The Kentico Search API utilizes Microsoft Cognitive Search and Azure Blob Storage for searching Kentico Kontent content.
This code sample is to provide the framework for creating an Azure Search based synchronization infrastructure to provide website search for your Kentico Kontent.
Modifications to the code base will be needed depending on your environment / Kentico Kontent models. This is not a turn key solution, but will get you about 90% on your way to having search capabilities on your application or website that relies on Kentico Kontent data.
This repository is heavily geared towards website search, but could be adapted for other content search scenarios.
This repository is a snapshot of working code in a production website that was developed using Kentico Kontent. Pull requests / Bug Reports are welcome.
- Kentico.Search.Api - Web API Endpoint
- Kentico.Search.Api.Client - NSwag generated API client to be used with the API Endpoints (Kentico.Search.Api)
- Kentico.Search.Api.Models - API Specific request/response models
- Kentico.Search.Api.Services - The bulk of the API logic lives here, has all the business logic for interacting with Kentico Kontent and Azure Cognitive Search
- Kentico.Web.Models - The auto-generated .NET classes that represent the content models in Kentico Kontent
Reindexing events are done on a scheduled basis and will be a simple PowerShell script placed on your server that will periodically call the PopulateAllIndexes API endpoint.
Search indexes will not be refreshed on webhook invalidation due to the complexity involved in only refreshing the items that changed. Instead the simpler schedule based approach was taken. Additionally Kentico Kontent currently does not have ability to receive webhook notifications of Asset changes (PDFs, etc) which forces you back to a scheduled based approach anyways.
The PowerShell scripts are in the PowerShell folder of this project of the Kentico.Search.Api project.
The Azure Cognitive Search service must first be created in Azure before you can create the indexes, indexer, and data source connections.
This is the walkthrough of setting that up in Azure:
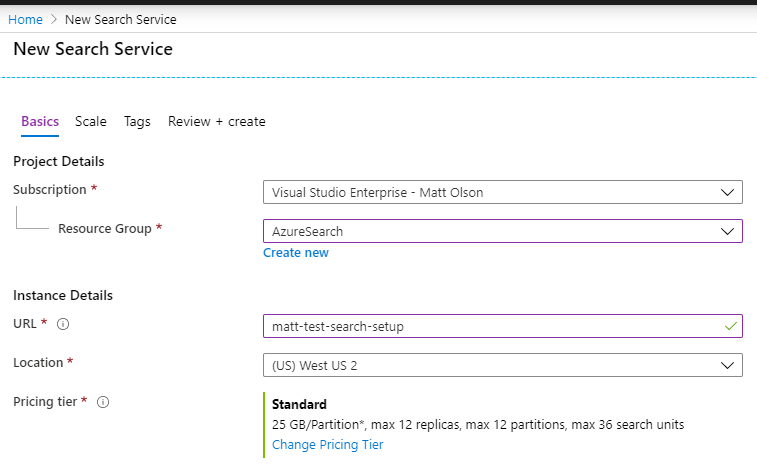
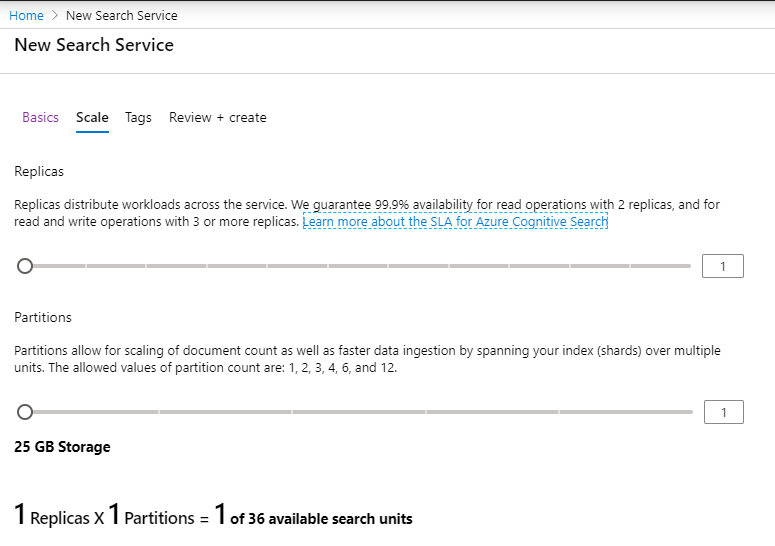
Once you have the Azure Search Service setup you can then hit the /api/Search/RebuildIndex endpoint in this application and it will setup the search service for you. The models project will need to be setup first however (see below).
This API relies on generated models from Kentico Kontent. The models we use are "Content Pages", "Landing Pages", and "News Articles" that are defined in Kentico Kontent and are present in the Kentico.Web.Models project. For other Kentico Kontent projects these model types may be different.
The models are generated for the Kentico.Web.Models\Tools\GenerateModels.ps1 script by pointing to the Kentico Kontent endpoint and generating the models library. Replace with your API keys and project identifiers.
The .NET API Client is auto generated using NSwag. If there are changes to the API definitions open the Kentico.Api.Client.csproj file and edit the "false" flag, and set it to "true". Then build the project and it will re-generate the API client.
NOTE: The API endpoint needs to be running as indicated in the nswag.json file that points to the Open API swagger file.
You use the Import Data button on the Azure Search Service to create the index manually. This section is just shown for reference purposes only. The API endpoint supports auto-rebuild / creation of the indexer, datasource, and index. It is recommended to just use the API endpoint to set all this up for you. See /api/Search/RebuildIndex endpoint for how that process works.
The programmatic way is documented here: https://docs.microsoft.com/en-us/azure/search/search-howto-indexing-azure-blob-storage
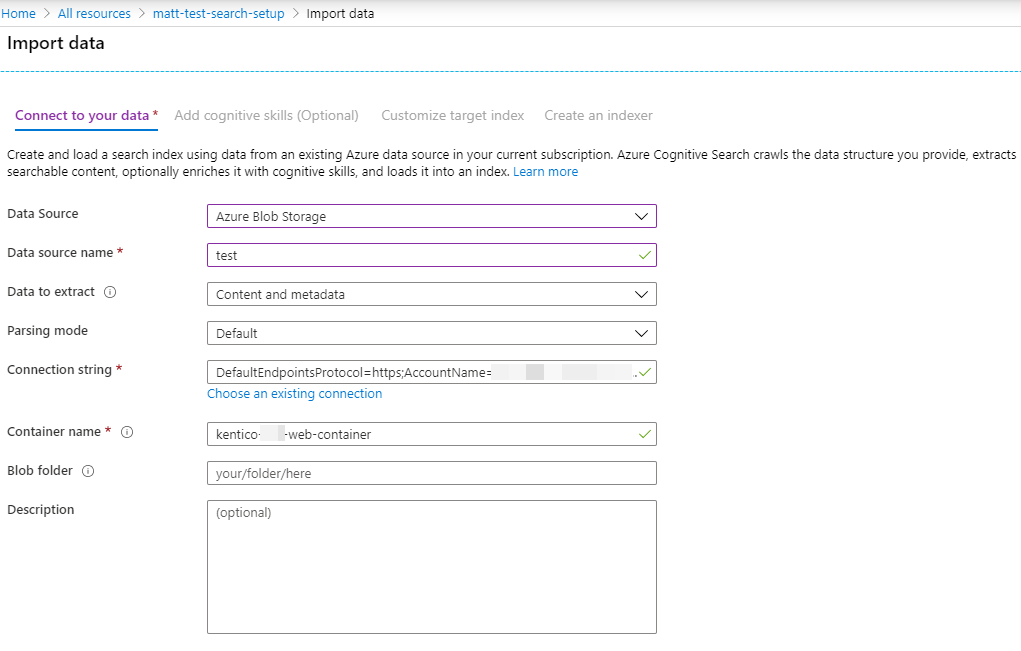
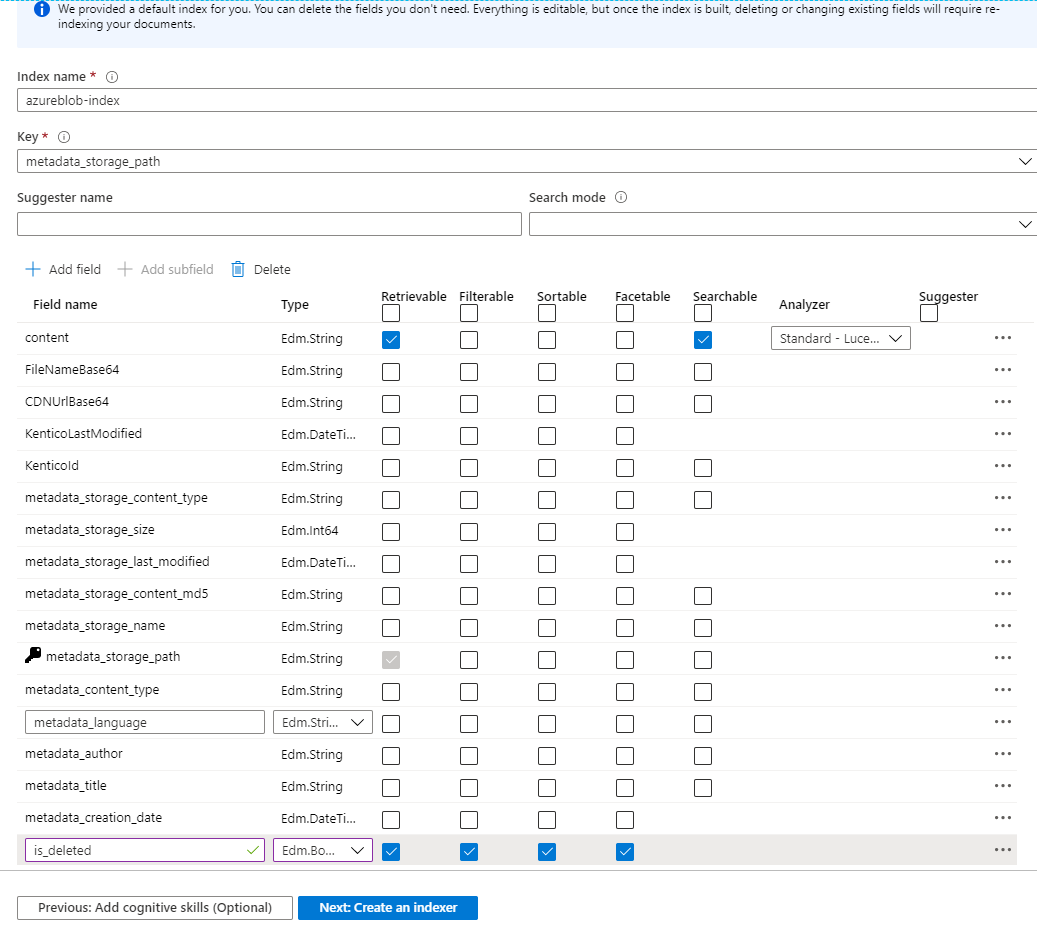
The UI has a bug where you can't put on the Delete tracking right away. The data type in the above screenshot is Edm.Boolean.
To enable it you have to go back to the data source and turn it on and use the appropriate is_deleted tracking column.
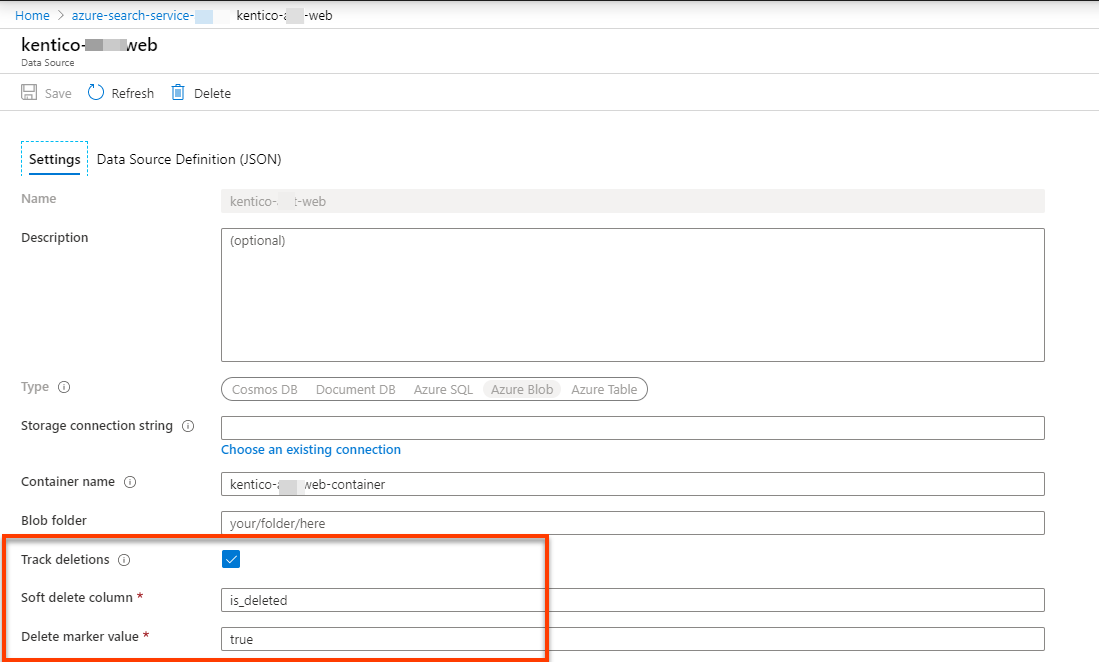
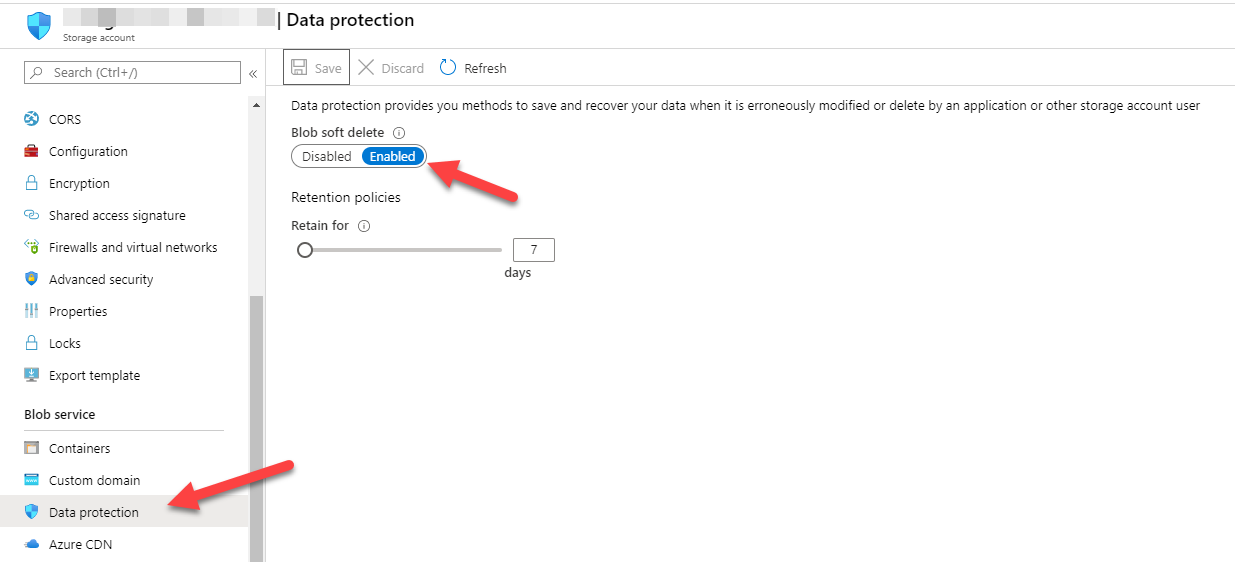
Ensure soft delete data protection is on the blob storage for the soft delete tracking to occur:
Blob synchronization occurs by comparing the last modification date of the content from Kentico Asset storage to that of the Azure Blob storage. It does this in a two way sync pattern as follows:
- First it fetches all assets from Kentico in the allowed file types to index setting in appsettings.json.
- It then ensures that all those assets are in the Azure Blob Storage container. If it is not found it is uploaded and the metadata is set on the blob storage item (Base64 encoded URL and title, and a few other kentico specific unique information).
- Once we have synchronized from Kentico -> Azure Blob Storage Container we then start a reverse loop and iterate over all items in the blob storage container and identify things in the blob storage container that need to be deleted because it didn't exist in step 1 above.
Azure blob storage data-source within the search service is setup with a deleted flag, which is required to indicate to the Azure Cognitive Search services that upon the next scheduled indexing event for the blobs to remove it from the index. It is recommended, in addition to the soft delete approach that we set the blob storage container to also have it's own soft delete data protection turned on.
Azure Blob indexing is handled via a scheduling function within Azure. This is not something we have to run a task for on our end. Only the asset synchronization process needs to run.
Default run time is set to ever 1 hour.
A reindexing request can be called by calling PopulateIndex or PopulateAllIndexes event after we have synchronized the Kentico assets.
Kentico content is synchronized by capturing all types of "pages" that are displayed to the end user. Pages in Kentico are based off of the following content types:
- Landing Page
- Content Page
- News Article
Those root content types make up the display of all pages on the website. There may be many levels of nested content within those three content types.
To get a full pages content programatically via the Kentico API's you would need to parse the JSON structure and recursively call the API to construct a complete content block from many other different embedded content types.
A simpler approach was taken, since this function is already taken care of for you using the .NET SDK's using MVC Display Templates and the .DisplayFor mechanism in MVC.
As such the synchronization will find all the unique code names (unique identifier in Kentico) for all of the content types indicated above and then create an HTTP client that will consume the raw content of the page. See Raw Content Views for more information.
Kentico Kontent has no formal way of defining URL's that are based on a taxonomy. It is up to the developer to implement the URL routing as a result.
You will need implemented that taxonomy in your web project to generate SEO friendly URL's if you chose to do so. As a result we needed to get the taxonomy based URL in our Raw Content page requests. This is done using the Kentico-Friendly-Url response header when the kentico search index synchronization event is downloading the raw content from website.
This was done using a header approach from the website so we didn't have to reproduce all of the logic involved in determining SEO friendly urls and centralizes that code into the website providing the content for the indexer.
For the search results to not be affected by menu / footer keywords influencing the search ranking of the content the three primary content types (listed above) have an MVC view called RawContent. This omits all menus and footer information and displays the raw Kentico Kontent data.
To achieve this a minimal layout page was created as follows (_LayoutRawContent.cshtml):
<!DOCTYPE html>
<html lang="en">
<head>
<title>@ViewData["Title"]</title>
<meta name="description" content="@ViewData["Description"]" />
</head>
<body>
<div class="sfPublicWrapper">
@RenderSection("topnavigation", required: false)
@RenderSection("pageheader", required: false)
<div class="main-content">
<div class="white-bg">
<div class="container">
@RenderBody()
</div>
</div>
</div>
@RenderSection("pagefooter", required: false)
</div>
</body>
</html>Then for each "Page" content type (in this project it is the ContentPage, LandingPage,and NewsArticle content types that are end user viewable content types that are rendered on the website. You would define the RawContent.cshtml view as follows. In this example we provide the RawContent.cshtml view for the ContentPageViewModel (a derivative of the ContentPage auto-generated Kentico Kontent model):
@model NavLayoutViewModel<ContentPageViewModel>
@inject IDeliveryClientFactory clientFactory
@{
ViewData["Title"] = Model.PageModel.MetadataMetaTitle;
ViewData["Description"] = Model.PageModel.MetadataMetaDescription;
Layout = "~/Views/Shared/_LayoutRawContent.cshtml";
var deliveryClient = clientFactory.Get();
}
@Html.DisplayFor(p => p.PageModel.Content)The controller definition for this is as follows:
[ResponseCache(CacheProfileName = CacheConstants.TwoHour)]
public class ContentPageController : BaseController<ContentPageController>
{
public const string Name = "ContentPage";
public ContentPageController(IDeliveryClientFactory clientFactory, ILogger<ContentPageController> logger,
IDeliveryCacheManager cacheManager,
IMemoryCache memoryCache, IOptions<ProjectOptions> projectOptions) :
base(clientFactory, logger, cacheManager, memoryCache, projectOptions)
{
}
public async Task<IActionResult> RawContent(string codename)
{
//In order to provide the search service which uses the rawcontent URL's to get all the data (minus the navigation menus which has text that would sway the search results
//we provide the actual URL to the content here and stuff it in the header since it is calculated by the sitemap and controller mapping logic in this application.
//We stuff this data into the response headers as this logic would all have to be copied to the search service and we would also have to setup additional cache eviction webhooks
//to our internal search service if we didn't do it this way. This seemed like the cleanest approach to decouple the search service from the Kentico.Web project as much as possible.
var deliveryClient = ClientFactory.Get();
var controllerMappings = (await MemoryCache.GetControllerMappings(deliveryClient));
var mapping = controllerMappings.FirstOrDefault(p => p.PageCodeName == codename);
Response.Headers.Add(Constants.FriendlyUrlResponseHeader, mapping?.FullUrl); //The taxonomy / content model derived SEO friendly URL
var model = await GetModel(codename);
if (model == null)
return this.RedirectToNotFoundPage();
return View(model);
}
private async Task<NavLayoutViewModel<ContentPageViewModel>> GetModel(string codename)
{
var deliveryClient = ClientFactory.Get();
var response = await deliveryClient.GetItemAsync<ContentPageViewModel>(codename, new DepthParameter(100));
if (response.Item == null)
return null;
var modelWithNav = new NavLayoutViewModel<ContentPageViewModel>(response.Item);
modelWithNav.ProjectOptions = ProjectOptions;
modelWithNav.ParentSystemInfo = response.Item.System;
modelWithNav.HeaderContent = response.Item.HeaderContent;
modelWithNav.Navigation = await response.Item.TypeOfNavigation.GetNavigationMenuViewModelAsync(deliveryClient);
modelWithNav.IsRestricted = response.Item.IsRestricted;
var notice = await deliveryClient.GetItemAsync<SiteNoticeViewModel>(ProjectOptions.SiteNoticeCodeName, new DepthParameter(100));
modelWithNav.SiteNotice = notice.Item;
return modelWithNav;
}
}You will see in the above code snippet we put in a special HTTP Header onto the result which contains the full URL to that page on the website. This is done because of the complex logic involved in creating taxonomy based URL's that exists in the website's code base and avoids having to re-create that same logic and data loading process on the search indexing side. This URL is then stored as part of the search index along with the page's raw content.
All page retrievals has their HTML removed and becomes just the raw content words on the page. This minimizes size in the index, and avoids false hits on html keywords.
Search configuration is handled from the appsettings.json. Multiple search configurations can be setup.
For search indexing to be generic across Kentico Kontent projects the following rules need to apply:
Page content type indexes should have the following content type fields:
- URL (the taxonomy based SEO friendly URL)
- Title (The title of the page)
News content type indexes should have the following content type fields:
- Url
- Title
- Synopsis
- Date
Blob indexes should have the following content type fields:
- Url (Base 64 encoded on the blob object itself as blob containers have limited character support in their metadata)
- Title (Also Base64 encoded on the blob object itself)
Base64 encoding is required as there are severe limits to the character sets that can be put onto blob metadata properties in Azure Blob Storage.
Currently only two index types exist. Pages and Blobs. Pages are for page content (web pages aka Content Pages, news articles, landing pages for example). Blobs are for all binary assets, such as PDF's that will need to be indexed.
- Kentico Asset API's do not fire webhook events to notify us of changes to blobs in Kentico Kontent. Therefore we are doing hourly reindexing events as indicated in Blob Synchronization.
- Currently the way it is programmed, the search service only supports one blob storage container per search configuration. However that storage is basically unlimited so it shouldn't be that big of a deal.
- Setting up a new search indexer for another website or another content source will require you to bring in your content type models. The API currently does not have a way to define the content type structure (would require much more effort then we would probably gain from such functionality).