Releases: mage-ai/mage-ai
0.9.38 | Goosebumps 😱 🎃

What's Changed
🎉 Exciting New Features
🧑💻 Side-by-side block view
Your Mage development workflow just got a whole lot more efficient. Starting today, you can view blocks side-by-side for twice the editing power! Check this one out to improve your DevEx and make more data magic! Simply click the "side-by-side" icon in the center of the editor to get started!

by @tommydangerous in #3804
🧱 Support for dbt-dremio

Dremio users, rejoice! You can now execute dbt models in you lakehouse thanks to support for the dbt-dremio package.
👨🏻💼 Support Github Enterprise authentication

An often-requested feature, Mage now supports Github Enterprise authentication! 💥
🤖 Support auto termination in workspace
Mage now supports auto-termination checks, which will run once every sixty seconds. This can be used to auto start/stop k8s workspaces. Configure it when creating your workspace to get started!

⏰ Show server time in app
This PR adds a new current time display in the top right of the app header. By default, the time display shows in the UTC format, but if you click on the time display, a dropdown menu shows up:

Nice! Frontend UX improvements coming in clutch!
by @anniexcheng in #3785
🐛 Bug Fixes
- Fix aws secrets circular dependency by @dy46 in #3783
- Fix adding dbt block with mage_secret_var by @wangxiaoyou1993 in #3786
- Fix botocore library pickle error in pipeline scheduler by @wangxiaoyou1993 in #3788
- Incorrect method call on PostgreSQL close connection by @tommydangerous in #3791
- Update block policy by @johnson-mage in #3797
- Fix
DISABLE_NOTEBOOK_EDIT_ACCESSvariable by @dy46 in #3796 - Fix GCS
listdirrecursive bug by @luizarvo in #3807 - Fix
IndexErrorin upstream dbt block by @wangxiaoyou1993 in #3808 - Redshift: Use
TIMESTAMPTZcolumn type for datetimes by @eofs in #3814 - Serialize
np.ndarraybefore exporting to postgres by @wangxiaoyou1993 in #3821 - Refactor workspace by @dy46 in #3811
- Initialize
db_connectionsession before interpolating repo config by @wangxiaoyou1993 in #3824 - Fix code block header overflow menu by @tommydangerous in #3832
- Fix
WorkspaceConfigdefault by @dy46 in #3784
💅 Enhancements & Polish
- Allow specifying credentials info in BigQuery source and dest by @wangxiaoyou1993 in #3790
- Support Redshift Serverless by @wangxiaoyou1993 in #3823
- Hide
mage-reporemote by @dy46 in #3806 - Added Custom Spark Cluster by @KamarulAdha in #3812
- Improved Slack notification design by @hanslemm in #3778
- Add total execution time to Pipeline Runs table by @anniexcheng in #3801
- Case sensitive column names in DI SQL destinations by @Luishfs in #3685
😎 New Contributors
- @KamarulAdha made their first contribution in #3812
- @eofs made their first contribution in #3814
- @hanslemm made their first contribution in #3778
- @edmondwinston made their first contribution in #3820
Full Changelog: 0.9.35...0.9.38
Contributors
Assets 2
0.9.35 | 🤹♂️ Loki

What's Changed
🎉 Exciting New Features
🙇♂️ The Great Pipeline Unification
Perhaps not as momentus as The Second Great Unification, this unification is much more useful for data pipelines! Data Integration sources & destinations can now be added as blocks in batch pipelines! 🤯
What does this mean? Using Mage, you can now perform integration (extract), transformation, and loading in the SAME pipeline using Singer sources and your favorite tools (dbt, Python, SQL)! Read more in our docs here.
This is like having Fivetran/Airbyte, dbt, and a jupyter notebook all-in-one WITH engineering best practices built-in!

👩🏻💻 Interactions - a no-code UI for configuring data pipelines
Another huge update, Mage now let's you build templates to unlock data at scale. You can configure data pipelines that are fully customizable for stakeholders and consumers. Read more about interactions here and get started building today!
This functionality will go a long way for democratizing data pipelines and easing data workloads!

🤓 Granular API Permissions
Mage now supports granular API permissions on ANY action. Each permission can grant read and write operations on specific resources (e.g. API endpoints). One or more roles can be assigned to 1 or multiple users.
What does this mean? You can create permissions for your team at the most granular level possible. Mage is now completely governable for ANY action. Read more here.

🥳 NEW MongoDB CDC Streaming Source

Mage now supports MongoDB CDC Streaming Sources! A big thanks to @emincanoguz11 for the contribution!
by @emincanoguz11 in #3716
🐛 Bug Fixes
- Fixed imports and removed flake8 check for taps/targets by @Luishfs in #3740
- Fix fetching roles new for User by @tommydangerous in #3743
- Fix extracting update statement from SQL by @wangxiaoyou1993 in #3749
- Convert schema name to uppercase when
disable_double_quotesby @wangxiaoyou1993 in #3761 - Fix loading data integration sources by @wangxiaoyou1993 in #3773
💅 Enhancements & Polish
- Project-wide pipeline run filters by @johnson-mage in #3659
- Cron expression syntax error display for triggers in code by @johnson-mage in #3696
- Flyout menu overflow by @johnson-mage in #3759
- Support upsert in MongoDB streaming sink by @wangxiaoyou1993 in #3774
- Support setting token in the header for API trigger by @dy46 in #3674
- Update Markdown block docs with image support by @anniexcheng in #3744
- Set attributes from PubSub message to handler dict by @fajrifernanda in #3736
- Display elapsed time on
datetimehover rather than UTC by @anniexcheng in #3739
New Contributors
- @fajrifernanda made their first contribution in #3736
- @emincanoguz11 made their first contribution in #3716
Full Changelog: 0.9.34...0.9.35
Contributors
Assets 2
0.9.34 | C-3PO

What's Changed
🎉 Exciting New Features
🧠 Add support for dbt-synapse
This is going to "dbt" amazing! Mage now supports the dbt-synapse library, allowing dbt to be executed against the Azure Synapse Data Warehouse. You can read more on the package here. Excited to see our Azure users make use of this one!
☁️ Added Google Cloud Pubsub as a sink for streaming pipeline
A big shout out to @pammusankolli, who recently added Google Cloud Pubsub as a sink for data streaming pipelines! If you're not familiar with PubSub, you can read more here. Be sure to check out the docs in Mage to build your next pipeline!
🤓 Support HTML tags in Markdown blocks
All of our Markdown enthusiasts will appreciate this one! Previously, Mage's markdown blocks only supported images via this format:

Now, Mage supports <img> elements with custom sizes in Markdown blocks by providing width and height attributes like so:
<img src="https://images.photowall.com/products/57215/golden-retriever-puppy.jpg?h=699&q=85" alt="drawing" width="200"/>
Here are some examples:


Nice!
🔍 Added Opensearch Destination

Mage now supports OpenSearch as a destination in data integration pipelines! 🥳
🐛 Bug Fixes
- Hide empty images by @tommydangerous in #3660
- YAML block language display by @johnson-mage in #3678
- Add None for block check by @dy46 in #3677
- Raise exception if there are serialization errors by @dy46 in #3630
- Fixed Twitter ads imports by @Luishfs in #3690
- Fixed target-salesforce imports by @Luishfs in #3688
- Fix git config preserve when
.preferences.yamlfile doesn't exist by @dy46 in #3693 - Fix MySQL source int comparisonby @wangxiaoyou1993 in #3709
- Suppress secret logs for aws secrets by @dy46 in #3704
- Update Backfill policy by @johnson-mage in #3723
- Fix block tests not getting output by @tommydangerous in #3724
- Remove the requirement for schedule type by @tommydangerous in #3726
- Check for empty column headers by @johnson-mage in #3729
- Fixed typo and simplified text for empty dashboard by @MageKai in #3668
💅 Enhancements & Polish
- Propagate tags of ECS task definition to task executors by @gabrieleiacono in #3670
- Also search pipeline run event_variables by @johnson-mage in #3672
- Read AWS secrets from Mage secrets when no ENVs are set by @jamesking-github in #3607
- Speed up IO MSSQL export method by @wangxiaoyou1993 in #3697
- Support
UPDATEcommand in raw SQL command by @wangxiaoyou1993 in #3705 - Allow customizing batch fetch limit for data integration pipelineby @wangxiaoyou1993 in #3713
- Support using custom Spark sessionby @wangxiaoyou1993 in #3725
- Add activity to status endpoint when requested by @dy46 in #3708
- Replace runtime variables card list with table by @anniexcheng in #3703
- Storybook cleanup by @johnson-mage in #3658
New Contributors
- @gabrieleiacono made their first contribution in #3670
- @anniexcheng made their first contribution in #3692
Full Changelog: 0.9.30...0.9.34
Contributors
Assets 2
0.9.30 | Cowboy Bebop 🤠🚀

What's Changed
🎉 Exciting New Features
🌊 Streaming: Base Class Overhaul + 8 New Destinations
This. is. huge. With a complete base class re-write, every IO destination is now a streaming destination.
That means you can stream to:
And any future destinations added as an IO base. Huge shutout to @wangxiaoyou1993 on the herculean effort!
by @wangxiaoyou1993 in #3623
👀 Recently viewed pipelines
Some frontend polish now allows you to see your Recently Viewed pipelines from the overview page— a nice touch!

by @tommydangerous in #3633
👨👩👧👦 Community: GCS Sensors
@pammusankolli deliver's his first contribution by adding a Google Cloud Storage sensor to check if a file exists in a given bucket! Thanks for the add— this will be super useful to our Google platform users!
by @pammusankolli in #3651
🧩 Support syncing Git submodules
A solid improvement to our Git Sync functionality, you can now sync submodules, too! Just check the Git Sync settings to enable the feature.

🔂 Add always on schedule interval
On user request, we've added an @always_on interval for scheduled triggers. Always on schedules will trigger the new pipeline run as soon as the latest pipeline run is completed.
Once a pipeline run ends, regardless of whether or not it failed or succeeded, it will start a new run. Let us know if you find that valuable!
🐛 Bug Fixes
- Lazy import dbt block and library by @wangxiaoyou1993 in #3608
- Fix invalid keyword argument error when requesting a list from Stripe by @jdvermeire in #3479
- Fix snowflake output column names by @wangxiaoyou1993 in #3612
- Fix charts when trying to change name by @tommydangerous in #3614
- Fix export_batch_data not accepting tags as a kwarg by @tommydangerous in #3619
- Handle secret key and uuid whitespace by @dy46 in #3621
- Fix materializing upstream outputs for dbt by @christopherscholz in #3617
- Fix memory leak in data integration pipelines by @wangxiaoyou1993 in #3641
- Initialize db connection session by @dy46 in #3609
- Fix auto generating mage_sources.yml for dbt upstream blocks by @wangxiaoyou1993 in #3647
- Pipelines list fixes by @johnson-mage in #3648
💅 Enhancements & Polish
- Add sortable block run columns by @johnson-mage in #3613
- Clarify components based on UTC time in Overview page by @johnson-mage in #3615
- Support interpolating pipeline variables in streaming configs by @wangxiaoyou1993 in #3616
- Scheduler trigger interval as environment variable setting by @PopaRares in #3591
- Pipeline runs table (for individual pipelines) updates by @johnson-mage in #3629
- Reduce dynamic child block at any level by @tommydangerous in #3634
- Apache Kafka - SASL_PLAINTEXT by @Senpumaru in #3643
- Support Kafka SASL_SSL SCRAM-SHA-512 authentication by @wangxiaoyou1993 in #3649
- Update search_path command by @dy46 in #3625
New Contributors
- @jdvermeire made their first contribution in #3479
- @PopaRares made their first contribution in #3591
- @Senpumaru made their first contribution in #3643
- @pammusankolli made their first contribution in #3651
Full Changelog: 0.9.28...0.9.30
Contributors
Assets 2
0.9.28 | The Creator 🤖

What's Changed
🎉 Exciting New Features
🫨 Brand new dbt blocks!
One of our top contributors @christopherscholz just delivered a huge feature! A completely streamlined dbt Block!

Here are some of the highlights:
- Directly integrated into
dbt-core, instead of calling it via a subprocess, which allows to use all of dbts functionalities - Use dbt to seed output dataframes from upstream blocks
- Use dbt to generate correct relations e.g. default schema names, which differ between databases
- Use dbt to preview models, by backporting the
dbt seedcommand todbt-core==1.4.7 - No use of any mage based database connections to handle the block
- Allows to install any dbt adapter, which supports the dbt-core version
- Moved all code into a single interface called
DBTBlock- Doubles as a factory for child blocks
DBTBlockSQLandDBTBlockYAML - Child blocks make it easier to understand which block does what
- Doubles as a factory for child blocks
There's lots to unpack in this one, so be sure to read more in the PR below and check out our updated docs.
by @christopherscholz in #3497
➕ Add GCS storage to store block output variables
Google Cloud users rejoice! Mage already supports storing block output variables in S3, but thanks to contributor @luizarvo, you can now do the same in GCS!
Check out the PR for more details and read-up on implementation here.
✨ Tableau Data Integration Source
Another community-led integration! Thank you @mohamad-balouza for adding a Tableau source for data integration pipelines!

by @mohamad-balouza in #3581
🦆 Add DuckDB loader and exporter templates
Last week, we rolled out a ton of new DuckDB functionality, this week, we're adding DuckDB loader and exporter templates! Be sure to check them out when building your new DuckDB pipelines! 😄


by @matrixstone in #3553
🧱 Bulk retry incomplete block runs
Exciting frontend improvements are coming your way! You can now retry all of a pipeline's incomplete block runs from the UI. This includes all block runs that do not have completed status.

🐛 Bug Fixes
- Fix using
S3Storageto store block output variables by @wangxiaoyou1993 in #3559 and #3588 - Support local timezone for cron expressions by @johnson-mage in #3561
- Make API middlware set status codes if there's an API key or OAUTH token error by @splatcollision in #3560
- Fix Postgres connection url parsing by @dy46 in #3570
- Fix passing in logger for alternative block execution methods by @dy46 in #3571
- Fix variables interpolation in dbt target by @wangxiaoyou1993 in #3578
- Fixed
dbt seedrequiring variables by @tommydangerous in #3579 - Fix updating of
pipelineRowsSortedwhen clearing search query by @johnson-mage in #3596 - Check yaml serialization before writing variable by @dy46 in #3598
- Fix
condition_failedcheck for dynamic blocks by @dy46 in #3595
💅 Enhancements & Polish
- Display warning on demo site to prevent users from entering private credentials by @johnson-mage in #3550
- Update wording for empty pipeline template state by @johnson-mage in #3557
- Reorder upstream blocks by @johnson-mage in #3541
- Prioritize using
remote_variables_dirfor variable manager by @wangxiaoyou1993 in #3562 - Customize ecs config by @dy46 in #3558
- Bookmark values minor improvements by @johnson-mage in #3576
- Speed up bigquery destination in data integration pipeline by @wangxiaoyou1993 in #3590
- Allow declared cookies to propagate to resources by @hugabora in #3555
- Refactor: use generic function to call LLM avoid code duplication by @matrixstone in #3358
- Allow configuring EMR cluster spark properties by @wangxiaoyou1993 in #3592
- Support
TIMESTAMPin redshift convert by @RobinFrcd #3567
New Contributors
- @luizarvo made their first contribution in #3597
- @RobinFrcd made their first contribution in #3567
Full Changelog: 0.9.26...0.9.28
Contributors
Assets 2
0.9.26 | Expend4bles 💥

What's Changed
🎉 Exciting New Features
🐣 DuckDB IO Class and SQL Block
Folks, we've got some ducking magic going on in this release. You can now use DuckDB files inside Mage's SQL Blocks. 🥳 🦆 🪄
You can use data loaders to CREATE and SELECT from DuckDB tables as well as write new data to DuckDB.

Check out our docs to get started today!
by @matrixstone in #3463
📊 Charts 2.0
This is another huge feature— a complete overhaul of our Charts functionality!
There are 2 new charts dashboards: a dashboard for all your pipelines and a dashboard for each pipeline.
You can add charts of various types with different sources of data and use these dashboards for observability or for analytics.
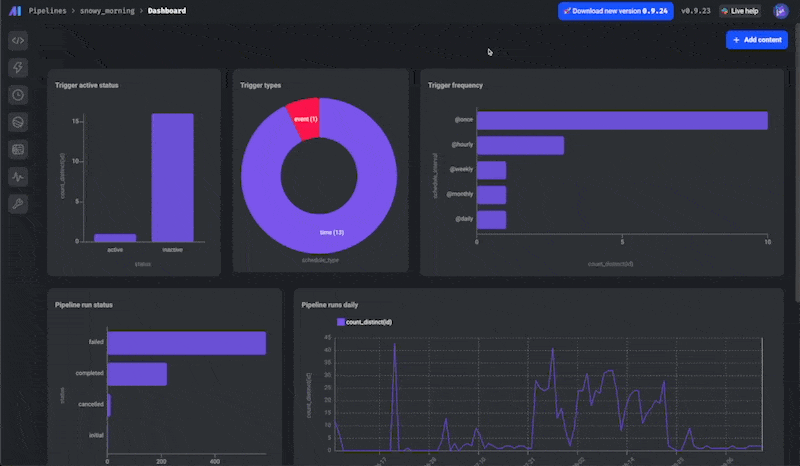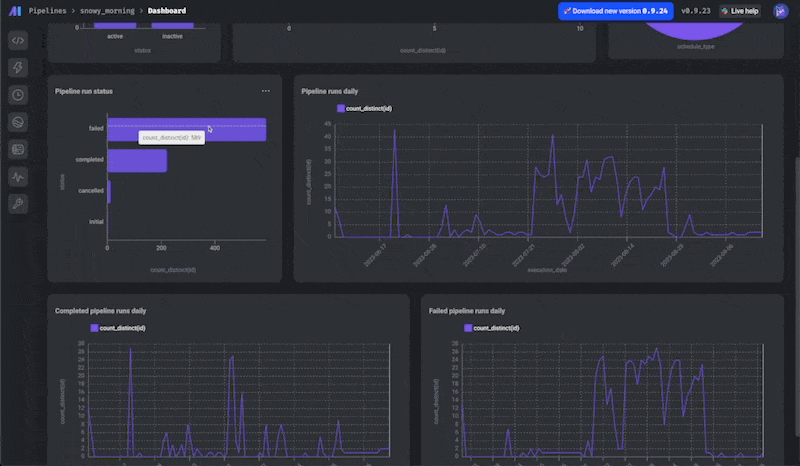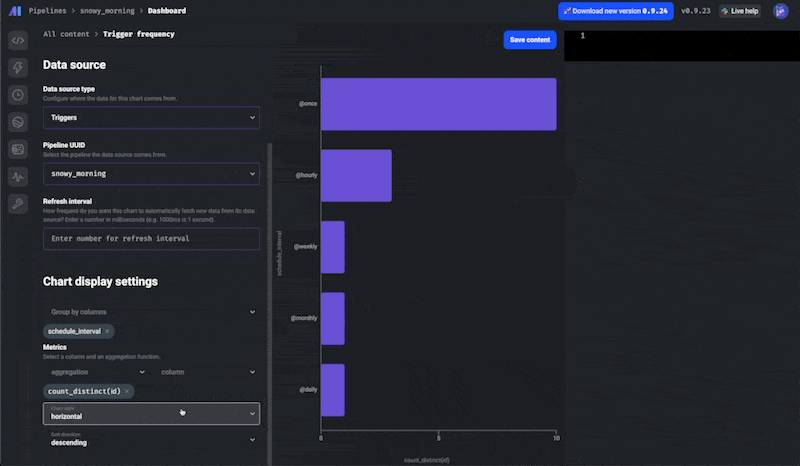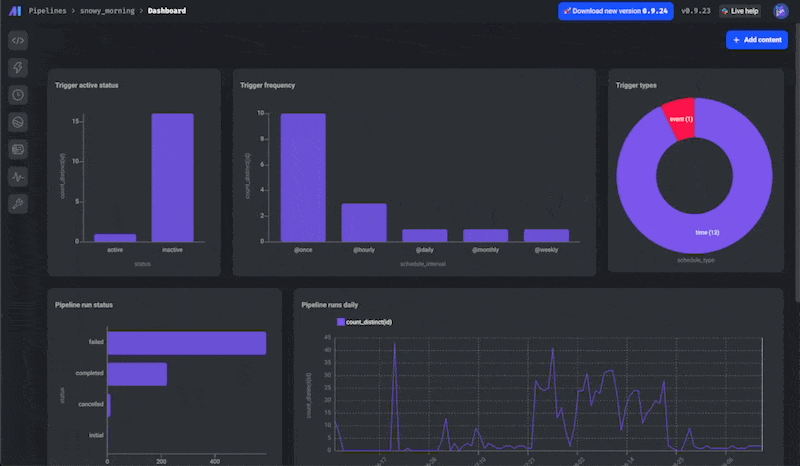
There's a ton to unpack here, so be sure to read more in our docs.
⏰ Local timezone setting
This one is a big quality of life improvement: Mage can now display datetimes in local timezones... No more UTC conversion! Just navigate to Settings > Workspace > Preferences to enable a new timezone!

by @johnson-mage in #3481
🔁 Influxdb data loader

A big shoutout to @mazieb! You can now stream data from InfluxDB via Mage. Thanks for your hard work! They added a destination last week!
Read more in our docs here.
🎚️ Support for custom logging levels
Another frequently requested feature shipping this week, courtesy of @dy46: custom block-level logging!
You can now specify logging at the block-level by directly changing the logger settings:
@data_loader
def load_data(*args, **kwargs):
kwarg_logger = kwargs.get('logger')
kwarg_logger.info('Test logger info')
kwarg_logger.warning('Test logger warning')
kwarg_logger.error('Test logger error')
...See more in our docs here.
🐛 Bug Fixes
- Update Oracle discovery table by @matrixstone in #3506
- Locking Polars version to 0.19.2 by @Luishfs in #3510
- Fix memory leak caused by
zmqcontext destroy by @wangxiaoyou1993 in #3514 - Fix: S3 path is joined using
os.path.join-> Error non posix systems by @christopherscholz in #3520 - Fix raw SQL alias by @tommydangerous in #3534
- Fix how table name is parsed for SQL blocks by @dy46 in #3498
- Fix:
dtypeintis not always casted asint64by @christopherscholz in #3522 - Fix: paths include posix like forward slash in many instances, which will not work on non-posix systems by @christopherscholz in #3521
- Fix git authentication issue by @dy46 in #3537
- Fix overwriting runtime variables for dbt block by @tommydangerous in #3543
- Added the Elasticsearch library to setup file by @sujiplr in #3501
- Fix:
timestamp out of rangeon Windows by @christopherscholz in #3519 - Fix: Dependency mismatch between
mage_aiandmage_integrationsby @christopherscholz in #3525
💅 Enhancements & Polish
- Only show
Executepipeline action for streaming pipelines by @johnson-mage in #3492 - Throw exception for ingress by @dy46 in #3484
- Update terminal icon by @johnson-mage in #3503
- Only allow switching to local branches by @dy46 in #3507
- Add usage statistics for creating blocks, pipelines, and custom templates by @tommydangerous in #3528
- Support multiple kafka topics in kafka source by @wangxiaoyou1993 in #3532
- Support trailing slash when base path set by @hugabora in #3530
- Add checks for cwd in websocket server by @dy46 in #3495
- Kafka source and sink include metadata by @mazieb in #3404
- Removing obsolete code, handle root path by @hugabora in #3546
New Contributors
Full Changelog: 0.9.23...0.9.26
Contributors
Assets 2
0.9.23 | One Piece 🏴☠️

What's Changed
🎉 Exciting New Features
✨ Add & update block variables through UI
📰 Hot off the press, you can now add and update block variables via the Mage UI!


Check out our docs to learn more about block variables.
by @johnson-mage in #3451
✨ PowerBI source [Data Integration]

You can now pull PowerBI data in to all your Mage projects!
A big shoutout to @mohamad-balouza for this awesome contribution. 🎉
Read more about the connection here.
by @mohamad-balouza in #3433
✨ Knowi source [Data Integration]

@mohamad-balouza was hard at work! You can also integrate Knowi data in your Mage projects! 🤯
Read more about the connection here.
by @mohamad-balouza in #3446
✨ InfluxDB Destination [Streaming]
A big shoutout to @mazieb! You can now stream data to InfluxDB via Mage. Thanks for your hard work!
Read more in our docs here.
🐛 Bug Fixes
- Fix command on GCP cloud run by @wangxiaoyou1993 in #3437
- Fix Git sync issues by @dy46 in #3436
- Bump GitPython and update Git Sync logic by @dy46 in #3458
- Remove unnecessary
statusquery from block runs request by @johnson-mage in #3444 - Fix AWS secrets manager dependency issue by @dy46 in #3448
- Fix comparing bookmark value for timestamp column in BigQuery by @wangxiaoyou1993 in #3452
- Compare
start_timeandexecution_dateinshould_scheduleby @wangxiaoyou1993 in #3466 - Fix initial ordering of pipeline rows by @johnson-mage in #3472
💅 Enhancements & Polish
- Update Triggers list page with filters and clean up subheader by @johnson-mage in #3424
- Fix and optimize pre-commit hook check-yaml and add check-json by @christopherscholz in #3412
- Full Code Quality Check in Github Action Workflow "Build and Test" by @christopherscholz in #3413
- Docker: Lint Image and some best practices by @christopherscholz in #3410
- Support for
local_python_forceexecutor type and configuring ECS executor launch type @wangxiaoyou1993 in #3447 - Limit Github Action Workflow "Build and Test" by @christopherscholz in #3411
- Hide OpenAI API key by @johnson-mage in #3455
- Add additional health check message and support unique constraints in Postgres sink by @wangxiaoyou1993 in #3457
- Support autoscaling EMR clusters by @wangxiaoyou1993 in #3468
- Support GitHub Auth for different workspaces by @dy46 in #3456
- Add timestamp precision in Trino by @Luishfs in #3465
- Handle transformer renaming columns not breaking destination data types in integration pipelines by @splatcollision in #3462
New Contributors
Full Changelog: 0.9.21...0.9.23
Contributors
Assets 2
0.9.21 | Ahsoka 🥷🏻

What's Changed
🎉 Exciting New Features
✨ Single-task ECS pipeline executor 🤖
Mage now supports running the whole pipeline process in one AWS ECS task instead of running pipeline blocks in separate ECS tasks! This allows you to speed up pipeline execution in ECS tasks by saving ECS task startup time.
Here's an example pipeline metadata.yaml:
blocks:
- ...
- ...
executor_type: ecs
run_pipeline_in_one_process: true
name: example_pipeline
...The ECS executor_config can also be configured at the pipeline level.
by @wangxiaoyou1993 in #3418
✨ Postgres streaming destination 🐘
Postgres enthusiasts rejoice! You can now stream data directly to Postgres via streaming pipelines! 😳
Check out the docs for more information on this handy new destination.
by @wangxiaoyou1993 in #3423
✨ Added sorting to the Block Runs table
You can now sort the Block Runs table by clicking on the column headers! Those of us who are passionate about having our ducks in a row are happy about this one! 🦆

by @johnson-mage in #3356
✨ Enable deleting individual runs from pipeline runs table
Bothered by that one run you'd rather forget? Individual runs can be dropped from the pipeline runs table, so you don't have to worry about them anymore!

by @johnson-mage in #3370
✨ Add timeout for block runs and pipeline runs
Much like Buzz Lightyear, we're headed "to infinity and beyond," but we get that your pipelines shouldn't be. This feature allows you to configure timeouts for both blocks and pipelines— if a run exceeds the timeout, it will be marked as failed.


🐛 Bug Fixes
- Fix
nextjslocal build type error by @johnson-mage in #3389 - Fixed
NULLheaders breaking API Source by @Luishfs in #3386 - Fixes on MongoDB destination (Data integration) by @Luishfs in #3388
- Fix Git commit from version control by @dy46 in #3397
- Change the default search path to the schema given in the connection URL for PostgreSQL by @csharplus in #3406
- Raise exception if a pipeline has duplicate block uuids by @dy46 in #3385
- Fix creating subfolder when renaming block by @wangxiaoyou1993 in #3419
- Docker: Installation Method of Node using
setup_17.xis no longer supported by @christopherscholz in #3405 - [dy] Add support for key properties for postgresql destination by @dy46 in #3422
💅 Enhancements & Polish
- Added disable schema creation config by @Luishfs in #3417
- Read DB credentials from AWS secret manager by @dy46 in #3354
- Add healthcheck to sqs streaming sourceby @wangxiaoyou1993 in #3393
- Enhancement: token expiry time env by @juancaven1988 in #3396
- Auto-update triggers in code when making changes in UI by @johnson-mage in #3395
- Add fetch and reset to version control app by @dy46 in #3409
- Set correct file permissions when using shutil by @christopherscholz in #3262
- Create
lsnand_mage_deleted_atin initial log_based syncby @wangxiaoyou1993 in #3394 - Feat: Added Missing destination block warning by @Luishfs in #3407
New Contributors
Full Changelog: 0.9.19...0.9.21
Contributors
Assets 2
0.9.19 | The Equalizer ⌚

What's Changed
🎉 Exciting New Features
✨ New AI Functionality
As a part of this release, we have some exciting new AI functionality: you can now generate pipelines and add inline comments using AI. 🤯


See the following links for documentation of the new functionality.
by @tommydangerous in #3365 and #3359
✨ Elasticsearch as sink for streaming
Elasiticsearch is now available as a streaming sink. 🥳🎉

A big thanks to @sujiplr for their contribution!
✨ Add GitHub source
The GitHub API is now available as a data integrations— you can pull in commits, changes, and more from the GitHub API!
✨ Interpolate variables in dbt profiles
This is a big one for our dbt users out there! You can now use {{ variables('...') }} in dbt profiles.yml.
jaffle_shop:
outputs:
dev:
dbname: postgres
host: host.docker.internal
port: 5432
schema: {{ variables('dbt_schema') }}
target: devThat means pulling in custom Mage variables, directly!
by @tommydangerous in #3337
✨ Enable sorting on pipelines dashboard
Some great frontend improvements are going down! You can now sort pipelines on the dashboards, both with and without groups/filters enabled!

by @johnson-mage in #3327
✨ Display data integration source docs inline
Another awesome community contribution— this one also on the frontend. Thanks to @splatcollision, we now have inline documentation for our data integration sources!

Now, you can see exactly what you need, directly from the UI!
by @splatcollision in #3349
🐛 Bug Fixes
- Fix MongoDB source by @wangxiaoyou1993 in #3342
- Overwrite existing project_uuid if a project_uuid is set when starting the server by @dy46 in #3338
- Add started_at to pipeline run policy by @dy46 in #3345
- Fix passing variables to run_blocks by @wangxiaoyou1993 in #3346
- Not pass liveness_probe to cloud run jobs by @wangxiaoyou1993 in #3355
- Fix data integration pipeline column renaming in transformer block by @wangxiaoyou1993 in #3360
- Fix FileContentResource file path check by @dy46 in #3363
- Update api/status endpoint by @dy46 in #3352
- Removed unique_constraints from valid_replication_keys definition by @Luishfs in #3369
- Fix dbt command failure due to empty content args by @wangxiaoyou1993 in #3376
💅 Enhancements & Polish
✨ New Docs Structure
You might notice our docs have a new look! We've changed how we think about side-navs and tabs.

Our goal is to help you find what you need, faster. We hope you like it!
_by @mattppal in #3324 and #3367
✨ Other Enhancements
- Explain cron syntax in a human readable way by @johnson-mage in #3348
- Add run_pipeline_in_one_process in pipeline settings by @tommydangerous in #3347
- Preview next pipeline run time for triggers by @johnson-mage in #3341
- Optimize Docker build by @christopherscholz in #3329
- Integration pipeline column explanations by @johnson-mage in #3353
- Allow using k8s executor config for streaming pipeline by @wangxiaoyou1993 in #3371
- Add role to Snowflake data integration pipeline by @wangxiaoyou1993 in #3374
- Disable automatic dbt tests by @tommydangerous in #3357
- Update terminal server user token handling by @dy46 in #3350
- Restrict file creation via API by @dy46 in #3351
New Contributors
- @sujiplr made their first contribution in #3335
- @splatcollision made their first contribution in #3349
- @pilosoposerio made their first contribution in #3377
Full Changelog: 0.9.16...0.9.19
Contributors
Assets 2
0.9.16 | Gran Turismo 🏁

What's Changed
🎉 Exciting New Features
✨ Global data products are now available in Mage! 🎉
A data product is any piece of data created by 1 or more blocks in a pipeline. For example, a block can create a data product that is an in-memory DataFrame, or a JSON serializable data structure, or a table in a database.
A global data product is a data product that can be referenced and used in any pipeline across the entire project. A global data product is entered into the global registry (global_data_products.yaml) under a unique ID (UUID) and it references an existing pipeline. Learn more here.
by @tommydangerous in #3206
✨ Add block templates for MSSQL 🤘
We now have some awesome block templates for our MySQL users out there!
Check them out:


by @wangxiaoyou1993 in #3294
✨ Support sharing memory objects across blocks
In the metadata.yml of a standard batch pipeline, you can now configure running pipelines in a single process:
blocks:
...
run_pipeline_in_one_process: true
...You may now also:
- Define object once and make it available in any block in the pipeline via keyword arguments
kwargs['context'] - Pass variables between blocks in memory directly


by @wangxiaoyou1993 in #3280
🐛 Bug Fixes
- Added type check on unique_constraints by @Luishfs in #3282
- Proper filtering in multi-workspace pipeline runs & subproject role creation by @dy46 in #3283
- Add column identifier for Trino by @dy46 in #3311
- Fix mage run cli command with variables by @wangxiaoyou1993 in #3315
- Fix
async_generate_block_with_descriptionupstream_blocksparam by @matrixstone in #3313 - Removed unused config in Salesforce destination by @Luishfs in #3287
- Fix BigQuery bookmark datetime comparison by @wangxiaoyou1993 in #3325
- Improve secrets handling by @dy46 in #3309
- Adding
oracledblib to mage-ai by @Luishfs in #3319
💅 Enhancements & Polish
base.py: Add XML support for file read/write in S3, GCP, and other cloud storage providers by @adelcast in #3279- Save logs scroll position for trigger logs by @johnson-mage in #3285
- Update error logging for block runs by @dy46 in #3234
- Browser-specific dependency graph improvements by @johnson-mage in #3300
- Updated Clickhouse destination by @Luishfs in #3286
- Make pipeline run count pagination consistent by @johnson-mage in #3310
- Add new base path environment variables by @dy46 in #3289
- Add pipeline
created_atproperty by @johnson-mage in #3317 - Add pagination to pipeline run block runs page by @johnson-mage in #3316
- Added all columns as replication key by @Luishfs in #3301
- Improve streaming pipeline stability by @wangxiaoyou1993 in #3326
- Added test connection to
google_adssource by @Luishfs in #3322 - Open and edit any file, including prefix . by @tommydangerous in #3255
- Add namespace to K8sBlockExecutor config by @mattcamp in #3246
- Add a community Code of Conduct by @mattppal in #3318
- Add documentation for adapting an existing tap by @mattppal in #3290
New Contributors
Full Changelog: 0.9.14...0.9.16