Reactor Kore - A Cross-Platform Non-Blocking Reactive Foundation #979
Comments
|
I see two primary paths towards this goal:
In particular, lets us single out coroutines. Indeed, coroutines make implementing operators simple and they allow to somewhat reduce API surface, since may exotic operators can be easily implemented as needed. However, every generic solution has its cost. While coroutine-based asynchronous operators are readily composable, this ease comes with somewhat suboptimal performance due to additional implementation abstractions. So, the design challenge is to carefully decide which "core" operators need low-level implementation for efficiency and where efficiency is not of paramount importance and simpler implementation can be used. |
|
Thanks for continuing this conversation. I'm glad you linked to Jake Wharton's Reagent experiment because I think it offers some compelling ideas regarding type system. To be honest, I'm not vested in any existing specification (ReactiveX, Reactor, etc). As a matter of fact, I think a reactive Kotlin framework needs to "go big or go home" and be written from scratch. If we don't support nullable types, Kotlin idioms, and multiplatform, how much are we really gaining when existing JVM libraries exist? Personally I just want fluent, composable, and concurrent streams that can easily emit events and data alike. From a user perspective, if Kotlin Sequences supported events and schedulers, I'd use those over RxJava. As a matter of fact, it would be pretty awesome to have that in the std-lib. Although I haven't used coroutines in production, I like what they offer and the abstraction implementations they can simplify. |
|
Roman I'm not sure how your definition of "suboptimal" measures. But honestly... if we can relatively get in the ballpark in terms of performance, I don't think it will be a hindrance to adoption. I'd happily take a slight performance hit just to use Kotlin's standard library and no other dependencies. Performance optimization can always be done later even in "experimental" packages. |
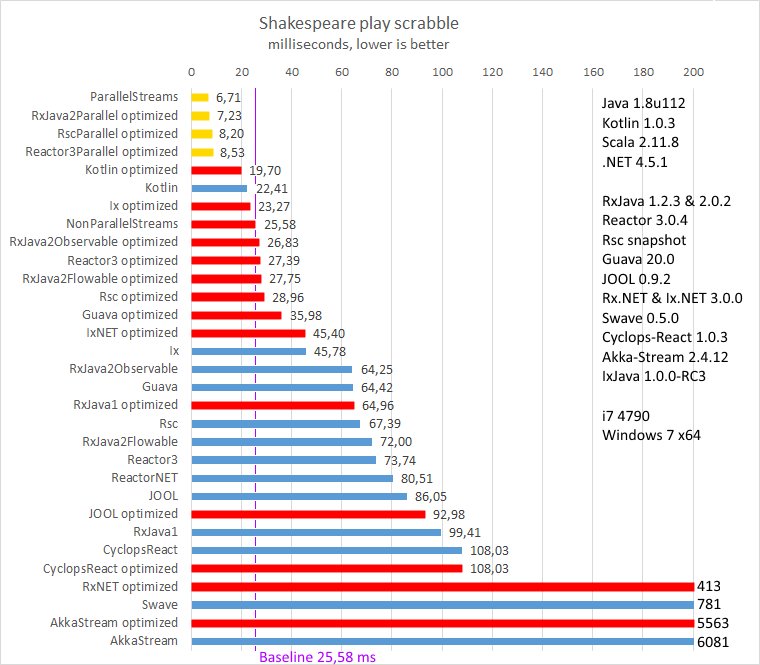
|
@thomasnield Kotlin Sequences are indeed fast, exactly because they are always single-threaded and do not support any form of asynchrony. However, if you write the corresponding benchmark with current version of On the other hand, Rx and Reactor designs are currently quite balanced in terms of performance. By default, they work like a synchronous stream processing library and employ additional abstraction layers to synchronize multiple threads only when needed. We cannot just "extend" sequences to support async. We need a reactive abstraction that supports async and has the corresponding design. I an ideal world, I would hope that people use sequences for sync case and this other abstraction for async ones, but the practice shows that it is not going to happen. We'll see async abstraction being used left-and-right for 100% synchronous use-cases, so it has to support those async use-cases, too, without loosing too much performance. |
|
@elizarov sorry I was definitely vague there. I didn't really mean to implement asynchronous behaviors into Sequences but rather create a separate Sequence-like entity that is asynchronous. So I definitely agree 100% with your thoughts. Jake Wharton's Reagent might be a great starting point to explore this new abstraction. |
|
I am very supportive of this, but I don't see much reason to work on a new reactive library unless it's going to significantly move the bar. I'd really like to see a reactive library written in Kotlin because it means we could (in theory) get most or all of the following:
Some of that is at odds with Reactive Streams / Flow. I guess it comes down as to whether we want all types to be compatible with one of those two or rather it be done via explicit boundary operators. |
|
@JakeWharton which of these points did you have in mind when saying some are at odds with Reactive Streams? |
|
Nulls being allowed as values in streams. |
|
Ah, right... I interpreted that bullet point as "Kotlin will be able to correctly infer that a stream is NonNull all the way", which I saw as quite valuable in itself. (edit: dubious that the use cases for |
|
It doesn't necessarily sacrifice interop, it just means the core types aren't directly Anyway I don't think it's a hard requirement to allow nulls in the stream. In a language that's designed to embrace null as a representation of absence rather than a wrapping box, it certainly would feel at home if it did, though. |
|
The I wonder if it would somehow be possible in Kotlin to be a |
|
I'll second @JakeWharton here. I don't see a direct interop with As for 3rd party libraries, like Spring, the experience, so far, shows that Spring, for one, is very extensible and customizable, so one can build integration modules that are fully transparent to the end user. See, for example, integration of Spring and coroutines by @konrad-kaminski https://github.com/konrad-kaminski/spring-kotlin-coroutine |
|
I have experience in supporting two platforms with the same reactive library, namely Reactive4Java and Reactive4GWT. Since GWT, and JavaScript, isn't really multithreaded, you'll have the problem to remove features from the Java code that are not working in the JavaScript version. Therefore, you either need library code transformation and/or aim at the lowest common denominator. However, this brings us to a more higher level question: libraries are written fewer times than they are used, why not put in the effort to utilize the target platform's features to its maximum extent and not make compromises due to limits in another platform? For example, backpressure works in JavaScript but you don't need Reactive Streams is an interoperation standard which doesn't rule out synchronous use or it being a backbone of a fluent library where components talk to each other through its protocol (or extended protocol). Writing operators is not easy but once you learn the two dozen operator building patterns, it becomes straightforward most of the time. Plus, when it is part of a library, you don't have implement the same operator over and over again. Forbidding Finally, you know my opinion on coroutines. In short, the suspension overhead is much higher than a cooperative request management overhead due to more atomics, trampolining and that the common case could be the cycle of getting suspended and resumed all the time. TL;DRMy suggestions are:
|
|
Let me get some performance facts straight in this discussion. Supporting suspension in APIs is not the same as actually suspending and trampolining all the time. In order to demonstrate this, I've build upon prior work by @akarnokd on benchmarking coroutines and created a very simple show-case PoC. I'm using the following basic pipeline for this benchmark: See here. I've implemented this pipeline in multitude of various ways, with Rx2, for example, it looks like this: See here. All synchronous reactive implementations using Rx2 Now, when I naively implement this pipeline with coroutine-based rendezvous channels using In order to answer this question I wrote a prototype of such suspension-based abstraction: See here. I wrote basic implementations of See here. This is the first key advantage -- operators can be trivially implemented. Notice that What about backpressure? There is no The resulting abstraction is easy to use: See here. How fast is it? It performs in 22.7 ms. I'd say it is very good, given that no performance optimizations have been made yet neither in the library itself, nor in the compiler (the work on optimizing support for suspending functions in Kotlin compiler is now in process as a part of coroutine design finalization effort). But what if we want to offload computations to other threads? From the user stand-point it is as easy as plugging a special operator into the chain: See here. Internally I've just used non-optimized multi-producer/multi-consumer channel to implement this To summarize. Building reactive abstractions over suspending functions brings the following game-changing benefits while paying reasonable performance penalty vs existing reactive implementations:
|
|
That's exactly what I was going for with Reagent except I used
ReceiveChannel to demo it. The key was to achieve trivial operator
implementation.
…On Thu, Dec 14, 2017 at 11:55 AM Roman Elizarov ***@***.***> wrote:
Let me get some performance facts straight in this discussion.
Supporting suspension in APIs is not the same as actually suspending and
trampolining all the time. In order to demonstrate this, I've build upon
prior work by @akarnokd <https://github.com/akarnokd> on benchmarking
coroutines and created a very simple show-case PoC. I'm using the following
basic pipeline for this benchmark:
(1..N).filter { it.isGood() } // here and everywhere it.isGood() = it % 4 == 0
.fold(0, { a, b -> a + b })
See here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/benchmark/RangeFilterSumBenchmark.kt#L105>
.
I've implemented this pipeline in multitude of various ways, with Rx2, for
example, it looks like this:
Observable
.range(1, N)
.filter { it.isGood() }
.collect({ IntBox(0) }, { b, x -> b.v += x })
.blockingGet().v
See here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/benchmark/RangeFilterSumBenchmark.kt#L123>
.
All synchronous reactive implementations using Rx2 Observable, Rx2
Flowable or Reactor Flux yield quite similar performance numbers of
4.2-4.6 ms on my MacBook Pro (sorry for my lax benchmarking using notebook,
I hope it will suffice for this non-scientific discussion). Implementation
with Kotlin Sequence follows a bit behind at 5.3 ms and Java Stream
implementation takes 7.6 ms in this particular test (this is likely an
artifact of it not having a native range operator). For an ultimate
baseline note that the corresponding imperative loop works in 0.9ms.
Now, when I naively implement this pipeline with coroutine-based
rendezvous channels using produce { ... } coroutine builders at each
step, then the performance is orders of magnitude worse. Running it
Unconfined improves its performance considerably by it is still a
whooping 326ms. Why so slow? Because RendezvousChannel in
kotlinx.coroutines is a concurrent abstraction designed for transferring
"big chunks" (like network requests and responses) between coroutines
running in different threads in cases when the cost of operation itself
vastly dominates the transfer cost and the work on their performance
optimization have not been even started yet. But even when all the channels
are optimized, they definitely cannot serve as an abstraction for reactive
data processing pipelines. So, what kind of abstraction can?
In order to answer this question I wrote a prototype of such
suspension-based abstraction:
interface Source<out E> {
suspend fun consume(sink: Sink<E>)
}
interface Sink<in E> {
suspend fun send(item: E)
fun close(cause: Throwable?)
}
See here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/source/Sources.kt#L11>
.
I wrote basic implementations of range builder, filter intermediate
operation, and fold terminal operation without any attempt to optimize
them in any way. I have not used inline in any place and the
implementations are deliberately high-level, so filter implementation,
for example, uses source { ... } builder and consumeEach extension and
looks like this:
fun <E> Source<E>.filter(predicate: suspend (E) -> Boolean) = source<E> {
consumeEach {
if (predicate(it)) send(it)
}
}
See here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/source/Sources.kt#L60>.
This is the first key advantage -- operators can be trivially implemented.
Notice that predicate in filter is marked suspend, so if I want to filter
my stream of values based on the result of some asynchronous invocation,
then I, as a user of this library, don't need to know another special
operator. I just use the corresponding suspending function right from
inside the filter { ... }. We need *less* operators to implement with
approach. No need for multiple versions of flatMap, for example. Do you
need to flatten the stream of futures? Just use .map { it.await() } since
you can do any suspending invocation inside of a regular map. That is the
other key advantage.
What about backpressure? There is no request in the above interfaces.
There is no need to have one. We can do backpressure via suspension and we
don't pay the cost of writing code to support that backpressure, we just
have it. That is another key advantage.
The resulting abstraction is easy to use:
Source
.range(1, N)
.filter { it.isGood() }
.fold(0, { a, b -> a + b })
See here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/benchmark/RangeFilterSumBenchmark.kt#L264>.
How fast is it? It performs in 22.7 ms. I'd say it is very good, given that
no performance optimizations have been made yet neither in the library
itself, nor in the compiler (the work on optimizing support for support for
suspending function in Kotlin compiler is now in process as a part of
coroutine design finalization effort).
But what if we want to offload computations to other threads? From the
user stand-point it is as easy as plugging a special operator into the
chain:
Source
.range(1, N)
.async(buffer = 128)
.filter { it.isGood() }
.fold(0, { a, b -> a + b })
See here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/benchmark/RangeFilterSumBenchmark.kt#L280>.
Internally I've just used non-optimized multi-producer/multi-consumer
channel to implement this async operator but it is doing all the proper
backpressure when consumer is slower than producer (suspension!). You can
see it here
<https://github.com/elizarov/StreamBenchmarks/blob/0.0.1/src/main/kotlin/source/Sources.kt#L66>.
Rewriting this operator on top of a fast SPSC channel would bring a
considerable performance improvement, without making the code more
complicated.
To summarize. Building reactive abstractions over suspending functions
brings the following game-changing benefits while paying reasonable
performance penalty vs existing reactive implementations:
- Operators can be trivially implemented.
- No need for separate versions of operators for asynchronous cases,
futures, etc.
- Backpressure support works via suspension "automagically".
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#979 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAEEEUPaitehQzhtEtL5guMBEaKjoMZ4ks5tAVL_gaJpZM4Q8a17>
.
|
|
elizarov wrote: "The other approach is to design APIs and implementation from scratch. The upside is that API can be made 100% Kotlin idiomatic ..., but the downside is that it is quite a large undertaking". |
|
At Badoo we are working on multiplatform library: https://github.com/badoo/Reaktive it's almost production ready |
|
With the availability of Coroutines |
|
@arkivanov Thanks for the link. It seems Reaktive is focusing on non-backpressured types of RxJava 2, so I think |
|
@sdeleuze thanks for the feedback! Actually I'm working on backpressure at the moment. It will be added either by separate Flowable or by updating Observable (not sure yet). Feature is ~50% ready. |
Preface
This past year, Kotlin's growth has been remarkable and Jetbrains strong position to make Kotlin available in the Mobile, Browser, Server and Desktop platforms is exciting to say the least.
At the same time, the asynchronous programming space has been increasingly active as well. JVM reactive libraries (RxJava2, Reactor) have had major releases and the ecosystems surrounding them have increased the adoption and/or facilitated asynchronous programming (Android Architecture Components, Spring 5, etc). Moreover, the intersection between the management of data mutation and asynchronicity continues to lead an explosion of interest in patterns/frameworks (CycleJS, Flux, CQRS, Event-Sourcing, Redux) to address this concerns. This can be seen as well from the increase of literature in this space.
This two trends together present a great opportunity for rich collaboration between software communities spanning multiple platforms.
Reactor Kore
The purpose of this issue is to bring forth conversation regarding the possibility/feasibility of building a kotlin-based cross-platform reactor-core. For starters, this core could target both the JVM and the Android environments.
Members of the Android/ReactiveX community have expressed interest in a Kotlin implementation of RxJava2 and there are some interesting experiments to leverage kotlin coroutines to simplify job scheduler code. A kotlin-based reactor could be an interesting path as well.
It'd be great to hear your thoughts.
@thomasnield
@JakeWharton
@stepango
@smaldini
@simonbasle
@elizarov
@sdeleuze
The text was updated successfully, but these errors were encountered: