5.设计文档
- 一、CacheCloud是做什么的
- 二、CacheCloud提供哪些功能
- 三、CacheCloud解决什么问题
- 四、CacheCloud提供的价值
- 五、CacheCloud在搜狐的规模
- 六、CacheCloud环境需求
- 七、Cachecloud架构
- 八、CacheCloud接入流程
- 九、CacheCloud运维与优化
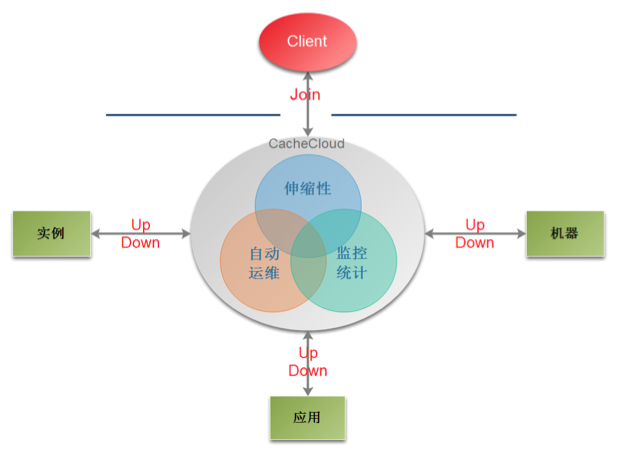 ## 二、CacheCloud提供哪些功能 ###
### CacheCloud主要提供的功能如下:
+ **监控统计:** 提供了机器、应用、实例下各个维度数据的监控和统计界面。
## 二、CacheCloud提供哪些功能 ###
### CacheCloud主要提供的功能如下:
+ **监控统计:** 提供了机器、应用、实例下各个维度数据的监控和统计界面。
 + **一键开启:** Redis Standalone、Redis Sentinel、Redis Cluster三种类型的应用,无需手动配置初始化。
+ **一键开启:** Redis Standalone、Redis Sentinel、Redis Cluster三种类型的应用,无需手动配置初始化。
 + **Failover:** 支持哨兵,集群的高可用模式。
+ **伸缩:** 提供完善的垂直和水平在线伸缩功能。
+ **完善运维:** 提供自动运维和简化运维操作功能,避免纯手工运维出错。
+ **方便的客户端:**方便快捷的客户端接入。
+ **元数据管理:** 提供机器、应用、实例、用户信息管理。
+ **Failover:** 支持哨兵,集群的高可用模式。
+ **伸缩:** 提供完善的垂直和水平在线伸缩功能。
+ **完善运维:** 提供自动运维和简化运维操作功能,避免纯手工运维出错。
+ **方便的客户端:**方便快捷的客户端接入。
+ **元数据管理:** 提供机器、应用、实例、用户信息管理。

 + **流程化:** 提供申请,运维,伸缩,修改等完善的处理流程
## 三、CacheCloud解决什么问题 ###
+ **流程化:** 提供申请,运维,伸缩,修改等完善的处理流程
## 三、CacheCloud解决什么问题 ###
 ####1.部署成本
Redis多机(Redis-Sentinel, Redis-Cluster)部署和配置相对比较复杂,较容易出错。
####1.部署成本
Redis多机(Redis-Sentinel, Redis-Cluster)部署和配置相对比较复杂,较容易出错。
例如:100个redis数据节点组成的redis-cluster集群,如果单纯手工安装,既耗时又容易出错。
####2.实例碎片化 作为一个Redis管理员(可以看做redis DBA)需要帮助开发者管理上百个Redis-Cluster集群,分布在数百台机器上,人工维护成本很高,需要自动化运维工具。 ####3. 监控、统计和管理不完善 一些开源的Redis监控和管理工具,例如:RedisLive(Python)、Redis Commander(Node.js),Redmon(Ruby)无论从功能的全面性(例如配置管理,支持Redis-Cluster等等)、扩展性很难满足需求。 ####4. 运维成本 Redis的使用者需要维护各自的Redis,但是用户可能更加善于使用Redis实现各种功能,但是没有足够的精力和经验维护Redis。 Redis的开发人员如同使用Mysql一样,不需要运维Mysql服务器,同样使用Redis服务,不要自己运维Redis,Redis由一些在Redis运维方面更有经验的人来维护(保证高可用,高扩展性),使得开发者更加关注于Redis使用本身。 ####5. 伸缩性 本产品支持Redis最新的Redis-Sentinel、Redis-Cluster集群机构,既满足Redis高可用性、又能满足Redis的可扩展性,具有较强的容量和性能伸缩能力。 ####6. 经济成本 机器利用率低,各个项目组的Redis较为分散的部署在各自服务器上,造成了大量闲置资源没有有效利用。 ####7. 版本不统一 各个项目的Redis使用各种不同的版本,不便于管理和交互。
## 四、CacheCloud提供的价值 ### + 规模化自动运维: 降低运维成本,降低人为操作出错率。 + 自由伸缩: 提供灵活的伸缩性,应用扩容/收缩成本降低,机器资源得到重复利用。 + 团队提升,开源贡献: 团队提升,开源贡献:提升云产品开发设计经验,自己作为开发者和使用者,Eating your own dog food。 ## 五、CacheCloud在搜狐的规模 ### + 每天100+亿次命令调用 + 2T+的内存空间 + 800+个Redis实例 + 100+台机器 ## 六、CacheCloud环境需求 ### + Java 7 + Maven 3 + MySQL ## 七、架构 ###1. 类型架构 ####(1)standalone类型架构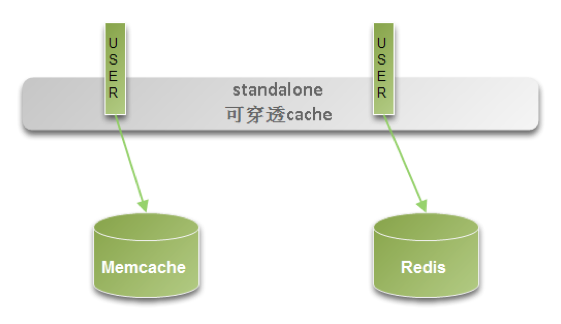
用于可穿透业务场景,如后端有DB存储,脱机影响不大的应用。 ####(2) sentinel类型架构
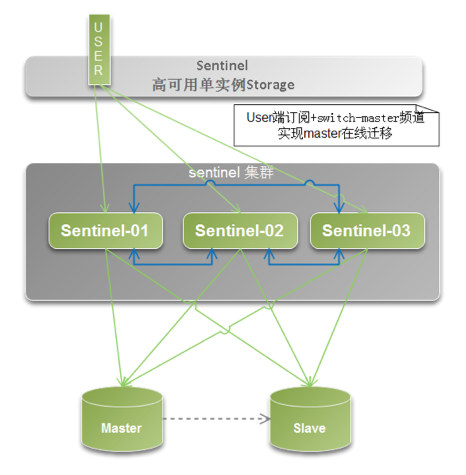
用于高可用需求场景,可用于高可用Cache,存储等场景。 内存/QPS受限于单机。
####(3)cluster类型架构
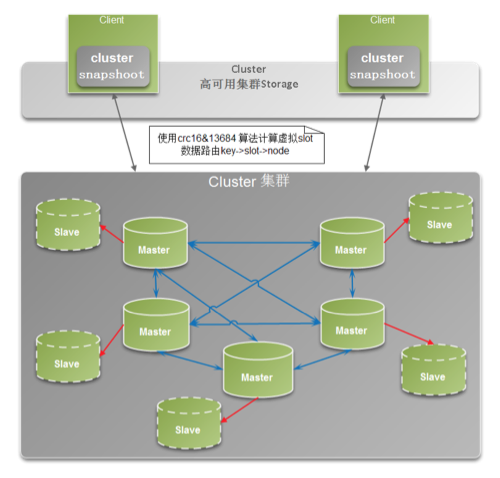
用于高可用需求场景,可用于大数据量高可用Cache/存储等场景。 内存/QPS不受限于单机,可受益于分布式集群高扩展性
###2: 伸缩架构 ####(1) 垂直伸缩架构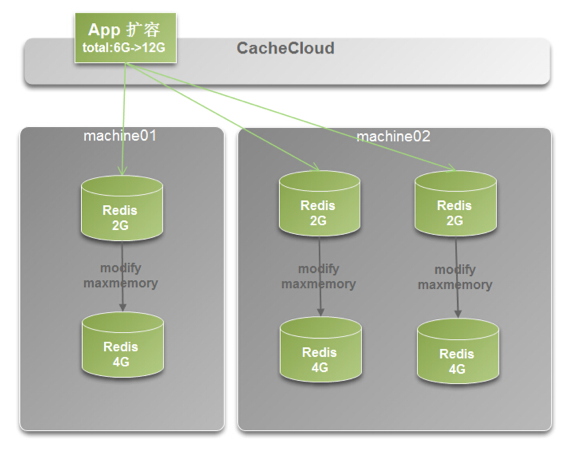
通过统一调整每个实例可用内存量做到垂直拓展,受限于机器物理内存资源. 适用于所有redis类型应用
####(2) 水平(sentinel)伸缩架构
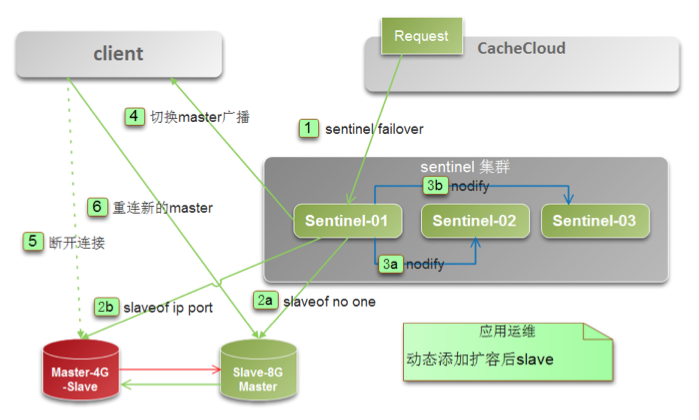
通过在线切换主从关系和实例所属机器实现扩容。 适用于sentinel应用,在物理资源不够用/换掉故障机器时使用.
####(3) 水平(cluster)伸缩架构
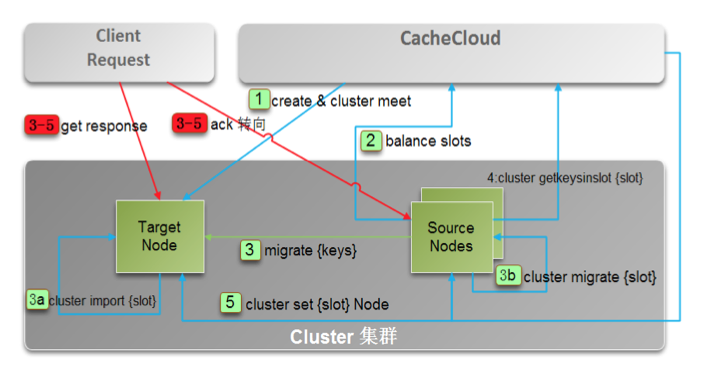
通过动态加减实例并在线迁移数据实现伸缩性。 适用于redis-cluster应用,伸缩性最灵活但是速度最慢。
###3: 技术架构:
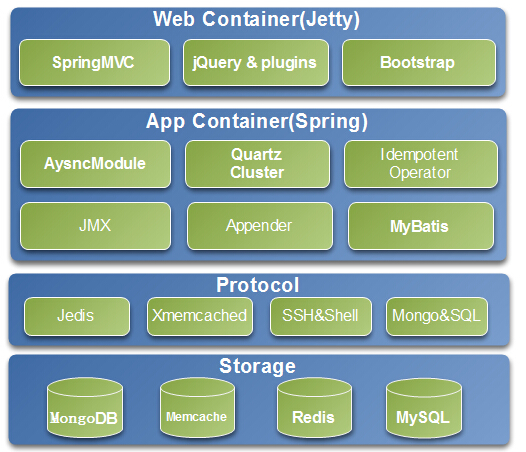 ##八、CacheCloud接入流程
##八、CacheCloud接入流程
- 根据需求填写应用申请。
- 管理员根据后端资源池开通应用。
- 使用方通过appId接入CacheCloud资源。
- 整个接入过程非常快速,10分钟Done.

异步工作线程扫描每台机器aof文件增长率。 对于达到aof重写机制的实例在本机轮流触发重写,实现重写隔离机制。
###2. redis复制流程分析和优化
####(1)redis复制操作: 分为全量复制和增量复制,全量复制开销主要在三方面:
- (a) master节点bgsave是rdb落地操作。
- (b) rdb文件在主从之间传输开销。
- (c) slave节点加载rdb文件. 避免不必须的全量复制。
####(2)增量复制用于网络不稳定等原因造成rdb重传的问题:
- (a) 使用psync master_run_id offset 向主节点获取miss数据,
- (b) master检查repl-backlog-buffer是否存在offset内的数据,
- (c) 存在时,发送增量数据
- (d) 不存在时做全量复制操作
####(3)总结:增量复制是否生效依赖于以下三点,根据应用场景做优化:
- repl-backlog-size参数大小
- 主从节点写入量
- 主从网络环境
redis-cluster节点不支持mget,mset等批量操作,client端只能批量get模拟mget操作,与redis节点通信io复杂度N(keys)
CacheCloud-client端使用pipeline封装mget等批量操作, 与redis节点通信io复杂度为N(nodes)
