This repository contains the code for the paper Deliberate Reasoning for LLMs as Structure-aware Planning with Accurate World Model.
SWAP consists of three main components: the policy model
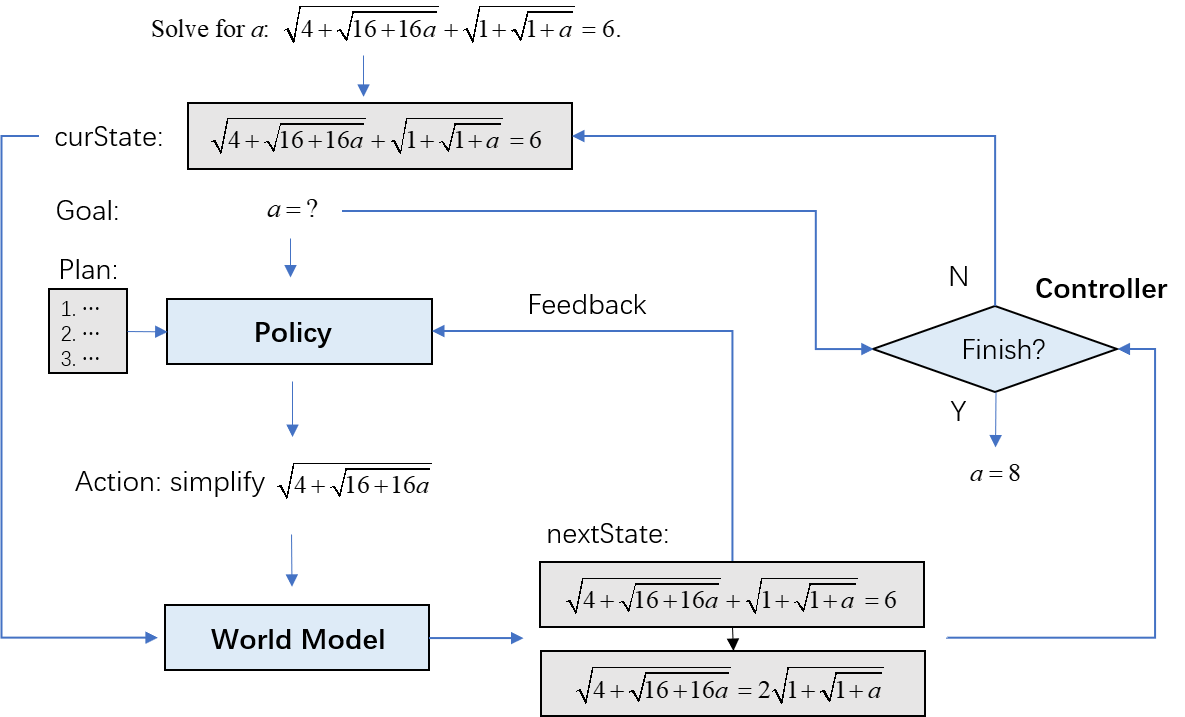
SWAP performs multi-step reasoning through structure-aware planning in FOLIO (left) and MATH (right). At each step, given the current state, represented as a graph, and an action, the world model predicts the next state as an updated graph. The policy model is guided by this graph to propose next action.

We use Hugging Face platform to load the Llama3 and Mistral models. Make sure you have an account (Guidance).
The structure of the file folder should be like
SWAP/
│
├── materials/
│
├── model_weights/
│
├── results/
│
└── src/# git clone this repo
# create a new environment with anaconda and install the necessary Python packages
# install hugging face packages to load the base models and datasets
# create the folders
cd SWAP
mkdir model_weights
mkdir results
cd src- Base model fine-tuning
# Train the generator
accelerate launch SFT_Generator.py --dataset MATH --subset algebra --prob_type math --train --print_example
# (Optional)
accelerate launch DPO_Generator.py --dataset MATH --subset algebra --prob_type math --train --print_example
# Train the semantical equivalence LoRA
accelerate launch SFT_sem_equ_LoRA.py --dataset MATH --subset algebra --train --print_example
# Train the discriminator
accelerate launch SFT_Discriminator.py --dataset MATH --subset algebra --prob_type math --group_size 2 --train --print_example - Inference
accelerate launch main.py --dataset MATH --subset algebra --prob_type math --enable_DBM --visualize --max_steps 20 --num_rollouts 3 --num_generations 3 --group_size 2Please check the source code for detailed parameter explanation.
All the datasets (gsm8k, MATH, FOLIO, ReClor, HumanEval, MBPP) with trajectories and process supervision can be found here.
To download the dataset, install Huggingface Datasets and then use the following command:
from datasets import load_dataset
dataset = load_dataset("sxiong/SWAP", "MATH_trajectory")
print(dataset)
split = dataset['train']The default training/inference arguments are for a single A100 (GPU memory: 80G). If you have multiple GPUs, the training process can be accelerated in a distributed way. Here we recommend the library of DeepSpeed [docs].
Also, you can accelerate the inference with multiple GPUs.
If you have any inquiries, please feel free to raise an issue or reach out to [email protected].
@article{xiong2024deliberate,
title={Deliberate Reasoning for LLMs as Structure-aware Planning with Accurate World Model},
author={Xiong, Siheng and Payani, Ali and Yang, Yuan and Fekri, Faramarz},
journal={arXiv preprint arXiv:2410.03136},
year={2024}
}