示成树这种数据结构。计算每个部门的薪资开支这样一个需求,也可以通过在树上的遍历算法来实现。所以,从这个角度来看,这个应用场景可以使用组合模式来设计和实现。
- 这个例子的代码结构跟上一个例子的很相似,代码实现我直接贴在了下面,你可以对比着看一下。其中,HumanResource 是部门类(Department)和员工类(Employee)抽象出来的父类,为的是能统一薪资的处理逻辑。Demo 中的代码负责从数据库中读取数据并在内存中构建组织架构图。
public abstract class HumanResource {
protected long id;
protected double salary;
public HumanResource(long id) {
this.id = id;
}
public long getId() {
return id;
}
public abstract double calculateSalary();
}
public class Employee extends HumanResource {
public Employee(long id, double salary) {
super(id);
this.salary = salary;
}
@Override
public double calculateSalary() {
return salary;
}
}
public class Department extends HumanResource {
private List<HumanResource> subNodes = new ArrayList<>();
public Department(long id) {
super(id);
}
@Override
public double calculateSalary() {
double totalSalary = 0;
for (HumanResource hr : subNodes) {
totalSalary += hr.calculateSalary();
}
this.salary = totalSalary;
return totalSalary;
}
public void addSubNode(HumanResource hr) {
subNodes.add(hr);
}
}
// 构建组织架构的代码
public class Demo {
private static final long ORGANIZATION\_ROOT\_ID = 1001;
private DepartmentRepo departmentRepo; // 依赖注入
private EmployeeRepo employeeRepo; // 依赖注入
public void buildOrganization() {
Department rootDepartment = new Department(ORGANIZATION\_ROOT\_ID);
buildOrganization(rootDepartment);
}
private void buildOrganization(Department department) {
List<Long> subDepartmentIds = departmentRepo.getSubDepartmentIds(department.getId());
for (Long subDepartmentId : subDepartmentIds) {
Department subDepartment = new Department(subDepartmentId);
department.addSubNode(subDepartment);
buildOrganization(subDepartment);
}
List<Long> employeeIds = employeeRepo.getDepartmentEmployeeIds(department.getId());
for (Long employeeId : employeeIds) {
double salary = employeeRepo.getEmployeeSalary(employeeId);
department.addSubNode(new Employee(employeeId, salary));
}
}
}我们再拿组合模式的定义跟这个例子对照一下:“将一组对象(员工和部门)组织成树形结构,以表示一种‘部分 - 整体’的层次结构(部门与子部门的嵌套结构)。组合模式让客户端可以统一单个对象(员工)和组合对象(部门)的处理逻辑(递归遍历)。”
跟其他所有的设计模式类似,享元模式的原理和实现也非常简单。今天,我会通过棋牌游戏和文本编辑器两个实际的例子来讲解。除此之外,我还会讲到它跟单例、缓存、对象池的区别和联系。在后面一下享元模式在 Java Integer、String 中的应用。
- 所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
- 具体来讲,当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,我们就可以利用享元模式将对象设计成享元,在内存中只保留一份实例,供多处代码引用。这样可以减少内存中对象的数量,起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段)提取出来,设计成享元,让这些大量相似对象引用这些享元。
- 这里我稍微解释一下,定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。所以,不可变对象不能暴露任何 set() 等修改内部状态的方法。之所以要求享元是不可变对象,那是因为它会被多处代码共享使用,避免一处代码对享元进行了修改,影响到其他使用它的代码。
- 接下来,我们通过一个简单的例子解释一下享元模式。
- 假设我们在开发一个棋牌游戏(比如象棋)。一个游戏厅中有成千上万个“房间”,每个房间对应一个棋局。棋局要保存每个棋子的数据,比如:棋子类型(将、相、士、炮等)、棋子颜色(红方、黑方)、棋子在棋局中的位置。利用这些数据,我们就能显示一个完整的棋盘给玩家。具体的代码如下所示。其中,ChessPiece 类表示棋子,ChessBoard 类表示一个棋局,里面保存了象棋中 30 个棋子的信息。
public class ChessPiece { // 棋子
private int id;
private String text;
private Color color;
private int positionX;
private int positionY;
public ChessPiece(int id, String text, Color color, int positionX, int positionY) {
this.id = id;
this.text = text;
this.color = color;
this.positionX = positionX;
this.positionY = positionX;
}
public static enum Color {
RED,
BLACK
}
// ...省略其他属性和getter/setter方法...
}
public class ChessBoard { // 棋局
private Map<Integer, ChessPiece> chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(1, "車", ChessPiece.Color.BLACK, 0, 0));
chessPieces.put(2, new ChessPiece(2, "馬", ChessPiece.Color.BLACK, 0, 1));
// ...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
// ...省略...
}
}为了记录每个房间当前的棋局情况,我们需要给每个房间都创建一个 ChessBoard 棋局对象。因为游戏大厅中有成千上万的房间(实际上,百万人同时在线的游戏大厅也有很多),那保存这么多棋局对象就会消耗大量的内存。有没有什么办法来节省内存呢?
这个时候,享元模式就可以派上用场了。像刚刚的实现方式,在内存中会有大量的相似对象。这些相似对象的 id、text、color 都是相同的,唯独 positionX、positionY 不同。实际上,我们可以将棋子的 id、text、color 属性拆分出来,设计成独立的类,并且作为享元供多个棋盘复用。这样,棋盘只需要记录每个棋子的位置信息就可以了。具体的代码实现如下所示:
// 享元类
public class ChessPieceUnit {
private int id;
private String text;
private Color color;
public ChessPieceUnit(int id, String text, Color color) {
this.id = id;
this.text = text;
this.color = color;
}
public static enum Color {
RED,
BLACK
}
// ...省略其他属性和getter方法...
}
public class ChessPieceUnitFactory {
private static final Map<Integer, ChessPieceUnit> pieces = new HashMap<>();
static {
pieces.put(1, new ChessPieceUnit(1, "車", ChessPieceUnit.Color.BLACK));
pieces.put(2, new ChessPieceUnit(2, "馬", ChessPieceUnit.Color.BLACK));
// ...省略摆放其他棋子的代码...
}
public static ChessPieceUnit getChessPiece(int chessPieceId) {
return pieces.get(chessPieceId);
}
}
public class ChessPiece {
private ChessPieceUnit chessPieceUnit;
private int positionX;
private int positionY;
public ChessPiece(ChessPieceUnit unit, int positionX, int positionY) {
this.chessPieceUnit = unit;
this.positionX = positionX;
this.positionY = positionY;
}
// 省略getter、setter方法
}
public class ChessBoard {
private Map<Integer, ChessPiece> chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(ChessPieceUnitFactory.getChessPiece(1), 0, 0));
chessPieces.put(1, new ChessPiece(ChessPieceUnitFactory.getChessPiece(2), 1, 0));
// ...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
// ...省略...
}
}- 在上面的代码实现中,我们利用工厂类来缓存 ChessPieceUnit 信息(也就是 id、text、color)。通过工厂类获取到的 ChessPieceUnit 就是享元。所有的 ChessBoard 对象共享这 30 个 ChessPieceUnit 对象(因为象棋中只有 30 个棋子)。在使用享元模式之前,记录 1 万个棋局,我们要创建 30 万(30*1 万)个棋子的 ChessPieceUnit 对象。利用享元模式,我们只需要创建 30 个享元对象供所有棋局共享使用即可,大大节省了内存。
- 那享元模式的原理讲完了,我们来总结一下它的代码结构。实际上,它的代码实现非常简单,主要是通过工厂模式,在工厂类中,通过一个 Map 来缓存已经创建过的享元对象,来达到复用的目的。
- 弄懂了享元模式的原理和实现之后,我们再来看另外一个例子,也就是文章标题中给出的:如何利用享元模式来优化文本编辑器的内存占用?
- 你可以把这里提到的文本编辑器想象成 Office 的 Word。不过,为了简化需求背景,我们假设这个文本编辑器只实现了文字编辑功能,不包含图片、表格等复杂的编辑功能。对于简化之后的文本编辑器,我们要在内存中表示一个文本文件,只需要记录文字和格式两部分信息就可以了,其中,格式又包括文字的字体、大小、颜色等信息。
- 尽管在实际的文档编写中,我们一般都是按照文本类型(标题、正文……)来设置文字的格式,标题是一种格式,正文是另一种格式等等。但是,从理论上讲,我们可以给文本文件中的每个文字都设置不同的格式。为了实现如此灵活的格式设置,并且代码实现又不过于太复杂,我们把每个文字都当作一个独立的对象来看待,并且在其中包含它的格式信息。具体的代码示例如下所示:
public class Character { // 文字
private char c;
private Font font;
private int size;
private int colorRGB;
public Character(char c, Font font, int size, int colorRGB) {
this.c = c;
this.font = font;
this.size = size;
this.colorRGB = colorRGB;
}
}
public class Editor {
private List<Character> chars = new ArrayList<>();
public void appendCharacter(char c, Font font, int size, int colorRGB) {
Character character = new Character(c, font, size, colorRGB);
chars.add(character);
}
}- 在文本编辑器中,我们每敲一个文字,都会调用 Editor 类中的 appendCharacter() 方法,创建一个新的 Character 对象,保存到 chars 数组中。如果一个文本文件中,有上万、十几万、几十万的文字,那我们就要在内存中存储这么多 Character 对象。那有没有办法可以节省一点内存呢?
- 实际上,在一个文本文件中,用到的字体格式不会太多,毕竟不大可能有人把每个文字都设置成不同的格式。所以,对于字体格式,我们可以将它设计成享元,让不同的文字共享使用。按照这个设计思路,我们对上面的代码进行重构。重构后的代码如下所示:
public class CharacterStyle {
private Font font;
private int size;
private int colorRGB;
public CharacterStyle(Font font, int size, int colorRGB) {
this.font = font;
this.size = size;
this.colorRGB = colorRGB;
}
@Override
public boolean equals(Object o) {
CharacterStyle otherStyle = (CharacterStyle) o;
return font.equals(otherStyle.font)
&& size == otherStyle.size
&& colorRGB == otherStyle.colorRGB;
}
}
public class CharacterStyleFactory {
private static final List<CharacterStyle> styles = new ArrayList<>();
public static CharacterStyle getStyle(Font font, int size, int colorRGB) {
CharacterStyle newStyle = new CharacterStyle(font, size, colorRGB);
for (CharacterStyle style : styles) {
if (style.equals(newStyle)) {
return style;
}
}
styles.add(newStyle);
return newStyle;
}
}
public class Character {
private char c;
private CharacterStyle style;
public Character(char c, CharacterStyle style) {
this.c = c;
this.style = style;
}
}
public class Editor {
private List<Character> chars = new ArrayList<>();
public void appendCharacter(char c, Font font, int size, int colorRGB) {
Character character = new Character(c, CharacterStyleFactory.getStyle(font, size, colorRGB));
chars.add(character);
}
}在上面的讲解中,我们多次提到“共享”“缓存”“复用”这些字眼,那它跟单例、缓存、对象池这些概念有什么区别呢?我们来简单对比一下。
- 在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。实际上,享元模式有点类似于之前讲到的单例的变体:多例。
- 我们前面也多次提到,区别两种设计模式,不能光看代码实现,而是要看设计意图,也就是要解决的问题。尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用多例模式是为了限制对象的个数。
在享元模式的实现中,我们通过工厂类来“缓存”已经创建好的对象。这里的“缓存”实际上是“存储”的意思,跟我们平时所说的“数据库缓存”“CPU 缓存”“MemCache 缓存”是两回事。我们平时所讲的缓存,主要是为了提高访问效率,而非复用。
- 对象池、连接池(比如数据库连接池)、线程池等也是为了复用,那它们跟享元模式有什么区别呢?
- 你可能对连接池、线程池比较熟悉,对对象池比较陌生,所以,这里我简单解释一下对象池。像 C++ 这样的编程语言,内存的管理是由程序员负责的。为了避免频繁地进行对象创建和释放导致内存碎片,我们可以预先申请一片连续的内存空间,也就是这里说的对象池。每次创建对象时,我们从对象池中直接取出一个空闲对象来使用,对象使用完成之后,再放回到对象池中以供后续复用,而非直接释放掉。
- 虽然对象池、连接池、线程池、享元模式都是为了复用,但是,如果我们再细致地抠一抠“复用”这个字眼的话,对象池、连接池、线程池等池化技术中的“复用”和享元模式中的“复用”实际上是不同的概念。
- 池化技术中的“复用”可以理解为“重复使用”,主要目的是节省时间(比如从数据库池中取一个连接,不需要重新创建)。在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用。享元模式中的“复用”可以理解为“共享使用”,在整个生命周期中,都是被所有使用者共享的,主要目的是节省空间。
我们先来看下面这样一段代码。你可以先思考下,这段代码会输出什么样的结果。
Integer i1 = 56;
Integer i2 = 56;
Integer i3 = 129;
Integer i4 = 129;
System.out.println(i1 == i2);
System.out.println(i3 == i4);- Java提供了自动拆箱与装箱机制,比如int的装箱就是Integer.valueOf(); 拆箱就是i.intValue();
- 前 4 行赋值语句都会触发自动装箱操作,也就是会创建 Integer 对象并且赋值给 i1、i2、i3、i4 这四个变量。根据刚刚的讲解,i1、i2 尽管存储的数值相同,都是 56,但是指向不同的 Integer 对象,所以通过“==”来判定是否相同的时候,会返回 false。同理,i3==i4 判定语句也会返回 false。
- 不过,上面的分析还是不对,答案并非是两个 false,而是一个 true,一个 false。看到这里,你可能会比较纳闷了。实际上,这正是因为 Integer 用到了享元模式来复用对象,才导致了这样的运行结果。当我们通过自动装箱,也就是调用 valueOf() 来创建 Integer 对象的时候,如果要创建的 Integer 对象的值在 -128 到 127 之间,会从 IntegerCache 类中直接返回,否则才调用 new 方法创建。看代码更加清晰一些,Integer 类的 valueOf() 函数的具体代码如下所示:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}实际上,这里的 IntegerCache 相当于,我们上面讲的生成享元对象的工厂类,只不过名字不叫 xxxFactory 而已。我们来看它的具体代码实现。这个类是 Integer 的内部类,你也可以自行查看 JDK 源码。
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}- 为什么 IntegerCache 只缓存 -128 到 127 之间的整型值呢?
- 在 IntegerCache 的代码实现中,当这个类被加载的时候,缓存的享元对象会被集中一次性创建好。毕竟整型值太多了,我们不可能在 IntegerCache 类中预先创建好所有的整型值,这样既占用太多内存,也使得加载 IntegerCache 类的时间过长。所以,我们只能选择缓存对于大部分应用来说最常用的整型值,也就是一个字节的大小(-128 到 127 之间的数据)。
- 实际上,JDK 也提供了方法来让我们可以自定义缓存的最大值,有下面两种方式。如果你通过分析应用的 JVM 内存占用情况,发现 -128 到 255 之间的数据占用的内存比较多,你就可以用如下方式,将缓存的最大值从 127 调整到 255。不过,这里注意一下,JDK 并没有提供设置最小值的方法。
//方法一:
-Djava.lang.Integer.IntegerCache.high=255
//方法二:
-XX:AutoBoxCacheMax=255-
现在,让我们再回到最开始的问题,因为 56 处于 -128 和 127 之间,i1 和 i2 会指向相同的享元对象,所以 i1==i2 返回 true。而 129 大于 127,并不会被缓存,每次都会创建一个全新的对象,也就是说,i3 和 i4 指向不同的 Integer 对象,所以 i3==i4 返回 false。
-
实际上,除了 Integer 类型之外,其他包装器类型,比如 Long、Short、Byte 等,也都利用了享元模式来缓存 -128 到 127 之间的数据。比如,Long 类型对应的 LongCache 享元工厂类及 valueOf() 函数代码如下所示:
-
在我们平时的开发中,对于下面这样三种创建整型对象的方式,我们优先使用后两种。
Integer a = new Integer(123);
Integer a = 123;
Integer a = Integer.valueOf(123);- 第一种创建方式并不会使用到 IntegerCache,而后面两种创建方法可以利用 IntegerCache 缓存,返回共享的对象,以达到节省内存的目的。举一个极端一点的例子,假设程序需要创建 1 万个 -128 到 127 之间的 Integer 对象。使用第一种创建方式,我们需要分配 1 万个 Integer 对象的内存空间;使用后两种创建方式,我们最多只需要分配 256 个 Integer 对象的内存空间。
- 刚刚我们讲了享元模式在 Java Integer 类中的应用,现在,我们再来看下,享元模式在 Java String 类中的应用。同样,我们还是先来看一段代码,你觉得这段代码输出的结果是什么呢?
String s1 = "哈哈哈";
String s2 = "哈哈哈";
String s3 = new String("哈哈哈");
System.out.println(s1 == s2);
System.out.println(s1 == s3);-
上面代码的运行结果是:一个 true,一个 false。跟 Integer 类的设计思路相似,String 类利用享元模式来复用相同的字符串常量(也就是代码中的“小争哥”)。JVM 会专门开辟一块存储区来存储字符串常量,这块存储区叫作“字符串常量池”。上面代码对应的内存存储结构如下所示:【笔者的JVM系列有专门讲String的各种情况】
-
不过,String 类的享元模式的设计,跟 Integer 类稍微有些不同。Integer 类中要共享的对象,是在类加载的时候,就集中一次性创建好的。但是,对于字符串来说,我们没法事先知道要共享哪些字符串常量,所以没办法事先创建好,只能在某个字符串常量第一次被用到的时候,存储到常量池中,当之后再用到的时候,直接引用常量池中已经存在的即可,就不需要再重新创建了。