You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
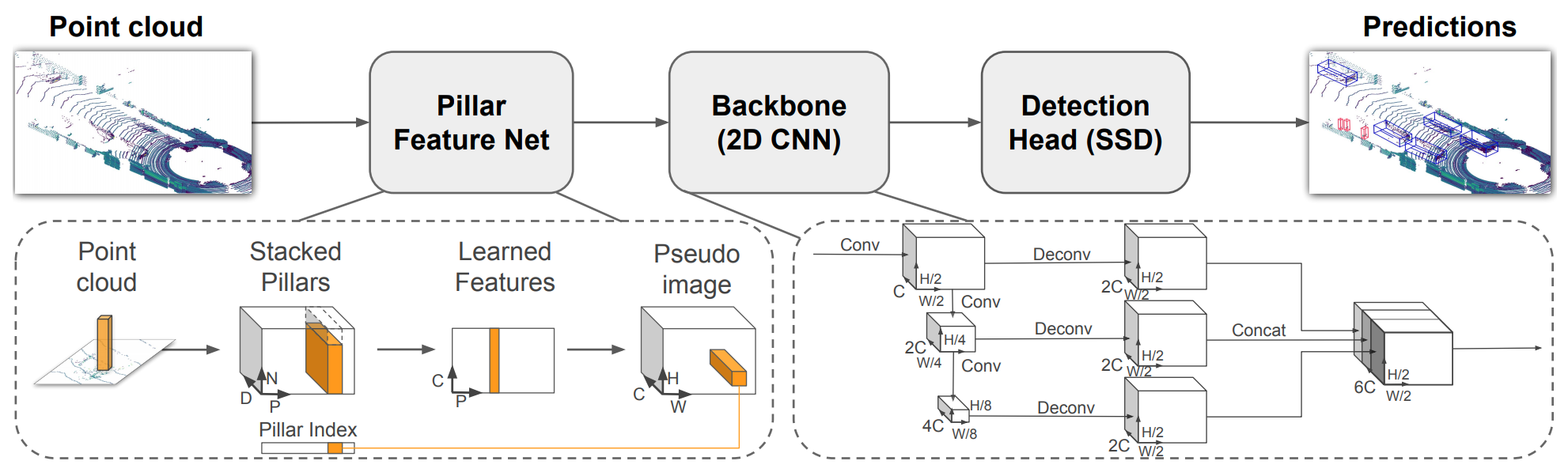
Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.
Introduction
We implement PointPillars and provide the results and checkpoints on KITTI, nuScenes, Lyft and Waymo datasets.
Metric: For model trained with 3 classes, the average APH@L2 (mAPH@L2) of all the categories is reported and used to rank the model. For model trained with only 1 class, the APH@L2 is reported and used to rank the model.
Data Split: Here we provide several baselines for waymo dataset, among which D5 means that we divide the dataset into 5 folds and only use one fold for efficient experiments. Using the complete dataset can boost the performance a lot, especially for the detection of cyclist and pedestrian, where more than 5 mAP or mAPH improvement can be expected.
Implementation Details: We basically follow the implementation in the paper in terms of the network architecture (having a
stride of 1 for the first convolutional block). Different settings of voxelization, data augmentation and hyper parameters make these baselines outperform those in the paper by about 7 mAP for car and 4 mAP for pedestrian with only a subset of the whole dataset. All of these results are achieved without bells-and-whistles, e.g. ensemble, multi-scale training and test augmentation.
License Aggrement: To comply the license agreement of Waymo dataset, the pre-trained models on Waymo dataset are not released. We still release the training log as a reference to ease the future research.
FP16 means Mixed Precision (FP16) is adopted in training. With mixed precision training, we can train PointPillars with nuScenes dataset on 8 Titan XP GPUS with batch size of 2. This will cause OOM error without mixed precision training. The loss scale for PointPillars on nuScenes dataset is specifically tuned to avoid the loss to be Nan. We find 32 is more stable than 512, though loss scale 32 still cause Nan sometimes.
Citation
@inproceedings{lang2019pointpillars,
title={Pointpillars: Fast encoders for object detection from point clouds},
author={Lang, Alex H and Vora, Sourabh and Caesar, Holger and Zhou, Lubing and Yang, Jiong and Beijbom, Oscar},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={12697--12705},
year={2019}
}