From 591d5e48bfc5708b51c8bb28b1720709356f5b77 Mon Sep 17 00:00:00 2001
From: gongna <2036479155@qq.com>
Date: Wed, 31 Jul 2024 13:56:56 +0800
Subject: [PATCH] feat:Migrate all blog notes
---
_posts/2020-02-1-test-markdown.md | 76 +
_posts/2020-02-2-test-markdown.md | 66 +
.../2020-02-26-flake-it-till-you-make-it.md | 161 +-
_posts/2020-02-28-sample-markdown.md | 95 -
_posts/2020-02-28-test-markdown.md | 185 ++
_posts/2020-06-15-test-markdown.md | 67 +
_posts/2021-02-28-test-markdown.md | 105 +
_posts/2021-11-20-test-markdown.md | 88 +
_posts/2021-12-30-test-markdown.md | 254 ++
_posts/2022-02-15-test-markdown.md | 461 ++++
_posts/2022-02-19-test-markdown.md | 32 +
_posts/2022-03-14-test-markdown.md | 1133 +++++++++
_posts/2022-04-17-test-markdown.md | 270 ++
_posts/2022-04-18-test-markdown.md | 128 +
_posts/2022-04-20-test-markdown.md | 264 ++
_posts/2022-04-25-test-markdown.md | 326 +++
_posts/2022-05-18-test-markdown.md | 55 +
_posts/2022-05-20-test-markdown.md | 358 +++
_posts/2022-06-14-test-markdown.md | 77 +
_posts/2022-06-15-test-markdown.md | 162 ++
_posts/2022-07-08-test-markdown.md | 692 ++++++
_posts/2022-07-09test-markdown.md | 50 +
_posts/2022-07-11-test-markdown.md | 118 +
_posts/2022-07-12-test-markdown.md | 397 +++
_posts/2022-07-13-test-markdown.md | 726 ++++++
_posts/2022-07-14-test-markdown.md | 89 +
_posts/2022-07-15-test-markdown.md | 33 +
_posts/2022-07-16-test-markdown.md | 463 ++++
_posts/2022-07-17-test-markdown.md | 296 +++
_posts/2022-07-18-test-markdown.md | 433 ++++
_posts/2022-07-20-test-markdown.md | 60 +
_posts/2022-07-21-test-markdown.md | 233 ++
_posts/2022-07-22-test-markdown.md | 210 ++
_posts/2022-08-19-test-markdown.md | 326 +++
_posts/2022-08-20-test-markdown.md | 220 ++
_posts/2022-08-21-test-markdown.md | 92 +
_posts/2022-08-27-test-markdown.md | 174 ++
_posts/2022-08-28-test-markdown.md | 366 +++
_posts/2022-09-01-test-markdown.md | 57 +
_posts/2022-09-02-test-markdown.md | 223 ++
_posts/2022-09-04-test-markdown.md | 277 +++
_posts/2022-09-05-test-markdown.md | 962 ++++++++
_posts/2022-09-06-test-markdown.md | 239 ++
_posts/2022-10-02-test-markdown.md | 138 ++
_posts/2022-10-03-test-markdown.md | 127 +
_posts/2022-10-04-test-markdown.md | 898 +++++++
_posts/2022-10-05-test-markdown.md | 366 +++
_posts/2022-10-06-test-markdown.md | 58 +
_posts/2022-10-07-test-markdown.md | 547 +++++
_posts/2022-10-09-test-markdown.md | 973 ++++++++
_posts/2022-10-10-test-markdown.md | 88 +
_posts/2022-10-11-test-markdown.md | 292 +++
_posts/2022-10-12-test-markdown.md | 75 +
_posts/2022-10-13-test-markdown.md | 1134 +++++++++
_posts/2022-10-14-test-markdown.md | 149 ++
_posts/2022-10-15-test-markdown.md | 246 ++
_posts/2022-10-21-test-markdown.md | 14 +
_posts/2022-10-22-test-markdown.md | 23 +
_posts/2022-10-23-test-markdown.md | 7 +
_posts/2022-10-24-test-markdown.md | 115 +
_posts/2022-11-01-test-markdown.md | 79 +
_posts/2022-11-02-test-markdown.md | 436 ++++
_posts/2022-11-03-test-markdown.md | 1986 +++++++++++++++
_posts/2022-11-09-test-markdown.md | 604 +++++
_posts/2022-11-11-test-markdown.md | 216 ++
_posts/2022-11-12-test-markdown.md | 118 +
_posts/2022-11-19-test-markdown.md | 356 +++
_posts/2022-11-20-test-markdown.md | 183 ++
_posts/2022-11-21-test-markdown.md | 1568 ++++++++++++
_posts/2022-11-22-test-markdown.md | 190 ++
_posts/2022-11-23-test-markdown.md | 632 +++++
_posts/2022-11-24-test-markdown.md | 186 ++
_posts/2022-11-25-test-markdown.md | 133 +
_posts/2022-11-26-test-markdown.md | 407 ++++
_posts/2022-12-29-test-markdown.md | 287 +++
_posts/2022-12-31-test-markdown.md | 19 +
_posts/2022-12-5-test-markdown.md | 112 +
_posts/2022-12-6-test-markdown.md | 320 +++
_posts/2023-1-1-test-markdown.md | 200 ++
_posts/2023-1-10-test-markdown.md | 76 +
_posts/2023-1-16-test-markdown.md | 268 ++
_posts/2023-1-17-test-markdown.md | 170 ++
_posts/2023-1-18-test-markdown.md | 150 ++
_posts/2023-1-19-test-markdown.md | 1030 ++++++++
_posts/2023-1-20-test-markdown.md | 170 ++
_posts/2023-1-21-test-markdown.md | 273 +++
_posts/2023-1-22-test-markdown.md | 366 +++
_posts/2023-1-29-test-markdown.md | 346 +++
_posts/2023-1-3-test-markdown.md | 30 +
_posts/2023-1-30-test-markdown.md | 9 +
_posts/2023-1-31-test-markdown.md | 347 +++
_posts/2023-1-9-test-markdown.md | 37 +
_posts/2023-10-1-test-markdown.md | 46 +
_posts/2023-10-10-test-markdown.md | 289 +++
_posts/2023-10-11-test-markdown.md | 1406 +++++++++++
_posts/2023-10-12-test-markdown.md | 835 +++++++
_posts/2023-10-13-test-markdown.md | 909 +++++++
_posts/2023-10-14-test-markdown.md | 573 +++++
_posts/2023-10-15-test-markdown.md | 39 +
_posts/2023-10-16-test-markdown.md | 258 ++
_posts/2023-10-17-test-markdown.md | 369 +++
_posts/2023-10-18-test-markdown.md | 632 +++++
_posts/2023-10-19-test-markdown.md | 1103 +++++++++
_posts/2023-10-2-test-markdown.md | 128 +
_posts/2023-10-22-test-markdown.md | 83 +
_posts/2023-10-23-test-markdown.md | 223 ++
_posts/2023-10-3-test-markdown.md | 263 ++
_posts/2023-10-4-test-markdown.md | 87 +
_posts/2023-10-5-test-markdown.md | 278 +++
_posts/2023-10-6-test-markdown.md | 305 +++
_posts/2023-10-7-test-markdown.md | 1035 ++++++++
_posts/2023-10-8-test-markdown.md | 976 ++++++++
_posts/2023-10-9-test-markdown.md | 411 ++++
_posts/2023-11-10-test-markdown.md | 704 ++++++
_posts/2023-11-11-test-markdown.md | 215 ++
_posts/2023-11-12-test-markdown.md | 196 ++
_posts/2023-11-5-test-markdown.md | 364 +++
_posts/2023-11-6-test-markdown.md | 515 ++++
_posts/2023-11-7-test-markdown.md | 59 +
_posts/2023-11-9-test-markdown.md | 51 +
_posts/2023-2-1-test-markdown.md | 338 +++
_posts/2023-2-10-test-markdown.md | 797 ++++++
_posts/2023-2-2-test-markdown.md | 7 +
_posts/2023-2-20-test-markdown.md | 347 +++
_posts/2023-2-3-test-markdown.md | 91 +
_posts/2023-2-4-test-markdown.md | 276 +++
_posts/2023-3-27-test-markdown.md | 286 +++
_posts/2023-3-28-test-markdown.md | 335 +++
_posts/2023-4-10-test-markdown.md | 858 +++++++
_posts/2023-4-11-test-markdown.md | 198 ++
_posts/2023-4-13-test-markdown.md | 722 ++++++
_posts/2023-4-14-test-markdown.md | 83 +
_posts/2023-4-16-test-markdown.md | 782 ++++++
_posts/2023-4-17-test-markdown.md | 1251 ++++++++++
_posts/2023-4-19-test-markdown.md | 343 +++
_posts/2023-4-20-test-markdown.md | 1270 ++++++++++
_posts/2023-4-24-test-markdown.md | 566 +++++
_posts/2023-4-25-test-markdown.md | 459 ++++
_posts/2023-4-26-test-markdown.md | 160 ++
_posts/2023-4-27-test-markdown.md | 7 +
_posts/2023-4-29-test-markdown.md | 1047 ++++++++
_posts/2023-4-3-test-markdown.md | 534 ++++
_posts/2023-4-30-test-markdown.md | 35 +
_posts/2023-5-10-test-markdown.md | 1791 ++++++++++++++
_posts/2023-5-12-test-markdown.md | 1465 +++++++++++
_posts/2023-5-2-test-markdown.md | 146 ++
_posts/2023-5-21-test-markdown.md | 299 +++
_posts/2023-5-22-test-markdown.md | 219 ++
_posts/2023-5-23-test-markdown.md | 641 +++++
_posts/2023-5-24-test-markdown.md | 371 +++
_posts/2023-5-29-test-markdown.md | 555 +++++
_posts/2023-5-30-test-markdown.md | 154 ++
_posts/2023-5-7-test-markdown.md | 1006 ++++++++
_posts/2023-5-8-test-markdown.md | 2165 +++++++++++++++++
_posts/2023-6-1-test-markdown.md | 169 ++
_posts/2023-7-20-test-markdown.md | 117 +
_posts/2023-7-21-test-markdown.md | 10 +
_posts/2023-7-29-test-markdown.md | 347 +++
_posts/2023-8-29-test-markdown.md | 415 ++++
_posts/2023-8-30-test-markdown.md | 320 +++
_posts/2023-9-1-test-markdown.md | 333 +++
_posts/2023-9-10-test-markdown.md | 696 ++++++
_posts/2023-9-12-test-markdown.md | 433 ++++
_posts/2023-9-13-test-markdown.md | 2138 ++++++++++++++++
_posts/2023-9-2-test-markdown.md | 885 +++++++
_posts/2023-9-20-test-markdown.md | 48 +
_posts/2023-9-21-test-markdown.md | 250 ++
_posts/2023-9-22-test-markdown.md | 125 +
_posts/2023-9-23-test-markdown.md | 430 ++++
_posts/2023-9-24-test-markdown.md | 123 +
_posts/2023-9-25-test-markdown.md | 1071 ++++++++
_posts/2023-9-26-test-markdown.md | 125 +
_posts/2023-9-27-test-markdown.md | 61 +
_posts/2023-9-28-test-markdown.md | 478 ++++
_posts/2023-9-29-test-markdown.md | 542 +++++
_posts/2023-9-30-test-markdown.md | 404 +++
_posts/2023-9-5-test-markdown.md | 545 +++++
_posts/2023-9-7-test-markdown.md | 1454 +++++++++++
_posts/2023-9-8-test-markdown.md | 544 +++++
_posts/2023-9-9-test-markdown.md | 1422 +++++++++++
_posts/2024-03-29-test-markdown.md | 208 ++
_posts/2024-07-29-test-markdown.md | 100 +
_posts/2024-07-7-test-markdown.md | 55 +
_posts/2024-07-8-test-markdown.md | 152 ++
_posts/2024-07-9-test-markdown.md | 154 ++
_posts/2024-1-23-test-markdown.md | 75 +
_posts/2024-11-13-test-markdown.md | 1037 ++++++++
_posts/2024-11-14-test-markdown.md | 199 ++
_posts/2024-11-15-test-markdown.md | 186 ++
_posts/2024-11-16-test-markdown.md | 397 +++
_posts/2024-11-17-test-markdown.md | 144 ++
_posts/2024-11-18-test-markdown.md | 334 +++
_posts/2024-11-19-test-markdown.md | 26 +
_posts/2024-11-20-test-markdown.md | 1706 +++++++++++++
_posts/2024-11-21-test-markdown.md | 133 +
_posts/2024-11-22-test-markdown.md | 197 ++
_posts/2024-11-24-test-markdown.md | 43 +
_posts/2024-11-8-test-markdown.md | 763 ++++++
_posts/2024-3-12-test-markdown.md | 81 +
199 files changed, 78978 insertions(+), 106 deletions(-)
create mode 100644 _posts/2020-02-1-test-markdown.md
create mode 100644 _posts/2020-02-2-test-markdown.md
delete mode 100644 _posts/2020-02-28-sample-markdown.md
create mode 100644 _posts/2020-02-28-test-markdown.md
create mode 100644 _posts/2020-06-15-test-markdown.md
create mode 100644 _posts/2021-02-28-test-markdown.md
create mode 100644 _posts/2021-11-20-test-markdown.md
create mode 100644 _posts/2021-12-30-test-markdown.md
create mode 100644 _posts/2022-02-15-test-markdown.md
create mode 100644 _posts/2022-02-19-test-markdown.md
create mode 100644 _posts/2022-03-14-test-markdown.md
create mode 100644 _posts/2022-04-17-test-markdown.md
create mode 100644 _posts/2022-04-18-test-markdown.md
create mode 100644 _posts/2022-04-20-test-markdown.md
create mode 100644 _posts/2022-04-25-test-markdown.md
create mode 100644 _posts/2022-05-18-test-markdown.md
create mode 100644 _posts/2022-05-20-test-markdown.md
create mode 100644 _posts/2022-06-14-test-markdown.md
create mode 100644 _posts/2022-06-15-test-markdown.md
create mode 100644 _posts/2022-07-08-test-markdown.md
create mode 100644 _posts/2022-07-09test-markdown.md
create mode 100644 _posts/2022-07-11-test-markdown.md
create mode 100644 _posts/2022-07-12-test-markdown.md
create mode 100644 _posts/2022-07-13-test-markdown.md
create mode 100644 _posts/2022-07-14-test-markdown.md
create mode 100644 _posts/2022-07-15-test-markdown.md
create mode 100644 _posts/2022-07-16-test-markdown.md
create mode 100644 _posts/2022-07-17-test-markdown.md
create mode 100644 _posts/2022-07-18-test-markdown.md
create mode 100644 _posts/2022-07-20-test-markdown.md
create mode 100644 _posts/2022-07-21-test-markdown.md
create mode 100644 _posts/2022-07-22-test-markdown.md
create mode 100644 _posts/2022-08-19-test-markdown.md
create mode 100644 _posts/2022-08-20-test-markdown.md
create mode 100644 _posts/2022-08-21-test-markdown.md
create mode 100644 _posts/2022-08-27-test-markdown.md
create mode 100644 _posts/2022-08-28-test-markdown.md
create mode 100644 _posts/2022-09-01-test-markdown.md
create mode 100644 _posts/2022-09-02-test-markdown.md
create mode 100644 _posts/2022-09-04-test-markdown.md
create mode 100644 _posts/2022-09-05-test-markdown.md
create mode 100644 _posts/2022-09-06-test-markdown.md
create mode 100644 _posts/2022-10-02-test-markdown.md
create mode 100644 _posts/2022-10-03-test-markdown.md
create mode 100644 _posts/2022-10-04-test-markdown.md
create mode 100644 _posts/2022-10-05-test-markdown.md
create mode 100644 _posts/2022-10-06-test-markdown.md
create mode 100644 _posts/2022-10-07-test-markdown.md
create mode 100644 _posts/2022-10-09-test-markdown.md
create mode 100644 _posts/2022-10-10-test-markdown.md
create mode 100644 _posts/2022-10-11-test-markdown.md
create mode 100644 _posts/2022-10-12-test-markdown.md
create mode 100644 _posts/2022-10-13-test-markdown.md
create mode 100644 _posts/2022-10-14-test-markdown.md
create mode 100644 _posts/2022-10-15-test-markdown.md
create mode 100644 _posts/2022-10-21-test-markdown.md
create mode 100644 _posts/2022-10-22-test-markdown.md
create mode 100644 _posts/2022-10-23-test-markdown.md
create mode 100644 _posts/2022-10-24-test-markdown.md
create mode 100644 _posts/2022-11-01-test-markdown.md
create mode 100644 _posts/2022-11-02-test-markdown.md
create mode 100644 _posts/2022-11-03-test-markdown.md
create mode 100644 _posts/2022-11-09-test-markdown.md
create mode 100644 _posts/2022-11-11-test-markdown.md
create mode 100644 _posts/2022-11-12-test-markdown.md
create mode 100644 _posts/2022-11-19-test-markdown.md
create mode 100644 _posts/2022-11-20-test-markdown.md
create mode 100644 _posts/2022-11-21-test-markdown.md
create mode 100644 _posts/2022-11-22-test-markdown.md
create mode 100644 _posts/2022-11-23-test-markdown.md
create mode 100644 _posts/2022-11-24-test-markdown.md
create mode 100644 _posts/2022-11-25-test-markdown.md
create mode 100644 _posts/2022-11-26-test-markdown.md
create mode 100644 _posts/2022-12-29-test-markdown.md
create mode 100644 _posts/2022-12-31-test-markdown.md
create mode 100644 _posts/2022-12-5-test-markdown.md
create mode 100644 _posts/2022-12-6-test-markdown.md
create mode 100644 _posts/2023-1-1-test-markdown.md
create mode 100644 _posts/2023-1-10-test-markdown.md
create mode 100644 _posts/2023-1-16-test-markdown.md
create mode 100644 _posts/2023-1-17-test-markdown.md
create mode 100644 _posts/2023-1-18-test-markdown.md
create mode 100644 _posts/2023-1-19-test-markdown.md
create mode 100644 _posts/2023-1-20-test-markdown.md
create mode 100644 _posts/2023-1-21-test-markdown.md
create mode 100644 _posts/2023-1-22-test-markdown.md
create mode 100644 _posts/2023-1-29-test-markdown.md
create mode 100644 _posts/2023-1-3-test-markdown.md
create mode 100644 _posts/2023-1-30-test-markdown.md
create mode 100644 _posts/2023-1-31-test-markdown.md
create mode 100644 _posts/2023-1-9-test-markdown.md
create mode 100644 _posts/2023-10-1-test-markdown.md
create mode 100644 _posts/2023-10-10-test-markdown.md
create mode 100644 _posts/2023-10-11-test-markdown.md
create mode 100644 _posts/2023-10-12-test-markdown.md
create mode 100644 _posts/2023-10-13-test-markdown.md
create mode 100644 _posts/2023-10-14-test-markdown.md
create mode 100644 _posts/2023-10-15-test-markdown.md
create mode 100644 _posts/2023-10-16-test-markdown.md
create mode 100644 _posts/2023-10-17-test-markdown.md
create mode 100644 _posts/2023-10-18-test-markdown.md
create mode 100644 _posts/2023-10-19-test-markdown.md
create mode 100644 _posts/2023-10-2-test-markdown.md
create mode 100644 _posts/2023-10-22-test-markdown.md
create mode 100644 _posts/2023-10-23-test-markdown.md
create mode 100644 _posts/2023-10-3-test-markdown.md
create mode 100644 _posts/2023-10-4-test-markdown.md
create mode 100644 _posts/2023-10-5-test-markdown.md
create mode 100644 _posts/2023-10-6-test-markdown.md
create mode 100644 _posts/2023-10-7-test-markdown.md
create mode 100644 _posts/2023-10-8-test-markdown.md
create mode 100644 _posts/2023-10-9-test-markdown.md
create mode 100644 _posts/2023-11-10-test-markdown.md
create mode 100644 _posts/2023-11-11-test-markdown.md
create mode 100644 _posts/2023-11-12-test-markdown.md
create mode 100644 _posts/2023-11-5-test-markdown.md
create mode 100644 _posts/2023-11-6-test-markdown.md
create mode 100644 _posts/2023-11-7-test-markdown.md
create mode 100644 _posts/2023-11-9-test-markdown.md
create mode 100644 _posts/2023-2-1-test-markdown.md
create mode 100644 _posts/2023-2-10-test-markdown.md
create mode 100644 _posts/2023-2-2-test-markdown.md
create mode 100644 _posts/2023-2-20-test-markdown.md
create mode 100644 _posts/2023-2-3-test-markdown.md
create mode 100644 _posts/2023-2-4-test-markdown.md
create mode 100644 _posts/2023-3-27-test-markdown.md
create mode 100644 _posts/2023-3-28-test-markdown.md
create mode 100644 _posts/2023-4-10-test-markdown.md
create mode 100644 _posts/2023-4-11-test-markdown.md
create mode 100644 _posts/2023-4-13-test-markdown.md
create mode 100644 _posts/2023-4-14-test-markdown.md
create mode 100644 _posts/2023-4-16-test-markdown.md
create mode 100644 _posts/2023-4-17-test-markdown.md
create mode 100644 _posts/2023-4-19-test-markdown.md
create mode 100644 _posts/2023-4-20-test-markdown.md
create mode 100644 _posts/2023-4-24-test-markdown.md
create mode 100644 _posts/2023-4-25-test-markdown.md
create mode 100644 _posts/2023-4-26-test-markdown.md
create mode 100644 _posts/2023-4-27-test-markdown.md
create mode 100644 _posts/2023-4-29-test-markdown.md
create mode 100644 _posts/2023-4-3-test-markdown.md
create mode 100644 _posts/2023-4-30-test-markdown.md
create mode 100644 _posts/2023-5-10-test-markdown.md
create mode 100644 _posts/2023-5-12-test-markdown.md
create mode 100644 _posts/2023-5-2-test-markdown.md
create mode 100644 _posts/2023-5-21-test-markdown.md
create mode 100644 _posts/2023-5-22-test-markdown.md
create mode 100644 _posts/2023-5-23-test-markdown.md
create mode 100644 _posts/2023-5-24-test-markdown.md
create mode 100644 _posts/2023-5-29-test-markdown.md
create mode 100644 _posts/2023-5-30-test-markdown.md
create mode 100644 _posts/2023-5-7-test-markdown.md
create mode 100644 _posts/2023-5-8-test-markdown.md
create mode 100644 _posts/2023-6-1-test-markdown.md
create mode 100644 _posts/2023-7-20-test-markdown.md
create mode 100644 _posts/2023-7-21-test-markdown.md
create mode 100644 _posts/2023-7-29-test-markdown.md
create mode 100644 _posts/2023-8-29-test-markdown.md
create mode 100644 _posts/2023-8-30-test-markdown.md
create mode 100644 _posts/2023-9-1-test-markdown.md
create mode 100644 _posts/2023-9-10-test-markdown.md
create mode 100644 _posts/2023-9-12-test-markdown.md
create mode 100644 _posts/2023-9-13-test-markdown.md
create mode 100644 _posts/2023-9-2-test-markdown.md
create mode 100644 _posts/2023-9-20-test-markdown.md
create mode 100644 _posts/2023-9-21-test-markdown.md
create mode 100644 _posts/2023-9-22-test-markdown.md
create mode 100644 _posts/2023-9-23-test-markdown.md
create mode 100644 _posts/2023-9-24-test-markdown.md
create mode 100644 _posts/2023-9-25-test-markdown.md
create mode 100644 _posts/2023-9-26-test-markdown.md
create mode 100644 _posts/2023-9-27-test-markdown.md
create mode 100644 _posts/2023-9-28-test-markdown.md
create mode 100644 _posts/2023-9-29-test-markdown.md
create mode 100644 _posts/2023-9-30-test-markdown.md
create mode 100644 _posts/2023-9-5-test-markdown.md
create mode 100644 _posts/2023-9-7-test-markdown.md
create mode 100644 _posts/2023-9-8-test-markdown.md
create mode 100644 _posts/2023-9-9-test-markdown.md
create mode 100644 _posts/2024-03-29-test-markdown.md
create mode 100644 _posts/2024-07-29-test-markdown.md
create mode 100644 _posts/2024-07-7-test-markdown.md
create mode 100644 _posts/2024-07-8-test-markdown.md
create mode 100644 _posts/2024-07-9-test-markdown.md
create mode 100644 _posts/2024-1-23-test-markdown.md
create mode 100644 _posts/2024-11-13-test-markdown.md
create mode 100644 _posts/2024-11-14-test-markdown.md
create mode 100644 _posts/2024-11-15-test-markdown.md
create mode 100644 _posts/2024-11-16-test-markdown.md
create mode 100644 _posts/2024-11-17-test-markdown.md
create mode 100644 _posts/2024-11-18-test-markdown.md
create mode 100644 _posts/2024-11-19-test-markdown.md
create mode 100644 _posts/2024-11-20-test-markdown.md
create mode 100644 _posts/2024-11-21-test-markdown.md
create mode 100644 _posts/2024-11-22-test-markdown.md
create mode 100644 _posts/2024-11-24-test-markdown.md
create mode 100644 _posts/2024-11-8-test-markdown.md
create mode 100644 _posts/2024-3-12-test-markdown.md
diff --git a/_posts/2020-02-1-test-markdown.md b/_posts/2020-02-1-test-markdown.md
new file mode 100644
index 000000000000..7541657f323a
--- /dev/null
+++ b/_posts/2020-02-1-test-markdown.md
@@ -0,0 +1,76 @@
+---
+layout: post
+title: HomeBrew卸载和安装
+subtitle:
+tags: [brew]
+comments: true
+---
+
+## HomeBrew卸载
+```shell
+/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/HomebrewUninstall.sh)"
+```
+
+## HomeBrew安装
+
+```shell
+/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
+```
+
+## 设置环境变量
+
+为了将 node@18 加入到 PATH 环境变量中,使其成为优先选择的版本,可以运行以下命令:
+```shell
+echo 'export PATH="/opt/homebrew/opt/node@18/bin:$PATH"' >> ~/.zshrc
+```
+此命令将 export PATH=... 添加到的 ~/.zshrc 文件中,以确保 node@18 的二进制文件在的路径中优先被找到。
+
+另外,为了让编译器能找到 node@18,可能需要设置以下环境变量:
+
+
+```shell
+export LDFLAGS="-L/opt/homebrew/opt/node@18/lib"
+export CPPFLAGS="-I/opt/homebrew/opt/node@18/include"
+```
+
+这些环境变量指定了编译器在编译过程中需要搜索的库文件和头文件路径。设置这些变量可以确保在编译需要使用到 node@18 的程序时,编译器能够正确地找到所需的文件。
+
+
+## 更换Homebrew的镜像源
+可以通过以下步骤来更换Homebrew的镜像源:
+1. **更换Homebrew的formula源**:
+
+```shell
+# 切换到Homebrew的目录
+cd "$(brew --repo)"
+# 更换源
+git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git
+```
+
+1. **更换Homebrew的bottle源**:
+
+在的shell配置文件(比如`~/.bash_profile`或者`~/.zshrc`)中添加以下行:
+
+```shell
+export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles
+```
+
+然后运行`source ~/.bash_profile`或者`source ~/.zshrc`来使更改生效。
+
+1. **更换Homebrew的核心formula源**:
+
+```shell
+# 切换到Homebrew的目录
+cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core"
+
+# 更换源
+git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git
+```
+
+以上步骤将Homebrew的源更换为了清华大学的镜像站点,可以根据需要更换为其他的镜像站点。
+
+注意:如果在更换源之后遇到了问题,可以通过运行以上命令并将URL更换为官方源的URL来恢复到官方源。官方源的URL分别为:
+
+- Homebrew:https://github.com/Homebrew/brew.git
+- Homebrew Bottles:https://homebrew.bintray.com/bottles
+- Homebrew Core:https://github.com/Homebrew/homebrew-core.git
\ No newline at end of file
diff --git a/_posts/2020-02-2-test-markdown.md b/_posts/2020-02-2-test-markdown.md
new file mode 100644
index 000000000000..1c9b972a8bf1
--- /dev/null
+++ b/_posts/2020-02-2-test-markdown.md
@@ -0,0 +1,66 @@
+---
+layout: post
+title: HomeBrew安装ETCD
+subtitle:
+tags: [etcd]
+comments: true
+---
+
+## 使用 brew 安装
+
+第一步: 确定 brew 是否有 etcd 包:
+```shell
+brew search etcd
+```
+避免盲目使用 brew install balabala
+
+第二步: 安装
+```shell
+brew install etcd
+```
+
+第三步:运行
+推荐使用 brew services 来管理这些应用。
+
+```shell
+brew list
+```
+```shell
+brew services list
+```
+```shell
+brew services list
+Name Status User Plist
+etcd started bigbug/Library/LaunchAgents/homebrew.mxcl.etcd.plist
+privoxy started bigbug/Library/LaunchAgents/homebrew.mxcl.privoxy.plist
+redis stopped
+可以看到,我本机的 etcd 已经是启动的状态,所以我可以直接使用。
+```
+
+brew services 常用的操作
+
+### 启动某个应用,这里用 etcd 做演示
+```shell
+brew services start etcd
+```
+
+### 停止某个应用
+```shell
+brew services stop etcd
+```
+
+### 查看当前应用列表
+```shell
+brew services list
+```
+好了, etcd 已经启动了,现在验证下,是否正确的启动:
+### 验证
+```shell
+etcdctl endpoint health
+```
+正常情况会输出:
+
+```shell
+127.0.0.1:2379 is healthy: successfully committed proposal: took = 2.258149ms
+```
+至此,etcd 已经安装完毕。
\ No newline at end of file
diff --git a/_posts/2020-02-26-flake-it-till-you-make-it.md b/_posts/2020-02-26-flake-it-till-you-make-it.md
index 768f6328da09..f652cf138988 100644
--- a/_posts/2020-02-26-flake-it-till-you-make-it.md
+++ b/_posts/2020-02-26-flake-it-till-you-make-it.md
@@ -1,18 +1,157 @@
---
layout: post
-title: Flake it till you make it
-subtitle: Excerpt from Soulshaping by Jeff Brown
-cover-img: /assets/img/path.jpg
-thumbnail-img: /assets/img/thumb.png
-share-img: /assets/img/path.jpg
-tags: [books, test]
-author: Sharon Smith and Barry Simpson
+title: 中介者模式
+subtitle: 调解人、控制器、Intermediary、Controller、Mediator
+tags: [设计模式]
---
-Under what circumstances should we step off a path? When is it essential that we finish what we start? If I bought a bag of peanuts and had an allergic reaction, no one would fault me if I threw it out. If I ended a relationship with a woman who hit me, no one would say that I had a commitment problem. But if I walk away from a seemingly secure route because my soul has other ideas, I am a flake?
+# 中介者模式
-The truth is that no one else can definitively know the path we are here to walk. It’s tempting to listen—many of us long for the omnipotent other—but unless they are genuine psychic intuitives, they can’t know. All others can know is their own truth, and if they’ve actually done the work to excavate it, they will have the good sense to know that they cannot genuinely know anyone else’s. Only soul knows the path it is here to walk. Since you are the only one living in your temple, only you can know its scriptures and interpretive structure.
+> **亦称:** 调解人、控制器、Intermediary、Controller、Mediator
-At the heart of the struggle are two very different ideas of success—survival-driven and soul-driven. For survivalists, success is security, pragmatism, power over others. Success is the absence of material suffering, the nourishing of the soul be damned. It is an odd and ironic thing that most of the material power in our world often resides in the hands of younger souls. Still working in the egoic and material realms, they love the sensations of power and focus most of their energy on accumulation. Older souls tend not to be as materially driven. They have already played the worldly game in previous lives and they search for more subtle shades of meaning in this one—authentication rather than accumulation. They are often ignored by the culture at large, although they really are the truest warriors.
+
-A soulful notion of success rests on the actualization of our innate image. Success is simply the completion of a soul step, however unsightly it may be. We have finished what we started when the lesson is learned. What a fear-based culture calls a wonderful opportunity may be fruitless and misguided for the soul. Staying in a passionless relationship may satisfy our need for comfort, but it may stifle the soul. Becoming a famous lawyer is only worthwhile if the soul demands it. It is an essential failure if you are called to be a monastic this time around. If you need to explore and abandon ten careers in order to stretch your soul toward its innate image, then so be it. Flake it till you make it.
\ No newline at end of file
+## 1.概念
+
+**中介者模式**是一种行为设计模式, 能让减少对象之间混乱无序的依赖关系。 该模式会限制对象之间的直接交互, 迫使它们通过一个中介者对象进行合作。
+
+假如有一个创建和修改客户资料的对话框, 它由各种控件组成, 例如文本框 (TextField)、 复选框 (Checkbox) 和按钮 (Button) 等。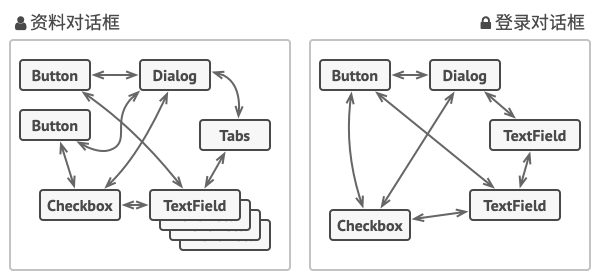
+
+
+- 元素间存在许多关联。 因此, 对某些元素进行修改可能会影响其他元素。
+
+- 如果直接在表单元素代码中实现业务逻辑, 将很难在程序其他表单中复用这些元素类。
+
+
+## 2.问题
+
+#### 1.元素可能会直接进行互动。
+
+提交按钮必须在保存数据前校验所有输入内容。
+
+#### 2.元素间存在许多关联
+
+对某些元素进行修改可能会影响其他元素
+
+#### 3.在元素代码中实现业务逻辑将很难复用其他的元素类
+
+
+## 3.解决方法
+
+> 中介者模式建议停止组件之间的直接交流并使其相互独立。 这些组件必须调用特殊的中介者对象, 通过中介者对象重定向调用行为, 以间接的方式进行合作。 最终, 组件仅依赖于一个中介者类, 无需与多个其他组件相耦合。
+
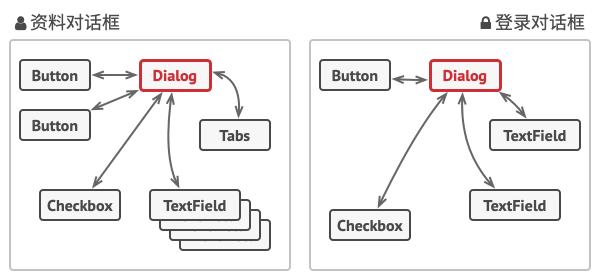
+在资料编辑表单的例子中, 对话框 (Dialog) 类本身将作为中介者, 其很可能已知自己所有的子元素, 因此甚至无需在该类中引入新的依赖关系。
+
+
+
+绝大部分重要的修改都在实际表单元素中进行。 想想提交按钮。 之前, 当用户点击按钮后, 它必须对所有表单元素数值进行校验。 而现在它的唯一工作是将点击事件通知给对话框。 收到通知后, 对话框可以自行校验数值或将任务委派给各元素。 这样一来, 按钮不再与多个表单元素相关联, 而仅依赖于对话框类。
+
+## 4.类比
+
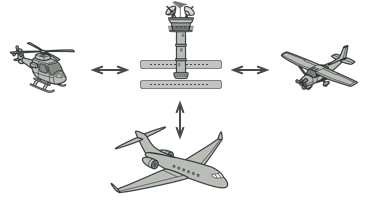
+
+
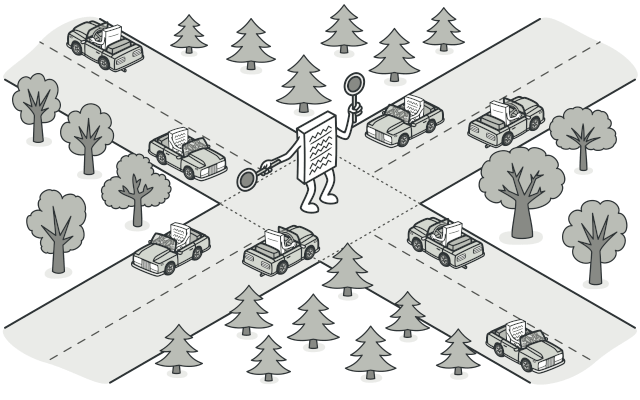
+> 飞行器驾驶员之间不会通过相互沟通来决定下一架降落的飞机。 所有沟通都通过控制塔台进行。飞行器驾驶员们在靠近或离开空中管制区域时不会直接相互交流。 但他们会与飞机跑道附近, 塔台中的空管员通话。 如果没有空管员, 驾驶员就需要留意机场附近的所有飞机, 并与数十位飞行员组成的委员会讨论降落顺序。 那恐怕会让飞机坠毁的统计数据一飞冲天吧。
+
+- 塔台无需管制飞行全程, 只需在航站区加强管控即可, 因为该区域的决策**参与者数量**对于飞行员来说实在**太多**了。
+
+## 5.中介者模式结构
+
+
+
+1. **组件** (Component) 是各种包含业务逻辑的类。 每个组件都有一个指向中介者的引用, 该引用被声明为中介者接口类型。 组件不知道中介者实际所属的类, 因此可通过将其连接到不同的中介者以使其能在其他程序中复用。
+2. **中介者** (Mediator) 接口声明了与组件交流的方法, 但通常仅包括一个通知方法。 组件可将任意上下文 (包括自己的对象) 作为该方法的参数, 只有这样接收组件和发送者类之间才不会耦合。
+3. **具体中介者** (Concrete Mediator) 封装了多种组件间的关系。 具体中介者通常会保存所有组件的引用并对其进行管理, 甚至有时会对其生命周期进行管理。
+4. 组件并不知道其他组件的情况。 如果组件内发生了重要事件, 它只能通知中介者。 中介者收到通知后能轻易地确定发送者, 这或许已足以判断接下来需要触发的组件了。
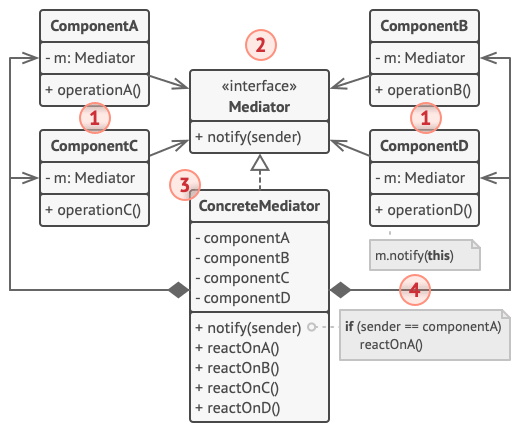
+5. 对于组件来说, **中介者看上去完全就是一个黑箱。 发送者不知道最终会由谁来处理自己的请求, 接收者也不知道最初是谁发出了请求**。
+
+## 6.伪代码
+
+**中介者**模式可帮助减少各种 UI 类 (按钮、 复选框和文本标签) 之间的相互依赖关系。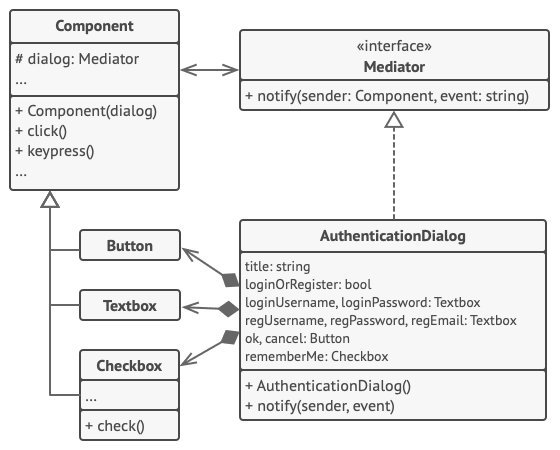
+
+用户触发的元素不会直接与其他元素交流, 即使看上去它们应该这样做。 相反, 元素只需让中介者知晓事件即可, 并能在发出通知时同时传递任何上下文信息。
+
+本例中的中介者是整个认证对话框。 对话框知道具体元素应如何进行合作并促进它们的间接交流。 当接收到事件通知后, 对话框会确定负责处理事件的元素并据此重定向请求。
+
+```
+// 中介者接口声明了一个能让组件将各种事件通知给中介者的方法。中介者可对这些事件做出响应并将执行工作传递给其他组件。
+interface Mediator is
+ method notify(sender: Component, event: string)
+
+// 具体中介者类要解开各组件之间相互交叉的连接关系并将其转移到中介者中。
+class AuthenticationDialog implements Mediator is
+ private field title: string
+ private field loginOrRegisterChkBx: Checkbox
+ private field loginUsername, loginPassword: Textbox
+ private field registrationUsername, registrationPassword,
+ registrationEmail: Textbox
+ private field okBtn, cancelBtn: Button
+ constructor AuthenticationDialog() is
+ // 创建所有组件对象并将当前中介者传递给其构造函数以建立连接。
+ // 当组件中有事件发生时,它会通知中介者。中介者接收到通知后可自行处理也可将请求传递给另一个组件。
+ method notify(sender, event) is
+ if (sender == loginOrRegisterChkBx and event == "check")
+ if (loginOrRegisterChkBx.checked)
+ title = "登录"
+ // 1. 显示登录表单组件。
+ // 2. 隐藏注册表单组件。
+ else
+ title = "注册"
+ // 1. 显示注册表单组件。
+ // 2. 隐藏登录表单组件。
+
+ if (sender == okBtn && event == "click")
+ if (loginOrRegister.checked)
+ // 尝试找到使用登录信息的用户。
+ if (!found)
+ // 在登录字段上方显示错误信息。
+ else
+ // 1. 使用注册字段中的数据创建用户账号。
+ // 2. 完成用户登录工作。 …
+
+ class Component is
+ field dialog: Mediator
+ constructor Component(dialog) is
+ this.dialog = dialog
+ method click() is
+ dialog.notify(this, "click")
+ method keypress() is
+ dialog.notify(this, "keypress")
+
+ // 具体组件之间无法进行交流。它们只有一个交流渠道,那就是向中介者发送通知。
+class Button extends Component is
+ // ...
+
+class Textbox extends Component is
+ // ...
+
+class Checkbox extends Component is
+ method check() is
+ dialog.notify(this, "check")
+ // ...
+
+
+```
+
+- 当一些对象和其他对象紧密耦合以致难以对其进行修改时, 可使用中介者模式。
+
+ 该模式让将对象间的所有关系抽取成为一个单独的类, 以使对于特定组件的修改工作独立于其他组件。
+
+- 当组件因过于依赖其他组件而无法在不同应用中复用时,可使用中介者模式
+
+ 应用中介者模式后, 每个组件不再知晓其他组件的情况。 尽管这些组件无法直接交流, 但它们仍可通过中介者对象进行间接交流。 如果希望在不同应用中复用一个组件, 则需要为其提供一个新的中介者类。
+
+- 如果为了能在不同情景下复用一些基本行为,导致需要被迫创建大量组件子类时,可使用中介者模式。
+
+- 由于所有组件间关系都被包含在中介者中, 因此无需修改组件就能方便地新建中介者类以定义新的组件合作方式。
+
+## 7.实现
+
+1. 找到一组当前紧密耦合, 且提供其独立性能带来更大好处的类 (例如更易于维护或更方便复用)。
+2. 声明中介者接口并描述中介者和各种组件之间所需的交流接口。 在绝大多数情况下, 一个接收组件通知的方法就足够了。
+3. 如果希望在不同情景下复用组件类, 那么该接口将非常重要。 只要组件使用通用接口与其中介者合作, 就能将该组件与不同实现中的中介者进行连接。
+4. 实现具体中介者类。 该类可从自行保存其下所有组件的引用中受益。
+5. 可以更进一步, 让中介者负责组件对象的创建和销毁。 此后, 中介者可能会与工厂或外观模式类似。
+6. 组件必须保存对于中介者对象的引用。 该连接通常在组件的构造函数中建立, 该函数会将中介者对象作为参数传递。
+7. 修改组件代码, 使其可调用中介者的通知方法, 而非**其他组件**的方法。 然后将调用其他组件的代码抽取到中介者类中, 并在**中介者**接收到该组件通知时**执行**这些**代码**。(中介者执行调用其他组件代码的逻辑)
+
+.
\ No newline at end of file
diff --git a/_posts/2020-02-28-sample-markdown.md b/_posts/2020-02-28-sample-markdown.md
deleted file mode 100644
index 6a59d6a14aac..000000000000
--- a/_posts/2020-02-28-sample-markdown.md
+++ /dev/null
@@ -1,95 +0,0 @@
----
-layout: post
-title: Sample blog post to learn markdown tips
-subtitle: There's lots to learn!
-gh-repo: daattali/beautiful-jekyll
-gh-badge: [star, fork, follow]
-tags: [test]
-comments: true
-mathjax: true
-author: Bill Smith
----
-
-{: .box-success}
-This is a demo post to show you how to write blog posts with markdown. I strongly encourage you to [take 5 minutes to learn how to write in markdown](https://markdowntutorial.com/) - it'll teach you how to transform regular text into bold/italics/tables/etc.
I also encourage you to look at the [code that created this post](https://raw.githubusercontent.com/daattali/beautiful-jekyll/master/_posts/2020-02-28-sample-markdown.md) to learn some more advanced tips about using markdown in Beautiful Jekyll.
-
-**Here is some bold text**
-
-## Here is a secondary heading
-
-[This is a link to a different site](https://deanattali.com/) and [this is a link to a section inside this page](#local-urls).
-
-Here's a table:
-
-| Number | Next number | Previous number |
-| :------ |:--- | :--- |
-| Five | Six | Four |
-| Ten | Eleven | Nine |
-| Seven | Eight | Six |
-| Two | Three | One |
-
-You can use [MathJax](https://www.mathjax.org/) to write LaTeX expressions. For example:
-When \\(a \ne 0\\), there are two solutions to \\(ax^2 + bx + c = 0\\) and they are $$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$
-
-How about a yummy crepe?
-
-
-
-It can also be centered!
-
-{: .mx-auto.d-block :}
-
-Here's a code chunk:
-
-~~~
-var foo = function(x) {
- return(x + 5);
-}
-foo(3)
-~~~
-
-And here is the same code with syntax highlighting:
-
-```javascript
-var foo = function(x) {
- return(x + 5);
-}
-foo(3)
-```
-
-And here is the same code yet again but with line numbers:
-
-{% highlight javascript linenos %}
-var foo = function(x) {
- return(x + 5);
-}
-foo(3)
-{% endhighlight %}
-
-## Boxes
-You can add notification, warning and error boxes like this:
-
-### Notification
-
-{: .box-note}
-**Note:** This is a notification box.
-
-### Warning
-
-{: .box-warning}
-**Warning:** This is a warning box.
-
-### Error
-
-{: .box-error}
-**Error:** This is an error box.
-
-## Local URLs in project sites {#local-urls}
-
-When hosting a *project site* on GitHub Pages (for example, `https://USERNAME.github.io/MyProject`), URLs that begin with `/` and refer to local files may not work correctly due to how the root URL (`/`) is interpreted by GitHub Pages. You can read more about it [in the FAQ](https://beautifuljekyll.com/faq/#links-in-project-page). To demonstrate the issue, the following local image will be broken **if your site is a project site:**
-
-
-
-If the above image is broken, then you'll need to follow the instructions [in the FAQ](https://beautifuljekyll.com/faq/#links-in-project-page). Here is proof that it can be fixed:
-
-
diff --git a/_posts/2020-02-28-test-markdown.md b/_posts/2020-02-28-test-markdown.md
new file mode 100644
index 000000000000..0eaaaec97a6f
--- /dev/null
+++ b/_posts/2020-02-28-test-markdown.md
@@ -0,0 +1,185 @@
+---
+layout: post
+title: Go中单例模式的安全性
+subtitle: golang
+tags: [设计模式]
+comments: true
+---
+
+# 浅谈Go中单例模式的安全性
+
+## 1.常见错误
+
+不考虑线程安全的单例实现
+
+```go
+package singleton
+
+type singleton struct {
+}
+
+var instance *singleton
+
+func GetInstance() *singleton {
+ if instance == nil {
+ instance = &singleton{} // <--- NOT THREAD SAFE
+ }
+ return instance
+}
+```
+
+在上述场景中,多个 go 例程可以评估第一次检查,它们都将创建该`singleton`类型的实例并相互覆盖。无法保证这里会返回哪个实例,这不好的原因是,如果通过代码保留对单例实例的引用,则可能存在具有不同状态的类型的多个实例,从而产生潜在的不同代码行为。在调试时,由于运行时暂停,没有什么真正出现错误,最大限度地减少了非线程安全执行的可能性,很容易隐藏开发的问题。
+
+## 2.Aggressive Locking
+
+### 激进的锁定
+
+```go
+var mu Sync.Mutex
+
+func GetInstance() *singleton {
+ mu.Lock() // <--- Unnecessary locking if instance already created
+ defer mu.Unlock()
+
+ if instance == nil {
+ instance = &singleton{}
+ }
+ return instance
+}
+```
+
+实际上,这解决了线程安全问题,但会产生其他潜在的严重问题。我们通过`Sync.Mutex`在创建单例实例之前引入并获取锁来解决线程安全问题。问题是在这里我们执行了过多的锁定,即使我们不需要这样做,**如果实例已经创建并且我们应该简单地返回缓存的单例实例。** 高度并发的代码库上,这可能会产生瓶颈,因为一次只有一个 go 例程可以获取单例实例。
+
+- **当某个函数,执行的功能,第一次创建一个单例,之后要做的仅仅是返回这个单例时,如果为单例的第一次创建加了锁,这么做是为了保证,第一次全局我们只能获取到一个单例,但是,之后的每一次调用,我们的函数要做的仅仅是返回这个单例,而加锁,导致的后果是每次只有一个进程可以获取到已经存在的单例,如果这种获取是百万并发级别的,那么后果是不堪设想的。**
+
+## 3.Check-Lock-Check Pattern
+
+```go
+if check() {
+ lock() {
+ if check() {
+ // perform your lock-safe code here
+ }
+ }
+}
+```
+
+在 C++ 和其他语言中,确保最小锁定并且仍然是线程安全的最好和最安全的方法是在获取锁时使用称为 Check-Lock-Check 的众所周知的模式。这种模式背后的想法是,需要先进行检查,以尽量减少任何**激进的锁定**,(开销非常大的锁定)因为 **IF 语句比锁定更便宜**。其次,我们希望等待并获取排他锁,因此一次只有一个执行在该块内。但是在第一次检查和获得排他锁之前,可能有另一个线程确实获得了锁,因此我们需要再次检查锁内部以避免用另一个实例替换实例。
+
+如果我们将这种模式应用到我们的`GetInstance()`方法中,我们将得到如下内容:
+
+```
+func GetInstance() *singleton {
+ if instance == nil { // <-- Not yet perfect. since it's not fully atomic
+ mu.Lock()
+ defer mu.Unlock()
+
+ if instance == nil {
+ instance = &singleton{}
+ }
+ }
+ return instance
+}
+```
+
+这是一种更好的方法,但仍然**不**完美。由于由于编译器优化,没有对实例存储状态进行原子检查。考虑到所有的技术因素,这仍然不是完美的。但它比最初的方法要好得多。但是使用该`sync/atomic`包,我们可以自动加载并设置一个标志,该标志将指示我们是否已初始化我们的实例。
+
+```
+import "sync"
+import "sync/atomic"
+
+var initialized uint32
+...
+
+func GetInstance() *singleton {
+
+ if atomic.LoadUInt32(&initialized) == 1 {
+ return instance
+ }
+
+ mu.Lock()
+ defer mu.Unlock()
+
+ if initialized == 0 {
+ instance = &singleton{}
+ atomic.StoreUint32(&initialized, 1)
+ }
+
+ return instance
+}
+```
+
+## 4.Go 中惯用的单例方法
+
+```
+// Once is an object that will perform exactly one action.
+type Once struct {
+ m Mutex
+ done uint32
+}
+
+// Do calls the function f if and only if Do is being called for the
+// first time for this instance of Once. In other words, given
+// var once Once
+// if once.Do(f) is called multiple times, only the first call will invoke f,
+// even if f has a different value in each invocation. A new instance of
+// Once is required for each function to execute.
+//
+// Do is intended for initialization that must be run exactly once. Since f
+// is niladic, it may be necessary to use a function literal to capture the
+// arguments to a function to be invoked by Do:
+// config.once.Do(func() { config.init(filename) })
+//
+// Because no call to Do returns until the one call to f returns, if f causes
+// Do to be called, it will deadlock.
+//
+// If f panics, Do considers it to have returned; future calls of Do return
+// without calling f.
+//
+func (o *Once) Do(f func()) {
+ if atomic.LoadUint32(&o.done) == 1 { // <-- Check
+ return
+ }
+ // Slow-path.
+ o.m.Lock() // <-- Lock
+ defer o.m.Unlock()
+ if o.done == 0 { // <-- Check
+ defer atomic.StoreUint32(&o.done, 1)
+ f()
+ }
+}
+```
+
+这意味着我们可以利用很棒的 Go 同步包只调用一次方法。因此,我们可以这样调用该`once.Do()`方法:
+
+```
+once.Do(func() {
+ // perform safe initialization here
+})
+//利用sync.Once类型来同步对 的访问,GetInstance()并确保我们的类型只被初始化一次。
+```
+
+```
+package singleton
+
+import (
+ "sync"
+)
+
+type singleton struct {
+}
+
+var instance *singleton
+var once sync.Once
+
+func GetInstance() *singleton {
+ once.Do(func() {
+ instance = &singleton{}
+ })
+ return instance
+}
+```
+
+因此,使用`sync.Once`包是安全实现这一点的首选方式,类似于 Objective-C 和 Swift (Cocoa) 实现`dispatch_once`方法来执行类似的初始化。
+
+
diff --git a/_posts/2020-06-15-test-markdown.md b/_posts/2020-06-15-test-markdown.md
new file mode 100644
index 000000000000..5dfcd7a43e72
--- /dev/null
+++ b/_posts/2020-06-15-test-markdown.md
@@ -0,0 +1,67 @@
+---
+layout: post
+title: Go值拷贝的理解
+subtitle: In a function call, the function value and arguments are evaluated in the usual order. After they are evaluated, the parameters of the call are passed by value to the function and the called function begins execution.
+tags: [golang]
+---
+# Go值拷贝的理解
+
+> In a function call, the function value and arguments are evaluated in the usual order. After they are evaluated, the parameters of the call are passed by value to the function and the called function begins execution.
+
+官方文档已经明确说明:Go里边函数传参只有值传递一种方式: 值传递
+那么为什么还会有有关Go的值拷贝的思考?
+
+```
+package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ arr := [5]int{0, 1, 2, 3, 4}
+ s := arr[1:]
+ changeSlice(s)
+ fmt.Println(s)
+ fmt.Println(arr)
+}
+
+func changeSlice(arr []int) {
+ for i := range arr {
+ arr[i] = 10
+ }
+}
+
+
+Output:
+[10 10 10 10]
+[0 10 10 10 10]
+```
+
+如果Go是值拷贝的,那么我修改了函数 `changeSlice` 里面的`slice s` 的值,为什么main函数里面的`slice`和 `array`也被修改了
+
+以上图为例,a 是初始变量,b 是引用变量(Go中并不存在),p 是指针变量,
+
+在这里变量a被拷贝后,地址发生了变化,地址上存储的是原先地址存储的值 10 变量p被拷贝后,地址发生了变化,地址上存储的还是原先地址存储的值 )0X001, 然后按照这个地址去查找,找到的是 0X001 上面存储的值
+
+所以,当去修改拷贝后的*p的值,其实修改的还是0X001地址上的值,而不是 拷贝后a的值
+
+> 怎么理解呢?就是对于切片的底层数据而言,其中三个 要素。类型,容量,指针,指针是用来干嘛的,就是指向数组啊,所以说,不论怎么拷贝切片,切片的指针都是指向原来的数组,当修改切片的值时,其实是在修改数组的值!!!!
+
+**slice在实现的时候,其实是对array的映射,也就是说slice存对应的是原array的地址,就类似于p与a的关系,那么整个slice拷贝后,拷贝后的slice中存储的还是array的地址,去修改拷贝后的slice,其实跟修改slice,和原array是一样的**
+
+**上面这句话很很很重要,要记住的是: 1.切片是对数组的映射,相当于是数组a和指向a的指针 2.不论对切片的拷贝是什么样的?切片的底层数据的指针都是指向数组的。去修改切片的值就是修改数组的值。**
+
+
+
+
+
+#### 总结:
+
+> go 值的拷贝都是值拷贝,只是切片中储存的是原数组的地址,“切片是对数组的引用” 每得到的一个切片都是一个指向数组的指针,当企图修改切片的值,就是在修改数组的值。内在的逻辑是:一个切片就是一个指向数组的指针,通过切片去修改数组,然后在引用数组,自始至终,都是在引用数组,不存在切片里面存了所引用的数组的数据!!!
+
+
+
+> Go的拷贝都是值拷贝,只是slice中存储的是原array的地址,所以在拷贝的时候,其实是把地址拷贝的新的slice,那么此时修改slice的时候,还是根据slice中存储的地址,找到要修改的内容
+
+
diff --git a/_posts/2021-02-28-test-markdown.md b/_posts/2021-02-28-test-markdown.md
new file mode 100644
index 000000000000..00787806022a
--- /dev/null
+++ b/_posts/2021-02-28-test-markdown.md
@@ -0,0 +1,105 @@
+---
+layout: post
+title: 远程分支有更新,如何同步?
+subtitle:
+tags: [git]
+---
+
+## 首先同步远程的仓库和远程 fork 的仓库
+
+在 github 上找到 fork 到自己主页的仓库,然后点击`Sync fork`
+
+## 其次本地仓库和自己主页的仓库
+
+然后在本地切换到 master 分支后
+
+```shell
+git fetch --all
+```
+
+```shell
+git reset --hard origin/master
+```
+
+```shell
+git pull
+```
+
+Tips:
+**git fetch 只是下载远程的库的内容,不做任何的合并**
+
+**git reset 把 HEAD 指向刚刚下载的最新的版本**
+
+## 第三就是同步本地仓库的其他分支和本地仓库的 master 分支
+
+然后在本地切换到 master 分支后,(在记得切换到 master 分支后,先要在其他的分支保存自己的更改)
+在 my-feature7 分支执行:
+
+```shell
+git add .
+```
+
+在 my-feature7 分支执行:
+
+```shell
+git commit -m"fix:"
+```
+
+```shell
+git pull
+```
+
+然后在本地切换到想要更新的其他分支
+
+```shell
+git checkout my-feature7
+```
+
+然后合并
+
+```shell
+git merge master
+```
+
+然后在 my-feature7 分支做出修改,提交到远程的 my-feature7 分支后提交 pr
+
+```shell
+git add newfile.go
+```
+
+```shell
+git commit -m"fix:555"
+```
+
+```shell
+git push origin my-feature7
+```
+
+
+## 常见问题
+
+当你在本地有更改,但是想丢弃所有的这些更改的时候:
+
+首先,需要处理当前分支(feat_shard_join)上的未暂存的更改。有几个选项:
+
+提交这些更改:
+```shell
+git add -A && git commit -m "你的提交信息"
+```
+撤销这些更改:
+```shell
+git restore .
+```
+确保所有的更改已处理后,你可以切换到 develop 分支:
+
+```shell
+git checkout develop
+```
+同步远程的 develop 分支更新到你的本地:
+
+```shell
+git pull origin develop
+```
+这样,你就成功切换到了 develop 分支并与远程仓库同步。请注意,在执行这些操作之前最好备份你的代码,以防意外发生。
+
+
diff --git a/_posts/2021-11-20-test-markdown.md b/_posts/2021-11-20-test-markdown.md
new file mode 100644
index 000000000000..5d5cbbc215ac
--- /dev/null
+++ b/_posts/2021-11-20-test-markdown.md
@@ -0,0 +1,88 @@
+---
+layout: post
+title: 并发一致性问题
+subtitle: 在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。
+tags: [数据库]
+---
+
+## 并发一致性问题
+
+在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。
+
+### 丢失修改
+
+丢失修改指一个事务的更新操作被另外一个事务的更新操作替换。一般在现实生活中常会遇到,例如:T1 和 T2 两个事务都对一个数据进行修改,T1 先修改并提交生效,T2 随后修改,T2 的修改覆盖了 T1 的修改。
+
+> 丢失修改(Lost Update):假设有两个用户A和B同时对数据库中的某一数据进行修改,并且A先提交了修改,然后B也提交了修改,那么A的修改就会被B的修改覆盖,从而导致A的修改丢失。例如,A和B同时对某一商品的库存进行修改,A将库存从100减少到90并提交了修改,然后B也将库存从100减少到95并提交了修改,那么最终库存会变成95而不是90。
+
+
+### 读脏数据
+
+读脏数据指在不同的事务下,当前事务可以读到另外事务未提交的数据。例如:T1 修改一个数据但未提交,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据
+
+> 读脏数据(Dirty Read):假设有一个用户A对数据库中的某一数据进行修改,并且在修改过程中,另一个用户B对该数据进行了查询,那么B就可能会读到未提交的“脏数据”,从而导致数据的不一致性。例如,A对某一商品的价格进行修改,将价格从100元增加到120元,但是还没有提交修改,此时B查询该商品的价格时,发现价格已经变成了120元,但是实际上A的修改还没有提交,因此B读到了未提交的“脏数据”。
+
+
+### 不可重复读
+
+不可重复读指在一个事务内多次读取同一数据集合。在这一事务还未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。例如:T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
+
+
+
+产生并发不一致性问题的主要原因是破坏了事务的隔离性,解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。
+
+
+> 不可重复读(Non-repeatable Read):假设有一个用户A对数据库中的某一数据进行查询,并且在查询过程中,另一个用户B对该数据进行了修改,那么A再次查询该数据时就会发现数据与之前不一致。例如,A查询某一商品的价格为100元,然后B将该商品的价格修改为110元,并提交了修改,此时A再次查询该商品的价格时,发现价格已经变成了110元,与之前不一致。
+
+### 解决该问题
+
+
+> 丢失修改:由于事务在修改数据R之前必须加上X锁,其他事务无法同时修改R,因此可以避免丢失修改的问题。
+
+> 不可重复读:由于事务在读取数据R之前必须加上S锁,其他事务无法同时修改或删除R,因此可以避免不可重复读的问题
+
+> 读脏数据:由于事务在读取数据R之前必须加上S锁,其他事务无法同时修改或删除R,因此可以避免读脏数据的问题。
+
+
+存在的问题:缺点是锁的粒度较大,可能会导致资源的浪费和性能的下降
+
+## 两段封锁协议
+
+两段封锁协议是一种并发控制方法,它要求事务必须分两个阶段对数据项进行加锁和解锁操作。这两个阶段分别是封锁阶段和解封锁阶段,具体如下:
+
+封锁阶段:在该阶段中,事务可以获得任何数据项上的任何类型的锁,但不能释放锁。在该阶段,事务需要先获得所有需要使用的锁,然后才能进行相应的操作,例如读取或修改数据。该阶段的目的是保证在事务对数据进行操作时,其他事务无法修改或删除数据,从而避免数据不一致的情况。
+
+解封锁阶段:在该阶段中,事务可以释放任何数据项上的任何类型的锁,但不能申请新的锁。在该阶段,事务需要先释放所有不再需要使用的锁,然后才能提交事务或者回滚事务。该阶段的目的是释放事务在该阶段中,事务可以释放任何数据项上的任何类型的锁,但不能申请新的锁。在该阶段,事务需要先释放所有不再需要使用的锁,然后才能提交事务或者回滚事务。该阶段的目的是释放事务占用的资源,避免资源的浪费。
+
+
+## 死锁/活锁
+
+活锁是指在并发访问的过程中,由于某些原因,事务一直处于等待状态,但是等待的条件不满足,导致事务无法继续执行。例如,在两个事务同时请求封锁同一条数据时,如果它们始终无法获取到该数据的封锁,就会导致活锁的情况发生。在活锁的情况下,事务一直在运行,但是无法完成任务,导致系统资源的浪费和性能的下降。
+
+死锁是指在并发访问的过程中,由于多个事务之间相互等待对方持有的锁,导致多个事务都无法继续执行,从而形成了一个死循环。例如,如果事务A请求封锁数据R1后又请求封锁数据R2,而事务B则请求封锁数据R2后又请求封锁数据R1,这样就会导致事务A和事务B之间形成了一个死锁。在死锁的情况下,事务都无法继续执行,只能等待其他事务释放锁,从而导致系统的资源浪费和性能下降。
+
+
+> 封锁协议可以解决死锁的问题,封锁协议可以通过以下两种方式来避免死锁的情况:
+
+- 顺序加锁:在多个事务同时访问多个数据项时,按照固定的顺序对数据项进行加锁,从而避免不同事务之间加锁的顺序不一致,导致死锁的情况发生。
+
+- 封锁超时:如果一个事务不能在规定的时间内获得所需的锁,就会取消该事务的请求,从而避免死锁的情况发生。在这种情况下,事务需要在等待锁的过程中,不断地检查是否超时,如果超时,则可以回滚事务,释放已经获得的锁。
+
+
+## 并发调度的可串行化
+
+并发调度是指在多个事务同时访问共享资源的情况下,如何安排这些事务的执行顺序,以保证系统的正确性和性能。可串行性是并发调度的一个重要准则,它指的是多个事务的并发执行结果与某一次序串行地执行这些事务时的结果相同。
+
+举个例子,假设有两个事务T1和T2,它们要同时访问数据R1和R2。如果这两个事务的执行顺序是T1访问R1,然后T2访问R2,最后T1访问R2,T2访问R1,那么这个调度是可串行化的,因为将这两个事务按照顺序串行地执行,也会得到相同的结果。如果这个调度不是可串行化的,例如T1和T2同时访问R1和R2,那么这个调度就是不正确的,因为它可能导致数据的错误或者不一致。
+
+要实现可串行化的调度,需要采用一些并发控制方法,例如加锁、封锁协议、事务隔离级别等。其中,加锁是最基本的并发控制方法,并且可以有效地避免并发访问的冲突。封锁协议可以保证事务的一致性和可串行性,从而避免数据的不一致和错误。事务隔离级别可以控制事务之间的相互影响,从而保证事务的独立性和正确性。
+
+### 实现并发调度的可串行化
+
+加锁:采用锁机制来控制事务之间的访问顺序和互斥访问,从而保证事务的正确性和一致性。一般来说,加锁的粒度越小,锁的争用就越少,但是也会带来更多的锁开销。
+
+封锁协议:通过规定事务加锁的顺序,避免出现事务之间的死锁和活锁的情况,从而保证事务的可串行性和正确性。封锁协议有很多种,如二段锁、多粒度锁等。
+
+事务隔离级别:事务隔离级别可以控制事务之间的相互影响,从而保证事务的独立性和正确性。一般来说,事务隔离级别越高,事务之间的相互影响就越小,但是也会带来更多的性能开销。
+
+MVCC(多版本并发控制):采用多版本的方式来控制并发访问,从而保证事务的可串行性和正确性。MVCC可以避免一些常见的并发问题,例如脏读、不可重复读和幻读等
\ No newline at end of file
diff --git a/_posts/2021-12-30-test-markdown.md b/_posts/2021-12-30-test-markdown.md
new file mode 100644
index 000000000000..fb11f6376c14
--- /dev/null
+++ b/_posts/2021-12-30-test-markdown.md
@@ -0,0 +1,254 @@
+---
+layout: post
+title: 并发工作者池模式
+subtitle: 并不是要讨论并发,而是我们要实现一组作业如何让他并发的执行
+tags: [并发]
+---
+# Go Concurrency Worker Pool PatternGo 并发工作者池模式
+
+> 并不是要讨论并发,而是我们要实现一组作业如何让他并发的执行
+
+## **WorkerPool 组件编排**
+
+
+
+### 1.**第一步**
+
+```
+// 创建了一个名为 的最小工作单元Job
+type Job struct {
+ Descriptor JobDescriptor
+ ExecFn ExecutionFn
+ Args interface{}
+}
+
+// ExecutionFn 是这个函数类型 func ( ctx context.Context, args interface{})(value ,error)
+// 可以看到函数返回了一个value类型 和 error类型
+// 我们自己定义一个 Result 类型来存储Job的方法对应的信息
+和里面存储 Job.Descriptor 类型是JobDescriptor
+// 还存储了 Job.ExecFn函数执行得到的错误的信息
+type Result struct{
+ //Err字段来存储Job.ExecFn函数执行的结果中的Error
+ Err error
+ //Value字段来存储Job.ExecFn函数执行的结果中的value 类型
+ Value value
+ //Descriptor字段来存储Job这个结构体自己带的Descriptor描述信息
+ Descriptor JobDescriptor
+}
+//执行函数最简单的逻辑就是得到结果
+func (j Job) execute(ctx context.Context) Result {
+ value, err := j.ExecFn(ctx, j.Args)
+ if err != nil {
+ return Result{
+ Err: err,
+ Descriptor: j.Descriptor,
+ }
+ }
+
+ return Result{
+ Value: value,
+ Descriptor: j.Descriptor,
+ }
+}
+```
+
+### 2.第二步
+
+```
+//我们要使用generator并发模式将所有Jobs 流式传输到WorkerPool.
+
+//说人话就是......
+//从某个客户端定义Job的 s 切片上生成一个流,将它们中的每一个推入一个通道,即Jobs 通道。这将用于同时馈送WorkerPool.
+//所以客户端定义Job的 s 切片在哪里?
+//忘了在前面加了...
+//补充完毕之后完整的代码应该是下面这个样子
+//map[string]interface{} string 用来代表不同的客户端 (为了便于处理)具体客户端携带的东西可以是任何的东西
+
+type jobMetadata map[string]interface{}
+type Job struct {
+ Descriptor JobDescriptor
+ ExecFn ExecutionFn
+ Args interface{}
+}
+
+type Result struct{
+ //Err字段来存储Job.ExecFn函数执行的结果中的Error
+ Err error
+ //Value字段来存储Job.ExecFn函数执行的结果中的value 类型
+ Value value
+ //Descriptor字段来存储Job这个结构体自己带的Descriptor描述信息
+ Descriptor JobDescriptor
+}
+
+func (j Job) execute(ctx context.Context) Result {
+ value, err := j.ExecFn(ctx, j.Args)
+ if err != nil {
+ return Result{
+ Err: err,
+ Descriptor: j.Descriptor,
+ }
+ }
+
+ return Result{
+ Value: value,
+ Descriptor: j.Descriptor,
+ }
+}
+
+```
+
+```
+// 当然要写个函数喽,来把我们客户端的工作全部推入到 Jobs 通道
+// func GenerateFrom( jobsBulk []Job )
+// 这个函数应该是属于 Jobs 通道的 ,我们当然要抽象出来一个 Jobs 通道
+// WorkerPool 就是我们抽象出来的一个结构体
+// WorkerPool 里面有个字段 jobs
+// WorkerPool.jobs应该是一个通道
+// 我们把我们的[]Job 切片依次放到这个通道里面
+// 然后关闭通道
+func (wp WorkerPool) GenerateFrom(jobsBulk []Job) {
+ for i, _ := range jobsBulk {
+ wp.jobs <- jobsBulk[i]
+ }
+ close(wp.jobs)
+}
+
+// WorkerPool.jobs是一个缓冲通道(workers count capped的大小)WorkerPool.workersCount 这个
+
+// 一旦它被填满,任何进一步的写入尝试都会阻塞当前的 goroutine
+// 在这种情况下,流的生成器 goroutine 从 1 开始)
+// 在任何时候,如果WorkerPool.jobs通道上存在任何内容,将被Worker函数消耗以供以后执行。通过这种方式,通道将为从前一点Job流出的新写入解除阻塞。generator
+```
+
+### 3.第三步**WorkerPool**
+
+```
+// workersCount 字段
+// jobs 字段 工人自己将负责在channel可用时从channel中获取Job
+// 从 jobs channel中提取所有可用的作业后,WorkerPool 将通过关闭自己的 Done channel 和 Results channel来完成其执行。
+// results 字段 工人执行Job并将其Result存储到Result的channel
+// 只要没有在 Context 上调用 cancel() 函数,Worker 就会执行前面提到的操作。
+// Done 字段
+// 否则,循环制动,WaitGroup 被标记为 Done()。这与“杀死工人”的想法非常相似。
+type WorkerPool struct{
+ workersCount int
+ jobs chan Job
+ results chan Result
+ Done chan struct{}
+}
+//工人自己将负责在channe可用时从channe中获取Job
+
+func worker(ctx context.Context, wg *sync.WaitGroup, jobs <-chan Job, results chan<- Result) {
+ defer wg.Done()
+ for {
+ select {
+ case job, ok := <-jobs:
+ if !ok {
+ return
+ }
+ // fan-in job execution multiplexing results into the results channel
+ //执行多路复用结果到结果通道
+ results <- job.execute(ctx)
+ case <-ctx.Done():
+ fmt.Printf("cancelled worker. Error detail: %v\n", ctx.Err())
+ results <- Result{
+ Err: ctx.Err(),
+ }
+ return
+ }
+ }
+}
+
+func New(wcount int) WorkerPool {
+ return WorkerPool{
+ workersCount: wcount,
+ jobs: make(chan Job, wcount),
+ results: make(chan Result, wcount),
+ Done: make(chan struct{}),
+ }
+}
+
+
+
+func (wp WorkerPool) Run(ctx context.Context) {
+ var wg sync.WaitGroup
+
+ for i := 0; i < wp.workersCount; i++ {
+ wg.Add(1)
+ // fan out worker goroutines
+ //reading from jobs channel and
+ //pushing calcs into results channel
+ go worker(ctx, &wg, wp.jobs, wp.results)
+ }
+
+ wg.Wait()
+ close(wp.Done)
+ close(wp.results)
+}
+```
+
+### 4.第四步Results Channel
+
+如前所述,即使工作人员在不同的 goroutine 上运行,他们也会通过将它们多路复用到' 通道(AKA ***fanning-in\***`Job` )来发布' 执行。即使通道因上述任何原因关闭,客户端也可以从此源读取。`Result``Result``WorkerPool`
+
+### 5. Reading Results
+
+如前所述,即使工人在不同的 goroutine 上运行,他们通过将 Job 的执行结果多路复用到 Result 的通道(AKA fanning-in)来发布作业的执行结果。即使通道因上述任何原因关闭,WorkerPool 的客户端也可以从此源读取。
+
+一旦关闭 WorkerPool 的 Done 通道返回并向前移动,for 循环就会中断。
+
+```
+func TestWorkerPool(t *testing.T) {
+ wp := New(workerCount)
+
+ ctx, cancel := context.WithCancel(context.TODO())
+ defer cancel()
+
+ go wp.GenerateFrom(testJobs())
+
+ go wp.Run(ctx)
+
+ for {
+ select {
+ case r, ok := <-wp.Results():
+ if !ok {
+ continue
+ }
+
+ i, err := strconv.ParseInt(string(r.Descriptor.ID), 10, 64)
+ if err != nil {
+ t.Fatalf("unexpected error: %v", err)
+ }
+
+ val := r.Value.(int)
+ if val != int(i)*2 {
+ t.Fatalf("wrong value %v; expected %v", val, int(i)*2)
+ }
+ case <-wp.Done:
+ return
+ default:
+ }
+ }
+}
+```
+
+### 6.Cancel Gracefully
+
+无论如何,如果客户端需要优雅地关闭 WorkerPool 的执行,它可以在给定的 Context 上调用 cancel() 函数,或者配置由 Context.WithTimeout 方法定义的超时持续时间。
+
+是否发生一个或其他选项(最终都调用 cancel() 函数,一个显式调用,另一个在超时发生后)将从 Context 返回一个关闭的 Done 通道,该通道将传播到所有 Worker 函数
+
+这使得 for select 循环中断,因此工人停止在通道外消费作业。然后稍后,WaitGroup 被标记为完成。但是,运行中的工作人员将在 WorkerPool 关闭之前完成他们的工作执行。
+
+### 7.Sum Up
+
+当我们利用这种模式时,我们将利用我们的系统实现并发作业执行,从而在作业执行中提高性能和一致性。
+
+乍一看,这种模式可能很难掌握。但是,请花点时间消化它,特别是如果您是 GoLang 并发模型的新手。
+
+可能有帮助的一件事是将通道视为管道,其中数据从一侧流向另一侧,并且可以容纳的数据量是有限的。
+
+所以如果我们想注入更多的数据,我们只需要在等待的时候先取出一些数据来为它腾出一些额外的空间
+
+另一方面,如果我们想从管道中消费,就必须有一些东西,否则,我们等到那发生。通过这种方式,我们使用这些管道在 goroutine 之间进行通信和共享数据。
+
diff --git a/_posts/2022-02-15-test-markdown.md b/_posts/2022-02-15-test-markdown.md
new file mode 100644
index 000000000000..0b158c6a28e1
--- /dev/null
+++ b/_posts/2022-02-15-test-markdown.md
@@ -0,0 +1,461 @@
+---
+layout: post
+title: 什么是 REST API?
+subtitle: RESTful API 设计规范
+tags: [架构]
+---
+## RESTful API 设计规范
+
+**从字面可以看出,他是Rest式的接口,所以我们先了解下什么是Rest**
+
+#### 什么是 REST API?
+
+REST API 也称为 RESTful API,是遵循 REST 架构规范的应用编程接口(API 或 Web API),支持与 RESTful Web 服务进行交互。REST全称 **RE**presentational **S**tate **T**ransfer。 由Roy Thomas Fielding博士在2000年于其论文 *Architectural Styles and the Design of Network-based Software Architectures* 中提出的。 是一种分布式超媒体架构风格。
+
+> #### 什么是 API?
+>
+> API 由一组定义和协议组合而成,可用于构建和集成应用软件。有时我们可以把它们当做信息提供者和信息用户之间的合同——建立消费者(呼叫)所需的内容和制作者(响应)要求的内容。例如,天气服务的 API 可指定用户提供邮编,制作者回复的答案由两部分组成,第一部分是最高温度,第二部分是最低温度。
+>
+> 换言之,如果想与计算机或系统交互以检索信息或执行某项功能,API 可帮助将需要的信息传达给该系统,使其能够理解并满足的请求。
+>
+> 可以把 API 看做是用户或客户端与他们想要的资源或 Web 服务之间的传递者。它也是企业在共享资源和信息的同时保障安全、控制和身份验证的一种方式,即确定哪些人可以访问什么内容。
+>
+> API 的另一个优势是无需了解缓存的具体信息,即如何检索资源或资源来自哪里。
+
+> #### 如何理解 REST 的含义?
+>
+> **REST 是一组架构规范,并非协议或标准。API 开发人员可以采用各种方式实施 REST。**
+>
+> 当客户端通过 RESTful API 提出请求时,它会将资源状态表述传递给请求者或终端。该信息或表述通过 HTTP 以下列某种格式传输:JSON(Javascript 对象表示法)、HTML、XLT、Python、PHP 或纯文本。JSON 是最常用的编程语言,尽管它的名字英文原意为“JavaScript 对象表示法”,但它适用于各种语言,并且人和机器都能读。
+>
+> **头和参数在 RESTful API HTTP 请求的 HTTP 方法中也很重要,因为其中包含了请求的元数据、授权、统一资源标识符(URI)、缓存、cookie 等重要标识信息。有请求头和响应头,每个头都有自己的 HTTP 连接信息和状态码。**
+
+#### **如何实现 RESTful API?**
+
+API 要被视为 RESTful API,必须遵循以下标准:
+
+- **客户端-服务器架构由客户端、服务器和资源组成,并且通过 HTTP 管理请求。**
+
+- **[无状态](https://www.redhat.com/zh/topics/cloud-native-apps/stateful-vs-stateless)客户端-服务器通信,即 get 请求间隔期间,不会存储任何客户端信息,并且每个请求都是独立的,互不关联。**客户端到服务端的所有请求必须包含了所有信息,不能够利用任何服务器存储的上下文。 这一约束可以保证绘画状态完全由客户端控制
+
+ 这一点在写一个接口的时候需要独立思考一下,如果每个请求都是独立的,互不关联的,那么他们怎么配合着实现一整套的功能,
+
+- **可缓存性数据**:可简化客户端-服务器交互。
+
+- **组件间的统一接口:使信息以标准形式传输。这要求:**
+
+ - Identification of resources 资源标识符**所请求的资源可识别并与发送给客户端的表述分离开。**
+
+ - Manipulation of resources through representations
+
+ 通过“representation”来操作资源
+
+ - Self-descriptive messages 自我描述
+
+ 客户端可通过接收的表述操作资源,因为表述包含操作所需的充足信息。返回给客户端的自描述消息包含充足的信息,能够指明客户端应该如何处理所收到的信息。
+
+ - 超文本/超媒体可用,是指在访问资源后,客户端应能够使用超链接查找其当前可采取的所有其他操作。
+
+- **组织各种类型服务器(负责安全性、负载平衡等的服务器)的分层系统会参与将请求的信息检索到对客户端不可见的层次结构中。**
+
+ 系统是分层的,客户端无法知道也不需要知道与他交互的是否是真正的终端服务器。 这也就给了系统在中间切入的可能,提高了安全性和伸缩性。
+
+ ### Resource 资源
+
+ 在了解了REST API的约束后,REST最关键的概念就是资源。 任何的信息在REST架构里都被抽象为资源:图像、文档、集合、用户,等等。 (这在某些场景是和直觉相悖的,后文会详述) REST通过资源标识符来和特定资源进行交互。
+
+ 资源在特定时间戳下的状态称之为资源表示(Resource Representation),由**数据**,**元数据**和**超链接**组成。 资源的格式由媒体类型(media type)指定。(我们熟悉的JSON即是一种方式)
+
+ 一个真正的REST API看上去就像是超文本一样。 除了数据本身以外还包含了其他客户端想了解的信息以描述自己, 比如一个典型的例子是在获取分页数据时,服务端同时还会返回页码总数以及下一页的链接。
+
+## REST vs HTTP
+
+从上面的概念我们就可以知道,REST和任何具体技术无关。 我们会认为REST就是HTTP,主要是因为HTTP是最广为流行的客户端服务端通信协议。 但是HTTP本身和REST无关,可以通过其他协议构建RESTful服务; 用HTTP构建的服务也很有可能不是RESTful的。
+
+
+
+## REST vs JSON
+
+与通信协议一样,REST与任何具体的数据格式无关。 无论用XML,JSON或是HTML,都可以构建REST服务。
+
+更进一步的,JSON甚至不是一种超媒体格式,只是一种数据格式。 比如JSON并没有定义超链接发现的行为。 真正的REST需要的是有着清楚规范的超媒体格式,比较标准的JSON-base超媒体格式有 [JSON-LD](http://www.w3.org/TR/json-ld/) 和 [HAL](http://stateless.co/hal_specification.html)
+
+**个人最想分享的部分!!!**
+
+# Richardson Maturity Model
+
+> steps toward the glory of REST
+>
+> *A model (developed by Leonard Richardson) that breaks down the principal elements of a REST approach into three steps. These introduce resources, http verbs, and hypermedia controls.*
+>
+> *一个模型(由 Leonard Richardson 开发)将 REST 方法的主要元素分解为三个步骤。这些介绍了资源、http 动词和超媒体控件。*
+
+**核心是这样一个概念,即网络是一个运行良好的大规模可扩展分布式系统的存在证明,我们可以从中汲取灵感来更轻松地构建集成系统。**
+
+*走向 REST 的步骤*
+
+
+
+## 级别 0
+
+该模型的出发点是使用 HTTP 作为远程交互的传输系统,但不使用任何 Web 机制。本质上,在这里所做的是使用 HTTP 作为自己的远程交互机制的隧道机制,通常基于[Remote Procedure Invocation](http://www.eaipatterns.com/EncapsulatedSynchronousIntegration.html)。
+
+
+
+*0 级交互示例*
+
+假设我想和我的医生预约。我的预约软件首先需要知道我的医生在给定日期有哪些空档,因此它会向医院预约系统发出请求以获取该信息。在 0 级场景中,医院将在某个 URI 处公开服务端点。然后,我将包含我的请求详细信息的文档发布到该端点。
+
+```
+POST /appointmentService HTTP/1.1
+[various headers]
+
+
+然后服务器将返回一个文件给我这个信息
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+
+
+ <医生 id = "mjones"/>
+
+
+
+我在这里使用 XML 作为示例,但内容实际上可以是任何内容:JSON、YAML、键值对或任何自定义格式。
+
+我的下一步是预约,我可以再次通过将文档发布到端点来进行预约。
+POST /appointmentService HTTP/1.1
+[various headers]
+
+
+
+
+
+如果一切顺利,我会收到回复说我的约会已预订。
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+
+如果有问题,说其他人在我之前进入,那么我会在回复正文中收到某种错误消息。
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+ Slot not available
+
+```
+
+到目前为止,这是一个简单的 RPC 样式系统。这很简单,因为它只是来回传输普通的旧 XML (POX)。如果您使用 SOAP 或 XML-RPC,它基本上是相同的机制,唯一的区别是您将 XML 消息包装在某种信封中。
+
+## 级别 1 - 资源
+
+在 RMM 中实现REST的荣耀的第一步是引入资源。因此,现在我们不再向单个服务端点发出所有请求,而是开始与单个资源进行对话。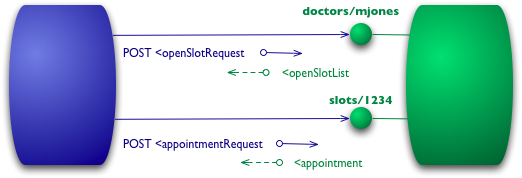
+
+*图 3:1 级添加资源*
+
+```
+因此,对于我们的初始查询,我们可能有给定医生的资源。
+
+POST /doctors/mjones HTTP/1.1
+[various headers]
+
+
+回复带有相同的基本信息,但现在每个插槽都是可以单独寻址的资源。
+
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+
+
+使用特定资源预约意味着发布到特定位置。
+
+POST /slots/1234 HTTP/1.1
+[各种其他标头]
+
+
+ <患者 id = "jsmith"/>
+
+如果一切顺利,我会收到与之前类似的回复。
+
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+
+```
+
+**区别是我们不是调用某个函数并传递参数,而是在一个特定对象上调用一个方法,为其他信息提供参数。**
+
+## 第 2 级 - HTTP 动词
+
+在 0 级和 1 级的所有交互中都使用了 HTTP POST 动词,但有些人使用 GET 代替或附加使用。在这些级别上并没有太大区别,它们都被用作隧道机制,允许我们通过 HTTP 隧道交互。级别 2 远离这一点,使用 HTTP 动词尽可能接近它们在 HTTP 本身中的使用方式
+
+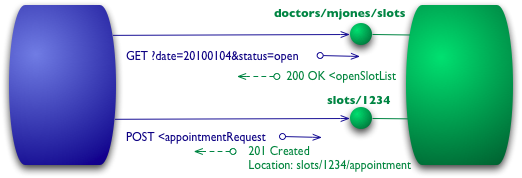
+
+对于我们的插槽列表,这意味着我们要使用 GET。
+
+```
+GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1
+主机:royalhope.nhs.uk
+```
+
+回复与 POST 的回复相同
+
+```
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+
+```
+
+在第 2 级,对这样的请求使用 GET 至关重要。HTTP 将 GET 定义为一种安全操作,即它不会对任何事物的状态进行任何重大更改。这允许我们以任何顺序安全地调用 GET 多次,并且每次都获得相同的结果。这样做的一个重要结果是,**它允许请求路由中的任何参与者使用缓存,**这是使 Web 性能与它一样好的关键因素。HTTP 包括各种支持缓存的措施,通信中的所有参与者都可以使用这些措施。通过遵循 HTTP 的规则,我们能够利用该功能。
+
+为了预约,我们需要一个改变状态的 HTTP 动词,一个 POST 或一个 PUT。我将使用与之前相同的 POST。
+
+即使我使用与级别 1 相同的帖子,远程服务的响应方式也存在另一个显着差异。如果一切顺利,该服务会回复一个响应代码 201,表示世界上有一个新资源。
+
+```
+HTTP/1.1 201 Created
+Location: slots/1234/appointment
+[various headers]
+
+
+
+
+
+
+201 响应包含一个带有 URI 的 location 属性,客户端可以使用该 URI 来获取该资源的当前状态。此处的响应还包括该资源的表示,以立即为客户端节省额外的调用。
+
+如果出现问题,例如其他人预订会话,则还有另一个区别。
+
+HTTP/1.1 409 Conflict
+[various headers]
+
+
+
+
+```
+
+此响应的重要部分是使用 HTTP 响应代码来指示出现问题。在这种情况下,409 似乎是一个不错的选择,表明其他人已经以不兼容的方式更新了资源。不是使用返回码 200 而是包含错误响应,在第 2 级,我们明确地使用了类似这样的某种错误响应。由协议设计者决定使用什么代码,但如果出现错误,应该有一个非 2xx 响应。第 2 级介绍了使用 HTTP 动词和 HTTP 响应代码。
+
+这里有一个不一致的地方。REST 倡导者谈论使用所有 HTTP 动词。他们还通过说 REST 试图从 Web 的实际成功中学习来证明他们的方法是正确的。但是万维网在实践中很少使用 PUT 或 DELETE。更多地使用 PUT 和 DELETE 有合理的理由,但网络的存在证明不是其中之一。
+
+Web 存在支持的关键元素是安全(例如 GET)和非安全操作之间的强分离,以及使用状态代码来帮助传达遇到的各种错误。
+
+## 3 级 - 超媒体控制
+
+最后一层介绍了一些经常听到的东西,它被称为 HATEOAS(超文本作为应用程序状态的引擎)它解决了如何从列表中获取空缺职位以了解如何进行预约的问题。
+
+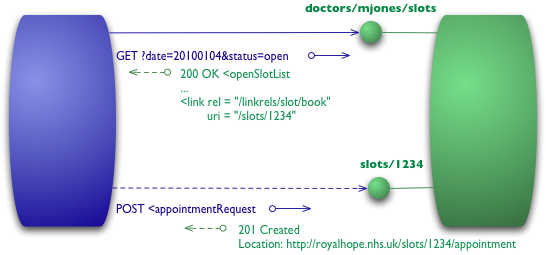
+
+```
+我们从在级别 2 中发送的相同初始 GET 开始
+
+GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1
+Host: royalhope.nhs.uk
+但回应有一个新的元素
+HTTP/1.1 200 OK
+[various headers]
+
+
+
+
+
+
+
+
+
+```
+
+每个插槽现在都有一个链接元素,其中包含一个 URI,告诉我们如何预约。
+
+超媒体控件的重点是它们告诉我们下一步可以做什么,以及我们需要操作的资源的 URI。我们不必知道在哪里发布我们的预约请求,响应中的超媒体控件会告诉我们如何去做。
+
+POST 将再次复制 2 级的
+
+```
+POST /slots/1234 HTTP/1.1
+[various other headers]
+
+
+
+
+
+HTTP/1.1 201 Created
+Location: http://royalhope.nhs.uk/slots/1234/appointment
+[various headers]
+回复包含许多超媒体控件,用于接下来要做的不同事情
+
+
+
+
+
+
+
+
+
+
+
+```
+
+我应该强调,虽然 RMM 是一种思考 REST 元素的好方法,但它并不是 REST 本身级别的定义。Roy Fielding 明确表示,[3 级 RMM 是 REST 的先决条件](http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven)。与软件中的许多术语一样,REST 有很多定义,但自从 Roy Fielding 创造了这个术语,他的定义应该比大多数人更重要。
+
+我发现这个 RMM 的有用之处在于它提供了一个很好的循序渐进的方式来理解restfulness.思维背后的基本思想。因此,我认为它是帮助我们了解概念的工具,而不是应该在某种评估机制中使用的东西。我认为我们还没有足够的示例来真正确定 restful 方法是集成系统的正确方法,我确实认为这是一种非常有吸引力的方法,并且在大多数情况下我会推荐这种方法。
+
+这个模型的吸引力在于它与常见设计技术的关系。
+
+- 级别 1 通过使用分而治之,将大型服务端点分解为多个资源来解决处理复杂性的问题。
+
+- Level 2 引入了一组标准的动词,以便我们以相同的方式处理类似的情况,消除不必要的变化。
+
+### 局限:
+
+#### 不是所有业务都可以被表示为资源
+
+这在构建REST API时是经常会碰到的,我们不能正确表示资源,所以被迫采用了其他实际。
+
+例如,一个简单的用户登入登出,如果抽象为资源可能变成了创建一个会话, 即`POST /api/session`,这其实远不如`POST /login`来的直观。
+
+又比如,一个播放器资源,当我们要播放或停止时,一个典型的设计肯定是`POST /player/stop`, 而如果要满足REST规范,停止这个动作将不复存在,取而代之的是`播放器状态`,API形如 `POST /player {state:"stop"}`。
+
+以上两例都展示了,REST在某些场景下可能并不能提供良好的表现力。
+
+## 基于 HTTP+JSON 的类 REST API 设计
+
+http://www.ruanyifeng.com/blog/2014/05/restful_api.html
+
+##### 一、协议
+
+API与用户的通信协议,总是使用[HTTPs协议](https://www.ruanyifeng.com/blog/2014/02/ssl_tls.html)。
+
+##### 二、域名
+
+应该尽量将API部署在专用域名之下。
+
+> ```javascript
+> https://api.example.com
+> ```
+
+如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
+
+> ```javascript
+> https://example.org/api/
+> ```
+
+##### 三、版本(Versioning)
+
+应该将API的版本号放入URL。
+
+> ```javascript
+> https://api.example.com/v1/
+> ```
+
+另一种做法是,将版本号放在HTTP头信息中,但不如放入URL方便和直观。[Github](https://developer.github.com/v3/media/#request-specific-version)采用这种做法。
+
+##### 四、路径(Endpoint)
+
+路径又称"终点"(endpoint),表示API的具体网址。
+
+在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。
+
+举例来说,有一个API提供动物园(zoo)的信息,还包括各种动物和雇员的信息,则它的路径应该设计成下面这样。
+
+> - https://api.example.com/v1/zoos
+> - https://api.example.com/v1/animals
+> - https://api.example.com/v1/employees
+
+##### 五、HTTP动词
+
+对于资源的具体操作类型,由HTTP动词表示。
+
+常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
+
+> - GET(SELECT):从服务器取出资源(一项或多项)。
+> - POST(CREATE):在服务器新建一个资源。
+> - PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
+> - PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
+> - DELETE(DELETE):从服务器删除资源。
+
+##### 六、过滤信息(Filtering)
+
+如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
+
+下面是一些常见的参数。
+
+> - ?limit=10:指定返回记录的数量
+> - ?offset=10:指定返回记录的开始位置。
+> - ?page=2&per_page=100:指定第几页,以及每页的记录数。
+> - ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
+> - ?animal_type_id=1:指定筛选条件
+
+参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
+
+##### 七、状态码(Status Codes)
+
+##### 八、错误处理(Error handling)
+
+如果状态码是4xx,就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
+
+> ```javascript
+> {
+> error: "Invalid API key"
+> }
+> ```
+
+##### 九、返回结果
+
+针对不同操作,服务器向用户返回的结果应该符合以下规范。
+
+> - GET /collection:返回资源对象的列表(数组)
+> - GET /collection/resource:返回单个资源对象
+> - POST /collection:返回新生成的资源对象
+> - PUT /collection/resource:返回完整的资源对象
+> - PATCH /collection/resource:返回完整的资源对象
+> - DELETE /collection/resource:返回一个空文档
+
+##### 十、Hypermedia API
+
+RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
+
+比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
+
+> ```javascript
+> {"link": {
+> "rel": "collection https://www.example.com/zoos",
+> "href": "https://api.example.com/zoos",
+> "title": "List of zoos",
+> "type": "application/vnd.yourformat+json"
+> }}
+> ```
+
+上面代码表示,文档中有一个link属性,用户读取这个属性就知道下一步该调用什么API了。rel表示这个API与当前网址的关系(collection关系,并给出该collection的网址),href表示API的路径,title表示API的标题,type表示返回类型
+
+##### 十一、其他
+
+(1)API的身份认证应该使用[OAuth 2.0](https://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html)框架。
+
+(2)服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
\ No newline at end of file
diff --git a/_posts/2022-02-19-test-markdown.md b/_posts/2022-02-19-test-markdown.md
new file mode 100644
index 000000000000..29fb1f8560e8
--- /dev/null
+++ b/_posts/2022-02-19-test-markdown.md
@@ -0,0 +1,32 @@
+---
+layout: post
+title: 浅谈MVC、MVP、MVVM架构模式
+subtitle: MVC、MVP、MVVM这些模式是为了解决开发过程中的实际问题而提出来的,目前作为主流的几种架构模式而被广泛使用.
+tags: [架构]
+---
+# 浅谈MVC、MVP、MVVM架构模式
+
+MVC、MVP、MVVM这些模式是为了解决开发过程中的实际问题而提出来的,目前作为主流的几种架构模式而被广泛使用.
+
+### 一、MVC(Model-View-Controller)(最简单数据单线传递)
+
+#### MVC是比较直观的架构模式,用户操作->View(负责接收用户的输入操作)->Controller(业务逻辑处理)->Model(数据持久化)->View(将结果反馈给View).
+
+### 二、MVP(Model-View-Presenter)
+
+##### MVP是把MVC中的Controller换成了Presenter(呈现),目的就是为了完全切断View跟Model之间的联系,由Presenter充当桥梁,做到View-Model之间通信的完全隔离.
+
+Model提供数据,View负责显示,Controller/Presenter负责逻辑的处理.MVP与MVC有着一个重大的区别:在MVP中View并不直接使用Model,它们之间的通信是通过Presenter (MVC中的Controller)来进行的,所有的交互都发生在Presenter内部,而在MVC中View会直接从Model中读取数据而不是通过 Controller.
+
+- 特点:
+ 1. 各部分之间的通信,都是双向的.
+ 2. View 与 Model 不发生联系,都通过 Presenter 传递.
+ 3. View 非常薄,不部署任何业务逻辑,称为”被动视图”(Passive View),即没有任何主动性,而 Presenter非常厚,所有逻辑都部署在那里.
+
+### 三、MVVM(Model-View-ViewModel)
+
+##### 如果说MVP是对MVC的进一步改进,那么MVVM则是思想的完全变革.它是将“数据模型数据双向绑定”的思想作为核心,因此在View和Model之间没有联系,通过ViewModel进行交互,而且Model和ViewModel之间的交互是双向的,因此视图的数据的变化会同时修改数据源,而数据源数据的变化也会立即反应到View上.
+
+MVVM 模式将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致.唯一的区别是,它采用双向绑定(data-binding):View的变动,自动反映在 ViewModel,反之亦然;
+
+这种模式跟经典的MVP(Model-View-Presenter)模式很相似,除了需要一个为View量身定制的model,这个model就是ViewModel.ViewModel包含所有由UI特定的接口和属性,并由一个 ViewModel 的视图的绑定属性,并可获得二者之间的松散耦合,所以需要在ViewModel 直接更新视图中编写相应代码.数据绑定系统还支持提供了标准化的方式传输到视图的验证错误的输入的验证.
\ No newline at end of file
diff --git a/_posts/2022-03-14-test-markdown.md b/_posts/2022-03-14-test-markdown.md
new file mode 100644
index 000000000000..c987d1f60a80
--- /dev/null
+++ b/_posts/2022-03-14-test-markdown.md
@@ -0,0 +1,1133 @@
+---
+layout: post
+title: Goroutines以及通道在 Golang 中的应用
+subtitle: Go 使用通道在 goroutine 之间共享数据。它就像一个发送和接收数据的管道。通道是并发安全的。因此,您不需要处理锁定。线程使用共享内存。这是与流程最重要的区别。但是,必须使用互斥锁、信号量等来避免与 goroutines 相反的任何问题。
+tags: [golang]
+---
+# Goroutines以及通道在 Golang 中的应用
+
+
+
+> 共享数据
+>
+> Go 使用**通道**在 goroutine 之间共享数据。它就像一个发送和接收数据的管道。通道是并发安全的。因此,您不需要处理锁定。线程使用共享内存。这是与流程最重要的区别。但是,必须使用互斥锁、信号量等来避免与 goroutines 相反的任何问题。
+
+## Example 1
+
+让我们以餐厅为例。餐厅有一些服务员和厨师。
+
+通常餐厅里顾客、服务员和厨师之间的互动是这样的:
+
+1. 一些服务员接受顾客的订单。
+2. 服务员将订单交给了一些厨师。
+3. 厨师烹饪订单。
+4. 厨师将煮好的菜交给某个服务员(不一定是接受订单的同一位服务员)。
+5. 服务员把菜递给顾客。
+
+如何在代码中表示这个流程?
+
+```
+package main
+
+import (
+ "fmt"
+ "math/rand"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int) {
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+}
+
+func cookOrlder(ordlerId int) {
+ chef := getChef()
+ fmt.Printf("%s is cooking orlder number %v\n ", chef, ordlerId)
+}
+func bringOrlder(ordlerId int) {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+}
+func main() {
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ takeOrlder(orlderId)
+ cookOrlder(orlderId)
+ bringOrlder(orlderId)
+ }
+}
+
+```
+
+假设我们有**N**个客户,那么我们将以线性方式一个一个地为客户服务。服务员**X**将接受顾客 1 的订单,将其交给某位厨师**Y。**主厨**Y**会做这道菜,然后交给服务员**Z。**服务员**Z**将把这道菜带给顾客 1。然后顾客 2、3…… **N**也会发生同样的过程。
+
+##### **disadvantage**
+
+如果很多顾客大约在同一时间到达餐厅,那么他们中的很多人将不得不等待甚至将他们的订单交给服务员。目前,餐厅无法充分发挥其员工(服务员和厨师)的潜力。换句话说,使用此策略将无法很好地扩展或在更短的时间内为大量客户提供服务。
+
+```
+//results are ...
+
+Waiter 3 has taken orlder number 0
+Chef 1 is cooking orlder number 0
+ Waiter 3 has brought dishes for orlder number 0
+Waiter 3 has taken orlder number 1
+Chef 2 is cooking orlder number 1
+ Waiter 1 has brought dishes for orlder number 1
+Waiter 2 has taken orlder number 2
+Chef 3 is cooking orlder number 2
+ Waiter 2 has brought dishes for orlder number 2
+Waiter 1 has taken orlder number 3
+Chef 3 is cooking orlder number 3
+ Waiter 2 has brought dishes for orlder number 3
+Waiter 1 has taken orlder number 4
+Chef 3 is cooking orlder number 4
+ Waiter 2 has brought dishes for orlder number 4
+Waiter 3 has taken orlder number 5
+Chef 1 is cooking orlder number 5
+ Waiter 3 has brought dishes for orlder number 5
+Waiter 3 has taken orlder number 6
+Chef 3 is cooking orlder number 6
+ Waiter 3 has brought dishes for orlder number 6
+Waiter 1 has taken orlder number 7
+Chef 3 is cooking orlder number 7
+ Waiter 2 has brought dishes for orlder number 7
+```
+
+
+
+##### solution?
+
+```
+// solution 1
+
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int) {
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+}
+
+func cookOrlder(ordlerId int) {
+ chef := getChef()
+ fmt.Printf("%s is cooking orlder number %v\n ", chef, ordlerId)
+}
+func bringOrlder(ordlerId int) {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup) {
+
+ takeOrlder(orlderId)
+ cookOrlder(orlderId)
+ bringOrlder(orlderId)
+ wg.Done()
+
+}
+func main() {
+ var wg sync.WaitGroup
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ wg.Add(1)
+ go DealOrlder(orlderId, &wg)
+ }
+ wg.Wait()
+
+}
+// result1 are ...
+Waiter 3 has taken orlder number 7
+Chef 1 is cooking orlder number 7
+ Waiter 3 has brought dishes for orlder number 7
+Waiter 3 has taken orlder number 0
+Chef 2 is cooking orlder number 0
+ Waiter 1 has brought dishes for orlder number 0
+Waiter 3 has taken orlder number 4
+Chef 1 is cooking orlder number 4
+ Waiter 3 has brought dishes for orlder number 4
+Waiter 2 has taken orlder number 5
+Chef 1 is cooking orlder number 5
+ Waiter 3 has brought dishes for orlder number 5
+Waiter 2 has taken orlder number 2
+Waiter 2 has taken orlder number 6
+Chef 1 is cooking orlder number 6
+ Waiter 3 has brought dishes for orlder number 6
+Waiter 2 has taken orlder number 3
+Chef 3 is cooking orlder number 3
+ Waiter 3 has brought dishes for orlder number 3
+Chef 3 is cooking orlder number 2
+ Waiter 1 has brought dishes for orlder number 2
+Waiter 3 has taken orlder number 1
+Chef 3 is cooking orlder number 1
+ Waiter 2 has brought dishes for orlder number 1
+```
+
+```
+//solution 2
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int, wg *sync.WaitGroup) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+ wg.Done()
+}
+
+func cookOrlder(ordlerId int, wg *sync.WaitGroup) {
+
+ chef := getChef()
+ fmt.Printf("%s is cooking orlder number %v\n ", chef, ordlerId)
+ wg.Done()
+}
+func bringOrlder(ordlerId int, wg *sync.WaitGroup) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+ wg.Done()
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup) {
+ wg.Add(3)
+ go takeOrlder(orlderId, wg)
+ go cookOrlder(orlderId, wg)
+ go bringOrlder(orlderId, wg)
+
+}
+func main() {
+ var wg sync.WaitGroup
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ DealOrlder(orlderId, &wg)
+ }
+ wg.Wait()
+
+}
+
+// results are ...
+Waiter 3 has brought dishes for orlder number 7
+Waiter 3 has brought dishes for orlder number 3
+Waiter 3 has taken orlder number 4
+Chef 2 is cooking orlder number 4
+ Waiter 1 has brought dishes for orlder number 4
+Waiter 2 has taken orlder number 5
+Chef 3 is cooking orlder number 5
+ Waiter 2 has brought dishes for orlder number 5
+Waiter 1 has taken orlder number 6
+Chef 3 is cooking orlder number 6
+ Waiter 2 has brought dishes for orlder number 6
+Chef 1 is cooking orlder number 3
+ Waiter 3 has taken orlder number 7
+Chef 2 is cooking orlder number 7
+ Chef 1 is cooking orlder number 2
+ Waiter 3 has taken orlder number 2
+Waiter 3 has brought dishes for orlder number 2
+Waiter 1 has taken orlder number 0
+Chef 3 is cooking orlder number 0
+ Waiter 1 has taken orlder number 3
+Waiter 3 has brought dishes for orlder number 0
+Chef 3 is cooking orlder number 1
+ Waiter 2 has taken orlder number 1
+Waiter 3 has brought dishes for orlder number 1
+```
+
+##### **new problem?**
+
+```
+ //Chef 1 is cooking orlder number 2
+ //Waiter 3 has taken orlder number 2
+
+ //也就是说:有时某个特定的订单甚至在服务员拿走之前就已经做好了!或者订单甚至在烹饪或拿走之前就已交付!虽然现在服务员和厨师同时工作,但是点菜、煮熟和带回来的顺序应该是固定的(拿->煮->带)
+```
+
+##### **new solution?**
+
+```
+//厨师在收到某个服务员的订单之前不应开始准备订单
+```
+
+- 需要同步不同 `goroutine` 之间的通信
+- 厨师在收到某个服务员的订单之前不应开始准备订单
+- 服务员在收到厨师的订单之前不应交付订单
+- 通道本质上类似于消息队列
+- 创建两个通道。一种用于厨师和服务员之间的互动,他们接受顾客的订单并将其交付给厨师。
+- 另一个是厨师和服务员之间的互动,他们将准备好的菜肴送到顾客手中。
+
+```
+// solution1
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+ "time"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int, wg *sync.WaitGroup, canTakedOrlders chan int, done chan bool) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+ canTakedOrlders <- ordlerId
+ wg.Done()
+ select {
+ case <-done:
+ fmt.Println("case done return")
+ return
+
+ }
+}
+
+func cookOrlder(wg *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int, done chan bool) {
+
+ for ordlerId := range canCookedOrlders {
+
+ chef := getChef()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", chef, ordlerId)
+ canBringedrlders <- ordlerId
+ wg.Done()
+ }
+
+ select {
+ case <-done:
+ fmt.Println("case done return")
+ return
+
+ }
+
+}
+func bringOrlder(wg *sync.WaitGroup, canBringedrlders chan int, done chan bool) {
+
+ for ordlerId := range canBringedrlders {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+ wg.Done()
+ }
+ select {
+ case <-done:
+ fmt.Println("case done return")
+ return
+
+ }
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup, done chan bool) {
+ wg.Add(3)
+
+ canCookedOrlders := make(chan int)
+ canBringedrlders := make(chan int)
+ go takeOrlder(orlderId, wg, canCookedOrlders, done)
+ go cookOrlder(wg, canCookedOrlders, canBringedrlders, done)
+ go bringOrlder(wg, canBringedrlders, done)
+
+}
+func main() {
+ start := time.Now()
+
+ var wg sync.WaitGroup
+ done := make(chan bool)
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ DealOrlder(orlderId, &wg, done)
+ }
+
+ wg.Wait()
+ fmt.Println("wg wait over")
+ done <- true
+ stop := time.Now()
+ fmt.Printf("Time waste %v \n", stop.Sub(start))
+}
+
+// results are
+Waiter 3 has taken orlder number 0
+Chef 3 has brought dishes for orlder number 0
+Waiter 3 has brought dishes for orlder number 0
+Waiter 2 has taken orlder number 1
+Waiter 1 has taken orlder number 4
+Chef 2 has brought dishes for orlder number 4
+Waiter 3 has taken orlder number 2
+Chef 1 has brought dishes for orlder number 1
+Waiter 2 has brought dishes for orlder number 4
+Waiter 1 has taken orlder number 5
+Chef 2 has brought dishes for orlder number 2
+Waiter 3 has brought dishes for orlder number 1
+Chef 1 has brought dishes for orlder number 5
+Waiter 2 has brought dishes for orlder number 5
+Waiter 3 has taken orlder number 7
+Waiter 3 has taken orlder number 6
+Chef 3 has brought dishes for orlder number 6
+Waiter 3 has brought dishes for orlder number 6
+Chef 3 has brought dishes for orlder number 7
+Waiter 3 has brought dishes for orlder number 7
+Waiter 1 has brought dishes for orlder number 2
+Waiter 1 has taken orlder number 3
+Chef 3 has brought dishes for orlder number 3
+Waiter 2 has brought dishes for orlder number 3
+wg wait over
+Time waste 236.574µs
+
+```
+
+```
+// solution2
+
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+ "time"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int, wg *sync.WaitGroup, canTakedOrlders chan int) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+ canTakedOrlders <- ordlerId
+ wg.Done()
+
+}
+
+func cookOrlder(wg *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+
+ for ordlerId := range canCookedOrlders {
+
+ chef := getChef()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", chef, ordlerId)
+ canBringedrlders <- ordlerId
+ wg.Done()
+ }
+
+}
+func bringOrlder(wg *sync.WaitGroup, canBringedrlders chan int) {
+
+ for ordlerId := range canBringedrlders {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+ wg.Done()
+ }
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup) {
+ wg.Add(3)
+
+ canCookedOrlders := make(chan int)
+ canBringedrlders := make(chan int)
+ go takeOrlder(orlderId, wg, canCookedOrlders)
+ go cookOrlder(wg, canCookedOrlders, canBringedrlders)
+ go bringOrlder(wg, canBringedrlders)
+
+}
+func main() {
+ start := time.Now()
+
+ var wg sync.WaitGroup
+
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ DealOrlder(orlderId, &wg)
+ }
+
+ wg.Wait()
+ fmt.Println("wg wait over")
+
+ stop := time.Now()
+ fmt.Printf("Time waste %v \n", stop.Sub(start))
+}
+
+//results are
+Waiter 3 has taken orlder number 2
+Chef 1 has brought dishes for orlder number 2
+Waiter 3 has brought dishes for orlder number 2
+Waiter 2 has taken orlder number 3
+Chef 1 has brought dishes for orlder number 3
+Waiter 2 has brought dishes for orlder number 3
+Waiter 3 has taken orlder number 4
+Chef 2 has brought dishes for orlder number 4
+Waiter 1 has taken orlder number 6
+Chef 2 has brought dishes for orlder number 6
+Waiter 3 has brought dishes for orlder number 6
+Waiter 1 has taken orlder number 0
+Waiter 2 has brought dishes for orlder number 4
+Waiter 3 has taken orlder number 5
+Chef 1 has brought dishes for orlder number 5
+Waiter 3 has taken orlder number 1
+Waiter 3 has taken orlder number 7
+Waiter 3 has brought dishes for orlder number 5
+Chef 3 has brought dishes for orlder number 0
+Waiter 1 has brought dishes for orlder number 0
+Chef 3 has brought dishes for orlder number 1
+Waiter 3 has brought dishes for orlder number 1
+Chef 3 has brought dishes for orlder number 7
+Waiter 2 has brought dishes for orlder number 7
+wg wait over
+Time waste 223.942µs
+
+```
+
+```
+// solution3
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+ "time"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int, wg *sync.WaitGroup, canTakedOrlders chan int) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+ canTakedOrlders <- ordlerId
+ wg.Done()
+
+}
+
+func cookOrlder(wg *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+
+ for ordlerId := range canCookedOrlders {
+
+ chef := getChef()
+ fmt.Printf("%s is cooked dishes for orlder number %v\n", chef, ordlerId)
+ canBringedrlders <- ordlerId
+ wg.Done()
+ }
+
+}
+func bringOrlder(wg *sync.WaitGroup, canBringedrlders chan int) {
+
+ for ordlerId := range canBringedrlders {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+ wg.Done()
+ }
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+ wg.Add(3)
+
+ go takeOrlder(orlderId, wg, canCookedOrlders)
+ go cookOrlder(wg, canCookedOrlders, canBringedrlders)
+ go bringOrlder(wg, canBringedrlders)
+
+}
+func main() {
+ start := time.Now()
+
+ var wg sync.WaitGroup
+ canCookedOrlders := make(chan int)
+ canBringedrlders := make(chan int)
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ DealOrlder(orlderId, &wg, canCookedOrlders, canBringedrlders)
+ }
+
+ wg.Wait()
+ fmt.Println("wg wait over")
+
+ stop := time.Now()
+ fmt.Printf("Time waste %v \n", stop.Sub(start))
+}
+
+// results are
+Waiter 1 has taken orlder number 1
+Chef 3 is cooked dishes for orlder number 1
+Waiter 2 has taken orlder number 3
+Chef 3 is cooked dishes for orlder number 3
+Waiter 2 has brought dishes for orlder number 3
+Waiter 2 has taken orlder number 5
+Waiter 1 has taken orlder number 6
+Waiter 2 has taken orlder number 7
+Chef 1 is cooked dishes for orlder number 6
+Chef 3 is cooked dishes for orlder number 5
+Waiter 1 has brought dishes for orlder number 5
+Chef 3 is cooked dishes for orlder number 7
+Waiter 3 has brought dishes for orlder number 7
+Waiter 3 has brought dishes for orlder number 6
+Waiter 2 has taken orlder number 4
+Chef 3 is cooked dishes for orlder number 4
+Waiter 3 has brought dishes for orlder number 4
+Waiter 3 has taken orlder number 0
+Chef 3 is cooked dishes for orlder number 0
+Waiter 1 has brought dishes for orlder number 0
+Waiter 1 has brought dishes for orlder number 1
+Waiter 3 has taken orlder number 2
+Chef 3 is cooked dishes for orlder number 2
+Waiter 2 has brought dishes for orlder number 2
+wg wait over
+Time waste 187.335µs
+```
+
+```
+// solution4
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+ "time"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int, wg *sync.WaitGroup, canTakedOrlders chan int) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+ canTakedOrlders <- ordlerId
+ wg.Done()
+
+}
+
+func cookOrlder(wg *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+
+ for ordlerId := range canCookedOrlders {
+
+ chef := getChef()
+ fmt.Printf("%s is cooked dishes for orlder number %v\n", chef, ordlerId)
+ canBringedrlders <- ordlerId
+ wg.Done()
+ }
+
+}
+func bringOrlder(wg *sync.WaitGroup, canBringedrlders chan int) {
+
+ for ordlerId := range canBringedrlders {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+ wg.Done()
+ }
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup, wg2 *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+ wg.Add(3)
+ go takeOrlder(orlderId, wg, canCookedOrlders)
+ go cookOrlder(wg, canCookedOrlders, canBringedrlders)
+ go bringOrlder(wg, canBringedrlders)
+ wg2.Done()
+
+}
+func main() {
+ start := time.Now()
+
+ var wg sync.WaitGroup
+ var wg2 sync.WaitGroup
+ canCookedOrlders := make(chan int)
+ canBringedrlders := make(chan int)
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ wg2.Add(1)
+ DealOrlder(orlderId, &wg, &wg2, canCookedOrlders, canBringedrlders)
+ }
+
+ wg.Wait()
+ wg2.Wait()
+ fmt.Println("wg wait over")
+
+ stop := time.Now()
+ fmt.Printf("Time waste %v \n", stop.Sub(start))
+}
+//results are
+Waiter 3 has taken orlder number 0
+Waiter 2 has taken orlder number 6
+Chef 2 is cooked dishes for orlder number 6
+Waiter 3 has taken orlder number 4
+Waiter 3 has taken orlder number 2
+Chef 2 is cooked dishes for orlder number 2
+Waiter 1 has brought dishes for orlder number 2
+Waiter 1 has taken orlder number 1
+Chef 2 is cooked dishes for orlder number 1
+Chef 3 is cooked dishes for orlder number 4
+Waiter 3 has taken orlder number 3
+Chef 1 is cooked dishes for orlder number 0
+Waiter 1 has brought dishes for orlder number 4
+Waiter 3 has taken orlder number 5
+Chef 3 is cooked dishes for orlder number 5
+Waiter 3 has brought dishes for orlder number 5
+Waiter 3 has brought dishes for orlder number 1
+Waiter 3 has brought dishes for orlder number 0
+Waiter 1 has taken orlder number 7
+Chef 1 is cooked dishes for orlder number 7
+Waiter 3 has brought dishes for orlder number 7
+Waiter 2 has brought dishes for orlder number 6
+Chef 3 is cooked dishes for orlder number 3
+Waiter 2 has brought dishes for orlder number 3
+wg wait over
+Time waste 187.19µs
+```
+
+```
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+ "time"
+)
+
+func getWaiter() string {
+ waiters := []string{
+ "Waiter 1",
+ "Waiter 2",
+ "Waiter 3",
+ }
+ idx := rand.Intn(len(waiters))
+ return waiters[idx]
+
+}
+
+func getChef() string {
+ chefs := []string{
+ "Chef 1",
+ "Chef 2",
+ "Chef 3",
+ }
+ inx := rand.Intn(len(chefs))
+ return chefs[inx]
+
+}
+func takeOrlder(ordlerId int, wg *sync.WaitGroup, canTakedOrlders chan int) {
+
+ waiter := getWaiter()
+ fmt.Printf("%s has taken orlder number %v\n", waiter, ordlerId)
+ canTakedOrlders <- ordlerId
+ wg.Done()
+
+}
+
+func cookOrlder(wg *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+
+ for ordlerId := range canCookedOrlders {
+
+ chef := getChef()
+ fmt.Printf("%s is cooked dishes for orlder number %v\n", chef, ordlerId)
+ canBringedrlders <- ordlerId
+ wg.Done()
+ }
+
+}
+func bringOrlder(wg *sync.WaitGroup, canBringedrlders chan int) {
+
+ for ordlerId := range canBringedrlders {
+ waiter := getWaiter()
+ fmt.Printf("%s has brought dishes for orlder number %v\n", waiter, ordlerId)
+
+ wg.Done()
+ }
+
+}
+func DealOrlder(orlderId int, wg *sync.WaitGroup, wg2 *sync.WaitGroup, canCookedOrlders chan int, canBringedrlders chan int) {
+ wg.Add(3)
+ go takeOrlder(orlderId, wg, canCookedOrlders)
+ go cookOrlder(wg, canCookedOrlders, canBringedrlders)
+ go bringOrlder(wg, canBringedrlders)
+ wg.Wait()
+ wg2.Done()
+
+}
+func main() {
+ start := time.Now()
+
+ var wg sync.WaitGroup
+ var wg2 sync.WaitGroup
+ canCookedOrlders := make(chan int)
+ canBringedrlders := make(chan int)
+ for orlderId := 0; orlderId < 8; orlderId++ {
+ wg2.Add(1)
+ go DealOrlder(orlderId, &wg, &wg2, canCookedOrlders, canBringedrlders)
+ }
+
+ wg2.Wait()
+ fmt.Println("wg wait over")
+
+ stop := time.Now()
+ fmt.Printf("Time waste %v \n", stop.Sub(start))
+}
+
+//Results are ...
+Waiter 3 has taken orlder number 7
+Chef 1 is cooked dishes for orlder number 7
+Waiter 3 has brought dishes for orlder number 7
+Waiter 3 has taken orlder number 0
+Chef 2 is cooked dishes for orlder number 0
+Waiter 1 has brought dishes for orlder number 0
+Waiter 2 has taken orlder number 5
+Chef 3 is cooked dishes for orlder number 5
+Waiter 2 has brought dishes for orlder number 5
+Waiter 1 has taken orlder number 6
+Chef 2 is cooked dishes for orlder number 6
+Waiter 1 has brought dishes for orlder number 6
+Waiter 3 has taken orlder number 2
+Chef 2 is cooked dishes for orlder number 2
+Waiter 3 has brought dishes for orlder number 2
+Waiter 1 has taken orlder number 1
+Chef 3 is cooked dishes for orlder number 1
+Waiter 3 has brought dishes for orlder number 1
+Waiter 3 has taken orlder number 3
+Chef 3 is cooked dishes for orlder number 3
+Waiter 1 has brought dishes for orlder number 3
+Waiter 3 has taken orlder number 4
+Chef 3 is cooked dishes for orlder number 4
+Waiter 2 has brought dishes for orlder number 4
+wg wait over
+Time waste 272.353µs
+```
+
+## Example 2
+
+##### Qustion --Rate limit
+
+每当调用 Web 服务的某个特定 API 时,它都会在内部对某个外部服务进行多个并发调用。衍生出多个 goroutine 来服务这个请求。外部服务可以是任何东西(可能是 AWS 服务)。如果您的服务在很短的时间内(在 API 的单次调用中)向外部服务发送了太多请求,则外部服务可能会限制(速率限制)的服务!
+
+注意:我们在这里使用并发是因为我们希望尽可能降低 API 的延迟。如果没有并发,我们将不得不迭代地调用外部服务。
+
+##### solution-- prevent this throttling
+
+假设我们的服务当前对我们的 API 的每个请求都对外部服务进行**N次调用。**我们将在这里进行批处理。我们将使用一个 goroutine 池或 M 个 goroutine 的工作池**(** M **<** N **,** M **=** N **/** X **)**,而不是分离**N个 goroutine。**现在在任何特定时刻,我们最多向外部服务发送**M**个请求而不是**N**。
+
+工作池将监听作业频道。并发工作人员将从通道(队列)的前端获取工作(调用外部服务)以执行。一旦工作人员完成工作,它会将结果发送到结果通道(队列)。一旦完成所有工作,我们将计算并将最终结果发送回 API 的调用者。
+
+```
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func Worker(workerIndex int, jobs chan int, result chan int) {
+
+ for jobIndex := range jobs {
+ fmt.Println("Worker", workerIndex, " has started job", jobIndex)
+ fmt.Println("Worker is doing job....")
+ time.Sleep(1 * time.Second)
+ fmt.Println("Worker", workerIndex, " has finished job", jobIndex)
+ result <- jobIndex * 2
+ }
+
+}
+func API(numJobs int) int {
+ jobs := make(chan int, numJobs)
+ defer close(jobs)
+
+ result := make(chan int, numJobs)
+ defer close(result)
+ workNums := 10
+ //处理工作
+ for workIndex := 0; workIndex < workNums; workIndex++ {
+ go Worker(workIndex, jobs, result)
+ }
+ //工作进入
+ for jobIdx := 0; jobIdx < numJobs; jobIdx++ {
+ jobs <- jobIdx
+ }
+ //读取结果
+ sum := 0
+ for jobIdx := 0; jobIdx < numJobs; jobIdx++ {
+ select {
+ case temp := <-result:
+ fmt.Println(temp, "is pushed in result channel ")
+ sum = sum + temp
+
+ }
+
+ }
+
+ return sum
+}
+func main() {
+ fmt.Println("API excute result is ", API(5))
+ fmt.Println("API excute result is ", API(10))
+ fmt.Println("API excute result is ", API(15))
+
+}
+
+//result
+Worker 9 has started job 0
+Worker is doing job....
+Worker 0 has started job 1
+Worker is doing job....
+Worker 1 has started job 2
+Worker is doing job....
+Worker 6 has started job 3
+Worker is doing job....
+Worker 5 has started job 4
+Worker is doing job....
+Worker 5 has finished job 4
+8 is pushed in result channel
+Worker 0 has finished job 1
+2 is pushed in result channel
+Worker 9 has finished job 0
+0 is pushed in result channel
+Worker 1 has finished job 2
+4 is pushed in result channel
+Worker 6 has finished job 3
+6 is pushed in result channel
+API excute result is 20
+Worker 9 has started job 0
+Worker is doing job....
+Worker 6 has started job 2
+Worker is doing job....
+Worker 7 has started job 3
+Worker 8 has started job 5
+Worker 4 has started job 1
+Worker 0 has started job 6
+Worker is doing job....
+Worker is doing job....
+Worker is doing job....
+Worker 5 has started job 4
+Worker 2 has started job 7
+Worker is doing job....
+Worker is doing job....
+Worker 1 has started job 9
+Worker is doing job....
+Worker 3 has started job 8
+Worker is doing job....
+Worker is doing job....
+Worker 4 has finished job 1
+2 is pushed in result channel
+Worker 2 has finished job 7
+Worker 0 has finished job 6
+Worker 1 has finished job 9
+Worker 8 has finished job 5
+Worker 7 has finished job 3
+Worker 9 has finished job 0
+Worker 3 has finished job 8
+14 is pushed in result channel
+12 is pushed in result channel
+18 is pushed in result channel
+10 is pushed in result channel
+6 is pushed in result channel
+0 is pushed in result channel
+16 is pushed in result channel
+Worker 6 has finished job 2
+4 is pushed in result channel
+Worker 5 has finished job 4
+8 is pushed in result channel
+API excute result is 90
+Worker 7 has started job 7
+Worker is doing job....
+Worker 8 has started job 8
+Worker is doing job....
+Worker 2 has started job 3
+Worker is doing job....
+Worker 1 has started job 2
+Worker is doing job....
+Worker 6 has started job 6
+Worker is doing job....
+Worker 5 has started job 4
+Worker is doing job....
+Worker 0 has started job 0
+Worker is doing job....
+Worker 4 has started job 5
+Worker is doing job....
+Worker 3 has started job 1
+Worker is doing job....
+Worker 9 has started job 9
+Worker is doing job....
+Worker 7 has finished job 7
+Worker 4 has finished job 5
+Worker 3 has finished job 1
+Worker 3 has started job 12
+Worker is doing job....
+Worker 5 has finished job 4
+Worker 5 has started job 13
+Worker is doing job....
+Worker 1 has finished job 2
+Worker 1 has started job 14
+Worker is doing job....
+Worker 0 has finished job 0
+Worker 2 has finished job 3
+Worker 7 has started job 10
+Worker is doing job....
+Worker 4 has started job 11
+Worker 9 has finished job 9
+14 is pushed in result channel
+10 is pushed in result channel
+2 is pushed in result channel
+8 is pushed in result channel
+4 is pushed in result channel
+0 is pushed in result channel
+6 is pushed in result channel
+Worker is doing job....
+Worker 8 has finished job 8
+18 is pushed in result channel
+16 is pushed in result channel
+Worker 6 has finished job 6
+12 is pushed in result channel
+Worker 5 has finished job 13
+26 is pushed in result channel
+Worker 3 has finished job 12
+24 is pushed in result channel
+Worker 4 has finished job 11
+22 is pushed in result channel
+Worker 7 has finished job 10
+20 is pushed in result channel
+Worker 1 has finished job 14
+28 is pushed in result channel
+API excute result is 210
+```
+
+
+
+假设我们的服务当前对我们的 API 的每个请求都对外部服务进行**N次调用。**我们将在这里进行批处理。我们将使用一个 goroutine 池或 M 个 goroutine 的工作池**(** M **<** N **,** M **=** N **/** X **)**,而不是分离**N个 goroutine。**现在在任何特定时刻,我们最多向外部服务发送**M**个请求而不是**N**。
+
+工作池将监听作业频道。并发工作人员将从通道(队列)的前端获取工作(调用外部服务)以执行。一旦工作人员完成工作,它会将结果发送到结果通道(队列)。一旦完成所有工作,我们将计算并将最终结果发送回 API 的调用者。
diff --git a/_posts/2022-04-17-test-markdown.md b/_posts/2022-04-17-test-markdown.md
new file mode 100644
index 000000000000..f5424e0acf4a
--- /dev/null
+++ b/_posts/2022-04-17-test-markdown.md
@@ -0,0 +1,270 @@
+---
+layout: post
+title: Go的推迟、恐慌和恢复
+subtitle: 一个defer语句推动一个函数调用到列表中。保存的调用列表在周围函数返回后执行。
+tags: [golang]
+---
+## go的推迟、恐慌和恢复
+
+> 一个**defer语句**推动一个函数调用到列表中。**保存的调用列表在周围函数返回后执行。**
+
+### **使用场景:Defer语句通常用于~~简化~~执行各种清理操作的函数**
+
+举个例子:
+
+```
+func CopyFile(dstName, srcName string) (written int64, err error) {
+ src, err := os.Open(srcName)
+ if err != nil {
+ return
+ }
+
+ dst, err := os.Create(dstName)
+ if err != nil {
+ return
+ }
+
+ written, err = io.Copy(dst, src)
+ dst.Close()
+ src.Close()
+ return
+}
+//这有效,但有一个错误。如果对 os.Create 的调用失败,该函数将返回而不关闭源文件,但是可以通过在第二个return语句之前调用src.Close 来解决,但是如果函数更加的复杂,那么这个问题将不会轻易的被注意到,更加优雅的做法是,打开文件之后,我们在第一个return语句之后,(因为一旦返回,证明打开失败,就不需要关闭文件了)执行defer src.Close()来延迟关闭文件,它将会在第二个os.Create()语句失败之后,第二个语句return 语句返回之后执行关闭。
+//这也验证了那句话:一个defer语句推动一个函数调用的列表,保存的函数调用的列表,会在(周围)函数返回之后执行!!!这个周围二字要慢慢体会,很精辟!!
+
+func CopyFile(dstName, srcName string) (written int64, err error) {
+ src, err := os.Open(srcName)
+ if err != nil {
+ return
+ }
+ defer src.Close()
+
+ dst, err := os.Create(dstName)
+ if err != nil {
+ return
+ }
+ defer dst.Close()
+
+ return io.Copy(dst, src)
+}
+
+
+Defer 语句允许我们在打开每个文件后立即考虑关闭它,保证无论函数中有多少个 return 语句,文件都将被关闭。
+```
+
+### **defer 语句的行为是直接且可预测的。有三个简单的规则:**
+
+#### 1.*在计算 defer 语句时计算延迟函数的参数。*
+
+```
+func a() {
+ i := 0
+ defer fmt.Println(i)
+ i++
+ return
+}
+```
+
+
+
+#### 2.*延迟的函数调用在周围函数返回后以后进先出的顺序执行*。
+
+```
+func b() {
+ for i := 0; i < 4; i++ {
+ defer fmt.Print(i)
+ }
+}
+此函数打印“3210”:
+```
+
+
+
+#### 3.*延迟函数可以读取并分配给返回函数的命名返回值。*
+
+```
+func c() (i int) {
+ defer func() { i++ }()
+ return 1
+}
+//在此示例中,延迟函数 在周围函数返回后增加返回值 i 。因此,此函数返回 2
+```
+
+**这样方便修改函数的错误返回值;我们很快就会看到一个例子。**
+
+
+
+### **Panic**是一个内置函数,它停止普通的控制流并开始*恐慌*
+
+> 也就是说:当一个函数F内部调用panic时,这个函数F的执行将停止,但是F中任何的延迟执行的函数将正常执行,然后F返回给它的调用者。对于调用者而言,F的行为就像是调用panic.这个过程继续向上堆栈,直到当前的`goroutine`中所有的函数返回。此时程序崩溃。恐慌可以通过直接调用恐慌来启动。他们可能是由运行时的错误引起:例如数组访问越界。
+
+
+
+### **Recover**是一个内置函数,可以重新控制恐慌的 `goroutine`
+
+> 值得注意的是:Recover只在延迟调用的函数中有用,这个是为什么呢?
+>
+> 因为对于正常执行期间,调用recovery函数只会返回一个nil并且没有其他影响。但是如果当前的`goroutine `处于恐慌时,调用`recovery`,`recovery `将捕获给予`goroutine `恐慌的值,并且恢复正常执行。
+>
+> 以下是一个演示恐慌和延迟机制的例子:
+
+```
+package main
+
+import "fmt"
+
+func main() {
+ f()
+ fmt.Println("Returned normally from f.")
+}
+
+func f() {
+ defer func() {
+ if r := recover(); r != nil {
+ //r := recover()就是捕获引起恐慌的值,在根据这个值的空与否来进行进一步的操作。
+ fmt.Println("Recovered in f", r)
+ }
+ }()
+ fmt.Println("Calling g.")
+ g(0)
+ fmt.Println("Returned normally from g.")
+}
+
+
+
+func g(i int) {
+ if i > 3 {
+ fmt.Println("Panicking!")
+ panic(fmt.Sprintf("%v", i))
+ }
+ defer fmt.Println("Defer in g", i)
+ fmt.Println("Printing in g", i)
+ g(i + 1)
+}
+
+
+
+猜测输出:
+Calling g.
+Printing in g", 0
+Printing in g", 1
+Printing in g", 2
+Printing in g", 3
+Panicking!
+Returned normally from g.
+Defer in g", 3
+Defer in g", 2
+Defer in g", 1
+Defer in g", 0
+Returned normally from f
+Recovered in f 4
+
+//判断错误是因为:延迟执行的打印语句
+defer func() {
+ if r := recover(); r != nil {
+ //r := recover()就是捕获引起恐慌的值,在根据这个值的空与否来进行进一步的操作。
+ fmt.Println("Recovered in f", r)
+ }
+ }()
+ 个人认为这些语句是在f 里面,所以要在main函数返回后执行所以要在Returned normally from f.这个语句之后,目前还未得到解决。
+
+
+
+
+
+实际输出:
+
+Calling g.
+Printing in g 0
+Printing in g 1
+Printing in g 2
+Printing in g 3
+Panicking!
+Defer in g 3
+Defer in g 2
+Defer in g 1
+Defer in g 0
+Recovered in f 4
+Returned normally from f.
+
+如果我们从 f 中删除延迟函数,恐慌不会恢复并到达 goroutine 调用堆栈的顶部,终止程序。这个修改后的程序为:
+package main
+
+import "fmt"
+
+func main() {
+ f()
+ fmt.Println("Returned normally from f.")
+}
+
+func f() {
+
+ fmt.Println("Calling g.")
+ g(0)
+ fmt.Println("Returned normally from g.")
+}
+
+
+
+func g(i int) {
+ if i > 3 {
+ fmt.Println("Panicking!")
+ panic(fmt.Sprintf("%v", i))
+ }
+ defer fmt.Println("Defer in g", i)
+ fmt.Println("Printing in g", i)
+ g(i + 1)
+}
+
+
+
+这个修改后的程序将输出:
+
+Calling g.
+Printing in g 0
+Printing in g 1
+Printing in g 2
+Printing in g 3
+Panicking!
+Defer in g 3
+Defer in g 2
+Defer in g 1
+Defer in g 0
+panic: 4
+panic PC=0x2a9cd8
+[stack trace omitted]
+
+与我们捕获恐慌数据不同的是:我们看到,当我们不调用recover来捕获引起的数据时 ,程序就会奔溃,不会继续往下执行,并且会抛出引起恐慌的数据,和错误提示,让主函数停下来。
+```
+
+
+
+有关**panic**和**recovery**的真实示例,请参阅Go 标准库中的[json 包](https://golang.org/pkg/encoding/json/)。它使用一组递归函数对接口进行编码。如果在遍历值时发生错误,则调用 panic 将堆栈展开到顶级函数调用,该函数调用从 panic 中恢复并返回适当的错误值(参见 encodeState 类型的 'error' 和 'marshal' 方法在[encode.go 中](https://golang.org/src/pkg/encoding/json/encode.go))。
+
+Go 库中的约定是,即使包在内部使用 panic,其外部 API 仍会显示明确的错误返回值。
+
+### *defer 的其他用途*——释放互斥锁
+
+```
+mu.Lock()
+defer mu.Unlock()
+
+//个人觉得在并发编程那一章这个defer关键字释放互斥锁的功能还是很强大的!!!
+
+```
+
+### *defer 的其他用途*——打印页脚
+
+```
+printHeader()
+defer printFooter()
+```
+
+
+
+
+
+### 吐血总结:
+
+> defer 语句为控制流提供了一种不寻常而且强大的机制。
+
diff --git a/_posts/2022-04-18-test-markdown.md b/_posts/2022-04-18-test-markdown.md
new file mode 100644
index 000000000000..6645677191a6
--- /dev/null
+++ b/_posts/2022-04-18-test-markdown.md
@@ -0,0 +1,128 @@
+---
+layout: post
+title: LRU 实现(层层剖析)
+subtitle: 采用 hashmap+ 双向链表
+tags: [LRU]
+---
+
+# LRU 实现(层层剖析)
+
+> **我们需要频繁的去调整首尾元素的位置。而双向链表的结构,刚好满足这一点**
+
+### 采用 hashmap+ 双向链表
+
+首先,我们定义一个 `LinkNode` ,用以存储元素。因为是双向链表,自然我们要定义 `pre` 和 `next`。同时,我们需要存储下元素的 `key` 和 `value` 。`val` 大家应该都能理解,关键是为什么需要存储 `key`?举个例子,比如当整个cache 的元素满了,此时我们需要删除 map 中的数据,需要通过 `LinkNode` 中的`key` 来进行查询,否则无法获取到 `key`。
+
+```go
+type LinkNode struct {
+ key, val
+ pre, next *LinkNode
+}
+```
+
+现在有了 LinkNode ,自然需要一个 Cache 来存储所有的 Node。我们定义 cap 为 cache 的长度,m用来存储元素。head 和 tail 作为 Cache 的首尾。
+
+```
+type LRUCache struct {
+ m map[int]*LinkNode
+ cap int
+ head, tail *LinkNode
+}
+```
+
+接下来我们对整个 Cache 进行初始化。在初始化 head 和 tail 的时候将它们连接在一起。
+
+```
+ func Constructor(capacity int) LRUCache {
+ head := &LinkNode{0, 0, nil, nil}
+ tail := &LinkNode{0, 0, nil, nil}
+ head.next = tail
+ tail.pre = head
+ return LRUCache{make(map[int]*LinkNode), capacity, head, tail}
+
+}
+```
+
+
+
+现在我们已经完成了 Cache 的构造,剩下的就是添加它的 API 了。因为 Get 比较简单,我们先完成Get 方法。这里分两种情况考虑,如果没有找到元素,我们返回 -1。如果元素存在,我们需要把这个元素移动到首位置上去。
+
+```
+func (this *LRUCache) Get(key int) int {
+ head := this.head
+ cache := this.m
+ if v, exist := cache[key]; exist {
+ v.pre.next = v.next
+ v.next.pre = v.pre
+ v.next = head.next
+ head.next.pre = v
+ v.pre = head
+ head.next = v
+ return v.val
+ } else {
+ return -1
+ }
+}
+
+```
+
+大概就是下面这个样子(假若 2 是我们 get 的元素)
+
+我们很容易想到这个方法后面还会用到,所以将其抽出。
+1
+
+```
+func (this *LRUCache) AddNode(node *LinkNode) {
+ head := this.head
+ //从当前位置删除
+ node.pre.next = node.next
+ node.next.pre = node.pre
+ //移动到首位置
+ node.next = head.next
+ head.next.pre = node
+ node.pre = head
+ head.next = node
+}
+
+func (this *LRUCache) Get(key int) int {
+ cache := this.m
+ if v, exist := cache[key]; exist {
+ this.MoveToHead(v)
+ return v.val
+ } else {
+ return -1
+ }
+}
+```
+
+
+
+```
+func (this *LRUCache) Put(key int, value int) {
+ head := this.head
+ tail := this.tail
+ cache := this.m
+ //假若元素存在
+ if v, exist := cache[key]; exist {
+ //1.更新值
+ v.val = value
+ //2.移动到最前
+ this.MoveToHead(v)
+ } else {
+ //TODO
+ v := &LinkNode{key, value, nil, nil}
+ v.next = head.next
+ if len(cache) == this.cap {
+ //删除最后元素
+ delete(cache, tail.pre.key)
+ tail.pre.pre.next = tail
+ tail.pre = tail.pre.pre
+ }
+ v.pre = head
+ head.next.pre = v
+ head.next = v
+ cache[key] = v
+ }
+}
+```
+
diff --git a/_posts/2022-04-20-test-markdown.md b/_posts/2022-04-20-test-markdown.md
new file mode 100644
index 000000000000..82f79954d40d
--- /dev/null
+++ b/_posts/2022-04-20-test-markdown.md
@@ -0,0 +1,264 @@
+---
+layout: post
+title: 传统网站的请求响应过程
+subtitle: 引入CDN之后 用户访问经历
+tags: [网络]
+---
+## 传统网站的请求响应过程
+
+1.输入网站的域名
+
+2.浏览器向本地的DNS服务器发出解析域名的请求
+
+3.本地的DNS服务器如果有该域名的解析结果,直接返回给浏览器该结果
+
+4.如果本地的服务器没有对于该域名的解析结果的缓存,就会迭代的向整个DNS服务器发出请求解析该域名。总会有一个DNS服务器解析该域名,然后获得该域名对应的解析结果,获得相应的解析结果后就会把解析结果发送到对应的浏览器。
+
+5.浏览器获得的解析结果,就是该域名对应的服务设备的IP地址
+
+6.浏览器获得IP地址后才能进行标准的TCP握手连接,建立TCP连接
+
+7.建立TCP连接之后,浏览器发出HTTP请求
+
+8.那个对应的IP设备(服务器)相应浏览器的请求,就是把浏览器想要的内容发送给浏览器
+
+9.再经过标准的TCP挥手流程,断开TCP连接
+
+
+
+## 引入CDN之后 用户访问经历
+
+1. 还是先经过本地DNS服务器进行解析,如果本地的DNS服务器没有相应的域名缓存,那么就会把继续解析的权限给CNAME指CDN专用的DNS服务器。
+2. CDN的DNS服务器将**全局负载均衡的设备**的IP地址返回给浏览器
+3. 浏览器向这个全局负载均衡的设备发出URL访问请求。
+4. 全局负载均衡的设备根据用户IP地址以及用户的请求,把用户的请求转发到 **用户所属的区域内的负载均衡的设备**
+
+**也就是说*全局负载设备*会选择 距离用户较近的 *区域负载均衡设备***
+
+> 区域负载均衡设备,选择一个最优的缓存服务器的节点,然后把缓存服务器节点得到的缓存服务器的IP地址返回给全局负载均衡设备。这个全局负载均衡设备把从(缓存服务器节点得到的缓存服务器的IP地址)返回给用户
+
+区域负载均衡设备还干了什么呢?
+
+- 根据用户的IP判断哪个节点服务器距离用户最近
+- 根据用户请求的URL判断哪个节点服务器有用户想要的东西
+- 查询各个节点,判断哪个节点服务器有服务的能力
+
+全局负载均衡设备干了什么?
+
+- 把从区域负载均衡设备那里得到的可以提供服务的服务器的IP地址发送给用户。
+- 然后用户向这个IP地址对应的服务器发出请求,这个服务器响应用户请求,把用户想要的东西传给用户。如果这个缓存服务器并没有用户想要的内容,那么这个服务器就会像它的上一级缓存服务器请求内容,直至到网站的源服务器。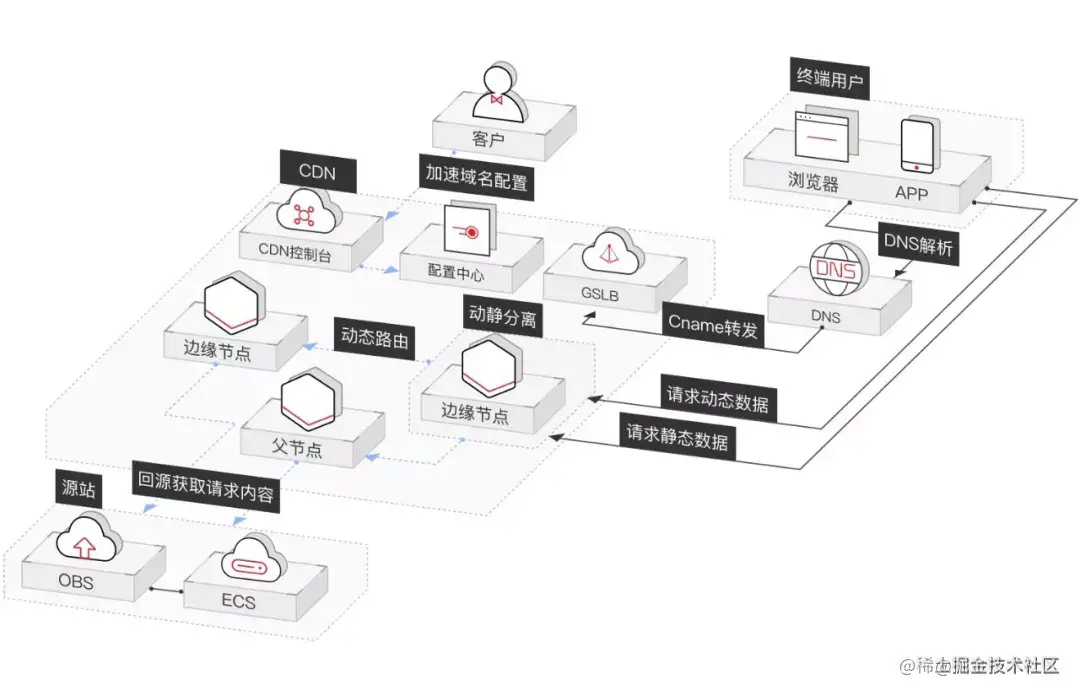
+
+
+
+# Amazon Web Services (AWS)
+
+Amazon Web Services (AWS) 是全球最全面、应用最广泛的云平台
+
+> 无论我们接触的是什么行业,教育,医疗,金融,我们的业务都要基于安全,可靠的运行,且成本要符合个人的需求的应用程序。Amazon Web Services (AWS)提供——互联网访问的一整套云计算服务,帮助我们创建和运行这些应用程序。在AWS提供了计算服务,存储服务,数据库服务,使得企业无需大量的资本投资就可以使用大量的IT资源。
+>
+> AWS几乎可以提供传统数据中心可以提供的一切数据服务。不过AWS所有的服务都是**按需付费**的。无前期资本付出。
+>
+> 在AWS可以找到**高持久的存储服务**,**低延迟的数据库**,**以及一套应用程序开发工具**只需在使用时付费。
+>
+> **以低经营成本提供强大资源**
+>
+> **容量规划也变得更加简单**在传统的数据中心中启动新的应用程序不至于冒险。准备太多的服务器,会浪费大量的金钱和时间。准备太少的服务器,客户体验不好。有**弹性添加和移出**的能力后,应用程序可以扩大以满足应用需求,也可以迅速缩小以节省成本。
+>
+> 让开发人员专注与为客户提供差异化的价值,而不必搬动堆栈服务器。成功的实验可以很快投产,免于失败带来的损害。
+>
+> AWS在多个地区帮助企业服务客户,不用费时,费力的进行地域扩展。
+>
+>
+
+> 云计算就是在互联网上以按需付费的方式提供计算服务
+>
+> 而不是管理本地存储设备上的文件和服务。
+>
+> 云计算有两种类型的模型,部署模型和服务模型
+
+部署模型
+
+- **公共云**
+
+ 云基础设施(一辆云公共汽车)通过互联网向公共提供,这辆公共汽车由云服务提供商拥有。
+
+- **私有云**
+
+ (一辆私有汽车),云基础设施由一个组织独家运营。
+
+- **混合云**
+
+ (一辆出租车)**公共云**和**私有云**的组合
+
+服务模型
+
+
+
+> 不久前,一家公司的所有 IT 系统都在本地,而云只是天空中的白色蓬松物。
+
+- **IASS ** (基础设施即服务)
+
+基于云的服务,为存储、网络和虚拟化等服务按需付费。
+
+IaaS 业务提供按需付费存储、网络和虚拟化等服务。
+
+IaaS 为用户提供基于云的本地基础设施替代方案,因此企业可以避免投资昂贵的现场资源。**IaaS 交付:**通过互联网。
+
+维护本地 IT 基础架构成本高昂且劳动强度大。
+
+它通常需要对物理硬件进行大量初始投资,然后您可能需要聘请外部 IT 承包商来维护硬件并保持一切正常工作和保持最新状态。
+
+aaS 的另一个优势是将基础设施的控制权交还给您。
+
+您不再需要信任外部 IT 承包商;如果您愿意,您可以自己访问和监督 IaaS 平台(无需成为 IT 专家)。
+
+**用户只需为服务器的使用付费,从而为他们节省了投资物理硬件的成本(以及相关的持续维护)。**
+
+
+
+- **PASS**(平台即服务)
+
+互联网上可用的硬件和软件工具。
+
+IaaS 业务提供按需付费存储、网络和虚拟化等服务。
+
+IaaS 为用户提供基于云的本地基础设施替代方案,因此企业可以避免投资昂贵的现场资源。
+
+PaaS 主要由构建软件或应用程序的开发人员使用。
+
+PaaS 解决方案为开发人员提供了**创建独特、可定制软件的平台**。
+
+PaaS 供应商通过 Internet 提供硬件和软件工具,人们使用这些工具来开发应用程序。PaaS 用户往往是开发人员。
+
+这意味着开发人员在创建应用程序时无需从头开始,从而为他们节省大量时间(和金钱)来编写大量代码。
+
+对于想要创建独特应用程序而又不花大钱或承担所有责任的企业来说,PaaS 是一种流行的选择。这有点像**租用场地进行表演与建造场地进行表演之间的区别。**场地保持不变,但您在该空间中创造的东西是独一无二的。
+
+PaaS 允许开发人员专注于应用程序开发的创造性方面,而不是管理软件更新或安全补丁等琐碎任务。他们所有的时间和脑力都将用于创建、测试和部署应用程序。
+
+**PaaS 非电子商务示例:**
+
+PaaS 的一个很好的例子是[AWS Elastic Beanstalk](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/Welcome.html)。这些服务大部分都可以用作 IaaS,大多数使用 AWS 的公司都会挑选他们需要的服务。然而,管理多个不同的服务对用户来说很快就会变得困难和耗时。这就是 AWS Elastic Beanstalk 的用武之地:它作为基础设施服务之上的另一层,**自动处理容量预置**、**负载平衡**、**扩展和应用程序运行状况监控的细节。**
+
+您需要做的就是上传和维护您的应用程序。
+
+- **SASS**(软件即服务)。
+
+ SaaS 平台通过互联网向用户提供软件,通常按月支付订阅费。使用[SaaS](https://learn.g2crowd.com/what-is-saas),您无需在您的计算机(或任何计算机)上安装和运行软件应用程序。当您在线登录您的帐户时,一切都可以通过互联网获得。您通常可以随时从任何设备访问该软件(只要有互联网连接)。
+
+ 其他使用该软件的人也是如此。您的所有员工都将拥有适合其访问级别的个性化登录。
+
+ 当您希望应用程序以最少的输入平稳可靠地运行时,SaaS 平台是理想的选择。
+
+可通过互联网通过第三方获得的软件。
+
+- **内部部署**:与您的企业安装在同一建筑物中的软件。
+
+
+
+**IaaS、PaaS 和 SaaS 之间有什么区别?**
+
+- 在托管定制应用程序以及提供通用数据中心用于数据存储方面,IaaS 可为您提供最大的灵活性。
+- PaaS 通常构建在 IaaS 平台之上,以减少对系统管理的需求。它使您可以专注于应用程序开发而不是基础架构管理。
+- SaaS 提供即用型、开箱即用的解决方案,可满足特定业务需求(例如网站或电子邮件)。大多数现代 SaaS 平台都是基于 IaaS 或 PaaS 平台构建的。
+
+
+
+
+
+## **AWS ELB ALB NLB 关联与区别**
+
+弹性负载均衡器、应用程序负载均衡器和网络负载均衡器。
+
+### 共同特征
+
+让我们先来看看这三种负载均衡器的共同点。
+
+显然,所有 AWS 负载均衡器都将传入请求分发到多个目标,这些目标可以是 EC2 实例或 Docker 容器。它们都实现了健康检查,用于检测不健康的实例。它们都具有高可用性和弹性(用 AWS 的说法:它们根据工作负载在几分钟内向上和向下扩展)。
+
+TLS 终止也是所有三个都可用的功能,它们都可以是面向互联网的或内部的。最后,ELB、ALB 和 NLB 都将有用的指标导出到 CloudWatch,并且可以将相关信息记录到 CloudWatch Logs。
+
+#### 经典负载均衡器
+
+此负载均衡器通常缩写为 ELB,即 Elastic Load Balancer,因为这是它在 2009 年首次推出时的名称,并且是唯一可用的负载均衡器类型。如果这让更容易理解,它可以被认为是一个 Nginx 或 HAProxy 实例。
+
+ELB 在第 4 层 (TCP) 和第 7 层 (HTTP) 上都工作,并且是唯一可以在 EC2-Classic 中工作的负载均衡器,以防您有一个非常旧的 AWS 账户。此外,它是唯一支持应用程序定义的粘性会话 cookie 的负载均衡器;相反,ALB 使用自己的 cookie,您无法控制它。
+
+在第 7 层,ELB 可以终止 TLS 流量。它还可以重新加密到目标的流量,只要它们提供 SSL 证书(自签名证书很好,顺便说一句)。这提供了端到端加密,这是许多合规计划中的常见要求。或者,可以将 ELB 配置为验证目标提供的 TLS 证书以提高安全性。
+
+ELB 有很多限制。例如,它与在 Fargate 上运行的 EKS 容器不兼容。此外,它不能在每个实例上转发多个端口上的流量,也不支持转发到 IP 地址——它只能转发到显式 EC2 实例或 ECS 或 EKS 中的容器。最后,ELB 不支持 websocket;但是,您可以通过使用第 4 层来解决此限制。
+
+要在 us-east-1 区域运行 ELB,每 ELB 小时 0.025 美元 + 每 GB 流量 0.008 美元。
+
+AWS 不鼓励使用 ELB,而是支持其较新的负载均衡器。诚然,在极少数情况下使用 ELB 会更好。通常,在这些情况下您根本没有选择。例如,您的工作负载可能仍在[EC2-Classic](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-classic-platform.html)上运行,或者您需要负载均衡器使用您自己的粘性会话 cookie,在这种情况下,ELB 将是您唯一可用的选项。负载平衡的下一步
+
+2016 年,AWS 推出了 Elastic Load Balancing 第 2 版,它由两个产品组成:Application Load Balancer (ALB) 和 Network Load Balancer (NLB)。它们都使用相似的架构和概念。
+
+最重要的是,它们都使用“目标群体”的概念,这是重定向的一个附加级别。可以这样概念化。侦听器接收请求并决定(基于广泛的规则)将请求转发到哪个目标组。然后,目标组将请求路由到实例、容器或 IP 地址。目标组通过决定如何拆分流量和对目标执行健康检查来管理目标。
+
+ALB 和 NLB 都可以将流量转发到 IP 地址,这允许它们在 AWS 云之外拥有目标(例如:本地服务器或托管在另一个云提供商上的实例)。
+
+现在让我们深入研究这两个提议。
+
+#### 应用程序负载均衡器
+
+应用程序负载均衡器 (ALB) 仅适用于第 7 层 (HTTP)。它具有广泛的基于主机名、路径、查询字符串参数、HTTP 方法、HTTP 标头、源 IP 或端口号的传入请求的路由规则。相比之下,ELB 只允许基于端口号的路由。此外,与 ELB 不同,ALB 可以将请求路由到单个目标上的多个端口。此外,ALB 可以将请求路由到 Lambda 函数。
+
+ALB 的一个非常有用的特性是它可以配置为返回固定响应或重定向。因此,您不需要服务器来执行这些基本任务,因为它都嵌入在 ALB 本身中。同样非常重要的是,ALB 支持 HTTP/2 和 websockets。
+
+ALB 进一步支持[服务器名称指示 (SNI)](https://www.cloudflare.com/learning/ssl/what-is-sni/),这允许它为许多域名提供服务。(相比之下,ELB 只能服务一个域名)。但是,可以附加到 ALB 的证书数量是有限制的,[即 25 个证书](https://aws.amazon.com/blogs/aws/new-application-load-balancer-sni/)加上默认证书。
+
+ALB 的一个有趣特性是它支持通过多种方法进行用户身份验证,包括 OIDC、SAML、LDAP、Microsoft AD 以及 Facebook 和 Google 等知名社交身份提供商。这可以帮助您将应用程序的用户身份验证部分卸载到负载均衡器。
+
+#### 网络负载均衡器
+
+网络负载均衡器 (NLB) 仅在第 4 层工作,可以处理 TCP 和 UDP,以及使用 TLS 加密的 TCP 连接。它的主要特点是它具有非常高的性能。此外,它使用静态 IP 地址,并且可以分配弹性 IP — 这对于 ALB 和 ELB 是不可能的。
+
+NLB 原生保留 TCP/UDP 数据包中的源 IP 地址;相比之下,ALB 和 ELB 可以配置为添加带有转发信息的附加 HTTP 标头,这些标头必须由您的应用程序正确解析。
+
+### 什么是 Amazon EC2?
+
+Amazon Elastic Compute Cloud (Amazon EC2) 在 Amazon Web Services (Amazon) 云中提供可扩展的计算容量。使用 Amazon EC2 可避免前期的硬件投入,因此您能够快速开发和部署应用程序。您可以使用 Amazon EC2 启动所需数量的虚拟服务器,配置安全性和联网以及管理存储。Amazon EC2 可让您扩展或缩减以处理需求变化或使用高峰,从而减少预测流量的需求。
+
+
+
+### 域名解析—— A 记录、CNAME 和 URL 转发区别
+
+- **域名A记录:A `(Address)` 记录是域名与 IP 对应的记录。**
+
+- **CNAME** 也是一个常见的记录类别,它是一个域名与域名的别名`( Canonical Name )`对应的记录。当 DNS 系统在查询 CNAME 左面的名称的时候,都会转向 CNAME 右面的名称再进行查询,一直追踪到最后的 PTR 或 A 名称,成功查询后才会做出回应,否则失败。这种记录允许将多个名字映射到同一台计算机。
+
+- **URL转发:** 如果没有一台独立的服务器(也就是没有一个独立的IP地址)或者还有一个域名 B ,想访问 A 域名时访问到 B 域名的内容,这时就可以通过 URL 转发来实现。
+
+ 转发的方式有两种:隐性转发和显性转发
+
+ 隐性转发的时候 [www.abc.com](http://www.abc.com/) 跳转到 [www.123.com](http://www.123.com/) 的内容页面以后,地址栏的域名并不会改变(仍然显示 [www.abc.com](http://www.abc.com/) )。网页上的相对链接都会显示 [www.abc.com](http://www.abc.com/)
+
+### A记录、CNAME和URL转发的区别
+
+- A记录 —— 映射域名到一个或多个IP。
+
+- CNAME——映射域名到另一个域名(子域名)。
+
+- URL转发——重定向一个域名到另一个 URL 地址,使用 HTTP 301状态码。
+
+注意,无论是 A 记录、CNAME、URL 转发,在实际使用时是全部可以设置多条记录的。比如:
+
+```
+ftp.example.com A记录到 IP1,而mail.example.com则A记录到IP2
+
+ftp.example.com CNAME到 ftp.abc.com,而mail.example.com则CNAME到mail.abc.com
+
+ftp.example.com 转发到 ftp.abc.com,而mail.example.com则A记录到mail.abc.com
+```
+
+### A记录、CNAME、URL适用范围
+
+了解以上区别,在应用方面:
+
+A记录——适应于独立主机、有固定IP地址
+
+CNAME——适应于虚拟主机、变动IP地址主机
+
+URL转发——适应于更换域名又不想抛弃老用户
+
diff --git a/_posts/2022-04-25-test-markdown.md b/_posts/2022-04-25-test-markdown.md
new file mode 100644
index 000000000000..73966618cb9c
--- /dev/null
+++ b/_posts/2022-04-25-test-markdown.md
@@ -0,0 +1,326 @@
+---
+layout: post
+title: Go 并发应用于数据管道
+subtitle: Go concurrency applied to data pipelines
+tags: [golang]
+---
+# Go concurrency applied to data pipelines
+
+> ## Go 并发应用于数据管道
+
+
+
+**一种不同的批处理方法,以及如何在使用 Go 并发模型的过程中增强数据管道的功能。**
+
+## 1.Introduction to pipelines
+
+> #### 管道简介
+
+应用于计算机科学领域的术语 ——**管道** 无非是一系列阶段,这些阶段接收数据,对该数据执行一些操作,并将处理后的数据作为结果传回。
+
+```
+ 接收数据—— 处理数据—— 返回数据
+```
+
+因此,在使用这种模式时
+
+- 可以通过添加/删除/修改阶段来封装每个阶段的逻辑并快速扩展功能
+
+- 每个阶段都变得易于测试
+- 更不必说通过使用并发来利用这个的巨大的好处
+
+想象一下,有机会在一家食品和 CPG 配送公司担任软件工程师,在那里是一个团队的一员,负责构建软件,将**零售商的产品可用性集成到主公司的应用程序中**。运行该集成后,用户能够以更少的缺货风险购买产品。
+
+- 为了完成这个功能,怎么 GoLang 中构建了这个“可用性引擎”呢?
+
+- 这个“可用性引擎”要怎么实现?
+
+- 这个“可用性引擎”要实现什么功能?
+
+ ```
+ // 1.应该提取了几个零售商的 CSV 文件,其中包含产品可用性信息
+ // 2.执行几个步骤来根据某些业务逻辑来丰富和过滤数据
+ // 3.流程结束后应该制作一个新的文件
+ // 4.所有的产品都将集成到公司的应用程序中供用户购买。
+
+ ```
+
+ 
+
+
+
+批量处理架构示例
+
+- 管道的第一阶段接收一组 CSV 行,将它们全部处理,然后将结果放入新批次(新的地图切片)中。
+- 相同的过程重复它的次数与管道实际具有的阶段数一样多,这种模式的特殊性在于,如果管道中的上一步尚未完成对整组行的处理,则下一个阶段都无法开始。如所见,它在概念上是一个批处理管道。
+- 为了加快和优化工作,我们开始在 CSV 文件级别使用并发,因此我们能够同时处理文件。这种方法非常适合我们,但没有我们常说的灵丹妙药……
+- 我偶然发现了一种奇妙的模式,即通过**使用通道来利用管道!!!!!!!!!!**
+
+## 2.A better approach for data pipelines: streams of data
+
+> #### 更好的数据管道方法:数据流
+
+在阶段之间使用批处理,这对我们来说已经足够了,但肯定还有其他选项更适合使其更高效。
+
+特别是我们谈论的是跨不同管道阶段的*流数据。*这实际上意味着**每个阶段一次接收和发出一个元素**,而**不是等待上一步的一整批结果来处理它们**。
+
+- **如果我们必须比较批处理和流式处理之间的内存占用,前者更大,因为每个阶段都必须制作一个新的等长映射切片来存储其计算结果。**
+- **相反,流式处理方法最终会一次接收和发送一个元素,因此内存占用量会降低到管道输入的大小**
+
+## Implementation example
+
+> #### 实现示例
+
+```
+// 第一阶段stream.UserIDs(done, userIDs...)将通过流式传输UserIDs值来为管道提供数据
+package stream
+
+//为了实现这一点,使用了一个生成器模式,它接收一个UserID切片(输入),并通过对其进行测距,开始将每个值推入一个通道(输出)。因此,返回的通道将依次成为下一阶段的输入。
+
+type UserID uint
+
+func UserIDs(done <-chan interface{}, uids ...UserID) <-chan UserID {
+ uidStream := make(chan UserID)
+ go func() {
+ defer close(uidStream)
+ for v := range uids {
+
+ select {
+ case <-done:
+ return
+ case uidStream <- UserID(v):
+ fmt.Printf("[In func UserIDs] UserID %v has been push in Stream Channel\n", v)
+
+ }
+
+ }
+
+ }()
+ return uidStream
+
+}
+```
+
+正因为如此,跨管道使用通道将允许我们安全地同时执行每个管道阶段,因为我们的输入和输出在并发上下文中是安全的。
+
+让我们看一下链上的以下阶段,其中基于来自第一阶段(生成器)的流数据,我们**获取实际的用户数据,过滤掉不活跃的用户**,用其配置文件丰富他们,最后将一些数据拆分为从整个聚合/过滤过程中制作一个普通对象。
+
+```
+// 获取用户并在频道上返回他们
+
+type User struct {
+ ID UserID
+ Username string
+ Email string
+ IsActive bool
+}
+
+func UserInput(done <-chan interface{}, uids <-chan UserID) <-chan User {
+ stream := make(chan User)
+ go func() {
+ defer close(stream)
+ for v := range uids {
+ user, err := getUser(v)
+ if err != nil {
+ fmt.Println("some error ocurred", err)
+ } else {
+ select {
+ case <-done:
+ fmt.Println("[case done ] return ")
+ return
+ case stream <- user:
+ fmt.Printf("[In func UserInput] UserID %#v has been push in Stream Channel\n", v)
+ default:
+ fmt.Println("channel blocking")
+
+ }
+
+ }
+
+ }
+ }()
+ return stream
+}
+// getUser 是一个虚拟的函数 用来模拟在处理数据时,对不同的数据进行不同的操作。
+
+func getUser(ID UserID) (User, error) {
+ username := fmt.Sprintf("username_%v", ID)
+ user := User{
+ ID: ID,
+ Username: username,
+ Email: fmt.Sprintf("%v@pipeliner.com"),
+ IsActive: true,
+ }
+
+ if ID%3 == 0 {
+ user.IsActive = false
+ }
+ return user, nil
+}
+
+```
+
+```
+// 过滤掉不活跃的用户
+func InactiveUsers(done <-chan interface{}, users <-chan User) <-chan User {
+ stream := make(chan User)
+ go func() {
+ defer close(stream)
+ for v := range users {
+ if v.IsActive == false {
+ fmt.Printf("[In func InactiveUsers] %#v has been filtered", v)
+ continue
+ }
+ select {
+ case <-done:
+ fmt.Println("[case done ] return ")
+ return
+ case stream <- v:
+ fmt.Printf("[In func InactiveUsers] User %#v has been push in Stream Channel\n", v)
+ }
+
+ }
+
+ }()
+
+ return stream
+}
+
+```
+
+```
+type ProfileID uint
+
+//将用户的配置文件聚合到有效负载
+
+//定义一个配置文件
+type Profile struct {
+ ID ProfileID
+ PhotoURL string
+}
+
+//将配置文件和用户聚合在一起
+type UserProfileAggregation struct {
+ User User
+ Profile Profile
+}
+
+type PlainStruct struct {
+ UserID UserID
+ ProfileID ProfileID
+ Username string
+ PhotoURL string
+}
+
+func ProfileInput(done <-chan interface{}, users <-chan User) <-chan UserProfileAggregation {
+ stream := make(chan UserProfileAggregation)
+ go func() {
+ defer close(stream)
+
+ for v := range users {
+ profile, err := getByUserID(v.ID)
+ if err != nil {
+ // TODO address errors in a better way
+ fmt.Println("some error ocurred")
+ p := UserProfileAggregation{
+ User: v,
+ Profile: profile}
+ select {
+ case <-done:
+ return
+ case stream <- p:
+ fmt.Println("[In func Profile] UserProfileAggregation has been inputed in channel")
+ }
+ }
+
+ }
+ }()
+ return stream
+}
+
+
+func getByUserID(uids UserID) (Profile, error) {
+ p := Profile{
+ ID: ProfileID(uint(uids) + 100),
+ PhotoURL: fmt.Sprintf("https://some-storage-url/%v-photo", uids),
+ }
+ return p, nil
+
+}
+
+```
+
+```
+//将有效负载转换为它的简化版本
+
+func UPAggToPlainStruct(done <-chan interface{}, upAggToPlainStruct <-chan UserProfileAggregation) <-chan PlainStruct {
+ stream := make(chan PlainStruct)
+ go func() {
+ defer close(stream)
+ for v := range upAggToPlainStruct {
+ p := v.ToPlainStruct()
+ select {
+ case <-done:
+ return
+ case stream <- p:
+ fmt.Println("[In func UPAggToPlainStruct ] PlainStruct has been pushed into channel")
+
+ }
+
+ }
+
+ }()
+ return stream
+}
+
+
+func (upa UserProfileAggregation) ToPlainStruct() PlainStruct {
+ return PlainStruct{
+ UserID: upa.User.ID,
+ ProfileID: upa.Profile.ID,
+ Username: upa.User.Username,
+ PhotoURL: upa.Profile.PhotoURL,
+ }
+}
+
+```
+
+```
+const maxUserID = 100
+
+func main() {
+ done := make(chan interface{})
+ defer close(done)
+ userIDs := make([]UserID, maxUserID)
+ for i := 1; i <= maxUserID; i++ {
+ userIDs = append(userIDs, UserID(i))
+ }
+ arg1 := UserInput(
+ done,
+ UserIDs(done, userIDs...),
+ )
+ arg2 := InactiveUsers(
+ done,
+ arg1,
+ )
+ arg3 := ProfileInput(
+ done,
+ arg2,
+ )
+ plainStructs := UPAggToPlainStruct(done, arg3)
+
+ for ps := range plainStructs {
+ fmt.Printf("[result] plain struct for UserID %v is: -> %v \n", ps.UserID, ps)
+ }
+}
+
+
+```
+
+我在各个阶段传递了一个*done chan 接口{} 。*这个是来做什么的?值得一提的是,goroutines 在运行时不会被垃圾回收,所以作为程序员,我们必须确保它们都是可抢占的。因此,通过这样做,我们不会泄漏任何 goroutine(我将在稍后的另一篇文章中写更多关于此的内容)并释放内存。*因此,只要关闭done*通道,就可以停止对管道的任何调用。这个动作将导致所有 spawn children 的 goroutines 的终止并清理它们。
+
+总而言之,在管道上的最新阶段之后,开始通过其输出通道将数据推出另一个例程.
+
+简而言之,如果我有机会解决与以前类似的问题,我肯定会采用这种模式,它不仅在内存占用方面性能更高,而且速度比使用批处理方法,因为我们可以同时处理数据。
+
+此外,我们还可以对管道进行许多其他操作,例如速率限制和扇入/扇出。这个主题将在后面继续学习,其想法是通过添加和组合更多的并发模式来不断迭代这个模式。
\ No newline at end of file
diff --git a/_posts/2022-05-18-test-markdown.md b/_posts/2022-05-18-test-markdown.md
new file mode 100644
index 000000000000..f0f053d93150
--- /dev/null
+++ b/_posts/2022-05-18-test-markdown.md
@@ -0,0 +1,55 @@
+---
+layout: post
+title: Linux环境变量设置文件
+subtitle:
+tags: [linux]
+---
+Linux环境变量设置文件
+/etc/profile 全局用户,应用于所有的Shell。
+/$HOME/.profile 当前用户,应用于所有的Shell。
+/etc/bash_bashrc 全局用户,应用于Bash Shell。
+~/.bashrc 局部当前,应用于Bash Sell。
+
+查找软件安装目录
+whereis mongodb
+
+查看PATH
+#echo $PATH 显示PATH设置。
+#env 显示当前用户变量。
+
+以添加mongodb server为列
+修改方法一:
+export PATH=/usr/local/mongodb/bin:$PATH
+//配置完后可以通过echo $PATH查看配置结果。
+生效方法:立即生效
+有效期限:临时改变,只能在当前的终端窗口中有效,当前窗口关闭后就会恢复原有的path配置
+用户局限:仅对当前用户
+
+
+修改方法二:
+通过修改.bashrc文件:
+vim ~/.bashrc
+//在最后一行添上:
+export PATH=/usr/local/mongodb/bin:$PATH
+生效方法:(有以下两种)
+1、关闭当前终端窗口,重新打开一个新终端窗口就能生效
+2、输入“source ~/.bashrc”命令,立即生效
+有效期限:永久有效
+用户局限:仅对当前用户
+
+修改方法三:
+通过修改profile文件:
+vim /etc/profile
+/export PATH //找到设置PATH的行,添加
+export PATH=/usr/local/mongodb/bin:$PATH
+生效方法:系统重启
+有效期限:永久有效
+用户局限:对所有用户
+
+修改方法四:
+通过修改environment文件:
+vim /etc/environment
+在PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"中加入“:/usr/local/mongodb/bin”
+生效方法:系统重启
+有效期限:永久有效
+用户局限:对所有用户
diff --git a/_posts/2022-05-20-test-markdown.md b/_posts/2022-05-20-test-markdown.md
new file mode 100644
index 000000000000..01ced95d785a
--- /dev/null
+++ b/_posts/2022-05-20-test-markdown.md
@@ -0,0 +1,358 @@
+---
+layout: post
+title: CQRS 架构模式
+subtitle: 使用 CQRS 架构模式优化数据访问
+tags: [架构]
+---
+
+# CQRS 架构模式
+
+> 使用 CQRS 架构模式优化数据访问
+
+## 1.CRUD系统
+
+> 围绕关系数据库构建而成的“创建(Create)、读取(Read)、更新(Update)、删除(Delete)”系统(即CRUD系统)
+
+我们平常最熟悉的就是三层架构,通常都是通过数据访问层来修改或者查询数据,一般修改和查询使用的是相同的实体。通过业务层来处理业务逻辑,将处理结果封装成DTO对象返回给控制层,再通过前端渲染。反之亦然。
+
+
+
+这里基本上是围绕关系数据库构建而成的“创建、读取、更新、删除”系统(即CRUD系统)此类系统在一些业务逻辑简单的项目中可能没有什么问题,但是随着系统逻辑变得复杂,用户增多,这种设计就会出现一些性能问题。
+
+### 存在的问题:
+
+对数据库进行读写分离。让**主数据库处理事务性的增、删、改操作**,让**从数据库处理查询操作**,然后主从数据库之间进行同步。
+
+- **为什么要分库、分表、读写分?**
+
+ 单表的数据量限制,当单表数据量到一定条数之后数据库性能会显著下降。
+
+ > 当一个订单单表突破两百G,且查询维度较多,即使通过增加了两个从库,优化索引,仍然存在很多查询不理想的情况。当大量抢购活动的开展,数据库就会达到瓶颈,应用只能通过限速、异步队列等对其进行保护。
+ >
+ > 对订单库进行垂直切分,将原有的订单库分为基础订单库、订单流程库等。 + >
+ > 垂直切分缓解了原来单集群的压力,但是在抢购时依然捉襟见肘。原有的订单模型已经无法满足业务需求,可以设计了一套新的统一订单模型,为同时满足C端用户、B端商户、客服、运营等的需求,通过用户ID和商户ID进行切分)同步到一个运营库。
+ >
+ >
+ >
+ > 垂直切分缓解了原来单集群的压力,但是在抢购时依然捉襟见肘。原有的订单模型已经无法满足业务需求,可以设计了一套新的统一订单模型,为同时满足C端用户、B端商户、客服、运营等的需求,通过用户ID和商户ID进行切分)同步到一个运营库。
+ >
+ >  + >
+ >
+
+- **切分策略**
+
+ 1. 查询切分
+ >
+ >
+
+- **切分策略**
+
+ 1. 查询切分 +
+ 将ID和库的Mapping关系记录在一个单独的库中。
+
+ 优点:ID和库的Mapping算法可以随意更改。
+
+ 缺点:引入额外的单点。
+
+ 2. 范围切分
+
+
+
+ 将ID和库的Mapping关系记录在一个单独的库中。
+
+ 优点:ID和库的Mapping算法可以随意更改。
+
+ 缺点:引入额外的单点。
+
+ 2. 范围切分
+
+  +
+ 比如按照时间区间或ID区间来切分。
+
+ 优点:单表大小可控,天然水平扩展。
+ 缺点:无法解决集中写入瓶颈的问题。
+
+ 3. Hash切分
+
+ 一般采用Mod来切分,下面着重讲一下Mod的策略。
+
+
+
+ 比如按照时间区间或ID区间来切分。
+
+ 优点:单表大小可控,天然水平扩展。
+ 缺点:无法解决集中写入瓶颈的问题。
+
+ 3. Hash切分
+
+ 一般采用Mod来切分,下面着重讲一下Mod的策略。
+
+  +
+ 方法1:32*32
+
+ 数据水平切分后我们希望是一劳永逸或者是易于水平扩展的,所以推荐采用mod 2^n这种一致性Hash。如果分库分表的方案是32*32的,即通过UserId后四位mod 32分到32个库中,同时再将UserId后四位Div 32 Mod 32将每个库分为32个表。共计分为1024张表。线上部署情况为8个集群(主从),每个集群4个库。
+
+ 方法2:32 * 32 * 32
+
+ 如果是32 * 32 * 32 (32个集群,32个库,32个表=32768个表)。
+
+ 方法3:单表容量达到瓶颈(或者1024已经无法满足)
+
+ 分库规则不变,单库里的表再进行裂变,当然,在目前订单这种规则下(用userId后四位 mod)还是有极限。
+
+
+
+ 4. 唯一ID方案
+
+ - 利用数据库自增ID
+
+ 优点:最简单。 缺点:单点风险、单机性能瓶颈。
+
+ - 利用数据库集群并设置相应的步长(Flickr方案)
+
+ 优点:高可用、ID较简洁。 缺点:需要单独的数据库集群。
+
+ - Twitter Snowflake
+
+ 优点:高性能高可用、易拓展。 缺点:需要独立的集群以及ZK。
+
+
+
+ 5. 带有业务属性的方案
+
+ \> 时间戳+用户标识码+随机数
+
+ 用户标识码即为用户ID的后四位,在查询的场景下,只需要订单号就可以匹配到相应的库表而无需用户ID,只取四位是希望订单号尽可能的短一些,并且评估下来四位已经足够。
+
+### 数据迁移
+
+数据库拆分一般是业务发展到一定规模后的优化和重构,为了支持业务快速上线,很难一开始就分库分表,垂直拆分还好办,改改数据源就搞定了,一旦开始水平拆分,数据清洗就是个大问题。
+
+#### 阶段1:
+
+
+
+ 方法1:32*32
+
+ 数据水平切分后我们希望是一劳永逸或者是易于水平扩展的,所以推荐采用mod 2^n这种一致性Hash。如果分库分表的方案是32*32的,即通过UserId后四位mod 32分到32个库中,同时再将UserId后四位Div 32 Mod 32将每个库分为32个表。共计分为1024张表。线上部署情况为8个集群(主从),每个集群4个库。
+
+ 方法2:32 * 32 * 32
+
+ 如果是32 * 32 * 32 (32个集群,32个库,32个表=32768个表)。
+
+ 方法3:单表容量达到瓶颈(或者1024已经无法满足)
+
+ 分库规则不变,单库里的表再进行裂变,当然,在目前订单这种规则下(用userId后四位 mod)还是有极限。
+
+
+
+ 4. 唯一ID方案
+
+ - 利用数据库自增ID
+
+ 优点:最简单。 缺点:单点风险、单机性能瓶颈。
+
+ - 利用数据库集群并设置相应的步长(Flickr方案)
+
+ 优点:高可用、ID较简洁。 缺点:需要单独的数据库集群。
+
+ - Twitter Snowflake
+
+ 优点:高性能高可用、易拓展。 缺点:需要独立的集群以及ZK。
+
+
+
+ 5. 带有业务属性的方案
+
+ \> 时间戳+用户标识码+随机数
+
+ 用户标识码即为用户ID的后四位,在查询的场景下,只需要订单号就可以匹配到相应的库表而无需用户ID,只取四位是希望订单号尽可能的短一些,并且评估下来四位已经足够。
+
+### 数据迁移
+
+数据库拆分一般是业务发展到一定规模后的优化和重构,为了支持业务快速上线,很难一开始就分库分表,垂直拆分还好办,改改数据源就搞定了,一旦开始水平拆分,数据清洗就是个大问题。
+
+#### 阶段1:
+
+ +
+- 数据库双写(事务成功以老模型为准),查询走老模型。
+
+#### 阶段2
+
+- 数据库双写(事务成功以老模型为准),查询走老模型。
+
+#### 阶段2 +
+#### 阶段3:
+
+#### 阶段3: +
+
+
+#### Tips:
+
+并非所有表都需要水平拆分,要看增长的类型和速度,水平拆分是大招,拆分后会增加开发的复杂度,不到万不得已不使用。在大规模并发的业务上,尽量做到**在线查询**和**离线查询**隔离,**交易查询**和**运营/客服查询隔离**。
+
+#### 本质:
+
+这只是从DB角度处理了读写分离,从业务或者系统层面上来说,读和写的逻辑仍然是存放在一起的,他们都是操作同一个实体对象。
+
+## 2. CQRS系统
+
+> Command Query Responsibility Segration
+
+命令(Command)处理和查询(Query)处理 (Responsibility )责任 分离(Segration)
+
+
+
+
+
+#### Tips:
+
+并非所有表都需要水平拆分,要看增长的类型和速度,水平拆分是大招,拆分后会增加开发的复杂度,不到万不得已不使用。在大规模并发的业务上,尽量做到**在线查询**和**离线查询**隔离,**交易查询**和**运营/客服查询隔离**。
+
+#### 本质:
+
+这只是从DB角度处理了读写分离,从业务或者系统层面上来说,读和写的逻辑仍然是存放在一起的,他们都是操作同一个实体对象。
+
+## 2. CQRS系统
+
+> Command Query Responsibility Segration
+
+命令(Command)处理和查询(Query)处理 (Responsibility )责任 分离(Segration)
+
+ +
+命令与查询两边可以用不同的架构实现,以实现CQ两端(即Command Side,简称C端;Query Side,简称Q端)的分别优化。两边所涉及到的实体对象也可以不同,从而继续演变成下面这样。
+
+
+
+命令与查询两边可以用不同的架构实现,以实现CQ两端(即Command Side,简称C端;Query Side,简称Q端)的分别优化。两边所涉及到的实体对象也可以不同,从而继续演变成下面这样。
+
+ +
+CQRS 作为一个**读写分离思想的架构**,在数据存储方面,也没有做过多的约束。所以 CQRS可以有不同层次的实现。
+
+#### CQRS 实现方式:
+
+###### 第一种实现:CQ 两端数据库共享,只是在上层代码上分离。
+
+好处是可以让我们的代码读写分离,更容易维护,而且不存在 CQ 两端的数据一致性问题。因为是共享一个数据库的。这种架构是非常实用的(也就是上面画的那种)
+
+###### 第二种实现:CQ 两端不仅代码分离,数据库也分离,然后Q端数据由C端同步过来
+
+同步方式有两种:同步或异步,如果需要 CQ 两端的强一致性,则需要用同步;如果能接受 CQ 两端数据的最终一致性,则可以使用异步。
+
+C端可以采用Event Sourcing(简称ES)模式,所有C端的最新数据全部用 Domain Event 表达即可。要查询显示用的数据,则从Q端的 ReadDB(关系型数据库)查询即可。
+
+###### 第一种CQRS 的简单实现:
+
+代码层面实现分离,数据库共享。
+
+CQRS 模式中,首先需要有 Command,这个 Command 命令会对应一个实体和一个命令的执行类。肯定有很多不同的 Command,那么还需要一个 CommandBus 来做命令的分发处理。
+
+假设有个用户管理模块,我要新增一个用户的信息。那么根据上文的分析,需要有个新增命令以及对应的用户实体(这个用户实体并不一定和数据库的订单实体完全对应)。
+
+- 首先先创建一个命令接口,接口内部是这个命令的处理方法。
+
+ ```
+ type Create interface{
+ Excute()
+ }
+ ```
+
+- 创建用户的新增命令
+
+ ```
+ type UserCreate struct{
+ account string
+ password string
+ }
+ func (u *UserCreate) Excute(){
+ //检验是否合法,为了防止恶意的新增用户的请求
+ //然后创建一个和数据库对应的model
+ //数据赋值
+ //插入到数据库当中
+ }
+ ```
+
+- 写好命令具体的执行逻辑之后,该命令的执行需要放到 CommandBus 中去执行
+
+ ```
+ type CommandBus struct{
+ }
+ func (b *CommandBus) DisPath( c Create){
+ c.Excute()
+ }
+ ```
+
+- Controller 层该如何去调用呢?
+
+ ```
+ //java实现
+ @PostMapping(value = "/getInfo")
+ public Object getOrderInfo(GetOrderInfoModel model) {
+ return getOrderInfoService.getOrderInfos(model);
+ }
+
+ @PostMapping(value = "/creat")
+ public Object createOrderInfo(CreateOrderModel model) {
+ return commandBus.dispatch(createOrderCommand, model);
+ }
+
+ ```
+
+ 查询和插入是不同的方式,插入走的是 `CommandBus` 分发到 `CreateOrderCommand` 去执行.
+
+ #### tips:
+
+ CQRS 是一种思想很简单清晰的设计模式,通过在业务上分离**操作**和**查询**来使得系统具有更好的可扩展性及性能,使得能够对系统的不同部分进行扩展和优化。在 CQRS 中,所有的涉及到对 DB 的操作都是通过发送 Command,然后特定的 Command 触发对应事件来完成操作,也可以做成异步的,主要看业务上的需求了。
+
+### 3.CQRS解决了什么问题
+
+当使用像 CRUD 这样的传统架构时,使用相同的数据模型来更新和查询数据库以获得大规模解决方案,最终可能会成为一种负担。例如:
+
+- 读取端点可以在查询端对不同的源执行多个查询,以返回具有不同形状的复杂 DTO 映射。我们已经知道映射可能会变得相当复杂
+- 在写入方面,模型可能会**实现多个复杂的业务规则**来**验证创建**和**更新操作。**
+- 我们可能希望以其他方式查询模型,可能将多条记录合并为一条,或者将**更多信息聚合**到当前在其域中不可用的模型,或者只是通过使用一些辅助字段来更改查询查看记录的方式作为一把钥匙。
+- 结果,我们围绕模型对象的 CRUD 服务开始做太多事情,并且随着它的增长变得最糟糕。
+
+### 4.CQRS模式
+
+CQRS 是*Command and Query Responsibility Segregation*
+
+它的主要目的是基于将数据操作(命令)与读取操作(查询)分离的简单思想。为了实现这一点,它将**读取**和**写入**分离到不同的模型中,使用命令进行创建/更新,并使用查询从它们中读取数据。
+
+
+
+如上图所示,您会注意到,每次在写入端创建/更新我们域的实例时,都会通过将事件推送到主题上来连接写入和读取世界的事件队列。然后,查询服务将从传入的事件中读取,对数据进行非规范化、丰富、切片和切块,以创建查询优化模型并将它们存储起来以供以后读取。
+
+特别是,重点在于**通过将事件溯源架构**添加到组合中来**利用 CQRS 模式**。当我们希望保持此流程具有明确的**关注点分离**、**异步**以及**利用适当的数据库引擎**以提高查询性能时(例如,用于写作的 SQL 数据库和用于在物化视图上查询操作的 NoSQL),它非常适合查询以避免昂贵的连接)
+
+除此之外,当我们使用事件溯源架构时,事件主题将成为我们的黄金数据源,因为它可以**随时用于存放整个事件集合**并**重现数据的当前状态**。这样我们就有可能从一开始就**异步读取队列**,并在系统进化时,或者读取模型必须改变时,从原始数据中生成一组新的**物化视图**。物化视图实际上是**数据的持久只读缓存**。
+
+分离世界的另一个好处是有机会分别扩展两者,从而减少锁争用。由于大多数复杂的业务逻辑都进入了写入模型。因此通过分离模型使它们更加灵活并简化了维护。
+
+##### 5.CQRS适用场合
+
+- 数据读取的性能必须与数据写入的性能分开进行微调,尤其是在读取次数远大于写入次数时。在这种情况下,您可以扩展读取模型,但仅在少数实例上运行写入模型。
+- 允许读取最终一致的数据。由于这种模式的**异步**性质。
+
+
+
+## DDD 不是什么?
+
+- DDD 不是一个软件框架。但是基于 DDD 思想的框架是存在的,比如 Axon,它是以 DDD 为**指导思想**,使用 Java 实现的一个微服务软件框架。
+- DDD 不是一种软件设计模式。它不是像工厂,单例这样子的设计模式。但是 DDD 思想中提出了**诸如资源库(Repository)之类的设计模式**。
+- DDD 不是一种系统架构模式。它不是像 MVC 之类的架构模式。但是 DDD 思想中提出了诸如事件溯源(Event Souring),读写隔离(Command Query Responsibility Segregation) 之类的架构模式。
+
+
+
+### 1.DDD 到底是什么?
+
+> 建模的方法论
+
+软件是服务于人类,为提高人类生产效率而产生的一种工具, 每一个软件都服务于某一个特定的领域。比如一个 CRM,它是以管理客户数据为核心,帮助商户与客户保持联系的工具。而软件的实质是计算机中**运行的代码**,如何**将抽象的代码更准确地映射到人类所关心的领域**中,这是软件开发者一直在探寻的话题.函数式编程(FP)还是面向对象编程(OOP)也好,都是为了帮助开发者开发出更贴近于领域中的软件模型。
+
+在传统的软件开发方法中,我们常常会遇到一系列影响软件质量的技术以及非技术问题:
+
+- 开发者热衷于技术,但缺乏设计和业务思考。开发人员在不完全了解业务需求的情况下,闭门造车,即使功能上线也无人问津。
+- 代码输入而非业务输入。技术人员对技术实现情有独钟,出现杀鸡焉用牛刀的情况。
+- 过于重视数据库。以数据库设计为中心,而非业务来进行开发,结果往往是,软件无法适应一直在变动的业务逻辑。
+
+**DDD 是一种设计思想,一种以领域(业务)为出发点,以解决软件建模复杂度为目的设计思想.就是建模的方法论。**
+
+### 2.DDD 的设计思想:战略和战术
+
+#### 战略设计
+
+##### 通用语言(Ubiquitous Language)
+
+开发人员习惯了使用技术术语,领域专家(领域专家在此泛指精通业务的专家,比如用户,客户等等)对技术术语毫不关心,于是造成了不可避免的沟通问题,一旦沟通出现问题,开发出来的软件便很难解决领域专家的真正痛点。通用语言是 DDD 思想的基石,它是开发人员和领域专家共同创建一套沟通语言,一套在团队中流行的,通用的沟通语言,团队的组员之间可使用**通用语言进行无障碍交流**。
+
+通用语言往往可以直接应用于代码中,它可以直接被写成一个类或者一个类的方法。
+
+```
+//开发一个购物车时,与其使用技术术语:
+Cart::create(): 创建一个购物车。
+Cart::updateStatus():更新购物车状态。
+Cart::remove():移除购物车。
+
+//贴近业务的通用语言:
+Cart::init(): 创建一个购物车。
+Cart::addItemToCart():添加商品。
+Cart::removeItemFromCart():移除商品。
+Cart::empty():清空购物车。
+//使用后者时,开发人员不用解释每一个类方法的意义,领域专家可以直接看懂每一个类方法的目的。开发人员甚至可以和领域专家坐在一起使用代码来打磨业务流程。
+```
+
+##### 限界上下文(Bounded Context)
+
+实现了通用语言自由以后,我们需要使用限界上下文来**规定每一套通用语言的使用边界**。限界上下文是语义和语境的边界,在其内的每一个元素都有自己特定的含义,也就是说**每一个概念在一个限界上下文中都是独一无二**,不可以出现一词多义的情况
+
+> 比如在一个购物车的限界上下文中,我们可以用 User 一词来代表购买商品的客户。
+>
+> 在一个注册系统中,我们可以用 User 一词指的是带有用户名和密码的账号。虽然词汇一样,但是在不同的限界上下文中,它们的含义不同。
+
+我们使用限界上下文和通用语言,对业务进行语言层面的拆分。**限界上下文为领域中的每一个元素赋予清晰的概念**。
+
+##### 子域(Subdomain)
+
+如果说限界上下文是对业务进行语言层面拆分的话,那么子域便是对业务进行商业价值的拆分。每一个商业都有自己的关注点,即便是看起来一样的电商平台,淘宝是**开放平台模式**,京东是**价值链整合模式**,一个明显的区别是,淘宝使用第三方物流而京东自建物流体系。那么作为一个开发人员,为何要关心看起来似乎与自己无关的商业模式呢?恰恰相反,只有当我们了解一个商业的结构时,才能开发出一个主次分明的系统来支撑一个商业的飞速发展。**子域**便是这样一个帮助我们**划分主次**的工具。
+
+有三种类型的子域:
+
+- **核心域(Core Domain)**:这是系统中需要最大投资的领域,它代表着整个商业的核心竞争力。我们需要花大量资源以及资源来打磨核心域,这关乎一个企业的存亡。比如京东的自建物流系统。
+- **支撑域(Supporting Domain)**:此领域并非一个企业的核心业务,但是核心域却离不开它,它可以采用外包定制方案实现。比如认证上下文,权限上下文。
+- **通用域(Generic Domain):**如果已有成熟的解决方案,通用域可以采购现成方案来,如果没有,也可以采用外包,在通用域上的投资应该是最小的。比如对于淘宝而言,物流便是其通用域。
+
+限界上下文和子域的关系众说纷纭,有专家提倡1:1,也有专家提倡1:N。个人比较提倡 1:1。
+
+##### 上下文映射(Context Mapping)
+
+在一个庞大的系统中,限界上下文之间必定存在一定的依赖关系。如何将一个上下文中的概念映射到另一个上下文中?我们使用上下文映射。以下是几种上下文映射的关系类型:
+
+- 合作关系(Partnership)
+- 共享内核(Shared Kernel)
+- 客户方-供应方开发(Customer-Supplier Development)
+- 遵奉者(Conformist)
+- 防腐层(Anticorruption Layer)
+- 开放主机服务(Open Host Service)
+- 发布语言(Published Language)
+- 另谋他路(SeparateWay)
+- 大泥球(Big Ball of Mud)
+
+#### 战术设计
+
+##### 实体(Entity)
+
+首先我们讲到的是,实体。
+
+实体是领域中独立事物的模型,每个实体都拥有一个唯一的标识符,比如 ID, UUID,Username 等等。大多数情况下,实体是可变的,它的状态会随着时间的迁移改变,不过,一个实体不一定必须可变。
+
+实体的最大的特征是它的个体性,唯一性。比如在一个简单的购物车上下文中,订单(Order) 便是一个实体,ID 是它的标识符,它的状态可以在提交(placed),确认(confirmed) 以及已退 (refunded) 之间变化。
+
+##### 值对象(Value Object)
+
+值对象是领域中用来描述,量化或者测量实体的模型。和实体不同,值对象没有唯一的标识符,两个对等的值对象是可以替换的。值对象具有不变性(Immutability),一旦创建以后,一个值对象的属性就定型了,不可更改。
+
+理解值对象的最直接的方法是,想象我们现实生活中的钞票,在日常生活中,甲的十块钱人民币和乙的十块钱人民币是可以对等交换的。在上文的购物车上下文中,金额(Money)便是一个值对象,金额由货币(currency)和数目(amount)
+
+##### 聚合(Aggregate)
+
+聚合是什么?聚合是上下文中对业务领域更精细的划分,每一个聚合保证自己的业务一致性。
+
+那么什么是业务不变性?业务不变性表示一个业务规则,该规则在业务领域中不可违背,必须保证其一致性。比如,在进行订单退款时,退款金额不可以超过已付金额。聚合的组成部分是实体和值对象,有时候也只有实体。为了保护聚合的业务一致性,每个聚合只可以通过某一个实体对其进行操作,该实体被称为聚合根。
+
+##### 领域事件(Domain Event)
+
+领域事件是通过通用语言分析出来的事件,与常见的事务事件不同的是它与业务息息相关,所以它的命名往往夹带业务名词,而不应该与数据库挂钩。比如购物车增添商品,对应的领域事件应该是 `ProductAddedToCart`, 而不是 `CartUpdated`。
+
+#### Tips
+
+DDD 还提供了诸如应用服务(Application Service),领域服务(Domain Service) 等战术设计,DDD 还提出了文章开头就提过的事件溯源,六边形等架构模式,在此我们将不一一介绍。
+
+DDD 的核心是从业务的角度为软件建立模型,其目的是打造更贴近业务的代码,能更直观的从代码理清业务流程。 然而实现 DDD 并非一日之举,它需要不断的实践,不断的打磨。
\ No newline at end of file
diff --git a/_posts/2022-06-14-test-markdown.md b/_posts/2022-06-14-test-markdown.md
new file mode 100644
index 000000000000..4387bc600344
--- /dev/null
+++ b/_posts/2022-06-14-test-markdown.md
@@ -0,0 +1,77 @@
+---
+layout: post
+title: 关于TCP滑动窗口和拥塞控制
+subtitle: 四次握手
+tags: [网络]
+---
+
+# 关于TCP滑动窗口和拥塞控制
+
+- TCP头部记录端口号,IP头部记录IP,以太网头部记录MAC地址
+
+- 一个TCP连接需要四个元组来表示是同一个连接(src_ip, src_port, dst_ip, dst_port)
+
+- 为什么TCP建立连接要三次握手?
+
+- - 通信的双方要互相通知对方自己的初始化的Sequence Number,用来判断之后发来的数据包的顺序。
+ - 通知——ACK 因此需要至少三次握手了
+
+- 建立连接时,SYN超时没收到ACK会重发,为了防止被恶意flood攻击,Linux下给了一个叫tcp_syncookies的参数
+
+- 关闭连接的四次握手
+
+ 
+
+- TIME_WAIT状态是为了等待确保对端也收到了ACK,否则对端还会重发FIN。
+
+- **滑动窗口(swnd,即真正的发送窗口) = min(拥塞窗口,通告窗口)**
+
+- **通告窗口**:即TCP头里的一个字段AdvertisedWindow,是**接收端告诉发送端自己还有多少缓冲区可以接收数据**。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
+
+- - 原则:快的发送方不能淹没慢的接收方
+
+ 
+
+ - 接收端在给发送端回ACK中会汇报自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
+
+ - 而发送方会根据这个窗口来控制发送数据的大小,以保证接收方可以处理。
+
+- **拥塞窗口**(Congestion Window简称cwnd):指某一源端数据流在一个RTT内可以最多发送的数据包数。
+
+- 拥塞控制主要是四个算法:**1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复**
+
+
+
+- **TCP的核心是拥塞控制,**目的是探测网络速度,保证传输顺畅
+
+- 慢启动:
+
+- - 初始化cwnd = 1,表明可以传一个MSS大小的数据(Linux默认2/3/4,google实验10最佳,国内7最佳)
+ - 每当收到一个ACK,cwnd++; 呈线性上升
+ - 因此,每个RTT(Round Trip Time,一个数据包从发出去到回来的时间)时间内发送的数据包数量翻倍,导致了每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
+ - ssthresh(slow start threshold)是上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
+
+- 拥塞避免算法:(当cwnd达到ssthresh时后,一般来说是65535byte)
+
+- - 收到一个ACK时,cwnd = cwnd + 1/cwnd
+ - 当每过一个RTT时,cwnd = cwnd + 1
+
+- 拥塞发生时:
+
+- - \1. 表现为RTO(Retransmission TimeOut)超时,重传数据包(反应比较强烈)
+
+ - - sshthresh = cwnd /2
+ - cwnd 重置为 1,进入慢启动过程
+
+ - \2. 收到第3个duplicate ACK时(从收到第一个重复ACK起,到收到第三个重复ACK止,窗口不做调整,即fast restransmit)
+
+ - - cwnd = cwnd /2
+ - sshthresh = cwnd
+ - 进入快速恢复算法——Fast Recovery
+
+- 快速恢复算法(执行完上述两个步骤之后):
+
+- - cwnd = sshthresh + 3 (MSS)
+ - 重传Duplicated ACKs指定的数据包
+ - 之后每收到一个duplicated Ack,cwnd = cwnd +1 (此时增窗速度很快)
+ - 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法
\ No newline at end of file
diff --git a/_posts/2022-06-15-test-markdown.md b/_posts/2022-06-15-test-markdown.md
new file mode 100644
index 000000000000..cf0a10e93dd5
--- /dev/null
+++ b/_posts/2022-06-15-test-markdown.md
@@ -0,0 +1,162 @@
+---
+layout: post
+title: Fork开源项目并提交PR
+subtitle: 以及关于 提交的pr `go fmt` check 不通过的问题:`Your branch is ahead of 'origin/master' by 1 commit.`
+tags: [开源]
+---
+# Fork开源项目并提交PR
+
+> 以及关于 提交的pr `go fmt` check 不通过的问题:`Your branch is ahead of 'origin/master' by 1 commit.`
+
+## 1 第一次提交pr的操作
+
+### 1.fork 目标仓库
+
+```
+https://github.com/apache/dubbo-go-pixiu.git
+```
+
+fork到自己的仓库
+
+```
+https://github.com/gongna-au/dubbo-go-pixiu.git
+```
+
+### 2.将`forked的`仓库clone到本地
+
+```
+git clone https://github.com/gongna-au/dubbo-go-pixiu.git
+```
+
+> 不是`要`fork的仓库,而是fork到自己账户的仓库
+
+### 3.切一个新的开发分支
+
+```
+git checkout -b my-feature
+```
+
+### 4.在该分支进行修改,添加代码
+
+### 5.将分支push到远程仓库
+
+```
+$ go mod tidy
+```
+
+```
+$ git add .
+```
+
+```
+$ git commit -m"add :new change"
+```
+
+```
+$ git push origin my-feature
+Counting objects: 3, done.
+Delta compression using up to 4 threads.
+Compressing objects: 100% (3/3), done.
+Writing objects: 100% (3/3), 288 bytes | 0 bytes/s, done.
+Total 3 (delta 2), reused 0 (delta 0)
+remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
+To git@github.com:oyjjpp/hey.git
+ f3676ef..d7a9529 my-feature -> my-feature
+
+```
+
+### 6.为fork项目配置远程仓库
+
+当前项目一般只有自己仓库的源,当fork开源仓库的源码时,如果要提交PR,首先需要将上游仓库的源配置到本地版本控制中,这样既可以提交本地仓库代码到上游仓库,同样可以拉取最新上游仓库代码到本地。
+
+> 第一次提交pr的时候需要添加上游仓库,之后提交pr不需要
+
+###### 列出当前项目配置的远程仓库
+
+```
+$ git remote -v
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (fetch)
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (push)
+
+```
+
+###### 指定fork项目的新远程仓库
+
+```
+git remote add upstream https://github.com/apache/dubbo-go-pixiu.git
+```
+
+###### 然后重新列出配置的远程仓库
+
+```
+$ git remote -v
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (fetch)
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (push)
+upstream https://github.com/apache/dubbo-go-pixiu.git (fetch)
+upstream https://github.com/apache/dubbo-go-pixiu.git (push)
+```
+
+### 7.从上游仓库获取最新的代码
+
+确定好修改好的代码是想要合并到上游仓库的哪个分支(一般开源仓库都是有很多的分支, 但需要合并的往往只是特定的一个分支)
+
+这里选择我要合并的上游分支develop
+
+```
+$ git fetch upstream develop
+remote: Enumerating objects: 4, done.
+remote: Counting objects: 100% (4/4), done.
+remote: Total 5 (delta 4), reused 4 (delta 4), pack-reused 1
+Unpacking objects: 100% (5/5), done.
+From https://github.com/rakyll/hey
+ * [new branch] my-feature -> upstream/develop
+ * [new tag] v0.1.4 -> v0.1.4
+
+```
+
+### 8.将开发的分支和上游仓库代码merge
+
+```
+git merge upstream/develop
+```
+
+### 9.提交PR
+
+## 2 第二次提交pr
+
+```
+$ go mod tidy
+```
+
+```
+$ git add .
+```
+
+```
+$ git commit -m"add :new change"
+```
+
+```
+$ git push origin my-feature
+Counting objects: 3, done.
+Delta compression using up to 4 threads.
+Compressing objects: 100% (3/3), done.
+Writing objects: 100% (3/3), 288 bytes | 0 bytes/s, done.
+Total 3 (delta 2), reused 0 (delta 0)
+remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
+To git@github.com:oyjjpp/hey.git
+ f3676ef..d7a9529 my-feature -> my-feature
+```
+
+```
+$ git fetch upstream develop
+```
+
+```
+git merge upstream/develop
+```
+
+```
+提交pr
+```
+
diff --git a/_posts/2022-07-08-test-markdown.md b/_posts/2022-07-08-test-markdown.md
new file mode 100644
index 000000000000..75a5a62adfa2
--- /dev/null
+++ b/_posts/2022-07-08-test-markdown.md
@@ -0,0 +1,692 @@
+---
+layout: post=
+title: Service Mesh, What & Why ?
+subtitle: 正在构建基于服务的架构,无论是micro services微服务还是纳米服务nano services 的service meshes 需要了解服务到服务通信的基本知识。
+tags: [架构]
+
+---
+# Service Mesh: What & Why ?
+
+> 正在构建基于服务的架构,无论是`micro services`微服务还是纳米服务`nano services` 的**service meshes **需要了解服务到服务通信的基本知识。
+
+service a调用 service b ,如果对service b 的调用失败,我们通常会做的是 service a Retry
+
+retry 称为重试逻辑,开发人员通常在他们的代码库中有重试逻辑来处理这些类型的失败场景,这个逻辑可能在不同类型的
+服务和不同的编程语言。
+
+在放弃之前重试了多少次,太多的重试逻辑在服务 a 和 b 之间造成的弊大于利怎么办?并且服务 b 必须具有关于
+如何处理身份验证的逻辑,所以代码库现在会增长并变得更加复杂 。我们可能还希望微服务之间的相互 tls 或 ssl 连接。我们可能不希望服务通过端口 80 进行通信,而是通过端口 443 安全地进行通信。这意味着:
+
+- 必须为每个服务颁发证书
+
+- 必须为每个服务轮换和维护。避免成为大规模维护的噩梦。
+
+
+另一个是我们可能想知道:
+
+- **服务 a 每秒发送给service b 的请求数是多少**?
+- 服务 b 每秒接收的请求数是多少?
+
+我们也可能想知道关于:
+
+- service b响应的 latency 延迟和 time 的metrics
+
+有很多可用的指标库,但这需要开发工作,这使得代码库变得越来越复杂。如果服务 a 调用服务 b,但服务 b
+向服务c和d发出请求,该怎么办? 有时我们可能希望将请求跟踪到每个服务,以确定延迟可能在哪里.
+
+比如:服务 a 到 b 可能需要 5 秒、服务 b 到 c 只需要半秒,跟踪这些 Web 请求将帮助我们找到Web 系统中的慢计时区域,这实现起来非常复杂,并且每个都需要大量的代码投资。并且服务为了跟踪每个请求和延迟有时我们可能还想进行流量拆分,只将 10% 的流量发送到服务 d 。现在在传统的 Web 服务器中,我们有防火墙,允许我们控制哪些服务现在可以相互通信。但是大规模分布式系统和微服务 这几乎是不可能去维护的。我们添加的服务越多,我们就越需要不断调整复杂的防火墙规则,我们可能需要不断更新和设置允许哪些服务通信和哪些服务不能通信的策略。
+
+ 所以如果给服务 a和服务 b 并且添加重试逻辑在两者之间、添加身份验证在两者之间、添加相互 tls在两者之间、关于每秒请求数和延迟的指标在两者之间。根据需求进行扩展我们添加服务 e f g h i。如您所见,这会增加大量的开发工作和操作上的痛苦。
+
+很好的解决方案就是 service mesh technology
+
+## 1. service mesh technology
+
+> 在软件架构中service mesh 是一个专用的基础设施层,用于促进服务到服务的通信。通常在微服务之间服务service mesh旨在使网络更智能。基本上采用我所说的所有逻辑和功能,将它从代码库中移出并移入网络。这样可以使您的应用程序代码库更小更简单,这样您就可以获得所有这些功能。并保持您的代码库基本不变,
+
+所以让我们再看看service a 、service b
+
+service mesh的工作原理是它谨慎地将 proxy作为 sidecar 注入到每个服务。proxy劫持来自服务pod的请求。这意味着 web 数据包将首先访问服务service a 中的proxy,在实际访问服务service b 之前到service b的proxy
+而不是为service a 和 service b 添加logic 。logic 存在于 sidecar proxy我们可以在declarative (声明性)config 配置中挑选我们想要的功能:
+
+- 我们希望代理上的 tls 将管理自己的证书并自动rotate轮换它们
+- 我们希望代理上的自动重试将在失败的情况下重试请求
+- 假设我们想要服务 a 和b 之间进行身份验证,代理将处理服务之间的身份验证,而无需代码。
+- 我们可以打开指标并自动查看集群中每个 pod 的metrics、automatically see requests、per second and latency而无需向我们的服务添加代码。
+- 无论什么编程语言他们都将获得相同的指标所有这些都在每个微服务的声明性配置文件中定义。
+
+
+这使得轻松加入和 扩展微服务,尤其是当您的集群中有 100 多个服务时,因此要开始service mesh ,我们将需要一个非常好的用例来说明。
+
+
+
+我有 一个 kubernetes 文件夹,有一个带有自述文件的service mesh文件夹
+along in the service 我们将看一下 linkid 和 istio 。 现在的服务度量涵盖了我之前提到的各种功能,但是service mesh 的好处在于它不是在cluster 集群中打开的东西。而是我建议
+
+- installing a service mesh 安装服务网格
+
+- cherry picking the features 挑选您需要的功能
+
+- turn them on for services 为您需要的服务打开它们
+
+- 然后应用该方法直到这些概念在您的团队中成熟,或者一旦您从中获得价值,
+ apply that approach until these concepts mature within your team and then once you gain value from it
+
+- 您就可以决定将这些功能扩展到其他服务
+
+ it you can decide to expand these features to other services or more features as you need
+
+
+
+kubernetes service mesh folder下面有三个applications folder 其中包含三个用于此用例的微服务micro services 。这些服务组成了一个视频目录,基本上是一个网页将显示播放列表和视频列表。
+
+1. 我们从一个简单的 web ui 开始,它被称为 videos web 这是一个 html 应用程序,它列出了一堆包含视频的播放列表。
+2. playlists api来获取播放列表
+3. videos web 调用播放列表 api
+4. 完整的架构 :videos web加载到浏览器——>向playlist api 发出单个 Web 请求——>api 将向playlists-db数据库发出请求以加载——>playlist api 遍历每个播放列表并获取——>对videos- api 进行网络调用——> 从videos db 视频数据库获取视频内容所需的所有视频 ID
+5. playlist api 和videos api在它们之间发出大量请求
+6. 在 docker 容器中构建所有这些应用程序和启动它们。
+7. 所以现在我们的应用程序在本地 docker 容器中运行,以查看service meshes 我们要做的是部署所有 这些东西到 kubernetes
+8. 使用名为 kind 的产品,它可以帮助我在 docker 容器中本地运行 kubernetes 集群。
+9. 在我的机器上的容器内启动一个 kubernetes 集群以便可以在其中部署视频。
+10. 三个微服务,部署它们中的每一个。
+
+```
+//servicemesh/applications/playlists-api/playlist-api app.go
+package main
+
+import (
+ "net/http"
+ "github.com/julienschmidt/httprouter"
+ log "github.com/sirupsen/logrus"
+ "encoding/json"
+ "fmt"
+ "os"
+ "bytes"
+ "io/ioutil"
+ "context"
+ "github.com/go-redis/redis/v8"
+)
+
+var environment = os.Getenv("ENVIRONMENT")
+var redis_host = os.Getenv("REDIS_HOST")
+var redis_port = os.Getenv("REDIS_PORT")
+var ctx = context.Background()
+var rdb *redis.Client
+
+func main() {
+
+ router := httprouter.New()
+
+ router.GET("/", func(w http.ResponseWriter, r *http.Request, p httprouter.Params){
+ cors(w)
+ playlistsJson := getPlaylists()
+
+ playlists := []playlist{}
+ err := json.Unmarshal([]byte(playlistsJson), &playlists)
+ if err != nil {
+ panic(err)
+ }
+
+ //get videos for each playlist from videos api
+ for pi := range playlists {
+
+ vs := []videos{}
+ for vi := range playlists[pi].Videos {
+
+ v := videos{}
+ videoResp, err := http.Get("http://videos-api:10010/" + playlists[pi].Videos[vi].Id)
+
+ if err != nil {
+ fmt.Println(err)
+ break
+ }
+
+ defer videoResp.Body.Close()
+ video, err := ioutil.ReadAll(videoResp.Body)
+
+ if err != nil {
+ panic(err)
+ }
+
+
+ err = json.Unmarshal(video, &v)
+
+ if err != nil {
+ panic(err)
+ }
+
+ vs = append(vs, v)
+
+ }
+
+ playlists[pi].Videos = vs
+ }
+
+ playlistsBytes, err := json.Marshal(playlists)
+ if err != nil {
+ panic(err)
+ }
+
+ reader := bytes.NewReader(playlistsBytes)
+ if b, err := ioutil.ReadAll(reader); err == nil {
+ fmt.Fprintf(w, "%s", string(b))
+ }
+
+ })
+
+ r := redis.NewClient(&redis.Options{
+ Addr: redis_host + ":" + redis_port,
+ DB: 0,
+ })
+ rdb = r
+
+ fmt.Println("Running...")
+ log.Fatal(http.ListenAndServe(":10010", router))
+}
+
+func getPlaylists()(response string){
+ playlistData, err := rdb.Get(ctx, "playlists").Result()
+
+ if err != nil {
+ fmt.Println(err)
+ fmt.Println("error occured retrieving playlists from Redis")
+ return "[]"
+ }
+
+ return playlistData
+}
+
+type playlist struct {
+ Id string `json:"id"`
+ Name string `json:"name"`
+ Videos []videos `json:"videos"`
+}
+
+type videos struct {
+ Id string `json:"id"`
+ Title string `json:"title"`
+ Description string `json:"description"`
+ Imageurl string `json:"imageurl"`
+ Url string `json:"url"`
+
+}
+
+type stop struct {
+ error
+}
+
+func cors(writer http.ResponseWriter) () {
+ if(environment == "DEBUG"){
+ writer.Header().Set("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE")
+ writer.Header().Set("Access-Control-Allow-Headers", "Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization, accept, origin, Cache-Control, X-Requested-With, X-MY-API-Version")
+ writer.Header().Set("Access-Control-Allow-Credentials", "true")
+ writer.Header().Set("Access-Control-Allow-Origin", "*")
+ }
+}
+```
+
+```
+// servicemesh/applications/playlists-apiplaylist-api/deploy.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: playlists-api
+ labels:
+ app: playlists-api
+spec:
+ selector:
+ matchLabels:
+ app: playlists-api
+ replicas: 1
+ strategy:
+ type: RollingUpdate
+ rollingUpdate:
+ maxSurge: 1
+ maxUnavailable: 0
+ template:
+ metadata:
+ labels:
+ app: playlists-api
+ spec:
+ containers:
+ - name: playlists-api
+ image: aimvector/service-mesh:playlists-api-1.0.0
+ imagePullPolicy : Always
+ ports:
+ - containerPort: 10010
+ env:
+ - name: "ENVIRONMENT"
+ value: "DEBUG"
+ - name: "REDIS_HOST"
+ value: "playlists-db"
+ - name: "REDIS_PORT"
+ value: "6379"
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: playlists-api
+ labels:
+ app: playlists-api
+spec:
+ type: ClusterIP
+ selector:
+ app: playlists-api
+ ports:
+ - protocol: TCP
+ name: http
+ port: 80
+ targetPort: 10010
+---
+apiVersion: networking.k8s.io/v1beta1
+kind: Ingress
+metadata:
+ annotations:
+ kubernetes.io/ingress.class: "nginx"
+ nginx.ingress.kubernetes.io/ssl-redirect: "false"
+ nginx.ingress.kubernetes.io/rewrite-target: /$2
+ name: playlists-api
+spec:
+ rules:
+ - host: servicemesh.demo
+ http:
+ paths:
+ - path: /api/playlists(/|$)(.*)
+ backend:
+ serviceName: playlists-api
+ servicePort: 80
+
+
+```
+
+```
+//servicemesh/applications/videos-api/app.go
+package main
+
+import (
+ "net/http"
+ "github.com/julienschmidt/httprouter"
+ log "github.com/sirupsen/logrus"
+ "github.com/go-redis/redis/v8"
+ "fmt"
+ "context"
+ "os"
+ "math/rand"
+)
+
+var environment = os.Getenv("ENVIRONMENT")
+var redis_host = os.Getenv("REDIS_HOST")
+var redis_port = os.Getenv("REDIS_PORT")
+var flaky = os.Getenv("FLAKY")
+
+var ctx = context.Background()
+var rdb *redis.Client
+
+func main() {
+
+ router := httprouter.New()
+
+ router.GET("/:id", func(w http.ResponseWriter, r *http.Request, p httprouter.Params){
+
+ if flaky == "true"{
+ if rand.Intn(90) < 30 {
+ panic("flaky error occurred ")
+ }
+ }
+
+ video := video(w,r,p)
+
+ cors(w)
+ fmt.Fprintf(w, "%s", video)
+ })
+
+ r := redis.NewClient(&redis.Options{
+ Addr: redis_host + ":" + redis_port,
+ DB: 0,
+ })
+ rdb = r
+
+ fmt.Println("Running...")
+ log.Fatal(http.ListenAndServe(":10010", router))
+}
+
+func video(writer http.ResponseWriter, request *http.Request, p httprouter.Params)(response string){
+
+ id := p.ByName("id")
+ fmt.Print(id)
+
+ videoData, err := rdb.Get(ctx, id).Result()
+ if err == redis.Nil {
+ return "{}"
+ } else if err != nil {
+ panic(err)
+} else {
+ return videoData
+}
+}
+
+type stop struct {
+ error
+}
+
+func cors(writer http.ResponseWriter) () {
+ if(environment == "DEBUG"){
+ writer.Header().Set("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE")
+ writer.Header().Set("Access-Control-Allow-Headers", "Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization, accept, origin, Cache-Control, X-Requested-With, X-MY-API-Version")
+ writer.Header().Set("Access-Control-Allow-Credentials", "true")
+ writer.Header().Set("Access-Control-Allow-Origin", "*")
+ }
+}
+
+type videos struct {
+ Id string `json:"id"`
+ Title string `json:"title"`
+ Description string `json:"description"`
+ Imageurl string `json:"imageurl"`
+ Url string `json:"url"`
+
+}
+```
+
+```
+//servicemesh/applications/videos-api/deploy.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: videos-api
+ labels:
+ app: videos-api
+spec:
+ selector:
+ matchLabels:
+ app: videos-api
+ replicas: 1
+ strategy:
+ type: RollingUpdate
+ rollingUpdate:
+ maxSurge: 1
+ maxUnavailable: 0
+ template:
+ metadata:
+ labels:
+ app: videos-api
+ spec:
+ containers:
+ - name: videos-api
+ image: aimvector/service-mesh:videos-api-1.0.0
+ imagePullPolicy : Always
+ ports:
+ - containerPort: 10010
+ env:
+ - name: "ENVIRONMENT"
+ value: "DEBUG"
+ - name: "REDIS_HOST"
+ value: "videos-db"
+ - name: "REDIS_PORT"
+ value: "6379"
+ - name: "FLAKY"
+ value: "false"
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: videos-api
+ labels:
+ app: videos-api
+spec:
+ type: ClusterIP
+ selector:
+ app: videos-api
+ ports:
+ - protocol: TCP
+ name: http
+ port: 10010
+ targetPort: 10010
+---
+
+
+```
+
+
+
+## 2.Introduction to Linkerd for beginners | a Service Mesh
+
+Linkerd是最具侵入性的Service Mesh之一,这意味着您可以轻松安装它,并轻松删除它,轻松选择加入和退出某些功能并将其添加到某些微服务中。所以我非常兴奋,我们有有很多话要说,所以不用多说,让我们开始
+
+#### Full application architecture
+
+```
++------------+ +---------------+ +--------------+
+| videos-web +---->+ playlists-api +--->+ playlists-db |
+| | | | | |
++------------+ +-----+---------+ +--------------+
+ |
+ v
+ +-----+------+ +-----------+
+ | videos-api +------>+ videos-db |
+ | | | |
+ +------------+ +-----------+
+```
+
+#### A simple Web UI: videos-web
+
+这是一个 HTML 应用程序,列出了一堆包含视频的播放列表
+
+```
++------------+
+| videos-web |
+| |
++------------+
+```
+
+#### A simple API: playlists-api
+
+要让videos-web 获取任何内容,它需要调用playlists-api
+
+```
++------------+ +---------------+
+| videos-web +---->+ playlists-api |
+| | | |
++------------+ +---------------+
+```
+
+播放列表由`title,description`等数据和视频列表组成。 播放列表存储在数据库中。 playlists-api 将其数据存储在数据库中
+
+```
++------------+ +---------------+ +--------------+
+| videos-web +---->+ playlists-api +--->+ playlists-db |
+| | | | | |
++------------+ +---------------+ +--------------+
+```
+
+每个playlist item 仅包含一个视频 ID 列表。 播放列表没有每个视频的完整元数据。
+
+Example `playlist`:
+
+```
+{
+ "id" : "playlist-01",
+ "title": "Cool playlist",
+ "videos" : [ "video-1", "video-x" , "video-b"]
+}
+```
+
+Take not above videos: [] 是视频 id 的列表 视频有自己的标题和描述以及其他元数据。 为了得到这些数据,我们需要一个videos-api 这个videos-api也有自己的数据库
+
+```
++------------+ +-----------+
+| videos-api +------>+ videos-db |
+| | | |
++------------+ +-----------+
+```
+
+## 3.Traffic flow
+
+对 `playlists-api` 的单个 `GET` 请求将通过单个 DB 调用从其数据库中获取所有播放列表对于每个播放列表和每个列表中的每个视频,将单独`GET`调用`videos-api`将从其数据库中检索视频元数据。这将导致许多网络扇出`playlists-api`和`videos-api`许多对其数据库的调用。
+
+
+
+## 4.Run the apps: Docker
+
+```
+//终z端在`在ocker-compose.yaml`下,运行:
+docker-compose build
+
+docker-compose up
+
+```
+
+您可以在 http://localhost 上访问该应用程序
+
+## 5.Run the apps: Kubernetes
+
+```
+//Creae a cluster with kind
+kind create cluster --name servicemesh --image kindest/node:v1.18.4
+```
+
+### Deploy videos-web
+
+```
+cd ./kubernetes/servicemesh/
+
+kubectl apply -f applications/videos-web/deploy.yaml
+kubectl port-forward svc/videos-web 80:80
+```
+
+您应该在 http://localhost/ 看到空白页 它是空白的,因为它需要 playlists-api 来获取数据
+
+### Deploy playlists-api and database
+
+```
+cd ./kubernetes/servicemesh/
+
+kubectl apply -f applications/playlists-api/deploy.yaml
+kubectl apply -f applications/playlists-db/
+kubectl port-forward svc/playlists-api 81:80
+//转发
+```
+
+您应该在 http://localhost/ 看到空的播放列表页面 播放列表是空的,因为它需要 video-api 来获取视频数据
+
+### Deploy videos-api and database
+
+```
+cd ./kubernetes/servicemesh/
+
+kubectl apply -f applications/videos-api/deploy.yaml
+kubectl apply -f applications/videos-db/
+```
+
+在 http://localhost/ 刷新页面 您现在应该在浏览器中看到完整的架构
+
+```
+servicemesh.demo/home --> videos-web
+servicemesh.demo/api/playlists --> playlists-api
+
+
+ servicemesh.demo/home/ +--------------+
+ +------------------------------> | videos-web |
+ | | |
+servicemesh.demo/home/ +------+------------+ +--------------+
+ +------------------>+ingress-nginx |
+ |Ingress controller |
+ +------+------------+ +---------------+ +--------------+
+ | | playlists-api +--->+ playlists-db |
+ +------------------------------> | | | |
+ servicemesh.demo/api/playlists +-----+---------+ +--------------+
+ |
+ v
+ +-----+------+ +-----------+
+ | videos-api +------>+ videos-db |
+ | | | |
+ +------------+ +-----------+
+
+```
+
+
+
+# Introduction to Linkerd
+
+## 1.We need a Kubernetes cluster
+
+我们需要一个 Kubernetes 集群,让我们使用kind创建一个 Kubernetes 集群来玩
+
+```
+kind create cluster --name linkerd --image kindest/node:v1.19.1
+```
+
+## 2.Deploy our microservices (Video catalog)
+
+部署我们的微服务(视频目录)
+
+```
+# ingress controller
+kubectl create ns ingress-nginx
+kubectl apply -f kubernetes/servicemesh/applications/ingress-nginx/
+
+# applications
+kubectl apply -f kubernetes/servicemesh/applications/playlists-api/
+kubectl apply -f kubernetes/servicemesh/applications/playlists-db/
+kubectl apply -f kubernetes/servicemesh/applications/videos-web/
+kubectl apply -f kubernetes/servicemesh/applications/videos-api/
+kubectl apply -f kubernetes/servicemesh/applications/videos-db/
+```
+
+
+
+## 3.Make sure our applications are running
+
+```
+kubectl get pods
+NAME READY STATUS RESTARTS AGE
+playlists-api-d7f64c9c6-rfhdg 1/1 Running 0 2m19s
+playlists-db-67d75dc7f4-p8wk5 1/1 Running 0 2m19s
+videos-api-7769dfc56b-fsqsr 1/1 Running 0 2m18s
+videos-db-74576d7c7d-5ljdh 1/1 Running 0 2m18s
+videos-web-598c76f8f-chhgm 1/1 Running 0 100s
+
+```
+
+确保我们的应用程序正在运行
+
+## 4.Make sure our ingress controller is running
+
+```
+kubectl -n ingress-nginx get pods
+NAME READY STATUS RESTARTS AGE
+nginx-ingress-controller-6fbb446cff-8fwxz 1/1 Running 0 2m38s
+nginx-ingress-controller-6fbb446cff-zbw7x 1/1 Running 0 2m38s
+
+```
+
+确保我们的入口控制器正在运行。
+
+我们需要一个伪造的 DNS 名称让我们通过在 hosts ( ) 文件`servicemesh.demo`
+中添加以下条目来伪造一个:`C:\Windows\System32\drivers\etc\hosts`
+
+```
+127.0.0.1 servicemesh.demo
+```
+
+## Let's access our applications via Ingress
+
+```
+kubectl -n ingress-nginx port-forward deploy/nginx-ingress-controller 80
+```
+
+让我们通过 Ingress 访问我们的应用程序
+
+## Access our application in the browser
+
+在浏览器中访问我们的应用程序,我们应该能够访问我们的网站`http://servicemesh.demo/home/`
+
+
+
+
+
+
+
+
+
diff --git a/_posts/2022-07-09test-markdown.md b/_posts/2022-07-09test-markdown.md
new file mode 100644
index 000000000000..294f02258249
--- /dev/null
+++ b/_posts/2022-07-09test-markdown.md
@@ -0,0 +1,50 @@
+---
+layout: post
+title: 什么是 Sidecar 模式,为什么它在微服务中被大量使用?
+subtitle: Sidecar 模式是一种架构模式,其中位于同一个主机的两个或者多个进程可以相互通信。他们是环回本地主机,本质是 启动进程间通讯。
+tags: [架构]
+---
+
+# 什么是 Sidecar 模式,为什么它在微服务中被大量使用?
+
+## 1.什么是 Sidecar 模式
+
+Sidecar 模式是一种架构模式,其中位于同一个主机的两个或者多个进程可以相互通信。他们是环回本地主机,本质是 **启动进程间通讯**。
+
+#### How We Do Traditionally ?
+
+假设现有一个传统的`golang`应用,我们在其中导入一些重要的 `golang`包,然后这个程序做为一个。`exe` 运行在本地主机上 `localhost` 在这种情况下我有一个很不错的 `golang`库,我花了很多时间在这个库上,它是一个高级的库,可以进行日志记录和对话。因为我是用 `golang`写的库,所以我的应用程序也是 `golang`写的。我需要做的就是,使用这个库,调用函数。
+
+```
+-----------------------------------------
+| |
+| ------------------ |
+| | |------- | |
+| | |Library | |
+| | |------- | |
+| |app | |
+| ----------------- |
+| |
+| |
+----------------------------------------
+
+```
+
+如果是Sidecar pattern ,那么我需要做的就是拆封我的日记记录库
+
+```
+log(localhost:8080)
+```
+
+```
+golang.log(localhost:8080)
+```
+
+也就是说,我们所做的,不是引用或者导入而是向端口的本地主机发出请求。任务本质上没有离开哪个那个主机。它会通过网络堆栈。当我们开始运行程序时,就会返回调用我们写的库。
+
+- **让两个进程生活在同一台机器上,然后他们直接通信**
+- 这个时候,我们的库可以被其他任何语言使用。
+- **公开给其他任何语言use**
+
+
+
diff --git a/_posts/2022-07-11-test-markdown.md b/_posts/2022-07-11-test-markdown.md
new file mode 100644
index 000000000000..e65c448737a9
--- /dev/null
+++ b/_posts/2022-07-11-test-markdown.md
@@ -0,0 +1,118 @@
+---
+layout: post
+title: 什么是 Distributed Tracing(分布式跟踪)?
+subtitle: 在微服务的世界中,大多数问题是由于网络问题和不同微服务之间的关系而发生的。分布式架构(相对于单体架构)使得找到问题的根源变得更加困难。要解决这些问题,我们需要查看哪个服务向另一个服务或组件(数据库、队列等)发送了哪些参数。分布式跟踪通过使我们能够从系统的不同部分收集数据来帮助我们实现这一目标,从而使我们的系统能够实现这种所需的可观察性。
+tags: [分布式]
+---
+# 什么是 Distributed Tracing(分布式跟踪)?
+
+> 在微服务的世界中,大多数问题是由于网络问题和不同微服务之间的关系而发生的。分布式架构(相对于单体架构)使得找到问题的根源变得更加困难。要解决这些问题,我们需要查看哪个服务向另一个服务或组件(数据库、队列等)发送了哪些参数。分布式跟踪通过使我们能够从系统的不同部分收集数据来帮助我们实现这一目标,从而使我们的系统能够实现这种所需的可观察性。
+
+- **分布式跟踪使我们从系统的不同部分收集数据从而找到问题的根源。**
+- **此外,trace 是一种可视化工具,可以让我们将系统可视化以更好地了解服务之间的关系,从而更容易调查和查明问题**
+
+## 1.**什么是 Jaeger 追踪?**
+
+Jaeger 是 Uber 在 2015 年创建的开源分布式跟踪平台。它由检测 SDK、用于数据收集和存储的后端、用于可视化数据的 UI 以及用于聚合跟踪分析的 Spark/Flink 框架组成。
+
+Jaeger 数据模型与 OpenTracing 兼容,OpenTracing 是一种规范,用于定义收集的跟踪数据的外观,以及不同语言的实现库(稍后将详细介绍 OpenTracing 和 OpenTelemetry)。
+
+与大多数其他分布式跟踪系统一样,Jaeger 使用spans and traces,如 OpenTracing 规范中定义的那样。
+
+
+
+span 代表应用程序中的一个工作单元(HTTP 请求、对 DB 的调用等),是 Jaeger 最基本的工作单元。Span必须具有操作名称、开始时间和持续时间。
+
+Traces 是以父/子关系连接的跨度的集合/列表(也可以被认为是Span的有向无环图)。Traces 指定如何通过我们的服务和其他组件传播请求。
+
+## 2.Jaeger 追踪架构
+
+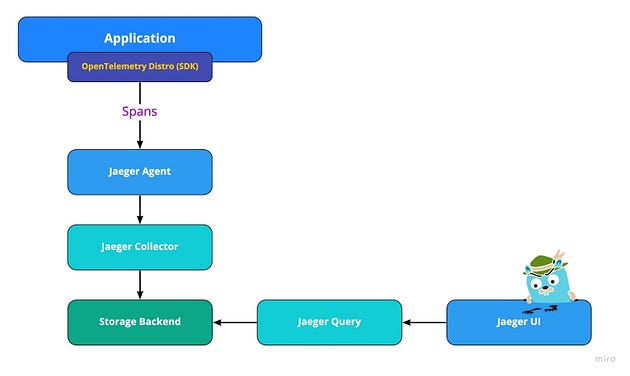
+
+它由几个部分组成,我将在下面解释所有这些部分:
+
+- **Instrumentation SDK:**集成到应用程序和框架中以捕获跟踪数据的库。从历史上看,Jaeger 项目支持使用各种编程语言编写的自己的客户端库。它们现在被弃用,取而代之的是 OpenTelemetry(同样,稍后会详细介绍)。
+
+- **Jaeger 代理:** Jaeger 代理是一个网络守护程序,用于侦听通过 UDP 从 Jaeger 客户端接收到的跨度。它收集成批的它们,然后将它们一起发送给收集器。如果 SDK 被配置为将 span 直接发送到收集器,则不需要代理。
+- **Jaeger 收集器:** Jaeger 收集器负责从 Jaeger 代理接收跟踪,执行验证和转换,并将它们保存到选定的存储后端。
+- **存储后端:** Jaeger 支持各种存储后端来存储跨度。支持的存储后端有 In-Memory、Cassandra、Elasticsearch 和 Badger(用于单实例收集器部署)。
+- **Jaeger Query:**这是一项服务,负责从 Jaeger 存储后端检索跟踪信息,并使其可供 Jaeger UI 访问。
+- **Jaeger UI:**一个 React 应用程序,可让您可视化跟踪并分析它们。对于调试系统问题很有用。
+- **Ingester:**只有当我们使用 Kafka 作为收集器和存储后端之间的缓冲区时,ingester 才有意义。它负责从 Kafka 接收数据并将其摄取到存储后端。更多信息可以在[官方 Jaeger Tracing 文档](https://www.jaegertracing.io/docs/1.30/architecture/#ingester)中找到。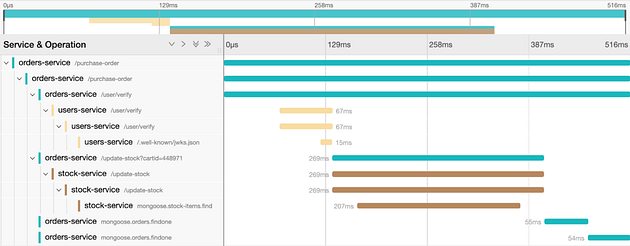
+
+# 使用 Docker 在本地运行 Jaeger
+
+Jaeger 附带一个即用**型一体化**Docker 映像,其中包含 Jaeger 运行所需的所有组件。
+
+在本地机器上启动并运行它非常简单:
+
+```
+docker run -d --name jaeger \
+ -e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
+ -p 5775:5775/udp \
+ -p 6831:6831/udp \
+ -p 6832:6832/udp \
+ -p 5778:5778 \
+ -p 16686: 16686 \
+ -p 14250:14250 \
+ -p 14268:14268 \
+ -p 14269:14269 \
+ -p 9411:9411 \
+ jaegertracing/all-in-one:1.30
+```
+
+然后可以简单地在`http://localhost:16686`上打开 `jaeger UI` 。
+
+# Jaeger 跟踪和 OpenTelemetry
+
+我之前确实提到过 Jaeger 的数据模型与 OpenTracing 规范兼容。可能已经知道 OpenTracing 和 OpenCensus 已合并形成 OpenTelemetry。
+
+### SDK 中的采样策略
+
+(弃用的)Jaeger SDK 有 4 种采样模式:
+
+- Remote:默认值,用于告诉 Jaeger SDK 采样策略由 Jaeger 后端控制。
+- 常数:要么取所有痕迹,要么不取。中间什么都没有。全部为 1,无为 0
+- 速率限制:选择每秒采样的跟踪数。
+- 概率:选择将被采样的轨迹的百分比,例如 - 选择 0.1 以使每 10 条轨迹中有 1 条被采样。
+
+### 远程采样
+
+如果我们选择启用远程采样,Jaeger 收集器将负责确定每个服务中的 SDK 应该使用哪种采样策略。操作员有两种配置收集器的方法:使用采样策略配置文件,或使用自适应采样。
+
+配置文件 — 为收集器提供一个文件路径,该文件包含每个服务和操作前采样配置。
+
+自适应采样——让 Jaeger 了解每个端点接收的流量并计算出该端点最合适的速率。请注意,在撰写本文时,只有 Memory 和 Cassandra 后端支持这一点。
+
+可以在此处找到有关 Jaeger 采样的更多信息:[https ://www.jaegertracing.io/docs/latest/sampling/](https://www.jaegertracing.io/docs/1.30/sampling/)
+
+## Jaeger 追踪术语表
+
+**Span**——我们系统中发生的工作单元(动作/操作)的表示;跨越时间的 HTTP 请求或数据库操作(从 X 开始,持续时间为 Y 毫秒)。通常,它将是另一个跨度的父级和/或子级。
+
+**Trace** — 表示请求进程的树/跨度列表,因为它由我们系统中的不同服务和组件处理。例如,向 user-service 发送 API 调用会导致对 users-db 的 DB 查询。它们是分布式服务的“调用堆栈”。
+
+**Observability可观察**性——衡量我们根据外部输出了解系统内部状态的程度。当您拥有日志、指标和跟踪时,您就拥有了“可观察性的 3 个支柱”。
+
+**OpenTelemetry** — OpenTelemetry 是 CNCF(云原生计算功能)的一个开源项目,它提供了一系列工具、API 和 SDK。OpenTelemetry 支持使用单一规范自动收集和生成跟踪、日志和指标。
+
+**OpenTracing** — 一个用于分布式跟踪的开源项目。它已被弃用并“合并”到 OpenTelemetry 中。OpenTelemetry 为 OpenTracing 提供向后兼容性。
+
+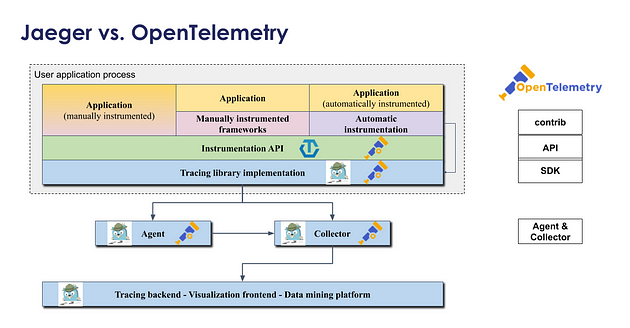
+
+## OpenTelemetry 和 Jaeger
+
+与其他一些跟踪后端不同,Jaeger 项目从未打算解决代码检测问题。通过发布与 OpenTracing 兼容的跟踪器库,我们能够利用现有兼容 OpenTracing 的仪器的丰富生态系统,并将我们的精力集中在构建跟踪后端、可视化工具和数据挖掘技术上。
+
+## 上下文传播作为底层
+
+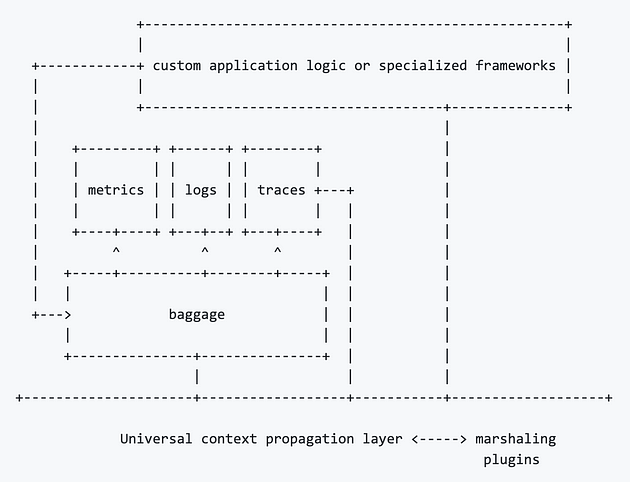
+
+
+
+## OpenCensus 代理/收集器呢?
+
+即使对于 OpenCensus 库,“包含电池”的方法也并不总是有效,因为它们仍然需要配置特定的导出器插件才能将数据发送到具体的跟踪后端,如 Jaeger 或 Zipkin。为了解决这个问题,OpenCensus 项目开始开发两个称为**agent**和**collector**的后端组件,它们扮演着与 Jaeger 的 agent 和 collector 几乎相同的角色:
+
+- **代理**是一个边车/主机代理,它以标准化格式从客户端库接收遥测数据并将其转发给收集器;
+- **收集器**将数据转换为特定跟踪后端可以理解的格式并将其发送到那里。OpenCensus Collector 还能够执行基于尾部的抽样。
\ No newline at end of file
diff --git a/_posts/2022-07-12-test-markdown.md b/_posts/2022-07-12-test-markdown.md
new file mode 100644
index 000000000000..5904841d2d39
--- /dev/null
+++ b/_posts/2022-07-12-test-markdown.md
@@ -0,0 +1,397 @@
+---
+layout: post
+title: 什么是分布式跟踪和 OpenTracing?
+subtitle: 分布式跟踪是一种建立在微服务架构上的监控和分析系统的技术
+tags: [分布式]
+---
+# 什么是分布式跟踪和 OpenTracing?
+
+## 1.What is Distributed Tracing and OpenTracing?
+
+> 分布式跟踪是一种建立在微服务架构上的监控和分析系统的技术,由 X-Trace、[Google 的 Dapper](http://research.google.com/pubs/pub36356.html)和[Twitter 的 Zipkin](http://zipkin.io/)等系统推广。其基础是*分布式上下文传播* 的概念,它涉及将某些元数据与进入系统的每个请求相关联,并在请求执行转到其他微服务时跨线程和进程边界传播该元数据。如果我们为每个入站请求分配一个唯一 ID 并将其作为分布式上下文的一部分携带,那么我们可以将来自多个线程和多个进程的各种分析数据拼接成一个“跟踪”,该“跟踪”代表我们系统对请求的执行.
+
+- **微服务架构上的监控和分析系统技术**
+- **分布式上下文传播**
+- **数据与进入系统的每个请求相关联**
+- **请求执行转到其他微服务时——跨线程和进程边界传播该元数据**
+- 请求分配一个唯一 ID,这个ID作为分布式上下文的一部分携带。
+- **来自多个线程和多个进程的各种数据拼凑成一个跟踪。**
+- 这个 **跟踪** 完全的向我们展示了系统在执行请求时经历了什么。
+
+## 2. OK ,What we need to do ?
+
+> Distributed tracing requires instrumentation of the application code (or the frameworks it uses) with profiling hooks and a context propagation mechanism. in October 2015 a new community was formed that gave birth to the [OpenTracing API](http://opentracing.io/), an open, vendor-neutral, language-agnostic standard for distributed tracing You can read more about it in [Ben Sigelman](https://medium.com/u/bbb65ce0911b?source=post_page-----7cc1282a100a--------------------------------)’s article about [the motivations and design principles behind OpenTracing](https://medium.com/opentracing/towards-turnkey-distributed-tracing-5f4297d1736#.zbnged9wk).
+
+分布式跟踪需要使用分析挂钩 `profiling hooks` 和上下文传播机制 `context propagation mechanism` 对应用程序代码(或其使用的框架)进行检测。 [OpenTracing API](http://opentracing.io/) 实现了 跨编程语言内部一致且与特定跟踪系统没有紧密联系的良好 API。
+
+## 3. Show me the code already!
+
+```
+import (
+ "net/http"
+ "net/http/httptrace"
+
+ "github.com/opentracing/opentracing-go"
+ "github.com/opentracing/opentracing-go/log"
+ "golang.org/x/net/context"
+)
+
+// 这个我们后面会讲
+var tracer opentracing.Tracer
+
+func AskGoogle(ctx context.Context) error {
+ // 从上下文中检索当前 Span
+ // 寻找父context —— parentCtx
+ var parentCtx opentracing.SpanContext
+ // 寻找父Span —— parentSpan
+ parentSpan := opentracing.SpanFromContext(ctx);
+ if parentSpan != nil {
+ parentCtx = parentSpan.Context()
+ }
+
+ // 启动一个新的 Span 来包装 HTTP 请求
+ span := tracer.StartSpan(
+ "ask google",
+ opentracing.ChildOf(parentCtx),
+ )
+
+ // 确保 Span完成后完成
+ defer span.Finish()
+
+ // 使 Span 在上下文中成为当前的
+ ctx = opentracing.ContextWithSpan(ctx, span)
+
+ // 现在准备请求
+ req, err := http.NewRequest("GET", "http://google.com", nil)
+ if err != nil {
+ return err
+ }
+
+ //将 ClientTrace 附加到 Context,并将 Context 附加到请求
+ // 创建一个*httptrace.ClientTrace
+ trace := NewClientTrace(span)
+ //将httptrace.ClientTrace 添加到`context.Context`中
+ ctx = httptrace.WithClientTrace(ctx, trace)
+ //把context添加到请求中
+ req = req.WithContext(ctx)
+ // 执行请求
+ res, err := http.DefaultClient.Do(req)
+ if err != nil {
+ return err
+ }
+
+ //谷歌主页不是太精彩,所以忽略结果
+ res.Body.Close()
+ return nil
+}
+
+```
+
+```
+func NewClientTrace(span opentracing.Span) *httptrace.ClientTrace {
+ trace := &clientTrace{span: span}
+ return &httptrace.ClientTrace {
+ DNSStart: trace.dnsStart,
+ DNSDone: trace.dnsDone,
+ }
+}
+// clientTrace 持有对 Span 的引用和
+// 提供用作 ClientTrace 回调的方法
+type clientTrace struct {
+ span opentracing.Span
+}
+
+func (h *clientTrace) dnsStart(info httptrace.DNSStartInfo) {
+ h.span.LogKV(
+ log.String( "event" , "DNS start" ),
+ log.Object( "主机", info.Host),
+ )
+}
+
+func (h *clientTrace) dnsDone(httptrace.DNSDoneInfo) {
+ h.span.LogKV(log.String( "event" , "DNS done" ))
+}
+```
+
+- 发起一个请求前,准备好 Span `opentracing.Tracer.StartSpan()`
+
+- 然后是请求 `req, err := http.NewRequest("GET", "http://google.com", nil)`
+
+- 根据 Span 创建好一个 `*httptrace.ClientTrace `
+
+ ```
+ httptrace.ClientTrace{
+ DNSStart: trace.dnsStart,,
+ DNSDone: trace.dnsDone,
+ }
+ //DNSStart是函数类型func (info httptrace.DNSStartInfo){}
+ //NSDone 是函数类型func (info httptrace.DNSDoneInfo){}
+ ```
+
+- 将`httptrace.ClientTrace` 添加到`context.Context`中
+
+ ```
+ ctx = httptrace.WithClientTrace(ctx, trace)
+ ```
+
+- 把context添加到请求中
+
+ ```
+ req = req.WithContext(ctx)
+ ```
+
+- AskGoogle 函数接受**context.Context**对象。这是[Go 中开发分布式应用程序的推荐方式](https://blog.golang.org/context),因为 Context 对象允许分布式上下文传播。
+- 我们假设上下文已经包含一个父跟踪 Span。OpenTracing API 中的 Span 用于表示由微服务执行的工作单元。HTTP 调用是可以包装在跟踪 Span 中的操作的一个很好的示例。当我们运行一个处理入站请求的服务时,该服务通常会为每个请求**创建一个跟踪跨度`tracing span`并将其存储在上下文中**,以便在我们对另一个服务进行下游调用时它是可用的。
+- 我们为由私有结构`clientTrace`实现的`DNSStart和``DNSDone`事件注册两个回调,该结构包含对跟踪 Span 的引用。在回调方法中,我们使用 **Span 的键值日志 API 来记录有关事件的信息**,以及 Span 本身隐式捕获的时间戳。
+
+## 4.OpenTracing API 的工作方式
+
+OpenTracing API 的工作方式是,一旦调用了追踪 Span 上的 Finish() 方法,span 捕获的数据就会被发送到追踪系统后端,通常在后台异步发送。然后我们可以使用跟踪系统 UI 来查找跟踪并在时间轴上将其可视化
+
+上面的例子只是为了说明使用 OpenTracing 和**httptrace**的原理。对于真正的工作示例,我们将使用来自[Dominik Honnef](http://dominik.honnef.co/)的现有库https://github.com/opentracing-contrib/go-stdlib,这为我们完成了大部分仪器。使用这个库,我们的客户端代码不需要担心跟踪实际的 HTTP 调用。但是,我们仍然希望创建一个顶级跟踪 Span 来表示客户端应用程序的整体执行情况,并将任何错误记录到它。
+
+```
+package main
+
+import (
+ "fmt"
+ "io/ioutil"
+ "log"
+ "net/http"
+
+ "github.com/opentracing-contrib/go-stdlib/nethttp"
+ "github.com/opentracing/opentracing-go"
+ "github.com/opentracing/opentracing-go/ext"
+ otlog "github.com/opentracing/opentracing-go/log"
+ "golang.org/x/net/context"
+)
+
+func runClient(tracer opentracing.Tracer) {
+ // nethttp.Transport from go-stdlib will do the tracing
+ c := &http.Client{Transport: &nethttp.Transport{}}
+
+ // create a top-level span to represent full work of the client
+ span := tracer.StartSpan(client)
+ span.SetTag(string(ext.Component), client)
+ defer span.Finish()
+ ctx := opentracing.ContextWithSpan(context.Background(), span)
+
+ req, err := http.NewRequest(
+ "GET",
+ fmt.Sprintf("http://localhost:%s/", *serverPort),
+ nil,
+ )
+ if err != nil {
+ onError(span, err)
+ return
+ }
+
+ req = req.WithContext(ctx)
+ // wrap the request in nethttp.TraceRequest
+ req, ht := nethttp.TraceRequest(tracer, req)
+ defer ht.Finish()
+
+ res, err := c.Do(req)
+ if err != nil {
+ onError(span, err)
+ return
+ }
+ defer res.Body.Close()
+ body, err := ioutil.ReadAll(res.Body)
+ if err != nil {
+ onError(span, err)
+ return
+ }
+ fmt.Printf("Received result: %s\n", string(body))
+}
+
+func onError(span opentracing.Span, err error) {
+ // handle errors by recording them in the span
+ span.SetTag(string(ext.Error), true)
+ span.LogKV(otlog.Error(err))
+ log.Print(err)
+}
+```
+
+上面的客户端代码调用本地服务器。让我们也实现它。
+
+```
+package main
+
+import (
+ "fmt"
+ "io"
+ "log"
+ "net/http"
+ "time"
+
+ "github.com/opentracing-contrib/go-stdlib/nethttp"
+ "github.com/opentracing/opentracing-go"
+)
+
+func getTime(w http.ResponseWriter, r *http.Request) {
+ log.Print("Received getTime request")
+ t := time.Now()
+ ts := t.Format("Mon Jan _2 15:04:05 2006")
+ io.WriteString(w, fmt.Sprintf("The time is %s", ts))
+}
+
+func redirect(w http.ResponseWriter, r *http.Request) {
+ http.Redirect(w, r,
+ fmt.Sprintf("http://localhost:%s/gettime", *serverPort), 301)
+}
+
+func runServer(tracer opentracing.Tracer) {
+ http.HandleFunc("/gettime", getTime)
+ http.HandleFunc("/", redirect)
+ log.Printf("Starting server on port %s", *serverPort)
+ http.ListenAndServe(
+ fmt.Sprintf(":%s", *serverPort),
+ // use nethttp.Middleware to enable OpenTracing for server
+ nethttp.Middleware(tracer, http.DefaultServeMux))
+}
+```
+
+请注意,客户端向根端点“/”发出请求,但服务器将其重定向到“/gettime”端点。这样做可以让我们更好地说明如何在跟踪系统中捕获跟踪。
+
+## 5. 运行
+
+我假设有一个 Go 1.7 的本地安装,以及一个正在运行的 Docker,我们将使用它来运行 Zipkin 服务器。
+
+演示项目使用[glide](https://github.com/Masterminds/glide)进行依赖管理,请先安装。例如,在 Mac OS 上,您可以执行以下操作:
+
+```
+$ brew install glide
+```
+
+```
+$ glide install
+```
+
+```
+$ go build .
+```
+
+现在在另一个终端,让我们启动 Zipkin 服务器
+
+```
+$ docker run -d -p 9410-9411:9410-9411 openzipkin/zipkin:1.12.0
+Unable to find image 'openzipkin/zipkin:1.12.0' locally
+1.12.0: Pulling from openzipkin/zipkin
+4d06f2521e4f: Already exists
+93bf0c6c4f8d: Already exists
+a3ed95caeb02: Pull complete
+3db054dce565: Pull complete
+9cc214bea7a6: Pull complete
+Digest: sha256:bf60e4b0ba064b3fe08951d5476bf08f38553322d6f640d657b1f798b6b87c40
+Status: Downloaded newer image for openzipkin/zipkin:1.12.0
+da9353ac890e0c0b492ff4f52ff13a0dd12826a0b861a67cb044f5764195e005
+```
+
+如果没有 Docker,另一种运行 Zipkin 服务器的方法是直接从 jar 中:
+
+```
+$ wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
+$ java -jar zipkin.jar
+```
+
+打开用户界面:
+
+```
+open http://localhost:9411/
+```
+
+如果您重新加载 UI 页面,您应该会看到“客户端”出现在第一个下拉列表中。
+
+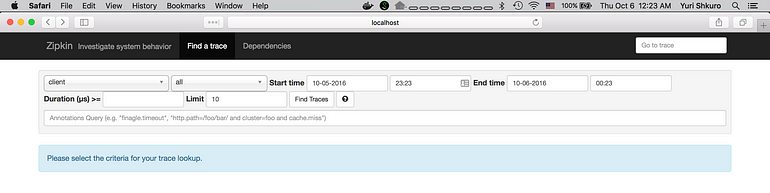
+
+单击 Find Traces 按钮,您应该会看到一条跟踪。
+
+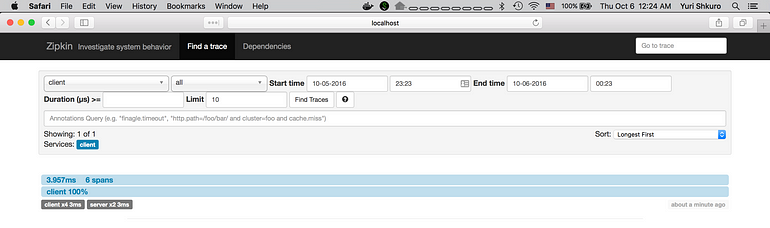
+
+单击trace.
+
+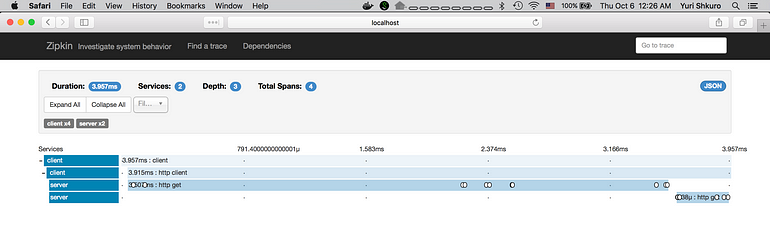
+
+在这里,我们看到以下跨度:
+
+1. 由服务生成的称为“client”的顶级(根)跨度也称为“client”,它跨越整个时间轴 3.957 毫秒。
+2. 下一级(子)跨度称为“http 客户端”,也是由“客户端”服务生成的。这个跨度是由**go-stdlib**库自动创建的,跨越整个 HTTP 会话。
+3. 由名为“server”的服务生成的两个名为“http get”的跨度。这有点误导,因为这些跨度中的每一个实际上在内部都由两部分组成,客户端提交的数据和服务器提交的数据。Zipkin UI 总是选择接收服务的名称显示在左侧。这两个跨度表示对“/”端点的第一个请求,在收到重定向响应后,对“/gettime”端点的第二个请求。
+
+另请注意,最后两个跨度在时间轴上显示白点。如果我们将鼠标悬停在其中一个点上,我们将看到它们实际上是 ClientTrace 捕获的事件,例如 DNSStart:
+
+您还可以单击每个跨度以查找更多详细信息,包括带时间戳的日志和键值标签。例如,单击第一个“http get”跨度会显示以下弹出窗口:
+
+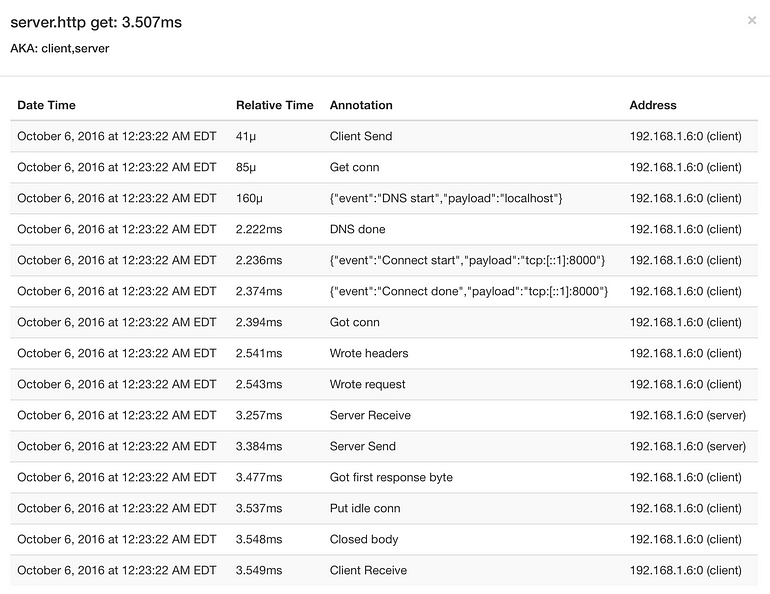
+
+在这里,我们看到两种类型的事件。从客户端和服务器的角度来看的整体开始/结束事件:客户端发送(请求),服务器接收(请求),服务器发送(响应),客户端接收(响应)。**在它们之间,我们看到go-stdlib**检测记录到跨度的其他事件,因为它们是由**httptrace**报告的,例如从 0.16 毫秒开始并在 2.222 毫秒完成的 DNS 查找、建立连接以及发送/接收请求/响应数据。
+
+这是显示跨度的键/值标签的同一弹出窗口的延续。标签与任何时间戳无关,只是提供有关跨度的元数据。在这里,我们可以看到在哪个 URL 发出请求、收到的**301**响应代码(重定向)、运行客户端的主机名(屏蔽)以及有关跟踪器实现的一些信息,例如客户端库版本“Go- 1.6”。
+
+第 4 个跨度的细节类似。需要注意的一点是,第 4 个跨度要短得多,因为没有 DNS 查找延迟,并且它针对状态代码为 200 的 /gettime 端点
+
+
+
+## 6.跟踪器
+
+跟踪器是 OpenTracing API 的实际实现。在我的示例中,我使用了https://github.com/uber/jaeger-client-go,它是来自 Uber 的分布式跟踪系统 Jaeger 的与 OpenTracing 兼容的客户端库。
+
+```
+package main
+
+import (
+ "flag"
+ "log"
+
+ "github.com/uber/jaeger-client-go"
+ "github.com/uber/jaeger-client-go/transport/zipkin"
+)
+
+var (
+ zipkinURL = flag.String("url",
+ "http://localhost:9411/api/v1/spans", "Zipkin server URL")
+ serverPort = flag.String("port", "8000", "server port")
+ actorKind = flag.String("actor", "server", "server or client")
+)
+
+const (
+ server = "server"
+ client = "client"
+)
+
+func main() {
+ flag.Parse()
+
+ if *actorKind != server && *actorKind != client {
+ log.Fatal("Please specify '-actor server' or '-actor client'")
+ }
+
+ // Jaeger tracer can be initialized with a transport that will
+ // report tracing Spans to a Zipkin backend
+ transport, err := zipkin.NewHTTPTransport(
+ *zipkinURL,
+ zipkin.HTTPBatchSize(1),
+ zipkin.HTTPLogger(jaeger.StdLogger),
+ )
+ if err != nil {
+ log.Fatalf("Cannot initialize HTTP transport: %v", err)
+ }
+ // create Jaeger tracer
+ tracer, closer := jaeger.NewTracer(
+ *actorKind,
+ jaeger.NewConstSampler(true), // sample all traces
+ jaeger.NewRemoteReporter(transport, nil),
+ )
+ // Close the tracer to guarantee that all spans that could
+ // be still buffered in memory are sent to the tracing backend
+ defer closer.Close()
+ if *actorKind == server {
+ runServer(tracer)
+ return
+ }
+ runClient(tracer)
+}
+
+```
+
diff --git a/_posts/2022-07-13-test-markdown.md b/_posts/2022-07-13-test-markdown.md
new file mode 100644
index 000000000000..078d153fa7fa
--- /dev/null
+++ b/_posts/2022-07-13-test-markdown.md
@@ -0,0 +1,726 @@
+---
+layout: post
+title: RPC应用
+subtitle: RPC 代指远程过程调用(Remote Procedure Call),它的调用包含了传输协议和编码(对象序列)协议等等,允许运行于一台计算机的程序调用另一台计算机的子程序,而开发人员无需额外地为这个交互作用编程,因此我们也常常称 RPC 调用,就像在进行本地函数调用一样方便。
+tags: [RPC]
+---
+# RPC应用
+
+> 写这篇文章的起源是,,,,,,,,对,没错,就是为了回顾一波,发现在回顾的过程中 还是有很多很多地方之前学习的不够清晰。
+
+首先我们将对 gRPC 和 Protobuf 进行介绍,然后会在接下来会对两者做更进一步的使用和详细介绍。
+
+## 1.什么是 RPC
+
+RPC 代指远程过程调用(Remote Procedure Call),它的调用包含了传输协议和编码(对象序列)协议等等,允许运行于一台计算机的程序调用另一台计算机的子程序,而**开发人员无需额外地为这个交互作用编程**,因此我们也常常称 RPC 调用,就像在进行本地函数调用一样方便。
+
+> 开发人员无需额外地为这个交互作用编程。
+
+## 2.gRPC
+
+> gRPC 是一个高性能、开源和通用的 RPC 框架,面向移动和基于 HTTP/2 设计。目前提供 C、Java 和 Go 语言等等版本,分别是:grpc、grpc-java、grpc-go,其中 C 版本支持 C、C++、Node.js、Python、Ruby、Objective-C、PHP 和 C# 支持。
+
+gRPC 基于 HTTP/2 标准设计,带来诸如双向流、流控、头部压缩、单 TCP 连接上的多复用请求等特性。这些特性使得其在移动设备上表现更好,在一定的情况下更节省空间占用。
+
+gRPC 的接口描述语言(Interface description language,缩写 IDL)使用的是 Protobuf,都是由 Google 开源的。
+
+> gRPC 使用Protobuf 作为接口描述语言。
+
+#### gRPC 调用模型
+
+
+
+1. 客户端(gRPC Stub)在程序中调用某方法,发起 RPC 调用。
+2. 对请求信息使用 Protobuf 进行对象序列化压缩(IDL)。
+3. 服务端(gRPC Server)接收到请求后,解码请求体,进行业务逻辑处理并返回。
+4. 对响应结果使用 Protobuf 进行对象序列化压缩(IDL)。
+5. 客户端接受到服务端响应,解码请求体。回调被调用的 A 方法,唤醒正在等待响应(阻塞)的客户端调用并返回响应结果。
+
+## 3. Protobuf
+
+> Protocol Buffers(Protobuf)是一种与语言、平台无关,可扩展的序列化结构化数据的数据描述语言,我们常常称其为 IDL,常用于通信协议,数据存储等等,相较于 JSON、XML,它更小、更快,因此也更受开发人员的青眯。
+
+### 基本语法
+
+```
+syntax = "proto3";
+
+package helloworld;
+
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+}
+
+message HelloRequest {
+ string name = 1;
+}
+
+message HelloReply {
+ string message = 1;
+}
+```
+
+1. 第一行(非空的非注释行)声明使用 `proto3` 语法。如果不声明,将默认使用 `proto2` 语法。同时建议无论是用 v2 还是 v3 版本,都应当进行显式声明。而在版本上,目前主流推荐使用 v3 版本。
+2. 定义名为 `Greeter` 的 RPC 服务(Service),其包含 RPC 方法 `SayHello`,入参为 `HelloRequest` 消息体(message),出参为 `HelloReply` 消息体。
+3. 定义 `HelloRequest`、`HelloReply` 消息体,每一个消息体的字段包含三个属性:类型、字段名称、字段编号。在消息体的定义上,除类型以外均不可重复。
+
+在编写完.proto 文件后,我们一般会进行编译和生成对应语言的 proto 文件操作,这个时候 Protobuf 的编译器会根据选择的语言不同、调用的插件情况,生成相应语言的 Service Interface Code 和 Stubs。
+
+### 基本数据类型
+
+在生成了对应语言的 proto 文件后,需要注意的是 protobuf 所生成出来的数据类型并非与原始的类型完全一致,因此需要有一个基本的了解,下面是我列举了的一些常见的类型映射,如下表:
+
+| .proto Type | C++ Type | Java Type | Go Type | PHP Type |
+| ----------- | -------- | ---------- | ------- | -------------- |
+| double | double | double | float64 | float |
+| float | float | float | float32 | float |
+| int32 | int32 | int | int32 | integer |
+| int64 | int64 | long | int64 | integer/string |
+| uint32 | uint32 | int | uint32 | integer |
+| uint64 | uint64 | long | uint64 | integer/string |
+| sint32 | int32 | int | int32 | integer |
+| sint64 | int64 | long | int64 | integer/string |
+| fixed32 | uint32 | int | uint32 | integer |
+| fixed64 | uint64 | long | uint64 | integer/string |
+| sfixed32 | int32 | int | int32 | integer |
+| sfixed64 | int64 | long | int64 | integer/string |
+| bool | bool | boolean | bool | boolean |
+| string | string | String | string | string |
+| bytes | string | ByteString | []byte | string |
+
+## 4.gRPC 与 RESTful API 对比
+
+| 特性 | gRPC | RESTful API |
+| ---------- | ---------------------- | -------------------- |
+| 规范 | 必须.proto | 可选 OpenAPI |
+| 协议 | HTTP/2 | 任意版本的 HTTP 协议 |
+| 有效载荷 | Protobuf(小、二进制) | JSON(大、易读) |
+| 浏览器支持 | 否(需要 grpc-web) | 是 |
+| 流传输 | 客户端、服务端、双向 | 客户端、服务端 |
+| 代码生成 | 是 | OpenAPI+ 第三方工具 |
+
+#### 性能
+
+gRPC 使用的 IDL 是 Protobuf,Protobuf 在客户端和服务端上都能快速地进行序列化,并且序列化后的结果较小,能够有效地节省传输占用的数据大小。另外众多周知,gRPC 是基于 HTTP/2 协议进行设计的,有非常显著的优势。
+
+另外常常会有人问,为什么是 Protobuf,为什么 gRPC 不用 JSON、XML 这类 IDL 呢,我想主要有如下原因:
+
+- 在定义上更简单,更明了。
+- 数据描述文件只需原来的 1/10 至 1/3。
+- 解析速度是原来的 20 倍至 100 倍。
+- 减少了二义性。
+- 生成了更易使用的数据访问类。
+- 序列化和反序列化速度快。
+- 开发者本身在传输过程中并不需要过多的关注其内容。
+
+#### 代码生成
+
+在代码生成上,我们只需要一个 proto 文件就能够定义 gRPC 服务和消息体的约定,并且 gRPC 及其生态圈提供了大量的工具从 proto 文件中生成服务基类、消息体、客户端等等代码,也就是客户端和服务端共用一个 proto 文件就可以了,保证了 IDL 的一致性且减少了重复工作。
+
+> **客户端和服务端共用一个 proto 文件**
+
+#### 流传输
+
+gRPC 通过 HTTP/2 对流传输提供了大量的支持:
+
+1. Unary RPC:一元 RPC。
+2. Server-side streaming RPC:服务端流式 RPC。
+3. Client-side streaming RPC:客户端流式 RPC。
+4. Bidirectional streaming RPC:双向流式 RPC。
+
+#### 超时和取消
+
+并且根据 Go 语言的上下文(context)的特性,截止时间的传递是可以一层层传递下去的,也就是我们可以通过一层层 gRPC 调用来进行上下文的传播截止日期和取消事件,有助于我们处理一些上下游的连锁问题等等场景。
+
+# Protobuf 的使用
+
+### protoc 安装
+
+```
+wget https://github.com/google/protobuf/releases/download/v3.11.2/protobuf-all-3.11.2.zip
+$ unzip protobuf-all-3.11.2.zip && cd protobuf-3.11.2/
+$ ./configure
+$ make
+$ make install
+```
+
+##### protoc 插件安装
+
+Go 语言就是 protoc-gen-go 插件
+
+```
+go get -u github.com/golang/protobuf/protoc-gen-go@v1.3.2
+```
+
+##### 将所编译安装的 Protoc Plu
+
+```
+mv $GOPATH/bin/protoc-gen-go /usr/local/go/bin/
+```
+
+这里的命令操作并非是绝对必须的,主要目的是将二进制文件 protoc-gen-go 移动到 bin 目录下,让其可以直接运行 protoc-gen-go 执行,只要达到这个效果就可以了。
+
+## 初始化 Demo 项目
+
+在初始化目录结构后,新建 server、client、proto 目录,便于后续的使用,最终目录结构如下:
+
+```
+grpc-demo
+├── go.mod
+├── client
+├── proto
+└── server
+```
+
+##### 编译和生成 proto 文件
+
+```
+syntax = "proto3";
+
+package helloworld;
+
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+}
+
+message HelloRequest {
+ string name = 1;
+}
+
+message HelloReply {
+ string message = 1;
+}
+```
+
+##### 生成 proto 文件
+
+```
+$ protoc --go_out=plugins=grpc:. ./proto/*.proto
+```
+
+##### 生成的.pb.go 文件
+
+```
+type HelloRequest struct {
+ Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
+ ...
+}
+
+func (m *HelloRequest) Reset() { *m = HelloRequest{} }
+func (m *HelloRequest) String() string { return proto.CompactTextString(m) }
+func (*HelloRequest) ProtoMessage() {}
+func (*HelloRequest) Descriptor() ([]byte, []int) {
+ return fileDescriptor_4d53fe9c48eadaad, []int{0}
+}
+func (m *HelloRequest) GetName() string {...}
+```
+
+ HelloRequest 类型,其包含了一组 Getters 方法,能够提供便捷的取值方式,并且处理了一些空指针取值的情况,还能够通过 Reset 方法来重置该参数。而该方法通过实现 ProtoMessage 方法,以此表示这是一个实现了 proto.Message 的接口。另外 HelloReply 类型也是类似的生成结果,因此不重复概述。
+
+接下来我们看到.pb.go 文件的初始化方法,其中比较特殊的就是 fileDescriptor 的相关语句,如下:
+
+```
+func init() {
+ proto.RegisterType((*HelloRequest)(nil), "helloworld.HelloRequest")
+ proto.RegisterType((*HelloReply)(nil), "helloworld.HelloReply")
+}
+
+func init() { proto.RegisterFile("proto/helloworld.proto", fileDescriptor_4d53fe9c48eadaad) }
+
+var fileDescriptor_4d53fe9c48eadaad = []byte{
+ 0x1f, 0x8b, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0xff, 0xe2, 0x12, 0x2b, 0x28, 0xca, 0x2f,
+ ...
+}
+```
+
+`fileDescriptor_4d53fe9c48eadaad` 表示的是一个经过编译后的 proto 文件,是对 proto 文件的整体描述,其包含了 proto 文件名、引用(import)内容、包(package)名、选项设置、所有定义的消息体(message)、所有定义的枚举(enum)、所有定义的服务( service)、所有定义的方法(rpc method)等等内容,可以认为就是整个 proto 文件的信息都能够取到。
+
+同时在我们的每一个 Message Type 中都包含了 Descriptor 方法,Descriptor 代指对一个消息体(message)定义的描述,而这一个方法则会在 fileDescriptor 中寻找属于自己 Message Field 所在的位置再进行返回,如下:
+
+```
+func (*HelloRequest) Descriptor() ([]byte, []int) {
+ return fileDescriptor_4d53fe9c48eadaad, []int{0}
+}
+
+func (*HelloReply) Descriptor() ([]byte, []int) {
+ return fileDescriptor_4d53fe9c48eadaad, []int{1}
+}
+```
+
+接下来我们再往下看可以看到 GreeterClient 接口,因为 Protobuf 是客户端和服务端可共用一份.proto 文件的,因此除了存在数据描述的信息以外,还会存在客户端和服务端的相关内部调用的接口约束和调用方式的实现,在后续我们在多服务内部调用的时候会经常用到,如下:
+
+```
+type GreeterClient interface {
+ SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error)
+}
+```
+
+```
+type greeterClient struct {
+ cc *grpc.ClientConn
+}
+```
+
+```
+func NewGreeterClient(cc *grpc.ClientConn) GreeterClient {
+ return &greeterClient{cc}
+}
+```
+
+```
+func (c *greeterClient) SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+```
+
+## 更多的类型支持
+
+### 通用类型
+
+在 Protobuf 中一共支持 double、float、int32、int64、uint32、uint64、sint32、sint64、fixed32、fixed64、sfixed32、sfixed64、bool、string、bytes 类型
+
+```
+message HelloRequest {
+ bytes name = 1;
+}
+```
+
+另外我们常常会遇到需要传递动态数组的情况,在 protobuf 中,我们可以使用 repeated 关键字,如果一个字段被声明为 repeated,那么该字段可以重复任意次(包括零次),重复值的顺序将保留在 protobuf 中,将重复字段视为动态大小的数组,如下:
+
+```
+message HelloRequest {
+ repeated string name = 1;
+}
+```
+
+### 嵌套类型
+
+```
+message HelloRequest {
+ message World {
+ string name = 1;
+ }
+
+ repeated World worlds = 1;
+}
+```
+
+```
+message World {
+ string name = 1;
+}
+
+message HelloRequest {
+ repeated World worlds = 1;
+}
+```
+
+第一种是将 World 消息体定义在 HelloRequest 消息体中,也就是其归属在消息体 HelloRequest 下,若要调用则需要使用 `HelloRequest.World` 的方式,外部才能引用成功。
+
+第二种是将 World 消息体定义在外部,一般比较推荐使用这种方式,清晰、方便。
+
+### Oneof
+
+如果希望的消息体可以包含多个字段,但前提条件是最多同时只允许设置一个字段,那么就可以使用 oneof 关键字来实现这个功能,如下:
+
+```
+message HelloRequest {
+ oneof name {
+ string nick_name = 1;
+ string true_name = 2;
+ }
+}
+```
+
+### Enum
+
+```
+enum NameType {
+ NickName = 0;
+ TrueName = 1;
+}
+
+message HelloRequest {
+ string name = 1;
+ NameType nameType = 2;
+}
+```
+
+### Map
+
+```
+message HelloRequest {
+ map names = 2;
+}
+```
+
+# gRPC
+
+### gRPC 的四种调用方式
+
+1. Unary RPC:一元 RPC。
+
+2. Server-side streaming RPC:服务端流式 RPC。
+
+3. Client-side streaming RPC:客户端流式 RPC。
+
+4. Bidirectional streaming RPC:双向流式 RPC。
+
+ 不同的调用方式往往代表着不同的应用场景,我们接下来将一同深入了解各个调用方式的实现和使用场景,在下述代码中,我们统一将项目下的 proto 引用名指定为 pb,并设置端口号都由外部传入,如下:
+
+```
+import (
+ ...
+ // 设置引用别名
+ pb "github.com/go-programming-tour-book/grpc-demo/proto"
+)
+
+var port string
+
+func init() {
+ flag.StringVar(&port, "p", "8000", "启动端口号")
+ flag.Parse()
+}
+```
+
+我们下述的调用方法都是在 `server` 目录下的 server.go 和 `client` 目录的 client.go 中完成,需要注意的该两个文件的 package 名称应该为 main(IDE 默认会创建与目录名一致的 package 名称),这样子的 main 方法才能够被调用,并且在**本章中我们的 proto 引用都会以引用别名 pb 来进行调用**。
+
+### Unary RPC:一元 RPC
+
+一元 RPC,也就是是单次 RPC 调用,简单来讲就是客户端发起一次普通的 RPC 请求,响应,是最基础的调用类型,也是最常用的方式,大致如图:
+
+
+
+#### Proto
+
+```
+rpc SayHello (HelloRequest) returns (HelloReply) {};
+```
+
+#### Server
+
+```
+type GreeterServer struct{}
+
+func (s *GreeterServer) SayHello(ctx context.Context, r *pb.HelloRequest) (*pb.HelloReply, error) {
+ return &pb.HelloReply{Message: "hello.world"}, nil
+}
+
+func main() {
+ server := grpc.NewServer()
+ pb.RegisterGreeterServer(server, &GreeterServer{})
+ lis, _ := net.Listen("tcp", ":"+port)
+ server.Serve(lis)
+}
+```
+
+- **创建 gRPC Server 对象,可以理解为它是 Server 端的抽象对象。**
+- **将 GreeterServer(其包含需要被调用的服务端接口)注册到 gRPC Server。 的内部注册中心。这样可以在接受到请求时,通过内部的 “服务发现”,发现该服务端接口并转接进行逻辑处理。**
+- **创建 Listen,监听 TCP 端口。**
+- **gRPC Server 开始 lis.Accept,直到 Stop 或 GracefulStop。**
+
+#### Client
+
+```
+func main() {
+ conn, _ := grpc.Dial(":"+port, grpc.WithInsecure())
+ defer conn.Close()
+
+ client := pb.NewGreeterClient(conn)
+ _ = SayHello(client)
+}
+
+func SayHello(client pb.GreeterClient) error {
+ resp, _ := client.SayHello(context.Background(), &pb.HelloRequest{Name: "eddycjy"})
+ log.Printf("client.SayHello resp: %s", resp.Message)
+ return nil
+}
+```
+
+What is important?
+
+- ```
+ pb.NewGreeterClient()
+ pb.RegisterGreetServer()
+ //也就是说Protobuf 及其编译工具的使用 就是为我们自动生成这个两个函数
+ ```
+
+- ```
+ pb.NewGreeterClient() 需要一个grpc.Dial(":"+port, grpc.WithInsecure())客户端作为参数
+ ```
+
+- ```
+ pb.RegisterGreetServer() 不仅需要一个grpc.NewServer()服务端,还需要自己抽象出的服务端,&GreeterServer{}
+ ```
+
+### Server-side streaming RPC:服务端流式 RPC
+
+> 简单来讲就是客户端发起一次普通的 RPC 请求,服务端通过流式响应多次发送数据集,客户端 Recv 接收数据集。大致如图:
+
+
+
+#### Proto
+
+```protobuf
+rpc SayList (HelloRequest) returns (stream HelloReply) {};
+```
+
+#### Server
+
+```
+func (s *GreeterServer) SayList(r *pb.HelloRequest, stream pb.Greeter_SayListServer) error {
+ for n := 0; n <= 6; n++ {
+ _ = stream.Send(&pb.HelloReply{Message: "hello.list"})
+ }
+ return nil
+}
+```
+
+在 Server 端,主要留意 `stream.Send` 方法,通过阅读源码,可得知是 protoc 在生成时,根据定义生成了各式各样符合标准的接口方法。最终再统一调度内部的 `SendMsg` 方法,该方法涉及以下过程:
+
+- 消息体(对象)序列化。
+- 压缩序列化后的消息体。
+- 对正在传输的消息体增加 5 个字节的 header(标志位)。
+- 判断压缩 + 序列化后的消息体总字节长度是否大于预设的 maxSendMessageSize(预设值为 `math.MaxInt32`),若超出则提示错误。
+- 写入给流的数据集。
+
+#### Client
+
+```
+func SayList(client pb.GreeterClient, r *pb.HelloRequest) error {
+ stream, _ := client.SayList(context.Background(), r)
+ for {
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ break
+ }
+ if err != nil {
+ return err
+ }
+
+ log.Printf("resp: %v", resp)
+ }
+
+ return nil
+}
+```
+
+#### what is important?
+
+```
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+ rpc SayList (HelloRequest) returns (stream HelloReply) {};
+}
+
+type GreeterServer struct{}
+
+func (s *GreeterServer) SayList(r *pb.HelloRequest, stream pb.Greeter_SayListServer) error {
+ for n := 0; n <= 6; n++ {
+ _ = stream.Send(&pb.HelloReply{Message: "hello.list"})
+ }
+ return nil
+}
+
+func (s *GreeterServer) SayHello(ctx context.Context, r *pb.HelloRequest) (*pb.HelloReply, error) {
+ return &pb.HelloReply{Message: "hello.world"}, nil
+}
+
+//服务端调用的是 pb.Greeter_SayListServer.Send()
+//客户端调用的是 pb.GreeterClient.SayList()
+
+```
+
+1. service Greeter 对应 `pb.ResisterGreetService()`
+2. 调用`pb.ResisterGreetService()`注册 GreeterServer{}
+3. SayList 实际调用 pb.Greeter_SayListServer.Send()来实现流输出.
+4. SayHello实际调用 `func (s *GreeterServer) SayHello(ctx context.Context, r *pb.HelloRequest) (*pb.HelloReply, error) {`
+ `return &pb.HelloReply{Message: "hello.world"}, nil`
+ `}`函数直接写入
+
+```
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+ rpc SayList (HelloRequest) returns (stream HelloReply) {};
+}
+```
+
+```
+type greeterClient struct {
+ cc *grpc.ClientConn
+}
+```
+
+```
+func NewGreeterClient(cc *grpc.ClientConn) GreeterClient {
+ return &greeterClient{cc}
+}
+```
+
+```
+func (c *greeterClient) SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+```
+
+```
+func (c *greeterClient) SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+```
+
+```
+func (c *greeterClient) SayList(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+
+```
+
+```
+func (h *HelloReply) Recv(){
+ //是对ClientStream.RecvMsg()的封装
+ //RecvMsg 方法会从流中读取完整的 gRPC 消息体
+}
+```
+
+- `SayHello()`调用`greeterClient.cc.Invoke` 实际是`grpc.ClientConn.Invoke`
+
+```
+type greeterClient struct {
+ cc *grpc.ClientConn
+}
+```
+
+- `SayList()`调用`ClientStream.RecvMsg()`
+
+### Client-side streaming RPC:客户端流式 RPC
+
+> 客户端流式 RPC,单向流,客户端通过流式发起**多次** RPC 请求给服务端,服务端发起**一次**响应给客户端,大致如图:
+
+
+
+#### Proto
+
+```
+rpc SayRecord(stream HelloRequest) returns (HelloReply) {};
+```
+
+#### Server
+
+```
+func (s *GreeterServer) SayRecord(stream pb.Greeter_SayRecordServer) error {
+ for {
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ return stream.SendAndClose(&pb.HelloReply{Message:"say.record"})
+ }
+ if err != nil {
+ return err
+ }
+
+ log.Printf("resp: %v", resp)
+ }
+
+ return nil
+}
+```
+
+#### Client
+
+```
+func SayRecord(client pb.GreeterClient, r *pb.HelloRequest) error {
+ stream, _ := client.SayRecord(context.Background())
+ for n := 0; n < 6; n++ {
+ _ = stream.Send(r)
+ }
+ resp, _ := stream.CloseAndRecv()
+
+ log.Printf("resp err: %v", resp)
+ return nil
+}
+```
+
+在 Server 端的 `stream.SendAndClose`,与 Client 端 `stream.CloseAndRecv` 是配套使用的方法。
+
+### Bidirectional streaming RPC:双向流式 RPC
+
+> 双向流式 RPC,顾名思义是双向流,由客户端以流式的方式发起请求,服务端同样以流式的方式响应请求。
+>
+> 首个请求一定是 Client 发起,但具体交互方式(谁先谁后、一次发多少、响应多少、什么时候关闭)根据程序编写的方式来确定(可以结合协程)。
+>
+> 假设该双向流是**按顺序发送**的话,大致如图:
+
+
+
+#### Proto
+
+```
+rpc SayRoute(stream HelloRequest) returns (stream HelloReply) {};
+```
+
+#### Server
+
+```
+func (s *GreeterServer) SayRoute(stream pb.Greeter_SayRouteServer) error {
+ n := 0
+ for {
+ _ = stream.Send(&pb.HelloReply{Message: "say.route"})
+
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ return nil
+ }
+ if err != nil {
+ return err
+ }
+
+ n++
+ log.Printf("resp: %v", resp)
+ }
+}
+```
+
+#### Client
+
+```
+func SayRoute(client pb.GreeterClient, r *pb.HelloRequest) error {
+ stream, _ := client.SayRoute(context.Background())
+ for n := 0; n <= 6; n++ {
+ _ = stream.Send(r)
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ break
+ }
+ if err != nil {
+ return err
+ }
+
+ log.Printf("resp err: %v", resp)
+ }
+
+ _ = stream.CloseSend()
+
+ return nil
+}
+```
+
diff --git a/_posts/2022-07-14-test-markdown.md b/_posts/2022-07-14-test-markdown.md
new file mode 100644
index 000000000000..02d2b7757bd4
--- /dev/null
+++ b/_posts/2022-07-14-test-markdown.md
@@ -0,0 +1,89 @@
+---
+layout: post
+title: 适配器模式
+subtitle: 亦称 封装器模式、Wrapper、Adapter
+tags: [设计模式]
+---
+
+# 适配器模式
+
+> **亦称:** 封装器模式、Wrapper、Adapter
+
+**适配器模式**是一种结构型设计模式, 它能使接口不兼容的对象能够相互合作。
+
+
+
+假如正在开发一款股票市场监测程序, 它会从不同来源下载 XML 格式的股票数据, 然后向用户呈现出美观的图表。在开发过程中, 决定在程序中整合一个第三方智能分析函数库。 但是遇到了一个问题, 那就是分析函数库只兼容 JSON 格式的数据。
+
+
+
+可以修改程序库来支持 XML。 但是, 这可能需要修改部分依赖该程序库的现有代码。 甚至还有更糟糕的情况, 可能根本没有程序库的源代码, 从而无法对其进行修改。
+
+## 解决
+
+创建一个*适配器*。 这是一个特殊的对象, 能够转换对象接口, 使其能与其他对象进行交互。
+
+适配器模式通过**封装对象**将复杂的转换过程隐藏于幕后。 **被封装的对象**甚至察觉不到适配器的存在。
+
+适配器不仅可以转换不同格式的数据, 其还有助于**不同接口的对象之间的合作**。 它的运作方式如下:
+
+1. **适配器实现**与其中一个**现有对象**兼容**的接口**。
+2. **现有对象**可以使用该接口安全地调用适配器方法。
+3. **适配器方法被调用**后将以另一个对象兼容的格式和顺序将请求传递给该对象。
+
+有时甚至可以创建一个双向适配器来实现双向转换调用。
+
+> 谁适配谁? A 适配 B 、B 是已经有的库和接口,然后我们去适配, 所以要找到 B 的接口 ,然后用我们需要的适配器去实现 B 的接口 ,适配器在实现B的接口的时候,要做的事就是 在 B的接口对应的函数里面,调用适配器对应的想要调用的函数,那么具体适配器想要调用的函数具体是什么就要看 想要让 A 如何去适配 B ,如果 A 适配 B 我这里的A 是一系列自己写的函数,那么适配器就搞个函数类型去适配 B ,如果我这里是一堆对象想要去适配 B 那么我就写个适配器对象。第一种在http编程里面有很好的体现。
+
+```
+//golang 的标准库 net/http 提供了 http 编程有关的接口,封装了内部TCP连接和报文解析的复杂琐碎的细节,使用者只需要和 http.request 和 http.ResponseWriter 两个对象交互就行。也就是说,我们只要写一个 handler,请求会通过参数传递进来,而它要做的就是根据请求的数据做处理,把结果写到 Response 中。
+
+package main
+
+import (
+ "io"
+ "net/http"
+)
+
+type helloHandler struct{}
+
+func (h *helloHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
+ w.Write([]byte("Hello, world!"))
+}
+
+func main() {
+ http.Handle("/", &helloHandler{})
+ http.ListenAndServe(":12345", nil)
+}
+// helloHandler实现了 ServeHTTP 方法
+// 只要实现了 ServeHTTP 方法的对象都可以作为 Handler 传给http.Handle()
+```
+
+```
+//接口原型
+type Handler interface {
+ ServeHTTP(ResponseWriter, *Request)
+}
+```
+
+```
+//不便:每次写 Handler 的时候,都要定义一个类型,然后编写对应的 ServeHTTP 方法
+
+//提供了 http.HandleFunc 方法,允许直接把特定类型的函数作为 handler
+//怎么做的
+// The HandlerFunc type is an adapter to allow the use of
+// ordinary functions as HTTP handlers. If f is a function
+// with the appropriate signature, HandlerFunc(f) is a
+// Handler object that calls f.
+type HandlerFunc func(ResponseWriter, *Request)
+
+// ServeHTTP calls f(w, r).
+func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
+ f(w, r)
+}
+
+```
+
+**`type HandlerFunc func(ResponseWriter, *Request) ` 就是一个适配器**
+
+自动给 `f` 函数添加了 `HandlerFunc` 这个壳,最终调用的还是 `ServerHTTP`,只不过会直接使用 `f(w, r)`。这样封装的好处是:使用者可以专注于业务逻辑的编写,省去了很多重复的代码处理逻辑。如果只是简单的 Handler,会直接使用函数;如果是需要传递更多信息或者有复杂的操作,会使用上部分的方法。
\ No newline at end of file
diff --git a/_posts/2022-07-15-test-markdown.md b/_posts/2022-07-15-test-markdown.md
new file mode 100644
index 000000000000..3b5774610a02
--- /dev/null
+++ b/_posts/2022-07-15-test-markdown.md
@@ -0,0 +1,33 @@
+---
+layout: post
+title: 关于Metrics, tracing, and logging 的不同
+subtitle: 从本质来看........
+tags: [Metric]
+---
+# 关于Metrics, tracing, and logging 的不同
+
+
+
+## 1.`metrics`
+
+我认为`metrics`的定义特征是它们是可聚合`aggregatable`的:它们是在一段时间内组成单个逻辑量规、计数器或直方图的原子。例如:队列的当前深度可以建模为一个计量器,其更新与 last-writer-win 语义聚合;传入的 HTTP 请求的数量可以建模为一个计数器,其更新通过简单的加法聚合;并且观察到的请求持续时间可以建模为直方图,其更新聚合到时间桶中并产生统计摘要。
+
+
+
+## 2.`logging `
+
+我认`logging` 的定义特征是它处理离散事件。例如:应用程序调试或错误消息通过logs实例发送到 终端或者文件流输出。审计跟踪`audit-trail`事件通过 Kafka 推送到 BigTable 等数据湖;或从服务调用中提取的特定于请求的元数据并发送到像 NewRelic 这样的错误跟踪服务。
+
+## 3.` tracking `
+
+我认为 tracking 的唯一定义特征**是**它处理请求范围内的信息。可以绑定到系统中单个事务对象的生命周期的任何数据或元数据。例如:出站 `RPC` 到远程服务的持续时间;发送到数据库的实际 `SQL` 查询的文本;或入站 HTTP 请求的相关 ID。
+
+通过这些定义,我们可以标记重叠部分。
+
+
+
+当然,云原生应用程序的许多典型工具最终都将是请求范围的,因此在更广泛的跟踪上下文中讨论可能是有意义的。但是我们现在可以观察到,并非*所有*仪器都绑定到请求生命周期:例如逻辑组件诊断信息或流程生命周期细节,它们与任何离散请求正交。因此,例如,并非所有指标或日志都可以硬塞到跟踪系统中——至少,不是没有一些工作。或者,我们可能会意识到直接在我们的应用程序中检测指标会给我们带来强大的好处,比如]`prometheus.io/docs/querying/basics`估我们车队的实时视图;相比之下,将指标硬塞到日志管道中可能会迫使我们放弃其中的一些优势。
+
+此外,我观察到一个奇怪的操作细节作为这种可视化的副作用。在这三个领域中,metrics往往需要最少的资源来管理,因为它们的本质是“压缩”得很好。相反,**logging**往往是压倒性的,经常超过它报告的生产流量。tracking可能位于中间的某个位置。
+
+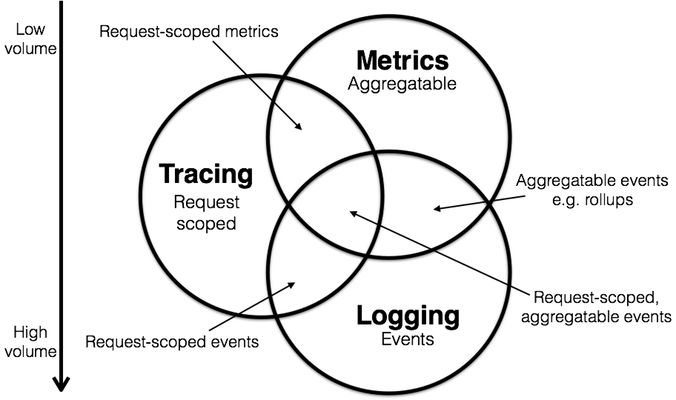
\ No newline at end of file
diff --git a/_posts/2022-07-16-test-markdown.md b/_posts/2022-07-16-test-markdown.md
new file mode 100644
index 000000000000..a7a60e81c04f
--- /dev/null
+++ b/_posts/2022-07-16-test-markdown.md
@@ -0,0 +1,463 @@
+---
+layout: post
+title: 装饰器模式
+subtitle: 亦称: 装饰者模式、装饰器模式、Wrapper、Decorator
+tags: [设计模式]
+---
+# 装饰器模式
+
+亦称: 装饰者模式、装饰器模式、Wrapper、Decorator
+
+
+
+**装饰模式**是一种结构型设计模式, 允许通过将对象放入包含行为的特殊封装对象中来为原对象绑定新的行为。
+
+- 对象放入包含行为的特殊封装对象
+- 特殊封装对象有新的行为
+
+### 场景
+
+假设正在开发一个提供通知功能的库, 其他程序可使用它向用户发送关于重要事件的通知。
+
+库的最初版本基于 `通知器``Notifier`类, 其中只有很少的几个成员变量, 一个构造函数和一个 `send`发送方法。 该方法可以接收来自客户端的消息参数, 并将该消息发送给一系列的邮箱, 邮箱列表则是通过构造函数传递给通知器的。 作为客户端的第三方程序仅会创建和配置通知器对象一次, 然后在有重要事件发生时对其进行调用。此后某个时刻, 会发现库的用户希望使用除邮件通知之外的功能。 许多用户会希望接收关于紧急事件的手机短信, 还有些用户希望在微信上接收消息, 而公司用户则希望在 QQ 上接收消息。
+
+
+
+每种通知类型都将作为通知器的一个子类得以实现。
+
+这有什么难的呢? 首先扩展 `通知器`类, 然后在新的子类中加入额外的通知方法。 现在客户端要对所需通知形式的对应类进行初始化, 然后使用该类发送后续所有的通知消息。
+
+### 问题
+
+但是很快有人会问: “为什么不同时使用多种通知形式呢? 如果房子着火了, 大概会想在所有渠道中都收到相同的消息吧。”
+
+可以尝试创建一个特殊子类来将多种通知方法组合在一起以解决该问题。 但这种方式会使得代码量迅速膨胀, 不仅仅是程序库代码, 客户端代码也会如此。
+
+
+
+### 解决
+
+- 当需要更改一个对象的行为时, 第一个跳入脑海的想法就是扩展它所属的类。 但是, 不能忽视继承可能引发的几个严重问题。
+
+- 继承是静态的。 无法在运行时更改已有对象的行为, 只能使用由不同子类创建的对象来替代当前的整个对象。
+
+ 也就是说,不能更改`Wechat Notiifier`已有的行为,只能用`QQNotifier`来替换。
+
+ ```
+ var notifier = new Notifier
+ notifier = Wechat Notiifier
+ //要更改行为
+ notifier = QQ Notifier
+ ```
+
+- 子类只能有一个父类。 大部分编程语言不允许一个类同时继承多个类的行为。
+
+其中一种方法是用*聚合*或*组合* , 而不是*继承*。 两者的工作方式几乎一模一样: 一个对象*包含*指向另一个对象的引用, 并将部分工作委派给引用对象; 继承中的对象则继承了父类的行为, 它们自己*能够*完成这些工作。
+
+可以使用这个新方法来轻松替换各种连接的 “小帮手” 对象, 从而能在运行时改变容器的行为。 一个对象可以使用多个类的行为, 包含多个指向其他对象的引用, 并将各种工作委派给引用对象。 聚合 (或组合) 组合是许多设计模式背后的关键原则 (包括装饰在内)。 记住这一点后, 让我们继续关于模式的讨论。
+
+
+
+*封装器*是装饰模式的别称, 这个称谓明确地表达了该模式的主要思想。 “封装器” 是一个能与其他 “目标” 对象连接的对象。 封装器包含与目标对象相同的一系列方法(与被封装对象实现相同的接口), 它会将所有接收到的请求委派给目标对象。 但是, 封装器可以在将请求委派给目标前后对其进行处理, 所以可能会改变最终结果。
+
+那么什么时候一个简单的封装器可以被称为是真正的装饰呢? 正如之前提到的, 封装器实现了与其封装对象相同的接口。 因此从客户端的角度来看, 这些对象是完全一样的。 封装器中的引用成员变量可以是遵循相同接口的任意对象。 这使得可以将一个对象放入多个封装器中, 并在对象中添加所有这些封装器的组合行为。
+
+- **封装器实现了与其封装对象相同的接口。 **
+- **将请求委派给目标前后对其进行处理**
+- **封装器中的引用成员变量可以是遵循相同接口的任意对象。**
+- 一个对象放入多个封装器中, 并在对象中添加所有这些封装器的组合行为
+
+比如在消息通知示例中, 我们可以将简单邮件通知行为放在基类 `通知器`中, 但将所有其他通知方法放入装饰中。
+
+
+
+实际与客户端进行交互的对象将是最后一个进入栈中的装饰对象。 由于所有的装饰都实现了与通知基类相同的接口, 客户端的其他代码并不在意自己到底是与 “纯粹” 的通知器对象, 还是与装饰后的通知器对象进行交互。
+
+我们可以使用相同方法来完成其他行为 (例如设置消息格式或者创建接收人列表)。 只要所有装饰都遵循相同的接口, 客户端就可以使用任意自定义的装饰来装饰对象。
+
+
+
+穿衣服是使用装饰的一个例子。 觉得冷时, 可以穿一件毛衣。 如果穿毛衣还觉得冷, 可以再套上一件夹克。 如果遇到下雨, 还可以再穿一件雨衣。 所有这些衣物都 “扩展” 了的基本行为, 但它们并不是的一部分, 如果不再需要某件衣物, 可以方便地随时脱掉。
+
+- “扩展” 了的基本行为, 但它们并不是的一部分.
+
+### 结构
+
+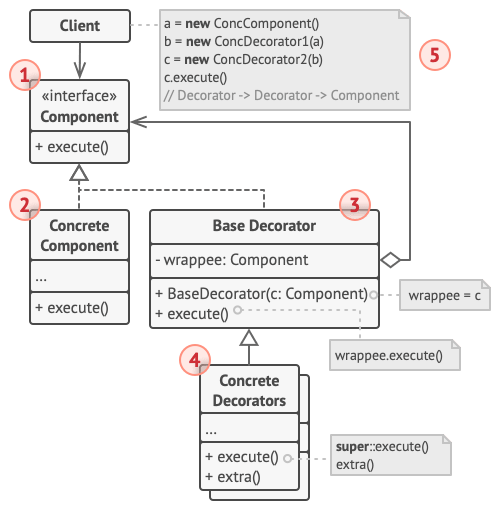
+
+1. **部件** (`Component`) 声明封装器和被封装对象的公用接口。
+2. **具体部件** (Concrete Component) 类是被封装对象所属的类。 它定义了基础行为, 但装饰类可以改变这些行为。
+3. **基础装饰** (`Base Decorator`) 类拥有一个指向被封装对象的引用成员变量。 该变量的类型应当被声明为通用部件接口, 这样它就可以引用具体的部件和装饰。 装饰基类会将所有操作委派给被封装的对象。
+4. **具体装饰类** (`Concrete Decorators`) 定义了可动态添加到部件的额外行为。 具体装饰类会重写装饰基类的方法, 并在调用父类方法之前或之后进行额外的行为。
+5. **客户端** (Client) 可以使用多层装饰来封装部件, 只要它能使用通用接口与所有对象互动即可。
+
+### 伪代码
+
+
+
+```
+// 装饰可以改变组件接口所定义的操作。
+interface DataSource is
+ method writeData(data)
+ method readData():data
+
+// 具体组件提供操作的默认实现。这些类在程序中可能会有几个变体。
+class FileDataSource implements DataSource is
+ constructor FileDataSource(filename) { ... }
+
+ method writeData(data) is
+ // 将数据写入文件。
+
+ method readData():data is
+ // 从文件读取数据。
+
+
+// 装饰基类和其他组件遵循相同的接口。该类的主要任务是定义所有具体装饰的封
+// 装接口。封装的默认实现代码中可能会包含一个保存被封装组件的成员变量,并
+// 且负责对其进行初始化。
+class DataSourceDecorator implements DataSource is
+ protected field wrappee: DataSource
+
+ constructor DataSourceDecorator(source: DataSource) is
+ wrappee = source
+
+ // 装饰基类会直接将所有工作分派给被封装组件。具体装饰中则可以新增一些
+ // 额外的行为。
+ method writeData(data) is
+ wrappee.writeData(data)
+
+ // 具体装饰可调用其父类的操作实现,而不是直接调用被封装对象。这种方式
+ // 可简化装饰类的扩展工作。
+ method readData():data is
+ return wrappee.readData()
+
+
+
+/ 具体装饰必须在被封装对象上调用方法,不过也可以自行在结果中添加一些内容。
+// 装饰必须在调用封装对象之前或之后执行额外的行为。
+class EncryptionDecorator extends DataSourceDecorator is
+ method writeData(data) is
+ // 1. 对传递数据进行加密。
+ // 2. 将加密后数据传递给被封装对象 writeData(写入数据)方法。
+
+ method readData():data is
+ // 1. 通过被封装对象的 readData(读取数据)方法获取数据。
+ // 2. 如果数据被加密就尝试解密。
+ // 3. 返回结果。
+
+ // 可以将对象封装在多层装饰中。
+class CompressionDecorator extends DataSourceDecorator is
+ method writeData(data) is
+ // 1. 压缩传递数据。
+ // 2. 将压缩后数据传递给被封装对象 writeData(写入数据)方法。
+
+ method readData():data is
+ // 1. 通过被封装对象的 readData(读取数据)方法获取数据。
+ // 2. 如果数据被压缩就尝试解压。
+ // 3. 返回结果。
+
+// 选项 1:装饰组件的简单示例
+class Application is
+ method dumbUsageExample() is
+ source = new FileDataSource("somefile.dat")
+ source.writeData(salaryRecords)
+ // 已将明码数据写入目标文件。
+
+ source = new CompressionDecorator(source)
+ source.writeData(salaryRecords)
+ // 已将压缩数据写入目标文件。
+
+ source = new EncryptionDecorator(source)
+ // 源变量中现在包含:
+ // Encryption > Compression > FileDataSource
+ source.writeData(salaryRecords)
+ // 已将压缩且加密的数据写入目标文件。
+
+// 选项 1:装饰组件的简单示例
+class Application is
+ method dumbUsageExample() is
+ source = new FileDataSource("somefile.dat")
+ source.writeData(salaryRecords)
+ // 已将明码数据写入目标文件。
+
+ source = new CompressionDecorator(source)
+ source.writeData(salaryRecords)
+ // 已将压缩数据写入目标文件。
+
+ source = new EncryptionDecorator(source)
+ // 源变量中现在包含:
+ // Encryption > Compression > FileDataSource
+ source.writeData(salaryRecords)
+ // 已将压缩且加密的数据写入目标文件。
+```
+
+```
+
+// 选项 2:客户端使用外部数据源。SalaryManager(工资管理器)对象并不关心
+// 数据如何存储。它们会与提前配置好的数据源进行交互,数据源则是通过程序配
+// 置器获取的。
+class SalaryManager is
+ field source: DataSource
+
+ constructor SalaryManager(source: DataSource) { ... }
+
+ method load() is
+ return source.readData()
+
+ method save() is
+ source.writeData(salaryRecords)
+ // ...其他有用的方法...
+
+
+// 程序可在运行时根据配置或环境组装不同的装饰堆桟。
+class ApplicationConfigurator is
+ method configurationExample() is
+ source = new FileDataSource("salary.dat")
+ if (enabledEncryption)
+ source = new EncryptionDecorator(source)
+ if (enabledCompression)
+ source = new CompressionDecorator(source)
+
+ logger = new SalaryManager(source)
+ salary = logger.load()
+ // ...
+```
+
+### 应用场景
+
+ 如果希望在无需修改代码的情况下即可使用对象, 且希望在运行时为对象新增额外的行为, 可以使用装饰模式。
+
+ 装饰能将业务逻辑组织为层次结构, 可为各层创建一个装饰, 在运行时将各种不同逻辑组合成对象。 由于这些对象都遵循通用接口, 客户端代码能以相同的方式使用这些对象。
+
+ 如果用继承来扩展对象行为的方案难以实现或者根本不可行, 可以使用该模式。
+
+ 许多编程语言使用 `final`最终关键字来限制对某个类的进一步扩展。 复用最终类已有行为的唯一方法是使用装饰模式: 用封装器对其进行封装。
+
+### 实现方式
+
+1. 确保业务逻辑可用一个基本组件及多个额外可选层次表示。
+2. 找出基本组件和可选层次的通用方法。 创建一个组件接口并在其中声明这些方法。
+3. 创建一个具体组件类, 并定义其基础行为。
+4. 创建装饰基类, 使用一个成员变量存储指向被封装对象的引用。 该成员变量必须被声明为组件接口类型, 从而能在运行时连接具体组件和装饰。 装饰基类必须将所有工作委派给被封装的对象。
+5. 确保所有类实现组件接口。
+6. 将装饰基类扩展为具体装饰。 具体装饰必须在调用父类方法 (总是委派给被封装对象) 之前或之后执行自身的行为。
+7. 客户端代码负责创建装饰并将其组合成客户端所需的形式。
+
+### go语言实现
+
+```
+package main
+import "fmt"
+
+type pizza interface {
+ getPrice() int
+}
+
+type veggeMania struct {
+}
+
+func (p *veggeMania) getPrice() int {
+ return 15
+}
+
+type tomatoTopping struct {
+ pizza pizza
+}
+func (c *tomatoTopping) getPrice() int {
+ pizzaPrice := c.pizza.getPrice()
+ return pizzaPrice + 7
+}
+
+type cheeseTopping struct {
+ pizza pizza
+}
+
+func (c *cheeseTopping) getPrice() int {
+ pizzaPrice := c.pizza.getPrice()
+ return pizzaPrice + 10
+}
+
+func main() {
+
+ pizza := &veggeMania{}
+
+ //Add cheese topping
+ pizzaWithCheese := &cheeseTopping{
+ pizza: pizza,
+ }
+
+ //Add tomato topping
+ pizzaWithCheeseAndTomato := &tomatoTopping{
+ pizza: pizzaWithCheese,
+ }
+
+ fmt.Printf("Price of veggeMania with tomato and cheese topping is %d\n", pizzaWithCheeseAndTomato.getPrice())
+}
+```
+
+```
+package main
+
+import (
+ "fmt"
+ "github.com/gin-gonic/gin"
+)
+
+//数据类
+type Data struct {
+ filePath string
+ fileName string
+ fileContent string
+}
+
+type DataTransport interface {
+ //客户端从服务端获取到数据
+ ReadData(c *gin.Context)
+ //客户端的数据写入服务端
+ WriteData(c *gin.Context)
+}
+
+//具体组件提供操作的默认实现。
+type ConcreteComponents struct {
+}
+
+func (con *ConcreteComponents) ReadData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+ c.JSON(200, gin.H{
+ "data": d,
+ })
+
+}
+func (con *ConcreteComponents) WriteData(c *gin.Context) {
+ //从客户端获得数据
+ var data Data
+ err := c.ShouldBindQuery(&data)
+ if err != nil {
+ c.JSON(400, gin.H{
+ "err": "something wrong ",
+ })
+ return
+ } else {
+ //写入数据库
+ c.JSON(200, gin.H{
+ "data": "data has write in DB",
+ })
+ }
+}
+
+//具体组件提供操作的默认实现。
+type EncryptAndDecryptDecorator struct {
+}
+
+func (con *EncryptAndDecryptDecorator) ReadData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+
+ c.JSON(200, gin.H{
+ //解密
+ "msg": "data has been Decrypt",
+ "data": d,
+ })
+
+}
+func (con *EncryptAndDecryptDecorator) WriteData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+ c.JSON(200, gin.H{
+ //加密
+ "msg": "Encrypted has write in DB ",
+ "data": d,
+ })
+}
+
+//装饰基类和其他组件遵循相同的接口。该类的主要任务是定义所有具体装饰的封装接口。封装的默认实现代码中可能会包含一个保存被封装组件的成员变量,并且负责对其进行初始化。
+type DecorativeBase struct {
+ //保存了默认的行为,在默认的行为上面可以增加其他的操作,而不会更改任何原来的默认行为
+ //我这里只能把wrappee定义为接口类型,不能是定义 ConcreteComponents 结构体类型。
+ //因为如果是结构体类型,那么我DecorativeBase调用ReadData()和)WriteData()方法时,就调用的是默认的行为,不能增加新的行为。
+ //wrappee *ConcreteComponents 不可以
+ wrappee DataTransport
+}
+
+//装饰器当然也要实现 DataTransport 这个接口,因为它只有和 ConcreteComponents看起来一样(对于客户端而言)才能在已经有的行为上绑定新的行为,装饰器要做的就是把工作委派给ConcreteComponents
+func (d *DecorativeBase) ReadData(c *gin.Context) {
+ d.wrappee.ReadData(c)
+}
+
+func (d *DecorativeBase) WriteData(c *gin.Context) {
+ d.wrappee.WriteData(c)
+}
+
+//新的行为2 压缩和解压缩
+type ZipAndUnZipDecorator struct {
+}
+
+func (e *ZipAndUnZipDecorator) ReadData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+
+ c.JSON(200, gin.H{
+ //解密
+ "msg": "data has been Zip",
+ "data": d,
+ })
+
+}
+func (e *ZipAndUnZipDecorator) WriteData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+
+ c.JSON(200, gin.H{
+ //解密
+ "msg": "data has been Uzip",
+ "data", d,
+ })
+
+}
+func main() {
+ g := gin.New()
+
+ //模拟用户端进行装饰的需求
+ input := 0
+ fmt.Scanf("%d", &input)
+ d := DecorativeBase{}
+
+ if input == 1 {
+ //加密解密行为
+ d.wrappee = &EncryptAndDecryptDecorator{}
+
+ }
+ if input == 2 {
+ d.wrappee = &ZipAndUnZipDecorator{}
+
+ }
+
+ g.POST("/read", d.ReadData)
+ g.POST("/write", d.WriteData)
+ g.Run()
+
+}
+
+```
+
diff --git a/_posts/2022-07-17-test-markdown.md b/_posts/2022-07-17-test-markdown.md
new file mode 100644
index 000000000000..4a828e1068b5
--- /dev/null
+++ b/_posts/2022-07-17-test-markdown.md
@@ -0,0 +1,296 @@
+---
+layout: post
+title: 外观模式
+subtitle: 亦称: Facade
+tags: [设计模式]
+---
+# 外观模式
+
+**亦称:** Facade
+
+**外观模式**是一种结构型设计模式, 能为程序库、 框架或其他复杂类提供一个简单的接口。
+
+### 问题:
+
+假设必须在代码中使用某个复杂的库或框架中的众多对象。 正常情况下, 需要负责所有对象的初始化工作、 管理其依赖关系并按正确的顺序执行方法等。
+
+最终, 程序中类的业务逻辑将与第三方类的实现细节紧密耦合, 使得理解和维护代码的工作很难进行。
+
+### 解决:
+
+外观类为包含许多活动部件的复杂子系统提供一个简单的接口。 与直接调用子系统相比, 外观提供的功能可能比较有限, 但它却包含了客户端真正关心的功能。
+
+例如, 上传猫咪搞笑短视频到社交媒体网站的应用可能会用到专业的视频转换库, 但它只需使用一个包含 `encode(filename, format)`方法 (以文件名与文件格式为参数进行编码的方法) 的类即可。 在创建这个类并将其连接到视频转换库后, 就拥有了自己的第一个外观。
+
+
+
+当通过电话给商店下达订单时, 接线员就是该商店的所有服务和部门的外观。 接线员为提供了一个同购物系统、 支付网关和各种送货服务进行互动的简单语音接口。
+
+
+
+### 外观模式结构
+
+
+
+**外观** (Facade) 提供了一种访问特定子系统功能的便捷方式, 其了解如何重定向客户端请求, 知晓如何操作一切活动部件。
+
+创建**附加外观** (Additional Facade) 类可以避免多种不相关的功能污染单一外观, 使其变成又一个复杂结构。 客户端和其他外观都可使用附加外观。
+
+**复杂子系统** (Complex Subsystem) 由数十个不同对象构成。 如果要用这些对象完成有意义的工作, 必须深入了解子系统的实现细节, 比如按照正确顺序初始化对象和为其提供正确格式的数据。
+
+子系统类不会意识到外观的存在, 它们在系统内运作并且相互之间可直接进行交互。
+
+**客户端** (Client) 使用外观代替对子系统对象的直接调用。
+
+
+
+使用单个外观类隔离多重依赖的示例
+
+可以创建一个封装所需功能并隐藏其他代码的外观类, 从而无需使全部代码直接与数十个框架类进行交互。 该结构还能将未来框架升级或更换所造成的影响最小化, 因为只需修改程序中外观方法的实现即可。
+
+```
+// 这里有复杂第三方视频转换框架中的一些类。我们不知晓其中的代码,因此无法
+// 对其进行简化
+class VideoFile
+// ...
+
+class OggCompressionCodec
+// ...
+
+class MPEG4CompressionCodec
+// ...
+
+class CodecFactory
+// ...
+
+class BitrateReader
+// ...
+
+class AudioMixer
+
+// 为了将框架的复杂性隐藏在一个简单接口背后,我们创建了一个外观类。它是在
+// 功能性和简洁性之间做出的权衡。
+class VideoConverter is
+ method convert(filename, format):File is
+ file = new VideoFile(filename)
+ sourceCodec = new CodecFactory.extract(file)
+ if (format == "mp4")
+ destinationCodec = new MPEG4CompressionCodec()
+ else
+ destinationCodec = new OggCompressionCodec()
+ buffer = BitrateReader.read(filename, sourceCodec)
+ result = BitrateReader.convert(buffer, destinationCodec)
+ result = (new AudioMixer()).fix(result)
+ return new File(result)
+
+// 应用程序的类并不依赖于复杂框架中成千上万的类。同样,如果决定更换框架,
+// 那只需重写外观类即可。
+class Application is
+ method main() is
+ convertor = new VideoConverter()
+ mp4 = convertor.convert("funny-cats-video.ogg", "mp4")
+ mp4.save()
+```
+
+### 适合场景
+
+- **如果需要一个指向复杂子系统的直接接口****,** **且该接口的功能有限****,** **则可以使用外观模式****。
+- **如果需要将子系统组织为多层结构****,** **可以使用外观****。**
+- 创建外观来定义子系统中各层次的入口。 可以要求子系统仅使用外观来进行交互, 以减少子系统之间的耦合。
+- 让我们回到视频转换框架的例子。 该框架可以拆分为两个层次: 音频相关和视频相关。 可以为每个层次创建一个外观, 然后要求各层的类必须通过这些外观进行交互。 这种方式看上去与[中介者]模式非常相似。
+
+### 实现方式
+
+- 考虑能否在现有子系统的基础上提供一个更简单的接口。 如果该接口能让客户端代码独立于众多子系统类, 那么的方向就是正确的。
+- 在一个新的外观类中声明并实现该接口。 外观应将客户端代码的调用重定向到子系统中的相应对象处。 如果客户端代码没有对子系统进行初始化, 也没有对其后续生命周期进行管理, 那么外观必须完成此类工作。
+- 如果要充分发挥这一模式的优势, 必须确保所有客户端代码仅通过外观来与子系统进行交互。 此后客户端代码将不会受到任何由子系统代码修改而造成的影响, 比如子系统升级后, 只需修改外观中的代码即可。
+- 如果外观变得过于臃肿 可以考虑将其部分行为抽取为一个新的专用外观类。
+
+### 与其他模式的关系
+
+- 外观模式为现有对象定义了一个新接口, 适配器模式]则会试图运用已有的接口。 *适配器*通常只封装一个对象, *外观*通常会作用于整个对象子系统上。
+- 当只需对客户端代码隐藏子系统创建对象的方式时, 可以使用抽象工厂模式来代替外观
+- 享元模式展示了如何生成大量的小型对象, 外观]则展示了如何用一个对象来代表整个子系统。
+- 外观和中介者的职责类似: 它们都尝试在大量紧密耦合的类中组织起合作。
+ - *外观*为子系统中的所有对象定义了一个简单接口, 但是它不提供任何新功能。 子系统本身不会意识到外观的存在。 子系统中的对象可以直接进行交流。
+ - *中介者*将系统中组件的沟通行为中心化。 各组件只知道中介者对象, 无法直接相互交流。
+
+- [外观]类通常可以转换为单例模类, 因为在大部分情况下一个外观对象就足够了。
+
+### go语言实现
+
+人们很容易低估使用信用卡订购披萨时幕后工作的复杂程度。 在整个过程中会有不少的子系统发挥作用。 下面是其中的一部分:
+
+- 检查账户
+- 检查安全码
+- 借记/贷记余额
+- 账簿录入
+- 发送消息通知
+
+在如此复杂的系统中, 可以说是一步错步步错, 很容易就会引发大的问题。 这就是为什么我们需要外观模式, 让客户端可以使用一个简单的接口来处理众多组件。 客户端只需要输入卡片详情、 安全码、 支付金额以及操作类型即可。 外观模式会与多种组件进一步地进行沟通, 而又不会向客户端暴露其内部的复杂性。
+
+```
+package main
+
+import (
+ "fmt"
+ "log"
+)
+
+//复杂子系统1--检查账户
+type account struct {
+ name string
+}
+
+func newAccount(accountName string) *account {
+ return &account{
+ name: accountName,
+ }
+}
+
+func (a *account) checkAccount(accountName string) error {
+ if a.name != accountName {
+ return fmt.Errorf("Account Name is incorrect")
+ }
+ fmt.Println("Account Verified")
+ return nil
+}
+
+//复杂子系统2--检查安全码
+type securityCode struct {
+ code int
+}
+
+func newSecurityCode(code int) *securityCode {
+ return &securityCode{
+ code: code,
+ }
+}
+
+func (s *securityCode) checkCode(incomingCode int) error {
+ if s.code != incomingCode {
+ return fmt.Errorf("Security Code is incorrect")
+ }
+ fmt.Println("SecurityCode Verified")
+ return nil
+}
+
+//复杂子系统3--借记/贷记余额
+type wallet struct {
+ balance int
+}
+
+func newWallet() *wallet {
+ return &wallet{
+ balance: 0,
+ }
+}
+
+func (w *wallet) creditBalance(amount int) {
+ w.balance += amount
+ fmt.Println("Wallet balance added successfully")
+ return
+}
+
+func (w *wallet) debitBalance(amount int) error {
+ if w.balance < amount {
+ return fmt.Errorf("Balance is not sufficient")
+ }
+ fmt.Println("Wallet balance is Sufficient")
+ w.balance = w.balance - amount
+ return nil
+}
+
+//复杂子系统4--账簿录入
+type ledger struct {
+}
+
+func (s *ledger) makeEntry(accountID, txnType string, amount int) {
+ fmt.Printf("Make ledger entry for accountId %s with txnType %s for amount %d\n", accountID, txnType, amount)
+ return
+}
+
+//复杂子系统5--发送消息通知
+type notification struct {
+}
+
+func (n *notification) sendWalletCreditNotification() {
+ fmt.Println("Sending wallet credit notification")
+}
+
+func (n *notification) sendWalletDebitNotification() {
+ fmt.Println("Sending wallet debit notification")
+}
+
+//外观模式类
+type walletFacade struct {
+ account *account
+ wallet *wallet
+ securityCode *securityCode
+ notification *notification
+ ledger *ledger
+}
+
+func newWalletFacade(accountID string, code int) *walletFacade {
+ fmt.Println("Starting create account")
+ walletFacacde := &walletFacade{
+ account: newAccount(accountID),
+ securityCode: newSecurityCode(code),
+ wallet: newWallet(),
+ notification: ¬ification{},
+ ledger: &ledger{},
+ }
+ fmt.Println("Account created")
+ return walletFacacde
+}
+func (w *walletFacade) addMoneyToWallet(accountID string, securityCode int, amount int) error {
+ fmt.Println("Starting add money to wallet")
+ err := w.account.checkAccount(accountID)
+ if err != nil {
+ return err
+ }
+ err = w.securityCode.checkCode(securityCode)
+ if err != nil {
+ return err
+ }
+ w.wallet.creditBalance(amount)
+ w.notification.sendWalletCreditNotification()
+ w.ledger.makeEntry(accountID, "credit", amount)
+ return nil
+}
+func (w *walletFacade) deductMoneyFromWallet(accountID string, securityCode int, amount int) error {
+ fmt.Println("Starting debit money from wallet")
+ err := w.account.checkAccount(accountID)
+ if err != nil {
+ return err
+ }
+
+ err = w.securityCode.checkCode(securityCode)
+ if err != nil {
+ return err
+ }
+ err = w.wallet.debitBalance(amount)
+ if err != nil {
+ return err
+ }
+ w.notification.sendWalletDebitNotification()
+ w.ledger.makeEntry(accountID, "credit", amount)
+ return nil
+}
+
+func main() {
+ walletFacade := newWalletFacade("abc", 1234)
+ err := walletFacade.addMoneyToWallet("abc", 1234, 10)
+ if err != nil {
+ log.Fatalf("Error: %s\n", err.Error())
+ }
+ fmt.Println()
+ err = walletFacade.deductMoneyFromWallet("abc", 1234, 5)
+ if err != nil {
+ log.Fatalf("Error: %s\n", err.Error())
+ }
+
+}
+
+```
+
diff --git a/_posts/2022-07-18-test-markdown.md b/_posts/2022-07-18-test-markdown.md
new file mode 100644
index 000000000000..fc2758db210b
--- /dev/null
+++ b/_posts/2022-07-18-test-markdown.md
@@ -0,0 +1,433 @@
+---
+layout: post
+title: 责任链模式
+subtitle: 亦称: 职责链模式、命令链、CoR、Chain of Command、Chain of Responsibility
+tags: [设计模式]
+---
+
+# 责任链模式
+
+亦称: 职责链模式、命令链、CoR、Chain of Command、Chain of Responsibility
+
+
+
+### 目的:
+
+**责任链模式**是一种行为设计模式, 允许将请求沿着处理者链进行发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
+
+### 问题:
+
+假如正在开发一个在线订购系统。 希望对系统访问进行限制, 只允许认证用户创建订单。 此外, 拥有管理权限的用户也拥有所有订单的完全访问权限。
+
+简单规划后, 会意识到这些检查必须依次进行。 只要接收到包含用户凭据的请求, 应用程序就可尝试对进入系统的用户进行认证。 但如果由于用户凭据不正确而导致认证失败, 那就没有必要进行后续检查了。
+
+在接下来的几个月里, 实现了后续的几个检查步骤。
+
+- 一位同事认为直接将原始数据传递给订购系统存在安全隐患。 因此新增了额外的验证步骤来清理请求中的数据。
+- 过了一段时间, 有人注意到系统无法抵御暴力密码破解方式的攻击。 为了防范这种情况, 立刻添加了一个检查步骤来过滤来自同一 IP 地址的重复错误请求。
+- 又有人提议可以对包含同样数据的重复请求返回缓存中的结果, 从而提高系统响应速度。 因此, 新增了一个检查步骤, 确保只有没有满足条件的缓存结果时请求才能通过并被发送给系统。
+
+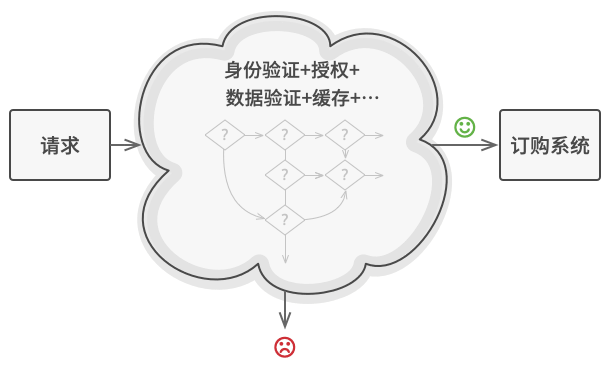
+
+检查代码本来就已经混乱不堪, 而每次新增功能都会使其更加臃肿。 修改某个检查步骤有时会影响其他的检查步骤。 最糟糕的是, 当希望复用这些检查步骤来保护其他系统组件时, 只能复制部分代码, 因为这些组件只需部分而非全部的检查步骤。
+
+系统会变得让人非常费解, 而且其维护成本也会激增。 在艰难地和这些代码共处一段时间后, 有一天终于决定对整个系统进行重构。
+
+### 解决:
+
+与许多其他行为设计模式一样, **责任链**会将特定行为转换为被称作*处理者*的独立对象。 在上述示例中, 每个检查步骤都可被抽取为仅有单个方法的类, 并执行检查操作。 请求及其数据则会被作为参数传递给该方法。
+
+模式建议将这些处理者连成一条链。 链上的每个处理者都有一个成员变量来保存对于下一处理者的引用。 除了处理请求外, 处理者还负责沿着链传递请求。 请求会在链上移动, 直至所有处理者都有机会对其进行处理。
+
+最重要的是: 处理者可以决定不再沿着链传递请求, 这可高效地取消所有后续处理步骤。
+
+- 每个检查步骤都可被抽取为仅有单个方法的类, 并执行检查操作。
+- 请求及其数据则会被作为参数传递给该方法。
+- 每个处理者都有一个成员变量来保存对于下一处理者的引用。
+- 除了处理请求外, 处理者还负责沿着链传递请求。 请求会在链上移动。
+
+在我们的订购系统示例中, 处理者会在进行请求处理工作后决定是否继续沿着链传递请求。 如果请求中包含正确的数据, 所有处理者都将执行自己的主要行为, 无论该行为是身份验证还是数据缓存。
+
+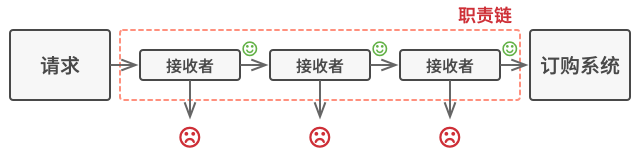
+
+不过还有一种稍微不同的方式 (也是更经典一种), 那就是处理者接收到请求后自行决定是否能够对其进行处理。 如果自己能够处理, 处理者就不再继续传递请求。 因此在这种情况下, 每个请求要么最多有一个处理者对其进行处理, 要么没有任何处理者对其进行处理。 在处理图形用户界面元素栈中的事件时, 这种方式非常常见。
+
+例如, 当用户点击按钮时, 按钮产生的事件将沿着 GUI 元素链进行传递, 最开始是按钮的容器 (如窗体或面板), 直至应用程序主窗口。 链上第一个能处理该事件的元素会对其进行处理。 此外, 该例还有另一个值得我们关注的地方: 它表明我们总能从对象树中抽取出链来。
+
+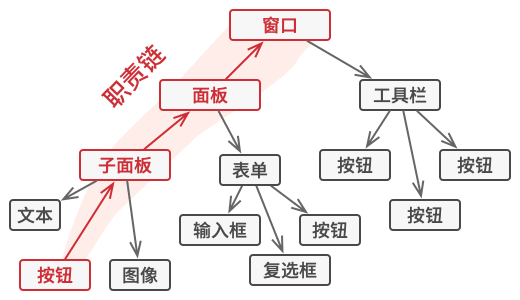
+
+所有处理者类均实现同一接口是关键所在。 每个具体处理者仅关心下一个包含 `execute`执行方法的处理者。 这样一来, 就可以在运行时使用不同的处理者来创建链, 而无需将相关代码与处理者的具体类进行耦合。
+
+- 使用不同的处理者来创建链。
+- 所有处理者类均实现同一接口。
+- 具体处理者仅关心下一个包含 `execute`执行方法的处理者。
+
+
+
+最近, 刚为自己的电脑购买并安装了一个新的硬件设备。 身为一名极客, 显然在电脑上安装了多个操作系统, 所以会试着启动所有操作系统来确认其是否支持新的硬件设备。 Windows 检测到了该硬件设备并对其进行了自动启用。 但是喜爱的 Linux 系统并不支持新硬件设备。 抱着最后一点希望, 决定拨打包装盒上的技术支持电话。
+
+首先会听到自动回复器的机器合成语音, 它提供了针对各种问题的九个常用解决方案, 但其中没有一个与遇到的问题相关。 过了一会儿, 机器人将转接到人工接听人员处。
+
+这位接听人员同样无法提供任何具体的解决方案。 他不断地引用手册中冗长的内容, 并不会仔细聆听的回应。 在第 10 次听到 “是否关闭计算机后重新启动呢?” 这句话后, 要求与一位真正的工程师通话。
+
+最后, 接听人员将的电话转接给了工程师, 他或许正缩在某幢办公大楼的阴暗地下室中, 坐在他所深爱的服务器机房里, 焦躁不安地期待着同一名真人交流。 工程师告诉了新硬件设备驱动程序的下载网址, 以及如何在 Linux 系统上进行安装。 问题终于解决了! 挂断了电话, 满心欢喜。
+
+### 模式结构:
+
+
+
+- **处理者** (Handler) 声明了所有具体处理者的通用接口。 该接口通常仅包含单个方法用于请求处理, 但有时其还会包含一个设置链上下个处理者的方法。
+
+- **基础处理者** (Base Handler) 是一个可选的类, 可以将所有处理者共用的样本代码放置在其中。
+
+ 通常情况下, 该类中定义了一个保存对于下个处理者引用的成员变量。 客户端可通过将处理者传递给上个处理者的构造函数或设定方法来创建链。 该类还可以实现默认的处理行为: 确定下个处理者存在后再将请求传递给它。
+
+- **具体处理者** (Concrete Handlers) 包含处理请求的实际代码。 每个处理者接收到请求后, 都必须决定是否进行处理, 以及是否沿着链传递请求。
+- 处理者通常是独立且不可变的, 需要通过构造函数一次性地获得所有必要地数据。
+- **客户端** (Client) 可根据程序逻辑一次性或者动态地生成链。 值得注意的是, 请求可发送给链上的任意一个处理者, 而非必须是第一个处理者。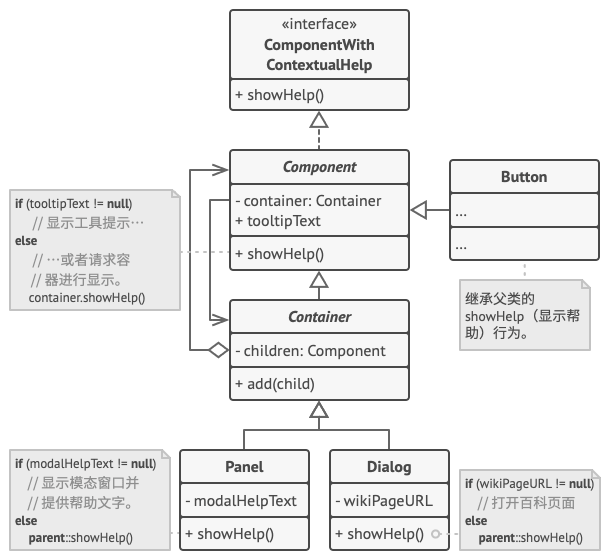
+
+应用程序的 GUI 通常为对象树结构。 例如, 负责渲染程序主窗口的 `对话框`类就是对象树的根节点。 对话框包含 `面板` , 而面板可能包含其他面板, 或是 `按钮`和 `文本框`等下层元素。
+
+只要给一个简单的组件指定帮助文本, 它就可显示简短的上下文提示。 但更复杂的组件可自定义上下文帮助文本的显示方式, 例如显示手册摘录内容或在浏览器中打开一个网页。
+
+```
+// 处理者接口声明了一个创建处理者链的方法。还声明了一个执行请求的方法。
+interface ComponentWithContextualHelp is
+ method showHelp()
+
+
+// 简单组件的基础类。
+abstract class Component implements ComponentWithContextualHelp is
+ field tooltipText: string
+
+ // 组件容器在处理者链中作为“下一个”链接。
+ protected field container: Container
+
+ // 如果组件设定了帮助文字,那它将会显示提示信息。如果组件没有帮助文字
+ // 且其容器存在,那它会将调用传递给容器。
+ method showHelp() is
+ if (tooltipText != null)
+ // 显示提示信息。
+ else
+ container.showHelp()
+
+
+// 容器可以将简单组件和其他容器作为其子项目。链关系将在这里建立。该类将从
+// 其父类处继承 showHelp(显示帮助)的行为。
+abstract class Container extends Component is
+ protected field children: array of Component
+
+ method add(child) is
+ children.add(child)
+ child.container = this
+
+
+// 客户端代码。
+class Application is
+ // 每个程序都能以不同方式对链进行配置。
+ method createUI() is
+ dialog = new Dialog("预算报告")
+ dialog.wikiPageURL = "http://..."
+ panel = new Panel(0, 0, 400, 800)
+ panel.modalHelpText = "本面板用于..."
+ ok = new Button(250, 760, 50, 20, "确认")
+ ok.tooltipText = "这是一个确认按钮..."
+ cancel = new Button(320, 760, 50, 20, "取消")
+ // ...
+ panel.add(ok)
+ panel.add(cancel)
+ dialog.add(panel)
+
+ // 想象这里会发生什么。
+ method onF1KeyPress() is
+ component = this.getComponentAtMouseCoords()
+ component.showHelp()
+```
+
+### 实现:
+
+- 声明处理者接口并描述请求处理方法的签名。
+
+ 确定客户端如何将请求数据传递给方法。 最灵活的方式是将请求转换为对象, 然后将其以参数的形式传递给处理函数。
+
+- 为了在具体处理者中消除重复的样本代码, 可以根据处理者接口创建抽象处理者基类。
+
+ 该类需要有一个成员变量来存储指向链上下个处理者的引用。 可以将其设置为不可变类。 但如果打算在运行时对链进行改变, 则需要定义一个设定方法来修改引用成员变量的值。
+
+ 为了使用方便, 还可以实现处理方法的默认行为。 如果还有剩余对象, 该方法会将请求传递给下个对象。 具体处理者还能够通过调用父对象的方法来使用这一行为。
+
+- 依次创建具体处理者子类并实现其处理方法。 每个处理者在接收到请求后都必须做出两个决定:
+
+ - 是否自行处理这个请求。
+ - 是否将该请求沿着链进行传递。
+
+- 客户端可以自行组装链, 或者从其他对象处获得预先组装好的链。 在后一种情况下, 必须实现工厂类以根据配置或环境设置来创建链。
+- 客户端可以触发链中的任意处理者, 而不仅仅是第一个。 请求将通过链进行传递, 直至某个处理者拒绝继续传递, 或者请求到达链尾。
+- 由于链的动态性, 客户端需要准备好处理以下情况:
+ - 链中可能只有单个链接。
+ - 部分请求可能无法到达链尾。
+ - 其他请求可能直到链尾都未被处理。
+
+### go语言实现
+
+让我们来看看一个医院应用的责任链模式例子。 医院中会有多个部门, 如:
+
+- 前台
+- 医生
+- 药房
+- 收银
+- 病人来访时, 他们首先都会去前台, 然后是看医生、 取药, 最后结账。 也就是说, 病人需要通过一条部门链, 每个部门都在完成其职能后将病人进一步沿着链条输送。
+- 此模式适用于有多个候选选项处理相同请求的情形, 适用于不希望客户端选择接收者 (因为多个对象都可处理请求) 的情形, 还适用于想将客户端同接收者解耦时。 客户端只需要链中的首个元素即可。
+
+```
+package main
+
+import (
+ "fmt"
+)
+
+//数据类
+type Context struct {
+ data map[string]string
+}
+
+func (c *Context) Get(str string) string {
+ k, ok := c.data[str]
+ if ok {
+ return k
+ }
+ return ""
+}
+
+func (c *Context) Set(key string, value string) {
+ c.data[key] = value
+}
+
+//处理者统一实现的接口
+type HandlerInterface interface {
+ Handle(c Context)
+ SetNext(HandlerInterface)
+}
+
+//处理者1
+type Reception struct {
+ nextHandler HandlerInterface
+}
+
+func (r *Reception) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+func (r *Reception) Handle(c Context) {
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "Doctor")
+ fmt.Println("Reception has handle over")
+ r.SetNext(&Doctor{})
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+
+//处理者2
+type Doctor struct {
+ nextHandler HandlerInterface
+}
+
+func (r *Doctor) Handle(c Context) {
+
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "Medical")
+ fmt.Println("Reception has handle over")
+ r.SetNext(&Medical{})
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+func (r *Doctor) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+
+//处理者3
+type Medical struct {
+ nextHandler HandlerInterface
+}
+
+func (r *Medical) Handle(c Context) {
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "CheckoutCounter")
+ fmt.Println("Reception has handle over")
+ r.SetNext(&CheckoutCounter{})
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+func (r *Medical) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+
+//处理者4
+type CheckoutCounter struct {
+ nextHandler HandlerInterface
+}
+
+func (r *CheckoutCounter) Handle(c Context) {
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "CheckoutCounter")
+ fmt.Println("Reception has handle over")
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+
+func (r *CheckoutCounter) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+
+func main() {
+ c := Context{
+ make(map[string]string),
+ }
+ //need -挂号看病 seeDoctor need -复诊FollowUp need -缴费 PayFee
+ c.data["need"] = "seeDoctor"
+
+ r := Reception{}
+ r.Handle(c)
+
+}
+
+```
+
+```
+package main
+
+import "fmt"
+
+//数据
+type patient struct {
+ name string
+ registrationDone bool
+ doctorCheckUpDone bool
+ medicineDone bool
+ paymentDone bool
+}
+
+//接口
+type department interface {
+ execute(*patient)
+ setNext(department)
+}
+
+//处理者1
+type reception struct {
+ next department
+}
+
+func (r *reception) execute(p *patient) {
+ if p.registrationDone {
+ fmt.Println("Patient registration already done")
+ r.next.execute(p)
+ return
+ }
+ fmt.Println("Reception registering patient")
+ p.registrationDone = true
+ r.next.execute(p)
+}
+
+func (r *reception) setNext(next department) {
+ r.next = next
+}
+
+//处理者2
+type doctor struct {
+ next department
+}
+
+func (d *doctor) execute(p *patient) {
+ if p.doctorCheckUpDone {
+ fmt.Println("Doctor checkup already done")
+ d.next.execute(p)
+ return
+ }
+ fmt.Println("Doctor checking patient")
+ p.doctorCheckUpDone = true
+ d.next.execute(p)
+}
+
+func (d *doctor) setNext(next department) {
+ d.next = next
+}
+
+//处理者3
+type medical struct {
+ next department
+}
+
+func (m *medical) execute(p *patient) {
+ if p.medicineDone {
+ fmt.Println("Medicine already given to patient")
+ m.next.execute(p)
+ return
+ }
+ fmt.Println("Medical giving medicine to patient")
+ p.medicineDone = true
+ m.next.execute(p)
+}
+
+func (m *medical) setNext(next department) {
+ m.next = next
+}
+
+//处理者4
+type cashier struct {
+ next department
+}
+
+func (c *cashier) execute(p *patient) {
+ if p.paymentDone {
+ fmt.Println("Payment Done")
+ }
+ fmt.Println("Cashier getting money from patient patient")
+}
+
+func (c *cashier) setNext(next department) {
+ c.next = next
+}
+
+func main() {
+
+ cashier := &cashier{}
+
+ //Set next for medical department
+ medical := &medical{}
+ medical.setNext(cashier)
+
+ //Set next for doctor department
+ doctor := &doctor{}
+ doctor.setNext(medical)
+
+ //Set next for reception department
+ reception := &reception{}
+ reception.setNext(doctor)
+
+ patient := &patient{name: "abc"}
+ //Patient visiting
+ reception.execute(patient)
+}
+
+```
+
diff --git a/_posts/2022-07-20-test-markdown.md b/_posts/2022-07-20-test-markdown.md
new file mode 100644
index 000000000000..ea875a6a1aef
--- /dev/null
+++ b/_posts/2022-07-20-test-markdown.md
@@ -0,0 +1,60 @@
+---
+layout: post
+title: 从Mosn 源码到dubbo-go-pixiu 源码
+subtitle: 七层负载均衡
+tags: [开源]
+---
+
+# 从Mosn 源码到dubbo-go-pixiu 源码
+
+## 七层负载均衡
+
+> 客户端建立一个到负载均衡 器的 TCP 连接。负载均衡器**终结该连接**(即直接响应 SYN),然后选择一个后端,并与该后端建立一个新的 TCP 连接(即发送一个新的 SYN)。四层负载均衡器通常只在四层 `TCP/UDP` 连接/会话级别上运行。因此, 负载均衡器通过转发数据,并确保来自同一会话的字节在同一后端结束。四层负载均衡器 不知道它正在转发数据的任何应用程序细节。数据内容可以是 `HTTP`, `Redis`, `MongoDB`,或任 何应用协议。
+>
+> 四层负载均衡有哪些缺点是七层(应用)负载均衡来解决的呢? 假如两个 `gRPC/HTTP2` 客户端通过四层负载均衡器连接想要与一个后端通信。四层负载均衡器为每个入站 TCP 连接创建一个出站的 TCP 连接,从而产生两个入站和两个出站的连接(CA ==> `loadbalancer` ==> SA, CB ==> `loadbalancer` ==> SB)。假设,客户端 A 每分钟发送 1 个请求,而客户端 B 每秒发送 50 个请求,则SA 的负载是 SB的 50倍。所以四层负载均衡器问题随着时 间的推移变得越来越不均衡。
+
+
+
+上图 显示了一个七层 HTTP/2 负载均衡器。客户端创建一个到负载均衡器的HTTP/2 TCP 连接。负载均衡器创建连接到两个后端。当客户端向负载均衡器发送两个HTTP/2 流时,流 1 被发送到后端 1,流 2 被发送到后端 2。因此,即使请求负载有很大差 异的客户端也会在后端之间实现高效地分发。这就是为什么七层负载均衡对现代协议如此 重要的原因。对于`mosn`来说,还支持协议转换,比如client `mosn` 之间是`http`,`mosn` 与server 之间是 `grpc` 协议。
+
+## 初始化和启动
+
+```
+// mosn.io/mosn/pkg/mosn/starter.go
+type Mosn struct {
+ servers []server.Server
+ clustermanager types.ClusterManager
+ routerManager types.RouterManager
+ config *v2.MOSNConfig
+ adminServer admin.Server
+ xdsClient *xds.Client
+ wg sync.WaitGroup
+ // for smooth upgrade. reconfigure
+ inheritListeners []net.Listener
+ reconfigure net.Conn
+}
+
+
+```
+
+```
+//dubbo-go-pixiu/pkg/server/pixiu_start.go
+// PX is Pixiu start struct
+type Server struct {
+ startWG sync.WaitGroup
+
+ listenerManager *ListenerManager
+ clusterManager *ClusterManager
+ adapterManager *AdapterManager
+ // routerManager and apiConfigManager are duplicate, because route and dubbo-protocol api_config are a bit repetitive
+ routerManager *RouterManager
+ apiConfigManager *ApiConfigManager
+ dynamicResourceManger DynamicResourceManager
+ traceDriverManager *tracing.TraceDriverManager
+}
+```
+
+- `clustermanager` 顾名思义就是集群管理器。 `types.ClusterManager` 也是接口类型。这里的 cluster 指得是 `MOSN` 连接到的一组逻辑上相似的上游主机。`MOSN` 通过服务发现来发现集群中的成员,并通过主动运行状况检查来确定集群成员的健康状况。`MOSN` 如何将请求路由到集群成员由负载均衡策略确定。
+- `routerManager` 是路由管理器,`MOSN` 根据路由规则来对请求进行代理。
+
+### 初始化
\ No newline at end of file
diff --git a/_posts/2022-07-21-test-markdown.md b/_posts/2022-07-21-test-markdown.md
new file mode 100644
index 000000000000..766b242a015d
--- /dev/null
+++ b/_posts/2022-07-21-test-markdown.md
@@ -0,0 +1,233 @@
+---
+layout: post
+title: 通过Exporter收集指标
+subtitle: 自定义Exporter收集指标
+tags: [Microservices gateway]
+---
+
+# 通过Exporter收集指标
+
+### Exporter介绍
+
+Exporter 是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,它负责从目标系统(Your 服务)搜集数据,并将其转化为 Prometheus 支持的格式。Prometheus 会周期性地调用 Exporter 提供的 metrics 数据接口来获取数据。那么使用 Exporter 的好处是什么?举例来说,如果要监控 Mysql/Redis 等数据库,我们必须要调用它们的接口来获取信息(前提要有),这样每家都有一套接口,这样非常不通用。所以 Prometheus 做法是每个软件做一个 Exporter,Prometheus 的 Http 读取 Exporter 的信息(将监控指标进行统一的格式化并暴露出来)。简单类比,Exporter 就是个翻译,把各种语言翻译成一种统一的语言。
+
+
+
+对于Exporter而言,它的功能主要就是将数据周期性地从监控对象中取出来进行加工,然后将数据规范化后通过端点暴露给Prometheus,所以主要包含如下3个功能。
+
+- 封装功能模块获取监控系统内部的统计信息。
+- 将返回数据进行规范化映射,使其成为符合Prometheus要求的格式化数据。
+- Collect模块负责存储规范化后的数据,最后当Prometheus定时从Exporter提取数据时,Exporter就将Collector收集的数据通过HTTP的形式在/metrics端点进行暴露。
+
+### Primetheus client
+
+golang client 是当pro收集所监控的系统的数据时,用于响应pro的请求,按照一定的格式给pro返回数据,说白了就是一个http server。
+
+### 数据类型
+
+```
+# HELP go_gc_duration_seconds A summary of the GC invocation durations.
+# TYPE go_gc_duration_seconds summary
+go_gc_duration_seconds{quantile="0.5"} 0.000107458
+go_gc_duration_seconds{quantile="0.75"} 0.000200112
+go_gc_duration_seconds{quantile="1"} 0.000299278
+go_gc_duration_seconds_sum 0.002341738
+go_gc_duration_seconds_count 18
+# HELP go_goroutines Number of goroutines that currently exist.
+# TYPE go_goroutines gauge
+go_goroutines 107
+```
+
+这些信息有一个共同点,就是采用了不同于JSON或者Protocol Buffers的数据组织形式——文本形式。在文本形式中,每个指标都占用一行,#HELP代表指标的注释信息,#TYPE用于定义样本的类型注释信息,紧随其后的语句就是具体的监控指标(即样本)。#HELP的内容格式如下所示,需要填入指标名称及相应的说明信息。
+
+```
+HELP
+```
+
+\#TYPE的内容格式如下所示,需要填入指标名称和指标类型(如果没有明确的指标类型,需要返回untyped)。
+
+```
+TYPE
+```
+
+监控样本部分需要满足如下格式规范。
+
+```
+metric_name [ "{" label_name "=" " label_value " { "," label_name "=" " label_value " } [ "," ] "}" ] value [ timestamp ]
+```
+
+其中,metric_name和label_name必须遵循PromQL的格式规范。value是一个f loat格式的数据,timestamp的类型为int64(从1970-01-01 00:00:00开始至今的总毫秒数),可设置其默认为当前时间。具有相同metric_name的样本必须按照一个组的形式排列,并且每一行必须是唯一的指标名称和标签键值对组合。
+
+- Counter:Counter是一个累加的数据类型。一个Counter类型的指标只会随着时间逐渐递增(当系统重启的时候,Counter指标会被重置为0)。记录系统完成的总任务数量、系统从最近一次启动到目前为止发生的总错误数等场景都适合使用Counter类型的指标。
+- Gauge:Gauge指标主要用于记录一个瞬时值,这个指标可以增加也可以减少,比如CPU的使用情况、内存使用量以及硬盘当前的空间容量等。
+- Histogram:Histogram表示柱状图,主要用于统计一些数据分布的情况,可以计算在一定范围内的数据分布情况,同时还提供了指标值的总和。在大多数情况下,用户会使用某些指标的平均值作为参考,例如,使用系统的平均响应时间来衡量系统的响应能力。这种方式有个明显的问题——如果大多数请求的响应时间都维持在100ms内,而个别请求的响应时间需要1s甚至更久,那么响应时间的平均值体现不出响应时间中的尖刺,这就是所谓的“长尾问题”。为了更加真实地反映系统响应能力,常用的方式是按照请求延迟的范围进行分组,例如在上述示例中,可以分别统计响应时间在[0,100ms]、[100,1s]和[1s,∞]这3个区间的请求数,通过查看这3个分区中请求量的分布,就可以比较客观地分析出系统的响应能力。
+- Summary:Summary与Histogram类似,也会统计指标的总数(以_count作为后缀)以及sum值(以_sum作为后缀)。两者的主要区别在于,Histogram指标直接记录了在不同区间内样本的个数,而Summary类型则由客户端计算对应的分位数。例如下面展示了一个Summary类型的指标,其中quantile=”0.5”表示中位数,quantile=”0.9”表示九分位数。
+
+广义上讲,所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter,Exporter的一个实例被称为target,Prometheus会通过轮询的形式定期从这些target中获取样本数据。
+
+### 动手编写一个Exporter
+
+```
+package main
+
+import (
+ "log"
+ "net/http"
+
+ "github.com/prometheus/client_golang/prometheus"
+ "github.com/prometheus/client_golang/prometheus/promhttp"
+)
+
+var (
+ cpuTemp = prometheus.NewGauge(prometheus.GaugeOpts{
+ NameSpace: "our_idc",
+ Subsystem: "k8s"
+ Name: "cpu_temperature_celsius",
+ Help: "Current temperature of the CPU.",
+ })
+ hdFailures = prometheus.NewCounterVec(
+ prometheus.CounterOpts{
+ NameSpace: "our_idc",
+ Subsystem: "k8s"
+ Name: "hd_errors_total",
+ Help: "Number of hard-disk errors.",
+ },
+ []string{"device"},
+ )
+)
+
+func init() {
+ // Metrics have to be registered to be exposed:
+ prometheus.MustRegister(cpuTemp)
+ prometheus.MustRegister(hdFailures)
+}
+
+func main() {
+ cpuTemp.Set(65.3)
+ hdFailures.With(prometheus.Labels{"device":"/dev/sda"}).Inc()
+
+ // The Handler function provides a default handler to expose metrics
+ // via an HTTP server. "/metrics" is the usual endpoint for that.
+ http.Handle("/metrics", promhttp.Handler())
+ log.Fatal(http.ListenAndServe(":8888", nil))
+}
+```
+
+- `CounterVec`是用来管理相同metric下不同label的一组`Counter`
+- `counterVec`是有label的,而单纯的gauage对象却不用lable标识,这就是基本数据类型和对应Vec版本的差别.
+
+### 自定义Collector
+
+直接使用Collector,go client Colletor只会在每次响应Prometheus请求的时候才收集数据。需要每次显式传递变量的值,否则就不会再维持该变量,在Prometheus也将看不到这个变量。Collector是一个接口,所有收集metrics数据的对象都需要实现这个接口,Counter和Gauage等不例外。它内部提供了两个函数,Collector用于收集用户数据,将收集好的数据传递给传入参数Channel就可;Descirbe函数用于描述这个Collector。
+
+```
+package main
+
+import (
+ "github.com/prometheus/client_golang/prometheus"
+ "github.com/prometheus/client_golang/prometheus/promhttp"
+ "net/http"
+ "sync"
+)
+
+type ClusterManager struct {
+ sync.Mutex
+ Zone string
+ metricMapCounters map[string]string
+ metricMapGauges map[string]string
+}
+
+//Simulate prepare the data
+func (c *ClusterManager) ReallyExpensiveAssessmentOfTheSystemState() (
+ metrics map[string]float64,
+) {
+ metrics = map[string]float64{
+ "oom_crashes_total": 42.00,
+ "ram_usage": 6.023e23,
+ }
+ return
+}
+
+//通过NewClusterManager方法创建结构体及对应的指标信息,代码如下所示。
+// NewClusterManager creates the two Descs OOMCountDesc and RAMUsageDesc. Note
+// that the zone is set as a ConstLabel. (It's different in each instance of the
+// ClusterManager, but constant over the lifetime of an instance.) Then there is
+// a variable label "host", since we want to partition the collected metrics by
+// host. Since all Descs created in this way are consistent across instances,
+// with a guaranteed distinction by the "zone" label, we can register different
+// ClusterManager instances with the same registry.
+func NewClusterManager(zone string) *ClusterManager {
+ return &ClusterManager{
+ Zone: zone,
+ metricMapGauges: map[string]string{
+ "ram_usage": "ram_usage",
+ },
+ metricMapCounters: map[string]string{
+ "oom_crashes": "oom_crashes_total",
+ },
+ }
+}
+
+func (c *ClusterManager) Describe(ch chan<- *prometheus.Desc) {
+ // prometheus.NewDesc(prometheus.BuildFQName(namespace, "", metricName), docString, labels, nil)
+ for _, v := range c.metricMapGauges {
+ ch <- prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", v), v, nil, nil)
+ }
+
+ for _, v := range c.metricMapCounters {
+ ch <- prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", v), v, nil, nil)
+ }
+}
+
+//Collect方法是核心,它会抓取需要的所有数据,根据需求对其进行分析,然后将指标发送回客户端库。
+// 用于传递所有可能指标的定义描述符
+// 可以在程序运行期间添加新的描述,收集新的指标信息
+// 重复的描述符将被忽略。两个不同的Collector不要设置相同的描述符
+func (c *ClusterManager) Collect(ch chan<- prometheus.Metric) {
+ c.Lock()
+ defer c.Unlock()
+ m := c.ReallyExpensiveAssessmentOfTheSystemState()
+ for k, v := range m {
+ t := prometheus.GaugeValue
+ if c.metricMapCounters[k] != "" {
+ t = prometheus.CounterValue
+ }
+ c.registerConstMetric(ch, k, v, t)
+ }
+}
+
+// 用于传递所有可能指标的定义描述符给指标
+func (c *ClusterManager) registerConstMetric(ch chan<- prometheus.Metric, metric string, val float64, valType prometheus.ValueType, labelValues ...string) {
+ descr := prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", metric), metric, nil, nil)
+ if m, err := prometheus.NewConstMetric(descr, valType, val, labelValues...); err == nil {
+ ch <- m
+ }
+}
+func main() {
+ workerCA := NewClusterManager("xiaodian")
+ reg := prometheus.NewPedanticRegistry()
+ reg.MustRegister(workerCA)
+ //当promhttp.Handler()被执行时,所有metric被序列化输出。题外话,其实输出的格式既可以是plain text,也可以是protocol Buffers。
+ http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{}))
+ http.ListenAndServe(":8888", nil)
+}
+
+```
+
+## 高质量Exporter的编写原则与方法
+
+- 在访问Exporter的主页(即http://yourExporter/这样的根路径)时,它会返回一个简单的页面,这就是Exporter的落地页(Landing Page)。落地页中可以放文档和帮助信息,包括监控指标项的说明。落地页上还包括最近执行的检查列表、列表的状态以及调试信息,这对故障排查非常有帮助。
+- 一台服务器或者容器上可能会有许多Exporter和Prometheus组件,它们都有自己的端口号。因此,在写Exporter和发布Exporter之前,需要检查新添加的端口是否已经被使用[1],建议使用默认端口分配范围之外的端口。
+- 我们应该根据业务类型设计好指标的#HELP#TYPE的格式。这些指标往往是可配置的,包括默认开启的指标和默认关闭的指标。这是因为大部分指标并不会真正被用到,设计过多的指标不仅会消耗不必要的资源,还会影响整体的性能。
+- 对于如何写高质量Exporter,除了合理分配端口号、设计落地页、梳理指标这3个方面外,还有一些其他的原则。
+ - 记录Exporter本身的运行状态指标。
+ - 可配置化进行功能的启用和关闭。
+ - 推荐使用YAML作为配置格式。
+ - 遵循度量标准命名的最佳实践[2],特别是_count、_sum、_total、_bucket和info等问题。
+ - 为度量提供正确的单位。
+ - 标签的唯一性、可读性及必要的冗余信息设计。
+ - 通过Docker等方式一键配置Exporter。
+ - 尽量使用Collectors方式收集指标,如Go语言中的MustNewConstMetric。
+ - 提供scrapes刮擦失败的错误设计,这有助于性能调试。
+ - 尽量不要重复提供已有的指标,如Node Exporter已经提供的CPU、磁盘等信息。
+ - 向Prometheus公开原始的度量数据,不建议自行计算,Exporter的核心是采集原始指标。
\ No newline at end of file
diff --git a/_posts/2022-07-22-test-markdown.md b/_posts/2022-07-22-test-markdown.md
new file mode 100644
index 000000000000..a7a8f9c30cbd
--- /dev/null
+++ b/_posts/2022-07-22-test-markdown.md
@@ -0,0 +1,210 @@
+---
+layout: post
+title: 微服务系列
+subtitle: 微服务间的通讯 服务注册 服务发现
+tags: [Microservices gateway]
+---
+
+# 微服务全系列
+
+## 1.微服务间的通讯
+
+### 单体系统和微服务的区别
+
+| **单体系统** | **微服务系统** |
+| ------------------------ | ------------------------------------ |
+| 程序、数据、配置集中管理 | 按照功能拆分、微服务化、松耦合 |
+| 开发效率低下 | 分模块快速迭代 |
+| 发布全量,启动慢 | 平滑发布,快速启动 |
+| 可靠性差 | 熔断、限流、降级,超时重试,异常离群 |
+| 服务内直接调用 | 轻量级通信 |
+| 技术单一 | 跨语言 |
+
+- 微服务有诸多的有利条件,但是如果微服务的粒度比较细(按照业务功能拆分),则他们之间服务调用就会比较复杂,链路会比较长。
+
+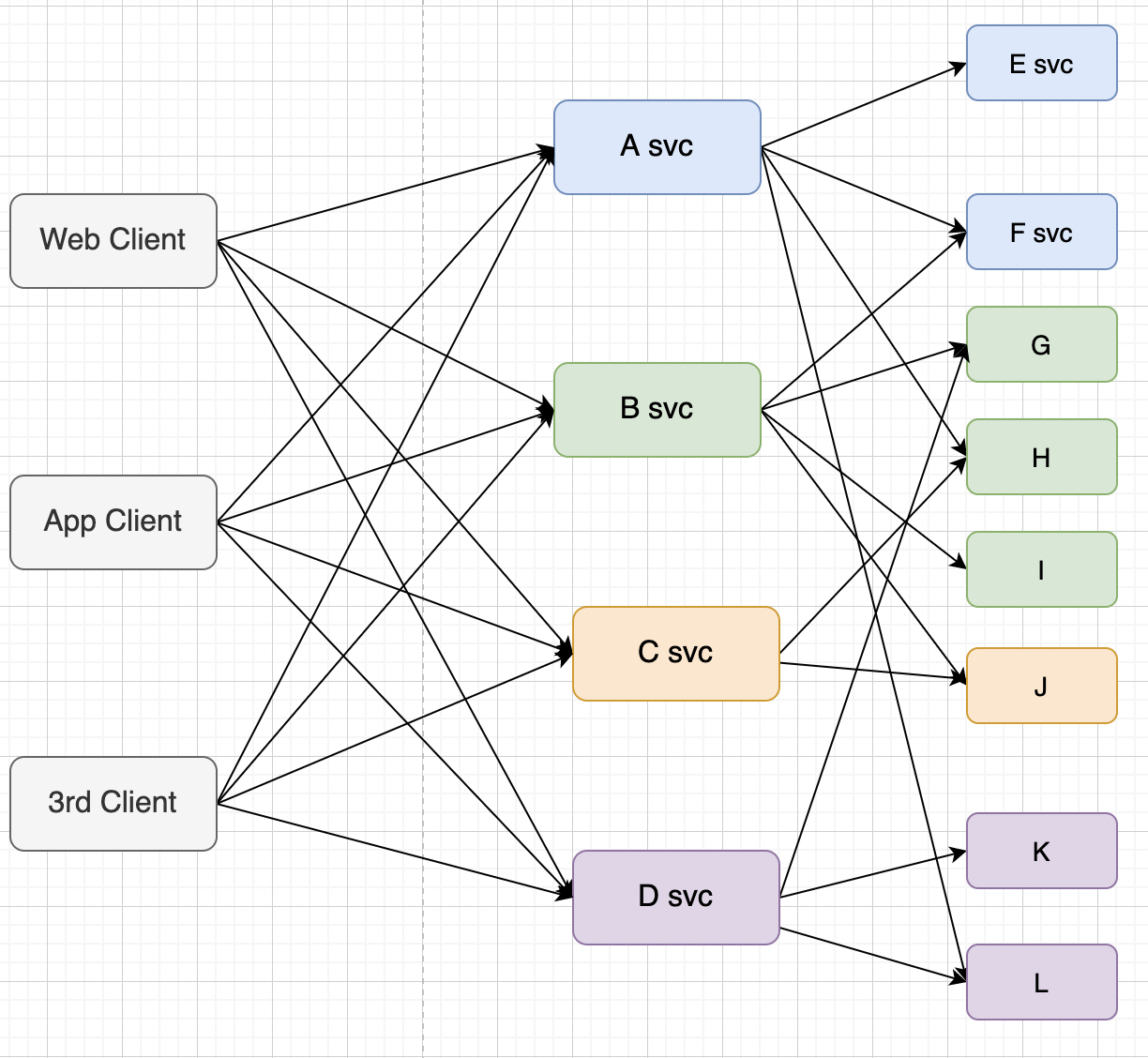
+
+- 按照职能将服务进行了拆分,这时候从不同的客户端(如 Web、App、3rd)访问,就有可能访问不同的服务。而服务与服务之间又有上下游的协作,调用就变得错综复杂。
+- 可能需要关注很多问题:
+ - 包括不同的技术栈不同的开发语言之间的上下游交互。
+ - 服务之间的注册与发现,请求认证,接入授权。
+ - 下游对上游进行调用的时候,上游怎么做负载均衡、故障注入、超时重复、熔断、降级、限流、ABTesting 等,端到端之间如何实现监控和 trace。
+
+### 微服务通信的三个方面
+
+### 1.基于网关的通信
+
+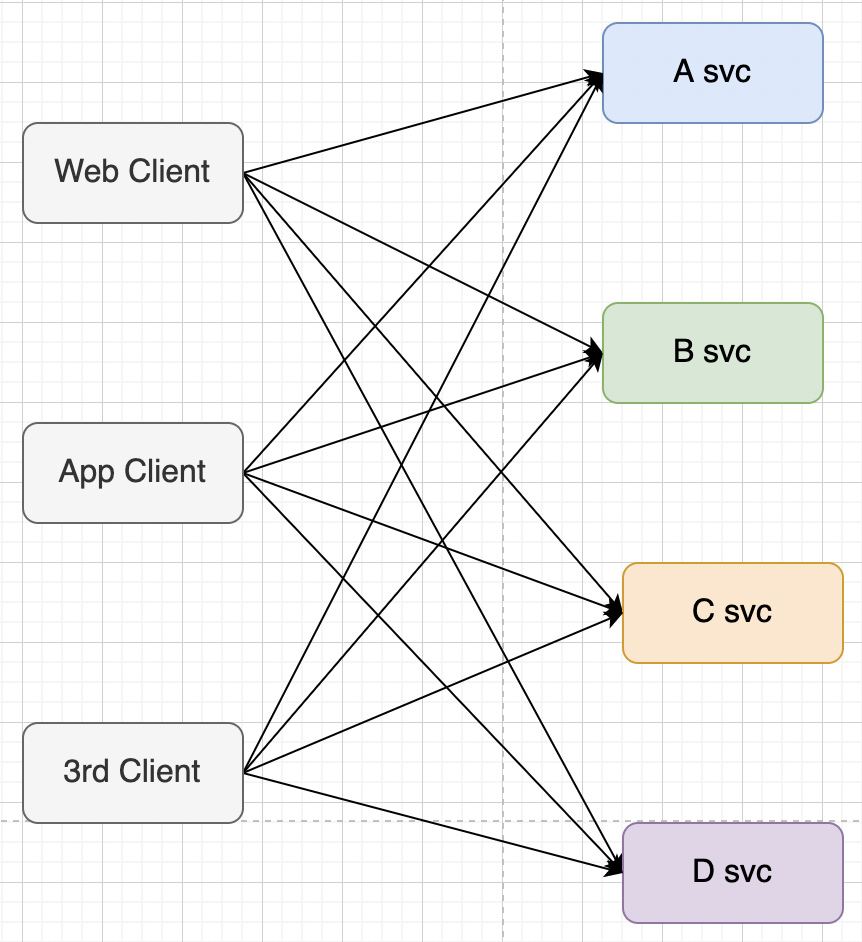
+
+没有网关的情况下进行通讯,如上图有 3 个客户端,在调用 4 个服务的接口。这种直连调用的方式有很多问题:客户端需要保存所有服务的地址,同时也需要实现一些系统级的容错策略。比如负载均衡、超时重试、服务熔断等,非常复杂,并且难以维护。因为是在各客户端保存的服务地址,一旦某个服务端出现问题或者发生迁移,所有的客户端都需要修改并且升级。另外如果再增加一个 E svc,所有的客户端也需要升级。而且在某些场景下存在跨域请求的问题,每个服务都需要实现独立的身份和权限认证等等。
+
+> 客户端都需要修改并且升级。我们需要的是客户端不要有太大的变化。
+
+如果我们在客户端和服务端增加一层网关,所有请求都经过网关转发到对应的下游服务,客户端只需要保存网关的地址并且只和网关进行交互,这样就大大简化了客户端的开发。
+
+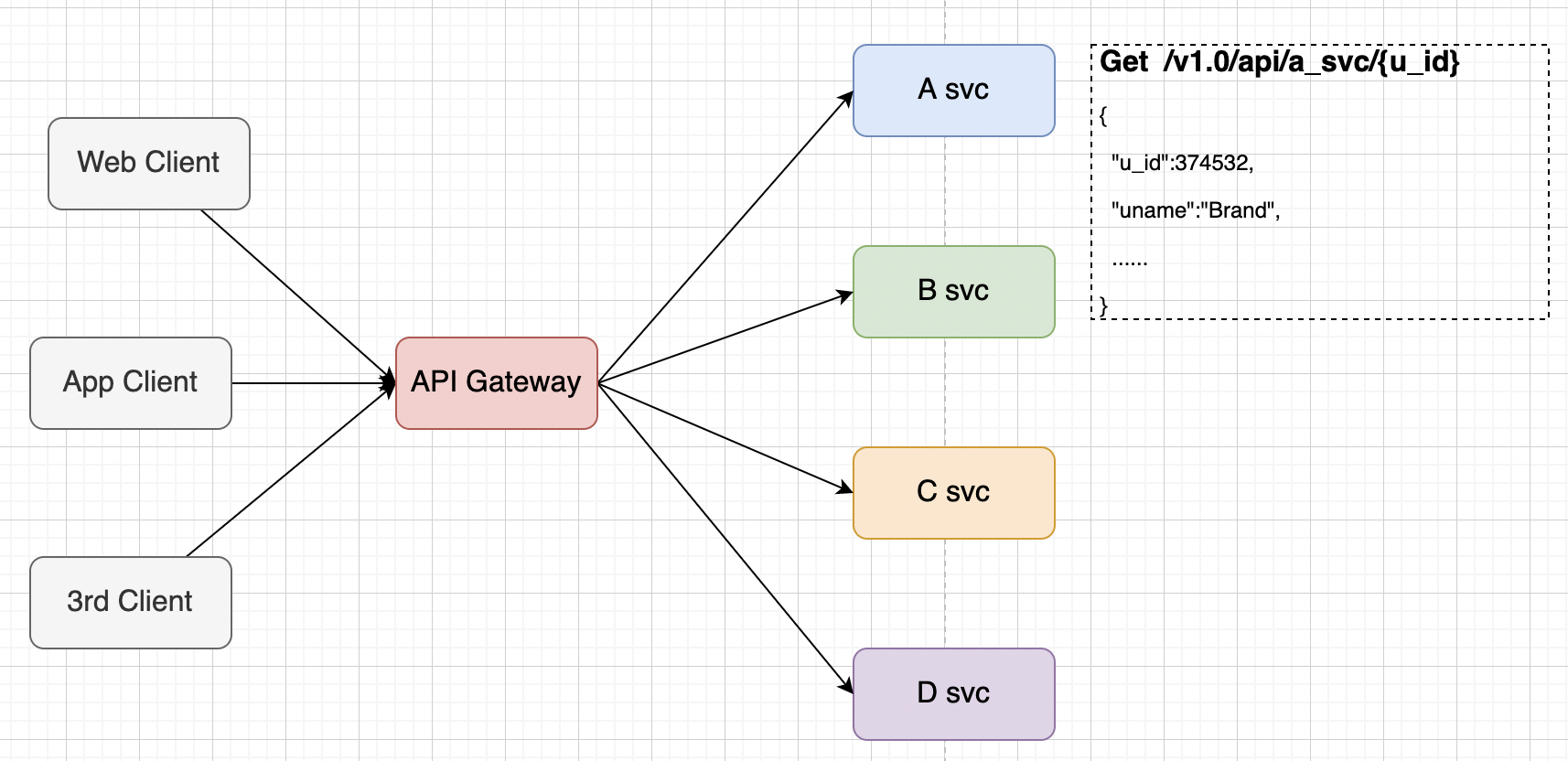
+
+如果需要访问用户服务,只需要构造右边这个请求发给网关,然后由网关将请求转发给对应的下游服务。
+
+可以将网关简单理解为:路由转发+治理策略,治理策略是指和业务无关的一些通用策略,包括:负载均衡,安全认证,身份验证,系统容错等等。网关作为一个 API 架构层,用来保护、增强和控制对服务的访问。
+
+##### 网关的主要功能
+
+###### **请求接入**
+
+1、为各种应用提供统一的服务接入
+
+2、管理所有的接入请求:提供流量分流、代理转发、延迟、故障注入等能力
+
+###### **安全防护**
+
+用户认证、权限校验、黑白名单、请求过滤、防 web 攻击
+
+###### **治理策略**
+
+负载均衡、接口限流、超时重试、服务熔断、灰度发布、协议适配、流量监控、日志统计等
+
+###### **统一管理**
+
+1、提供配置管理工具
+
+2、对所有服务进行统一管理
+
+3、对中介策略进行统一管理
+
+##### 网关使用场景
+
+###### **蓝绿部署**
+
+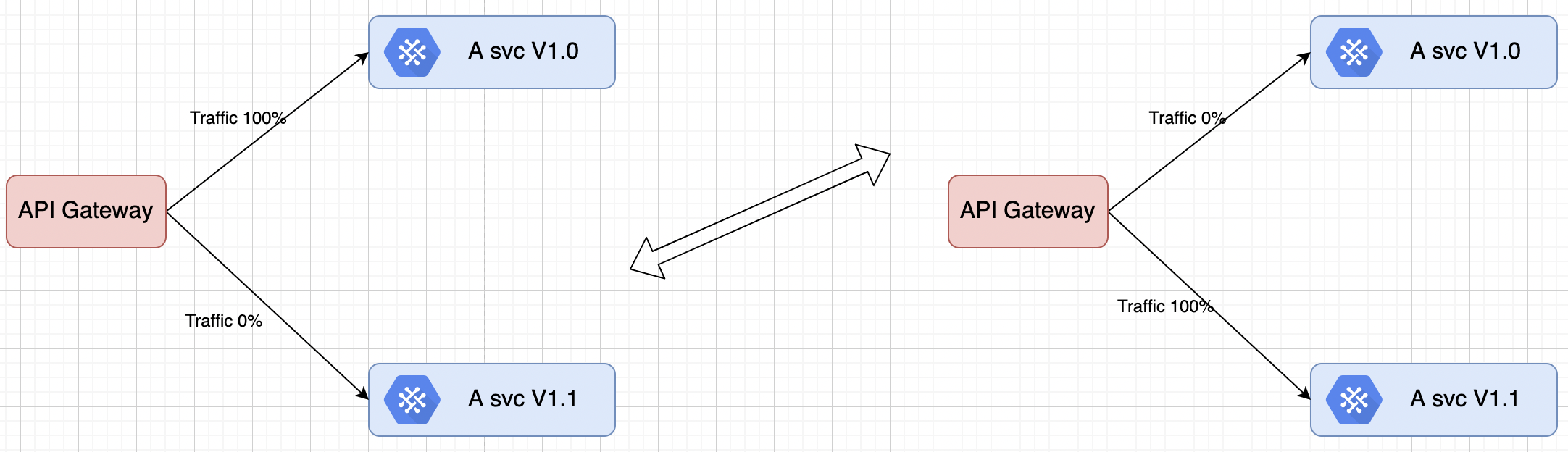
+
+前面看到,在单体应用中,部署是一件比较麻烦的事情,每次的改动,都需要把整个应用程序都发布启动一次。而且系统规模越大,部署过程越复杂,时间越长。
+
+而在微服务架构中,模块部署起来相对更快,更容易。可以在短时间内对于同一个模块做多次部署,网关可以帮实现蓝绿部署。
+
+如图所示之前的用户服务版本是 V1.0,然后部署 V1.1 版本,在网关上只需要做一个转发配置的修改,就可以迅速的将所有流量都流到新版本。
+
+###### **灰度发布**
+
+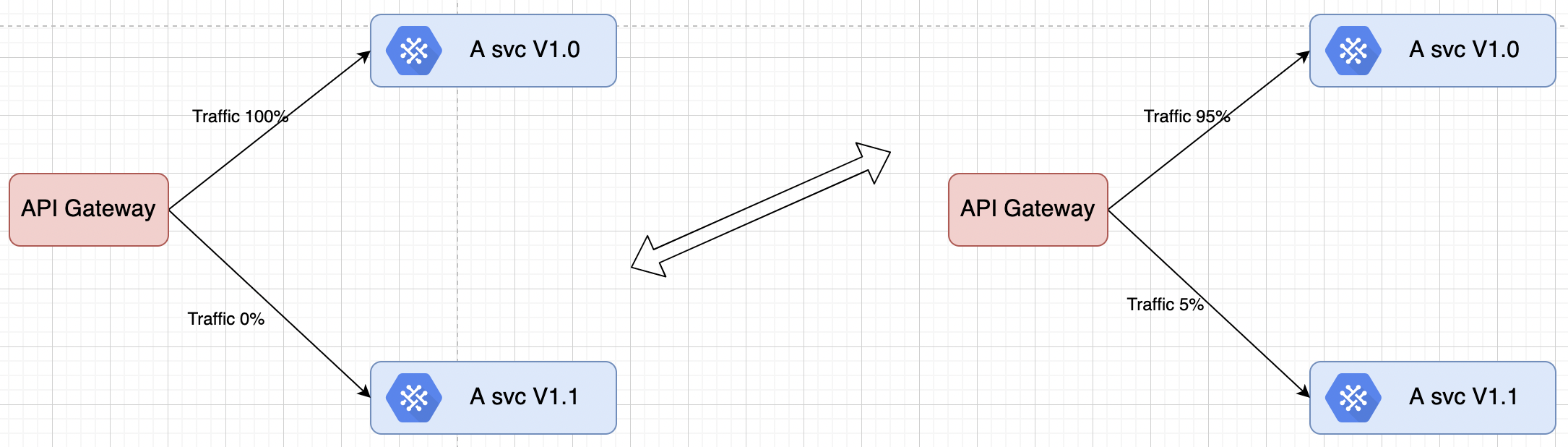
+
+类似金丝雀的理念,对一次性升级版本感到担忧,可以先配置 5%的流量达到新版本,让部分人试用一下,等线上观察一段时间后,可以逐步增加对新版本的流量百分比,最终实现百分之百切流。
+
+###### **负载均衡**
+
+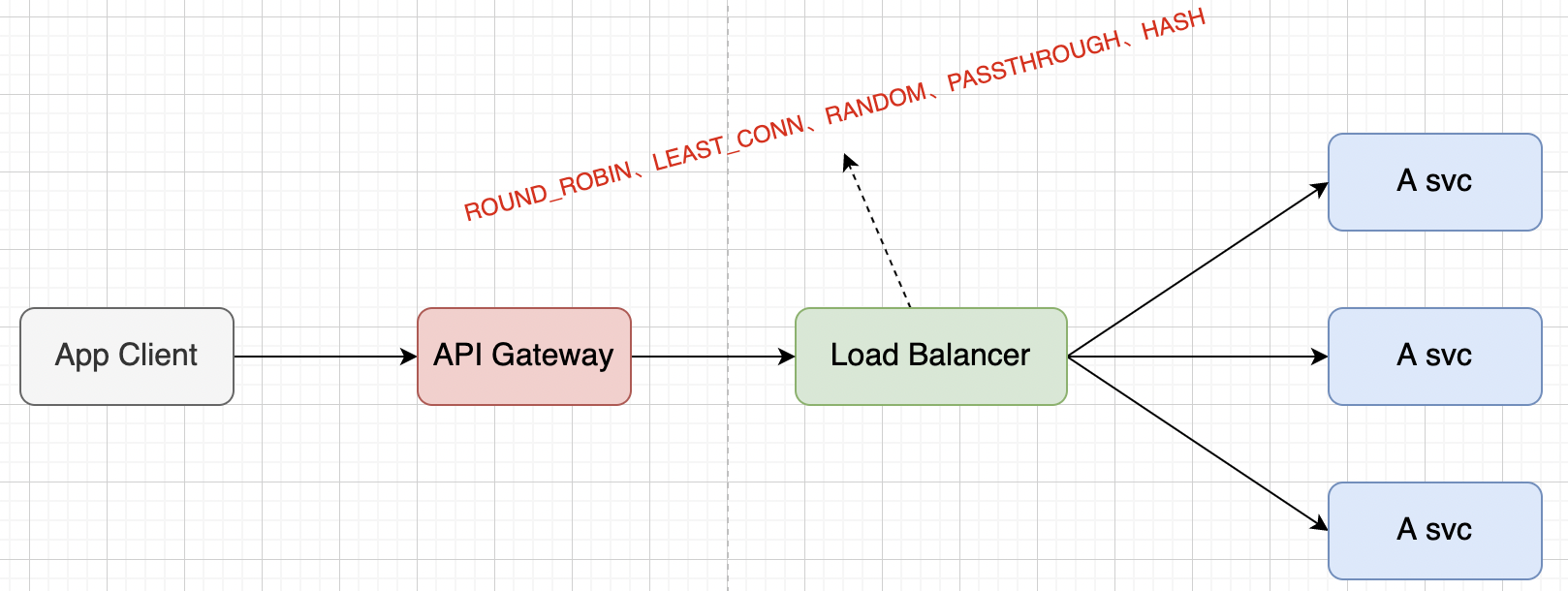
+
+此能力需要依赖服务注册和服务发现。
+
+###### **服务熔断**
+
+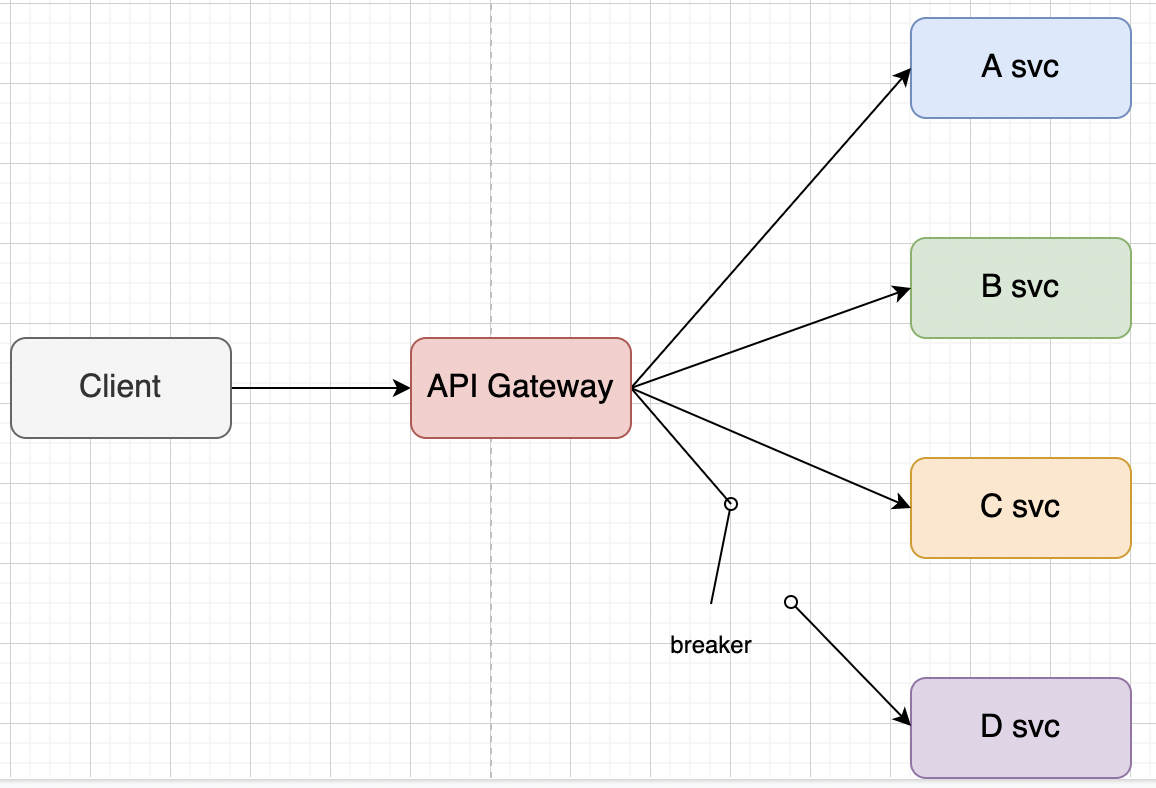
+
+网关还可以实现断路器的功能;如果某个下游忽然返回了大量错误,原因有可能是服务挂了或者网络问题或者服务器负载太高,如果此时继续给这个问题服务转发流量就可能会产生级联故障。
+
+出问题的服务有可能产生雪崩,雪崩会沿着调用链向上传递,导致整个服务链都崩溃。
+
+断路器可以停止向问题模块转发流量,在业务层面可以给用户返回一个服务降级之后的页面,开发人员就有相对充分的时间来定位和解决问题。
+
+##### 开源网关
+
+
+
+### 2.基于 RPC 的通信
+
+### 3.基于 ServiceMesh 的数据面(SideCar)的通信
+
+## 2.微服务的注册与发现
+
+微服务注册与发现类似于生活中的"电话通讯录"的概念,它记录了通讯录服务和电话的映射关系。在分布式架构中,服务会注册进去,当服务需要调用其它服务时,就这里找到服务的地址,进行调用。
+
+- 先要把"好友某某"记录在通讯录中
+- 拨打电话的时候通过通讯录中找到"好友某某",并拨通回电话。
+- 当好友某某电话号码更新的时候,需要通知到,并修改通讯录服务中的号码。
+
+1、把 "好友某某" 的电话号码写入通讯录中,统一在通讯录中维护,后续号码变更也是更新到通讯录中,这个过程就是服务注册的过程。
+
+2、后续我们通过"好友某某"就可以定位到通讯录中的电话号码,并拨通电话,这个过程理解为服务发现的过程。
+
+微服务架构中的服务注册与发现结构如下图所示:
+
+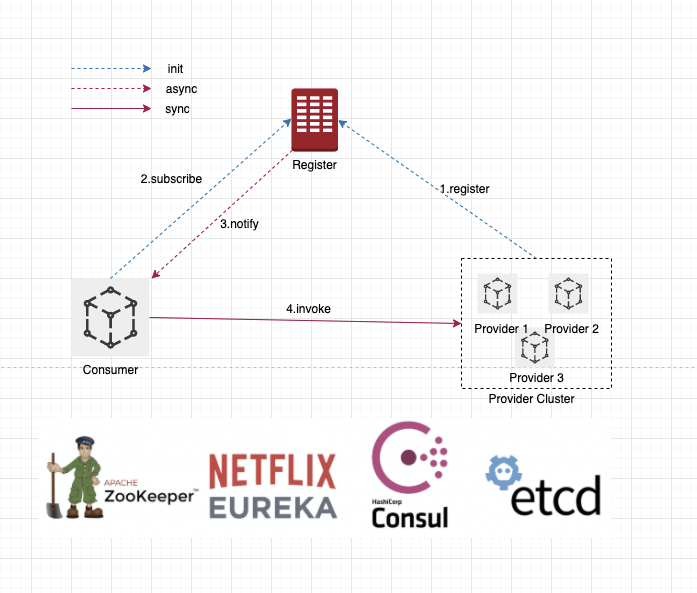
+
+```
+provider - 服务提供者
+consumer - 服务消费者
+register center - 注册中心
+```
+
+它们之间的关系大致如下:
+
+1. 每个微服务在启动时,将自己的网络地址等信息(微服务的`ServiceName`、`IP`、`Port`、`MetaData`等)注册到注册中心,注册中心存储这些数据。
+2. 服务消费者从注册中心查询服务提供者的地址,并通过该地址调用服务提供者的接口。
+3. 各个微服务与注册中心使用一定机制(例如心跳)通信。如果注册中心与某微服务长时间无法通信,就会注销该实例。
+
+优点如下:
+
+1、解耦:服务消费者跟服务提供者解耦,各自变化,不互相影响
+
+2、扩展:服务消费者和服务提供者增加和删除新的服务,对于双方没有任何影响
+
+3、中介者设计模式:用一个中介对象来封装一系列的对象交互,这是一种多对多关系的中介者模式。
+
+#### 服务注册
+
+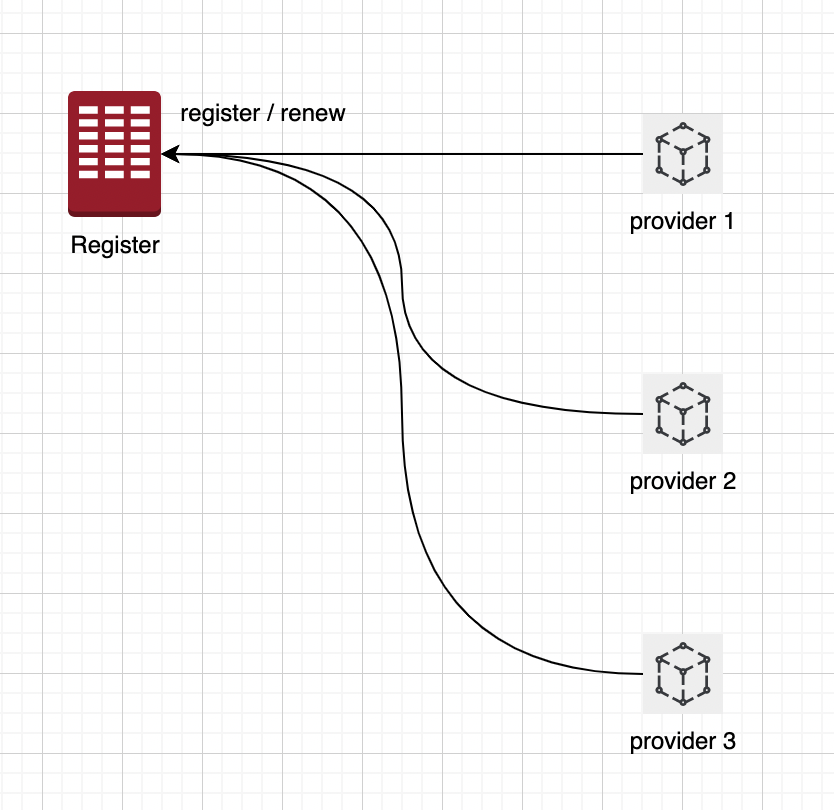
+
+如图中,为 Register 注册中心注册一个服务信息,会将服务的信息:`ServiceName`、`IP`、Port 以及服务实例`MetaData`元数据信息写入到注册中心。当服务发生变化的时候,也可以更新到注册中心。
+
+服务提供者(服务实例) 的服务注册模型是一种简单、容易理解、流行的服务注册模型,其在多种技术生态中都有所体现:
+
+- 在`K8S`生态中,通过 `K8S Service`服务信息,和 Pod 的 endpoint(用来记录 service 对应的 pod 的访问地址)来进行注册。
+- 在 Spring Cloud 生态中,应用名 对应 服务 Service,实例 `IP + Port` 对应 Instance 实例。比较典型的就是 A 服务,后面对应有多个实例做负载均衡。
+- 在其他的注册组件中,比如 Eureka、Consul,服务模型也都是 服务 → 服务实例。
+- 可以认为服务实例是一个真正的实体的载体,服务是对这些相同能力或者相同功能服务实例的一个抽象。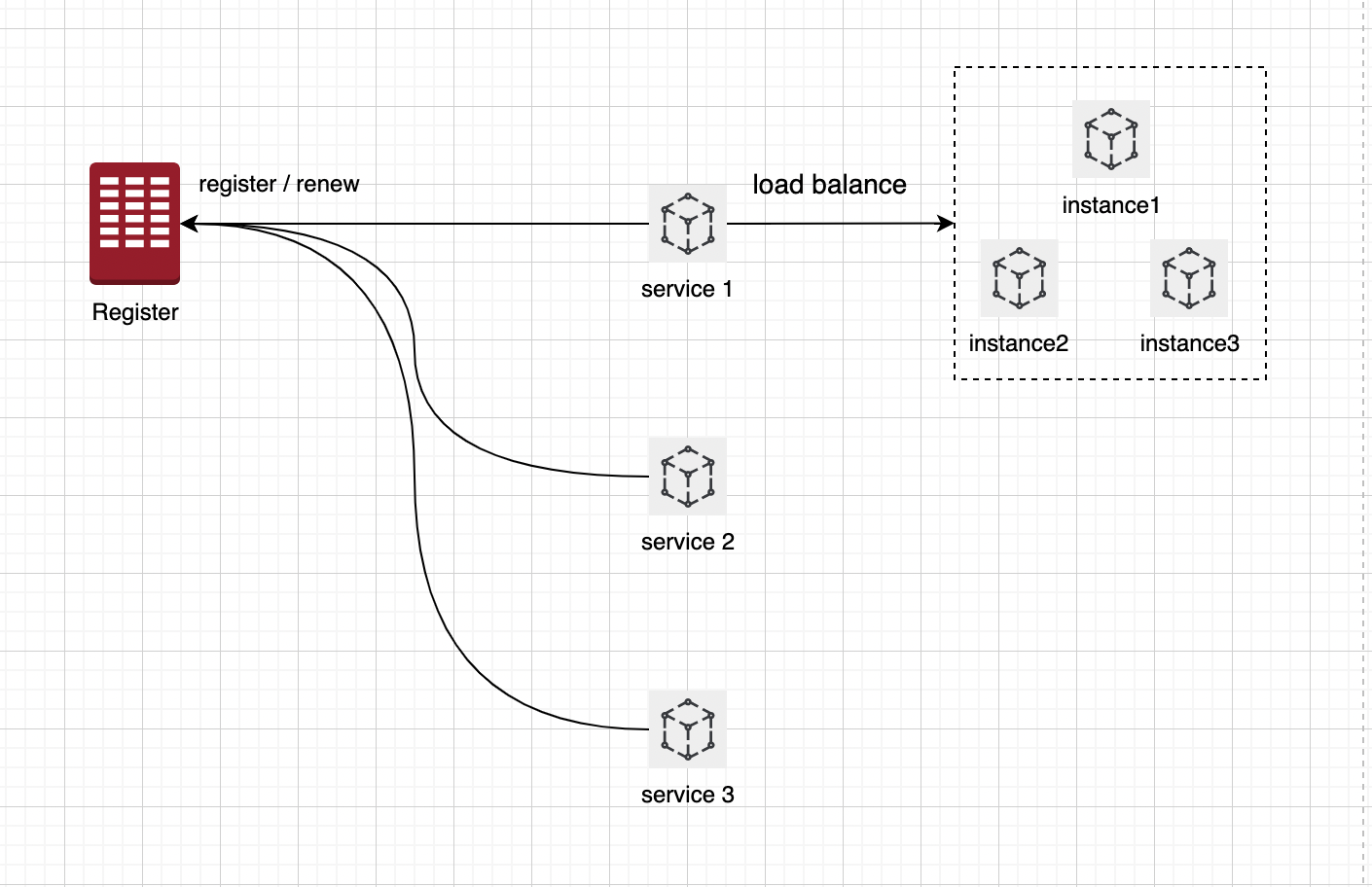
+
+#### 服务发现
+
+- 服务发现实际就是我们查询已经注册好的服务提供者,比如 `p->p.queryService(serviceName`),通过服务名称查询某个服务是否存在,如果存在,
+- 返回它的所有实例信息,即一组包含 ip 、 port 、`metadata`元数据信息的`endpoints`信息。
+- 这一组 endpoints 信息一般会被缓存在本地,如果注册中心挂掉,可保证段时间内依旧可用,这是去中心化的做法。对于单个 Service 后面有多个 Instance 的情况(如上图),做 load balance。
+
+服务发现的方式一般有两种:
+
+1、拉取的方式:服务消费方(Consumer)主动向注册中心发起服务查询的请求。
+
+2、推送的方式:服务订阅/通知变更(下发):服务消费方(Consumer)主动向注册中心订阅某个服务,当注册中心中该服务信息发生变更时,注册中心主动通知消费者。
+
+#### 注册中心
+
+注册中心提供的基本能力包括:提供服务注册、服务发现 以及 健康检查。
+
+服务注册跟服务发现上面已经详细介绍了, 健康检查指的是指注册中心能够感知到微服务实例的健康状况,便于上游微服务实例及时发现下游微服务实例的健康状况。采取必备的访问措施,如避免访问不健康的实例。
+
+主要的检查方式包括:
+
+1、服务 Provider 进行 TTL 健康汇报(Time To Live,微服务 Provider 定期向注册中心汇报健康状态)。
+
+2、注册中心主动检查服务 Provider 接口。
+
+综合我们前面的内容,可以总结下注册中心有如下几种能力:
+
+1、高可用
+
+这个主要体现在两个方面。一个方面是,注册中心本身作为基础设施层,具备高可用;第二种是就是前面我们说到的去中心化,极端情况下的故障,短时间内是不影响微服务应用的调用的
+
+2、可视化操作
+
+常用的注册中心,类似 Eureka、Consul 都有比较丰富的管理界面,对配置、服务注册、服务发现进行可视化管理。
+
+3、高效运维
+
+注册中心的文档丰富,对运维的支持比较好,并且对于服务的注册是动态感知获取的,方便动态扩容。
+
+4、权限控制
+
+数据是具有敏感性,无论是服务信息注册或服务是调用,需要具备权限控制能力,避免侵入或越权请求
+
+5、服务注册推、拉能力
+
+这个前面说过了,微服务应用程序(服务的 Consumer),能够快速感知到服务实例的变化情况,使用拉取或者注册中心下发的方式进行处理。
diff --git a/_posts/2022-08-19-test-markdown.md b/_posts/2022-08-19-test-markdown.md
new file mode 100644
index 000000000000..d7fc5e58bc1f
--- /dev/null
+++ b/_posts/2022-08-19-test-markdown.md
@@ -0,0 +1,326 @@
+---
+layout: post
+title: 什么是 Docker
+subtitle: Docker虚拟化
+tags: [docker]
+---
+
+## 什么是 Docker
+
+> **Docker** 使用 `Google` 公司推出的 [Go 语言](https://golang.google.cn/) 进行开发实现,基于 `Linux` 内核的 [cgroup](https://zh.wikipedia.org/wiki/Cgroups),[namespace](https://en.wikipedia.org/wiki/Linux_namespaces),以及 [OverlayFS](https://docs.docker.com/storage/storagedriver/overlayfs-driver/) 类的 [Union FS](https://en.wikipedia.org/wiki/Union_mount) 等技术,对进程进行封装隔离,属于 [操作系统层面的虚拟化技术](https://en.wikipedia.org/wiki/Operating-system-level_virtualization)。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。最初实现是基于 [LXC](https://linuxcontainers.org/lxc/introduction/),从 `0.7` 版本以后开始去除 `LXC`,转而使用自行开发的 [libcontainer](https://github.com/docker/libcontainer),从 `1.11` 版本开始,则进一步演进为使用 [runC](https://github.com/opencontainers/runc) 和 [containerd](https://github.com/containerd/containerd)。
+
+- 操作系统层面的虚拟化技术
+
+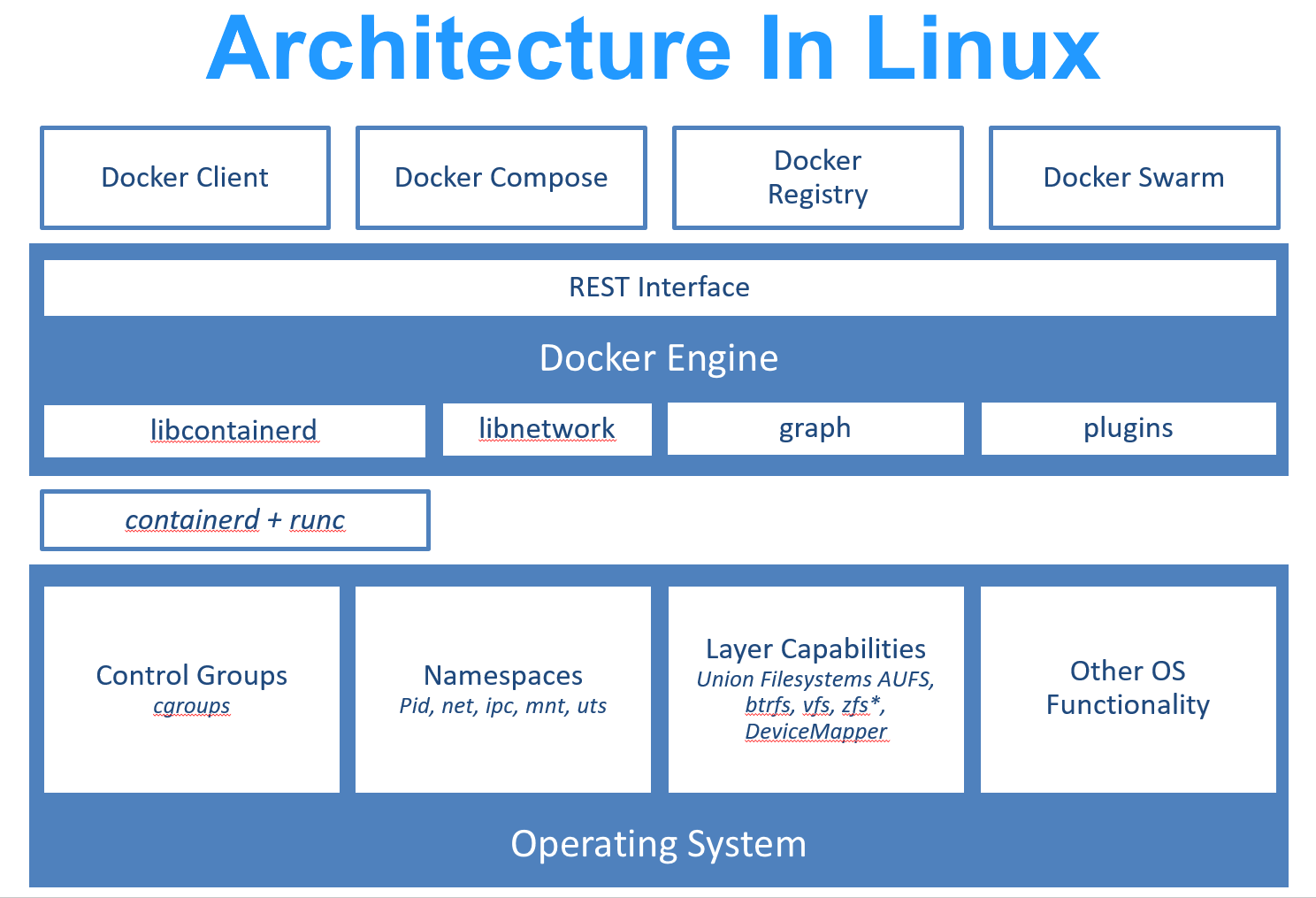
+
+- `runc` 是一个 Linux 命令行工具,用于根据 [OCI 容器运行时规范](https://github.com/opencontainers/runtime-spec) 创建和运行容器。
+- `containerd` 是一个守护程序,它管理容器生命周期,提供了在一个节点上执行容器和管理镜像的最小功能集。
+
+**Docker** 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 `Docker` 技术比虚拟机技术更为轻便、快捷
+
+下面的图片比较了 **Docker** 和传统虚拟化方式的不同之处。传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
+
+
+
+传统虚拟化
+
+
+
+Docker 虚拟化
+
+### 1.Docker 的优点
+
+- **相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用**。
+
+ 由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销`Docker` 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
+
+- **一致的运行环境**
+
+ 开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 `Docker` 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 _「这段代码在我机器上没问题啊」_ 这类问题。
+
+- 定制镜像
+
+ 对开发和运维([DevOps](https://zh.wikipedia.org/wiki/DevOps))人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
+
+ 使用 `Docker` 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 [Dockerfile]() 来进行镜像构建,并结合 [持续集成(Continuous Integration)](https://en.wikipedia.org/wiki/Continuous_integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 [持续部署(Continuous Delivery/Deployment)](https://en.wikipedia.org/wiki/Continuous_delivery) 系统进行自动部署。
+
+ 而且使用 [`Dockerfile`]() 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像
+
+- 轻松的迁移
+
+ 环境的一致性,使得应用的迁移更加容易。`Docker` 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的
+
+- 扩展
+
+ `Docker` 团队同各个开源项目团队一起维护了一大批高质量的 [官方镜像](https://hub.docker.com/search/?type=image&image_filter=official),
+
+### 2.**镜像**(`Image`)
+
+> 我们都知道,操作系统分为 **内核** 和 **用户空间**。对于 `Linux` 而言,内核启动后,会挂载 `root` 文件系统为其提供用户空间支持。而 **Docker 镜像**(`Image`),就相当于是一个 `root` 文件系统
+
+**Docker 镜像** 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像 **不包含** 任何动态数据,其内容在构建之后也不会被改变。
+
+##### 分层存储
+
+因为镜像包含操作系统完整的 `root` 文件系统,其体积往往是庞大的,因此在 Docker 设计时,就充分利用 [Union FS](https://en.wikipedia.org/wiki/Union_mount) 的技术,将其设计为分层存储的架构。所以严格来说,镜像并非是像一个 `ISO` 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由**多层文件系统**联合组成。
+
+镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
+
+分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
+
+> 总结:root 文件系统又被分成多层文件系统。
+
+### 3.**容器**(`Container`)
+
+镜像(`Image`)和容器(`Container`)的关系,就像是面向对象程序设计中的 `类` 和 `实例` 一样,镜像是静态的定义,**容器是镜像运行时的实体**。容器可以被创建、启动、停止、删除、暂停等。
+
+> **容器是镜像运行时的实体**。
+
+容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 [命名空间](https://en.wikipedia.org/wiki/Linux_namespaces)。因此容器可以拥有自己的 `root` 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
+
+前面讲过镜像使用的是**分层存储**,容器也是如此。每一个容器运行时,是以**镜像为基础层,在其上创建一个当前容器的存储层**,我们可以称这个为容器运行时读写而准备的存储层为 **容器存储层**。
+
+> 以**镜像为基础层,在其上创建一个当前容器的存储层**。
+
+按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 [数据卷(Volume)]()、或者 [绑定宿主目录](),在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高
+
+- **文件写入操作应该使用数据卷。**在数据卷的操作会跳过容器存储层。
+- **或者绑定宿主目录。**
+- 数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失
+
+### 4.**仓库**(`Repository`)
+
+#### Docker Registry 集中的存储、分发镜像的服务
+
+镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,[Docker Registry]() 就是这样的服务。一个 **Docker Registry** 中可以包含多个 **仓库**(`Repository`);每个仓库可以包含多个 **标签**(`Tag`);每个标签对应一个镜像。
+
+仓库 属于 [Docker Registry]() 服务,一个仓库可以包含多个 Tag ,一个 tag 标志 一个镜像。
+
+通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 **`<仓库名>:<标签>` 的格式来指定具体是这个软件哪个版本的镜像**。如果不给出标签,将以 `latest` 作为默认标签。 仓库名经常以 _两段式路径_ 形式出现,比如 `jwilder/nginx-proxy`,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名。但这并非绝对,取决于所使用的具体 Docker Registry 的软件或服务。
+
+#### Docker Registry 公开服务
+
+Docker Registry 公开服务是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
+
+最常使用的 Registry 公开服务是官方的 [Docker Hub](https://hub.docker.com/),这也是默认的 Registry,并拥有大量的高质量的 [官方镜像](https://hub.docker.com/search?q=&type=image&image_filter=official)。除此以外,还有 Red Hat 的 [Quay.io](https://quay.io/repository/);Google 的 [Google Container Registry](https://cloud.google.com/container-registry/),[Kubernetes](https://kubernetes.io/) 的镜像使用的就是这个服务;代码托管平台 [GitHub](https://github.com) 推出的 [ghcr.io](https://docs.github.com/cn/packages/working-with-a-github-packages-registry/working-with-the-container-registry)。
+
+由于某些原因,在国内访问这些服务可能会比较慢。国内的一些云服务商提供了针对 Docker Hub 的镜像服务(`Registry Mirror`),这些镜像服务被称为 **加速器**。常见的有 [阿里云加速器](https://www.aliyun.com/product/acr?source=5176.11533457&userCode=8lx5zmtu)、[DaoCloud 加速器](https://www.daocloud.io/mirror#accelerator-doc) 等。使用加速器会直接从国内的地址下载 Docker Hub 的镜像,比直接从 Docker Hub 下载速度会提高很多。在 [安装 Docker]() 一节中有详细的配置方法。
+
+国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [网易云镜像服务](https://c.163.com/hub#/m/library/)、[DaoCloud 镜像市场](https://hub.daocloud.io/)、[阿里云镜像库](https://www.aliyun.com/product/acr?source=5176.11533457&userCode=8lx5zmtu) 等。,
+
+#### 私有 Docker Registry
+
+除了使用公开服务外,用户还可以在本地搭建私有 Docker Registry。Docker 官方提供了 [Docker Registry](https://hub.docker.com/_/registry/) 镜像,可以直接使用做为私有 Registry 服务。在 [私有仓库]() 一节中,会有进一步的搭建私有 Registry 服务的讲解。
+
+开源的 Docker Registry 镜像只提供了 [Docker Registry API](https://docs.docker.com/registry/spec/api/) 的服务端实现,足以支持 `docker` 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
+
+除了官方的 Docker Registry 外,还有第三方软件实现了 Docker Registry API,甚至提供了用户界面以及一些高级功能。比如,[Harbor](https://github.com/goharbor/harbor) 和 [Sonatype Nexus]()。
+
+### 5.使用镜像
+
+在之前的介绍中,我们知道镜像是 Docker 的三大组件之一。
+
+Docker 运行容器前需要本地存在对应的镜像,如果本地不存在该镜像,Docker 会从镜像仓库下载该镜像。
+
+更多关于镜像的内容,包括:
+
+- 从仓库获取镜像;
+
+- 管理本地主机上的镜像;
+
+- 介绍镜像实现的基本原理。
+
+#### 获取镜像
+
+```
+$ docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签]
+
+$ docker pull ubuntu:18.04
+Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/create?fromImage=ubuntu&tag=18.04": dial unix /var/run/docker.sock: connect: permission denied
+
+$ sudo chown gongna:docker /var/run/docker.sock
+
+$ docker pull ubuntu:18.04
+18.04: Pulling from library/ubuntu
+22c5ef60a68e: Pull complete
+Digest: sha256:eb1392bbdde63147bc2b4ff1a4053dcfe6d15e4dfd3cce29e9b9f52a4f88bc74
+Status: Downloaded newer image for ubuntu:18.04
+docker.io/library/ubuntu:18.04
+
+$ ls -l /var/run/docker.sock
+srw-rw---- 1 gongna docker 0 8月 14 14:45 /var/run/docker.sock
+
+$ docker run -it --rm ubuntu:18.04 bash
+oot@14acce5f0a73:/# cat /etc/os-release
+NAME="Ubuntu"
+VERSION="18.04.6 LTS (Bionic Beaver)"
+ID=ubuntu
+ID_LIKE=debian
+PRETTY_NAME="Ubuntu 18.04.6 LTS"
+VERSION_ID="18.04"
+HOME_URL="https://www.ubuntu.com/"
+SUPPORT_URL="https://help.ubuntu.com/"
+BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
+PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
+VERSION_CODENAME=bionic
+UBUNTU_CODENAME=bionic
+root@14acce5f0a73:/# go env
+bash: go: command not found
+root@14acce5f0a73:/# ^C
+root@14acce5f0a73:/# ^C
+root@14acce5f0a73:/#
+
+
+
+
+
+
+```
+
+- `-it`:这是两个参数,一个是 `-i`:交互式操作,一个是 `-t` 终端。我们这里打算进入 `bash` 执行一些命令并查看返回结果,因此我们需要交互式终端。
+
+- `--rm`:这个参数是说容器退出后随之将其删除。默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动 `docker rm`。我们这里只是随便执行个命令,看看结果,不需要排障和保留结果,因此使用 `--rm` 可以避免浪费空间。
+
+- `ubuntu:18.04`:这是指用 `ubuntu:18.04` 镜像为基础来启动容器。
+
+- bash`:放在镜像名后的是 **命令**,这里我们希望有个交互式 Shell,因此用的是 `bash
+
+### 6.列出镜像
+
+```
+$ docker image ls
+ubuntu 18.04 8d5df41c547b 2 weeks ago 63.1MB
+hello-world latest feb5d9fea6a5 10 months ago 13.3kB
+```
+
+列表包含了 `仓库名`、`标签`、`镜像 ID`、`创建时间` 以及 `所占用的空间`。
+
+其中仓库名、标签在之前的基础概念章节已经介绍过了。**镜像 ID** 则是镜像的唯一标识,一个镜像可以对应多个 **标签**。因此,在上面的例子中,如果 拥有相同的 ID,因为它们对应的是同一个镜像。
+
+### 7.镜像体积
+
+如果仔细观察,会注意到,这里标识的所占用空间和在 Docker Hub 上看到的镜像大小不同。比如,`ubuntu:18.04` 镜像大小,在这里是 `63.3MB`,但是在 [Docker Hub](https://hub.docker.com/layers/ubuntu/library/ubuntu/bionic/images/sha256-32776cc92b5810ce72e77aca1d949de1f348e1d281d3f00ebcc22a3adcdc9f42?context=explore) 显示的却是 `25.47 MB`。这是因为 Docker Hub 中显示的体积是压缩后的体积。在镜像下载和上传过程中镜像是保持着压缩状态的,因此 Docker Hub 所显示的大小是网络传输中更关心的流量大小。而 `docker image ls` 显示的是镜像下载到本地后,展开的大小,准确说,是展开后的各层所占空间的总和,因为镜像到本地后,查看空间的时候,更关心的是本地磁盘空间占用的大小。
+
+另外一个需要注意的问题是,`docker image ls` 列表中的镜像体积总和并非是所有镜像实际硬盘消耗。由于 Docker 镜像是多层存储结构,并且可以继承、复用,因此不同镜像可能会因为使用相同的基础镜像,从而拥有共同的层。由于 Docker 使用 Union FS,相同的层只需要保存一份即可,因此实际镜像硬盘占用空间很可能要比这个列表镜像大小的总和要小的多。
+
+可以通过 `docker system df` 命令来便捷的查看镜像、容器、数据卷所占用的空间
+
+```
+$ docker system df
+TYPE TOTAL ACTIVE SIZE RECLAIMABLE
+Images 2 0 63.16MB 63.16MB (100%)
+Containers 0 0 0B 0B
+Local Volumes 0 0 0B 0B
+Build Cache 0 0 0B 0B
+```
+
+##### 中间层镜像
+
+为了加速镜像构建、重复利用资源,Docker 会利用 **中间层镜像**。所以在使用一段时间后,可能会看到一些依赖的中间层镜像。默认的 `docker image ls` 列表中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加 `-a` 参数
+
+```shell
+ docker image ls -a
+```
+
+##### 列出部分镜像
+
+不加任何参数的情况下,`docker image ls` 会列出所有顶层镜像,但是有时候我们只希望列出部分镜像。`docker image ls` 有好几个参数可以帮助做到这个事情。
+
+根据仓库名列出镜像
+
+```shell
+docker image ls ubuntu
+REPOSITORY TAG IMAGE ID CREATED SIZE
+
+ubuntu 18.04 329ed837d508 3 days ago 63.3MB
+
+ubuntu bionic 329ed837d508 3 days ago 63.3MB
+```
+
+##### 列出特定的某个镜像,也就是说指定仓库名和标签
+##### 列出指定格式
+
+```
+$ docker image ls --format "ID: Repository"
+5f515359c7f8: redis
+05a60462f8ba: nginx
+fe9198c04d62: mongo
+00285df0df87:
+329ed837d508: ubuntu
+329ed837d508: ubuntu
+```
+
+#### 8.删除本地镜像
+
+```shell
+$ docker image rm [选项] <镜像1> [<镜像2> ...]
+```
+
+```
+$ docker image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+centos latest 0584b3d2cf6d 3 weeks ago 196.5 MB
+redis alpine 501ad78535f0 3 weeks ago 21.03 MB
+docker latest cf693ec9b5c7 3 weeks ago 105.1 MB
+nginx
+```
+
+```
+$ docker image rm 501
+Untagged: redis:alpine
+Untagged: redis@sha256:f1ed3708f538b537eb9c2a7dd50dc90a706f7debd7e1196c9264edeea521a86d
+Deleted: sha256:501ad78535f015d88872e13fa87a828425117e3d28075d0c117932b05bf189b7
+Deleted: sha256:96167737e29ca8e9d74982ef2a0dda76ed7b430da55e321c071f0dbff8c2899b
+Deleted: sha256:32770d1dcf835f192cafd6b9263b7b597a1778a403a109e2cc2ee866f74adf23
+Deleted: sha256:127227698ad74a5846ff5153475e03439d96d4b1c7f2a449c7a826ef74a2d2fa
+Deleted: sha256:1333ecc582459bac54e1437335c0816bc17634e131ea0cc48daa27d32c75eab3
+Deleted: sha256:4fc455b921edf9c4aea207c51ab39b10b06540c8b4825ba57b3feed1668fa7c7
+```
+
+- 我们可以用镜像的完整 ID,也称为 `长 ID`,来删除镜像。使用脚本的时候可能会用长 ID,但是人工输入就太累了,所以更多的时候是用 `短 ID` 来删除镜像。`docker image ls` 默认列出的就已经是短 ID 了,一般取前 3 个字符以上,只要足够区分于别的镜像就可以了
+- 我们也可以用`镜像名`,也就是 `<仓库名>:<标签>`,来删除镜像。
+
+```
+$ docker image rm centos
+Untagged: centos:latest
+Untagged: centos@sha256:b2f9d1c0ff5f87a4743104d099a3d561002ac500db1b9bfa02a783a46e0d366c
+Deleted: sha256:0584b3d2cf6d235ee310cf14b54667d889887b838d3f3d3033acd70fc3c48b8a
+Deleted: sha256:97ca462ad9eeae25941546209454496e1d66749d53dfa2ee32bf1faabd239d38
+```
+
+当然,更精确的是使用 `镜像摘要` 删除镜像。
+
+```
+$ docker image ls --digests
+REPOSITORY TAG DIGEST IMAGE ID CREATED SIZE
+node slim sha256:b4f0e0bdeb578043c1ea6862f0d40cc4afe32a4a582f3be235a3b164422be228 6e0c4c8e3913 3 weeks ago 214 MB
+
+$ docker image rm node@sha256:b4f0e0bdeb578043c1ea6862f0d40cc4afe32a4a582f3be235a3b164422be228
+Untagged: node@sha256:b4f0e0bdeb578043c1ea6862f0d40cc4afe32a4a582f3be235a3b164422be228
+```
+
+#### 9.Untagged 和 Deleted
+
+如果观察上面这几个命令的运行输出信息的话,会注意到删除行为分为两类,一类是 `Untagged`,另一类是 `Deleted`。我们之前介绍过,镜像的唯一标识是其 ID 和摘要,而一个镜像可以有多个标签。
+
+因此当我们使用上面命令删除镜像的时候,实际上是在要求删除某个标签的镜像。所以首先需要做的是将满足我们要求的所有镜像标签都取消,这就是我们看到的 `Untagged` 的信息。因为一个镜像可以对应多个标签,因此当我们删除了所指定的标签后,可能还有别的标签指向了这个镜像,如果是这种情况,那么 `Delete` 行为就不会发生。所以并非所有的 `docker image rm` 都会产生删除镜像的行为,有可能仅仅是取消了某个标签而已。
+
+当该镜像所有的标签都被取消了,该镜像很可能会失去了存在的意义,因此会触发删除行为。镜像是多层存储结构,因此在删除的时候也是从上层向基础层方向依次进行判断删除。镜像的多层结构让镜像复用变得非常容易,因此很有可能某个其它镜像正依赖于当前镜像的某一层。这种情况,依旧不会触发删除该层的行为。直到没有任何层依赖当前层时,才会真实的删除当前层。这就是为什么,有时候会奇怪,为什么明明没有别的标签指向这个镜像,但是它还是存在的原因,也是为什么有时候会发现所删除的层数和自己 `docker pull` 看到的层数不一样的原因。
+
+除了镜像依赖以外,还需要注意的是容器对镜像的依赖。如果有用这个镜像启动的容器存在(即使容器没有运行),那么同样不可以删除这个镜像。之前讲过,容器是以镜像为基础,再加一层容器存储层,组成这样的多层存储结构去运行的。因此该镜像如果被这个容器所依赖的,那么删除必然会导致故障。如果这些容器是不需要的,应该先将它们删除,然后再来删除镜像。
+
+#### 10.用 docker image ls 命令来配合
+
+像其它可以承接多个实体的命令一样,可以使用 `docker image ls -q` 来配合使用 `docker image rm`,这样可以成批的删除希望删除的镜像。我们在“镜像列表”章节介绍过很多过滤镜像列表的方式都可以拿过来使用。
+
+比如,我们需要删除所有仓库名为 `redis` 的镜像:
+
+```
+$ docker image rm $(docker image ls -q redis)
+```
+
+或者删除所有在 `mongo:3.2` 之前的镜像:
+
+```
+$ docker image rm $(docker image ls -q -f before=mongo:3.2)
+```
diff --git a/_posts/2022-08-20-test-markdown.md b/_posts/2022-08-20-test-markdown.md
new file mode 100644
index 000000000000..add7d7f09589
--- /dev/null
+++ b/_posts/2022-08-20-test-markdown.md
@@ -0,0 +1,220 @@
+---
+layout: post
+title: 如何操作Docker容器
+subtitle:
+tags: [docker]
+---
+# **操作容器**
+
+容器是 Docker 又一核心概念。
+
+简单的说,容器是独立运行的一个或一组**应用**,以及它们的**运行态环境**。对应的,虚拟机可以理解为模拟运行的一整套操作系统(提供了运行态环境和其他系统环境)和跑在上面的应用。
+
+本章将具体介绍如何来管理一个容器,包括创建、启动和停止等。
+
+### 1.新建并启动
+
+所需要的命令主要为 `docker run`。
+
+例如,下面的命令输出一个 “Hello World”,之后终止容器。
+
+```
+$ docker run ubuntu:18.04 /bin/echo 'Hello world'
+
+Hello world
+```
+
+下面的命令则启动一个 bash 终端,允许用户进行交互
+
+```
+$ docker run -t -i ubuntu:18.04 /bin/bash
+root@af8bae53bdd3:/#
+```
+
+其中,`-t` 选项让Docker分配一个伪终端(pseudo-tty)并绑定到容器的标准输入上, `-i` 则让容器的标准输入保持打开。
+
+```
+root@af8bae53bdd3:/# pwd
+/
+root@af8bae53bdd3:/# ls
+bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
+```
+
+Docker 在后台运行的标准操作包括:
+
+- 检查本地是否存在指定的镜像,不存在就从 [registry]() 下载
+- 利用镜像创建并启动一个容器
+- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
+- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
+- 从地址池配置一个 `ip` 地址给容器
+- 执行用户指定的应用程序
+- 执行行完毕后容器被终止
+
+### 2.启动已终止容器
+
+可以利用 `docker container start` 命令,直接将一个已经终止(`exited`)的容器启动运行。
+
+容器的核心为所执行的应用程序,所需要的资源都是应用程序运行所必需的。除此之外,并没有其它的资源。可以在伪终端中利用 `ps` 或 `top` 来查看进程信息。
+
+```
+root@ba267838cc1b:/# ps
+ PID TTY TIME CMD
+ 1 ? 00:00:00 bash
+ 11 ? 00:00:00 ps
+```
+
+可见,容器中仅运行了指定的 bash 应用。这种特点使得 Docker 对资源的利用率极高,是货真价实的轻量级虚拟化。
+
+### 3.**守护态运行**
+
+```
+$ docker run ubuntu:18.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
+hello world
+hello world
+hello world
+hello world
+```
+
+如果使用了 `-d` 参数运行容器。
+
+```
+$ docker run -d ubuntu:18.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
+77b2dc01fe0f3f1265df143181e7b9af5e05279a884f4776ee75350ea9d8017a
+```
+
+此时容器会在后台运行并不会把输出的结果 (STDOUT) 打印到宿主机上面(输出结果可以用 `docker logs` 查看)。
+
+**注:** 容器是否会长久运行,是和 `docker run` 指定的命令有关,和 `-d` 参数无关。
+
+使用 `-d` 参数启动后会返回一个唯一的 id,也可以通过 `docker container ls` 命令来查看容器信息。
+
+```
+$ docker container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+77b2dc01fe0f ubuntu:18.04 /bin/sh -c 'while tr 2 minutes ago Up 1 minute agitated_wright
+```
+
+要获取容器的输出信息,可以通过 `docker container logs` 命令
+
+```
+$ docker container logs [container ID or NAMES]
+hello world
+hello world
+hello world
+. . .
+```
+
+可以使用 `docker container stop` 来终止一个运行中的容器。
+
+此外,当 Docker 容器中指定的应用终结时,容器也自动终止。
+
+例如对于上一章节中只启动了一个终端的容器,用户通过 `exit` 命令或 `Ctrl+d` 来退出终端时,所创建的容器立刻终止。
+
+终止状态的容器可以用 `docker container ls -a` 命令看到。例如
+
+```
+$ docker container ls -a
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+ba267838cc1b ubuntu:18.04 "/bin/bash" 30 minutes ago Exited (0) About a minute ago trusting_newton
+```
+
+处于终止状态的容器,可以通过 `docker container start` 命令来重新启动。
+
+此外,`docker container restart` 命令会将一个运行态的容器终止,然后再重新启动它。
+
+### 4.进入容器
+
+在使用 `-d` 参数时,容器启动后会进入后台。
+
+某些时候需要进入容器进行操作,包括使用 `docker attach` 命令或 `docker exec` 命令,推荐大家使用 `docker exec` 命令,原因会在下面说明。
+
+##### `attach` 命令
+
+下面示例如何使用 `docker attach` 命令。
+
+```
+$ docker run -dit ubuntu
+243c32535da7d142fb0e6df616a3c3ada0b8ab417937c853a9e1c251f499f550
+
+$ docker container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+243c32535da7 ubuntu:latest "/bin/bash" 18 seconds ago Up 17 seconds nostalgic_hypatia
+
+$ docker attach 243c
+root@243c32535da7:/#
+```
+
+*注意:* 如果从这个 stdin 中 exit,会导致容器的停止。
+
+##### `exec` 命令
+
+`-i` `-t` 参数
+
+`docker exec` 后边可以跟多个参数,这里主要说明 `-i` `-t` 参数。
+
+```
+$ docker run -dit ubuntu
+69d137adef7a8a689cbcb059e94da5489d3cddd240ff675c640c8d96e84fe1f6
+
+$ docker container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+69d137adef7a ubuntu:latest "/bin/bash" 18 seconds ago Up 17 seconds zealous_swirles
+
+$ docker exec -i 69d1 bash
+ls
+bin
+boot
+dev
+...
+
+$ docker exec -it 69d1 bash
+root@69d137adef7a:/#
+```
+
+如果从这个 stdin 中 exit,不会导致容器的停止。这就是为什么推荐大家使用 `docker exec` 的原因。
+
+### 5.容器的导入和导出
+
+##### 导出容器
+
+如果要导出本地某个容器,可以使用 `docker export` 命令
+
+```
+$ docker container ls -a
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+7691a814370e ubuntu:18.04 "/bin/bash" 36 hours ago Exited (0) 21 hours ago test
+$ docker export 7691a814370e > ubuntu.tar
+```
+
+这样将导出容器快照到本地文件
+
+##### 导入容器快照
+
+```
+$ cat ubuntu.tar | docker import - test/ubuntu:v1.0
+$ docker image ls
+REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
+test/ubuntu v1.0 9d37a6082e97 About a minute ago 171.3 MB
+```
+
+可以使用 `docker import` 从容器快照文件中再导入为镜像,例如
+
+```
+$ docker import http://example.com/exampleimage.tgz example/imagerepo
+```
+
+### 6.**删除容器**
+
+可以使用 `docker container rm` 来删除一个处于终止状态的容器。例如
+
+```
+$ docker container rm trusting_newton
+trusting_newton
+```
+
+清理所有处于终止状态的容器
+
+```
+$ docker container prune
+```
+
diff --git a/_posts/2022-08-21-test-markdown.md b/_posts/2022-08-21-test-markdown.md
new file mode 100644
index 000000000000..2728beb3189f
--- /dev/null
+++ b/_posts/2022-08-21-test-markdown.md
@@ -0,0 +1,92 @@
+---
+layout: post
+title: 利用 commit 理解镜像构成
+subtitle: 镜像是容器的基础
+tags: [Microservices gateway ]
+---
+# **利用 commit 理解镜像构成**
+
+注意: `docker commit` 命令除了学习之外,还有一些特殊的应用场合,比如被入侵后保存现场等。但是,不要使用 `docker commit` 定制镜像,定制镜像应该使用 `Dockerfile` 来完成。
+
+镜像是容器的基础,每次执行 `docker run` 的时候都会指定哪个镜像作为容器运行的基础。在之前的例子中,我们所使用的都是来自于 Docker Hub 的镜像。直接使用这些镜像是可以满足一定的需求,而当这些镜像无法直接满足需求时,我们就需要定制这些镜像。接下来的几节就将讲解如何定制镜像。
+
+回顾一下之前我们学到的知识,`镜像是多层存储`,每一层是在前一层的基础上进行的修改;而`容器同样也是多层存储`,是在以镜像为基础层,**在其基础上加一层作为容器运行时的存储层**。
+
+现在让我们以定制一个 Web 服务器为例子,来讲解镜像是如何构建的
+
+```
+$ docker run --name webserver -d -p 80:80 nginx
+```
+
+这条命令会用 `nginx` 镜像启动一个容器,命名为 `webserver`,并且映射了 80 端口,这样我们可以用浏览器去访问这个 `nginx` 服务器。
+
+如果是在本机运行的 Docker,那么可以直接访问:`http://localhost` ,如果是在虚拟机、云服务器上安装的 Docker,则需要将 `localhost` 换为虚拟机地址或者实际云服务器地址。
+
+直接用浏览器访问的话,我们会看到默认的 Nginx 欢迎页面。
+
+现在,假设我们非常不喜欢这个欢迎页面,我们希望改成欢迎 Docker 的文字,我们可以使用 `docker exec` 命令进入容器,修改其内容。
+
+```
+$ docker exec -it webserver bash
+root@3729b97e8226:/# echo '
+
+CQRS 作为一个**读写分离思想的架构**,在数据存储方面,也没有做过多的约束。所以 CQRS可以有不同层次的实现。
+
+#### CQRS 实现方式:
+
+###### 第一种实现:CQ 两端数据库共享,只是在上层代码上分离。
+
+好处是可以让我们的代码读写分离,更容易维护,而且不存在 CQ 两端的数据一致性问题。因为是共享一个数据库的。这种架构是非常实用的(也就是上面画的那种)
+
+###### 第二种实现:CQ 两端不仅代码分离,数据库也分离,然后Q端数据由C端同步过来
+
+同步方式有两种:同步或异步,如果需要 CQ 两端的强一致性,则需要用同步;如果能接受 CQ 两端数据的最终一致性,则可以使用异步。
+
+C端可以采用Event Sourcing(简称ES)模式,所有C端的最新数据全部用 Domain Event 表达即可。要查询显示用的数据,则从Q端的 ReadDB(关系型数据库)查询即可。
+
+###### 第一种CQRS 的简单实现:
+
+代码层面实现分离,数据库共享。
+
+CQRS 模式中,首先需要有 Command,这个 Command 命令会对应一个实体和一个命令的执行类。肯定有很多不同的 Command,那么还需要一个 CommandBus 来做命令的分发处理。
+
+假设有个用户管理模块,我要新增一个用户的信息。那么根据上文的分析,需要有个新增命令以及对应的用户实体(这个用户实体并不一定和数据库的订单实体完全对应)。
+
+- 首先先创建一个命令接口,接口内部是这个命令的处理方法。
+
+ ```
+ type Create interface{
+ Excute()
+ }
+ ```
+
+- 创建用户的新增命令
+
+ ```
+ type UserCreate struct{
+ account string
+ password string
+ }
+ func (u *UserCreate) Excute(){
+ //检验是否合法,为了防止恶意的新增用户的请求
+ //然后创建一个和数据库对应的model
+ //数据赋值
+ //插入到数据库当中
+ }
+ ```
+
+- 写好命令具体的执行逻辑之后,该命令的执行需要放到 CommandBus 中去执行
+
+ ```
+ type CommandBus struct{
+ }
+ func (b *CommandBus) DisPath( c Create){
+ c.Excute()
+ }
+ ```
+
+- Controller 层该如何去调用呢?
+
+ ```
+ //java实现
+ @PostMapping(value = "/getInfo")
+ public Object getOrderInfo(GetOrderInfoModel model) {
+ return getOrderInfoService.getOrderInfos(model);
+ }
+
+ @PostMapping(value = "/creat")
+ public Object createOrderInfo(CreateOrderModel model) {
+ return commandBus.dispatch(createOrderCommand, model);
+ }
+
+ ```
+
+ 查询和插入是不同的方式,插入走的是 `CommandBus` 分发到 `CreateOrderCommand` 去执行.
+
+ #### tips:
+
+ CQRS 是一种思想很简单清晰的设计模式,通过在业务上分离**操作**和**查询**来使得系统具有更好的可扩展性及性能,使得能够对系统的不同部分进行扩展和优化。在 CQRS 中,所有的涉及到对 DB 的操作都是通过发送 Command,然后特定的 Command 触发对应事件来完成操作,也可以做成异步的,主要看业务上的需求了。
+
+### 3.CQRS解决了什么问题
+
+当使用像 CRUD 这样的传统架构时,使用相同的数据模型来更新和查询数据库以获得大规模解决方案,最终可能会成为一种负担。例如:
+
+- 读取端点可以在查询端对不同的源执行多个查询,以返回具有不同形状的复杂 DTO 映射。我们已经知道映射可能会变得相当复杂
+- 在写入方面,模型可能会**实现多个复杂的业务规则**来**验证创建**和**更新操作。**
+- 我们可能希望以其他方式查询模型,可能将多条记录合并为一条,或者将**更多信息聚合**到当前在其域中不可用的模型,或者只是通过使用一些辅助字段来更改查询查看记录的方式作为一把钥匙。
+- 结果,我们围绕模型对象的 CRUD 服务开始做太多事情,并且随着它的增长变得最糟糕。
+
+### 4.CQRS模式
+
+CQRS 是*Command and Query Responsibility Segregation*
+
+它的主要目的是基于将数据操作(命令)与读取操作(查询)分离的简单思想。为了实现这一点,它将**读取**和**写入**分离到不同的模型中,使用命令进行创建/更新,并使用查询从它们中读取数据。
+
+
+
+如上图所示,您会注意到,每次在写入端创建/更新我们域的实例时,都会通过将事件推送到主题上来连接写入和读取世界的事件队列。然后,查询服务将从传入的事件中读取,对数据进行非规范化、丰富、切片和切块,以创建查询优化模型并将它们存储起来以供以后读取。
+
+特别是,重点在于**通过将事件溯源架构**添加到组合中来**利用 CQRS 模式**。当我们希望保持此流程具有明确的**关注点分离**、**异步**以及**利用适当的数据库引擎**以提高查询性能时(例如,用于写作的 SQL 数据库和用于在物化视图上查询操作的 NoSQL),它非常适合查询以避免昂贵的连接)
+
+除此之外,当我们使用事件溯源架构时,事件主题将成为我们的黄金数据源,因为它可以**随时用于存放整个事件集合**并**重现数据的当前状态**。这样我们就有可能从一开始就**异步读取队列**,并在系统进化时,或者读取模型必须改变时,从原始数据中生成一组新的**物化视图**。物化视图实际上是**数据的持久只读缓存**。
+
+分离世界的另一个好处是有机会分别扩展两者,从而减少锁争用。由于大多数复杂的业务逻辑都进入了写入模型。因此通过分离模型使它们更加灵活并简化了维护。
+
+##### 5.CQRS适用场合
+
+- 数据读取的性能必须与数据写入的性能分开进行微调,尤其是在读取次数远大于写入次数时。在这种情况下,您可以扩展读取模型,但仅在少数实例上运行写入模型。
+- 允许读取最终一致的数据。由于这种模式的**异步**性质。
+
+
+
+## DDD 不是什么?
+
+- DDD 不是一个软件框架。但是基于 DDD 思想的框架是存在的,比如 Axon,它是以 DDD 为**指导思想**,使用 Java 实现的一个微服务软件框架。
+- DDD 不是一种软件设计模式。它不是像工厂,单例这样子的设计模式。但是 DDD 思想中提出了**诸如资源库(Repository)之类的设计模式**。
+- DDD 不是一种系统架构模式。它不是像 MVC 之类的架构模式。但是 DDD 思想中提出了诸如事件溯源(Event Souring),读写隔离(Command Query Responsibility Segregation) 之类的架构模式。
+
+
+
+### 1.DDD 到底是什么?
+
+> 建模的方法论
+
+软件是服务于人类,为提高人类生产效率而产生的一种工具, 每一个软件都服务于某一个特定的领域。比如一个 CRM,它是以管理客户数据为核心,帮助商户与客户保持联系的工具。而软件的实质是计算机中**运行的代码**,如何**将抽象的代码更准确地映射到人类所关心的领域**中,这是软件开发者一直在探寻的话题.函数式编程(FP)还是面向对象编程(OOP)也好,都是为了帮助开发者开发出更贴近于领域中的软件模型。
+
+在传统的软件开发方法中,我们常常会遇到一系列影响软件质量的技术以及非技术问题:
+
+- 开发者热衷于技术,但缺乏设计和业务思考。开发人员在不完全了解业务需求的情况下,闭门造车,即使功能上线也无人问津。
+- 代码输入而非业务输入。技术人员对技术实现情有独钟,出现杀鸡焉用牛刀的情况。
+- 过于重视数据库。以数据库设计为中心,而非业务来进行开发,结果往往是,软件无法适应一直在变动的业务逻辑。
+
+**DDD 是一种设计思想,一种以领域(业务)为出发点,以解决软件建模复杂度为目的设计思想.就是建模的方法论。**
+
+### 2.DDD 的设计思想:战略和战术
+
+#### 战略设计
+
+##### 通用语言(Ubiquitous Language)
+
+开发人员习惯了使用技术术语,领域专家(领域专家在此泛指精通业务的专家,比如用户,客户等等)对技术术语毫不关心,于是造成了不可避免的沟通问题,一旦沟通出现问题,开发出来的软件便很难解决领域专家的真正痛点。通用语言是 DDD 思想的基石,它是开发人员和领域专家共同创建一套沟通语言,一套在团队中流行的,通用的沟通语言,团队的组员之间可使用**通用语言进行无障碍交流**。
+
+通用语言往往可以直接应用于代码中,它可以直接被写成一个类或者一个类的方法。
+
+```
+//开发一个购物车时,与其使用技术术语:
+Cart::create(): 创建一个购物车。
+Cart::updateStatus():更新购物车状态。
+Cart::remove():移除购物车。
+
+//贴近业务的通用语言:
+Cart::init(): 创建一个购物车。
+Cart::addItemToCart():添加商品。
+Cart::removeItemFromCart():移除商品。
+Cart::empty():清空购物车。
+//使用后者时,开发人员不用解释每一个类方法的意义,领域专家可以直接看懂每一个类方法的目的。开发人员甚至可以和领域专家坐在一起使用代码来打磨业务流程。
+```
+
+##### 限界上下文(Bounded Context)
+
+实现了通用语言自由以后,我们需要使用限界上下文来**规定每一套通用语言的使用边界**。限界上下文是语义和语境的边界,在其内的每一个元素都有自己特定的含义,也就是说**每一个概念在一个限界上下文中都是独一无二**,不可以出现一词多义的情况
+
+> 比如在一个购物车的限界上下文中,我们可以用 User 一词来代表购买商品的客户。
+>
+> 在一个注册系统中,我们可以用 User 一词指的是带有用户名和密码的账号。虽然词汇一样,但是在不同的限界上下文中,它们的含义不同。
+
+我们使用限界上下文和通用语言,对业务进行语言层面的拆分。**限界上下文为领域中的每一个元素赋予清晰的概念**。
+
+##### 子域(Subdomain)
+
+如果说限界上下文是对业务进行语言层面拆分的话,那么子域便是对业务进行商业价值的拆分。每一个商业都有自己的关注点,即便是看起来一样的电商平台,淘宝是**开放平台模式**,京东是**价值链整合模式**,一个明显的区别是,淘宝使用第三方物流而京东自建物流体系。那么作为一个开发人员,为何要关心看起来似乎与自己无关的商业模式呢?恰恰相反,只有当我们了解一个商业的结构时,才能开发出一个主次分明的系统来支撑一个商业的飞速发展。**子域**便是这样一个帮助我们**划分主次**的工具。
+
+有三种类型的子域:
+
+- **核心域(Core Domain)**:这是系统中需要最大投资的领域,它代表着整个商业的核心竞争力。我们需要花大量资源以及资源来打磨核心域,这关乎一个企业的存亡。比如京东的自建物流系统。
+- **支撑域(Supporting Domain)**:此领域并非一个企业的核心业务,但是核心域却离不开它,它可以采用外包定制方案实现。比如认证上下文,权限上下文。
+- **通用域(Generic Domain):**如果已有成熟的解决方案,通用域可以采购现成方案来,如果没有,也可以采用外包,在通用域上的投资应该是最小的。比如对于淘宝而言,物流便是其通用域。
+
+限界上下文和子域的关系众说纷纭,有专家提倡1:1,也有专家提倡1:N。个人比较提倡 1:1。
+
+##### 上下文映射(Context Mapping)
+
+在一个庞大的系统中,限界上下文之间必定存在一定的依赖关系。如何将一个上下文中的概念映射到另一个上下文中?我们使用上下文映射。以下是几种上下文映射的关系类型:
+
+- 合作关系(Partnership)
+- 共享内核(Shared Kernel)
+- 客户方-供应方开发(Customer-Supplier Development)
+- 遵奉者(Conformist)
+- 防腐层(Anticorruption Layer)
+- 开放主机服务(Open Host Service)
+- 发布语言(Published Language)
+- 另谋他路(SeparateWay)
+- 大泥球(Big Ball of Mud)
+
+#### 战术设计
+
+##### 实体(Entity)
+
+首先我们讲到的是,实体。
+
+实体是领域中独立事物的模型,每个实体都拥有一个唯一的标识符,比如 ID, UUID,Username 等等。大多数情况下,实体是可变的,它的状态会随着时间的迁移改变,不过,一个实体不一定必须可变。
+
+实体的最大的特征是它的个体性,唯一性。比如在一个简单的购物车上下文中,订单(Order) 便是一个实体,ID 是它的标识符,它的状态可以在提交(placed),确认(confirmed) 以及已退 (refunded) 之间变化。
+
+##### 值对象(Value Object)
+
+值对象是领域中用来描述,量化或者测量实体的模型。和实体不同,值对象没有唯一的标识符,两个对等的值对象是可以替换的。值对象具有不变性(Immutability),一旦创建以后,一个值对象的属性就定型了,不可更改。
+
+理解值对象的最直接的方法是,想象我们现实生活中的钞票,在日常生活中,甲的十块钱人民币和乙的十块钱人民币是可以对等交换的。在上文的购物车上下文中,金额(Money)便是一个值对象,金额由货币(currency)和数目(amount)
+
+##### 聚合(Aggregate)
+
+聚合是什么?聚合是上下文中对业务领域更精细的划分,每一个聚合保证自己的业务一致性。
+
+那么什么是业务不变性?业务不变性表示一个业务规则,该规则在业务领域中不可违背,必须保证其一致性。比如,在进行订单退款时,退款金额不可以超过已付金额。聚合的组成部分是实体和值对象,有时候也只有实体。为了保护聚合的业务一致性,每个聚合只可以通过某一个实体对其进行操作,该实体被称为聚合根。
+
+##### 领域事件(Domain Event)
+
+领域事件是通过通用语言分析出来的事件,与常见的事务事件不同的是它与业务息息相关,所以它的命名往往夹带业务名词,而不应该与数据库挂钩。比如购物车增添商品,对应的领域事件应该是 `ProductAddedToCart`, 而不是 `CartUpdated`。
+
+#### Tips
+
+DDD 还提供了诸如应用服务(Application Service),领域服务(Domain Service) 等战术设计,DDD 还提出了文章开头就提过的事件溯源,六边形等架构模式,在此我们将不一一介绍。
+
+DDD 的核心是从业务的角度为软件建立模型,其目的是打造更贴近业务的代码,能更直观的从代码理清业务流程。 然而实现 DDD 并非一日之举,它需要不断的实践,不断的打磨。
\ No newline at end of file
diff --git a/_posts/2022-06-14-test-markdown.md b/_posts/2022-06-14-test-markdown.md
new file mode 100644
index 000000000000..4387bc600344
--- /dev/null
+++ b/_posts/2022-06-14-test-markdown.md
@@ -0,0 +1,77 @@
+---
+layout: post
+title: 关于TCP滑动窗口和拥塞控制
+subtitle: 四次握手
+tags: [网络]
+---
+
+# 关于TCP滑动窗口和拥塞控制
+
+- TCP头部记录端口号,IP头部记录IP,以太网头部记录MAC地址
+
+- 一个TCP连接需要四个元组来表示是同一个连接(src_ip, src_port, dst_ip, dst_port)
+
+- 为什么TCP建立连接要三次握手?
+
+- - 通信的双方要互相通知对方自己的初始化的Sequence Number,用来判断之后发来的数据包的顺序。
+ - 通知——ACK 因此需要至少三次握手了
+
+- 建立连接时,SYN超时没收到ACK会重发,为了防止被恶意flood攻击,Linux下给了一个叫tcp_syncookies的参数
+
+- 关闭连接的四次握手
+
+ 
+
+- TIME_WAIT状态是为了等待确保对端也收到了ACK,否则对端还会重发FIN。
+
+- **滑动窗口(swnd,即真正的发送窗口) = min(拥塞窗口,通告窗口)**
+
+- **通告窗口**:即TCP头里的一个字段AdvertisedWindow,是**接收端告诉发送端自己还有多少缓冲区可以接收数据**。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
+
+- - 原则:快的发送方不能淹没慢的接收方
+
+ 
+
+ - 接收端在给发送端回ACK中会汇报自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
+
+ - 而发送方会根据这个窗口来控制发送数据的大小,以保证接收方可以处理。
+
+- **拥塞窗口**(Congestion Window简称cwnd):指某一源端数据流在一个RTT内可以最多发送的数据包数。
+
+- 拥塞控制主要是四个算法:**1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复**
+
+
+
+- **TCP的核心是拥塞控制,**目的是探测网络速度,保证传输顺畅
+
+- 慢启动:
+
+- - 初始化cwnd = 1,表明可以传一个MSS大小的数据(Linux默认2/3/4,google实验10最佳,国内7最佳)
+ - 每当收到一个ACK,cwnd++; 呈线性上升
+ - 因此,每个RTT(Round Trip Time,一个数据包从发出去到回来的时间)时间内发送的数据包数量翻倍,导致了每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
+ - ssthresh(slow start threshold)是上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
+
+- 拥塞避免算法:(当cwnd达到ssthresh时后,一般来说是65535byte)
+
+- - 收到一个ACK时,cwnd = cwnd + 1/cwnd
+ - 当每过一个RTT时,cwnd = cwnd + 1
+
+- 拥塞发生时:
+
+- - \1. 表现为RTO(Retransmission TimeOut)超时,重传数据包(反应比较强烈)
+
+ - - sshthresh = cwnd /2
+ - cwnd 重置为 1,进入慢启动过程
+
+ - \2. 收到第3个duplicate ACK时(从收到第一个重复ACK起,到收到第三个重复ACK止,窗口不做调整,即fast restransmit)
+
+ - - cwnd = cwnd /2
+ - sshthresh = cwnd
+ - 进入快速恢复算法——Fast Recovery
+
+- 快速恢复算法(执行完上述两个步骤之后):
+
+- - cwnd = sshthresh + 3 (MSS)
+ - 重传Duplicated ACKs指定的数据包
+ - 之后每收到一个duplicated Ack,cwnd = cwnd +1 (此时增窗速度很快)
+ - 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法
\ No newline at end of file
diff --git a/_posts/2022-06-15-test-markdown.md b/_posts/2022-06-15-test-markdown.md
new file mode 100644
index 000000000000..cf0a10e93dd5
--- /dev/null
+++ b/_posts/2022-06-15-test-markdown.md
@@ -0,0 +1,162 @@
+---
+layout: post
+title: Fork开源项目并提交PR
+subtitle: 以及关于 提交的pr `go fmt` check 不通过的问题:`Your branch is ahead of 'origin/master' by 1 commit.`
+tags: [开源]
+---
+# Fork开源项目并提交PR
+
+> 以及关于 提交的pr `go fmt` check 不通过的问题:`Your branch is ahead of 'origin/master' by 1 commit.`
+
+## 1 第一次提交pr的操作
+
+### 1.fork 目标仓库
+
+```
+https://github.com/apache/dubbo-go-pixiu.git
+```
+
+fork到自己的仓库
+
+```
+https://github.com/gongna-au/dubbo-go-pixiu.git
+```
+
+### 2.将`forked的`仓库clone到本地
+
+```
+git clone https://github.com/gongna-au/dubbo-go-pixiu.git
+```
+
+> 不是`要`fork的仓库,而是fork到自己账户的仓库
+
+### 3.切一个新的开发分支
+
+```
+git checkout -b my-feature
+```
+
+### 4.在该分支进行修改,添加代码
+
+### 5.将分支push到远程仓库
+
+```
+$ go mod tidy
+```
+
+```
+$ git add .
+```
+
+```
+$ git commit -m"add :new change"
+```
+
+```
+$ git push origin my-feature
+Counting objects: 3, done.
+Delta compression using up to 4 threads.
+Compressing objects: 100% (3/3), done.
+Writing objects: 100% (3/3), 288 bytes | 0 bytes/s, done.
+Total 3 (delta 2), reused 0 (delta 0)
+remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
+To git@github.com:oyjjpp/hey.git
+ f3676ef..d7a9529 my-feature -> my-feature
+
+```
+
+### 6.为fork项目配置远程仓库
+
+当前项目一般只有自己仓库的源,当fork开源仓库的源码时,如果要提交PR,首先需要将上游仓库的源配置到本地版本控制中,这样既可以提交本地仓库代码到上游仓库,同样可以拉取最新上游仓库代码到本地。
+
+> 第一次提交pr的时候需要添加上游仓库,之后提交pr不需要
+
+###### 列出当前项目配置的远程仓库
+
+```
+$ git remote -v
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (fetch)
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (push)
+
+```
+
+###### 指定fork项目的新远程仓库
+
+```
+git remote add upstream https://github.com/apache/dubbo-go-pixiu.git
+```
+
+###### 然后重新列出配置的远程仓库
+
+```
+$ git remote -v
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (fetch)
+origin https://github.com/gongna-au/dubbo-go-pixiu.git (push)
+upstream https://github.com/apache/dubbo-go-pixiu.git (fetch)
+upstream https://github.com/apache/dubbo-go-pixiu.git (push)
+```
+
+### 7.从上游仓库获取最新的代码
+
+确定好修改好的代码是想要合并到上游仓库的哪个分支(一般开源仓库都是有很多的分支, 但需要合并的往往只是特定的一个分支)
+
+这里选择我要合并的上游分支develop
+
+```
+$ git fetch upstream develop
+remote: Enumerating objects: 4, done.
+remote: Counting objects: 100% (4/4), done.
+remote: Total 5 (delta 4), reused 4 (delta 4), pack-reused 1
+Unpacking objects: 100% (5/5), done.
+From https://github.com/rakyll/hey
+ * [new branch] my-feature -> upstream/develop
+ * [new tag] v0.1.4 -> v0.1.4
+
+```
+
+### 8.将开发的分支和上游仓库代码merge
+
+```
+git merge upstream/develop
+```
+
+### 9.提交PR
+
+## 2 第二次提交pr
+
+```
+$ go mod tidy
+```
+
+```
+$ git add .
+```
+
+```
+$ git commit -m"add :new change"
+```
+
+```
+$ git push origin my-feature
+Counting objects: 3, done.
+Delta compression using up to 4 threads.
+Compressing objects: 100% (3/3), done.
+Writing objects: 100% (3/3), 288 bytes | 0 bytes/s, done.
+Total 3 (delta 2), reused 0 (delta 0)
+remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
+To git@github.com:oyjjpp/hey.git
+ f3676ef..d7a9529 my-feature -> my-feature
+```
+
+```
+$ git fetch upstream develop
+```
+
+```
+git merge upstream/develop
+```
+
+```
+提交pr
+```
+
diff --git a/_posts/2022-07-08-test-markdown.md b/_posts/2022-07-08-test-markdown.md
new file mode 100644
index 000000000000..75a5a62adfa2
--- /dev/null
+++ b/_posts/2022-07-08-test-markdown.md
@@ -0,0 +1,692 @@
+---
+layout: post=
+title: Service Mesh, What & Why ?
+subtitle: 正在构建基于服务的架构,无论是micro services微服务还是纳米服务nano services 的service meshes 需要了解服务到服务通信的基本知识。
+tags: [架构]
+
+---
+# Service Mesh: What & Why ?
+
+> 正在构建基于服务的架构,无论是`micro services`微服务还是纳米服务`nano services` 的**service meshes **需要了解服务到服务通信的基本知识。
+
+service a调用 service b ,如果对service b 的调用失败,我们通常会做的是 service a Retry
+
+retry 称为重试逻辑,开发人员通常在他们的代码库中有重试逻辑来处理这些类型的失败场景,这个逻辑可能在不同类型的
+服务和不同的编程语言。
+
+在放弃之前重试了多少次,太多的重试逻辑在服务 a 和 b 之间造成的弊大于利怎么办?并且服务 b 必须具有关于
+如何处理身份验证的逻辑,所以代码库现在会增长并变得更加复杂 。我们可能还希望微服务之间的相互 tls 或 ssl 连接。我们可能不希望服务通过端口 80 进行通信,而是通过端口 443 安全地进行通信。这意味着:
+
+- 必须为每个服务颁发证书
+
+- 必须为每个服务轮换和维护。避免成为大规模维护的噩梦。
+
+
+另一个是我们可能想知道:
+
+- **服务 a 每秒发送给service b 的请求数是多少**?
+- 服务 b 每秒接收的请求数是多少?
+
+我们也可能想知道关于:
+
+- service b响应的 latency 延迟和 time 的metrics
+
+有很多可用的指标库,但这需要开发工作,这使得代码库变得越来越复杂。如果服务 a 调用服务 b,但服务 b
+向服务c和d发出请求,该怎么办? 有时我们可能希望将请求跟踪到每个服务,以确定延迟可能在哪里.
+
+比如:服务 a 到 b 可能需要 5 秒、服务 b 到 c 只需要半秒,跟踪这些 Web 请求将帮助我们找到Web 系统中的慢计时区域,这实现起来非常复杂,并且每个都需要大量的代码投资。并且服务为了跟踪每个请求和延迟有时我们可能还想进行流量拆分,只将 10% 的流量发送到服务 d 。现在在传统的 Web 服务器中,我们有防火墙,允许我们控制哪些服务现在可以相互通信。但是大规模分布式系统和微服务 这几乎是不可能去维护的。我们添加的服务越多,我们就越需要不断调整复杂的防火墙规则,我们可能需要不断更新和设置允许哪些服务通信和哪些服务不能通信的策略。
+
+ 所以如果给服务 a和服务 b 并且添加重试逻辑在两者之间、添加身份验证在两者之间、添加相互 tls在两者之间、关于每秒请求数和延迟的指标在两者之间。根据需求进行扩展我们添加服务 e f g h i。如您所见,这会增加大量的开发工作和操作上的痛苦。
+
+很好的解决方案就是 service mesh technology
+
+## 1. service mesh technology
+
+> 在软件架构中service mesh 是一个专用的基础设施层,用于促进服务到服务的通信。通常在微服务之间服务service mesh旨在使网络更智能。基本上采用我所说的所有逻辑和功能,将它从代码库中移出并移入网络。这样可以使您的应用程序代码库更小更简单,这样您就可以获得所有这些功能。并保持您的代码库基本不变,
+
+所以让我们再看看service a 、service b
+
+service mesh的工作原理是它谨慎地将 proxy作为 sidecar 注入到每个服务。proxy劫持来自服务pod的请求。这意味着 web 数据包将首先访问服务service a 中的proxy,在实际访问服务service b 之前到service b的proxy
+而不是为service a 和 service b 添加logic 。logic 存在于 sidecar proxy我们可以在declarative (声明性)config 配置中挑选我们想要的功能:
+
+- 我们希望代理上的 tls 将管理自己的证书并自动rotate轮换它们
+- 我们希望代理上的自动重试将在失败的情况下重试请求
+- 假设我们想要服务 a 和b 之间进行身份验证,代理将处理服务之间的身份验证,而无需代码。
+- 我们可以打开指标并自动查看集群中每个 pod 的metrics、automatically see requests、per second and latency而无需向我们的服务添加代码。
+- 无论什么编程语言他们都将获得相同的指标所有这些都在每个微服务的声明性配置文件中定义。
+
+
+这使得轻松加入和 扩展微服务,尤其是当您的集群中有 100 多个服务时,因此要开始service mesh ,我们将需要一个非常好的用例来说明。
+
+
+
+我有 一个 kubernetes 文件夹,有一个带有自述文件的service mesh文件夹
+along in the service 我们将看一下 linkid 和 istio 。 现在的服务度量涵盖了我之前提到的各种功能,但是service mesh 的好处在于它不是在cluster 集群中打开的东西。而是我建议
+
+- installing a service mesh 安装服务网格
+
+- cherry picking the features 挑选您需要的功能
+
+- turn them on for services 为您需要的服务打开它们
+
+- 然后应用该方法直到这些概念在您的团队中成熟,或者一旦您从中获得价值,
+ apply that approach until these concepts mature within your team and then once you gain value from it
+
+- 您就可以决定将这些功能扩展到其他服务
+
+ it you can decide to expand these features to other services or more features as you need
+
+
+
+kubernetes service mesh folder下面有三个applications folder 其中包含三个用于此用例的微服务micro services 。这些服务组成了一个视频目录,基本上是一个网页将显示播放列表和视频列表。
+
+1. 我们从一个简单的 web ui 开始,它被称为 videos web 这是一个 html 应用程序,它列出了一堆包含视频的播放列表。
+2. playlists api来获取播放列表
+3. videos web 调用播放列表 api
+4. 完整的架构 :videos web加载到浏览器——>向playlist api 发出单个 Web 请求——>api 将向playlists-db数据库发出请求以加载——>playlist api 遍历每个播放列表并获取——>对videos- api 进行网络调用——> 从videos db 视频数据库获取视频内容所需的所有视频 ID
+5. playlist api 和videos api在它们之间发出大量请求
+6. 在 docker 容器中构建所有这些应用程序和启动它们。
+7. 所以现在我们的应用程序在本地 docker 容器中运行,以查看service meshes 我们要做的是部署所有 这些东西到 kubernetes
+8. 使用名为 kind 的产品,它可以帮助我在 docker 容器中本地运行 kubernetes 集群。
+9. 在我的机器上的容器内启动一个 kubernetes 集群以便可以在其中部署视频。
+10. 三个微服务,部署它们中的每一个。
+
+```
+//servicemesh/applications/playlists-api/playlist-api app.go
+package main
+
+import (
+ "net/http"
+ "github.com/julienschmidt/httprouter"
+ log "github.com/sirupsen/logrus"
+ "encoding/json"
+ "fmt"
+ "os"
+ "bytes"
+ "io/ioutil"
+ "context"
+ "github.com/go-redis/redis/v8"
+)
+
+var environment = os.Getenv("ENVIRONMENT")
+var redis_host = os.Getenv("REDIS_HOST")
+var redis_port = os.Getenv("REDIS_PORT")
+var ctx = context.Background()
+var rdb *redis.Client
+
+func main() {
+
+ router := httprouter.New()
+
+ router.GET("/", func(w http.ResponseWriter, r *http.Request, p httprouter.Params){
+ cors(w)
+ playlistsJson := getPlaylists()
+
+ playlists := []playlist{}
+ err := json.Unmarshal([]byte(playlistsJson), &playlists)
+ if err != nil {
+ panic(err)
+ }
+
+ //get videos for each playlist from videos api
+ for pi := range playlists {
+
+ vs := []videos{}
+ for vi := range playlists[pi].Videos {
+
+ v := videos{}
+ videoResp, err := http.Get("http://videos-api:10010/" + playlists[pi].Videos[vi].Id)
+
+ if err != nil {
+ fmt.Println(err)
+ break
+ }
+
+ defer videoResp.Body.Close()
+ video, err := ioutil.ReadAll(videoResp.Body)
+
+ if err != nil {
+ panic(err)
+ }
+
+
+ err = json.Unmarshal(video, &v)
+
+ if err != nil {
+ panic(err)
+ }
+
+ vs = append(vs, v)
+
+ }
+
+ playlists[pi].Videos = vs
+ }
+
+ playlistsBytes, err := json.Marshal(playlists)
+ if err != nil {
+ panic(err)
+ }
+
+ reader := bytes.NewReader(playlistsBytes)
+ if b, err := ioutil.ReadAll(reader); err == nil {
+ fmt.Fprintf(w, "%s", string(b))
+ }
+
+ })
+
+ r := redis.NewClient(&redis.Options{
+ Addr: redis_host + ":" + redis_port,
+ DB: 0,
+ })
+ rdb = r
+
+ fmt.Println("Running...")
+ log.Fatal(http.ListenAndServe(":10010", router))
+}
+
+func getPlaylists()(response string){
+ playlistData, err := rdb.Get(ctx, "playlists").Result()
+
+ if err != nil {
+ fmt.Println(err)
+ fmt.Println("error occured retrieving playlists from Redis")
+ return "[]"
+ }
+
+ return playlistData
+}
+
+type playlist struct {
+ Id string `json:"id"`
+ Name string `json:"name"`
+ Videos []videos `json:"videos"`
+}
+
+type videos struct {
+ Id string `json:"id"`
+ Title string `json:"title"`
+ Description string `json:"description"`
+ Imageurl string `json:"imageurl"`
+ Url string `json:"url"`
+
+}
+
+type stop struct {
+ error
+}
+
+func cors(writer http.ResponseWriter) () {
+ if(environment == "DEBUG"){
+ writer.Header().Set("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE")
+ writer.Header().Set("Access-Control-Allow-Headers", "Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization, accept, origin, Cache-Control, X-Requested-With, X-MY-API-Version")
+ writer.Header().Set("Access-Control-Allow-Credentials", "true")
+ writer.Header().Set("Access-Control-Allow-Origin", "*")
+ }
+}
+```
+
+```
+// servicemesh/applications/playlists-apiplaylist-api/deploy.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: playlists-api
+ labels:
+ app: playlists-api
+spec:
+ selector:
+ matchLabels:
+ app: playlists-api
+ replicas: 1
+ strategy:
+ type: RollingUpdate
+ rollingUpdate:
+ maxSurge: 1
+ maxUnavailable: 0
+ template:
+ metadata:
+ labels:
+ app: playlists-api
+ spec:
+ containers:
+ - name: playlists-api
+ image: aimvector/service-mesh:playlists-api-1.0.0
+ imagePullPolicy : Always
+ ports:
+ - containerPort: 10010
+ env:
+ - name: "ENVIRONMENT"
+ value: "DEBUG"
+ - name: "REDIS_HOST"
+ value: "playlists-db"
+ - name: "REDIS_PORT"
+ value: "6379"
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: playlists-api
+ labels:
+ app: playlists-api
+spec:
+ type: ClusterIP
+ selector:
+ app: playlists-api
+ ports:
+ - protocol: TCP
+ name: http
+ port: 80
+ targetPort: 10010
+---
+apiVersion: networking.k8s.io/v1beta1
+kind: Ingress
+metadata:
+ annotations:
+ kubernetes.io/ingress.class: "nginx"
+ nginx.ingress.kubernetes.io/ssl-redirect: "false"
+ nginx.ingress.kubernetes.io/rewrite-target: /$2
+ name: playlists-api
+spec:
+ rules:
+ - host: servicemesh.demo
+ http:
+ paths:
+ - path: /api/playlists(/|$)(.*)
+ backend:
+ serviceName: playlists-api
+ servicePort: 80
+
+
+```
+
+```
+//servicemesh/applications/videos-api/app.go
+package main
+
+import (
+ "net/http"
+ "github.com/julienschmidt/httprouter"
+ log "github.com/sirupsen/logrus"
+ "github.com/go-redis/redis/v8"
+ "fmt"
+ "context"
+ "os"
+ "math/rand"
+)
+
+var environment = os.Getenv("ENVIRONMENT")
+var redis_host = os.Getenv("REDIS_HOST")
+var redis_port = os.Getenv("REDIS_PORT")
+var flaky = os.Getenv("FLAKY")
+
+var ctx = context.Background()
+var rdb *redis.Client
+
+func main() {
+
+ router := httprouter.New()
+
+ router.GET("/:id", func(w http.ResponseWriter, r *http.Request, p httprouter.Params){
+
+ if flaky == "true"{
+ if rand.Intn(90) < 30 {
+ panic("flaky error occurred ")
+ }
+ }
+
+ video := video(w,r,p)
+
+ cors(w)
+ fmt.Fprintf(w, "%s", video)
+ })
+
+ r := redis.NewClient(&redis.Options{
+ Addr: redis_host + ":" + redis_port,
+ DB: 0,
+ })
+ rdb = r
+
+ fmt.Println("Running...")
+ log.Fatal(http.ListenAndServe(":10010", router))
+}
+
+func video(writer http.ResponseWriter, request *http.Request, p httprouter.Params)(response string){
+
+ id := p.ByName("id")
+ fmt.Print(id)
+
+ videoData, err := rdb.Get(ctx, id).Result()
+ if err == redis.Nil {
+ return "{}"
+ } else if err != nil {
+ panic(err)
+} else {
+ return videoData
+}
+}
+
+type stop struct {
+ error
+}
+
+func cors(writer http.ResponseWriter) () {
+ if(environment == "DEBUG"){
+ writer.Header().Set("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE")
+ writer.Header().Set("Access-Control-Allow-Headers", "Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization, accept, origin, Cache-Control, X-Requested-With, X-MY-API-Version")
+ writer.Header().Set("Access-Control-Allow-Credentials", "true")
+ writer.Header().Set("Access-Control-Allow-Origin", "*")
+ }
+}
+
+type videos struct {
+ Id string `json:"id"`
+ Title string `json:"title"`
+ Description string `json:"description"`
+ Imageurl string `json:"imageurl"`
+ Url string `json:"url"`
+
+}
+```
+
+```
+//servicemesh/applications/videos-api/deploy.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: videos-api
+ labels:
+ app: videos-api
+spec:
+ selector:
+ matchLabels:
+ app: videos-api
+ replicas: 1
+ strategy:
+ type: RollingUpdate
+ rollingUpdate:
+ maxSurge: 1
+ maxUnavailable: 0
+ template:
+ metadata:
+ labels:
+ app: videos-api
+ spec:
+ containers:
+ - name: videos-api
+ image: aimvector/service-mesh:videos-api-1.0.0
+ imagePullPolicy : Always
+ ports:
+ - containerPort: 10010
+ env:
+ - name: "ENVIRONMENT"
+ value: "DEBUG"
+ - name: "REDIS_HOST"
+ value: "videos-db"
+ - name: "REDIS_PORT"
+ value: "6379"
+ - name: "FLAKY"
+ value: "false"
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: videos-api
+ labels:
+ app: videos-api
+spec:
+ type: ClusterIP
+ selector:
+ app: videos-api
+ ports:
+ - protocol: TCP
+ name: http
+ port: 10010
+ targetPort: 10010
+---
+
+
+```
+
+
+
+## 2.Introduction to Linkerd for beginners | a Service Mesh
+
+Linkerd是最具侵入性的Service Mesh之一,这意味着您可以轻松安装它,并轻松删除它,轻松选择加入和退出某些功能并将其添加到某些微服务中。所以我非常兴奋,我们有有很多话要说,所以不用多说,让我们开始
+
+#### Full application architecture
+
+```
++------------+ +---------------+ +--------------+
+| videos-web +---->+ playlists-api +--->+ playlists-db |
+| | | | | |
++------------+ +-----+---------+ +--------------+
+ |
+ v
+ +-----+------+ +-----------+
+ | videos-api +------>+ videos-db |
+ | | | |
+ +------------+ +-----------+
+```
+
+#### A simple Web UI: videos-web
+
+这是一个 HTML 应用程序,列出了一堆包含视频的播放列表
+
+```
++------------+
+| videos-web |
+| |
++------------+
+```
+
+#### A simple API: playlists-api
+
+要让videos-web 获取任何内容,它需要调用playlists-api
+
+```
++------------+ +---------------+
+| videos-web +---->+ playlists-api |
+| | | |
++------------+ +---------------+
+```
+
+播放列表由`title,description`等数据和视频列表组成。 播放列表存储在数据库中。 playlists-api 将其数据存储在数据库中
+
+```
++------------+ +---------------+ +--------------+
+| videos-web +---->+ playlists-api +--->+ playlists-db |
+| | | | | |
++------------+ +---------------+ +--------------+
+```
+
+每个playlist item 仅包含一个视频 ID 列表。 播放列表没有每个视频的完整元数据。
+
+Example `playlist`:
+
+```
+{
+ "id" : "playlist-01",
+ "title": "Cool playlist",
+ "videos" : [ "video-1", "video-x" , "video-b"]
+}
+```
+
+Take not above videos: [] 是视频 id 的列表 视频有自己的标题和描述以及其他元数据。 为了得到这些数据,我们需要一个videos-api 这个videos-api也有自己的数据库
+
+```
++------------+ +-----------+
+| videos-api +------>+ videos-db |
+| | | |
++------------+ +-----------+
+```
+
+## 3.Traffic flow
+
+对 `playlists-api` 的单个 `GET` 请求将通过单个 DB 调用从其数据库中获取所有播放列表对于每个播放列表和每个列表中的每个视频,将单独`GET`调用`videos-api`将从其数据库中检索视频元数据。这将导致许多网络扇出`playlists-api`和`videos-api`许多对其数据库的调用。
+
+
+
+## 4.Run the apps: Docker
+
+```
+//终z端在`在ocker-compose.yaml`下,运行:
+docker-compose build
+
+docker-compose up
+
+```
+
+您可以在 http://localhost 上访问该应用程序
+
+## 5.Run the apps: Kubernetes
+
+```
+//Creae a cluster with kind
+kind create cluster --name servicemesh --image kindest/node:v1.18.4
+```
+
+### Deploy videos-web
+
+```
+cd ./kubernetes/servicemesh/
+
+kubectl apply -f applications/videos-web/deploy.yaml
+kubectl port-forward svc/videos-web 80:80
+```
+
+您应该在 http://localhost/ 看到空白页 它是空白的,因为它需要 playlists-api 来获取数据
+
+### Deploy playlists-api and database
+
+```
+cd ./kubernetes/servicemesh/
+
+kubectl apply -f applications/playlists-api/deploy.yaml
+kubectl apply -f applications/playlists-db/
+kubectl port-forward svc/playlists-api 81:80
+//转发
+```
+
+您应该在 http://localhost/ 看到空的播放列表页面 播放列表是空的,因为它需要 video-api 来获取视频数据
+
+### Deploy videos-api and database
+
+```
+cd ./kubernetes/servicemesh/
+
+kubectl apply -f applications/videos-api/deploy.yaml
+kubectl apply -f applications/videos-db/
+```
+
+在 http://localhost/ 刷新页面 您现在应该在浏览器中看到完整的架构
+
+```
+servicemesh.demo/home --> videos-web
+servicemesh.demo/api/playlists --> playlists-api
+
+
+ servicemesh.demo/home/ +--------------+
+ +------------------------------> | videos-web |
+ | | |
+servicemesh.demo/home/ +------+------------+ +--------------+
+ +------------------>+ingress-nginx |
+ |Ingress controller |
+ +------+------------+ +---------------+ +--------------+
+ | | playlists-api +--->+ playlists-db |
+ +------------------------------> | | | |
+ servicemesh.demo/api/playlists +-----+---------+ +--------------+
+ |
+ v
+ +-----+------+ +-----------+
+ | videos-api +------>+ videos-db |
+ | | | |
+ +------------+ +-----------+
+
+```
+
+
+
+# Introduction to Linkerd
+
+## 1.We need a Kubernetes cluster
+
+我们需要一个 Kubernetes 集群,让我们使用kind创建一个 Kubernetes 集群来玩
+
+```
+kind create cluster --name linkerd --image kindest/node:v1.19.1
+```
+
+## 2.Deploy our microservices (Video catalog)
+
+部署我们的微服务(视频目录)
+
+```
+# ingress controller
+kubectl create ns ingress-nginx
+kubectl apply -f kubernetes/servicemesh/applications/ingress-nginx/
+
+# applications
+kubectl apply -f kubernetes/servicemesh/applications/playlists-api/
+kubectl apply -f kubernetes/servicemesh/applications/playlists-db/
+kubectl apply -f kubernetes/servicemesh/applications/videos-web/
+kubectl apply -f kubernetes/servicemesh/applications/videos-api/
+kubectl apply -f kubernetes/servicemesh/applications/videos-db/
+```
+
+
+
+## 3.Make sure our applications are running
+
+```
+kubectl get pods
+NAME READY STATUS RESTARTS AGE
+playlists-api-d7f64c9c6-rfhdg 1/1 Running 0 2m19s
+playlists-db-67d75dc7f4-p8wk5 1/1 Running 0 2m19s
+videos-api-7769dfc56b-fsqsr 1/1 Running 0 2m18s
+videos-db-74576d7c7d-5ljdh 1/1 Running 0 2m18s
+videos-web-598c76f8f-chhgm 1/1 Running 0 100s
+
+```
+
+确保我们的应用程序正在运行
+
+## 4.Make sure our ingress controller is running
+
+```
+kubectl -n ingress-nginx get pods
+NAME READY STATUS RESTARTS AGE
+nginx-ingress-controller-6fbb446cff-8fwxz 1/1 Running 0 2m38s
+nginx-ingress-controller-6fbb446cff-zbw7x 1/1 Running 0 2m38s
+
+```
+
+确保我们的入口控制器正在运行。
+
+我们需要一个伪造的 DNS 名称让我们通过在 hosts ( ) 文件`servicemesh.demo`
+中添加以下条目来伪造一个:`C:\Windows\System32\drivers\etc\hosts`
+
+```
+127.0.0.1 servicemesh.demo
+```
+
+## Let's access our applications via Ingress
+
+```
+kubectl -n ingress-nginx port-forward deploy/nginx-ingress-controller 80
+```
+
+让我们通过 Ingress 访问我们的应用程序
+
+## Access our application in the browser
+
+在浏览器中访问我们的应用程序,我们应该能够访问我们的网站`http://servicemesh.demo/home/`
+
+
+
+
+
+
+
+
+
diff --git a/_posts/2022-07-09test-markdown.md b/_posts/2022-07-09test-markdown.md
new file mode 100644
index 000000000000..294f02258249
--- /dev/null
+++ b/_posts/2022-07-09test-markdown.md
@@ -0,0 +1,50 @@
+---
+layout: post
+title: 什么是 Sidecar 模式,为什么它在微服务中被大量使用?
+subtitle: Sidecar 模式是一种架构模式,其中位于同一个主机的两个或者多个进程可以相互通信。他们是环回本地主机,本质是 启动进程间通讯。
+tags: [架构]
+---
+
+# 什么是 Sidecar 模式,为什么它在微服务中被大量使用?
+
+## 1.什么是 Sidecar 模式
+
+Sidecar 模式是一种架构模式,其中位于同一个主机的两个或者多个进程可以相互通信。他们是环回本地主机,本质是 **启动进程间通讯**。
+
+#### How We Do Traditionally ?
+
+假设现有一个传统的`golang`应用,我们在其中导入一些重要的 `golang`包,然后这个程序做为一个。`exe` 运行在本地主机上 `localhost` 在这种情况下我有一个很不错的 `golang`库,我花了很多时间在这个库上,它是一个高级的库,可以进行日志记录和对话。因为我是用 `golang`写的库,所以我的应用程序也是 `golang`写的。我需要做的就是,使用这个库,调用函数。
+
+```
+-----------------------------------------
+| |
+| ------------------ |
+| | |------- | |
+| | |Library | |
+| | |------- | |
+| |app | |
+| ----------------- |
+| |
+| |
+----------------------------------------
+
+```
+
+如果是Sidecar pattern ,那么我需要做的就是拆封我的日记记录库
+
+```
+log(localhost:8080)
+```
+
+```
+golang.log(localhost:8080)
+```
+
+也就是说,我们所做的,不是引用或者导入而是向端口的本地主机发出请求。任务本质上没有离开哪个那个主机。它会通过网络堆栈。当我们开始运行程序时,就会返回调用我们写的库。
+
+- **让两个进程生活在同一台机器上,然后他们直接通信**
+- 这个时候,我们的库可以被其他任何语言使用。
+- **公开给其他任何语言use**
+
+
+
diff --git a/_posts/2022-07-11-test-markdown.md b/_posts/2022-07-11-test-markdown.md
new file mode 100644
index 000000000000..e65c448737a9
--- /dev/null
+++ b/_posts/2022-07-11-test-markdown.md
@@ -0,0 +1,118 @@
+---
+layout: post
+title: 什么是 Distributed Tracing(分布式跟踪)?
+subtitle: 在微服务的世界中,大多数问题是由于网络问题和不同微服务之间的关系而发生的。分布式架构(相对于单体架构)使得找到问题的根源变得更加困难。要解决这些问题,我们需要查看哪个服务向另一个服务或组件(数据库、队列等)发送了哪些参数。分布式跟踪通过使我们能够从系统的不同部分收集数据来帮助我们实现这一目标,从而使我们的系统能够实现这种所需的可观察性。
+tags: [分布式]
+---
+# 什么是 Distributed Tracing(分布式跟踪)?
+
+> 在微服务的世界中,大多数问题是由于网络问题和不同微服务之间的关系而发生的。分布式架构(相对于单体架构)使得找到问题的根源变得更加困难。要解决这些问题,我们需要查看哪个服务向另一个服务或组件(数据库、队列等)发送了哪些参数。分布式跟踪通过使我们能够从系统的不同部分收集数据来帮助我们实现这一目标,从而使我们的系统能够实现这种所需的可观察性。
+
+- **分布式跟踪使我们从系统的不同部分收集数据从而找到问题的根源。**
+- **此外,trace 是一种可视化工具,可以让我们将系统可视化以更好地了解服务之间的关系,从而更容易调查和查明问题**
+
+## 1.**什么是 Jaeger 追踪?**
+
+Jaeger 是 Uber 在 2015 年创建的开源分布式跟踪平台。它由检测 SDK、用于数据收集和存储的后端、用于可视化数据的 UI 以及用于聚合跟踪分析的 Spark/Flink 框架组成。
+
+Jaeger 数据模型与 OpenTracing 兼容,OpenTracing 是一种规范,用于定义收集的跟踪数据的外观,以及不同语言的实现库(稍后将详细介绍 OpenTracing 和 OpenTelemetry)。
+
+与大多数其他分布式跟踪系统一样,Jaeger 使用spans and traces,如 OpenTracing 规范中定义的那样。
+
+
+
+span 代表应用程序中的一个工作单元(HTTP 请求、对 DB 的调用等),是 Jaeger 最基本的工作单元。Span必须具有操作名称、开始时间和持续时间。
+
+Traces 是以父/子关系连接的跨度的集合/列表(也可以被认为是Span的有向无环图)。Traces 指定如何通过我们的服务和其他组件传播请求。
+
+## 2.Jaeger 追踪架构
+
+
+
+它由几个部分组成,我将在下面解释所有这些部分:
+
+- **Instrumentation SDK:**集成到应用程序和框架中以捕获跟踪数据的库。从历史上看,Jaeger 项目支持使用各种编程语言编写的自己的客户端库。它们现在被弃用,取而代之的是 OpenTelemetry(同样,稍后会详细介绍)。
+
+- **Jaeger 代理:** Jaeger 代理是一个网络守护程序,用于侦听通过 UDP 从 Jaeger 客户端接收到的跨度。它收集成批的它们,然后将它们一起发送给收集器。如果 SDK 被配置为将 span 直接发送到收集器,则不需要代理。
+- **Jaeger 收集器:** Jaeger 收集器负责从 Jaeger 代理接收跟踪,执行验证和转换,并将它们保存到选定的存储后端。
+- **存储后端:** Jaeger 支持各种存储后端来存储跨度。支持的存储后端有 In-Memory、Cassandra、Elasticsearch 和 Badger(用于单实例收集器部署)。
+- **Jaeger Query:**这是一项服务,负责从 Jaeger 存储后端检索跟踪信息,并使其可供 Jaeger UI 访问。
+- **Jaeger UI:**一个 React 应用程序,可让您可视化跟踪并分析它们。对于调试系统问题很有用。
+- **Ingester:**只有当我们使用 Kafka 作为收集器和存储后端之间的缓冲区时,ingester 才有意义。它负责从 Kafka 接收数据并将其摄取到存储后端。更多信息可以在[官方 Jaeger Tracing 文档](https://www.jaegertracing.io/docs/1.30/architecture/#ingester)中找到。
+
+# 使用 Docker 在本地运行 Jaeger
+
+Jaeger 附带一个即用**型一体化**Docker 映像,其中包含 Jaeger 运行所需的所有组件。
+
+在本地机器上启动并运行它非常简单:
+
+```
+docker run -d --name jaeger \
+ -e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
+ -p 5775:5775/udp \
+ -p 6831:6831/udp \
+ -p 6832:6832/udp \
+ -p 5778:5778 \
+ -p 16686: 16686 \
+ -p 14250:14250 \
+ -p 14268:14268 \
+ -p 14269:14269 \
+ -p 9411:9411 \
+ jaegertracing/all-in-one:1.30
+```
+
+然后可以简单地在`http://localhost:16686`上打开 `jaeger UI` 。
+
+# Jaeger 跟踪和 OpenTelemetry
+
+我之前确实提到过 Jaeger 的数据模型与 OpenTracing 规范兼容。可能已经知道 OpenTracing 和 OpenCensus 已合并形成 OpenTelemetry。
+
+### SDK 中的采样策略
+
+(弃用的)Jaeger SDK 有 4 种采样模式:
+
+- Remote:默认值,用于告诉 Jaeger SDK 采样策略由 Jaeger 后端控制。
+- 常数:要么取所有痕迹,要么不取。中间什么都没有。全部为 1,无为 0
+- 速率限制:选择每秒采样的跟踪数。
+- 概率:选择将被采样的轨迹的百分比,例如 - 选择 0.1 以使每 10 条轨迹中有 1 条被采样。
+
+### 远程采样
+
+如果我们选择启用远程采样,Jaeger 收集器将负责确定每个服务中的 SDK 应该使用哪种采样策略。操作员有两种配置收集器的方法:使用采样策略配置文件,或使用自适应采样。
+
+配置文件 — 为收集器提供一个文件路径,该文件包含每个服务和操作前采样配置。
+
+自适应采样——让 Jaeger 了解每个端点接收的流量并计算出该端点最合适的速率。请注意,在撰写本文时,只有 Memory 和 Cassandra 后端支持这一点。
+
+可以在此处找到有关 Jaeger 采样的更多信息:[https ://www.jaegertracing.io/docs/latest/sampling/](https://www.jaegertracing.io/docs/1.30/sampling/)
+
+## Jaeger 追踪术语表
+
+**Span**——我们系统中发生的工作单元(动作/操作)的表示;跨越时间的 HTTP 请求或数据库操作(从 X 开始,持续时间为 Y 毫秒)。通常,它将是另一个跨度的父级和/或子级。
+
+**Trace** — 表示请求进程的树/跨度列表,因为它由我们系统中的不同服务和组件处理。例如,向 user-service 发送 API 调用会导致对 users-db 的 DB 查询。它们是分布式服务的“调用堆栈”。
+
+**Observability可观察**性——衡量我们根据外部输出了解系统内部状态的程度。当您拥有日志、指标和跟踪时,您就拥有了“可观察性的 3 个支柱”。
+
+**OpenTelemetry** — OpenTelemetry 是 CNCF(云原生计算功能)的一个开源项目,它提供了一系列工具、API 和 SDK。OpenTelemetry 支持使用单一规范自动收集和生成跟踪、日志和指标。
+
+**OpenTracing** — 一个用于分布式跟踪的开源项目。它已被弃用并“合并”到 OpenTelemetry 中。OpenTelemetry 为 OpenTracing 提供向后兼容性。
+
+
+
+## OpenTelemetry 和 Jaeger
+
+与其他一些跟踪后端不同,Jaeger 项目从未打算解决代码检测问题。通过发布与 OpenTracing 兼容的跟踪器库,我们能够利用现有兼容 OpenTracing 的仪器的丰富生态系统,并将我们的精力集中在构建跟踪后端、可视化工具和数据挖掘技术上。
+
+## 上下文传播作为底层
+
+
+
+
+
+## OpenCensus 代理/收集器呢?
+
+即使对于 OpenCensus 库,“包含电池”的方法也并不总是有效,因为它们仍然需要配置特定的导出器插件才能将数据发送到具体的跟踪后端,如 Jaeger 或 Zipkin。为了解决这个问题,OpenCensus 项目开始开发两个称为**agent**和**collector**的后端组件,它们扮演着与 Jaeger 的 agent 和 collector 几乎相同的角色:
+
+- **代理**是一个边车/主机代理,它以标准化格式从客户端库接收遥测数据并将其转发给收集器;
+- **收集器**将数据转换为特定跟踪后端可以理解的格式并将其发送到那里。OpenCensus Collector 还能够执行基于尾部的抽样。
\ No newline at end of file
diff --git a/_posts/2022-07-12-test-markdown.md b/_posts/2022-07-12-test-markdown.md
new file mode 100644
index 000000000000..5904841d2d39
--- /dev/null
+++ b/_posts/2022-07-12-test-markdown.md
@@ -0,0 +1,397 @@
+---
+layout: post
+title: 什么是分布式跟踪和 OpenTracing?
+subtitle: 分布式跟踪是一种建立在微服务架构上的监控和分析系统的技术
+tags: [分布式]
+---
+# 什么是分布式跟踪和 OpenTracing?
+
+## 1.What is Distributed Tracing and OpenTracing?
+
+> 分布式跟踪是一种建立在微服务架构上的监控和分析系统的技术,由 X-Trace、[Google 的 Dapper](http://research.google.com/pubs/pub36356.html)和[Twitter 的 Zipkin](http://zipkin.io/)等系统推广。其基础是*分布式上下文传播* 的概念,它涉及将某些元数据与进入系统的每个请求相关联,并在请求执行转到其他微服务时跨线程和进程边界传播该元数据。如果我们为每个入站请求分配一个唯一 ID 并将其作为分布式上下文的一部分携带,那么我们可以将来自多个线程和多个进程的各种分析数据拼接成一个“跟踪”,该“跟踪”代表我们系统对请求的执行.
+
+- **微服务架构上的监控和分析系统技术**
+- **分布式上下文传播**
+- **数据与进入系统的每个请求相关联**
+- **请求执行转到其他微服务时——跨线程和进程边界传播该元数据**
+- 请求分配一个唯一 ID,这个ID作为分布式上下文的一部分携带。
+- **来自多个线程和多个进程的各种数据拼凑成一个跟踪。**
+- 这个 **跟踪** 完全的向我们展示了系统在执行请求时经历了什么。
+
+## 2. OK ,What we need to do ?
+
+> Distributed tracing requires instrumentation of the application code (or the frameworks it uses) with profiling hooks and a context propagation mechanism. in October 2015 a new community was formed that gave birth to the [OpenTracing API](http://opentracing.io/), an open, vendor-neutral, language-agnostic standard for distributed tracing You can read more about it in [Ben Sigelman](https://medium.com/u/bbb65ce0911b?source=post_page-----7cc1282a100a--------------------------------)’s article about [the motivations and design principles behind OpenTracing](https://medium.com/opentracing/towards-turnkey-distributed-tracing-5f4297d1736#.zbnged9wk).
+
+分布式跟踪需要使用分析挂钩 `profiling hooks` 和上下文传播机制 `context propagation mechanism` 对应用程序代码(或其使用的框架)进行检测。 [OpenTracing API](http://opentracing.io/) 实现了 跨编程语言内部一致且与特定跟踪系统没有紧密联系的良好 API。
+
+## 3. Show me the code already!
+
+```
+import (
+ "net/http"
+ "net/http/httptrace"
+
+ "github.com/opentracing/opentracing-go"
+ "github.com/opentracing/opentracing-go/log"
+ "golang.org/x/net/context"
+)
+
+// 这个我们后面会讲
+var tracer opentracing.Tracer
+
+func AskGoogle(ctx context.Context) error {
+ // 从上下文中检索当前 Span
+ // 寻找父context —— parentCtx
+ var parentCtx opentracing.SpanContext
+ // 寻找父Span —— parentSpan
+ parentSpan := opentracing.SpanFromContext(ctx);
+ if parentSpan != nil {
+ parentCtx = parentSpan.Context()
+ }
+
+ // 启动一个新的 Span 来包装 HTTP 请求
+ span := tracer.StartSpan(
+ "ask google",
+ opentracing.ChildOf(parentCtx),
+ )
+
+ // 确保 Span完成后完成
+ defer span.Finish()
+
+ // 使 Span 在上下文中成为当前的
+ ctx = opentracing.ContextWithSpan(ctx, span)
+
+ // 现在准备请求
+ req, err := http.NewRequest("GET", "http://google.com", nil)
+ if err != nil {
+ return err
+ }
+
+ //将 ClientTrace 附加到 Context,并将 Context 附加到请求
+ // 创建一个*httptrace.ClientTrace
+ trace := NewClientTrace(span)
+ //将httptrace.ClientTrace 添加到`context.Context`中
+ ctx = httptrace.WithClientTrace(ctx, trace)
+ //把context添加到请求中
+ req = req.WithContext(ctx)
+ // 执行请求
+ res, err := http.DefaultClient.Do(req)
+ if err != nil {
+ return err
+ }
+
+ //谷歌主页不是太精彩,所以忽略结果
+ res.Body.Close()
+ return nil
+}
+
+```
+
+```
+func NewClientTrace(span opentracing.Span) *httptrace.ClientTrace {
+ trace := &clientTrace{span: span}
+ return &httptrace.ClientTrace {
+ DNSStart: trace.dnsStart,
+ DNSDone: trace.dnsDone,
+ }
+}
+// clientTrace 持有对 Span 的引用和
+// 提供用作 ClientTrace 回调的方法
+type clientTrace struct {
+ span opentracing.Span
+}
+
+func (h *clientTrace) dnsStart(info httptrace.DNSStartInfo) {
+ h.span.LogKV(
+ log.String( "event" , "DNS start" ),
+ log.Object( "主机", info.Host),
+ )
+}
+
+func (h *clientTrace) dnsDone(httptrace.DNSDoneInfo) {
+ h.span.LogKV(log.String( "event" , "DNS done" ))
+}
+```
+
+- 发起一个请求前,准备好 Span `opentracing.Tracer.StartSpan()`
+
+- 然后是请求 `req, err := http.NewRequest("GET", "http://google.com", nil)`
+
+- 根据 Span 创建好一个 `*httptrace.ClientTrace `
+
+ ```
+ httptrace.ClientTrace{
+ DNSStart: trace.dnsStart,,
+ DNSDone: trace.dnsDone,
+ }
+ //DNSStart是函数类型func (info httptrace.DNSStartInfo){}
+ //NSDone 是函数类型func (info httptrace.DNSDoneInfo){}
+ ```
+
+- 将`httptrace.ClientTrace` 添加到`context.Context`中
+
+ ```
+ ctx = httptrace.WithClientTrace(ctx, trace)
+ ```
+
+- 把context添加到请求中
+
+ ```
+ req = req.WithContext(ctx)
+ ```
+
+- AskGoogle 函数接受**context.Context**对象。这是[Go 中开发分布式应用程序的推荐方式](https://blog.golang.org/context),因为 Context 对象允许分布式上下文传播。
+- 我们假设上下文已经包含一个父跟踪 Span。OpenTracing API 中的 Span 用于表示由微服务执行的工作单元。HTTP 调用是可以包装在跟踪 Span 中的操作的一个很好的示例。当我们运行一个处理入站请求的服务时,该服务通常会为每个请求**创建一个跟踪跨度`tracing span`并将其存储在上下文中**,以便在我们对另一个服务进行下游调用时它是可用的。
+- 我们为由私有结构`clientTrace`实现的`DNSStart和``DNSDone`事件注册两个回调,该结构包含对跟踪 Span 的引用。在回调方法中,我们使用 **Span 的键值日志 API 来记录有关事件的信息**,以及 Span 本身隐式捕获的时间戳。
+
+## 4.OpenTracing API 的工作方式
+
+OpenTracing API 的工作方式是,一旦调用了追踪 Span 上的 Finish() 方法,span 捕获的数据就会被发送到追踪系统后端,通常在后台异步发送。然后我们可以使用跟踪系统 UI 来查找跟踪并在时间轴上将其可视化
+
+上面的例子只是为了说明使用 OpenTracing 和**httptrace**的原理。对于真正的工作示例,我们将使用来自[Dominik Honnef](http://dominik.honnef.co/)的现有库https://github.com/opentracing-contrib/go-stdlib,这为我们完成了大部分仪器。使用这个库,我们的客户端代码不需要担心跟踪实际的 HTTP 调用。但是,我们仍然希望创建一个顶级跟踪 Span 来表示客户端应用程序的整体执行情况,并将任何错误记录到它。
+
+```
+package main
+
+import (
+ "fmt"
+ "io/ioutil"
+ "log"
+ "net/http"
+
+ "github.com/opentracing-contrib/go-stdlib/nethttp"
+ "github.com/opentracing/opentracing-go"
+ "github.com/opentracing/opentracing-go/ext"
+ otlog "github.com/opentracing/opentracing-go/log"
+ "golang.org/x/net/context"
+)
+
+func runClient(tracer opentracing.Tracer) {
+ // nethttp.Transport from go-stdlib will do the tracing
+ c := &http.Client{Transport: &nethttp.Transport{}}
+
+ // create a top-level span to represent full work of the client
+ span := tracer.StartSpan(client)
+ span.SetTag(string(ext.Component), client)
+ defer span.Finish()
+ ctx := opentracing.ContextWithSpan(context.Background(), span)
+
+ req, err := http.NewRequest(
+ "GET",
+ fmt.Sprintf("http://localhost:%s/", *serverPort),
+ nil,
+ )
+ if err != nil {
+ onError(span, err)
+ return
+ }
+
+ req = req.WithContext(ctx)
+ // wrap the request in nethttp.TraceRequest
+ req, ht := nethttp.TraceRequest(tracer, req)
+ defer ht.Finish()
+
+ res, err := c.Do(req)
+ if err != nil {
+ onError(span, err)
+ return
+ }
+ defer res.Body.Close()
+ body, err := ioutil.ReadAll(res.Body)
+ if err != nil {
+ onError(span, err)
+ return
+ }
+ fmt.Printf("Received result: %s\n", string(body))
+}
+
+func onError(span opentracing.Span, err error) {
+ // handle errors by recording them in the span
+ span.SetTag(string(ext.Error), true)
+ span.LogKV(otlog.Error(err))
+ log.Print(err)
+}
+```
+
+上面的客户端代码调用本地服务器。让我们也实现它。
+
+```
+package main
+
+import (
+ "fmt"
+ "io"
+ "log"
+ "net/http"
+ "time"
+
+ "github.com/opentracing-contrib/go-stdlib/nethttp"
+ "github.com/opentracing/opentracing-go"
+)
+
+func getTime(w http.ResponseWriter, r *http.Request) {
+ log.Print("Received getTime request")
+ t := time.Now()
+ ts := t.Format("Mon Jan _2 15:04:05 2006")
+ io.WriteString(w, fmt.Sprintf("The time is %s", ts))
+}
+
+func redirect(w http.ResponseWriter, r *http.Request) {
+ http.Redirect(w, r,
+ fmt.Sprintf("http://localhost:%s/gettime", *serverPort), 301)
+}
+
+func runServer(tracer opentracing.Tracer) {
+ http.HandleFunc("/gettime", getTime)
+ http.HandleFunc("/", redirect)
+ log.Printf("Starting server on port %s", *serverPort)
+ http.ListenAndServe(
+ fmt.Sprintf(":%s", *serverPort),
+ // use nethttp.Middleware to enable OpenTracing for server
+ nethttp.Middleware(tracer, http.DefaultServeMux))
+}
+```
+
+请注意,客户端向根端点“/”发出请求,但服务器将其重定向到“/gettime”端点。这样做可以让我们更好地说明如何在跟踪系统中捕获跟踪。
+
+## 5. 运行
+
+我假设有一个 Go 1.7 的本地安装,以及一个正在运行的 Docker,我们将使用它来运行 Zipkin 服务器。
+
+演示项目使用[glide](https://github.com/Masterminds/glide)进行依赖管理,请先安装。例如,在 Mac OS 上,您可以执行以下操作:
+
+```
+$ brew install glide
+```
+
+```
+$ glide install
+```
+
+```
+$ go build .
+```
+
+现在在另一个终端,让我们启动 Zipkin 服务器
+
+```
+$ docker run -d -p 9410-9411:9410-9411 openzipkin/zipkin:1.12.0
+Unable to find image 'openzipkin/zipkin:1.12.0' locally
+1.12.0: Pulling from openzipkin/zipkin
+4d06f2521e4f: Already exists
+93bf0c6c4f8d: Already exists
+a3ed95caeb02: Pull complete
+3db054dce565: Pull complete
+9cc214bea7a6: Pull complete
+Digest: sha256:bf60e4b0ba064b3fe08951d5476bf08f38553322d6f640d657b1f798b6b87c40
+Status: Downloaded newer image for openzipkin/zipkin:1.12.0
+da9353ac890e0c0b492ff4f52ff13a0dd12826a0b861a67cb044f5764195e005
+```
+
+如果没有 Docker,另一种运行 Zipkin 服务器的方法是直接从 jar 中:
+
+```
+$ wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
+$ java -jar zipkin.jar
+```
+
+打开用户界面:
+
+```
+open http://localhost:9411/
+```
+
+如果您重新加载 UI 页面,您应该会看到“客户端”出现在第一个下拉列表中。
+
+
+
+单击 Find Traces 按钮,您应该会看到一条跟踪。
+
+
+
+单击trace.
+
+
+
+在这里,我们看到以下跨度:
+
+1. 由服务生成的称为“client”的顶级(根)跨度也称为“client”,它跨越整个时间轴 3.957 毫秒。
+2. 下一级(子)跨度称为“http 客户端”,也是由“客户端”服务生成的。这个跨度是由**go-stdlib**库自动创建的,跨越整个 HTTP 会话。
+3. 由名为“server”的服务生成的两个名为“http get”的跨度。这有点误导,因为这些跨度中的每一个实际上在内部都由两部分组成,客户端提交的数据和服务器提交的数据。Zipkin UI 总是选择接收服务的名称显示在左侧。这两个跨度表示对“/”端点的第一个请求,在收到重定向响应后,对“/gettime”端点的第二个请求。
+
+另请注意,最后两个跨度在时间轴上显示白点。如果我们将鼠标悬停在其中一个点上,我们将看到它们实际上是 ClientTrace 捕获的事件,例如 DNSStart:
+
+您还可以单击每个跨度以查找更多详细信息,包括带时间戳的日志和键值标签。例如,单击第一个“http get”跨度会显示以下弹出窗口:
+
+
+
+在这里,我们看到两种类型的事件。从客户端和服务器的角度来看的整体开始/结束事件:客户端发送(请求),服务器接收(请求),服务器发送(响应),客户端接收(响应)。**在它们之间,我们看到go-stdlib**检测记录到跨度的其他事件,因为它们是由**httptrace**报告的,例如从 0.16 毫秒开始并在 2.222 毫秒完成的 DNS 查找、建立连接以及发送/接收请求/响应数据。
+
+这是显示跨度的键/值标签的同一弹出窗口的延续。标签与任何时间戳无关,只是提供有关跨度的元数据。在这里,我们可以看到在哪个 URL 发出请求、收到的**301**响应代码(重定向)、运行客户端的主机名(屏蔽)以及有关跟踪器实现的一些信息,例如客户端库版本“Go- 1.6”。
+
+第 4 个跨度的细节类似。需要注意的一点是,第 4 个跨度要短得多,因为没有 DNS 查找延迟,并且它针对状态代码为 200 的 /gettime 端点
+
+
+
+## 6.跟踪器
+
+跟踪器是 OpenTracing API 的实际实现。在我的示例中,我使用了https://github.com/uber/jaeger-client-go,它是来自 Uber 的分布式跟踪系统 Jaeger 的与 OpenTracing 兼容的客户端库。
+
+```
+package main
+
+import (
+ "flag"
+ "log"
+
+ "github.com/uber/jaeger-client-go"
+ "github.com/uber/jaeger-client-go/transport/zipkin"
+)
+
+var (
+ zipkinURL = flag.String("url",
+ "http://localhost:9411/api/v1/spans", "Zipkin server URL")
+ serverPort = flag.String("port", "8000", "server port")
+ actorKind = flag.String("actor", "server", "server or client")
+)
+
+const (
+ server = "server"
+ client = "client"
+)
+
+func main() {
+ flag.Parse()
+
+ if *actorKind != server && *actorKind != client {
+ log.Fatal("Please specify '-actor server' or '-actor client'")
+ }
+
+ // Jaeger tracer can be initialized with a transport that will
+ // report tracing Spans to a Zipkin backend
+ transport, err := zipkin.NewHTTPTransport(
+ *zipkinURL,
+ zipkin.HTTPBatchSize(1),
+ zipkin.HTTPLogger(jaeger.StdLogger),
+ )
+ if err != nil {
+ log.Fatalf("Cannot initialize HTTP transport: %v", err)
+ }
+ // create Jaeger tracer
+ tracer, closer := jaeger.NewTracer(
+ *actorKind,
+ jaeger.NewConstSampler(true), // sample all traces
+ jaeger.NewRemoteReporter(transport, nil),
+ )
+ // Close the tracer to guarantee that all spans that could
+ // be still buffered in memory are sent to the tracing backend
+ defer closer.Close()
+ if *actorKind == server {
+ runServer(tracer)
+ return
+ }
+ runClient(tracer)
+}
+
+```
+
diff --git a/_posts/2022-07-13-test-markdown.md b/_posts/2022-07-13-test-markdown.md
new file mode 100644
index 000000000000..078d153fa7fa
--- /dev/null
+++ b/_posts/2022-07-13-test-markdown.md
@@ -0,0 +1,726 @@
+---
+layout: post
+title: RPC应用
+subtitle: RPC 代指远程过程调用(Remote Procedure Call),它的调用包含了传输协议和编码(对象序列)协议等等,允许运行于一台计算机的程序调用另一台计算机的子程序,而开发人员无需额外地为这个交互作用编程,因此我们也常常称 RPC 调用,就像在进行本地函数调用一样方便。
+tags: [RPC]
+---
+# RPC应用
+
+> 写这篇文章的起源是,,,,,,,,对,没错,就是为了回顾一波,发现在回顾的过程中 还是有很多很多地方之前学习的不够清晰。
+
+首先我们将对 gRPC 和 Protobuf 进行介绍,然后会在接下来会对两者做更进一步的使用和详细介绍。
+
+## 1.什么是 RPC
+
+RPC 代指远程过程调用(Remote Procedure Call),它的调用包含了传输协议和编码(对象序列)协议等等,允许运行于一台计算机的程序调用另一台计算机的子程序,而**开发人员无需额外地为这个交互作用编程**,因此我们也常常称 RPC 调用,就像在进行本地函数调用一样方便。
+
+> 开发人员无需额外地为这个交互作用编程。
+
+## 2.gRPC
+
+> gRPC 是一个高性能、开源和通用的 RPC 框架,面向移动和基于 HTTP/2 设计。目前提供 C、Java 和 Go 语言等等版本,分别是:grpc、grpc-java、grpc-go,其中 C 版本支持 C、C++、Node.js、Python、Ruby、Objective-C、PHP 和 C# 支持。
+
+gRPC 基于 HTTP/2 标准设计,带来诸如双向流、流控、头部压缩、单 TCP 连接上的多复用请求等特性。这些特性使得其在移动设备上表现更好,在一定的情况下更节省空间占用。
+
+gRPC 的接口描述语言(Interface description language,缩写 IDL)使用的是 Protobuf,都是由 Google 开源的。
+
+> gRPC 使用Protobuf 作为接口描述语言。
+
+#### gRPC 调用模型
+
+
+
+1. 客户端(gRPC Stub)在程序中调用某方法,发起 RPC 调用。
+2. 对请求信息使用 Protobuf 进行对象序列化压缩(IDL)。
+3. 服务端(gRPC Server)接收到请求后,解码请求体,进行业务逻辑处理并返回。
+4. 对响应结果使用 Protobuf 进行对象序列化压缩(IDL)。
+5. 客户端接受到服务端响应,解码请求体。回调被调用的 A 方法,唤醒正在等待响应(阻塞)的客户端调用并返回响应结果。
+
+## 3. Protobuf
+
+> Protocol Buffers(Protobuf)是一种与语言、平台无关,可扩展的序列化结构化数据的数据描述语言,我们常常称其为 IDL,常用于通信协议,数据存储等等,相较于 JSON、XML,它更小、更快,因此也更受开发人员的青眯。
+
+### 基本语法
+
+```
+syntax = "proto3";
+
+package helloworld;
+
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+}
+
+message HelloRequest {
+ string name = 1;
+}
+
+message HelloReply {
+ string message = 1;
+}
+```
+
+1. 第一行(非空的非注释行)声明使用 `proto3` 语法。如果不声明,将默认使用 `proto2` 语法。同时建议无论是用 v2 还是 v3 版本,都应当进行显式声明。而在版本上,目前主流推荐使用 v3 版本。
+2. 定义名为 `Greeter` 的 RPC 服务(Service),其包含 RPC 方法 `SayHello`,入参为 `HelloRequest` 消息体(message),出参为 `HelloReply` 消息体。
+3. 定义 `HelloRequest`、`HelloReply` 消息体,每一个消息体的字段包含三个属性:类型、字段名称、字段编号。在消息体的定义上,除类型以外均不可重复。
+
+在编写完.proto 文件后,我们一般会进行编译和生成对应语言的 proto 文件操作,这个时候 Protobuf 的编译器会根据选择的语言不同、调用的插件情况,生成相应语言的 Service Interface Code 和 Stubs。
+
+### 基本数据类型
+
+在生成了对应语言的 proto 文件后,需要注意的是 protobuf 所生成出来的数据类型并非与原始的类型完全一致,因此需要有一个基本的了解,下面是我列举了的一些常见的类型映射,如下表:
+
+| .proto Type | C++ Type | Java Type | Go Type | PHP Type |
+| ----------- | -------- | ---------- | ------- | -------------- |
+| double | double | double | float64 | float |
+| float | float | float | float32 | float |
+| int32 | int32 | int | int32 | integer |
+| int64 | int64 | long | int64 | integer/string |
+| uint32 | uint32 | int | uint32 | integer |
+| uint64 | uint64 | long | uint64 | integer/string |
+| sint32 | int32 | int | int32 | integer |
+| sint64 | int64 | long | int64 | integer/string |
+| fixed32 | uint32 | int | uint32 | integer |
+| fixed64 | uint64 | long | uint64 | integer/string |
+| sfixed32 | int32 | int | int32 | integer |
+| sfixed64 | int64 | long | int64 | integer/string |
+| bool | bool | boolean | bool | boolean |
+| string | string | String | string | string |
+| bytes | string | ByteString | []byte | string |
+
+## 4.gRPC 与 RESTful API 对比
+
+| 特性 | gRPC | RESTful API |
+| ---------- | ---------------------- | -------------------- |
+| 规范 | 必须.proto | 可选 OpenAPI |
+| 协议 | HTTP/2 | 任意版本的 HTTP 协议 |
+| 有效载荷 | Protobuf(小、二进制) | JSON(大、易读) |
+| 浏览器支持 | 否(需要 grpc-web) | 是 |
+| 流传输 | 客户端、服务端、双向 | 客户端、服务端 |
+| 代码生成 | 是 | OpenAPI+ 第三方工具 |
+
+#### 性能
+
+gRPC 使用的 IDL 是 Protobuf,Protobuf 在客户端和服务端上都能快速地进行序列化,并且序列化后的结果较小,能够有效地节省传输占用的数据大小。另外众多周知,gRPC 是基于 HTTP/2 协议进行设计的,有非常显著的优势。
+
+另外常常会有人问,为什么是 Protobuf,为什么 gRPC 不用 JSON、XML 这类 IDL 呢,我想主要有如下原因:
+
+- 在定义上更简单,更明了。
+- 数据描述文件只需原来的 1/10 至 1/3。
+- 解析速度是原来的 20 倍至 100 倍。
+- 减少了二义性。
+- 生成了更易使用的数据访问类。
+- 序列化和反序列化速度快。
+- 开发者本身在传输过程中并不需要过多的关注其内容。
+
+#### 代码生成
+
+在代码生成上,我们只需要一个 proto 文件就能够定义 gRPC 服务和消息体的约定,并且 gRPC 及其生态圈提供了大量的工具从 proto 文件中生成服务基类、消息体、客户端等等代码,也就是客户端和服务端共用一个 proto 文件就可以了,保证了 IDL 的一致性且减少了重复工作。
+
+> **客户端和服务端共用一个 proto 文件**
+
+#### 流传输
+
+gRPC 通过 HTTP/2 对流传输提供了大量的支持:
+
+1. Unary RPC:一元 RPC。
+2. Server-side streaming RPC:服务端流式 RPC。
+3. Client-side streaming RPC:客户端流式 RPC。
+4. Bidirectional streaming RPC:双向流式 RPC。
+
+#### 超时和取消
+
+并且根据 Go 语言的上下文(context)的特性,截止时间的传递是可以一层层传递下去的,也就是我们可以通过一层层 gRPC 调用来进行上下文的传播截止日期和取消事件,有助于我们处理一些上下游的连锁问题等等场景。
+
+# Protobuf 的使用
+
+### protoc 安装
+
+```
+wget https://github.com/google/protobuf/releases/download/v3.11.2/protobuf-all-3.11.2.zip
+$ unzip protobuf-all-3.11.2.zip && cd protobuf-3.11.2/
+$ ./configure
+$ make
+$ make install
+```
+
+##### protoc 插件安装
+
+Go 语言就是 protoc-gen-go 插件
+
+```
+go get -u github.com/golang/protobuf/protoc-gen-go@v1.3.2
+```
+
+##### 将所编译安装的 Protoc Plu
+
+```
+mv $GOPATH/bin/protoc-gen-go /usr/local/go/bin/
+```
+
+这里的命令操作并非是绝对必须的,主要目的是将二进制文件 protoc-gen-go 移动到 bin 目录下,让其可以直接运行 protoc-gen-go 执行,只要达到这个效果就可以了。
+
+## 初始化 Demo 项目
+
+在初始化目录结构后,新建 server、client、proto 目录,便于后续的使用,最终目录结构如下:
+
+```
+grpc-demo
+├── go.mod
+├── client
+├── proto
+└── server
+```
+
+##### 编译和生成 proto 文件
+
+```
+syntax = "proto3";
+
+package helloworld;
+
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+}
+
+message HelloRequest {
+ string name = 1;
+}
+
+message HelloReply {
+ string message = 1;
+}
+```
+
+##### 生成 proto 文件
+
+```
+$ protoc --go_out=plugins=grpc:. ./proto/*.proto
+```
+
+##### 生成的.pb.go 文件
+
+```
+type HelloRequest struct {
+ Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
+ ...
+}
+
+func (m *HelloRequest) Reset() { *m = HelloRequest{} }
+func (m *HelloRequest) String() string { return proto.CompactTextString(m) }
+func (*HelloRequest) ProtoMessage() {}
+func (*HelloRequest) Descriptor() ([]byte, []int) {
+ return fileDescriptor_4d53fe9c48eadaad, []int{0}
+}
+func (m *HelloRequest) GetName() string {...}
+```
+
+ HelloRequest 类型,其包含了一组 Getters 方法,能够提供便捷的取值方式,并且处理了一些空指针取值的情况,还能够通过 Reset 方法来重置该参数。而该方法通过实现 ProtoMessage 方法,以此表示这是一个实现了 proto.Message 的接口。另外 HelloReply 类型也是类似的生成结果,因此不重复概述。
+
+接下来我们看到.pb.go 文件的初始化方法,其中比较特殊的就是 fileDescriptor 的相关语句,如下:
+
+```
+func init() {
+ proto.RegisterType((*HelloRequest)(nil), "helloworld.HelloRequest")
+ proto.RegisterType((*HelloReply)(nil), "helloworld.HelloReply")
+}
+
+func init() { proto.RegisterFile("proto/helloworld.proto", fileDescriptor_4d53fe9c48eadaad) }
+
+var fileDescriptor_4d53fe9c48eadaad = []byte{
+ 0x1f, 0x8b, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0xff, 0xe2, 0x12, 0x2b, 0x28, 0xca, 0x2f,
+ ...
+}
+```
+
+`fileDescriptor_4d53fe9c48eadaad` 表示的是一个经过编译后的 proto 文件,是对 proto 文件的整体描述,其包含了 proto 文件名、引用(import)内容、包(package)名、选项设置、所有定义的消息体(message)、所有定义的枚举(enum)、所有定义的服务( service)、所有定义的方法(rpc method)等等内容,可以认为就是整个 proto 文件的信息都能够取到。
+
+同时在我们的每一个 Message Type 中都包含了 Descriptor 方法,Descriptor 代指对一个消息体(message)定义的描述,而这一个方法则会在 fileDescriptor 中寻找属于自己 Message Field 所在的位置再进行返回,如下:
+
+```
+func (*HelloRequest) Descriptor() ([]byte, []int) {
+ return fileDescriptor_4d53fe9c48eadaad, []int{0}
+}
+
+func (*HelloReply) Descriptor() ([]byte, []int) {
+ return fileDescriptor_4d53fe9c48eadaad, []int{1}
+}
+```
+
+接下来我们再往下看可以看到 GreeterClient 接口,因为 Protobuf 是客户端和服务端可共用一份.proto 文件的,因此除了存在数据描述的信息以外,还会存在客户端和服务端的相关内部调用的接口约束和调用方式的实现,在后续我们在多服务内部调用的时候会经常用到,如下:
+
+```
+type GreeterClient interface {
+ SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error)
+}
+```
+
+```
+type greeterClient struct {
+ cc *grpc.ClientConn
+}
+```
+
+```
+func NewGreeterClient(cc *grpc.ClientConn) GreeterClient {
+ return &greeterClient{cc}
+}
+```
+
+```
+func (c *greeterClient) SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+```
+
+## 更多的类型支持
+
+### 通用类型
+
+在 Protobuf 中一共支持 double、float、int32、int64、uint32、uint64、sint32、sint64、fixed32、fixed64、sfixed32、sfixed64、bool、string、bytes 类型
+
+```
+message HelloRequest {
+ bytes name = 1;
+}
+```
+
+另外我们常常会遇到需要传递动态数组的情况,在 protobuf 中,我们可以使用 repeated 关键字,如果一个字段被声明为 repeated,那么该字段可以重复任意次(包括零次),重复值的顺序将保留在 protobuf 中,将重复字段视为动态大小的数组,如下:
+
+```
+message HelloRequest {
+ repeated string name = 1;
+}
+```
+
+### 嵌套类型
+
+```
+message HelloRequest {
+ message World {
+ string name = 1;
+ }
+
+ repeated World worlds = 1;
+}
+```
+
+```
+message World {
+ string name = 1;
+}
+
+message HelloRequest {
+ repeated World worlds = 1;
+}
+```
+
+第一种是将 World 消息体定义在 HelloRequest 消息体中,也就是其归属在消息体 HelloRequest 下,若要调用则需要使用 `HelloRequest.World` 的方式,外部才能引用成功。
+
+第二种是将 World 消息体定义在外部,一般比较推荐使用这种方式,清晰、方便。
+
+### Oneof
+
+如果希望的消息体可以包含多个字段,但前提条件是最多同时只允许设置一个字段,那么就可以使用 oneof 关键字来实现这个功能,如下:
+
+```
+message HelloRequest {
+ oneof name {
+ string nick_name = 1;
+ string true_name = 2;
+ }
+}
+```
+
+### Enum
+
+```
+enum NameType {
+ NickName = 0;
+ TrueName = 1;
+}
+
+message HelloRequest {
+ string name = 1;
+ NameType nameType = 2;
+}
+```
+
+### Map
+
+```
+message HelloRequest {
+ map names = 2;
+}
+```
+
+# gRPC
+
+### gRPC 的四种调用方式
+
+1. Unary RPC:一元 RPC。
+
+2. Server-side streaming RPC:服务端流式 RPC。
+
+3. Client-side streaming RPC:客户端流式 RPC。
+
+4. Bidirectional streaming RPC:双向流式 RPC。
+
+ 不同的调用方式往往代表着不同的应用场景,我们接下来将一同深入了解各个调用方式的实现和使用场景,在下述代码中,我们统一将项目下的 proto 引用名指定为 pb,并设置端口号都由外部传入,如下:
+
+```
+import (
+ ...
+ // 设置引用别名
+ pb "github.com/go-programming-tour-book/grpc-demo/proto"
+)
+
+var port string
+
+func init() {
+ flag.StringVar(&port, "p", "8000", "启动端口号")
+ flag.Parse()
+}
+```
+
+我们下述的调用方法都是在 `server` 目录下的 server.go 和 `client` 目录的 client.go 中完成,需要注意的该两个文件的 package 名称应该为 main(IDE 默认会创建与目录名一致的 package 名称),这样子的 main 方法才能够被调用,并且在**本章中我们的 proto 引用都会以引用别名 pb 来进行调用**。
+
+### Unary RPC:一元 RPC
+
+一元 RPC,也就是是单次 RPC 调用,简单来讲就是客户端发起一次普通的 RPC 请求,响应,是最基础的调用类型,也是最常用的方式,大致如图:
+
+
+
+#### Proto
+
+```
+rpc SayHello (HelloRequest) returns (HelloReply) {};
+```
+
+#### Server
+
+```
+type GreeterServer struct{}
+
+func (s *GreeterServer) SayHello(ctx context.Context, r *pb.HelloRequest) (*pb.HelloReply, error) {
+ return &pb.HelloReply{Message: "hello.world"}, nil
+}
+
+func main() {
+ server := grpc.NewServer()
+ pb.RegisterGreeterServer(server, &GreeterServer{})
+ lis, _ := net.Listen("tcp", ":"+port)
+ server.Serve(lis)
+}
+```
+
+- **创建 gRPC Server 对象,可以理解为它是 Server 端的抽象对象。**
+- **将 GreeterServer(其包含需要被调用的服务端接口)注册到 gRPC Server。 的内部注册中心。这样可以在接受到请求时,通过内部的 “服务发现”,发现该服务端接口并转接进行逻辑处理。**
+- **创建 Listen,监听 TCP 端口。**
+- **gRPC Server 开始 lis.Accept,直到 Stop 或 GracefulStop。**
+
+#### Client
+
+```
+func main() {
+ conn, _ := grpc.Dial(":"+port, grpc.WithInsecure())
+ defer conn.Close()
+
+ client := pb.NewGreeterClient(conn)
+ _ = SayHello(client)
+}
+
+func SayHello(client pb.GreeterClient) error {
+ resp, _ := client.SayHello(context.Background(), &pb.HelloRequest{Name: "eddycjy"})
+ log.Printf("client.SayHello resp: %s", resp.Message)
+ return nil
+}
+```
+
+What is important?
+
+- ```
+ pb.NewGreeterClient()
+ pb.RegisterGreetServer()
+ //也就是说Protobuf 及其编译工具的使用 就是为我们自动生成这个两个函数
+ ```
+
+- ```
+ pb.NewGreeterClient() 需要一个grpc.Dial(":"+port, grpc.WithInsecure())客户端作为参数
+ ```
+
+- ```
+ pb.RegisterGreetServer() 不仅需要一个grpc.NewServer()服务端,还需要自己抽象出的服务端,&GreeterServer{}
+ ```
+
+### Server-side streaming RPC:服务端流式 RPC
+
+> 简单来讲就是客户端发起一次普通的 RPC 请求,服务端通过流式响应多次发送数据集,客户端 Recv 接收数据集。大致如图:
+
+
+
+#### Proto
+
+```protobuf
+rpc SayList (HelloRequest) returns (stream HelloReply) {};
+```
+
+#### Server
+
+```
+func (s *GreeterServer) SayList(r *pb.HelloRequest, stream pb.Greeter_SayListServer) error {
+ for n := 0; n <= 6; n++ {
+ _ = stream.Send(&pb.HelloReply{Message: "hello.list"})
+ }
+ return nil
+}
+```
+
+在 Server 端,主要留意 `stream.Send` 方法,通过阅读源码,可得知是 protoc 在生成时,根据定义生成了各式各样符合标准的接口方法。最终再统一调度内部的 `SendMsg` 方法,该方法涉及以下过程:
+
+- 消息体(对象)序列化。
+- 压缩序列化后的消息体。
+- 对正在传输的消息体增加 5 个字节的 header(标志位)。
+- 判断压缩 + 序列化后的消息体总字节长度是否大于预设的 maxSendMessageSize(预设值为 `math.MaxInt32`),若超出则提示错误。
+- 写入给流的数据集。
+
+#### Client
+
+```
+func SayList(client pb.GreeterClient, r *pb.HelloRequest) error {
+ stream, _ := client.SayList(context.Background(), r)
+ for {
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ break
+ }
+ if err != nil {
+ return err
+ }
+
+ log.Printf("resp: %v", resp)
+ }
+
+ return nil
+}
+```
+
+#### what is important?
+
+```
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+ rpc SayList (HelloRequest) returns (stream HelloReply) {};
+}
+
+type GreeterServer struct{}
+
+func (s *GreeterServer) SayList(r *pb.HelloRequest, stream pb.Greeter_SayListServer) error {
+ for n := 0; n <= 6; n++ {
+ _ = stream.Send(&pb.HelloReply{Message: "hello.list"})
+ }
+ return nil
+}
+
+func (s *GreeterServer) SayHello(ctx context.Context, r *pb.HelloRequest) (*pb.HelloReply, error) {
+ return &pb.HelloReply{Message: "hello.world"}, nil
+}
+
+//服务端调用的是 pb.Greeter_SayListServer.Send()
+//客户端调用的是 pb.GreeterClient.SayList()
+
+```
+
+1. service Greeter 对应 `pb.ResisterGreetService()`
+2. 调用`pb.ResisterGreetService()`注册 GreeterServer{}
+3. SayList 实际调用 pb.Greeter_SayListServer.Send()来实现流输出.
+4. SayHello实际调用 `func (s *GreeterServer) SayHello(ctx context.Context, r *pb.HelloRequest) (*pb.HelloReply, error) {`
+ `return &pb.HelloReply{Message: "hello.world"}, nil`
+ `}`函数直接写入
+
+```
+service Greeter {
+ rpc SayHello (HelloRequest) returns (HelloReply) {}
+ rpc SayList (HelloRequest) returns (stream HelloReply) {};
+}
+```
+
+```
+type greeterClient struct {
+ cc *grpc.ClientConn
+}
+```
+
+```
+func NewGreeterClient(cc *grpc.ClientConn) GreeterClient {
+ return &greeterClient{cc}
+}
+```
+
+```
+func (c *greeterClient) SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+```
+
+```
+func (c *greeterClient) SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+```
+
+```
+func (c *greeterClient) SayList(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) {
+ out := new(HelloReply)
+ err := c.cc.Invoke(ctx, "/helloworld.Greeter/SayHello", in, out, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+
+```
+
+```
+func (h *HelloReply) Recv(){
+ //是对ClientStream.RecvMsg()的封装
+ //RecvMsg 方法会从流中读取完整的 gRPC 消息体
+}
+```
+
+- `SayHello()`调用`greeterClient.cc.Invoke` 实际是`grpc.ClientConn.Invoke`
+
+```
+type greeterClient struct {
+ cc *grpc.ClientConn
+}
+```
+
+- `SayList()`调用`ClientStream.RecvMsg()`
+
+### Client-side streaming RPC:客户端流式 RPC
+
+> 客户端流式 RPC,单向流,客户端通过流式发起**多次** RPC 请求给服务端,服务端发起**一次**响应给客户端,大致如图:
+
+
+
+#### Proto
+
+```
+rpc SayRecord(stream HelloRequest) returns (HelloReply) {};
+```
+
+#### Server
+
+```
+func (s *GreeterServer) SayRecord(stream pb.Greeter_SayRecordServer) error {
+ for {
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ return stream.SendAndClose(&pb.HelloReply{Message:"say.record"})
+ }
+ if err != nil {
+ return err
+ }
+
+ log.Printf("resp: %v", resp)
+ }
+
+ return nil
+}
+```
+
+#### Client
+
+```
+func SayRecord(client pb.GreeterClient, r *pb.HelloRequest) error {
+ stream, _ := client.SayRecord(context.Background())
+ for n := 0; n < 6; n++ {
+ _ = stream.Send(r)
+ }
+ resp, _ := stream.CloseAndRecv()
+
+ log.Printf("resp err: %v", resp)
+ return nil
+}
+```
+
+在 Server 端的 `stream.SendAndClose`,与 Client 端 `stream.CloseAndRecv` 是配套使用的方法。
+
+### Bidirectional streaming RPC:双向流式 RPC
+
+> 双向流式 RPC,顾名思义是双向流,由客户端以流式的方式发起请求,服务端同样以流式的方式响应请求。
+>
+> 首个请求一定是 Client 发起,但具体交互方式(谁先谁后、一次发多少、响应多少、什么时候关闭)根据程序编写的方式来确定(可以结合协程)。
+>
+> 假设该双向流是**按顺序发送**的话,大致如图:
+
+
+
+#### Proto
+
+```
+rpc SayRoute(stream HelloRequest) returns (stream HelloReply) {};
+```
+
+#### Server
+
+```
+func (s *GreeterServer) SayRoute(stream pb.Greeter_SayRouteServer) error {
+ n := 0
+ for {
+ _ = stream.Send(&pb.HelloReply{Message: "say.route"})
+
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ return nil
+ }
+ if err != nil {
+ return err
+ }
+
+ n++
+ log.Printf("resp: %v", resp)
+ }
+}
+```
+
+#### Client
+
+```
+func SayRoute(client pb.GreeterClient, r *pb.HelloRequest) error {
+ stream, _ := client.SayRoute(context.Background())
+ for n := 0; n <= 6; n++ {
+ _ = stream.Send(r)
+ resp, err := stream.Recv()
+ if err == io.EOF {
+ break
+ }
+ if err != nil {
+ return err
+ }
+
+ log.Printf("resp err: %v", resp)
+ }
+
+ _ = stream.CloseSend()
+
+ return nil
+}
+```
+
diff --git a/_posts/2022-07-14-test-markdown.md b/_posts/2022-07-14-test-markdown.md
new file mode 100644
index 000000000000..02d2b7757bd4
--- /dev/null
+++ b/_posts/2022-07-14-test-markdown.md
@@ -0,0 +1,89 @@
+---
+layout: post
+title: 适配器模式
+subtitle: 亦称 封装器模式、Wrapper、Adapter
+tags: [设计模式]
+---
+
+# 适配器模式
+
+> **亦称:** 封装器模式、Wrapper、Adapter
+
+**适配器模式**是一种结构型设计模式, 它能使接口不兼容的对象能够相互合作。
+
+
+
+假如正在开发一款股票市场监测程序, 它会从不同来源下载 XML 格式的股票数据, 然后向用户呈现出美观的图表。在开发过程中, 决定在程序中整合一个第三方智能分析函数库。 但是遇到了一个问题, 那就是分析函数库只兼容 JSON 格式的数据。
+
+
+
+可以修改程序库来支持 XML。 但是, 这可能需要修改部分依赖该程序库的现有代码。 甚至还有更糟糕的情况, 可能根本没有程序库的源代码, 从而无法对其进行修改。
+
+## 解决
+
+创建一个*适配器*。 这是一个特殊的对象, 能够转换对象接口, 使其能与其他对象进行交互。
+
+适配器模式通过**封装对象**将复杂的转换过程隐藏于幕后。 **被封装的对象**甚至察觉不到适配器的存在。
+
+适配器不仅可以转换不同格式的数据, 其还有助于**不同接口的对象之间的合作**。 它的运作方式如下:
+
+1. **适配器实现**与其中一个**现有对象**兼容**的接口**。
+2. **现有对象**可以使用该接口安全地调用适配器方法。
+3. **适配器方法被调用**后将以另一个对象兼容的格式和顺序将请求传递给该对象。
+
+有时甚至可以创建一个双向适配器来实现双向转换调用。
+
+> 谁适配谁? A 适配 B 、B 是已经有的库和接口,然后我们去适配, 所以要找到 B 的接口 ,然后用我们需要的适配器去实现 B 的接口 ,适配器在实现B的接口的时候,要做的事就是 在 B的接口对应的函数里面,调用适配器对应的想要调用的函数,那么具体适配器想要调用的函数具体是什么就要看 想要让 A 如何去适配 B ,如果 A 适配 B 我这里的A 是一系列自己写的函数,那么适配器就搞个函数类型去适配 B ,如果我这里是一堆对象想要去适配 B 那么我就写个适配器对象。第一种在http编程里面有很好的体现。
+
+```
+//golang 的标准库 net/http 提供了 http 编程有关的接口,封装了内部TCP连接和报文解析的复杂琐碎的细节,使用者只需要和 http.request 和 http.ResponseWriter 两个对象交互就行。也就是说,我们只要写一个 handler,请求会通过参数传递进来,而它要做的就是根据请求的数据做处理,把结果写到 Response 中。
+
+package main
+
+import (
+ "io"
+ "net/http"
+)
+
+type helloHandler struct{}
+
+func (h *helloHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
+ w.Write([]byte("Hello, world!"))
+}
+
+func main() {
+ http.Handle("/", &helloHandler{})
+ http.ListenAndServe(":12345", nil)
+}
+// helloHandler实现了 ServeHTTP 方法
+// 只要实现了 ServeHTTP 方法的对象都可以作为 Handler 传给http.Handle()
+```
+
+```
+//接口原型
+type Handler interface {
+ ServeHTTP(ResponseWriter, *Request)
+}
+```
+
+```
+//不便:每次写 Handler 的时候,都要定义一个类型,然后编写对应的 ServeHTTP 方法
+
+//提供了 http.HandleFunc 方法,允许直接把特定类型的函数作为 handler
+//怎么做的
+// The HandlerFunc type is an adapter to allow the use of
+// ordinary functions as HTTP handlers. If f is a function
+// with the appropriate signature, HandlerFunc(f) is a
+// Handler object that calls f.
+type HandlerFunc func(ResponseWriter, *Request)
+
+// ServeHTTP calls f(w, r).
+func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
+ f(w, r)
+}
+
+```
+
+**`type HandlerFunc func(ResponseWriter, *Request) ` 就是一个适配器**
+
+自动给 `f` 函数添加了 `HandlerFunc` 这个壳,最终调用的还是 `ServerHTTP`,只不过会直接使用 `f(w, r)`。这样封装的好处是:使用者可以专注于业务逻辑的编写,省去了很多重复的代码处理逻辑。如果只是简单的 Handler,会直接使用函数;如果是需要传递更多信息或者有复杂的操作,会使用上部分的方法。
\ No newline at end of file
diff --git a/_posts/2022-07-15-test-markdown.md b/_posts/2022-07-15-test-markdown.md
new file mode 100644
index 000000000000..3b5774610a02
--- /dev/null
+++ b/_posts/2022-07-15-test-markdown.md
@@ -0,0 +1,33 @@
+---
+layout: post
+title: 关于Metrics, tracing, and logging 的不同
+subtitle: 从本质来看........
+tags: [Metric]
+---
+# 关于Metrics, tracing, and logging 的不同
+
+
+
+## 1.`metrics`
+
+我认为`metrics`的定义特征是它们是可聚合`aggregatable`的:它们是在一段时间内组成单个逻辑量规、计数器或直方图的原子。例如:队列的当前深度可以建模为一个计量器,其更新与 last-writer-win 语义聚合;传入的 HTTP 请求的数量可以建模为一个计数器,其更新通过简单的加法聚合;并且观察到的请求持续时间可以建模为直方图,其更新聚合到时间桶中并产生统计摘要。
+
+
+
+## 2.`logging `
+
+我认`logging` 的定义特征是它处理离散事件。例如:应用程序调试或错误消息通过logs实例发送到 终端或者文件流输出。审计跟踪`audit-trail`事件通过 Kafka 推送到 BigTable 等数据湖;或从服务调用中提取的特定于请求的元数据并发送到像 NewRelic 这样的错误跟踪服务。
+
+## 3.` tracking `
+
+我认为 tracking 的唯一定义特征**是**它处理请求范围内的信息。可以绑定到系统中单个事务对象的生命周期的任何数据或元数据。例如:出站 `RPC` 到远程服务的持续时间;发送到数据库的实际 `SQL` 查询的文本;或入站 HTTP 请求的相关 ID。
+
+通过这些定义,我们可以标记重叠部分。
+
+
+
+当然,云原生应用程序的许多典型工具最终都将是请求范围的,因此在更广泛的跟踪上下文中讨论可能是有意义的。但是我们现在可以观察到,并非*所有*仪器都绑定到请求生命周期:例如逻辑组件诊断信息或流程生命周期细节,它们与任何离散请求正交。因此,例如,并非所有指标或日志都可以硬塞到跟踪系统中——至少,不是没有一些工作。或者,我们可能会意识到直接在我们的应用程序中检测指标会给我们带来强大的好处,比如]`prometheus.io/docs/querying/basics`估我们车队的实时视图;相比之下,将指标硬塞到日志管道中可能会迫使我们放弃其中的一些优势。
+
+此外,我观察到一个奇怪的操作细节作为这种可视化的副作用。在这三个领域中,metrics往往需要最少的资源来管理,因为它们的本质是“压缩”得很好。相反,**logging**往往是压倒性的,经常超过它报告的生产流量。tracking可能位于中间的某个位置。
+
+
\ No newline at end of file
diff --git a/_posts/2022-07-16-test-markdown.md b/_posts/2022-07-16-test-markdown.md
new file mode 100644
index 000000000000..a7a60e81c04f
--- /dev/null
+++ b/_posts/2022-07-16-test-markdown.md
@@ -0,0 +1,463 @@
+---
+layout: post
+title: 装饰器模式
+subtitle: 亦称: 装饰者模式、装饰器模式、Wrapper、Decorator
+tags: [设计模式]
+---
+# 装饰器模式
+
+亦称: 装饰者模式、装饰器模式、Wrapper、Decorator
+
+
+
+**装饰模式**是一种结构型设计模式, 允许通过将对象放入包含行为的特殊封装对象中来为原对象绑定新的行为。
+
+- 对象放入包含行为的特殊封装对象
+- 特殊封装对象有新的行为
+
+### 场景
+
+假设正在开发一个提供通知功能的库, 其他程序可使用它向用户发送关于重要事件的通知。
+
+库的最初版本基于 `通知器``Notifier`类, 其中只有很少的几个成员变量, 一个构造函数和一个 `send`发送方法。 该方法可以接收来自客户端的消息参数, 并将该消息发送给一系列的邮箱, 邮箱列表则是通过构造函数传递给通知器的。 作为客户端的第三方程序仅会创建和配置通知器对象一次, 然后在有重要事件发生时对其进行调用。此后某个时刻, 会发现库的用户希望使用除邮件通知之外的功能。 许多用户会希望接收关于紧急事件的手机短信, 还有些用户希望在微信上接收消息, 而公司用户则希望在 QQ 上接收消息。
+
+
+
+每种通知类型都将作为通知器的一个子类得以实现。
+
+这有什么难的呢? 首先扩展 `通知器`类, 然后在新的子类中加入额外的通知方法。 现在客户端要对所需通知形式的对应类进行初始化, 然后使用该类发送后续所有的通知消息。
+
+### 问题
+
+但是很快有人会问: “为什么不同时使用多种通知形式呢? 如果房子着火了, 大概会想在所有渠道中都收到相同的消息吧。”
+
+可以尝试创建一个特殊子类来将多种通知方法组合在一起以解决该问题。 但这种方式会使得代码量迅速膨胀, 不仅仅是程序库代码, 客户端代码也会如此。
+
+
+
+### 解决
+
+- 当需要更改一个对象的行为时, 第一个跳入脑海的想法就是扩展它所属的类。 但是, 不能忽视继承可能引发的几个严重问题。
+
+- 继承是静态的。 无法在运行时更改已有对象的行为, 只能使用由不同子类创建的对象来替代当前的整个对象。
+
+ 也就是说,不能更改`Wechat Notiifier`已有的行为,只能用`QQNotifier`来替换。
+
+ ```
+ var notifier = new Notifier
+ notifier = Wechat Notiifier
+ //要更改行为
+ notifier = QQ Notifier
+ ```
+
+- 子类只能有一个父类。 大部分编程语言不允许一个类同时继承多个类的行为。
+
+其中一种方法是用*聚合*或*组合* , 而不是*继承*。 两者的工作方式几乎一模一样: 一个对象*包含*指向另一个对象的引用, 并将部分工作委派给引用对象; 继承中的对象则继承了父类的行为, 它们自己*能够*完成这些工作。
+
+可以使用这个新方法来轻松替换各种连接的 “小帮手” 对象, 从而能在运行时改变容器的行为。 一个对象可以使用多个类的行为, 包含多个指向其他对象的引用, 并将各种工作委派给引用对象。 聚合 (或组合) 组合是许多设计模式背后的关键原则 (包括装饰在内)。 记住这一点后, 让我们继续关于模式的讨论。
+
+
+
+*封装器*是装饰模式的别称, 这个称谓明确地表达了该模式的主要思想。 “封装器” 是一个能与其他 “目标” 对象连接的对象。 封装器包含与目标对象相同的一系列方法(与被封装对象实现相同的接口), 它会将所有接收到的请求委派给目标对象。 但是, 封装器可以在将请求委派给目标前后对其进行处理, 所以可能会改变最终结果。
+
+那么什么时候一个简单的封装器可以被称为是真正的装饰呢? 正如之前提到的, 封装器实现了与其封装对象相同的接口。 因此从客户端的角度来看, 这些对象是完全一样的。 封装器中的引用成员变量可以是遵循相同接口的任意对象。 这使得可以将一个对象放入多个封装器中, 并在对象中添加所有这些封装器的组合行为。
+
+- **封装器实现了与其封装对象相同的接口。 **
+- **将请求委派给目标前后对其进行处理**
+- **封装器中的引用成员变量可以是遵循相同接口的任意对象。**
+- 一个对象放入多个封装器中, 并在对象中添加所有这些封装器的组合行为
+
+比如在消息通知示例中, 我们可以将简单邮件通知行为放在基类 `通知器`中, 但将所有其他通知方法放入装饰中。
+
+
+
+实际与客户端进行交互的对象将是最后一个进入栈中的装饰对象。 由于所有的装饰都实现了与通知基类相同的接口, 客户端的其他代码并不在意自己到底是与 “纯粹” 的通知器对象, 还是与装饰后的通知器对象进行交互。
+
+我们可以使用相同方法来完成其他行为 (例如设置消息格式或者创建接收人列表)。 只要所有装饰都遵循相同的接口, 客户端就可以使用任意自定义的装饰来装饰对象。
+
+
+
+穿衣服是使用装饰的一个例子。 觉得冷时, 可以穿一件毛衣。 如果穿毛衣还觉得冷, 可以再套上一件夹克。 如果遇到下雨, 还可以再穿一件雨衣。 所有这些衣物都 “扩展” 了的基本行为, 但它们并不是的一部分, 如果不再需要某件衣物, 可以方便地随时脱掉。
+
+- “扩展” 了的基本行为, 但它们并不是的一部分.
+
+### 结构
+
+
+
+1. **部件** (`Component`) 声明封装器和被封装对象的公用接口。
+2. **具体部件** (Concrete Component) 类是被封装对象所属的类。 它定义了基础行为, 但装饰类可以改变这些行为。
+3. **基础装饰** (`Base Decorator`) 类拥有一个指向被封装对象的引用成员变量。 该变量的类型应当被声明为通用部件接口, 这样它就可以引用具体的部件和装饰。 装饰基类会将所有操作委派给被封装的对象。
+4. **具体装饰类** (`Concrete Decorators`) 定义了可动态添加到部件的额外行为。 具体装饰类会重写装饰基类的方法, 并在调用父类方法之前或之后进行额外的行为。
+5. **客户端** (Client) 可以使用多层装饰来封装部件, 只要它能使用通用接口与所有对象互动即可。
+
+### 伪代码
+
+
+
+```
+// 装饰可以改变组件接口所定义的操作。
+interface DataSource is
+ method writeData(data)
+ method readData():data
+
+// 具体组件提供操作的默认实现。这些类在程序中可能会有几个变体。
+class FileDataSource implements DataSource is
+ constructor FileDataSource(filename) { ... }
+
+ method writeData(data) is
+ // 将数据写入文件。
+
+ method readData():data is
+ // 从文件读取数据。
+
+
+// 装饰基类和其他组件遵循相同的接口。该类的主要任务是定义所有具体装饰的封
+// 装接口。封装的默认实现代码中可能会包含一个保存被封装组件的成员变量,并
+// 且负责对其进行初始化。
+class DataSourceDecorator implements DataSource is
+ protected field wrappee: DataSource
+
+ constructor DataSourceDecorator(source: DataSource) is
+ wrappee = source
+
+ // 装饰基类会直接将所有工作分派给被封装组件。具体装饰中则可以新增一些
+ // 额外的行为。
+ method writeData(data) is
+ wrappee.writeData(data)
+
+ // 具体装饰可调用其父类的操作实现,而不是直接调用被封装对象。这种方式
+ // 可简化装饰类的扩展工作。
+ method readData():data is
+ return wrappee.readData()
+
+
+
+/ 具体装饰必须在被封装对象上调用方法,不过也可以自行在结果中添加一些内容。
+// 装饰必须在调用封装对象之前或之后执行额外的行为。
+class EncryptionDecorator extends DataSourceDecorator is
+ method writeData(data) is
+ // 1. 对传递数据进行加密。
+ // 2. 将加密后数据传递给被封装对象 writeData(写入数据)方法。
+
+ method readData():data is
+ // 1. 通过被封装对象的 readData(读取数据)方法获取数据。
+ // 2. 如果数据被加密就尝试解密。
+ // 3. 返回结果。
+
+ // 可以将对象封装在多层装饰中。
+class CompressionDecorator extends DataSourceDecorator is
+ method writeData(data) is
+ // 1. 压缩传递数据。
+ // 2. 将压缩后数据传递给被封装对象 writeData(写入数据)方法。
+
+ method readData():data is
+ // 1. 通过被封装对象的 readData(读取数据)方法获取数据。
+ // 2. 如果数据被压缩就尝试解压。
+ // 3. 返回结果。
+
+// 选项 1:装饰组件的简单示例
+class Application is
+ method dumbUsageExample() is
+ source = new FileDataSource("somefile.dat")
+ source.writeData(salaryRecords)
+ // 已将明码数据写入目标文件。
+
+ source = new CompressionDecorator(source)
+ source.writeData(salaryRecords)
+ // 已将压缩数据写入目标文件。
+
+ source = new EncryptionDecorator(source)
+ // 源变量中现在包含:
+ // Encryption > Compression > FileDataSource
+ source.writeData(salaryRecords)
+ // 已将压缩且加密的数据写入目标文件。
+
+// 选项 1:装饰组件的简单示例
+class Application is
+ method dumbUsageExample() is
+ source = new FileDataSource("somefile.dat")
+ source.writeData(salaryRecords)
+ // 已将明码数据写入目标文件。
+
+ source = new CompressionDecorator(source)
+ source.writeData(salaryRecords)
+ // 已将压缩数据写入目标文件。
+
+ source = new EncryptionDecorator(source)
+ // 源变量中现在包含:
+ // Encryption > Compression > FileDataSource
+ source.writeData(salaryRecords)
+ // 已将压缩且加密的数据写入目标文件。
+```
+
+```
+
+// 选项 2:客户端使用外部数据源。SalaryManager(工资管理器)对象并不关心
+// 数据如何存储。它们会与提前配置好的数据源进行交互,数据源则是通过程序配
+// 置器获取的。
+class SalaryManager is
+ field source: DataSource
+
+ constructor SalaryManager(source: DataSource) { ... }
+
+ method load() is
+ return source.readData()
+
+ method save() is
+ source.writeData(salaryRecords)
+ // ...其他有用的方法...
+
+
+// 程序可在运行时根据配置或环境组装不同的装饰堆桟。
+class ApplicationConfigurator is
+ method configurationExample() is
+ source = new FileDataSource("salary.dat")
+ if (enabledEncryption)
+ source = new EncryptionDecorator(source)
+ if (enabledCompression)
+ source = new CompressionDecorator(source)
+
+ logger = new SalaryManager(source)
+ salary = logger.load()
+ // ...
+```
+
+### 应用场景
+
+ 如果希望在无需修改代码的情况下即可使用对象, 且希望在运行时为对象新增额外的行为, 可以使用装饰模式。
+
+ 装饰能将业务逻辑组织为层次结构, 可为各层创建一个装饰, 在运行时将各种不同逻辑组合成对象。 由于这些对象都遵循通用接口, 客户端代码能以相同的方式使用这些对象。
+
+ 如果用继承来扩展对象行为的方案难以实现或者根本不可行, 可以使用该模式。
+
+ 许多编程语言使用 `final`最终关键字来限制对某个类的进一步扩展。 复用最终类已有行为的唯一方法是使用装饰模式: 用封装器对其进行封装。
+
+### 实现方式
+
+1. 确保业务逻辑可用一个基本组件及多个额外可选层次表示。
+2. 找出基本组件和可选层次的通用方法。 创建一个组件接口并在其中声明这些方法。
+3. 创建一个具体组件类, 并定义其基础行为。
+4. 创建装饰基类, 使用一个成员变量存储指向被封装对象的引用。 该成员变量必须被声明为组件接口类型, 从而能在运行时连接具体组件和装饰。 装饰基类必须将所有工作委派给被封装的对象。
+5. 确保所有类实现组件接口。
+6. 将装饰基类扩展为具体装饰。 具体装饰必须在调用父类方法 (总是委派给被封装对象) 之前或之后执行自身的行为。
+7. 客户端代码负责创建装饰并将其组合成客户端所需的形式。
+
+### go语言实现
+
+```
+package main
+import "fmt"
+
+type pizza interface {
+ getPrice() int
+}
+
+type veggeMania struct {
+}
+
+func (p *veggeMania) getPrice() int {
+ return 15
+}
+
+type tomatoTopping struct {
+ pizza pizza
+}
+func (c *tomatoTopping) getPrice() int {
+ pizzaPrice := c.pizza.getPrice()
+ return pizzaPrice + 7
+}
+
+type cheeseTopping struct {
+ pizza pizza
+}
+
+func (c *cheeseTopping) getPrice() int {
+ pizzaPrice := c.pizza.getPrice()
+ return pizzaPrice + 10
+}
+
+func main() {
+
+ pizza := &veggeMania{}
+
+ //Add cheese topping
+ pizzaWithCheese := &cheeseTopping{
+ pizza: pizza,
+ }
+
+ //Add tomato topping
+ pizzaWithCheeseAndTomato := &tomatoTopping{
+ pizza: pizzaWithCheese,
+ }
+
+ fmt.Printf("Price of veggeMania with tomato and cheese topping is %d\n", pizzaWithCheeseAndTomato.getPrice())
+}
+```
+
+```
+package main
+
+import (
+ "fmt"
+ "github.com/gin-gonic/gin"
+)
+
+//数据类
+type Data struct {
+ filePath string
+ fileName string
+ fileContent string
+}
+
+type DataTransport interface {
+ //客户端从服务端获取到数据
+ ReadData(c *gin.Context)
+ //客户端的数据写入服务端
+ WriteData(c *gin.Context)
+}
+
+//具体组件提供操作的默认实现。
+type ConcreteComponents struct {
+}
+
+func (con *ConcreteComponents) ReadData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+ c.JSON(200, gin.H{
+ "data": d,
+ })
+
+}
+func (con *ConcreteComponents) WriteData(c *gin.Context) {
+ //从客户端获得数据
+ var data Data
+ err := c.ShouldBindQuery(&data)
+ if err != nil {
+ c.JSON(400, gin.H{
+ "err": "something wrong ",
+ })
+ return
+ } else {
+ //写入数据库
+ c.JSON(200, gin.H{
+ "data": "data has write in DB",
+ })
+ }
+}
+
+//具体组件提供操作的默认实现。
+type EncryptAndDecryptDecorator struct {
+}
+
+func (con *EncryptAndDecryptDecorator) ReadData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+
+ c.JSON(200, gin.H{
+ //解密
+ "msg": "data has been Decrypt",
+ "data": d,
+ })
+
+}
+func (con *EncryptAndDecryptDecorator) WriteData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+ c.JSON(200, gin.H{
+ //加密
+ "msg": "Encrypted has write in DB ",
+ "data": d,
+ })
+}
+
+//装饰基类和其他组件遵循相同的接口。该类的主要任务是定义所有具体装饰的封装接口。封装的默认实现代码中可能会包含一个保存被封装组件的成员变量,并且负责对其进行初始化。
+type DecorativeBase struct {
+ //保存了默认的行为,在默认的行为上面可以增加其他的操作,而不会更改任何原来的默认行为
+ //我这里只能把wrappee定义为接口类型,不能是定义 ConcreteComponents 结构体类型。
+ //因为如果是结构体类型,那么我DecorativeBase调用ReadData()和)WriteData()方法时,就调用的是默认的行为,不能增加新的行为。
+ //wrappee *ConcreteComponents 不可以
+ wrappee DataTransport
+}
+
+//装饰器当然也要实现 DataTransport 这个接口,因为它只有和 ConcreteComponents看起来一样(对于客户端而言)才能在已经有的行为上绑定新的行为,装饰器要做的就是把工作委派给ConcreteComponents
+func (d *DecorativeBase) ReadData(c *gin.Context) {
+ d.wrappee.ReadData(c)
+}
+
+func (d *DecorativeBase) WriteData(c *gin.Context) {
+ d.wrappee.WriteData(c)
+}
+
+//新的行为2 压缩和解压缩
+type ZipAndUnZipDecorator struct {
+}
+
+func (e *ZipAndUnZipDecorator) ReadData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+
+ c.JSON(200, gin.H{
+ //解密
+ "msg": "data has been Zip",
+ "data": d,
+ })
+
+}
+func (e *ZipAndUnZipDecorator) WriteData(c *gin.Context) {
+ //从数据库取得数据的一系列操作
+ d := Data{
+ filePath: "Home/user/local",
+ fileName: "test.go",
+ fileContent: "Hello world",
+ }
+
+ c.JSON(200, gin.H{
+ //解密
+ "msg": "data has been Uzip",
+ "data", d,
+ })
+
+}
+func main() {
+ g := gin.New()
+
+ //模拟用户端进行装饰的需求
+ input := 0
+ fmt.Scanf("%d", &input)
+ d := DecorativeBase{}
+
+ if input == 1 {
+ //加密解密行为
+ d.wrappee = &EncryptAndDecryptDecorator{}
+
+ }
+ if input == 2 {
+ d.wrappee = &ZipAndUnZipDecorator{}
+
+ }
+
+ g.POST("/read", d.ReadData)
+ g.POST("/write", d.WriteData)
+ g.Run()
+
+}
+
+```
+
diff --git a/_posts/2022-07-17-test-markdown.md b/_posts/2022-07-17-test-markdown.md
new file mode 100644
index 000000000000..4a828e1068b5
--- /dev/null
+++ b/_posts/2022-07-17-test-markdown.md
@@ -0,0 +1,296 @@
+---
+layout: post
+title: 外观模式
+subtitle: 亦称: Facade
+tags: [设计模式]
+---
+# 外观模式
+
+**亦称:** Facade
+
+**外观模式**是一种结构型设计模式, 能为程序库、 框架或其他复杂类提供一个简单的接口。
+
+### 问题:
+
+假设必须在代码中使用某个复杂的库或框架中的众多对象。 正常情况下, 需要负责所有对象的初始化工作、 管理其依赖关系并按正确的顺序执行方法等。
+
+最终, 程序中类的业务逻辑将与第三方类的实现细节紧密耦合, 使得理解和维护代码的工作很难进行。
+
+### 解决:
+
+外观类为包含许多活动部件的复杂子系统提供一个简单的接口。 与直接调用子系统相比, 外观提供的功能可能比较有限, 但它却包含了客户端真正关心的功能。
+
+例如, 上传猫咪搞笑短视频到社交媒体网站的应用可能会用到专业的视频转换库, 但它只需使用一个包含 `encode(filename, format)`方法 (以文件名与文件格式为参数进行编码的方法) 的类即可。 在创建这个类并将其连接到视频转换库后, 就拥有了自己的第一个外观。
+
+
+
+当通过电话给商店下达订单时, 接线员就是该商店的所有服务和部门的外观。 接线员为提供了一个同购物系统、 支付网关和各种送货服务进行互动的简单语音接口。
+
+
+
+### 外观模式结构
+
+
+
+**外观** (Facade) 提供了一种访问特定子系统功能的便捷方式, 其了解如何重定向客户端请求, 知晓如何操作一切活动部件。
+
+创建**附加外观** (Additional Facade) 类可以避免多种不相关的功能污染单一外观, 使其变成又一个复杂结构。 客户端和其他外观都可使用附加外观。
+
+**复杂子系统** (Complex Subsystem) 由数十个不同对象构成。 如果要用这些对象完成有意义的工作, 必须深入了解子系统的实现细节, 比如按照正确顺序初始化对象和为其提供正确格式的数据。
+
+子系统类不会意识到外观的存在, 它们在系统内运作并且相互之间可直接进行交互。
+
+**客户端** (Client) 使用外观代替对子系统对象的直接调用。
+
+
+
+使用单个外观类隔离多重依赖的示例
+
+可以创建一个封装所需功能并隐藏其他代码的外观类, 从而无需使全部代码直接与数十个框架类进行交互。 该结构还能将未来框架升级或更换所造成的影响最小化, 因为只需修改程序中外观方法的实现即可。
+
+```
+// 这里有复杂第三方视频转换框架中的一些类。我们不知晓其中的代码,因此无法
+// 对其进行简化
+class VideoFile
+// ...
+
+class OggCompressionCodec
+// ...
+
+class MPEG4CompressionCodec
+// ...
+
+class CodecFactory
+// ...
+
+class BitrateReader
+// ...
+
+class AudioMixer
+
+// 为了将框架的复杂性隐藏在一个简单接口背后,我们创建了一个外观类。它是在
+// 功能性和简洁性之间做出的权衡。
+class VideoConverter is
+ method convert(filename, format):File is
+ file = new VideoFile(filename)
+ sourceCodec = new CodecFactory.extract(file)
+ if (format == "mp4")
+ destinationCodec = new MPEG4CompressionCodec()
+ else
+ destinationCodec = new OggCompressionCodec()
+ buffer = BitrateReader.read(filename, sourceCodec)
+ result = BitrateReader.convert(buffer, destinationCodec)
+ result = (new AudioMixer()).fix(result)
+ return new File(result)
+
+// 应用程序的类并不依赖于复杂框架中成千上万的类。同样,如果决定更换框架,
+// 那只需重写外观类即可。
+class Application is
+ method main() is
+ convertor = new VideoConverter()
+ mp4 = convertor.convert("funny-cats-video.ogg", "mp4")
+ mp4.save()
+```
+
+### 适合场景
+
+- **如果需要一个指向复杂子系统的直接接口****,** **且该接口的功能有限****,** **则可以使用外观模式****。
+- **如果需要将子系统组织为多层结构****,** **可以使用外观****。**
+- 创建外观来定义子系统中各层次的入口。 可以要求子系统仅使用外观来进行交互, 以减少子系统之间的耦合。
+- 让我们回到视频转换框架的例子。 该框架可以拆分为两个层次: 音频相关和视频相关。 可以为每个层次创建一个外观, 然后要求各层的类必须通过这些外观进行交互。 这种方式看上去与[中介者]模式非常相似。
+
+### 实现方式
+
+- 考虑能否在现有子系统的基础上提供一个更简单的接口。 如果该接口能让客户端代码独立于众多子系统类, 那么的方向就是正确的。
+- 在一个新的外观类中声明并实现该接口。 外观应将客户端代码的调用重定向到子系统中的相应对象处。 如果客户端代码没有对子系统进行初始化, 也没有对其后续生命周期进行管理, 那么外观必须完成此类工作。
+- 如果要充分发挥这一模式的优势, 必须确保所有客户端代码仅通过外观来与子系统进行交互。 此后客户端代码将不会受到任何由子系统代码修改而造成的影响, 比如子系统升级后, 只需修改外观中的代码即可。
+- 如果外观变得过于臃肿 可以考虑将其部分行为抽取为一个新的专用外观类。
+
+### 与其他模式的关系
+
+- 外观模式为现有对象定义了一个新接口, 适配器模式]则会试图运用已有的接口。 *适配器*通常只封装一个对象, *外观*通常会作用于整个对象子系统上。
+- 当只需对客户端代码隐藏子系统创建对象的方式时, 可以使用抽象工厂模式来代替外观
+- 享元模式展示了如何生成大量的小型对象, 外观]则展示了如何用一个对象来代表整个子系统。
+- 外观和中介者的职责类似: 它们都尝试在大量紧密耦合的类中组织起合作。
+ - *外观*为子系统中的所有对象定义了一个简单接口, 但是它不提供任何新功能。 子系统本身不会意识到外观的存在。 子系统中的对象可以直接进行交流。
+ - *中介者*将系统中组件的沟通行为中心化。 各组件只知道中介者对象, 无法直接相互交流。
+
+- [外观]类通常可以转换为单例模类, 因为在大部分情况下一个外观对象就足够了。
+
+### go语言实现
+
+人们很容易低估使用信用卡订购披萨时幕后工作的复杂程度。 在整个过程中会有不少的子系统发挥作用。 下面是其中的一部分:
+
+- 检查账户
+- 检查安全码
+- 借记/贷记余额
+- 账簿录入
+- 发送消息通知
+
+在如此复杂的系统中, 可以说是一步错步步错, 很容易就会引发大的问题。 这就是为什么我们需要外观模式, 让客户端可以使用一个简单的接口来处理众多组件。 客户端只需要输入卡片详情、 安全码、 支付金额以及操作类型即可。 外观模式会与多种组件进一步地进行沟通, 而又不会向客户端暴露其内部的复杂性。
+
+```
+package main
+
+import (
+ "fmt"
+ "log"
+)
+
+//复杂子系统1--检查账户
+type account struct {
+ name string
+}
+
+func newAccount(accountName string) *account {
+ return &account{
+ name: accountName,
+ }
+}
+
+func (a *account) checkAccount(accountName string) error {
+ if a.name != accountName {
+ return fmt.Errorf("Account Name is incorrect")
+ }
+ fmt.Println("Account Verified")
+ return nil
+}
+
+//复杂子系统2--检查安全码
+type securityCode struct {
+ code int
+}
+
+func newSecurityCode(code int) *securityCode {
+ return &securityCode{
+ code: code,
+ }
+}
+
+func (s *securityCode) checkCode(incomingCode int) error {
+ if s.code != incomingCode {
+ return fmt.Errorf("Security Code is incorrect")
+ }
+ fmt.Println("SecurityCode Verified")
+ return nil
+}
+
+//复杂子系统3--借记/贷记余额
+type wallet struct {
+ balance int
+}
+
+func newWallet() *wallet {
+ return &wallet{
+ balance: 0,
+ }
+}
+
+func (w *wallet) creditBalance(amount int) {
+ w.balance += amount
+ fmt.Println("Wallet balance added successfully")
+ return
+}
+
+func (w *wallet) debitBalance(amount int) error {
+ if w.balance < amount {
+ return fmt.Errorf("Balance is not sufficient")
+ }
+ fmt.Println("Wallet balance is Sufficient")
+ w.balance = w.balance - amount
+ return nil
+}
+
+//复杂子系统4--账簿录入
+type ledger struct {
+}
+
+func (s *ledger) makeEntry(accountID, txnType string, amount int) {
+ fmt.Printf("Make ledger entry for accountId %s with txnType %s for amount %d\n", accountID, txnType, amount)
+ return
+}
+
+//复杂子系统5--发送消息通知
+type notification struct {
+}
+
+func (n *notification) sendWalletCreditNotification() {
+ fmt.Println("Sending wallet credit notification")
+}
+
+func (n *notification) sendWalletDebitNotification() {
+ fmt.Println("Sending wallet debit notification")
+}
+
+//外观模式类
+type walletFacade struct {
+ account *account
+ wallet *wallet
+ securityCode *securityCode
+ notification *notification
+ ledger *ledger
+}
+
+func newWalletFacade(accountID string, code int) *walletFacade {
+ fmt.Println("Starting create account")
+ walletFacacde := &walletFacade{
+ account: newAccount(accountID),
+ securityCode: newSecurityCode(code),
+ wallet: newWallet(),
+ notification: ¬ification{},
+ ledger: &ledger{},
+ }
+ fmt.Println("Account created")
+ return walletFacacde
+}
+func (w *walletFacade) addMoneyToWallet(accountID string, securityCode int, amount int) error {
+ fmt.Println("Starting add money to wallet")
+ err := w.account.checkAccount(accountID)
+ if err != nil {
+ return err
+ }
+ err = w.securityCode.checkCode(securityCode)
+ if err != nil {
+ return err
+ }
+ w.wallet.creditBalance(amount)
+ w.notification.sendWalletCreditNotification()
+ w.ledger.makeEntry(accountID, "credit", amount)
+ return nil
+}
+func (w *walletFacade) deductMoneyFromWallet(accountID string, securityCode int, amount int) error {
+ fmt.Println("Starting debit money from wallet")
+ err := w.account.checkAccount(accountID)
+ if err != nil {
+ return err
+ }
+
+ err = w.securityCode.checkCode(securityCode)
+ if err != nil {
+ return err
+ }
+ err = w.wallet.debitBalance(amount)
+ if err != nil {
+ return err
+ }
+ w.notification.sendWalletDebitNotification()
+ w.ledger.makeEntry(accountID, "credit", amount)
+ return nil
+}
+
+func main() {
+ walletFacade := newWalletFacade("abc", 1234)
+ err := walletFacade.addMoneyToWallet("abc", 1234, 10)
+ if err != nil {
+ log.Fatalf("Error: %s\n", err.Error())
+ }
+ fmt.Println()
+ err = walletFacade.deductMoneyFromWallet("abc", 1234, 5)
+ if err != nil {
+ log.Fatalf("Error: %s\n", err.Error())
+ }
+
+}
+
+```
+
diff --git a/_posts/2022-07-18-test-markdown.md b/_posts/2022-07-18-test-markdown.md
new file mode 100644
index 000000000000..fc2758db210b
--- /dev/null
+++ b/_posts/2022-07-18-test-markdown.md
@@ -0,0 +1,433 @@
+---
+layout: post
+title: 责任链模式
+subtitle: 亦称: 职责链模式、命令链、CoR、Chain of Command、Chain of Responsibility
+tags: [设计模式]
+---
+
+# 责任链模式
+
+亦称: 职责链模式、命令链、CoR、Chain of Command、Chain of Responsibility
+
+
+
+### 目的:
+
+**责任链模式**是一种行为设计模式, 允许将请求沿着处理者链进行发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
+
+### 问题:
+
+假如正在开发一个在线订购系统。 希望对系统访问进行限制, 只允许认证用户创建订单。 此外, 拥有管理权限的用户也拥有所有订单的完全访问权限。
+
+简单规划后, 会意识到这些检查必须依次进行。 只要接收到包含用户凭据的请求, 应用程序就可尝试对进入系统的用户进行认证。 但如果由于用户凭据不正确而导致认证失败, 那就没有必要进行后续检查了。
+
+在接下来的几个月里, 实现了后续的几个检查步骤。
+
+- 一位同事认为直接将原始数据传递给订购系统存在安全隐患。 因此新增了额外的验证步骤来清理请求中的数据。
+- 过了一段时间, 有人注意到系统无法抵御暴力密码破解方式的攻击。 为了防范这种情况, 立刻添加了一个检查步骤来过滤来自同一 IP 地址的重复错误请求。
+- 又有人提议可以对包含同样数据的重复请求返回缓存中的结果, 从而提高系统响应速度。 因此, 新增了一个检查步骤, 确保只有没有满足条件的缓存结果时请求才能通过并被发送给系统。
+
+
+
+检查代码本来就已经混乱不堪, 而每次新增功能都会使其更加臃肿。 修改某个检查步骤有时会影响其他的检查步骤。 最糟糕的是, 当希望复用这些检查步骤来保护其他系统组件时, 只能复制部分代码, 因为这些组件只需部分而非全部的检查步骤。
+
+系统会变得让人非常费解, 而且其维护成本也会激增。 在艰难地和这些代码共处一段时间后, 有一天终于决定对整个系统进行重构。
+
+### 解决:
+
+与许多其他行为设计模式一样, **责任链**会将特定行为转换为被称作*处理者*的独立对象。 在上述示例中, 每个检查步骤都可被抽取为仅有单个方法的类, 并执行检查操作。 请求及其数据则会被作为参数传递给该方法。
+
+模式建议将这些处理者连成一条链。 链上的每个处理者都有一个成员变量来保存对于下一处理者的引用。 除了处理请求外, 处理者还负责沿着链传递请求。 请求会在链上移动, 直至所有处理者都有机会对其进行处理。
+
+最重要的是: 处理者可以决定不再沿着链传递请求, 这可高效地取消所有后续处理步骤。
+
+- 每个检查步骤都可被抽取为仅有单个方法的类, 并执行检查操作。
+- 请求及其数据则会被作为参数传递给该方法。
+- 每个处理者都有一个成员变量来保存对于下一处理者的引用。
+- 除了处理请求外, 处理者还负责沿着链传递请求。 请求会在链上移动。
+
+在我们的订购系统示例中, 处理者会在进行请求处理工作后决定是否继续沿着链传递请求。 如果请求中包含正确的数据, 所有处理者都将执行自己的主要行为, 无论该行为是身份验证还是数据缓存。
+
+
+
+不过还有一种稍微不同的方式 (也是更经典一种), 那就是处理者接收到请求后自行决定是否能够对其进行处理。 如果自己能够处理, 处理者就不再继续传递请求。 因此在这种情况下, 每个请求要么最多有一个处理者对其进行处理, 要么没有任何处理者对其进行处理。 在处理图形用户界面元素栈中的事件时, 这种方式非常常见。
+
+例如, 当用户点击按钮时, 按钮产生的事件将沿着 GUI 元素链进行传递, 最开始是按钮的容器 (如窗体或面板), 直至应用程序主窗口。 链上第一个能处理该事件的元素会对其进行处理。 此外, 该例还有另一个值得我们关注的地方: 它表明我们总能从对象树中抽取出链来。
+
+
+
+所有处理者类均实现同一接口是关键所在。 每个具体处理者仅关心下一个包含 `execute`执行方法的处理者。 这样一来, 就可以在运行时使用不同的处理者来创建链, 而无需将相关代码与处理者的具体类进行耦合。
+
+- 使用不同的处理者来创建链。
+- 所有处理者类均实现同一接口。
+- 具体处理者仅关心下一个包含 `execute`执行方法的处理者。
+
+
+
+最近, 刚为自己的电脑购买并安装了一个新的硬件设备。 身为一名极客, 显然在电脑上安装了多个操作系统, 所以会试着启动所有操作系统来确认其是否支持新的硬件设备。 Windows 检测到了该硬件设备并对其进行了自动启用。 但是喜爱的 Linux 系统并不支持新硬件设备。 抱着最后一点希望, 决定拨打包装盒上的技术支持电话。
+
+首先会听到自动回复器的机器合成语音, 它提供了针对各种问题的九个常用解决方案, 但其中没有一个与遇到的问题相关。 过了一会儿, 机器人将转接到人工接听人员处。
+
+这位接听人员同样无法提供任何具体的解决方案。 他不断地引用手册中冗长的内容, 并不会仔细聆听的回应。 在第 10 次听到 “是否关闭计算机后重新启动呢?” 这句话后, 要求与一位真正的工程师通话。
+
+最后, 接听人员将的电话转接给了工程师, 他或许正缩在某幢办公大楼的阴暗地下室中, 坐在他所深爱的服务器机房里, 焦躁不安地期待着同一名真人交流。 工程师告诉了新硬件设备驱动程序的下载网址, 以及如何在 Linux 系统上进行安装。 问题终于解决了! 挂断了电话, 满心欢喜。
+
+### 模式结构:
+
+
+
+- **处理者** (Handler) 声明了所有具体处理者的通用接口。 该接口通常仅包含单个方法用于请求处理, 但有时其还会包含一个设置链上下个处理者的方法。
+
+- **基础处理者** (Base Handler) 是一个可选的类, 可以将所有处理者共用的样本代码放置在其中。
+
+ 通常情况下, 该类中定义了一个保存对于下个处理者引用的成员变量。 客户端可通过将处理者传递给上个处理者的构造函数或设定方法来创建链。 该类还可以实现默认的处理行为: 确定下个处理者存在后再将请求传递给它。
+
+- **具体处理者** (Concrete Handlers) 包含处理请求的实际代码。 每个处理者接收到请求后, 都必须决定是否进行处理, 以及是否沿着链传递请求。
+- 处理者通常是独立且不可变的, 需要通过构造函数一次性地获得所有必要地数据。
+- **客户端** (Client) 可根据程序逻辑一次性或者动态地生成链。 值得注意的是, 请求可发送给链上的任意一个处理者, 而非必须是第一个处理者。
+
+应用程序的 GUI 通常为对象树结构。 例如, 负责渲染程序主窗口的 `对话框`类就是对象树的根节点。 对话框包含 `面板` , 而面板可能包含其他面板, 或是 `按钮`和 `文本框`等下层元素。
+
+只要给一个简单的组件指定帮助文本, 它就可显示简短的上下文提示。 但更复杂的组件可自定义上下文帮助文本的显示方式, 例如显示手册摘录内容或在浏览器中打开一个网页。
+
+```
+// 处理者接口声明了一个创建处理者链的方法。还声明了一个执行请求的方法。
+interface ComponentWithContextualHelp is
+ method showHelp()
+
+
+// 简单组件的基础类。
+abstract class Component implements ComponentWithContextualHelp is
+ field tooltipText: string
+
+ // 组件容器在处理者链中作为“下一个”链接。
+ protected field container: Container
+
+ // 如果组件设定了帮助文字,那它将会显示提示信息。如果组件没有帮助文字
+ // 且其容器存在,那它会将调用传递给容器。
+ method showHelp() is
+ if (tooltipText != null)
+ // 显示提示信息。
+ else
+ container.showHelp()
+
+
+// 容器可以将简单组件和其他容器作为其子项目。链关系将在这里建立。该类将从
+// 其父类处继承 showHelp(显示帮助)的行为。
+abstract class Container extends Component is
+ protected field children: array of Component
+
+ method add(child) is
+ children.add(child)
+ child.container = this
+
+
+// 客户端代码。
+class Application is
+ // 每个程序都能以不同方式对链进行配置。
+ method createUI() is
+ dialog = new Dialog("预算报告")
+ dialog.wikiPageURL = "http://..."
+ panel = new Panel(0, 0, 400, 800)
+ panel.modalHelpText = "本面板用于..."
+ ok = new Button(250, 760, 50, 20, "确认")
+ ok.tooltipText = "这是一个确认按钮..."
+ cancel = new Button(320, 760, 50, 20, "取消")
+ // ...
+ panel.add(ok)
+ panel.add(cancel)
+ dialog.add(panel)
+
+ // 想象这里会发生什么。
+ method onF1KeyPress() is
+ component = this.getComponentAtMouseCoords()
+ component.showHelp()
+```
+
+### 实现:
+
+- 声明处理者接口并描述请求处理方法的签名。
+
+ 确定客户端如何将请求数据传递给方法。 最灵活的方式是将请求转换为对象, 然后将其以参数的形式传递给处理函数。
+
+- 为了在具体处理者中消除重复的样本代码, 可以根据处理者接口创建抽象处理者基类。
+
+ 该类需要有一个成员变量来存储指向链上下个处理者的引用。 可以将其设置为不可变类。 但如果打算在运行时对链进行改变, 则需要定义一个设定方法来修改引用成员变量的值。
+
+ 为了使用方便, 还可以实现处理方法的默认行为。 如果还有剩余对象, 该方法会将请求传递给下个对象。 具体处理者还能够通过调用父对象的方法来使用这一行为。
+
+- 依次创建具体处理者子类并实现其处理方法。 每个处理者在接收到请求后都必须做出两个决定:
+
+ - 是否自行处理这个请求。
+ - 是否将该请求沿着链进行传递。
+
+- 客户端可以自行组装链, 或者从其他对象处获得预先组装好的链。 在后一种情况下, 必须实现工厂类以根据配置或环境设置来创建链。
+- 客户端可以触发链中的任意处理者, 而不仅仅是第一个。 请求将通过链进行传递, 直至某个处理者拒绝继续传递, 或者请求到达链尾。
+- 由于链的动态性, 客户端需要准备好处理以下情况:
+ - 链中可能只有单个链接。
+ - 部分请求可能无法到达链尾。
+ - 其他请求可能直到链尾都未被处理。
+
+### go语言实现
+
+让我们来看看一个医院应用的责任链模式例子。 医院中会有多个部门, 如:
+
+- 前台
+- 医生
+- 药房
+- 收银
+- 病人来访时, 他们首先都会去前台, 然后是看医生、 取药, 最后结账。 也就是说, 病人需要通过一条部门链, 每个部门都在完成其职能后将病人进一步沿着链条输送。
+- 此模式适用于有多个候选选项处理相同请求的情形, 适用于不希望客户端选择接收者 (因为多个对象都可处理请求) 的情形, 还适用于想将客户端同接收者解耦时。 客户端只需要链中的首个元素即可。
+
+```
+package main
+
+import (
+ "fmt"
+)
+
+//数据类
+type Context struct {
+ data map[string]string
+}
+
+func (c *Context) Get(str string) string {
+ k, ok := c.data[str]
+ if ok {
+ return k
+ }
+ return ""
+}
+
+func (c *Context) Set(key string, value string) {
+ c.data[key] = value
+}
+
+//处理者统一实现的接口
+type HandlerInterface interface {
+ Handle(c Context)
+ SetNext(HandlerInterface)
+}
+
+//处理者1
+type Reception struct {
+ nextHandler HandlerInterface
+}
+
+func (r *Reception) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+func (r *Reception) Handle(c Context) {
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "Doctor")
+ fmt.Println("Reception has handle over")
+ r.SetNext(&Doctor{})
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+
+//处理者2
+type Doctor struct {
+ nextHandler HandlerInterface
+}
+
+func (r *Doctor) Handle(c Context) {
+
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "Medical")
+ fmt.Println("Reception has handle over")
+ r.SetNext(&Medical{})
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+func (r *Doctor) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+
+//处理者3
+type Medical struct {
+ nextHandler HandlerInterface
+}
+
+func (r *Medical) Handle(c Context) {
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "CheckoutCounter")
+ fmt.Println("Reception has handle over")
+ r.SetNext(&CheckoutCounter{})
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+func (r *Medical) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+
+//处理者4
+type CheckoutCounter struct {
+ nextHandler HandlerInterface
+}
+
+func (r *CheckoutCounter) Handle(c Context) {
+ //数据处理
+ fmt.Println("data is", c.Get("need"))
+ c.Set("need", "CheckoutCounter")
+ fmt.Println("Reception has handle over")
+ if r.nextHandler != nil {
+ r.nextHandler.Handle(c)
+ } else {
+ fmt.Print("over")
+ }
+
+}
+
+func (r *CheckoutCounter) SetNext(h HandlerInterface) {
+ r.nextHandler = h
+}
+
+func main() {
+ c := Context{
+ make(map[string]string),
+ }
+ //need -挂号看病 seeDoctor need -复诊FollowUp need -缴费 PayFee
+ c.data["need"] = "seeDoctor"
+
+ r := Reception{}
+ r.Handle(c)
+
+}
+
+```
+
+```
+package main
+
+import "fmt"
+
+//数据
+type patient struct {
+ name string
+ registrationDone bool
+ doctorCheckUpDone bool
+ medicineDone bool
+ paymentDone bool
+}
+
+//接口
+type department interface {
+ execute(*patient)
+ setNext(department)
+}
+
+//处理者1
+type reception struct {
+ next department
+}
+
+func (r *reception) execute(p *patient) {
+ if p.registrationDone {
+ fmt.Println("Patient registration already done")
+ r.next.execute(p)
+ return
+ }
+ fmt.Println("Reception registering patient")
+ p.registrationDone = true
+ r.next.execute(p)
+}
+
+func (r *reception) setNext(next department) {
+ r.next = next
+}
+
+//处理者2
+type doctor struct {
+ next department
+}
+
+func (d *doctor) execute(p *patient) {
+ if p.doctorCheckUpDone {
+ fmt.Println("Doctor checkup already done")
+ d.next.execute(p)
+ return
+ }
+ fmt.Println("Doctor checking patient")
+ p.doctorCheckUpDone = true
+ d.next.execute(p)
+}
+
+func (d *doctor) setNext(next department) {
+ d.next = next
+}
+
+//处理者3
+type medical struct {
+ next department
+}
+
+func (m *medical) execute(p *patient) {
+ if p.medicineDone {
+ fmt.Println("Medicine already given to patient")
+ m.next.execute(p)
+ return
+ }
+ fmt.Println("Medical giving medicine to patient")
+ p.medicineDone = true
+ m.next.execute(p)
+}
+
+func (m *medical) setNext(next department) {
+ m.next = next
+}
+
+//处理者4
+type cashier struct {
+ next department
+}
+
+func (c *cashier) execute(p *patient) {
+ if p.paymentDone {
+ fmt.Println("Payment Done")
+ }
+ fmt.Println("Cashier getting money from patient patient")
+}
+
+func (c *cashier) setNext(next department) {
+ c.next = next
+}
+
+func main() {
+
+ cashier := &cashier{}
+
+ //Set next for medical department
+ medical := &medical{}
+ medical.setNext(cashier)
+
+ //Set next for doctor department
+ doctor := &doctor{}
+ doctor.setNext(medical)
+
+ //Set next for reception department
+ reception := &reception{}
+ reception.setNext(doctor)
+
+ patient := &patient{name: "abc"}
+ //Patient visiting
+ reception.execute(patient)
+}
+
+```
+
diff --git a/_posts/2022-07-20-test-markdown.md b/_posts/2022-07-20-test-markdown.md
new file mode 100644
index 000000000000..ea875a6a1aef
--- /dev/null
+++ b/_posts/2022-07-20-test-markdown.md
@@ -0,0 +1,60 @@
+---
+layout: post
+title: 从Mosn 源码到dubbo-go-pixiu 源码
+subtitle: 七层负载均衡
+tags: [开源]
+---
+
+# 从Mosn 源码到dubbo-go-pixiu 源码
+
+## 七层负载均衡
+
+> 客户端建立一个到负载均衡 器的 TCP 连接。负载均衡器**终结该连接**(即直接响应 SYN),然后选择一个后端,并与该后端建立一个新的 TCP 连接(即发送一个新的 SYN)。四层负载均衡器通常只在四层 `TCP/UDP` 连接/会话级别上运行。因此, 负载均衡器通过转发数据,并确保来自同一会话的字节在同一后端结束。四层负载均衡器 不知道它正在转发数据的任何应用程序细节。数据内容可以是 `HTTP`, `Redis`, `MongoDB`,或任 何应用协议。
+>
+> 四层负载均衡有哪些缺点是七层(应用)负载均衡来解决的呢? 假如两个 `gRPC/HTTP2` 客户端通过四层负载均衡器连接想要与一个后端通信。四层负载均衡器为每个入站 TCP 连接创建一个出站的 TCP 连接,从而产生两个入站和两个出站的连接(CA ==> `loadbalancer` ==> SA, CB ==> `loadbalancer` ==> SB)。假设,客户端 A 每分钟发送 1 个请求,而客户端 B 每秒发送 50 个请求,则SA 的负载是 SB的 50倍。所以四层负载均衡器问题随着时 间的推移变得越来越不均衡。
+
+
+
+上图 显示了一个七层 HTTP/2 负载均衡器。客户端创建一个到负载均衡器的HTTP/2 TCP 连接。负载均衡器创建连接到两个后端。当客户端向负载均衡器发送两个HTTP/2 流时,流 1 被发送到后端 1,流 2 被发送到后端 2。因此,即使请求负载有很大差 异的客户端也会在后端之间实现高效地分发。这就是为什么七层负载均衡对现代协议如此 重要的原因。对于`mosn`来说,还支持协议转换,比如client `mosn` 之间是`http`,`mosn` 与server 之间是 `grpc` 协议。
+
+## 初始化和启动
+
+```
+// mosn.io/mosn/pkg/mosn/starter.go
+type Mosn struct {
+ servers []server.Server
+ clustermanager types.ClusterManager
+ routerManager types.RouterManager
+ config *v2.MOSNConfig
+ adminServer admin.Server
+ xdsClient *xds.Client
+ wg sync.WaitGroup
+ // for smooth upgrade. reconfigure
+ inheritListeners []net.Listener
+ reconfigure net.Conn
+}
+
+
+```
+
+```
+//dubbo-go-pixiu/pkg/server/pixiu_start.go
+// PX is Pixiu start struct
+type Server struct {
+ startWG sync.WaitGroup
+
+ listenerManager *ListenerManager
+ clusterManager *ClusterManager
+ adapterManager *AdapterManager
+ // routerManager and apiConfigManager are duplicate, because route and dubbo-protocol api_config are a bit repetitive
+ routerManager *RouterManager
+ apiConfigManager *ApiConfigManager
+ dynamicResourceManger DynamicResourceManager
+ traceDriverManager *tracing.TraceDriverManager
+}
+```
+
+- `clustermanager` 顾名思义就是集群管理器。 `types.ClusterManager` 也是接口类型。这里的 cluster 指得是 `MOSN` 连接到的一组逻辑上相似的上游主机。`MOSN` 通过服务发现来发现集群中的成员,并通过主动运行状况检查来确定集群成员的健康状况。`MOSN` 如何将请求路由到集群成员由负载均衡策略确定。
+- `routerManager` 是路由管理器,`MOSN` 根据路由规则来对请求进行代理。
+
+### 初始化
\ No newline at end of file
diff --git a/_posts/2022-07-21-test-markdown.md b/_posts/2022-07-21-test-markdown.md
new file mode 100644
index 000000000000..766b242a015d
--- /dev/null
+++ b/_posts/2022-07-21-test-markdown.md
@@ -0,0 +1,233 @@
+---
+layout: post
+title: 通过Exporter收集指标
+subtitle: 自定义Exporter收集指标
+tags: [Microservices gateway]
+---
+
+# 通过Exporter收集指标
+
+### Exporter介绍
+
+Exporter 是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,它负责从目标系统(Your 服务)搜集数据,并将其转化为 Prometheus 支持的格式。Prometheus 会周期性地调用 Exporter 提供的 metrics 数据接口来获取数据。那么使用 Exporter 的好处是什么?举例来说,如果要监控 Mysql/Redis 等数据库,我们必须要调用它们的接口来获取信息(前提要有),这样每家都有一套接口,这样非常不通用。所以 Prometheus 做法是每个软件做一个 Exporter,Prometheus 的 Http 读取 Exporter 的信息(将监控指标进行统一的格式化并暴露出来)。简单类比,Exporter 就是个翻译,把各种语言翻译成一种统一的语言。
+
+
+
+对于Exporter而言,它的功能主要就是将数据周期性地从监控对象中取出来进行加工,然后将数据规范化后通过端点暴露给Prometheus,所以主要包含如下3个功能。
+
+- 封装功能模块获取监控系统内部的统计信息。
+- 将返回数据进行规范化映射,使其成为符合Prometheus要求的格式化数据。
+- Collect模块负责存储规范化后的数据,最后当Prometheus定时从Exporter提取数据时,Exporter就将Collector收集的数据通过HTTP的形式在/metrics端点进行暴露。
+
+### Primetheus client
+
+golang client 是当pro收集所监控的系统的数据时,用于响应pro的请求,按照一定的格式给pro返回数据,说白了就是一个http server。
+
+### 数据类型
+
+```
+# HELP go_gc_duration_seconds A summary of the GC invocation durations.
+# TYPE go_gc_duration_seconds summary
+go_gc_duration_seconds{quantile="0.5"} 0.000107458
+go_gc_duration_seconds{quantile="0.75"} 0.000200112
+go_gc_duration_seconds{quantile="1"} 0.000299278
+go_gc_duration_seconds_sum 0.002341738
+go_gc_duration_seconds_count 18
+# HELP go_goroutines Number of goroutines that currently exist.
+# TYPE go_goroutines gauge
+go_goroutines 107
+```
+
+这些信息有一个共同点,就是采用了不同于JSON或者Protocol Buffers的数据组织形式——文本形式。在文本形式中,每个指标都占用一行,#HELP代表指标的注释信息,#TYPE用于定义样本的类型注释信息,紧随其后的语句就是具体的监控指标(即样本)。#HELP的内容格式如下所示,需要填入指标名称及相应的说明信息。
+
+```
+HELP
+```
+
+\#TYPE的内容格式如下所示,需要填入指标名称和指标类型(如果没有明确的指标类型,需要返回untyped)。
+
+```
+TYPE
+```
+
+监控样本部分需要满足如下格式规范。
+
+```
+metric_name [ "{" label_name "=" " label_value " { "," label_name "=" " label_value " } [ "," ] "}" ] value [ timestamp ]
+```
+
+其中,metric_name和label_name必须遵循PromQL的格式规范。value是一个f loat格式的数据,timestamp的类型为int64(从1970-01-01 00:00:00开始至今的总毫秒数),可设置其默认为当前时间。具有相同metric_name的样本必须按照一个组的形式排列,并且每一行必须是唯一的指标名称和标签键值对组合。
+
+- Counter:Counter是一个累加的数据类型。一个Counter类型的指标只会随着时间逐渐递增(当系统重启的时候,Counter指标会被重置为0)。记录系统完成的总任务数量、系统从最近一次启动到目前为止发生的总错误数等场景都适合使用Counter类型的指标。
+- Gauge:Gauge指标主要用于记录一个瞬时值,这个指标可以增加也可以减少,比如CPU的使用情况、内存使用量以及硬盘当前的空间容量等。
+- Histogram:Histogram表示柱状图,主要用于统计一些数据分布的情况,可以计算在一定范围内的数据分布情况,同时还提供了指标值的总和。在大多数情况下,用户会使用某些指标的平均值作为参考,例如,使用系统的平均响应时间来衡量系统的响应能力。这种方式有个明显的问题——如果大多数请求的响应时间都维持在100ms内,而个别请求的响应时间需要1s甚至更久,那么响应时间的平均值体现不出响应时间中的尖刺,这就是所谓的“长尾问题”。为了更加真实地反映系统响应能力,常用的方式是按照请求延迟的范围进行分组,例如在上述示例中,可以分别统计响应时间在[0,100ms]、[100,1s]和[1s,∞]这3个区间的请求数,通过查看这3个分区中请求量的分布,就可以比较客观地分析出系统的响应能力。
+- Summary:Summary与Histogram类似,也会统计指标的总数(以_count作为后缀)以及sum值(以_sum作为后缀)。两者的主要区别在于,Histogram指标直接记录了在不同区间内样本的个数,而Summary类型则由客户端计算对应的分位数。例如下面展示了一个Summary类型的指标,其中quantile=”0.5”表示中位数,quantile=”0.9”表示九分位数。
+
+广义上讲,所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter,Exporter的一个实例被称为target,Prometheus会通过轮询的形式定期从这些target中获取样本数据。
+
+### 动手编写一个Exporter
+
+```
+package main
+
+import (
+ "log"
+ "net/http"
+
+ "github.com/prometheus/client_golang/prometheus"
+ "github.com/prometheus/client_golang/prometheus/promhttp"
+)
+
+var (
+ cpuTemp = prometheus.NewGauge(prometheus.GaugeOpts{
+ NameSpace: "our_idc",
+ Subsystem: "k8s"
+ Name: "cpu_temperature_celsius",
+ Help: "Current temperature of the CPU.",
+ })
+ hdFailures = prometheus.NewCounterVec(
+ prometheus.CounterOpts{
+ NameSpace: "our_idc",
+ Subsystem: "k8s"
+ Name: "hd_errors_total",
+ Help: "Number of hard-disk errors.",
+ },
+ []string{"device"},
+ )
+)
+
+func init() {
+ // Metrics have to be registered to be exposed:
+ prometheus.MustRegister(cpuTemp)
+ prometheus.MustRegister(hdFailures)
+}
+
+func main() {
+ cpuTemp.Set(65.3)
+ hdFailures.With(prometheus.Labels{"device":"/dev/sda"}).Inc()
+
+ // The Handler function provides a default handler to expose metrics
+ // via an HTTP server. "/metrics" is the usual endpoint for that.
+ http.Handle("/metrics", promhttp.Handler())
+ log.Fatal(http.ListenAndServe(":8888", nil))
+}
+```
+
+- `CounterVec`是用来管理相同metric下不同label的一组`Counter`
+- `counterVec`是有label的,而单纯的gauage对象却不用lable标识,这就是基本数据类型和对应Vec版本的差别.
+
+### 自定义Collector
+
+直接使用Collector,go client Colletor只会在每次响应Prometheus请求的时候才收集数据。需要每次显式传递变量的值,否则就不会再维持该变量,在Prometheus也将看不到这个变量。Collector是一个接口,所有收集metrics数据的对象都需要实现这个接口,Counter和Gauage等不例外。它内部提供了两个函数,Collector用于收集用户数据,将收集好的数据传递给传入参数Channel就可;Descirbe函数用于描述这个Collector。
+
+```
+package main
+
+import (
+ "github.com/prometheus/client_golang/prometheus"
+ "github.com/prometheus/client_golang/prometheus/promhttp"
+ "net/http"
+ "sync"
+)
+
+type ClusterManager struct {
+ sync.Mutex
+ Zone string
+ metricMapCounters map[string]string
+ metricMapGauges map[string]string
+}
+
+//Simulate prepare the data
+func (c *ClusterManager) ReallyExpensiveAssessmentOfTheSystemState() (
+ metrics map[string]float64,
+) {
+ metrics = map[string]float64{
+ "oom_crashes_total": 42.00,
+ "ram_usage": 6.023e23,
+ }
+ return
+}
+
+//通过NewClusterManager方法创建结构体及对应的指标信息,代码如下所示。
+// NewClusterManager creates the two Descs OOMCountDesc and RAMUsageDesc. Note
+// that the zone is set as a ConstLabel. (It's different in each instance of the
+// ClusterManager, but constant over the lifetime of an instance.) Then there is
+// a variable label "host", since we want to partition the collected metrics by
+// host. Since all Descs created in this way are consistent across instances,
+// with a guaranteed distinction by the "zone" label, we can register different
+// ClusterManager instances with the same registry.
+func NewClusterManager(zone string) *ClusterManager {
+ return &ClusterManager{
+ Zone: zone,
+ metricMapGauges: map[string]string{
+ "ram_usage": "ram_usage",
+ },
+ metricMapCounters: map[string]string{
+ "oom_crashes": "oom_crashes_total",
+ },
+ }
+}
+
+func (c *ClusterManager) Describe(ch chan<- *prometheus.Desc) {
+ // prometheus.NewDesc(prometheus.BuildFQName(namespace, "", metricName), docString, labels, nil)
+ for _, v := range c.metricMapGauges {
+ ch <- prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", v), v, nil, nil)
+ }
+
+ for _, v := range c.metricMapCounters {
+ ch <- prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", v), v, nil, nil)
+ }
+}
+
+//Collect方法是核心,它会抓取需要的所有数据,根据需求对其进行分析,然后将指标发送回客户端库。
+// 用于传递所有可能指标的定义描述符
+// 可以在程序运行期间添加新的描述,收集新的指标信息
+// 重复的描述符将被忽略。两个不同的Collector不要设置相同的描述符
+func (c *ClusterManager) Collect(ch chan<- prometheus.Metric) {
+ c.Lock()
+ defer c.Unlock()
+ m := c.ReallyExpensiveAssessmentOfTheSystemState()
+ for k, v := range m {
+ t := prometheus.GaugeValue
+ if c.metricMapCounters[k] != "" {
+ t = prometheus.CounterValue
+ }
+ c.registerConstMetric(ch, k, v, t)
+ }
+}
+
+// 用于传递所有可能指标的定义描述符给指标
+func (c *ClusterManager) registerConstMetric(ch chan<- prometheus.Metric, metric string, val float64, valType prometheus.ValueType, labelValues ...string) {
+ descr := prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", metric), metric, nil, nil)
+ if m, err := prometheus.NewConstMetric(descr, valType, val, labelValues...); err == nil {
+ ch <- m
+ }
+}
+func main() {
+ workerCA := NewClusterManager("xiaodian")
+ reg := prometheus.NewPedanticRegistry()
+ reg.MustRegister(workerCA)
+ //当promhttp.Handler()被执行时,所有metric被序列化输出。题外话,其实输出的格式既可以是plain text,也可以是protocol Buffers。
+ http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{}))
+ http.ListenAndServe(":8888", nil)
+}
+
+```
+
+## 高质量Exporter的编写原则与方法
+
+- 在访问Exporter的主页(即http://yourExporter/这样的根路径)时,它会返回一个简单的页面,这就是Exporter的落地页(Landing Page)。落地页中可以放文档和帮助信息,包括监控指标项的说明。落地页上还包括最近执行的检查列表、列表的状态以及调试信息,这对故障排查非常有帮助。
+- 一台服务器或者容器上可能会有许多Exporter和Prometheus组件,它们都有自己的端口号。因此,在写Exporter和发布Exporter之前,需要检查新添加的端口是否已经被使用[1],建议使用默认端口分配范围之外的端口。
+- 我们应该根据业务类型设计好指标的#HELP#TYPE的格式。这些指标往往是可配置的,包括默认开启的指标和默认关闭的指标。这是因为大部分指标并不会真正被用到,设计过多的指标不仅会消耗不必要的资源,还会影响整体的性能。
+- 对于如何写高质量Exporter,除了合理分配端口号、设计落地页、梳理指标这3个方面外,还有一些其他的原则。
+ - 记录Exporter本身的运行状态指标。
+ - 可配置化进行功能的启用和关闭。
+ - 推荐使用YAML作为配置格式。
+ - 遵循度量标准命名的最佳实践[2],特别是_count、_sum、_total、_bucket和info等问题。
+ - 为度量提供正确的单位。
+ - 标签的唯一性、可读性及必要的冗余信息设计。
+ - 通过Docker等方式一键配置Exporter。
+ - 尽量使用Collectors方式收集指标,如Go语言中的MustNewConstMetric。
+ - 提供scrapes刮擦失败的错误设计,这有助于性能调试。
+ - 尽量不要重复提供已有的指标,如Node Exporter已经提供的CPU、磁盘等信息。
+ - 向Prometheus公开原始的度量数据,不建议自行计算,Exporter的核心是采集原始指标。
\ No newline at end of file
diff --git a/_posts/2022-07-22-test-markdown.md b/_posts/2022-07-22-test-markdown.md
new file mode 100644
index 000000000000..a7a8f9c30cbd
--- /dev/null
+++ b/_posts/2022-07-22-test-markdown.md
@@ -0,0 +1,210 @@
+---
+layout: post
+title: 微服务系列
+subtitle: 微服务间的通讯 服务注册 服务发现
+tags: [Microservices gateway]
+---
+
+# 微服务全系列
+
+## 1.微服务间的通讯
+
+### 单体系统和微服务的区别
+
+| **单体系统** | **微服务系统** |
+| ------------------------ | ------------------------------------ |
+| 程序、数据、配置集中管理 | 按照功能拆分、微服务化、松耦合 |
+| 开发效率低下 | 分模块快速迭代 |
+| 发布全量,启动慢 | 平滑发布,快速启动 |
+| 可靠性差 | 熔断、限流、降级,超时重试,异常离群 |
+| 服务内直接调用 | 轻量级通信 |
+| 技术单一 | 跨语言 |
+
+- 微服务有诸多的有利条件,但是如果微服务的粒度比较细(按照业务功能拆分),则他们之间服务调用就会比较复杂,链路会比较长。
+
+
+
+- 按照职能将服务进行了拆分,这时候从不同的客户端(如 Web、App、3rd)访问,就有可能访问不同的服务。而服务与服务之间又有上下游的协作,调用就变得错综复杂。
+- 可能需要关注很多问题:
+ - 包括不同的技术栈不同的开发语言之间的上下游交互。
+ - 服务之间的注册与发现,请求认证,接入授权。
+ - 下游对上游进行调用的时候,上游怎么做负载均衡、故障注入、超时重复、熔断、降级、限流、ABTesting 等,端到端之间如何实现监控和 trace。
+
+### 微服务通信的三个方面
+
+### 1.基于网关的通信
+
+
+
+没有网关的情况下进行通讯,如上图有 3 个客户端,在调用 4 个服务的接口。这种直连调用的方式有很多问题:客户端需要保存所有服务的地址,同时也需要实现一些系统级的容错策略。比如负载均衡、超时重试、服务熔断等,非常复杂,并且难以维护。因为是在各客户端保存的服务地址,一旦某个服务端出现问题或者发生迁移,所有的客户端都需要修改并且升级。另外如果再增加一个 E svc,所有的客户端也需要升级。而且在某些场景下存在跨域请求的问题,每个服务都需要实现独立的身份和权限认证等等。
+
+> 客户端都需要修改并且升级。我们需要的是客户端不要有太大的变化。
+
+如果我们在客户端和服务端增加一层网关,所有请求都经过网关转发到对应的下游服务,客户端只需要保存网关的地址并且只和网关进行交互,这样就大大简化了客户端的开发。
+
+
+
+如果需要访问用户服务,只需要构造右边这个请求发给网关,然后由网关将请求转发给对应的下游服务。
+
+可以将网关简单理解为:路由转发+治理策略,治理策略是指和业务无关的一些通用策略,包括:负载均衡,安全认证,身份验证,系统容错等等。网关作为一个 API 架构层,用来保护、增强和控制对服务的访问。
+
+##### 网关的主要功能
+
+###### **请求接入**
+
+1、为各种应用提供统一的服务接入
+
+2、管理所有的接入请求:提供流量分流、代理转发、延迟、故障注入等能力
+
+###### **安全防护**
+
+用户认证、权限校验、黑白名单、请求过滤、防 web 攻击
+
+###### **治理策略**
+
+负载均衡、接口限流、超时重试、服务熔断、灰度发布、协议适配、流量监控、日志统计等
+
+###### **统一管理**
+
+1、提供配置管理工具
+
+2、对所有服务进行统一管理
+
+3、对中介策略进行统一管理
+
+##### 网关使用场景
+
+###### **蓝绿部署**
+
+
+
+前面看到,在单体应用中,部署是一件比较麻烦的事情,每次的改动,都需要把整个应用程序都发布启动一次。而且系统规模越大,部署过程越复杂,时间越长。
+
+而在微服务架构中,模块部署起来相对更快,更容易。可以在短时间内对于同一个模块做多次部署,网关可以帮实现蓝绿部署。
+
+如图所示之前的用户服务版本是 V1.0,然后部署 V1.1 版本,在网关上只需要做一个转发配置的修改,就可以迅速的将所有流量都流到新版本。
+
+###### **灰度发布**
+
+
+
+类似金丝雀的理念,对一次性升级版本感到担忧,可以先配置 5%的流量达到新版本,让部分人试用一下,等线上观察一段时间后,可以逐步增加对新版本的流量百分比,最终实现百分之百切流。
+
+###### **负载均衡**
+
+
+
+此能力需要依赖服务注册和服务发现。
+
+###### **服务熔断**
+
+
+
+网关还可以实现断路器的功能;如果某个下游忽然返回了大量错误,原因有可能是服务挂了或者网络问题或者服务器负载太高,如果此时继续给这个问题服务转发流量就可能会产生级联故障。
+
+出问题的服务有可能产生雪崩,雪崩会沿着调用链向上传递,导致整个服务链都崩溃。
+
+断路器可以停止向问题模块转发流量,在业务层面可以给用户返回一个服务降级之后的页面,开发人员就有相对充分的时间来定位和解决问题。
+
+##### 开源网关
+
+
+
+### 2.基于 RPC 的通信
+
+### 3.基于 ServiceMesh 的数据面(SideCar)的通信
+
+## 2.微服务的注册与发现
+
+微服务注册与发现类似于生活中的"电话通讯录"的概念,它记录了通讯录服务和电话的映射关系。在分布式架构中,服务会注册进去,当服务需要调用其它服务时,就这里找到服务的地址,进行调用。
+
+- 先要把"好友某某"记录在通讯录中
+- 拨打电话的时候通过通讯录中找到"好友某某",并拨通回电话。
+- 当好友某某电话号码更新的时候,需要通知到,并修改通讯录服务中的号码。
+
+1、把 "好友某某" 的电话号码写入通讯录中,统一在通讯录中维护,后续号码变更也是更新到通讯录中,这个过程就是服务注册的过程。
+
+2、后续我们通过"好友某某"就可以定位到通讯录中的电话号码,并拨通电话,这个过程理解为服务发现的过程。
+
+微服务架构中的服务注册与发现结构如下图所示:
+
+
+
+```
+provider - 服务提供者
+consumer - 服务消费者
+register center - 注册中心
+```
+
+它们之间的关系大致如下:
+
+1. 每个微服务在启动时,将自己的网络地址等信息(微服务的`ServiceName`、`IP`、`Port`、`MetaData`等)注册到注册中心,注册中心存储这些数据。
+2. 服务消费者从注册中心查询服务提供者的地址,并通过该地址调用服务提供者的接口。
+3. 各个微服务与注册中心使用一定机制(例如心跳)通信。如果注册中心与某微服务长时间无法通信,就会注销该实例。
+
+优点如下:
+
+1、解耦:服务消费者跟服务提供者解耦,各自变化,不互相影响
+
+2、扩展:服务消费者和服务提供者增加和删除新的服务,对于双方没有任何影响
+
+3、中介者设计模式:用一个中介对象来封装一系列的对象交互,这是一种多对多关系的中介者模式。
+
+#### 服务注册
+
+
+
+如图中,为 Register 注册中心注册一个服务信息,会将服务的信息:`ServiceName`、`IP`、Port 以及服务实例`MetaData`元数据信息写入到注册中心。当服务发生变化的时候,也可以更新到注册中心。
+
+服务提供者(服务实例) 的服务注册模型是一种简单、容易理解、流行的服务注册模型,其在多种技术生态中都有所体现:
+
+- 在`K8S`生态中,通过 `K8S Service`服务信息,和 Pod 的 endpoint(用来记录 service 对应的 pod 的访问地址)来进行注册。
+- 在 Spring Cloud 生态中,应用名 对应 服务 Service,实例 `IP + Port` 对应 Instance 实例。比较典型的就是 A 服务,后面对应有多个实例做负载均衡。
+- 在其他的注册组件中,比如 Eureka、Consul,服务模型也都是 服务 → 服务实例。
+- 可以认为服务实例是一个真正的实体的载体,服务是对这些相同能力或者相同功能服务实例的一个抽象。
+
+#### 服务发现
+
+- 服务发现实际就是我们查询已经注册好的服务提供者,比如 `p->p.queryService(serviceName`),通过服务名称查询某个服务是否存在,如果存在,
+- 返回它的所有实例信息,即一组包含 ip 、 port 、`metadata`元数据信息的`endpoints`信息。
+- 这一组 endpoints 信息一般会被缓存在本地,如果注册中心挂掉,可保证段时间内依旧可用,这是去中心化的做法。对于单个 Service 后面有多个 Instance 的情况(如上图),做 load balance。
+
+服务发现的方式一般有两种:
+
+1、拉取的方式:服务消费方(Consumer)主动向注册中心发起服务查询的请求。
+
+2、推送的方式:服务订阅/通知变更(下发):服务消费方(Consumer)主动向注册中心订阅某个服务,当注册中心中该服务信息发生变更时,注册中心主动通知消费者。
+
+#### 注册中心
+
+注册中心提供的基本能力包括:提供服务注册、服务发现 以及 健康检查。
+
+服务注册跟服务发现上面已经详细介绍了, 健康检查指的是指注册中心能够感知到微服务实例的健康状况,便于上游微服务实例及时发现下游微服务实例的健康状况。采取必备的访问措施,如避免访问不健康的实例。
+
+主要的检查方式包括:
+
+1、服务 Provider 进行 TTL 健康汇报(Time To Live,微服务 Provider 定期向注册中心汇报健康状态)。
+
+2、注册中心主动检查服务 Provider 接口。
+
+综合我们前面的内容,可以总结下注册中心有如下几种能力:
+
+1、高可用
+
+这个主要体现在两个方面。一个方面是,注册中心本身作为基础设施层,具备高可用;第二种是就是前面我们说到的去中心化,极端情况下的故障,短时间内是不影响微服务应用的调用的
+
+2、可视化操作
+
+常用的注册中心,类似 Eureka、Consul 都有比较丰富的管理界面,对配置、服务注册、服务发现进行可视化管理。
+
+3、高效运维
+
+注册中心的文档丰富,对运维的支持比较好,并且对于服务的注册是动态感知获取的,方便动态扩容。
+
+4、权限控制
+
+数据是具有敏感性,无论是服务信息注册或服务是调用,需要具备权限控制能力,避免侵入或越权请求
+
+5、服务注册推、拉能力
+
+这个前面说过了,微服务应用程序(服务的 Consumer),能够快速感知到服务实例的变化情况,使用拉取或者注册中心下发的方式进行处理。
diff --git a/_posts/2022-08-19-test-markdown.md b/_posts/2022-08-19-test-markdown.md
new file mode 100644
index 000000000000..d7fc5e58bc1f
--- /dev/null
+++ b/_posts/2022-08-19-test-markdown.md
@@ -0,0 +1,326 @@
+---
+layout: post
+title: 什么是 Docker
+subtitle: Docker虚拟化
+tags: [docker]
+---
+
+## 什么是 Docker
+
+> **Docker** 使用 `Google` 公司推出的 [Go 语言](https://golang.google.cn/) 进行开发实现,基于 `Linux` 内核的 [cgroup](https://zh.wikipedia.org/wiki/Cgroups),[namespace](https://en.wikipedia.org/wiki/Linux_namespaces),以及 [OverlayFS](https://docs.docker.com/storage/storagedriver/overlayfs-driver/) 类的 [Union FS](https://en.wikipedia.org/wiki/Union_mount) 等技术,对进程进行封装隔离,属于 [操作系统层面的虚拟化技术](https://en.wikipedia.org/wiki/Operating-system-level_virtualization)。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。最初实现是基于 [LXC](https://linuxcontainers.org/lxc/introduction/),从 `0.7` 版本以后开始去除 `LXC`,转而使用自行开发的 [libcontainer](https://github.com/docker/libcontainer),从 `1.11` 版本开始,则进一步演进为使用 [runC](https://github.com/opencontainers/runc) 和 [containerd](https://github.com/containerd/containerd)。
+
+- 操作系统层面的虚拟化技术
+
+
+
+- `runc` 是一个 Linux 命令行工具,用于根据 [OCI 容器运行时规范](https://github.com/opencontainers/runtime-spec) 创建和运行容器。
+- `containerd` 是一个守护程序,它管理容器生命周期,提供了在一个节点上执行容器和管理镜像的最小功能集。
+
+**Docker** 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 `Docker` 技术比虚拟机技术更为轻便、快捷
+
+下面的图片比较了 **Docker** 和传统虚拟化方式的不同之处。传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
+
+
+
+传统虚拟化
+
+
+
+Docker 虚拟化
+
+### 1.Docker 的优点
+
+- **相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用**。
+
+ 由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销`Docker` 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
+
+- **一致的运行环境**
+
+ 开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 `Docker` 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 _「这段代码在我机器上没问题啊」_ 这类问题。
+
+- 定制镜像
+
+ 对开发和运维([DevOps](https://zh.wikipedia.org/wiki/DevOps))人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
+
+ 使用 `Docker` 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 [Dockerfile]() 来进行镜像构建,并结合 [持续集成(Continuous Integration)](https://en.wikipedia.org/wiki/Continuous_integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 [持续部署(Continuous Delivery/Deployment)](https://en.wikipedia.org/wiki/Continuous_delivery) 系统进行自动部署。
+
+ 而且使用 [`Dockerfile`]() 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像
+
+- 轻松的迁移
+
+ 环境的一致性,使得应用的迁移更加容易。`Docker` 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的
+
+- 扩展
+
+ `Docker` 团队同各个开源项目团队一起维护了一大批高质量的 [官方镜像](https://hub.docker.com/search/?type=image&image_filter=official),
+
+### 2.**镜像**(`Image`)
+
+> 我们都知道,操作系统分为 **内核** 和 **用户空间**。对于 `Linux` 而言,内核启动后,会挂载 `root` 文件系统为其提供用户空间支持。而 **Docker 镜像**(`Image`),就相当于是一个 `root` 文件系统
+
+**Docker 镜像** 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像 **不包含** 任何动态数据,其内容在构建之后也不会被改变。
+
+##### 分层存储
+
+因为镜像包含操作系统完整的 `root` 文件系统,其体积往往是庞大的,因此在 Docker 设计时,就充分利用 [Union FS](https://en.wikipedia.org/wiki/Union_mount) 的技术,将其设计为分层存储的架构。所以严格来说,镜像并非是像一个 `ISO` 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由**多层文件系统**联合组成。
+
+镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
+
+分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
+
+> 总结:root 文件系统又被分成多层文件系统。
+
+### 3.**容器**(`Container`)
+
+镜像(`Image`)和容器(`Container`)的关系,就像是面向对象程序设计中的 `类` 和 `实例` 一样,镜像是静态的定义,**容器是镜像运行时的实体**。容器可以被创建、启动、停止、删除、暂停等。
+
+> **容器是镜像运行时的实体**。
+
+容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 [命名空间](https://en.wikipedia.org/wiki/Linux_namespaces)。因此容器可以拥有自己的 `root` 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
+
+前面讲过镜像使用的是**分层存储**,容器也是如此。每一个容器运行时,是以**镜像为基础层,在其上创建一个当前容器的存储层**,我们可以称这个为容器运行时读写而准备的存储层为 **容器存储层**。
+
+> 以**镜像为基础层,在其上创建一个当前容器的存储层**。
+
+按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 [数据卷(Volume)]()、或者 [绑定宿主目录](),在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高
+
+- **文件写入操作应该使用数据卷。**在数据卷的操作会跳过容器存储层。
+- **或者绑定宿主目录。**
+- 数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失
+
+### 4.**仓库**(`Repository`)
+
+#### Docker Registry 集中的存储、分发镜像的服务
+
+镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,[Docker Registry]() 就是这样的服务。一个 **Docker Registry** 中可以包含多个 **仓库**(`Repository`);每个仓库可以包含多个 **标签**(`Tag`);每个标签对应一个镜像。
+
+仓库 属于 [Docker Registry]() 服务,一个仓库可以包含多个 Tag ,一个 tag 标志 一个镜像。
+
+通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 **`<仓库名>:<标签>` 的格式来指定具体是这个软件哪个版本的镜像**。如果不给出标签,将以 `latest` 作为默认标签。 仓库名经常以 _两段式路径_ 形式出现,比如 `jwilder/nginx-proxy`,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名。但这并非绝对,取决于所使用的具体 Docker Registry 的软件或服务。
+
+#### Docker Registry 公开服务
+
+Docker Registry 公开服务是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
+
+最常使用的 Registry 公开服务是官方的 [Docker Hub](https://hub.docker.com/),这也是默认的 Registry,并拥有大量的高质量的 [官方镜像](https://hub.docker.com/search?q=&type=image&image_filter=official)。除此以外,还有 Red Hat 的 [Quay.io](https://quay.io/repository/);Google 的 [Google Container Registry](https://cloud.google.com/container-registry/),[Kubernetes](https://kubernetes.io/) 的镜像使用的就是这个服务;代码托管平台 [GitHub](https://github.com) 推出的 [ghcr.io](https://docs.github.com/cn/packages/working-with-a-github-packages-registry/working-with-the-container-registry)。
+
+由于某些原因,在国内访问这些服务可能会比较慢。国内的一些云服务商提供了针对 Docker Hub 的镜像服务(`Registry Mirror`),这些镜像服务被称为 **加速器**。常见的有 [阿里云加速器](https://www.aliyun.com/product/acr?source=5176.11533457&userCode=8lx5zmtu)、[DaoCloud 加速器](https://www.daocloud.io/mirror#accelerator-doc) 等。使用加速器会直接从国内的地址下载 Docker Hub 的镜像,比直接从 Docker Hub 下载速度会提高很多。在 [安装 Docker]() 一节中有详细的配置方法。
+
+国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [网易云镜像服务](https://c.163.com/hub#/m/library/)、[DaoCloud 镜像市场](https://hub.daocloud.io/)、[阿里云镜像库](https://www.aliyun.com/product/acr?source=5176.11533457&userCode=8lx5zmtu) 等。,
+
+#### 私有 Docker Registry
+
+除了使用公开服务外,用户还可以在本地搭建私有 Docker Registry。Docker 官方提供了 [Docker Registry](https://hub.docker.com/_/registry/) 镜像,可以直接使用做为私有 Registry 服务。在 [私有仓库]() 一节中,会有进一步的搭建私有 Registry 服务的讲解。
+
+开源的 Docker Registry 镜像只提供了 [Docker Registry API](https://docs.docker.com/registry/spec/api/) 的服务端实现,足以支持 `docker` 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
+
+除了官方的 Docker Registry 外,还有第三方软件实现了 Docker Registry API,甚至提供了用户界面以及一些高级功能。比如,[Harbor](https://github.com/goharbor/harbor) 和 [Sonatype Nexus]()。
+
+### 5.使用镜像
+
+在之前的介绍中,我们知道镜像是 Docker 的三大组件之一。
+
+Docker 运行容器前需要本地存在对应的镜像,如果本地不存在该镜像,Docker 会从镜像仓库下载该镜像。
+
+更多关于镜像的内容,包括:
+
+- 从仓库获取镜像;
+
+- 管理本地主机上的镜像;
+
+- 介绍镜像实现的基本原理。
+
+#### 获取镜像
+
+```
+$ docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签]
+
+$ docker pull ubuntu:18.04
+Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/create?fromImage=ubuntu&tag=18.04": dial unix /var/run/docker.sock: connect: permission denied
+
+$ sudo chown gongna:docker /var/run/docker.sock
+
+$ docker pull ubuntu:18.04
+18.04: Pulling from library/ubuntu
+22c5ef60a68e: Pull complete
+Digest: sha256:eb1392bbdde63147bc2b4ff1a4053dcfe6d15e4dfd3cce29e9b9f52a4f88bc74
+Status: Downloaded newer image for ubuntu:18.04
+docker.io/library/ubuntu:18.04
+
+$ ls -l /var/run/docker.sock
+srw-rw---- 1 gongna docker 0 8月 14 14:45 /var/run/docker.sock
+
+$ docker run -it --rm ubuntu:18.04 bash
+oot@14acce5f0a73:/# cat /etc/os-release
+NAME="Ubuntu"
+VERSION="18.04.6 LTS (Bionic Beaver)"
+ID=ubuntu
+ID_LIKE=debian
+PRETTY_NAME="Ubuntu 18.04.6 LTS"
+VERSION_ID="18.04"
+HOME_URL="https://www.ubuntu.com/"
+SUPPORT_URL="https://help.ubuntu.com/"
+BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
+PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
+VERSION_CODENAME=bionic
+UBUNTU_CODENAME=bionic
+root@14acce5f0a73:/# go env
+bash: go: command not found
+root@14acce5f0a73:/# ^C
+root@14acce5f0a73:/# ^C
+root@14acce5f0a73:/#
+
+
+
+
+
+
+```
+
+- `-it`:这是两个参数,一个是 `-i`:交互式操作,一个是 `-t` 终端。我们这里打算进入 `bash` 执行一些命令并查看返回结果,因此我们需要交互式终端。
+
+- `--rm`:这个参数是说容器退出后随之将其删除。默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动 `docker rm`。我们这里只是随便执行个命令,看看结果,不需要排障和保留结果,因此使用 `--rm` 可以避免浪费空间。
+
+- `ubuntu:18.04`:这是指用 `ubuntu:18.04` 镜像为基础来启动容器。
+
+- bash`:放在镜像名后的是 **命令**,这里我们希望有个交互式 Shell,因此用的是 `bash
+
+### 6.列出镜像
+
+```
+$ docker image ls
+ubuntu 18.04 8d5df41c547b 2 weeks ago 63.1MB
+hello-world latest feb5d9fea6a5 10 months ago 13.3kB
+```
+
+列表包含了 `仓库名`、`标签`、`镜像 ID`、`创建时间` 以及 `所占用的空间`。
+
+其中仓库名、标签在之前的基础概念章节已经介绍过了。**镜像 ID** 则是镜像的唯一标识,一个镜像可以对应多个 **标签**。因此,在上面的例子中,如果 拥有相同的 ID,因为它们对应的是同一个镜像。
+
+### 7.镜像体积
+
+如果仔细观察,会注意到,这里标识的所占用空间和在 Docker Hub 上看到的镜像大小不同。比如,`ubuntu:18.04` 镜像大小,在这里是 `63.3MB`,但是在 [Docker Hub](https://hub.docker.com/layers/ubuntu/library/ubuntu/bionic/images/sha256-32776cc92b5810ce72e77aca1d949de1f348e1d281d3f00ebcc22a3adcdc9f42?context=explore) 显示的却是 `25.47 MB`。这是因为 Docker Hub 中显示的体积是压缩后的体积。在镜像下载和上传过程中镜像是保持着压缩状态的,因此 Docker Hub 所显示的大小是网络传输中更关心的流量大小。而 `docker image ls` 显示的是镜像下载到本地后,展开的大小,准确说,是展开后的各层所占空间的总和,因为镜像到本地后,查看空间的时候,更关心的是本地磁盘空间占用的大小。
+
+另外一个需要注意的问题是,`docker image ls` 列表中的镜像体积总和并非是所有镜像实际硬盘消耗。由于 Docker 镜像是多层存储结构,并且可以继承、复用,因此不同镜像可能会因为使用相同的基础镜像,从而拥有共同的层。由于 Docker 使用 Union FS,相同的层只需要保存一份即可,因此实际镜像硬盘占用空间很可能要比这个列表镜像大小的总和要小的多。
+
+可以通过 `docker system df` 命令来便捷的查看镜像、容器、数据卷所占用的空间
+
+```
+$ docker system df
+TYPE TOTAL ACTIVE SIZE RECLAIMABLE
+Images 2 0 63.16MB 63.16MB (100%)
+Containers 0 0 0B 0B
+Local Volumes 0 0 0B 0B
+Build Cache 0 0 0B 0B
+```
+
+##### 中间层镜像
+
+为了加速镜像构建、重复利用资源,Docker 会利用 **中间层镜像**。所以在使用一段时间后,可能会看到一些依赖的中间层镜像。默认的 `docker image ls` 列表中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加 `-a` 参数
+
+```shell
+ docker image ls -a
+```
+
+##### 列出部分镜像
+
+不加任何参数的情况下,`docker image ls` 会列出所有顶层镜像,但是有时候我们只希望列出部分镜像。`docker image ls` 有好几个参数可以帮助做到这个事情。
+
+根据仓库名列出镜像
+
+```shell
+docker image ls ubuntu
+REPOSITORY TAG IMAGE ID CREATED SIZE
+
+ubuntu 18.04 329ed837d508 3 days ago 63.3MB
+
+ubuntu bionic 329ed837d508 3 days ago 63.3MB
+```
+
+##### 列出特定的某个镜像,也就是说指定仓库名和标签
+##### 列出指定格式
+
+```
+$ docker image ls --format "ID: Repository"
+5f515359c7f8: redis
+05a60462f8ba: nginx
+fe9198c04d62: mongo
+00285df0df87:
+329ed837d508: ubuntu
+329ed837d508: ubuntu
+```
+
+#### 8.删除本地镜像
+
+```shell
+$ docker image rm [选项] <镜像1> [<镜像2> ...]
+```
+
+```
+$ docker image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+centos latest 0584b3d2cf6d 3 weeks ago 196.5 MB
+redis alpine 501ad78535f0 3 weeks ago 21.03 MB
+docker latest cf693ec9b5c7 3 weeks ago 105.1 MB
+nginx
+```
+
+```
+$ docker image rm 501
+Untagged: redis:alpine
+Untagged: redis@sha256:f1ed3708f538b537eb9c2a7dd50dc90a706f7debd7e1196c9264edeea521a86d
+Deleted: sha256:501ad78535f015d88872e13fa87a828425117e3d28075d0c117932b05bf189b7
+Deleted: sha256:96167737e29ca8e9d74982ef2a0dda76ed7b430da55e321c071f0dbff8c2899b
+Deleted: sha256:32770d1dcf835f192cafd6b9263b7b597a1778a403a109e2cc2ee866f74adf23
+Deleted: sha256:127227698ad74a5846ff5153475e03439d96d4b1c7f2a449c7a826ef74a2d2fa
+Deleted: sha256:1333ecc582459bac54e1437335c0816bc17634e131ea0cc48daa27d32c75eab3
+Deleted: sha256:4fc455b921edf9c4aea207c51ab39b10b06540c8b4825ba57b3feed1668fa7c7
+```
+
+- 我们可以用镜像的完整 ID,也称为 `长 ID`,来删除镜像。使用脚本的时候可能会用长 ID,但是人工输入就太累了,所以更多的时候是用 `短 ID` 来删除镜像。`docker image ls` 默认列出的就已经是短 ID 了,一般取前 3 个字符以上,只要足够区分于别的镜像就可以了
+- 我们也可以用`镜像名`,也就是 `<仓库名>:<标签>`,来删除镜像。
+
+```
+$ docker image rm centos
+Untagged: centos:latest
+Untagged: centos@sha256:b2f9d1c0ff5f87a4743104d099a3d561002ac500db1b9bfa02a783a46e0d366c
+Deleted: sha256:0584b3d2cf6d235ee310cf14b54667d889887b838d3f3d3033acd70fc3c48b8a
+Deleted: sha256:97ca462ad9eeae25941546209454496e1d66749d53dfa2ee32bf1faabd239d38
+```
+
+当然,更精确的是使用 `镜像摘要` 删除镜像。
+
+```
+$ docker image ls --digests
+REPOSITORY TAG DIGEST IMAGE ID CREATED SIZE
+node slim sha256:b4f0e0bdeb578043c1ea6862f0d40cc4afe32a4a582f3be235a3b164422be228 6e0c4c8e3913 3 weeks ago 214 MB
+
+$ docker image rm node@sha256:b4f0e0bdeb578043c1ea6862f0d40cc4afe32a4a582f3be235a3b164422be228
+Untagged: node@sha256:b4f0e0bdeb578043c1ea6862f0d40cc4afe32a4a582f3be235a3b164422be228
+```
+
+#### 9.Untagged 和 Deleted
+
+如果观察上面这几个命令的运行输出信息的话,会注意到删除行为分为两类,一类是 `Untagged`,另一类是 `Deleted`。我们之前介绍过,镜像的唯一标识是其 ID 和摘要,而一个镜像可以有多个标签。
+
+因此当我们使用上面命令删除镜像的时候,实际上是在要求删除某个标签的镜像。所以首先需要做的是将满足我们要求的所有镜像标签都取消,这就是我们看到的 `Untagged` 的信息。因为一个镜像可以对应多个标签,因此当我们删除了所指定的标签后,可能还有别的标签指向了这个镜像,如果是这种情况,那么 `Delete` 行为就不会发生。所以并非所有的 `docker image rm` 都会产生删除镜像的行为,有可能仅仅是取消了某个标签而已。
+
+当该镜像所有的标签都被取消了,该镜像很可能会失去了存在的意义,因此会触发删除行为。镜像是多层存储结构,因此在删除的时候也是从上层向基础层方向依次进行判断删除。镜像的多层结构让镜像复用变得非常容易,因此很有可能某个其它镜像正依赖于当前镜像的某一层。这种情况,依旧不会触发删除该层的行为。直到没有任何层依赖当前层时,才会真实的删除当前层。这就是为什么,有时候会奇怪,为什么明明没有别的标签指向这个镜像,但是它还是存在的原因,也是为什么有时候会发现所删除的层数和自己 `docker pull` 看到的层数不一样的原因。
+
+除了镜像依赖以外,还需要注意的是容器对镜像的依赖。如果有用这个镜像启动的容器存在(即使容器没有运行),那么同样不可以删除这个镜像。之前讲过,容器是以镜像为基础,再加一层容器存储层,组成这样的多层存储结构去运行的。因此该镜像如果被这个容器所依赖的,那么删除必然会导致故障。如果这些容器是不需要的,应该先将它们删除,然后再来删除镜像。
+
+#### 10.用 docker image ls 命令来配合
+
+像其它可以承接多个实体的命令一样,可以使用 `docker image ls -q` 来配合使用 `docker image rm`,这样可以成批的删除希望删除的镜像。我们在“镜像列表”章节介绍过很多过滤镜像列表的方式都可以拿过来使用。
+
+比如,我们需要删除所有仓库名为 `redis` 的镜像:
+
+```
+$ docker image rm $(docker image ls -q redis)
+```
+
+或者删除所有在 `mongo:3.2` 之前的镜像:
+
+```
+$ docker image rm $(docker image ls -q -f before=mongo:3.2)
+```
diff --git a/_posts/2022-08-20-test-markdown.md b/_posts/2022-08-20-test-markdown.md
new file mode 100644
index 000000000000..add7d7f09589
--- /dev/null
+++ b/_posts/2022-08-20-test-markdown.md
@@ -0,0 +1,220 @@
+---
+layout: post
+title: 如何操作Docker容器
+subtitle:
+tags: [docker]
+---
+# **操作容器**
+
+容器是 Docker 又一核心概念。
+
+简单的说,容器是独立运行的一个或一组**应用**,以及它们的**运行态环境**。对应的,虚拟机可以理解为模拟运行的一整套操作系统(提供了运行态环境和其他系统环境)和跑在上面的应用。
+
+本章将具体介绍如何来管理一个容器,包括创建、启动和停止等。
+
+### 1.新建并启动
+
+所需要的命令主要为 `docker run`。
+
+例如,下面的命令输出一个 “Hello World”,之后终止容器。
+
+```
+$ docker run ubuntu:18.04 /bin/echo 'Hello world'
+
+Hello world
+```
+
+下面的命令则启动一个 bash 终端,允许用户进行交互
+
+```
+$ docker run -t -i ubuntu:18.04 /bin/bash
+root@af8bae53bdd3:/#
+```
+
+其中,`-t` 选项让Docker分配一个伪终端(pseudo-tty)并绑定到容器的标准输入上, `-i` 则让容器的标准输入保持打开。
+
+```
+root@af8bae53bdd3:/# pwd
+/
+root@af8bae53bdd3:/# ls
+bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
+```
+
+Docker 在后台运行的标准操作包括:
+
+- 检查本地是否存在指定的镜像,不存在就从 [registry]() 下载
+- 利用镜像创建并启动一个容器
+- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
+- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
+- 从地址池配置一个 `ip` 地址给容器
+- 执行用户指定的应用程序
+- 执行行完毕后容器被终止
+
+### 2.启动已终止容器
+
+可以利用 `docker container start` 命令,直接将一个已经终止(`exited`)的容器启动运行。
+
+容器的核心为所执行的应用程序,所需要的资源都是应用程序运行所必需的。除此之外,并没有其它的资源。可以在伪终端中利用 `ps` 或 `top` 来查看进程信息。
+
+```
+root@ba267838cc1b:/# ps
+ PID TTY TIME CMD
+ 1 ? 00:00:00 bash
+ 11 ? 00:00:00 ps
+```
+
+可见,容器中仅运行了指定的 bash 应用。这种特点使得 Docker 对资源的利用率极高,是货真价实的轻量级虚拟化。
+
+### 3.**守护态运行**
+
+```
+$ docker run ubuntu:18.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
+hello world
+hello world
+hello world
+hello world
+```
+
+如果使用了 `-d` 参数运行容器。
+
+```
+$ docker run -d ubuntu:18.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
+77b2dc01fe0f3f1265df143181e7b9af5e05279a884f4776ee75350ea9d8017a
+```
+
+此时容器会在后台运行并不会把输出的结果 (STDOUT) 打印到宿主机上面(输出结果可以用 `docker logs` 查看)。
+
+**注:** 容器是否会长久运行,是和 `docker run` 指定的命令有关,和 `-d` 参数无关。
+
+使用 `-d` 参数启动后会返回一个唯一的 id,也可以通过 `docker container ls` 命令来查看容器信息。
+
+```
+$ docker container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+77b2dc01fe0f ubuntu:18.04 /bin/sh -c 'while tr 2 minutes ago Up 1 minute agitated_wright
+```
+
+要获取容器的输出信息,可以通过 `docker container logs` 命令
+
+```
+$ docker container logs [container ID or NAMES]
+hello world
+hello world
+hello world
+. . .
+```
+
+可以使用 `docker container stop` 来终止一个运行中的容器。
+
+此外,当 Docker 容器中指定的应用终结时,容器也自动终止。
+
+例如对于上一章节中只启动了一个终端的容器,用户通过 `exit` 命令或 `Ctrl+d` 来退出终端时,所创建的容器立刻终止。
+
+终止状态的容器可以用 `docker container ls -a` 命令看到。例如
+
+```
+$ docker container ls -a
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+ba267838cc1b ubuntu:18.04 "/bin/bash" 30 minutes ago Exited (0) About a minute ago trusting_newton
+```
+
+处于终止状态的容器,可以通过 `docker container start` 命令来重新启动。
+
+此外,`docker container restart` 命令会将一个运行态的容器终止,然后再重新启动它。
+
+### 4.进入容器
+
+在使用 `-d` 参数时,容器启动后会进入后台。
+
+某些时候需要进入容器进行操作,包括使用 `docker attach` 命令或 `docker exec` 命令,推荐大家使用 `docker exec` 命令,原因会在下面说明。
+
+##### `attach` 命令
+
+下面示例如何使用 `docker attach` 命令。
+
+```
+$ docker run -dit ubuntu
+243c32535da7d142fb0e6df616a3c3ada0b8ab417937c853a9e1c251f499f550
+
+$ docker container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+243c32535da7 ubuntu:latest "/bin/bash" 18 seconds ago Up 17 seconds nostalgic_hypatia
+
+$ docker attach 243c
+root@243c32535da7:/#
+```
+
+*注意:* 如果从这个 stdin 中 exit,会导致容器的停止。
+
+##### `exec` 命令
+
+`-i` `-t` 参数
+
+`docker exec` 后边可以跟多个参数,这里主要说明 `-i` `-t` 参数。
+
+```
+$ docker run -dit ubuntu
+69d137adef7a8a689cbcb059e94da5489d3cddd240ff675c640c8d96e84fe1f6
+
+$ docker container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+69d137adef7a ubuntu:latest "/bin/bash" 18 seconds ago Up 17 seconds zealous_swirles
+
+$ docker exec -i 69d1 bash
+ls
+bin
+boot
+dev
+...
+
+$ docker exec -it 69d1 bash
+root@69d137adef7a:/#
+```
+
+如果从这个 stdin 中 exit,不会导致容器的停止。这就是为什么推荐大家使用 `docker exec` 的原因。
+
+### 5.容器的导入和导出
+
+##### 导出容器
+
+如果要导出本地某个容器,可以使用 `docker export` 命令
+
+```
+$ docker container ls -a
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+7691a814370e ubuntu:18.04 "/bin/bash" 36 hours ago Exited (0) 21 hours ago test
+$ docker export 7691a814370e > ubuntu.tar
+```
+
+这样将导出容器快照到本地文件
+
+##### 导入容器快照
+
+```
+$ cat ubuntu.tar | docker import - test/ubuntu:v1.0
+$ docker image ls
+REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
+test/ubuntu v1.0 9d37a6082e97 About a minute ago 171.3 MB
+```
+
+可以使用 `docker import` 从容器快照文件中再导入为镜像,例如
+
+```
+$ docker import http://example.com/exampleimage.tgz example/imagerepo
+```
+
+### 6.**删除容器**
+
+可以使用 `docker container rm` 来删除一个处于终止状态的容器。例如
+
+```
+$ docker container rm trusting_newton
+trusting_newton
+```
+
+清理所有处于终止状态的容器
+
+```
+$ docker container prune
+```
+
diff --git a/_posts/2022-08-21-test-markdown.md b/_posts/2022-08-21-test-markdown.md
new file mode 100644
index 000000000000..2728beb3189f
--- /dev/null
+++ b/_posts/2022-08-21-test-markdown.md
@@ -0,0 +1,92 @@
+---
+layout: post
+title: 利用 commit 理解镜像构成
+subtitle: 镜像是容器的基础
+tags: [Microservices gateway ]
+---
+# **利用 commit 理解镜像构成**
+
+注意: `docker commit` 命令除了学习之外,还有一些特殊的应用场合,比如被入侵后保存现场等。但是,不要使用 `docker commit` 定制镜像,定制镜像应该使用 `Dockerfile` 来完成。
+
+镜像是容器的基础,每次执行 `docker run` 的时候都会指定哪个镜像作为容器运行的基础。在之前的例子中,我们所使用的都是来自于 Docker Hub 的镜像。直接使用这些镜像是可以满足一定的需求,而当这些镜像无法直接满足需求时,我们就需要定制这些镜像。接下来的几节就将讲解如何定制镜像。
+
+回顾一下之前我们学到的知识,`镜像是多层存储`,每一层是在前一层的基础上进行的修改;而`容器同样也是多层存储`,是在以镜像为基础层,**在其基础上加一层作为容器运行时的存储层**。
+
+现在让我们以定制一个 Web 服务器为例子,来讲解镜像是如何构建的
+
+```
+$ docker run --name webserver -d -p 80:80 nginx
+```
+
+这条命令会用 `nginx` 镜像启动一个容器,命名为 `webserver`,并且映射了 80 端口,这样我们可以用浏览器去访问这个 `nginx` 服务器。
+
+如果是在本机运行的 Docker,那么可以直接访问:`http://localhost` ,如果是在虚拟机、云服务器上安装的 Docker,则需要将 `localhost` 换为虚拟机地址或者实际云服务器地址。
+
+直接用浏览器访问的话,我们会看到默认的 Nginx 欢迎页面。
+
+现在,假设我们非常不喜欢这个欢迎页面,我们希望改成欢迎 Docker 的文字,我们可以使用 `docker exec` 命令进入容器,修改其内容。
+
+```
+$ docker exec -it webserver bash
+root@3729b97e8226:/# echo 'Hello, Docker!
' > /usr/share/nginx/html/index.html
+root@3729b97e8226:/# exit
+exit
+```
+
+我们以交互式终端方式进入 `webserver` 容器,并执行了 `bash` 命令,也就是获得一个可操作的 Shell。
+
+然后,我们用 `Hello, Docker!
` 覆盖了 `/usr/share/nginx/html/index.html` 的内容。
+
+现在我们再刷新浏览器的话,会发现内容被改变了。
+
+我们修改了容器的文件,也就是改动了容器的存储层。我们可以通过 `docker diff` 命令看到具体的改动。
+
+```
+$ docker diff webserver
+C /root
+A /root/.bash_history
+C /run
+C /usr
+C /usr/share
+C /usr/share/nginx
+C /usr/share/nginx/html
+C /usr/share/nginx/html/index.html
+C /var
+C /var/cache
+C /var/cache/nginx
+A /var/cache/nginx/client_temp
+A /var/cache/nginx/fastcgi_temp
+A /var/cache/nginx/proxy_temp
+A /var/cache/nginx/scgi_temp
+A /var/cache/nginx/uwsgi_temp
+```
+
+现在我们定制好了变化,我们希望能将其保存下来形成镜像。
+
+要知道,当我们运行一个容器的时候(如果不使用卷的话),我们做的任何文件修改都会被记录于容器存储层里。而 Docker 提供了一个 `docker commit` 命令,可以将容器的存储层保存下来成为镜像。换句话说,就是在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像。以后我们运行这个新镜像的时候,就会拥有原有容器最后的文件变化。
+
+```
+$ docker commit \
+ --author "Tao Wang " \
+ --message "修改了默认网页" \
+ webserver \
+ nginx:v2
+sha256:07e33465974800ce65751acc279adc6ed2dc5ed4e0838f8b86f0c87aa1795214
+```
+
+我们还可以用 `docker history` 具体查看镜像内的历史记录,如果比较 `nginx:latest` 的历史记录,我们会发现新增了我们刚刚提交的这一层。
+
+```
+$ docker history nginx:v2
+IMAGE CREATED CREATED BY SIZE COMMENT
+07e334659748 54 seconds ago nginx -g daemon off; 95 B 修改了默认网页
+e43d811ce2f4 4 weeks ago /bin/sh -c #(nop) CMD ["nginx" "-g" "daemon 0 B
+ 4 weeks ago /bin/sh -c #(nop) EXPOSE 443/tcp 80/tcp 0 B
+ 4 weeks ago /bin/sh -c ln -sf /dev/stdout /var/log/nginx/ 22 B
+ 4 weeks ago /bin/sh -c apt-key adv --keyserver hkp://pgp. 58.46 MB
+ 4 weeks ago /bin/sh -c #(nop) ENV NGINX_VERSION=1.11.5-1 0 B
+ 4 weeks ago /bin/sh -c #(nop) MAINTAINER NGINX Docker Ma 0 B
+ 4 weeks ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0 B
+ 4 weeks ago /bin/sh -c #(nop) ADD file:23aa4f893e3288698c 123 MB
+```
+
diff --git a/_posts/2022-08-27-test-markdown.md b/_posts/2022-08-27-test-markdown.md
new file mode 100644
index 000000000000..60475655bb4e
--- /dev/null
+++ b/_posts/2022-08-27-test-markdown.md
@@ -0,0 +1,174 @@
+---
+layout: post
+title: 工厂方法
+subtitle: 虚拟构造函数、Virtual Constructor、Factory Method
+tags: [Microservices gateway ]
+---
+# 工厂方法
+
+> 虚拟构造函数、Virtual Constructor、Factory Method
+
+**工厂方法模式**是一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。
+
+假设正在开发一款物流管理应用。 最初版本只能处理卡车运输, 因此大部分代码都在位于名为 `卡车`的类中。
+
+一段时间后, 这款应用变得极受欢迎。 每天都能收到十几次来自海运公司的请求, 希望应用能够支持海上物流功能。
+
+
+
+如果代码其余部分与现有类已经存在耦合关系, 那么向程序中添加新类其实并没有那么容易。
+
+> 现有的代码是基于现有的类。如果想要利用原有的代码,并且增加新的类,不是那么的容易。
+>
+> 大部分代码都与 `卡车`类相关。 在程序中添加 `轮船`类需要修改全部代码。 更糟糕的是, 如果以后需要在程序中支持另外一种运输方式, 很可能需要再次对这些代码进行大幅修改
+
+## 解决方案
+
+工厂方法模式建议使用特殊的*工厂*方法代替对于对象构造函数的直接调用 (即使用 `new`运算符)。 不用担心, 对象仍将通过 `new`运算符创建, 只是该运算符改在工厂方法中调用罢了。 工厂方法返回的对象通常被称作 “产品”。
+
+**也就是说,在我们的代码中创建一个新的类,并不是动手写代码,直接创建出这个类,因为不知道,在将来会不会需要创建出和这个类平等功能的类。**
+
+
+
+乍看之下, 这种更改可能毫无意义: 我们只是改变了程序中调用构造函数的位置而已。 但是, 仔细想一下, 现在可以在子类中重写工厂方法, 从而改变其创建产品的类型。
+
+但有一点需要注意:仅当这些产品具有共同的基类或者接口时, 子类才能返回不同类型的产品, 同时基类中的工厂方法还应将其返回类型声明为这一共有接口。
+
+- **工厂方法的返回类型应该是共有的接口类型。**
+
+- **工厂方法应该是无参的,问题是如果是无参的,那么创建类需要的数据从哪里来?好问题,如果是类的方法,类本身包含创建本身的数据,或者该类从参数中获取需要的数据。**
+
+ ```
+ type Transport interface {
+ Drive()
+ }
+ func (c *RoadLogistics) Drive() {
+ //todo
+ }
+ func (b *SeaLogistics) Drive() {
+ //todo
+ }
+ type Creater interface{
+ CreateTransport() Transport
+ }
+ func (c *RoadLogistics) CreateTransport() Transport{
+ //todo
+ return c
+ }
+ func (b *SeaLogistics) CreateTransport() Transport {
+ //todo
+ return b
+ }
+
+ ```
+
+
+
+举例来说, `卡车`Truck和 `轮船`Ship类都必须实现 `运输`Transport`接口, 该接口声明了一个名为 `deliver`交付的方法。 每个类都将以不同的方式实现该方法: 卡车走陆路交付货物, 轮船走海路交付货物。 `陆路运输`RoadLogistics类中的工厂方法返回卡车对象, 而 `海路运输``SeaLogistics`类则返回轮船对象。举例来说, `卡车`Truck和 `轮船`Ship类都必须实现 `运输``Transport`接口, 该接口声明了一个名为 `deliver`交付的方法。 每个类都将以不同的方式实现该方法: 卡车走陆路交付货物, 轮船走海路交付货物。 `陆路运输``RoadLogistics`类中的工厂方法返回卡车对象, 而 `海路运输`SeaLogistics类则返回轮船对象。
+
+只要产品类实现一个共同的接口, 就可以将其对象传递给客户代码, 而无需提供额外数据。
+
+调用工厂方法的代码 (通常被称为*客户端*代码) 无需了解不同子类返回实际对象之间的差别。 客户端将所有产品视为抽象的 `运输` 。 客户端知道所有运输对象都提供 `交付`方法, 但是并不关心其具体实现方式。
+
+- **产品(`Product`) 将会对接口进行声明。 对于所有由创建者及其子类构建的对象, 这些接口都是通用的。**
+
+- **具体产品** (`Concrete Products`) 是产品接口的不同实现。
+
+- **创建者** (`Creator`) 类声明返回产品对象的工厂方法。 该方法的返回对象类型必须与产品接口相匹配。
+
+- 可以将工厂方法声明为抽象方法, 强制要求每个子类以不同方式实现该方法。 或者, 也可以在基础工厂方法中返回默认产品类型。
+
+ 注意, 尽管它的名字是创建者, 但它最主要的职责并**不是**创建产品。 一般来说, 创建者类包含一些与产品相关的核心业务逻辑。 工厂方法将这些逻辑处理从具体产品类中分离出来。 打个比方, 大型软件开发公司拥有程序员培训部门。 但是, 这些公司的主要工作还是编写代码, 而非生产程序员。
+
+ **具体创建者** (`Concrete Creators`) 将会重写基础工厂方法, 使其返回不同类型的产品。
+
+注意, 并不一定每次调用工厂方法都会**创建**新的实例。 工厂方法也可以返回缓存、 对象池或其他来源的已有对象。
+
+以下示例演示了如何使用**工厂方法**开发跨平台 UI (用户界面) 组件, 并同时避免客户代码与具体 UI 类之间的耦合。
+
+
+
+这是一个由执行到创建的过程。
+
+通过定义类的执行行为为一个接口A,然后另外一个接口B下面的函数就是负责返回这个接口A(执行行为的接口)
+
+然后不同的类去实现这个接口B,实现的代码里面就是返回具体的类。
+
+```
+//示例如下:
+//行为接口
+type Transport interface {
+ Drive()
+}
+func (c *RoadLogistics) Drive() {
+ //todo
+}
+func (b *SeaLogistics) Drive() {
+ //todo
+}
+//创建接口
+type Creater interface{
+ CreateTransport() Transport
+}
+func (c *RoadLogistics) CreateTransport() Transport{
+ //todo
+ return c
+}
+func (b *SeaLogistics) CreateTransport() Transport {
+ //todo
+ return b
+}
+```
+
+## 工厂方法模式适合应用场景
+
+ 当在编写代码的过程中, 如果**无法预知对象确切类别**及其依赖关系时, 可使用工厂方法。
+
+ 工厂方法将创建产品的代码与实际使用产品的代码分离, 从而能在**不影响其他代码的情况下扩展产品创建部分代码**。
+
+例如, 如果需要向应用中添加一种新产品, 只需要开发新的创建者子类, 然后重写其工厂方法即可。
+
+ 如果希望用户能扩展软件库或框架的内部组件, 可使用工厂方法。
+
+ 继承可能是扩展软件库或框架默认行为的最简单方法。 但是当使用子类替代标准组件时, 框架如何辨识出该子类?
+
+解决方案是将各框架中构造组件的代码集中到单个工厂方法中, 并在继承该组件之外允许任何人对该方法进行重写。
+
+让我们看看具体是如何实现的。 假设使用开源 UI 框架编写自己的应用。 希望在应用中使用圆形按钮, 但是原框架仅支持矩形按钮。 可以使用 `圆形按钮`RoundButton子类来继承标准的 `按钮`Button类。 但是, 需要告诉 `UI框架`UIFramework类使用新的子类按钮代替默认按钮。
+
+为了实现这个功能, 可以根据基础框架类开发子类 `圆形按钮 UI`UIWithRoundButtons , 并且重写其 `createButton`创建按钮方法。 基类中的该方法返回 `按钮`对象, 而开发的子类返回 `圆形按钮`对象。 现在, 就可以使用 `圆形按钮 UI`类代替 `UI框架`类。 就是这么简单!
+
+ 如果希望复用现有对象来节省系统资源, 而不是每次都重新创建对象, 可使用工厂方法。
+
+ 在处理大型资源密集型对象 (比如数据库连接、 文件系统和网络资源) 时, 会经常碰到这种资源需求。
+
+让我们思考复用现有对象的方法:
+
+1. 首先, 需要创建存储空间来存放所有已经创建的对象。
+2. 当他人请求一个对象时, 程序将在对象池中搜索可用对象。
+3. … 然后将其返回给客户端代码。
+4. 如果没有可用对象, 程序则创建一个新对象 (并将其添加到对象池中)。
+
+这些代码可不少! 而且它们必须位于同一处, 这样才能确保重复代码不会污染程序。
+
+可能最显而易见, 也是最方便的方式, 就是将这些代码放置在我们试图重用的对象类的构造函数中。 但是从定义上来讲, 构造函数始终返回的是**新对象**, 其无法返回现有实例。
+
+因此, 需要有一个既能够**创建新对象**, 又可以**重用现有对象的普通方法**。 这听上去和工厂方法非常相像。
+
+1. 让所有产品都遵循**同一接口**。 该接口必须声明对所有产品都有意义的方法。
+
+2. 在创建类中添加一个空的工厂方法。 该方法的**返回**类型必须遵循通用的**产品接口**。
+
+3. 在创建者代码中找到对于产品构造函数的所有引用。 将它们依次替换为对于工厂方法的调用, 同时将创建产品的代码移入工厂方法。
+
+ 可能需要在工厂方法中添加临时参数来控制返回的产品类型。
+
+ 工厂方法的代码看上去可能非常糟糕。 其中可能会有复杂的 `switch`分支运算符, 用于选择各种需要实例化的产品类。 但是不要担心, 我们很快就会修复这个问题。
+
+4. 现在, 为工厂方法中的每种产品编写一个创建者子类, 然后在子类中重写工厂方法, 并将基本方法中的相关创建代码移动到工厂方法中。
+
+5. 如果应用中的产品类型太多, 那么为每个产品创建子类并无太大必要, 这时也可以在子类中复用基类中的控制参数。
+
+ 例如, 设想有以下一些层次结构的类。 基类 `邮件`及其子类 `航空邮件`和 `陆路邮件` ; `运输`及其子类 `飞机`, `卡车`和 `火车` 。 `航空邮件`仅使用 `飞机`对象, 而 `陆路邮件`则会同时使用 `卡车`和 `火车`对象。 可以编写一个新的子类 (例如 `火车邮件` ) 来处理这两种情况, 但是还有其他可选的方案。 客户端代码可以给 `陆路邮件`类传递一个参数, 用于控制其希望获得的产品。
+
+6. 如果代码经过上述移动后, 基础工厂方法中已经没有任何代码, 可以将其转变为抽象类。 如果基础工厂方法中还有其他语句, 可以将其设置为该方法的默认行为。
\ No newline at end of file
diff --git a/_posts/2022-08-28-test-markdown.md b/_posts/2022-08-28-test-markdown.md
new file mode 100644
index 000000000000..5e48cea18816
--- /dev/null
+++ b/_posts/2022-08-28-test-markdown.md
@@ -0,0 +1,366 @@
+---
+layout: post
+title: 工厂方法模式(Factory Method Pattern)与复杂对象的初始化
+subtitle: 将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口
+tags: [Microservices gateway ]
+---
+## 工厂方法模式(Factory Method Pattern)与复杂对象的初始化
+
+### 注意事项:
+
+- (1)工厂方法模式跟上一节讨论的建造者模式类似,都是**将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口**。两者在应用场景上稍有区别,建造者模式更常用于需要传递多个参数来进行实例化的场景。
+- (2)**代码可读性更好**。相比于使用C++/Java中的构造函数,或者Go中的`{}`来创建对象,工厂方法因为可以通过函数名来表达代码含义,从而具备更好的可读性。比如,使用工厂方法`productA := CreateProductA()`创建一个`ProductA`对象,比直接使用`productA := ProductA{}`的可读性要好
+- (3)**与使用者代码解耦**。很多情况下,对象的创建往往是一个容易变化的点,通过工厂方法来封装对象的创建过程,可以在创建逻辑变更时,避免**霰弹式修改**
+
+### 实现方式:
+
+- 工厂方法模式也有两种实现方式:
+- (1)提供一个工厂对象,通过调用工厂对象的工厂方法来创建产品对象;
+- (2)将工厂方法集成到产品对象中(C++/Java中对象的`static`方法,Go中同一`package`下的函数
+
+```
+package aranatest
+
+type Type uint8
+
+// 事件类型定义
+const (
+ Start Type = iota
+ End
+)
+
+// 事件抽象接口
+type Event interface {
+ EventType() Type
+ Content() string
+}
+
+// 开始事件,实现了Event接口
+type StartEvent struct {
+ content string
+}
+
+func (s *StartEvent) EventType() Type {
+ return Start
+}
+func (s *StartEvent) Content() string {
+ return "start"
+}
+
+// 结束事件,实现了Event接口
+type EndEvent struct {
+ content string
+}
+
+func (s *EndEvent) EventType() Type {
+ return End
+}
+
+func (s *EndEvent) Content() string {
+ return "end"
+
+}
+
+type factroy struct {
+}
+
+func (f *factroy) Create(b Type) Event {
+ switch b {
+ case Start:
+ return &StartEvent{}
+ case End:
+ return &EndEvent{}
+ default:
+ return nil
+ }
+
+}
+
+```
+
+- 工厂方法首先知道所有的产品类型,并且每个产品需要一个属性需要来标志,而且所有的产品需要统一返回一个接口类型,并且这些产品都需要实现这个接口,这个接口下面肯定有一个方法来获取产品的类型的参数。
+
+
+
+- 另外一种实现方法是:给每种类型提供一个工厂方法
+
+```
+package aranatest
+
+type Type uint8
+
+// 事件类型定义
+const (
+ Start Type = iota
+ End
+)
+
+// 事件抽象接口
+type Event interface {
+ EventType() Type
+ Content() string
+}
+
+// 开始事件,实现了Event接口
+type StartEvent struct {
+ content string
+}
+
+func (s *StartEvent) EventType() Type {
+ return Start
+}
+func (s *StartEvent) Content() string {
+ return "start"
+}
+
+// 结束事件,实现了Event接口
+type EndEvent struct {
+ content string
+}
+
+func (s *EndEvent) EventType() Type {
+ return End
+}
+
+func (s *EndEvent) Content() string {
+ return "end"
+
+}
+
+type factroy struct {
+}
+
+func (f *factroy) Create(b Type) Event {
+ switch b {
+ case Start:
+ return &StartEvent{}
+ case End:
+ return &EndEvent{}
+ default:
+ return nil
+ }
+
+}
+
+```
+
+```
+package aranatest
+
+import "testing"
+
+func TestProduct(t *testing.T) {
+ s := OfStart()
+ if s.GetContent() != "start" {
+ t.Errorf("get%s want %s", s.GetContent(), "start")
+ }
+
+ e := OfEnd()
+ if e.GetContent() != "end" {
+ t.Errorf("get%s want %s", e.GetContent(), "end")
+ }
+
+}
+
+```
+
+
+
+## 抽象工厂模式 和 单一职责原则的矛盾
+
+> 抽象工厂模式通过给工厂类新增一个抽象层解决了该问题,如上图所示,`FactoryA`和`FactoryB`都实现·抽象工厂接口,分别用于创建`ProductA`和`ProductB`。如果后续新增了`ProductC`,只需新增一个`FactoryC`即可,无需修改原有的代码;因为每个工厂只负责创建一个产品,因此也遵循了**单一职责原则**。
+
+考虑需要如下一个插件架构风格的消息处理系统,`pipeline`是消息处理的管道,其中包含了`input`、`filter`和`output`三个插件。我们需要实现根据配置来创建`pipeline` ,加载插件过程的实现非常适合使用工厂模式,其中`input`、`filter`和`output`三类插件的创建使用抽象工厂模式,而`pipeline`的创建则使用工厂方法模式。
+
+### 抽象工厂模式和工厂方法的使用情景
+
+```
+package main
+
+import (
+ "fmt"
+ "reflect"
+ "strings"
+)
+
+type factoryType int
+
+type Factory interface {
+ CreateSpecificPlugin(cfg string) Plugin
+}
+
+//工厂来源
+var factorys = map[factoryType]Factory{
+ 1: &InputFactory{},
+ 2: &FilterFactory{},
+ 3: &OutputFactory{},
+}
+
+type AbstructFactory struct {
+}
+
+func (a *AbstructFactory) CreateSpecificFactory(t factoryType) Factory {
+ return factorys[t]
+}
+
+type Plugin interface {
+}
+
+//-----------------------------------------
+//input 创建来源
+var (
+ inputNames = make(map[string]reflect.Type)
+)
+
+func inputNamesInit() {
+ inputNames["hello"] = reflect.TypeOf(HelloInput{})
+ inputNames["hello"] = reflect.TypeOf(DataInput{})
+}
+
+type InputFactory struct {
+}
+
+func (i *InputFactory) CreateSpecificPlugin(cfg string) Plugin {
+ t, _ := inputNames[cfg]
+ return reflect.New(t).Interface().(Plugin)
+
+}
+
+//存储这两个插件的接口
+type Input interface {
+ Plugin
+ Input() string
+}
+
+//具体插件
+type HelloInput struct {
+}
+
+func (h *HelloInput) Input() string {
+ return "msg:hello"
+}
+
+type DataInput struct {
+}
+
+func (d *DataInput) Input() string {
+ return "msg:data"
+}
+
+//---------------------------
+//filter 创建来源
+var (
+ filterNames = make(map[string]reflect.Type)
+)
+
+func filterNamesInit() {
+ filterNames["upper"] = reflect.TypeOf(UpperFilter{})
+ filterNames["lower"] = reflect.TypeOf(LowerFilter{})
+}
+
+type FilterFactory struct {
+}
+
+func (f *FilterFactory) CreateSpecificPlugin(cfg string) Plugin {
+ t, _ := filterNames[cfg]
+ return reflect.New(t).Interface().(Plugin)
+}
+
+//存储这两个插件的接口
+type Filter interface {
+ Plugin
+ Process(msg string) string
+}
+
+//具体插件
+type UpperFilter struct {
+}
+
+func (u *UpperFilter) Process(msg string) string {
+ return strings.ToUpper(msg)
+}
+
+type LowerFilter struct {
+}
+
+func (l *LowerFilter) Process(msg string) string {
+ return strings.ToLower(msg)
+}
+
+//------------------------------------------
+//outPut 创建来源
+var (
+ outputNames = make(map[string]reflect.Type)
+)
+
+func outPutNamesInit() {
+ outputNames["console"] = reflect.TypeOf(ConsoleOutput{})
+ outputNames["file"] = reflect.TypeOf(FileOutput{})
+
+}
+
+type OutputFactory struct {
+}
+
+func (o *OutputFactory) CreateSpecificPlugin(cfg string) Plugin {
+ t, _ := outputNames[cfg]
+ return reflect.New(t).Interface().(Plugin)
+}
+
+//存储这两个插件的接口
+type Output interface {
+ Plugin
+ Send(msg string)
+}
+
+//具体插件
+type ConsoleOutput struct {
+}
+
+func (c *ConsoleOutput) Send(msg string) {
+ fmt.Println(msg, " has been send to Console")
+}
+
+type FileOutput struct {
+}
+
+func (c *FileOutput) Send(msg string) {
+ fmt.Println(msg, " has been send File")
+}
+
+//管道
+type PipeLine struct {
+ Input Input
+ Filter Filter
+ Output Output
+}
+
+func (p *PipeLine) Exec() {
+ msg := p.Input.Input()
+ processedMsg := p.Filter.Process(msg)
+ p.Output.Send(processedMsg)
+}
+
+func main() {
+ inputNamesInit()
+ outPutNamesInit()
+ filterNamesInit()
+
+ //创建最顶层的抽象总工厂
+ a := AbstructFactory{}
+ inputfactory := a.CreateSpecificFactory(1)
+ filterfactory := a.CreateSpecificFactory(2)
+ outputfactory := a.CreateSpecificFactory(3)
+ inputPlugin := inputfactory.CreateSpecificPlugin("hello")
+ filterPlugin := filterfactory.CreateSpecificPlugin("upper")
+ outputPlugin := outputfactory.CreateSpecificPlugin("console")
+ p := PipeLine{
+ Input: inputPlugin.(Input),
+ Filter: filterPlugin.(Filter),
+ Output: outputPlugin.(Output),
+ }
+ p.Exec()
+}
+
+```
+
diff --git a/_posts/2022-09-01-test-markdown.md b/_posts/2022-09-01-test-markdown.md
new file mode 100644
index 000000000000..47de4eb39c47
--- /dev/null
+++ b/_posts/2022-09-01-test-markdown.md
@@ -0,0 +1,57 @@
+---
+layout: post
+title: 关于代码重构
+subtitle: 大部分重构都致力于正确组合方法。在大多数情况下,过长的方法是万恶这些方法中的代码变幻莫测,执行逻辑并使该方法极难理解 甚至更难改变。一些重构技术简化了方法,消除了代码重复,并为未来铺平了道路
+tags: [设计模式 ]
+---
+
+# 关于代码重构
+
+大部分重构都致力于正确组合方法。在大多数情况下,过长的方法是万恶这些方法中的代码变幻莫测,执行逻辑并使该方法极难理解 甚至更难改变。一些重构技术简化了方法,消除了代码重复,并为未来铺平了道路
+
+### 1.提取方法
+
+> 问题:有一个可以分组的代码片段吗?
+
+解决方案:将此代码移至单独的新方法(或函数),并用对该方法的调用替换旧代码。
+
+### 2.内联方法
+
+> 问题:当**方法体**比方法本身简单,请使用此技术。
+
+解决方案:用方法的**内容**替换对方法的**调用**,并删除方法。
+
+### 3.提取变量
+
+> 问题:有一个难以理解的表达方式。
+
+解决方案:将表达式的结果或其部分放在不言自明的单独变量中
+
+### 4. 内联温度
+
+> 问题:您有一个临时变量,它分配了一个简单表达式的结果,仅此而已
+
+### 5.用查询替换 Temp
+
+> 问题:您将表达式的结果放在局部变量中以供以后在代码中使用。
+
+解决方案:将整个表达式移动到一个单独的方法中并从中返回结果。查询方法而不是使用变量。如有必要,将新方法合并到其他方法中。
+
+### 6. 拆分临时变量
+
+> 问题:您有一个用于存储 var 的局部变量
+
+解决方案:对不同的值使用不同的变量。每个变量应该只负责一件特定的事情。
+
+### 7.删除分配给参数
+
+> 问题:一些值被分配给方法体内的参数。
+
+解决方案:使用局部变量而不是参数。
+
+### 8. 用方法对象替换方法
+
+> 问题:您有一个很长的方法,其中局部变量如此交织在一起,以至于您无法应用提取方法。
+
+解决方案:将方法转换为单独的类,使局部变量成为类的字段。然后,您可以将该方法拆分为同一类中的多个方法。
+
diff --git a/_posts/2022-09-02-test-markdown.md b/_posts/2022-09-02-test-markdown.md
new file mode 100644
index 000000000000..fd96547c1c8e
--- /dev/null
+++ b/_posts/2022-09-02-test-markdown.md
@@ -0,0 +1,223 @@
+---
+layout: post
+title: 建造者模式(Builder Pattern) 与复杂对象的实例化
+subtitle: 注意事项
+tags: [设计模式]
+---
+
+## 建造者模式(Builder Pattern) 与复杂对象的实例化
+
+###### 注意事项:
+
+- (1)**复杂的对象,其中有很多成员属性,甚至嵌套着多个复杂的对象。这种情况下,创建这个复杂对象就会变得很繁琐。对于C++/Java而言,最常见的表现就是构造函数有着长长的参数列表**
+
+ ```
+ type Car struct{
+ Tire Tire
+ SteeringWheel SteeringWheel
+ Body Body
+ }
+
+ //轮胎
+ type Tire struct{
+ Size int
+ Model string
+ }
+
+ //方向盘
+ type SteeringWheel struct{
+ Price int
+ }
+
+ //车身
+ type Body struct{
+ Collor string
+ }
+ //多层的嵌套实例化
+ func main(){
+ car:= Car{
+ Tire :Tire {
+ },
+ SteeringWheel :SteeringWheel{
+
+ }
+ Body :Body {
+
+ }
+ }
+ }
+ ```
+
+ **对对象使用者不友好**,使用者在创建对象时需要知道的细节太多
+
+ **代码可读性很差**。
+
+
+
+- (2)建造者模式的作用有:
+
+ - 1、封装复杂对象的创建过程,使对象使用者不感知复杂的创建逻辑。
+
+ - 2、可以一步步按照顺序对成员进行赋值,或者创建嵌套对象,并最终完成目标对象的创建。
+
+ - 3、对多个对象复用同样的对象创建逻辑。
+
+ 其中,第1和第2点比较常用,下面对建造者模式的实现也主要是针对这两点进行示例。
+
+ ```
+ package main
+
+ type Message struct {
+ Header *Header
+ Body *Body
+ }
+
+ type Header struct {
+ SrcAddr string
+ SrcPort uint64
+ DestAddr string
+ DestPort uint64
+ Items map[string]string
+ }
+
+ type Body struct {
+ Items []string
+ }
+
+ func main(){
+ message := msg.Message{
+ Header: &msg.Header{
+ SrcAddr: "192.168.0.1",
+ SrcPort: 1234,
+ DestAddr: "192.168.0.2",
+ DestPort: 8080,
+ }
+ Items: make(map[string]string),
+ },
+ Body: &msg.Body{
+ Items: make([]string, 0),
+ },
+
+ }
+
+ ```
+
+ ```
+ package aranatest
+
+ import (
+ "sync"
+ )
+
+ type InterNetMessage struct {
+ Header *Header
+ Body *Body
+ }
+
+ type Header struct {
+ SrcAddr string
+ SrcPort uint64
+ DestAddr string
+ DestPort uint64
+ Items map[string]string
+ }
+
+ type Body struct {
+ Items []string
+ }
+
+ func GetMessuage() *InterNetMessage {
+ return GetBuilder().
+ WithSrcAddr("192.168.0.1").
+ WithSrcPort(1234).
+ WithDestAddr("192.168.0.2").
+ WithDestPort(8080).
+ WithHeaderItem("contents", "application/json").
+ WithBodyItem("record1").
+ WithBodyItem("record2").Build()
+
+ }
+
+ type builder struct {
+ once *sync.Once
+ msg *InterNetMessage
+ }
+
+ func GetBuilder() *builder {
+ return &builder{
+ once: &sync.Once{},
+ msg: &InterNetMessage{
+ Header: &Header{},
+ Body: &Body{},
+ },
+ }
+ }
+
+ func (b *builder) WithSrcAddr(addr string) *builder {
+ b.msg.Header.SrcAddr = addr
+ return b
+ }
+
+ func (b *builder) WithSrcPort(port uint64) *builder {
+ b.msg.Header.SrcPort = port
+ return b
+
+ }
+
+ func (b *builder) WithDestAddr(addr string) *builder {
+ b.msg.Header.DestAddr = addr
+ return b
+ }
+
+ func (b *builder) WithDestPort(port uint64) *builder {
+ b.msg.Header.DestPort = port
+ return b
+ }
+
+ func (b *builder) WithHeaderItem(key, value string) *builder {
+ // 保证map只初始化一次
+ b.once.Do(func() {
+ b.msg.Header.Items = make(map[string]string)
+ })
+ b.msg.Header.Items[key] = value
+ return b
+ }
+
+ func (b *builder) WithBodyItem(record string) *builder {
+ // 保证map只初始化一次
+ b.msg.Body.Items = append(b.msg.Body.Items, record)
+ return b
+ }
+
+ func (b *builder) Build() *InterNetMessage {
+ return b.msg
+ }
+
+ ```
+
+ 测试文件
+
+ ```
+ package aranatest
+
+ import (
+ "strings"
+ "testing"
+ )
+
+ func TestGetInternetMessage(t *testing.T) {
+ array := []string{
+ "record1",
+ "record2",
+ }
+ for k, v := range GetMessuage().Body.Items {
+ if strings.Compare(v, array[k]) != 0 {
+ t.Errorf("get:%s,want:%s", v, array[k])
+ }
+ }
+ }
+
+ ```
+
+
+
diff --git a/_posts/2022-09-04-test-markdown.md b/_posts/2022-09-04-test-markdown.md
new file mode 100644
index 000000000000..e3397df8796e
--- /dev/null
+++ b/_posts/2022-09-04-test-markdown.md
@@ -0,0 +1,277 @@
+---
+layout: post
+title: 单例模式 ——对象池技术
+subtitle: 注意事项:
+tags: [设计模式]
+---
+
+### 单例模式 ——对象池技术
+
+#### 注意事项:
+
+- (1)**限制调用者直接实例化该对象**
+
+ 利用 Go 语言`package`的访问规则来实现,将单例结构体设计成首字母小写,就能限定其访问范围只在当前 package 下,模拟了 C++/Java 中的私有构造函数。
+
+- (2)**为该对象的单例提供一个全局唯一的访问方法**。
+
+ 当前`package`下实现一个首字母大写的访问函数,就相当于`static`方法的作用了。
+
+- (3)**频繁的创建和销毁一则消耗 CPU,二则内存的利用率也不高,通常我们都会使用对象池技术来进行优化**
+
+- (4)**实现一个消息对象池,因为是全局的中心点,管理所有的 Message 实例,所以消息对象池就是一个单例**
+
+```
+package aranatest
+
+import (
+ "sync"
+)
+
+// 消息池
+type messagePool struct {
+ pool *sync.Pool
+}
+
+var msgPool = &messagePool{
+ pool: &sync.Pool{
+ New: func() interface{} {
+
+ return Message{
+ Content: "",
+ }
+ },
+ },
+}
+
+func Instance() *messagePool {
+ return msgPool
+}
+
+func (m *messagePool) AddMessage(msg *Message) {
+ m.pool.Put(msg)
+}
+
+func (m *messagePool) GetMessuage() *Message {
+ result := m.pool.Get()
+ if k, ok := result.(*Message); ok {
+ return k
+ } else {
+ return nil
+ }
+}
+
+type Message struct {
+ Content string
+}
+
+```
+
+```
+package aranatest
+
+import (
+ "testing"
+)
+
+type data struct {
+ in *Message
+ out *Message
+}
+
+var dataArray = []data{
+ {
+ in: &Message{
+ Content: "msg1",
+ },
+ out: &Message{
+ Content: "msg1",
+ },
+ },
+
+ {
+ in: &Message{
+ Content: "msg2",
+ },
+ out: &Message{
+ Content: "msg2",
+ },
+ },
+
+ {
+ in: &Message{
+ Content: "msg3",
+ },
+ out: &Message{
+ Content: "msg3",
+ },
+ },
+ {
+ in: &Message{
+ Content: "msg4",
+ },
+ out: &Message{
+ Content: "msg4",
+ },
+ },
+ {
+ in: &Message{
+ Content: "msg5",
+ },
+ out: &Message{
+ Content: "msg5",
+ },
+ },
+ {
+ in: &Message{
+ Content: "msg6",
+ },
+ out: &Message{
+ Content: "msg6",
+ },
+ },
+}
+
+func TestMsgPool(t *testing.T) {
+ for _, v := range dataArray {
+ t.Run(v.in.Content, func(t *testing.T) {
+ msgPool.AddMessage(v.in)
+ if msgPool.GetMessuage().Content != v.in.Content {
+ t.Errorf("get %s want %s", msgPool.GetMessuage().Content, v.out.Content)
+ }
+ })
+ }
+}
+
+```
+
+以上的单例模式就是典型的“**饿汉模式**”,实例在系统加载的时候就已经完成了初始化。
+
+对应地,还有一种“**懒汉模式**”,只有等到对象被使用的时候,才会去初始化它,从而一定程度上节省了内存。众所周知,“懒汉模式”会带来线程安全问题,可以通过**普通加锁**,或者更高效的**双重检验锁**来优化。对于“懒汉模式”,Go 语言有一个更优雅的实现方式,那就是利用`sync.Once`,它有一个`Do`方法,其入参是一个方法,Go 语言会保证仅仅只调用一次该方法。
+
+```
+package aranatest
+
+import (
+ "sync"
+)
+
+// 消息池
+type messagePool struct {
+ pool *sync.Pool
+ sync
+
+}
+
+var msgPool = &messagePool{
+ pool: &sync.Pool{
+ New: func() interface{} {
+
+ return Message{
+ Content: "",
+ }
+ },
+ },
+}
+
+func Instance() *messagePool {
+ return msgPool
+}
+
+func (m *messagePool) AddMessage(msg *Message) {
+ m.pool.Put(msg)
+}
+
+func (m *messagePool) GetMessuage() *Message {
+ result := m.pool.Get()
+ if k, ok := result.(*Message); ok {
+ return k
+ } else {
+ return nil
+ }
+}
+
+type Message struct {
+ Content string
+}
+
+```
+
+```
+package aranatest
+
+import (
+ "testing"
+)
+
+type data struct {
+ in *Message
+ out *Message
+}
+
+var dataArray = []data{
+ {
+ in: &Message{
+ Content: "msg1",
+ },
+ out: &Message{
+ Content: "msg1",
+ },
+ },
+
+ {
+ in: &Message{
+ Content: "msg2",
+ },
+ out: &Message{
+ Content: "msg2",
+ },
+ },
+
+ {
+ in: &Message{
+ Content: "msg3",
+ },
+ out: &Message{
+ Content: "msg3",
+ },
+ },
+ {
+ in: &Message{
+ Content: "msg4",
+ },
+ out: &Message{
+ Content: "msg4",
+ },
+ },
+ {
+ in: &Message{
+ Content: "msg5",
+ },
+ out: &Message{
+ Content: "msg5",
+ },
+ },
+ {
+ in: &Message{
+ Content: "msg6",
+ },
+ out: &Message{
+ Content: "msg6",
+ },
+ },
+}
+
+func TestMsgPool(t *testing.T) {
+ msgPool = Instance()
+ for _, v := range dataArray {
+ t.Run(v.in.Content, func(t *testing.T) {
+ msgPool.AddMessage(v.in)
+ if msgPool.GetMessuage().Content != v.in.Content {
+ t.Errorf("get %s want %s", msgPool.GetMessuage().Content, v.out.Content)
+ }
+ })
+ }
+}
+
+```
diff --git a/_posts/2022-09-05-test-markdown.md b/_posts/2022-09-05-test-markdown.md
new file mode 100644
index 000000000000..86186d04b77e
--- /dev/null
+++ b/_posts/2022-09-05-test-markdown.md
@@ -0,0 +1,962 @@
+---
+layout: post
+title: 重构代码
+subtitle: Composing Methods
+tags: [重构]
+---
+
+# 重构代码
+
+## Composing Methods
+
+> 大部分重构都致力于正确组合方法。在大多数情况下,过长的方法是一切邪恶。这些方法中的代码变幻莫测
+> 执行逻辑并使该方法极难理解——甚至更难改变。该组中的重构技术简化了方法**删除代码。**
+
+#### `提取方法`
+
+```
+func printOwing() {
+ printBanner()
+ // Print details.
+ fmt.Println("name: " + name);
+ fmt.Println("amount: " + getOutstanding());
+
+}
+
+func printOwing() {
+ printBanner()
+ // Print details.
+ printDetails(getOutstanding())
+
+}
+void printDetails(outstanding int, name int) {
+ System.out.println("name: " + name);
+ System.out.println("amount: " + outstanding)
+}
+```
+
+解决方案:
+将此代码移动到单独的新方法(或函数)和用对方法的调用替换旧代码
+
+为什么要重构?
+在方法中找到的行越多,就越难弄清楚该方法的作用。这是造成这种情况的
+
+主要原因:重构
+除了消除代码中的粗糙边缘之外,提取方法也是许多其他重构方法中的一个步骤。
+
+好处:
+更易读的代码!
+
+如何重构?
+
+创建一个新方法,并以使其纯粹的方式命名。
+
+### `Inline Method`
+
+```
+class PizzaDelivery {
+ // ...
+ int getRating() {
+ return moreThanFiveLateDeliveries() ? 2 : 1;
+ }
+ boolean moreThanFiveLateDeliveries() {
+ return numberOfLateDeliveries > 5;
+ }
+}
+```
+
+```
+class PizzaDelivery {
+ // ...
+ int getRating() {
+ return numberOfLateDeliveries > 5 ? 2 : 1
+ }
+ boolean moreThanFiveLateDeliveries() {
+ return numberOfLateDeliveries > 5;
+ }
+}
+```
+
+1. Make sure that the method isn’t redefined in subclasses. If the
+method is redefined, refrain from this technique.
+2. Find all calls to the method. Replace these calls with the con-
+tent of the method.
+3. Delete the method.
+
+### `Inline Temp`
+
+```
+
+boolean hasDiscount(Order order) {
+ double basePrice = order.basePrice();
+ return basePrice > 1000;
+}
+
+```
+
+```
+boolean hasDiscount(Order order) {
+ return order.basePrice()> 1000;
+}
+```
+
+### `Replace Temp with Query`
+
+```
+double calculateTotal() {
+ double basePrice = quantity * itemPrice;
+ if (basePrice > 1000) {
+ return basePrice * 0.95;
+ } else {
+ return basePrice * 0.98;
+ }
+}
+```
+
+```
+double calculateTotal() {
+ double basePrice = quantity * itemPrice;
+ if (basePrice > 1000) {
+ return basePrice * 0.95;
+ } else {
+ return basePrice * 0.98;
+ }
+}
+double basePrice(){
+ return quantity * itemPrice;
+}
+```
+
+### `Split Temporary Variable`
+
+```
+double temp = 2 * (height + width);
+System.out.println(temp);
+temp = height * width;
+System.out.println(temp);
+```
+
+```
+final double perimeter = 2 * (height + width);
+System.out.println(temp);
+final double area= height * width;
+System.out.println(temp);
+```
+
+### `Remove Assignments to Parameters`
+
+```
+int discount(int inputVal, int quantity) {
+ if (inputVal > 50) {
+ inputVal -= 2;
+ }
+}
+```
+
+```
+int discount(int inputVal, int quantity) {
+ int result = inputVal
+ if (inputVal > 50) {
+ result -= 2;
+ }
+}
+```
+
+### `Replace Methodnwith Method Object`
+
+```
+class Order {
+ // ...
+ public double price() {
+ double primaryBasePrice;
+ double secondaryBasePrice;
+ double tertiaryBasePrice;
+ // Perform long computation.
+
+ }
+}
+```
+
+```
+//订单的价格有多种算法
+class Order {
+ // ...
+ public double price() {
+ return new PriceCalculator(this).compute()
+
+ }
+}
+class PriceCalculator{
+ double primaryBasePrice;
+ double secondaryBasePrice;
+ double tertiaryBasePrice;
+ // Perform long computation.
+ public PriceCalculator(Order order){
+ //todo
+ }
+ public double compute() {
+ //todo
+ }
+}
+```
+
+### `Substitute Algorithm`
+
+```
+String foundPerson(String[] people){
+ for (int i = 0; i < people.length; i++) {
+ if (people[i].equals("Don")){
+ return "Don"
+ }
+ if (people[i].equals("John")){
+ return "John"
+ }
+ if (people[i].equals("John")){
+ return "John"
+ }
+ }
+ return "";
+}
+```
+
+```
+String foundPerson(String[] people){
+ List candidates = Arrays.asList(new String[] {"Don", "John", "Kent"});
+ for (int i = 0; i < people.length; i++) {
+ if (candidates.contains(people[i])){
+ return people[i]
+ }
+ }
+}
+```
+
+## `Moving Features between Objects`
+
+> 这些重构技术展示了如何安全地移动函数类,创建新类,并隐藏实现公开访问的详细信息。
+
+- 问题:
+
+ 一个方法在另一个类中的使用比在它的类中使用的多自己的班级。
+
+- 解决方案:
+
+ 在类中创建一个新方法,使用方法最多,然后将代码从旧方法移到那里。将原始方法的代码转换为对另一个类中新方
+ 法的引用,否则将其完全删除。
+
+- 问题:一个字段在另一个类中的使用比在它的类中更多自己的班级。
+
+- 解决方案:
+
+ 在一个新类中创建一个字段并重定向所有用户
+
+ ```
+ type Person struct{
+ name string
+ officeAreaCode string
+ officeNumber string
+ }
+ ```
+
+ ```
+ type Person struct{
+ name string
+ phone TelephoneNumber
+ }
+ type TelephoneNumber struct{
+ officeAreaCode string
+ officeNumber string
+ }
+ ```
+
+- 问题:当一个班级做两个班级的工作时,尴尬
+
+- 解决方案:
+ 相反,创建一个新类并将负责相关功能的字段和方法放入其中
+
+- 问题:一个类几乎什么都不做,也不对任何事情负责,也没有为它计划额外的责任
+
+- 解决方案:
+
+ 将所有功能从类移到另一个。
+
+- 问题:客户端从对象 А 的字段或方法中获取对象 B。然后客户端调用对象 B 的一个方法。
+
+- 解决方案:
+
+ 在 A 类中创建一个新方法,将调用委托给对象 B。现在客户端不知道或不依赖于 B 类。
+
+- 问题:一个类有太多简单地委托给其他对象的方法。
+
+- 解决办法:
+
+ 删除这些方法,强制客户端直接调用方法。创建一个getter 用于从服务器类对象。.用直接调用委托类中的方法替换对服务器类中委托方法的调用。
+
+- 问题:
+ 实用程序类不包含您需要的方法,并且您不能将该方法添加到类中。
+
+- 解决方案:
+ 将方法添加到客户端类并传递实用程序类将其作为参数。
+
+ ```
+ class Report {
+ // ...
+ void sendReport() {
+ Date nextDay = new Date(
+ previousEnd.getYear(),
+ previousEnd.getMonth(),
+ previousEnd.getDate() + 1
+ );
+ // ...
+ }
+ }
+ ```
+
+ ```
+ class Report {
+ // ...
+ void sendReport() {
+ Date newStart = nextDay(previousEnd);
+ // ...
+ }
+ private static Date nextDay(Date arg){
+ return new Date(arg.getYear(), arg.getMonth(), arg.getDate() + 1)
+ }
+ }
+ ```
+
+#### 组织数据
+
+> 类关联的解开,这使得类更便携和可重用
+
+- 自封装字段
+
+ > 问题:
+ > 您使用对类中私有字段的直接访问。
+ > 解决方案:
+ > 为该字段创建一个 getter 和 setter,并仅使用它们来访问该字段。
+
+- 用对象替换数据值
+
+ > 问题:
+ >
+ > 一个类(或一组类)包含一个数据字段。该字段有自己的行为和相关数据。
+ >
+ > 解决方法:
+ > 新建一个类,将旧的字段及其行为放在类中,将类的对象存放在原来的类中。
+
+- 将值更改为参考
+
+ >
+ > 问题:
+ > 您需要用单个对象替换单个类的许多相同实例。
+ > 解决方案:
+ > 将相同的对象转换为单个参考对象
+
+- 更改对值的引用
+
+ > 问题:
+ > 您有一个参考对象太小且很少更改,无法证明管理其生命周期是合理的。
+ > 解决方案:
+ > 把它变成一个值对象。
+
+- 用对象替换数组
+
+ > 问题:
+ > 您有一个包含各种类型数据的数组。
+ > 解决方案:
+ > 将数组替换为每个元素都有单独的速率字段的对象
+
+- 重复观测数据
+
+ > 问题:
+ > 域数据是否存储?
+ > 解决方案:
+ > 那么最好将数据分离到单独的类中,确保连接和同步
+
+- 将单向关联更改为双向
+
+ > 问题:
+ > 有两个类,每个类都需要使用彼此的关系,但它们之间的关联只是单向的。
+ >
+ > 解决方案:
+ > 将缺少的关联添加到需要它的类中。
+
+- 将双向关联更改为单向
+
+ > 有一个类之间的双向关联,es,但是其中一个类不使用另一个类的功能。
+
+- 用符号常数替换幻数
+
+ > 问题:
+ > 您的代码使用了一个具有特定含义的数字。
+ > 解决方案:
+ > 将此数字替换为具有人类可读名称的常量,以解释数字的含义。
+
+- 封装字段
+
+ > 问题:
+ > 有一个公共领域。
+ > 解决方案:
+ > 将字段设为私有并为其创建访问方法
+
+- 封装集合
+
+ > 问题:
+ > 一个类包含一个集合字段和一个用于处理集合的简单 getter 和 setter。
+ > 解决方案:
+ > 将 getter 返回的值设为只读,并创建用于添加/删除集合元素的方法。
+
+- 用类替换类型代码
+
+ > 问题:
+ > 一个类有一个包含类型代码的字段。该类型的值不用于操作符条件,也不影响程序的行为。
+ > 解决方案:
+ > 创建一个新类并使用其对象而不是类型代码值。
+
+- 用子类替换类型代码
+
+ > 问题:
+ > 您有一个编码类型,它直接影响每克行为(该字段的值触发条件中的各种代码)。
+ > 解决方案:
+ > 为编码类型的每个值创建子类。然后将原始类中的相关行为提取到这些子类中。用多态替换控制流代码。
+
+- 用状态/策略替换类型代码
+
+ > 问题:
+ > 您有一个影响行为的编码类型,但您不能使用子类来摆脱它。
+ > 解决方案:
+ > 将类型代码替换为状态对象。如果需要用类型代码替换字段值,则“插入”另一个状态对象
+
+## `Self Encapsulate Field`
+
+自封装
+
+```
+
+class Range {
+ private int low, high;
+ boolean includes(int arg) {
+ return arg >= low && arg <= high;
+ }
+}
+```
+
+```
+
+class Range {
+ private int low, high;
+ boolean includes(int arg) {
+ return arg >= getLow()&& arg <= getHigh();
+ }
+ int getLow(){
+ return low;
+ }
+ int getHigh(){
+ return high;
+ }
+
+}
+```
+
+用对象替换数据值
+
+```
+type Order struct{
+ Customer string
+}
+```
+
+```
+type Order struct{
+ Customer Customer
+}
+type Customer struct{
+ Name string
+}
+```
+
+通过用对象替换数据值,我们有了一个原始字段(数字、字符串等),由于程序的增长,它不再那么简单,现在有了相关的数据和行为。一方面,这些领域本身并没有什么可怕的。但是,这个字段和行为系列可以同时存在于多个类中,从而创建重复的代码。
+
+将值更改为引用
+
+```
+type Order struct{
+ Customer Customer
+}
+type Customer struct{
+ Name string
+}
+```
+
+```
+type Order struct{
+ Customer *Customer
+}
+type Customer struct{
+ Name string
+}
+```
+
+将引用更改为值
+
+```
+type Customer struct{
+ Currency *Currency
+}
+type Currency struct{
+ Code string
+}
+```
+
+```
+type Customer struct{
+ Currency Currency
+}
+type Currency struct{
+ Code string
+}
+```
+
+将数组替换为对象
+
+```
+ String[] row = new String[2];
+ row[0] = "Liverpool";
+ row[1] = "15";
+```
+
+```
+ Performance row = new Performance();
+ row.setName("Liverpool");
+ row.setWins("15");
+ nn
+```
+
+重复观察数据
+
+```
+type IntervalWindow struct{
+ Textstart sting
+ Textend string
+ legth int
+}
+func (I *IntervalWindow) CalculateLegth(){
+
+}
+func (I *IntervalWindow) CalculateEnd(){
+
+}
+func (I *IntervalWindow) CalculateStart(){
+
+}
+
+
+```
+
+```
+
+type IntervalWindow struct{
+ Interval Interval
+}
+type Interval struct{
+ Start sting
+ End string
+ legth int
+}
+
+func (I *Interval) CalculateLegth(){
+
+}
+func (I *Interval) CalculateEnd(){
+
+}
+func (I *Interval) CalculateStart(){
+
+}
+```
+
+单向关系变为双向
+
+```
+type Order struct{
+ Customer *Customer
+}
+type Customer struct{
+ Name string
+}
+```
+
+```
+type Order struct{
+ Customer *Customer
+}
+type Customer struct{
+ Order *Order
+ Name string
+}
+```
+
+变双向为单向
+
+```
+type Order struct{
+ Customer *Customer
+}
+type Customer struct{
+ Order *Order
+ Name string
+}
+```
+
+```
+type Order struct{
+ Customer *Customer
+}
+type Customer struct{
+ Name string
+}
+```
+
+替换魔法 编号和符号常量
+
+```
+
+double potentialEnergy(double mass, double height) {
+ return mass * height * 9.81;
+}
+```
+
+```
+
+static final double GRAVITATIONAL_CONSTANT = 9.81;
+
+double potentialEnergy(double mass, double height) {
+ return mass * height * GRAVITATIONAL_CONSTANT;
+}
+```
+
+封装数组
+
+```
+type Teacher struct{
+ PersonList []Person
+}
+type Person struct{
+ Name string
+}
+
+```
+
+```
+type Teacher struct{
+ PersonList []Person
+}
+func (t *Teacher) Getter(index int){
+ return t.PersonList[index]
+}
+func (t *Teacher) Setter(p Person , i int){
+ t.PersonList[i]=p
+}
+type Person struct{
+ Name string
+}
+```
+
+类型
+
+```
+type Teacher struct{
+ O int
+ B int
+ C int
+ AB int
+}
+
+```
+
+```
+type Teacher struct{
+ O Bloodgroup
+ B Bloodgroup
+ C Bloodgroup
+ AB Bloodgroup
+}
+type Bloodgroup int
+```
+
+有些字段无法被验证,由 IDE 检查类型。
+
+用子类替换类型代码
+
+```
+type Empployee struct{
+ engineer int
+ salesman int
+}
+```
+
+```
+type Empployee struct{
+ Engineer Engineer
+ Salesman Salesman
+}
+type Engineer struct{
+ Id int
+}
+type Salesman struct{
+ Id int
+}
+```
+
+用状态代替类型代码
+
+```
+type Empployee struct{
+ Engineer Engineer
+ Salesman Salesman
+}
+type Engineer struct{
+ Id int
+}
+type Salesman struct{
+ Id int
+}
+```
+
+```
+type Empployee EmpployeeType
+type EmpployeeType struct{
+ Engineer Engineer
+ Salesman Salesman
+}
+type Engineer struct{
+ Id int
+}
+type Salesman struct{
+ Id int
+}
+```
+
+用字段替换子类
+
+```
+type Person struct{
+ Male *Male
+ FeMale *FeMale
+}
+func (p *Person)GetCode(){
+
+}
+
+type Male struct{
+}
+func (p *Male)GetName()string{
+ return "M"
+}
+
+type FeMale struct{
+}
+func (p *FeMale)GetName()string{
+ return "F"
+}
+```
+
+```
+type Person struct{
+ code string
+
+}
+func (p *Person)GetCode(){
+
+}
+
+```
+
+## `Simplifying Conditional Expressions`
+
+> 问题:
+> 您有一个复杂的条件( if‑then / else或switch )。
+> 解决方案:
+> 将条件的复杂部分分解为单独的方法:条件,然后和其他。
+
+> 问题:
+> 您有多个导致相同结果或操作的条件。
+> 解决方案:
+> 将所有这些条件合并到一个表达式中
+
+> 问题:
+> 在所有分支中都可以找到相同的代码有条件的。
+> 解决方案:
+> 将代码移到条件之外。
+
+> 问题:
+> 您有一个用作控件的布尔变量多个布尔表达式的标志。
+> 解决方案:
+> 代替变量,使用break, continue 和return。
+
+> 问题:
+> 有一组嵌套条件,这很难,,来确定代码执行的正常流程。
+> 解决方案:
+> 将所有特殊检查和边缘情况隔离到单独的子句中,并将它们放在主要检查之前。理想的盟友,应该有一个“平坦”的条件列表,一个接一个,另一个。
+
+> 问题:
+> 您有一个执行各种操作的条件,取决于对象类型或属性。
+> 解决方案:
+> 创建与**条件分支匹配的子类**。在其中,创建一个共享方法并从条件的相应分支。然后更换
+> 带有相关方法调用的条件。结果是正确的实现将通过多态性获得,具体取决于对象类
+
+> 问题:
+> 由于某些方法返回null而不是 real,对象,您在代码中对null进行了许多检查。
+> 解决方案:
+> 而不是null, 返回一个展示的空对象.默认行为。
+
+>
+> 问题:
+> 要让一部分代码正常工作,某些条件或值必须为真。
+> 解决方案:
+> 用特定的断言替换这些假设检查。
+
+## `Decompose Conditional`
+
+```
+if (date.before(SUMMER_START) || date.after(SUMMER_END)) {
+ charge = quantity * winterRate + winterServiceCharge;
+}
+else {
+ charge = quantity * summerRate;
+ }
+```
+
+```
+if (isSummer(date)) {
+ charge = summerCharge(quantity);
+}
+ else {
+ charge = winterCharge(quantity);
+}
+```
+
+
+
+```
+double disabilityAmount() {
+if (seniority < 2) {
+ return 0;
+ }
+ if (monthsDisabled > 12) {
+ return 0;
+ }
+ if (isPartTime) {
+ return 0;
+ }
+ // Compute the disability amount.
+ // ...nn
+}
+```
+
+```
+double disabilityAmount() {
+ if (isNotEligableForDisability()) {
+ return 0;
+ nn}
+ // Compute the disability amount.
+ // ...
+}
+```
+
+
+
+```
+if (isSpecialDeal()) {
+ total = price * 0.95;
+ send();
+}
+else {
+ total = price * 0.98;
+ send();
+}
+```
+
+```
+
+if (isSpecialDeal()) {
+ total = price * 0.95;
+}
+ else {
+ total = price * 0.98;
+ }
+ nsend();
+```
+
+
+
+```
+break: stops loop
+continue: stops execution of the current loop branch and
+goes to check the loop conditions in the next iteration
+return: stops execution of the entire function and returns its
+result if given in the operator
+```
+
+
+
+## `Replace Nested Conditional with Guard Clauses`
+
+```
+
+public double getPayAmount() {
+ double result;
+ if (isDead){
+ result = deadAmount();
+ }else {
+ if (isSeparated){
+ result = separatedAmount();
+ }else {
+ if (isRetired){
+ r esult = retiredAmount();
+ }else{
+ result = normalPayAmount();
+ }
+ }
+ }
+ return result
+}
+```
+
+```
+public double getPayAmount() {
+ if (isDead){
+ return deadAmount();
+ }
+ if (isSeparated){
+ return separatedAmount();
+ }
+ if (isRetired){
+ return retiredAmount();
+ }
+ return normalPayAmount();
+}
+```
+
+
+
+## `Replace Conditional with Polymorphism`
+
+```
+class Bird {
+ // ...
+ double getSpeed() {
+ switch (type) {
+ case EUROPEAN:
+ return getBaseSpeed();
+ case AFRICAN:
+ return getBaseSpeed() - getLoadFactor() * numberOfCoconuts;
+ case NORWEGIAN_BLUE:
+ return (isNailed) ? 0 : getBaseSpeed(voltage);
+
+ }
+ throw new RuntimeException("Should be unreachable");
+ }
+}
+```
+
diff --git a/_posts/2022-09-06-test-markdown.md b/_posts/2022-09-06-test-markdown.md
new file mode 100644
index 000000000000..6bc2773bd209
--- /dev/null
+++ b/_posts/2022-09-06-test-markdown.md
@@ -0,0 +1,239 @@
+### 滑动窗口
+
+### 二分
+
+| 题目 | 类别 | 难度 | 难点 | 上次复习时间 |
+| ---- | -------- | ---- | ---- | :----------: |
+| 3 | 滑动窗口 | mid | | |
+| 76 | 二分 | mid | | |
+| 209 | 二分 | mid | | |
+| 438 | 二分 | mid | | |
+| 904 | 二分 | mid | | |
+| 930 | 二分 | mid | | |
+| 992 | 二分 | mid | | |
+| 978 | | | | |
+| 1004 | | | | |
+| 1234 | | | | |
+| 1658 | | | | |
+| | | | | |
+
+
+
+
+
+### 二分
+
+| 题号 | 类别 | 难度 | 题目 | 上次复习时间 |
+| ---- | ----------------- | ---- | ------------------------------------------------------------ | :----------: |
+| 154 | 二分 | hard | | |
+| 153 | 二分 | mid | | |
+| 34 | 二分 | mid | 排序数组查找元素的第一个和最后一个位置 | 4.12 |
+| 35 | 二分 | mid | | |
+| 189 | 二分 | mid | | |
+| 81 | 二分 | mid | | |
+| 33 | 二分 | mid | | 4.11 |
+| 658 | 二分/定长滑动窗口 | mid | 找到k个最接近的元素 | 4.12 |
+| 162 | 二分 | mid | 寻找峰值 | 4.11 |
+| 278 | 二分 | mid | 第一个错误的版本 | 4.11 |
+| 374 | 二分 | mid | | 4.11 |
+| 69 | 二分 | mid | x的平方根 | 4.11 |
+| 704 | 二分 | mid | 二分查找 | 4.11 |
+| 875 | 二分 | mid | 爱吃⾹蕉的珂珂 | 4.12 |
+| 475 | 二分 | mid | [供暖器](https://leetcode.cn/problems/heaters/) | 4.12 |
+| 1708 | 二分+贪心 | mid | [面试题 17.08. 马戏团人塔](https://leetcode.cn/problems/circus-tower-lcci/) | 4.13 |
+
+
+
+
+
+### 双指针
+
+| 题目 | 题目 | 类别 | 难点 | ****上次复习时间 |
+| ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ---- | ---------------- |
+| 80 | [ 删除有序数组中的重复项 II](https://leetcode.cn/problems/remove-duplicates-from-sorted-array-ii/) | 快慢指针 | | 4.13 |
+| 287 | [287. 寻找重复数](https://leetcode.cn/problems/find-the-duplicate-number/) | 快慢之争/Floyd Circle | | 4.13 |
+| 1 | [1. 两数之和](https://leetcode.cn/problems/two-sum/) | 左右指针夹逼 | | 4.13 |
+| 1304 | [1304. 和为零的 N 个不同整数](https://leetcode.cn/problems/find-n-unique-integers-sum-up-to-zero/) | 左右指针成对出现,向中间夹逼 | | 4.13 |
+| 7 | [剑指 Offer II 007. 数组中和为 0 的三个数](https://leetcode.cn/problems/1fGaJU/) | 一个left用来遍历,主要是mid 和 right指针负责缩小解空间 | | 4.13 |
+| 16 | [16. 最接近的三数之和](https://leetcode.cn/problems/3sum-closest/) | 左右指针向中间夹逼 | | 4.14 |
+| 977 | [977. 有序数组的平方](https://leetcode.cn/problems/squares-of-a-sorted-array/) | 左右指针向中间夹逼+临时空间存储 | | 4.14 |
+| 713 | [713. 乘积小于 K 的子数组](https://leetcode.cn/problems/subarray-product-less-than-k/) | 满足某个条件就右移right指针,然后不满足条件就是右移left指针(直到不满足条件) | | 4.14 |
+| 881 | [881. 救生艇](https://leetcode.cn/problems/boats-to-save-people/) | 排好序的数组,可以用两个指针分别指着最前端和最后端,如果两个数加起来都会比limit小,那这一队数绝对是最优的一种组合了.如果是大于的话,那就将大的那个数单独放在一艘游艇上,数更小的那个不要动,这个是因为小的可以和别的数子凑合,但是大的数一定是要单独一艘船的。 | | 4.14 |
+| 26 | [26. 删除有序数组中的重复项](https://leetcode.cn/problems/remove-duplicates-from-sorted-array/) | 快慢指针 | | 4.15 |
+| 141 | [141. 环形链表](https://leetcode.cn/problems/linked-list-cycle/) | 快慢指针 | | 4.15 |
+| 142 | [142. 环形链表 II](https://leetcode.cn/problems/linked-list-cycle-ii/) | 快慢指针 | | 4.15 |
+| 287 | [287. 寻找重复数](https://leetcode.cn/problems/find-the-duplicate-number/) | 快慢指针 | | 4.15 |
+| 202 | [202. 快乐数](https://leetcode.cn/problems/happy-number/) | 递归+全局记录判断是否出现过 | | 4.15 |
+| 1456 | [1456. 定长子串中元音的最大数目](https://leetcode.cn/problems/maximum-number-of-vowels-in-a-substring-of-given-length/) | 固定长指针 | | 4.15 |
+| 1446 | [1446. 连续字符](https://leetcode.cn/problems/consecutive-characters/) | 变长指针 | | 4.15 |
+| 101 | [101. 对称二叉树](https://leetcode.cn/problems/symmetric-tree/) | 左右端点指针 | | 4.15 |
+| | | | | |
+
+
+
+
+
+### 前缀树
+
+| | | | | |
+| ---- | ---- | ---- | ---- | ---- |
+| | | | | |
+| | | | | |
+| | | | | |
+
+
+
+### 树专题
+
+| 题目 | 方法 | 时间 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [365. 水壶问题](https://leetcode.cn/problems/water-and-jug-problem/) | DFS/BFS | 4.16 |
+| [886. 可能的二分法](https://leetcode.cn/problems/possible-bipartition/) | 图建立/图遍历/图递归遍历和迭代遍历。⼀个好⽤的技巧是使⽤ -1 和 1 来记录⽅向,这样我们就可以通过乘以 -1 得到另外⼀个⽅向 | 4.16 |
+| [785. 判断二分图](https://leetcode.cn/problems/is-graph-bipartite/) | 不是连通图需要对每个点都去DFS。思路是;如果没有Clored被访问就DFS,如果被访问,判断邻居节点和当前节点颜色是否相等,如果相等就返回false | 4.16 |
+| [99. 恢复二叉搜索树](https://leetcode.cn/problems/recover-binary-search-tree/) | 中序遍历可以记录全局的前躯节点,然后两两比较, | 4.17 |
+| [222. 完全二叉树的节点个数](https://leetcode.cn/problems/count-complete-tree-nodes/) | BFS 解决 | 4.17 |
+| [124. 二叉树中的最大路径和](https://leetcode.cn/problems/binary-tree-maximum-path-sum/) | 双递归/max(left,0)+max(right,0)+root.Val | 4.17 |
+| [113. 路径总和 II](https://leetcode.cn/problems/path-sum-ii/) | `res[][]int`存储的是对`path[]int`的引用,在递归的时候path被改变,那么最后的结果不正确。 | 4.18 |
+| [863. 二叉树中所有距离为 K 的结点](https://leetcode.cn/problems/all-nodes-distance-k-in-binary-tree/) | `findLCA` 寻找公共祖先+`fatherMap[son]father` +`depth(i)i!=nil d++`得到深度 | 4.18 |
+| [563. 二叉树的坡度](https://leetcode.cn/problems/binary-tree-tilt/) | 双递归 | 4.18 |
+| [面试题 04.12. 求和路径](https://leetcode.cn/problems/paths-with-sum-lcci/) | 求和路径 | 4.18 |
+| [1022. 从根到叶的二进制数之和](https://leetcode.cn/problems/sum-of-root-to-leaf-binary-numbers/) | 左移动`*2` / 右移`/2` | 4.18 |
+| | | |
+
+### 图专题
+
+
+
+| 题目 | 方法 | 时间 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [547. 省份数量](https://leetcode.cn/problems/number-of-provinces/) | 标准遍历-图的遍历 | 4.18 |
+| [802. 找到最终的安全状态](https://leetcode.cn/problems/find-eventual-safe-states/) | 递归超时/反向图+出度 | 4.20 |
+| [841. 钥匙和房间](https://leetcode.cn/problems/keys-and-rooms/) | 判断是不是一棵树 | |
+| [1129. 颜色交替的最短路径](https://leetcode.cn/problems/shortest-path-with-alternating-colors/) | `BFS` 队列+`len(queue)`,然后不断取出这k个节点。 | |
+| [329. 矩阵中的最长递增路径](https://leetcode.cn/problems/longest-increasing-path-in-a-matrix/) | `BFS+DP` `DP`用来计算以某个点结尾的最长递增的长度 | 4.27 |
+| [1042. 不邻接植花](https://leetcode.cn/problems/flower-planting-with-no-adjacent/) | `BFS+全局染色存储+从未被染色的节点开始+双向边+存在孤立节点` | 4.27 |
+| [207. 课程表](https://leetcode.cn/problems/course-schedule/) | 拓扑排序+从入度为0的点开始 | 4.27 |
+| [743. 网络延迟时间](https://leetcode.cn/problems/network-delay-time/) | 最短路径问题 核心:`dis[]记录起点到每个点的最短的距离,并把节点入队列,堆队列排序,取出距离最小的点,去判断这个点再到它的邻接点的距离,。` `一个集合 dis 来记录起点 s 到各个节点的最短路径长度` `一个优先队列或堆来维护当前还未处理的节点` `每次从堆中取出时间最小的点正好符合上述的要求,因为该节点距离起点 s 最近,并且它的最短路径长度已经被确定,可以作为最终结果之一` Dijkstra | 4.27 |
+| 1063 | 最短路径问题 | |
+| 1135 | 最小生成树问题 | |
+| 1584 | 最小生成树问题 | |
+| [1319. 连通网络的操作次数](https://leetcode.cn/problems/number-of-operations-to-make-network-connected/) | 如果边少于n-1不能连通。最开始默认n个点就是个n个独立的集合。每连通两个点,group--最后的答案是group-1。 `groupNum` 表示当前图中的连通分量数,最终结果就是将所有的连通分量合并为一。在添加第一条边时,就可以将两个连通分量合并为一个,因此连通分量数减 1。假设有以下 4 个节点,它们之间的边还未建立:初始状态下,这 4 个节点分别处于独立的连通分量中。因此 `groupNum` 的初始值为 4。为了将所有连通分量合并成一个,需要建立 3 条边。具体来说: 首先连接节点 1 和节点 2,这时候它们就连通了,剩余连通分量数量减少 1,也就是 `groupNum` 减少 1,此时 `groupNum` 的值为 3。 然后连接节点 3 和节点 4,同样地,它们也连通了,此时 `groupNum` 的值减少到 2。 最后连接连通分量 1 和连通分量 2 即可,此时 `groupNum` 的值变成了 1,所有连通分量都已经被合并成了一个。 | 5.4 |
+
+
+
+
+
+### 最短路径问题
+
+| 题目 | 方法 | 时间 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [127. 单词接龙](https://leetcode.cn/problems/word-ladder/) | `BFS+hashMap存储单词可以构成的状态` | 4.21 |
+| [200. 岛屿数量](https://leetcode.cn/problems/number-of-islands/) | `BFS+visted[][]bool` | 4.21 |
+| [279. 完全平方数](https://leetcode.cn/problems/perfect-squares/) | `BFS减枝优化`+`DP动态规划` | 4.21 |
+| [542. 01 矩阵](https://leetcode.cn/problems/01-matrix/) | `BFS从终点出发遍历,感觉像染色`那么其他点到终点的距离就是`res[cur.x][cur.y-1] = res[cur.x][cur.y] + 1 ` `0-1-1-1-1`和802一样都是从终点开始.[802. 找到最终的安全状态](https://leetcode.cn/problems/find-eventual-safe-states/) | 4.21 |
+| | | |
+| [752. 打开转盘锁](https://leetcode.cn/problems/open-the-lock/) | `BFS+HasMap`和127单词接龙有点类似,都是寻找某个状态对应的邻居状态,这么才能寻找到下一个需要注意的是一次只能转动一个,顺时针转+1,逆时针转+9。773 | 4.21 |
+| [773. 滑动谜题](https://leetcode.cn/problems/sliding-puzzle/) | `BFS+node.status +node.step+visited[string]bool` | 4.21 |
+| [207. 课程表](https://leetcode.cn/problems/course-schedule/) | `BFS+nodeInDegreeMap 统计儿子节点的入度+构建邻接表+遍历visitedMap判断存不存在某个节点没有被访问 ` | 4.22 |
+| [210. 课程表 II](https://leetcode.cn/problems/course-schedule-ii/) | | |
+
+
+
+### 启发式搜索
+
+| 题目 | 关键点/难点 | 时间 |
+| ---- | ----------- | ---- |
+| 1239 | | |
+| 1723 | | |
+| 127 | | |
+| 752 | | |
+
+
+
+
+
+### 堆
+
+| 题目 | 关键点/难点 | 时间 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [1046. 最后一块石头的重量](https://leetcode.cn/problems/last-stone-weight/) | 不断的寻找最小的数,与原来未排序的进行合并。 | 4.30 |
+| [313. 超级丑数](https://leetcode.cn/problems/super-ugly-number/) | `10 可以分解为 2 和 5 的乘积,因此它的质因数是 2 和 5;而 12 可以分解为 2、2 和 3 的乘积` 最小堆`container/heap` | 4.30 |
+| [295. 数据流的中位数](https://leetcode.cn/problems/find-median-from-data-stream/) | 维护最大堆和最小堆栈,往最小堆添加元素的情况,最小堆元素个数为0,元素>最小堆顶部元素,否则就往最大堆添加元素。 | 5.1 |
+| [857. 雇佣 K 名工人的最低成本](https://leetcode.cn/problems/minimum-cost-to-hire-k-workers/) | 按照ratio从小到大,以每个ratio为基准,计算K个工人(按照质量排好序)的堆,计算总的花费。 | |
+| [649. Dota2 参议院](https://leetcode.cn/problems/dota2-senate/) | | |
+| [1654. 到家的最少跳跃次数](https://leetcode.cn/problems/minimum-jumps-to-reach-home/) | | |
+
+
+
+### 多路归并
+
+| 题目 | 关键点/难点 | 时间 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [264. 丑数 II](https://leetcode.cn/problems/ugly-number-ii/) | 定义指针数组,然后都代表某个因数的指针被使用填充结果数组的一个数,那么就移动该因数指针。1-起始先将最小丑数1 放入队列。2-每次从队列取出最小值x ,然后将 x 所对应的丑数 2x 、3x 和 5x 进行入队 3-对步骤 2 循环多次,第 n 次出队的值即是答案。4-防止同一丑数多次进队,我们需要使用数据结构 Set 来记录入过队列的丑数。往后产生的丑数」都是基于「已有丑数」而来(使用「已有丑数」乘上「质因数」2 、3 、5 )。 | |
+| [313. 超级丑数](https://leetcode.cn/problems/super-ugly-number/) | 定义指针数组,然后都代表某个因数的指针被使用填充结果数组的一个数,那么就移动该因数指针。1-所有丑数的有序序列为 a1,a2,a3,...,an由以下三个有序序列合并而来:丑数 * 2 所得的有序序列`1*2 2*2 3*2 4*2 5*2 ` 丑数 * 3 所得的有序序列`1*3 2*3 3*3 4*3 ` 丑数 * 5 所得的有序序列`1*5 2*5 3*5 4*5` 使用三个指针来指向目标序列 arr的某一位下标,p2 ,p3 p5代表三个有序队列当前各自到了自己序列的哪个位置。 | |
+| [786. 第 K 个最小的素数分数](https://leetcode.cn/problems/k-th-smallest-prime-fraction/) | 找到以每个元素为分母的链表,把,每个元素都放入到小顶堆里面,不断的弹出元素,直到第K个元素。 | 5.2 |
+| [1508. 子数组和排序后的区间和](https://leetcode.cn/problems/range-sum-of-sorted-subarray-sums/) | 前缀和,把结果放入堆,然后弹出小的数 | 5.5 |
+| [719. 找出第 K 小的数对距离](https://leetcode.cn/problems/find-k-th-smallest-pair-distance/) | 某个mid D1对应K个,还要继续往左找直到mid D2对应K个 | 5.2 |
+| [1439. 有序矩阵中的第 k 个最小数组和](https://leetcode.cn/problems/find-the-kth-smallest-sum-of-a-matrix-with-sorted-rows/) | 放入小顶堆的是`node{pointer []int sum int}`其中`node.pointer 保存着每一行取出数字的列坐标,知道列坐标和行坐标就可以知道新加入的数字和旧的被剪去的数字。` | 5.2 |
+| [373. 查找和最小的 K 对数字](https://leetcode.cn/problems/find-k-pairs-with-smallest-sums/) | 放入小顶堆的是`node{pointer []int sum int}`其中`node.pointer 保存着每一行取出数字的列坐标,知道列坐标和行坐标就可以知道新加入的数字和旧的被剪去的数字。` `set`记录的是被访问过的坐标,那么其中`set[key]bool` key 是`[2]int 类型` | 5.2 |
+| [632. 最小区间](https://leetcode.cn/problems/smallest-range-covering-elements-from-k-lists/) | 维持大小为K的堆,堆的最大值,靠新加入节点的值与堆的最大值不断比较。初始状态的最大值可以求出,然后最小的节点的值,不断被弹出,距离的最小值,不断更新大小为K的堆中元素大小的区间。 | 5.3 |
+| [1675. 数组的最小偏移量](https://leetcode.cn/problems/minimize-deviation-in-array/) | 思路:维护最堆和堆的最小值。最开始处理的时候,把所有的奇数都乘以2加入到堆里面。偶数直接加入堆。对堆不断的除以2,直到堆顶为奇数。奇数只能乘一次2,偶数可以多次除以2,直到变成一个奇。操作时有限的。相当于数组的每个元素都是一个链表:`1 2 3 4` `1代表1-2-4-8` `2代表2-1` `3代表3-6-12` `4代表4-2-1` | 5.3 |
+| [871. 最低加油次数](https://leetcode.cn/problems/minimum-number-of-refueling-stops/) | 把终点当作一个加油站加入到数组,然后找到终点应该存在的位置,在循环中,不断的判断当前知否能到达下一站,如果能到达下一站,那么就消耗富有,如果不能到达下一站就不断的弹出历史中的加油站台,加油直到可以到达下一站。**事后诸葛** | 5.4 |
+| [1488. 避免洪水泛滥](https://leetcode.cn/problems/avoid-flood-in-the-city/) | 把晴天入队列,记录晴天是第几天,把雨天入MAP记录改天是在往哪个湖加水,并且给湖加水的日期,因为,找到的晴天必须是该湖填完水之后。**事后诸葛** | 5.4 |
+| [973. 最接近原点的 K 个点](https://leetcode.cn/problems/k-closest-points-to-origin/) | 最小堆 | 5.4 |
+| [347. 前 K 个高频元素](https://leetcode.cn/problems/top-k-frequent-elements/) | 最小堆 | 5.4 |
+| [剑指 Offer 40. 最小的k个数](https://leetcode.cn/problems/zui-xiao-de-kge-shu-lcof/) | 最小堆 | 5.4 |
+| | | |
+
+合并 `n` 个有序链表极其相似
+
+
+
+
+
+
+
+### Kruskal
+
+| 题目 | 关键点/难点 | 时间 |
+| ------------------------------------------------------------ | ----------- | ---- |
+| [1584. 连接所有点的最小费用](https://leetcode.cn/problems/min-cost-to-connect-all-points/) | | |
+| [1319. 连通网络的操作次数](https://leetcode.cn/problems/number-of-operations-to-make-network-connected/) | 连通个数-1 | 5.4 |
+| | | |
+| | | |
+
+
+
+### Dijkstra
+
+| 题目 | 关键点/难点 | 时间 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [1631. 最小体力消耗路径](https://leetcode.cn/problems/path-with-minimum-effort/) | | |
+| [1654. 到家的最少跳跃次数](https://leetcode.cn/problems/minimum-jumps-to-reach-home/) | BFS解决的最短路径问题A是向前跳。B是向后跳。上一步是往后跳而且再往后跳会跳到 forbidden 数组中的位置,则不能再往后跳。记录同一种状态是否被访问过,被访问过的则不在加入 | 5.6 |
+| [1631. 最小体力消耗路径](https://leetcode.cn/problems/path-with-minimum-effort/) | 定义全局记录着起点每个点的最小的消耗,只有在小于全局的这个值的时候,才会把他放入到队列中间,上下左右四个方向就相当于是图中的邻居,邻居A与B只有在小于全局Dis[B]的情况下,才会被加入到堆中 | 5.6 |
+| | | |
+
+
+
+
+
+
+
+### 贪心问题
+
+| 题目 | | |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ---- |
+| [435. 无重叠区间](https://leetcode.cn/problems/non-overlapping-intervals/) | 按照结束时间从小到大排序,快慢指针用来判断是第二个起始时间小于第一个结束时间,如果是大于等于`left=right`而不是`left=left+1` | 5.5 |
+| [455. 分发饼干](https://leetcode.cn/problems/assign-cookies/) | 孩子的胃口从小到大,饼干的尺寸从小到大 | 5.4 |
+| [45. 跳跃游戏 II](https://leetcode.cn/problems/jump-game-ii/) | 汽车加油问题,**统计边界范围内,哪一格能跳得更远,统计下一步的最优情况,如果到达了边界,那么一定要跳了,下一跳的边界下标就是之前统计的最优情况maxPosition,并且步数加1** | 5.7 |
+| [55. 跳跃游戏](https://leetcode.cn/problems/jump-game/) | 在这个过程中,贪心的思想体现在每一步决策上。我们从第一个位置开始,计算出当前位置所能到达的最远距离,即`maxJump`。然后看下一个位置能否到达这个`maxJump`,如果可以,就更新`maxJump`为新位置所能到达的最远距离;如果不能到达,直接返回`false`。 | 5.7 |
+| [1306. 跳跃游戏 III](https://leetcode.cn/problems/jump-game-iii/) | DFS | 5.7 |
+| [1345. 跳跃游戏 IV](https://leetcode.cn/problems/jump-game-iv/) | indexMap[arr[cur.index]] 中存储了值为 arr[cur.index] 的数在原数组中出现的所有下标,也就是从当前节点可以直接跳转到的所有节点。每当我们遍历完所有从当前节点可以抵达的节点的时候,将这些节点的下标从 `indexMap[val]` 中移除,以保证后续的遍历不会重复访问已经访问过的节点。BFS+贪心 | 5.7 |
+| [1340. 跳跃游戏 V](https://leetcode.cn/problems/jump-game-v/) | 动态规划,得到高度从小到大的序号,依次访问这些序号,并且判断旁边的邻居是否比自己小或者右边的邻居是否比自己小,小就更新该位置最多可以访问的下标。如何得到从小到大访问的序号,一个序号index[i]=i,然后就是对应的`array[index[i]] < array [index[j]]` | 5.8 |
+| [1696. 跳跃游戏 VI](https://leetcode.cn/problems/jump-game-vi/) | `len(queue)>0 && DP[queue[len(queue)-1]] < DP[i]` 类似 `3 2 1 4`遇到四的时候删除前面的3 2 1都是从尾部开始删除,维护一个单调递减的index ,里面存储的是的单调递减的DP的下标 | 5.8 |
+| [1871. 跳跃游戏 VII](https://leetcode.cn/problems/jump-game-vii/) | ` start := max(cur+minJump, farthest+1)`优化后的BFS可以通过 | 5.8 |
+| [452. 用最少数量的箭引爆气球](https://leetcode.cn/problems/minimum-number-of-arrows-to-burst-balloons/) | *每次选择局部最优解* `points[i][1] < points[j][1]`按照左端点坐标从小到大排序。 如果当前气球的左端点小于等于 `end`,说明它与前一个气球有重叠部分,此时我们不需要增加箭的数量,因为这个区间已经被覆盖了。 如果当前气球的左端点大于 `end`,说明它与前一个气球没有重叠部分,此时我们需要增加箭的数量,将当前气球的右端点赋值给 `end`。 | 5.8 |
+| [605. 种花问题](https://leetcode.cn/problems/can-place-flowers/) | 为了确保边界情况的正确性,我们需要在花坛左边、右边各增加一个未种植的位置,即 `bed = [0] + flowerbed + [0]`。这样可以保证每个位置都有前一个位置和后一个位置可以供我们检查。 | 5.8 |
+| [122. 买卖股票的最佳时机 II](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/) | 当前价格高于前一天价格,说明股票价格在上涨,我们就应该在前一天买入,在当前天卖出,这样可以获得当天的利润。而如果当前价格低于等于前一天价格,说明股票价格不变或者下跌,此时我们应该不进行任何操作,继续向后扫描即可 | 5.8 |
+| [121. 买卖股票的最佳时机](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/) | 在买卖股票时,我们应该尽可能地以更低的价格买入,以更高的价格抛售,那么我们在遍历股票价格数组时,可以通过记录当前的最低价格来确保能够以相对较低的价格进行买入,而如果在之后的某个时间找到了更高的股票价格,我们则可以考虑抛售股票并计算利润,维护一个全局的最大利润,不断更新即可。 | 5.8 |
+| [188. 买卖股票的最佳时机 IV](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iv/) | 贪心+DP `dp[i][j] = max(dp[i][j-1], prices[j]-maxDiff)` 第i次卖出,第j天卖出获得的利润,要么是前j-1天的最大利润,要么是这次买出获得的最大的利润,那么就是这次买出的价格-历史低价。更新历史低价,历史低价是这次的买出价格-前i-1次的买出利润。第i天结束时最多完成了j次交易且手上没有股票 = 前一天也没持有股票 /前一天持有股票但在当天卖出。第i天结束时最多完成了j次交易且手上持有股票时的最大收益,可以由前一天也持有股票和前一天没有持有股票但在当天买入两种情况中取较大值得到 | 5.9 |
\ No newline at end of file
diff --git a/_posts/2022-10-02-test-markdown.md b/_posts/2022-10-02-test-markdown.md
new file mode 100644
index 000000000000..efc7a55ca51e
--- /dev/null
+++ b/_posts/2022-10-02-test-markdown.md
@@ -0,0 +1,138 @@
+---
+layout: post
+title: 总结实现带有 callback 的迭代器模式的几个关键点:
+subtitle: 声明 callback 函数类型,以 Record 作为入参。
+tags: [设计模式]
+---
+
+## 总结实现带有 callback 的迭代器模式的几个关键点:
+
+1. 声明 callback 函数类型,以 Record 作为入参。
+2. 定义具体的 callback 函数,比如上述例子中打印记录的 `PrintRecord` 函数。
+3. 定义迭代器创建方法,以 callback 函数作为入参。
+4. 迭代器内,遍历记录时,调用 callback 函数作用在每条记录上。
+5. 客户端创建迭代器时,传入具体的 callback 函数。
+
+```
+package db
+
+import (
+ "fmt"
+)
+
+type callbacktableIteratorImpl struct {
+ rs []record
+}
+
+type Callback func(*record)
+
+func PrintRecord(record *record) {
+ fmt.Printf("%+v\n", record)
+}
+
+func (c *callbacktableIteratorImpl) Iterator(callback Callback) {
+ go func() {
+ for _, re := range c.rs {
+ callback(&re)
+ }
+ }()
+
+}
+
+func (r *callbacktableIteratorImpl) HasNext() bool {
+ return true
+}
+
+// 关键点: 在Next函数中取出下一个记录,并转换成客户端期望的对象类型,记得增加cursor
+func (r *callbacktableIteratorImpl) Next(next interface{}) error {
+
+ return nil
+}
+
+//用工厂模式来创建我们这个复杂的迭代器
+type callbackTableIteratorFactory struct {
+}
+
+func NewcallbackTableIteratorFactory() *complexTableIteratorFactory {
+ return &complexTableIteratorFactory{}
+
+}
+
+func (c *callbackTableIteratorFactory) Create(table *Table) TableIterator {
+ var res []record
+ for _, r := range table.records {
+ res = append(res, r)
+ }
+ return &complextableIteratorImpl{
+ rs: res,
+ }
+}
+
+```
+
+```
+package db
+
+import (
+ "reflect"
+ "testing"
+)
+
+func TestTableCallbackterator(t *testing.T) {
+ iteratorFactory := NewcallbackTableIteratorFactory()
+ // 关键点5: 使用时,直接通过for-range来遍历channel读取记录
+ table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
+ WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdLess))
+ table.Insert(3, &testRegion{Id: 3, Name: "beijing"})
+ table.Insert(1, &testRegion{Id: 1, Name: "shanghai"})
+ table.Insert(2, &testRegion{Id: 2, Name: "guangdong"})
+
+ iterator := iteratorFactory.Create(table)
+ if v, ok := iterator.(*callbacktableIteratorImpl); ok {
+ v.Iterator(PrintRecord)
+
+ }
+}
+
+```
+
+```
+type TableIterator interface {
+ HasNext() bool
+ Next(next interface{}) error
+}
+```
+
+## 迭代器的典型的应用场景
+
+- **对象集合/存储类模块**,并希望向客户端隐藏模块背后的复杂数据结构
+
+ 简单的来说就是,对于复杂的数据集合,一般通过一个`iterator`结构体 来存储复杂的数据集合,并且通过这个`iterator` 提供简单处理数据集合的函数,方法,这样就简化了对复杂数据集合操作,并且,当这个结构体再次作为更复杂的结构体的对象时,更复杂的结构体调用迭代器接口,或者直接调用迭代器的结构体的字段,就可以实现简单的操作复杂数据的集合了。
+
+- ```
+ //简单的来说,应该是这个样子
+ type Table struct{
+ iterator Iterator
+ }
+
+ type Iterator interface {
+ Next()record
+ }
+
+ //commonIterator是具体的迭代器,一般迭代器不会单独的只有一个,所以所有的迭代器构成一个迭代器接口
+ type commonIterator struct{
+ records []record
+ //这里的record是复杂的和数据
+ }
+ func (c *commonIterator) Next()record{
+ //do some thing
+ }
+
+ ```
+
+
+
+- 隐藏模块背后复杂的实现机制,**为客户端提供一个简单易用的接口**。
+- 支持扩展多种遍历方式,具备较强的可扩展性,符合 [开闭原则](https://mp.weixin.qq.com/s/s3aD4mK2Aw4v99tbCIe9HA)。
+- 遍历算法和数据存储分离,符合 [单一职责原则](https://mp.weixin.qq.com/s/s3aD4mK2Aw4v99tbCIe9HA)。
+- 迭代器模式通常会与 [工厂方法模式](https://mp.weixin.qq.com/s/PwHc31ANLDVMNiagtqucZQ) 一起使用,如前文实现。
diff --git a/_posts/2022-10-03-test-markdown.md b/_posts/2022-10-03-test-markdown.md
new file mode 100644
index 000000000000..ed1275eaf8f7
--- /dev/null
+++ b/_posts/2022-10-03-test-markdown.md
@@ -0,0 +1,127 @@
+---
+layout: post
+title: 原型模式(Prototype Pattern)与对象成员变量复制的问题
+subtitle: 核心就是`clone()`方法,返回`Prototype`对象的复制品。
+tags: [设计模式]
+---
+
+## 原型模式(Prototype Pattern)与对象成员变量复制的问题
+
+> 核心就是`clone()`方法,返回`Prototype`对象的复制品。
+>
+> 那么我们可能会这样进行对象的创建:*新创建一个相同对象的实例,然后遍历原始对象的所有成员变量, 并将成员变量值复制到新对象中*。这种方法的缺点很明显,那就是使用者必须知道对象的实现细节,导致代码之间的耦合。另外,对象很有可能存在除了对象本身以外不可见的变量,这种情况下该方法就行不通了。
+
+```
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+type clone interface {
+ clone() clone
+}
+type Message struct {
+ Header *Header
+ Body *Body
+}
+
+func (m *Message) clone() clone {
+ msg := *m
+ return &msg
+
+}
+
+type Header struct {
+ SrcAddr string
+ SrcPort uint64
+ DestAddr string
+ DestPort uint64
+ Items map[string]string
+}
+
+type Body struct {
+ Items []string
+}
+
+func GetMessuage() *Message {
+ return GetBuilder().
+ WithSrcAddr("192.168.0.1").
+ WithSrcPort(1234).
+ WithDestAddr("192.168.0.2").
+ WithDestPort(8080).
+ WithHeaderItem("contents", "application/json").
+ WithBodyItem("record1").
+ WithBodyItem("record2").Build()
+
+}
+
+type builder struct {
+ once *sync.Once
+ msg *Message
+}
+
+func GetBuilder() *builder {
+ return &builder{
+ once: &sync.Once{},
+ msg: &Message{
+ Header: &Header{},
+ Body: &Body{},
+ },
+ }
+}
+
+func (b *builder) WithSrcAddr(addr string) *builder {
+ b.msg.Header.SrcAddr = addr
+ return b
+}
+
+func (b *builder) WithSrcPort(port uint64) *builder {
+ b.msg.Header.SrcPort = port
+ return b
+
+}
+
+func (b *builder) WithDestAddr(addr string) *builder {
+ b.msg.Header.DestAddr = addr
+ return b
+}
+
+func (b *builder) WithDestPort(port uint64) *builder {
+ b.msg.Header.DestPort = port
+ return b
+}
+
+func (b *builder) WithHeaderItem(key, value string) *builder {
+ // 保证map只初始化一次
+ b.once.Do(func() {
+ b.msg.Header.Items = make(map[string]string)
+ })
+ b.msg.Header.Items[key] = value
+ return b
+}
+
+func (b *builder) WithBodyItem(record string) *builder {
+ // 保证map只初始化一次
+ b.msg.Body.Items = append(b.msg.Body.Items, record)
+ return b
+}
+
+func (b *builder) Build() *Message {
+ return b.msg
+}
+
+func main() {
+ msg := GetMessuage()
+ copy := msg.clone()
+ if copy.(*Message).Header.SrcAddr != msg.Header.SrcAddr {
+ fmt.Println("err")
+ } else {
+ fmt.Println("equal")
+ }
+
+}
+
+```
+
diff --git a/_posts/2022-10-04-test-markdown.md b/_posts/2022-10-04-test-markdown.md
new file mode 100644
index 000000000000..44b0284f091f
--- /dev/null
+++ b/_posts/2022-10-04-test-markdown.md
@@ -0,0 +1,898 @@
+---
+layout: post
+title: 观察者模式在网络 Socket 、Http 的应用
+subtitle: 观察者模式
+tags: [设计模式]
+---
+# 观察者模式在网络 Socket 、Http 的应用
+
+
+
+从上图可知,`App` 直接依赖 `http` 模块,而 `http` 模块底层则依赖 socket 模块:
+
+1. 在 `App2` 初始化时,先向 `http` 模块注册一个 `request handler`,处理 `App1` 发送的 `http` 请求。
+2. `http` 模块会将 `request handler` 转换为 `packet handler` 注册到 socket 模块上。
+3. `App 1` 发送 `http` 请求,`http` 模块将请求转换为 `socket packet` 发往 `App 2` 的 socket 模块。
+4. `App 2` 的 socket 模块收到 packet 后,调用 `packet handler` 处理该报文;`packet handler` 又会调用 `App 2` 注册的 `request handler` 处理该请求。
+
+在上述 **`socket - http - app` 三层模型** 中,对 socket 和 `http`,socket 是 Subject,`http` 是 Observer;对 `http 和 app`,`http 是 Subject`,`app 是 Observe`r。
+
+```
+// endpoint.go 代表这一个客户端
+package network
+
+import "strconv"
+
+// Endpoint 值对象,其中ip和port属性为不可变,如果需要变更,需要整对象替换
+type Endpoint struct {
+ ip string
+ port int
+}
+
+// EndpointOf 静态工厂方法,用于实例化对象
+func EndpointOf(ip string, port int) Endpoint {
+ return Endpoint{
+ ip: ip,
+ port: port,
+ }
+}
+
+func EndpointDefaultof(ip string) Endpoint {
+ return Endpoint{
+ ip: ip,
+ port: 80,
+ }
+}
+
+func (e Endpoint) Ip() string {
+ return e.ip
+
+}
+
+func (e Endpoint) Port() int {
+ return e.port
+
+}
+
+func (e Endpoint) String() string {
+ return e.ip + ":" + strconv.Itoa(e.port)
+}
+
+```
+
+```
+// socket.go
+// 从网络包中解析到 endpoint ,每个endpoint 代表一个独立的电脑 ,然后 network 根据network自己的map结构中解析到 这个endpoint对应的socketImpl ,真正的处理网络包裹其实是交给socketImpl 去处理,一旦socketImpl 接收到网络数据包,(也就是我们说的:被观察者的状态发生了变化 )此时socketImpl 去通知自己下面的 listeners 去处理,每一个listener代表一个处理网络数据包的函数
+package network
+
+/*
+观察者模式
+*/
+// socketListener 需要作出反应,就是向上获取数据package network
+// SocketListener Socket报文监听者
+type SocketListener interface {
+ Handle(packet *Packet) error
+}
+
+type Socket interface {
+ Listen(endpoint Endpoint) error
+ Close(endpoint Endpoint)
+ Send(packet *Packet) error
+ Receive(packet *Packet)
+}
+
+// 被观察者在未知的情况下应该先定义一个接口来代表观察者们
+// 被观察者往往应该持有观察者列表
+// socketImpl Socket的默认实现
+type socketImpl struct {
+ // 关键点4: 在Subject中持有Observer的集合
+ listeners []SocketListener
+}
+
+// Listen 在endpoint指向地址上起监听 endpoint资源是暴露一个服务的ip地址和port的列表。(endpoint来自与包裹里面的目的地址)
+func (s *socketImpl) Listen(endpoint Endpoint) error {
+ return GetnetworkInstance().Listen(endpoint, s)
+}
+
+func (s *socketImpl) Close(endpoint Endpoint) {
+ GetnetworkInstance().Disconnect(endpoint)
+
+}
+
+func (s *socketImpl) Send(packet *Packet) error {
+ return GetnetworkInstance().Send(packet)
+}
+
+// 关键点: 为Subject定义注册Observer的方法(为被观察者提供添加观察者的方法)
+func (s *socketImpl) AddListener(listener SocketListener) {
+ s.listeners = append(s.listeners, listener)
+
+}
+
+// 关键点: 当Subject状态变更时,遍历Observers集合,调用它们的更新处理方法
+// 当被观察者的状态发生变化的时候,需要遍历观察者的列表来调用观察者的行为
+// 被观察者一定有一个函数,用来在自己的状态改变时通知观察者们进行一系列的行为
+// 这里的状态改变(就是被观察者收到外界来的实参)
+func (s *socketImpl) Receive(packet *Packet) {
+ for _, listener := range s.listeners {
+ listener.Handle(packet)
+ }
+
+}
+
+```
+
+```
+// network.go
+package network
+
+import (
+ "errors"
+ "sync"
+)
+
+/*
+单例模式
+*/
+// 往网络的作用就是在多个地址上发起多个socket监听
+// 所以我们需要一个map结构来存储这种状态
+type network struct {
+ sockets sync.Map
+}
+
+// 懒汉版单例模式
+var networkInstance = &network{
+ sockets: sync.Map{},
+}
+
+func GetnetworkInstance() *network {
+ return networkInstance
+}
+
+// Listen 在endpoint指向地址上起监听 endpoint资源是暴露一个服务的ip地址和port的列表。
+// 监听的本质就是把目的地址和对目的地址的连接添加到网络的map存储结构当中
+// 用于socktImpl来调用
+// 这里的endpoint 是网络包里的目的地址,而socket里面存储的是目的地址对应的socket
+func (n *network) Listen(endpoint Endpoint, socket Socket) error {
+ if _, ok := n.sockets.Load(endpoint); ok {
+ return errors.New("ErrEndpointAlreadyListened")
+ }
+ n.sockets.Store(endpoint, socket)
+ return nil
+}
+
+// 用于socktImpl来调用
+func (n *network) Disconnect(endpoint Endpoint) {
+ n.sockets.Delete(endpoint)
+
+}
+
+// 用于socktImpl来调用
+func (n *network) DisconnectAll() {
+ n.sockets = sync.Map{}
+
+}
+
+// 网络的发送作用就是 向目的地址发送包裹
+// 包裹中含有目的地址和数据
+// 应该先在map中根据目的地址获取到连接,然后才能向连接发送数据
+// 向连接发送数据的本质就是 这个连接去接收到数据
+func (n *network) Send(packet *Packet) error {
+ con, okc := n.sockets.Load(packet.Dest())
+ socket, oks := con.(Socket)
+ if !okc || !oks {
+ return errors.New("ErrConnectionRefuse")
+ }
+ go socket.Receive(packet)
+ return nil
+}
+
+/*
+// 其余单例模式实现
+
+type network struct {}
+var once sync.Once
+var netnetworkInstance *network
+func GetnetworkInstance() *network {
+ once.Do(func (){
+ netnetworkInstance=&network {
+
+ }
+
+ })
+ return netnetworkInstance
+
+}
+
+*/
+
+```
+
+```
+// packet.go
+// 网络数据包的存储结构
+package network
+
+//一个网络包裹包括一个源ip地址和端口 和目的地址ip和端口
+type Packet struct {
+ src Endpoint
+ dest Endpoint
+ payload interface{}
+}
+
+func NewPacket(src, dest Endpoint, payload interface{}) *Packet {
+ return &Packet{
+ src: src,
+ dest: dest,
+ payload: payload,
+ }
+}
+
+//返回源地址
+func (p Packet) Src() Endpoint {
+ return p.src
+}
+
+//返回目的地址
+func (p Packet) Dest() Endpoint {
+ return p.dest
+}
+
+func (p Packet) Payload() interface{} {
+ return p.payload
+}
+
+```
+
+```
+http/http_client.go
+package http
+
+import (
+ "errors"
+ "github.com/Design-Pattern-Go-Implementation/network"
+ "math/rand"
+ "time"
+)
+
+// 观察者包含被观察者就可以封装被观察者,调用被观察者
+// 一般来说,观察者往往是用户,所以如果观察者存储有被观察者,那么就可以调用被观察者的接口实现一系列操作,
+// 而对对于网络来说,更像是两个被观察者在面对面交谈,而实际用户(观察者)因为保存有被观察者因而看起来像很多观察者面对面交流
+type Client struct {
+ // 接收网络数据包并且
+ socket network.Socket
+ // 把处理的结果写入到一个channel中,因为处理结果是有数据的
+ respChan chan *Response
+ // 代表者自己的的ip地址和端口
+ localEndpoint network.Endpoint
+}
+
+// 通过本机的ip 以及随即生成一个端口,代表本机的这个端口下的程序
+func NewClient(socket network.Socket, ip string) (*Client, error) {
+ // 一个观察者肯定有一个被观察者需要他去观察
+ // 一个client 肯定有一个 ip 代表自己要访问的
+ // 随机端口,从10000 ~ 19999
+ endpoint := network.EndpointOf(ip, int(rand.Uint32()%10000+10000))
+ client := &Client{
+ socket: socket,
+ localEndpoint: endpoint,
+ respChan: make(chan *Response),
+ }
+ // 一个观察者开始观察一个(被观察者)的时候,
+ // 也就意味着被观察者的监听列表肯定要把这个观察者加入它的列表
+ // 二者是同步的
+ client.socket.AddListener(client)
+ // 把本机器的socketImpl 添加到全局唯一一个的且被共享的网络实例
+ if err := client.socket.Listen(endpoint); err != nil {
+ return nil, err
+ }
+ return client, nil
+}
+
+func (c *Client) Close() {
+ //从全局的网络中删除
+ c.socket.Close(c.localEndpoint)
+ close(c.respChan)
+}
+
+// 底层调用network的Send 然后网络是根据网络包中目的地址 一下子得到目的地址对应的
+func (c *Client) Send(dest network.Endpoint, req *Request) (*Response, error) {
+ // 制作网络包 网络包包含着目的endpoint 通过目的endpoint可以在网络中查到对应的socketImpl(被观察者)
+ // req是携带的数据
+ packet := network.NewPacket(c.localEndpoint, dest, req)
+ // 通过底层调用network.Send()
+ // network.Send()就是根据网络数据包的目的地址得到对应的socketImpl
+ // 然后把数据发给socketImpl ,socketImpl 一旦接收到数据,就是调用自己listeners的也就是client去处理
+ err := c.socket.Send(packet)
+ if err != nil {
+ return nil, err
+ }
+ // 发送请求后同步阻塞等待响应
+ select {
+ case resp, ok := <-c.respChan:
+ if ok {
+ return resp, nil
+ }
+ errResp := ResponseOfId(req.ReqId()).AddStatusCode(StatusInternalServerError).
+ AddProblemDetails("connection is break")
+ return errResp, nil
+ case <-time.After(time.Second * time.Duration(3)):
+ // 超时时间为3s
+ resp := ResponseOfId(req.ReqId()).AddStatusCode(StatusGatewayTimeout).
+ AddProblemDetails("http server response timeout")
+ return resp, nil
+ }
+}
+
+//
+func (c *Client) Handle(packet *network.Packet) error {
+ resp, ok := packet.Payload().(*Response)
+ if !ok {
+ return errors.New("invalid packet, not http response")
+ }
+ c.respChan <- resp
+ return nil
+}
+
+```
+
+```
+http/server.go
+
+package http
+
+import (
+ "errors"
+ "github.com/Design-Pattern-Go-Implementation/network"
+)
+
+// Handler HTTP请求处理接口
+type Handler func(req *Request) *Response
+
+// Server Http服务器
+type Server struct {
+ socket network.Socket
+ localEndpoint network.Endpoint
+ routers map[Method]map[Uri]Handler
+}
+
+func NewServer(socket network.Socket) *Server {
+ server := &Server{
+ socket: socket,
+ routers: make(map[Method]map[Uri]Handler),
+ }
+ server.socket.AddListener(server)
+ return server
+}
+
+// 实现 Handle 方法才能被添加到listeners中
+// Server处理的是请求数据包
+// Client处理的是响应数据包
+// 请求数据包的路径 Client 发出请求数据包 ——> Network拿到请求数据包 ———> Network把请求数据包给到 Server (Server拿到请求数据包)
+// 响应数据包的处理 Sever拿到请求处理包处理得到响应数据包 ————> Server 把响应数据包给到Network ————> network 拿到响应数据包 然后把响应数据包给Client ————> client拿到响应数据包
+func (s *Server) Handle(packet *network.Packet) error {
+ req, ok := packet.Payload().(*Request)
+ if !ok {
+ return errors.New("invalid packet, not http request")
+ }
+ if req.IsInValid() {
+ resp := ResponseOfId(req.ReqId()).
+ AddStatusCode(StatusBadRequest).
+ AddProblemDetails("uri or method is invalid")
+ return s.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), resp))
+ }
+
+ router, ok := s.routers[req.Method()]
+ if !ok {
+ resp := ResponseOfId(req.ReqId()).
+ AddStatusCode(StatusMethodNotAllow).
+ AddProblemDetails(StatusMethodNotAllow.Details)
+ return s.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), resp))
+ }
+
+ var handler Handler
+ //得到所有的路由,然后把所有的路由和请求网络包中的携带的要请求的路由进行匹配
+ for u, h := range router {
+ if req.Uri().Contains(u) {
+ handler = h
+ break
+ }
+ }
+
+ if handler == nil {
+ resp := ResponseOfId(req.ReqId()).
+ AddStatusCode(StatusNotFound).
+ AddProblemDetails("can not find handler of uri")
+ return s.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), resp))
+ }
+
+ resp := handler(req)
+ return s.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), resp))
+}
+
+func (s *Server) Listen(ip string, port int) *Server {
+ s.localEndpoint = network.EndpointOf(ip, port)
+ return s
+}
+
+func (s *Server) Start() error {
+ return s.socket.Listen(s.localEndpoint)
+}
+
+func (s *Server) Shutdown() {
+ s.socket.Close(s.localEndpoint)
+}
+
+func (s *Server) Get(uri Uri, handler Handler) *Server {
+ if _, ok := s.routers[GET]; !ok {
+ s.routers[GET] = make(map[Uri]Handler)
+ }
+ s.routers[GET][uri] = handler
+ return s
+}
+
+func (s *Server) Post(uri Uri, handler Handler) *Server {
+ if _, ok := s.routers[POST]; !ok {
+ s.routers[POST] = make(map[Uri]Handler)
+ }
+ s.routers[POST][uri] = handler
+ return s
+}
+
+func (s *Server) Put(uri Uri, handler Handler) *Server {
+ if _, ok := s.routers[PUT]; !ok {
+ s.routers[PUT] = make(map[Uri]Handler)
+ }
+ s.routers[PUT][uri] = handler
+ return s
+}
+
+func (s *Server) Delete(uri Uri, handler Handler) *Server {
+ if _, ok := s.routers[DELETE]; !ok {
+ s.routers[DELETE] = make(map[Uri]Handler)
+ }
+ s.routers[DELETE][uri] = handler
+ return s
+}
+
+```
+
+```
+//request.go
+package http
+
+import (
+ "math/rand"
+ "strings"
+)
+
+type Method uint8
+
+const (
+ GET Method = iota + 1
+ POST
+ PUT
+ DELETE
+)
+
+type Uri string
+
+func (u Uri) Contains(other Uri) bool {
+ return strings.Contains(string(u), string(other))
+}
+
+type ReqId uint32
+
+type Request struct {
+ reqId ReqId
+ method Method
+ uri Uri
+ queryParams map[string]string
+ headers map[string]string
+ body interface{}
+}
+
+func EmptyRequest() *Request {
+ reqId := rand.Uint32() % 10000
+ return &Request{
+ reqId: ReqId(reqId),
+ uri: "",
+ queryParams: make(map[string]string),
+ headers: make(map[string]string),
+ }
+}
+
+// Clone 原型模式,其中reqId重新生成,其他都拷贝原来的值
+func (r *Request) Clone() *Request {
+ reqId := rand.Uint32() % 10000
+ return &Request{
+ reqId: ReqId(reqId),
+ method: r.method,
+ uri: r.uri,
+ queryParams: r.queryParams,
+ headers: r.headers,
+ body: r.body,
+ }
+}
+
+func (r *Request) IsInValid() bool {
+ return r.method < 1 || r.method > 4 || r.uri == ""
+}
+
+func (r *Request) AddMethod(method Method) *Request {
+ r.method = method
+ return r
+}
+
+func (r *Request) AddUri(uri Uri) *Request {
+ r.uri = uri
+ return r
+}
+
+func (r *Request) AddQueryParam(key, value string) *Request {
+ r.queryParams[key] = value
+ return r
+}
+
+func (r *Request) AddQueryParams(params map[string]string) *Request {
+ for k, v := range params {
+ r.queryParams[k] = v
+ }
+ return r
+}
+
+func (r *Request) AddHeader(key, value string) *Request {
+ r.headers[key] = value
+ return r
+}
+
+func (r *Request) AddHeaders(headers map[string]string) *Request {
+ for k, v := range headers {
+ r.headers[k] = v
+ }
+ return r
+}
+
+func (r *Request) AddBody(body interface{}) *Request {
+ r.body = body
+ return r
+}
+
+func (r *Request) ReqId() ReqId {
+ return r.reqId
+}
+
+func (r *Request) Method() Method {
+ return r.method
+}
+
+func (r *Request) Uri() Uri {
+ return r.uri
+}
+
+func (r *Request) QueryParams() map[string]string {
+ return r.queryParams
+}
+
+func (r *Request) QueryParam(key string) (string, bool) {
+ value, ok := r.queryParams[key]
+ return value, ok
+}
+
+func (r *Request) Headers() map[string]string {
+ return r.headers
+}
+
+func (r *Request) Header(key string) (string, bool) {
+ value, ok := r.headers[key]
+ return value, ok
+}
+
+func (r *Request) Body() interface{} {
+ return r.body
+}
+
+```
+
+```
+// response.go
+package http
+
+type StatusCode struct {
+ Code uint32
+ Details string
+}
+
+var (
+ StatusOk = StatusCode{Code: 200, Details: "OK"}
+ StatusCreate = StatusCode{Code: 201, Details: "Create"}
+ StatusNoContent = StatusCode{Code: 204, Details: "No Content"}
+ StatusBadRequest = StatusCode{Code: 400, Details: "Bad Request"}
+ StatusNotFound = StatusCode{Code: 404, Details: "Not Found"}
+ StatusMethodNotAllow = StatusCode{Code: 405, Details: "Method Not Allow"}
+ StatusTooManyRequest = StatusCode{Code: 429, Details: "Too Many Request"}
+ StatusInternalServerError = StatusCode{Code: 500, Details: "Internal Server Error"}
+ StatusGatewayTimeout = StatusCode{Code: 504, Details: "Gateway Timeout"}
+)
+
+type Response struct {
+ reqId ReqId
+ statusCode StatusCode
+ headers map[string]string
+ body interface{}
+ problemDetails string
+}
+
+func ResponseOfId(reqId ReqId) *Response {
+ return &Response{
+ reqId: reqId,
+ headers: make(map[string]string),
+ }
+}
+
+func (r *Response) Clone() *Response {
+ return &Response{
+ reqId: r.reqId,
+ statusCode: r.statusCode,
+ headers: r.headers,
+ body: r.body,
+ problemDetails: r.problemDetails,
+ }
+}
+
+func (r *Response) AddReqId(reqId ReqId) *Response {
+ r.reqId = reqId
+ return r
+}
+
+func (r *Response) AddStatusCode(statusCode StatusCode) *Response {
+ r.statusCode = statusCode
+ return r
+}
+
+func (r *Response) AddHeader(key, value string) *Response {
+ r.headers[key] = value
+ return r
+}
+
+func (r *Response) AddHeaders(headers map[string]string) *Response {
+ for k, v := range headers {
+ r.headers[k] = v
+ }
+ return r
+}
+
+func (r *Response) AddBody(body interface{}) *Response {
+ r.body = body
+ return r
+}
+
+func (r *Response) AddProblemDetails(details string) *Response {
+ r.problemDetails = details
+ return r
+}
+
+func (r *Response) ReqId() ReqId {
+ return r.reqId
+}
+
+func (r *Response) StatusCode() StatusCode {
+ return r.statusCode
+}
+
+func (r *Response) Headers() map[string]string {
+ return r.headers
+}
+
+func (r *Response) Header(key string) (string, bool) {
+ value, ok := r.headers[key]
+ return value, ok
+}
+
+func (r *Response) Body() interface{} {
+ return r.body
+}
+
+func (r *Response) ProblemDetails() string {
+ return r.problemDetails
+}
+
+// IsSuccess 如果status code为2xx,返回true,否则,返回false
+func (r *Response) IsSuccess() bool {
+ return r.StatusCode().Code/100 == 2
+}
+
+```
+
+# 装饰者模式与middleware 功能的实现
+
+> 装饰者模式通过**组合**的方式,提供了**能够动态地给对象/模块扩展新功能**
+
+> 如果写过 Java,那么一定对 I/O Stream 体系不陌生,它是装饰者模式的经典用法,客户端程序可以动态地为原始的输入输出流添加功能,比如按字符串输入输出,加入缓冲等,使得整个 I/O Stream 体系具有很高的可扩展性和灵活性
+
+设计了 Sidecar 边车模块,它的用处主要是为了 1)方便扩展 `network.Socket` 的功能,如增加日志、流控等非业务功能;2)让这些附加功能对业务程序隐藏起来,也即业务程序只须关心看到 `network.Socket` 接口即可。
+
+
+
+
+
+```
+package http
+
+import (
+ "context"
+ "log"
+ "net/http"
+ "time"
+)
+
+// 关键点1: 确定被装饰者接口,这里为原生的http.HandlerFunc
+// type HandlerFunc func(ResponseWriter, *Request)
+
+// HttpHandlerFuncDecorator
+// 关键点2: 定义装饰器类型,是一个函数类型,入参和返回值都是 http.HandlerFunc 函数
+type HttpHandlerFuncDecorator func(http.HandlerFunc) http.HandlerFunc
+
+// Decorate
+// 关键点3: 定义装饰方法,入参为被装饰的接口和装饰器可变列表
+func Decorate(h http.HandlerFunc, decorators ...HttpHandlerFuncDecorator) http.HandlerFunc {
+ // 关键点4: 通过for循环遍历装饰器,完成对被装饰接口的装饰
+ for _, decorator := range decorators {
+ h = decorator(h)
+ }
+
+ ctx := context.Background()
+ ctx, _ = context.WithCancel(ctx)
+ ctx, _ = context.WithTimeout(ctx, time.Duration(1))
+ ctx = context.WithValue(ctx, "key", "value")
+ return h
+}
+
+// WithBasicAuth
+// 关键点5: 实现具体的装饰器
+func WithBasicAuth(h http.HandlerFunc) http.HandlerFunc {
+ return func(w http.ResponseWriter, r *http.Request) {
+ cookie, err := r.Cookie("Auth")
+ if err != nil || cookie.Value != "Pass" {
+ w.WriteHeader(http.StatusForbidden)
+ return
+ }
+ // 关键点6: 完成功能扩展之后,调用被装饰的方法,才能将所有装饰器和被装饰者串起来
+ h(w, r)
+ }
+}
+
+func WithLogger(h http.HandlerFunc) http.HandlerFunc {
+ return func(w http.ResponseWriter, r *http.Request) {
+ log.Println(r.Form)
+ log.Printf("path %s", r.URL.Path)
+ h(w, r)
+ }
+}
+
+func hello(w http.ResponseWriter, r *http.Request) {
+ w.Write([]byte("hello, world"))
+}
+
+```
+
+```
+func main() {
+ // 关键点7: 通过Decorate方法完成对hello对装饰
+ http.HandleFunc("/hello", Decorate(hello, WithLogger, WithBasicAuth))
+ // 启动http服务器
+ http.ListenAndServe("localhost:8080", nil)
+}
+```
+
+# (补充)边车模式
+
+> 所谓的边车模式,对应于我们生活中熟知的边三轮摩托车。也就是说,我们可以通过给一个摩托车加上一个边车的方式来扩展现有的服务和功能。这样可以很容易地做到 " 控制 " 和 " 逻辑 " 的分离。
+>
+> 也就是说,我们不需要在服务中实现控制面上的东西,如监视、日志记录、限流、熔断、服务注册、协议适配转换等这些属于控制面上的东西,而只需要专注地做好和业务逻辑相关的代码,然后,由 " 边车 " 来实现这些与业务逻辑没有关系的控制功能。
+
+边车模式设计
+
+具体来说,可以理解为,边车就有点像一个服务的 Agent,这个服务所有对外的进出通讯都通过这个 Agent 来完成。这样,我们就可以在这个 Agent 上做很多文章了。但是,我们需要保证的是,这个 Agent 要和应用程序一起创建,一起停用。
+
+边车模式有时候也叫搭档模式,或是伴侣模式,或是跟班模式。就像我们在《编程范式游记》中看到的那样,编程的本质就是将控制和逻辑分离和解耦,而边车模式也是异曲同工,同样是让我们在分布式架构中做到逻辑和控制分离。
+
+
+
+对于像 " 监视、日志、限流、熔断、服务注册、协议转换……" 这些功能,其实都是大同小异,甚至是完全可以做成标准化的组件和模块的。一般来说,我们有两种方式。
+
+- 一种是通过 SDK、Lib 或 Framework 软件包方式,在开发时与真实的应用服务集成起来。
+- 另一种是通过像 Sidecar 这样的方式,在运维时与真实的应用服务集成起来。
+
+这两种方式各有优缺点。
+
+- 以软件包的方式可以和应用密切集成,有利于资源的利用和应用的性能,但是对应用有侵入,而且受应用的编程语言和技术限制。同时,当软件包升级的时候,需要重新编译并重新发布应用。
+- 以 Sidecar 的方式,对应用服务没有侵入性,并且不用受到应用服务的语言和技术的限制,而且可以做到控制和逻辑的分开升级和部署。但是,这样一来,增加了每个应用服务的依赖性,也增加了应用的延迟,并且也会大大增加管理、托管、部署的复杂度。
+
+注意,对于一些 " 老的系统 ",因为代码太老,改造不过来,我们又没有能力重写。比如一些银行里的很老的用 C 语言或是 COBAL 语言写的子系统,我们想把它们变成分布式系统,需要对其进行协议的改造以及进行相应的监控和管理。这个时候,Sidecar 的方式就很有价值了。因为没有侵入性,所以可以很快地低风险地改造.
+
+Sidecar 服务在逻辑上和应用服务部署在一个结点中,其和应用服务有相同的生命周期。对比于应用程序的每个实例,都会有一个 Sidecar 的实例。Sidecar 可以很快也很方便地为应用服务进行扩展,而不需要应用服务的改造。比如:
+
+- Sidecar 可以帮助服务注册到相应的服务发现系统,并对服务做相关的健康检查。如果服务不健康,我们可以从服务发现系统中把服务实例移除掉。
+
+- 当应用服务要调用外部服务时, Sidecar 可以帮助从服务发现中找到相应外部服务的地址,然后做服务路由。
+
+- Sidecar 接管了进出的流量,我们就可以做相应的日志监视、调用链跟踪、流控熔断……这些都可以放在 Sidecar 里实现。
+
+- 然后,服务控制系统可以通过控制 Sidecar 来控制应用服务,如流控、下线等。
+
+
+
+如果把 Sidecar 这个实例和应用服务部署在同一台机器中,那么,其实 Sidecar 的进程在理论上来说是可以访问应用服务的进程能访问的资源的。比如,Sidecar 是可以监控到应用服务的进程信息的。另外,因为两个进程部署在同一台机器上,所以两者之间的通信不存在明显的延迟。也就是说,服务的响应延迟虽然会因为跨进程调用而增加,但这个增加完全是可以接受的。
+
+另外,我们可以看到这样的部署方式,最好是与 Docker 容器的方式一起使用的。为什么 Docker 一定会是分布式系统或是云计算的关键技术,相信从我的这一系列文章中已经看到其简化架构的部署和管理的重要作用。否则,这么多的分布式架构模式实施起来会有很多麻烦。
+
+### 边车设计的重点
+
+首先,我们要知道边车模式重点解决什么样的问题。
+
+1. 控制和逻辑的分离。
+2. 服务调用中上下文的问题。
+
+我们知道,熔断、路由、服务发现、计量、流控、监视、重试、幂等、鉴权等控制面上的功能,以及其相关的配置更新,本质来上来说,和服务的关系并不大。但是传统的工程做法是在开发层面完成这些功能,这就会导致各种维护上的问题,而且还会受到特定语言和编程框架的约束和限制。
+
+而随着系统架构的复杂化和扩张,我们需要更统一地管理和控制这些控制面上的功能,所以传统的在开发层面上完成控制面的管理会变得非常难以管理和维护。这使得我们需要通过 Sidecar 模式来架构我们的系统
+
+###### 边车模式从概念上理解起来比较简单,但是在工程实现上来说,需要注意以下几点。
+
+- 进程间通讯机制是这个设计模式的重点,千万不要使用任何对应用服务有侵入的方式,比如,通过信号的方式,或是通过共享内存的方式。最好的方式就是网络远程调用的方式(因为都在 127.0.0.1 上通讯,所以开销并不明显)。
+- 服务协议方面,也请使用标准统一的方式。这里有两层协议,一个是 Sidecar 到 service 的内部协议,另一个是 Sidecar 到远端 Sidecar 或 service 的外部协议。对于内部协议,需要尽量靠近和兼容本地 service 的协议;对于外部协议,需要尽量使用更为开放更为标准的协议。但无论是哪种,都不应该使用与语言相关的协议。
+- 使用这样的模式,需要在服务的整体打包、构建、部署、管控、运维上设计好。使用 Docker 容器方面的技术可以帮助全面降低复杂度
+- Sidecar 中所实现的功能应该是控制面上的东西,而不是业务逻辑上的东西,所以请尽量不要把业务逻辑设计到 Sidecar 中。
+- 小心在 Sidecar 中包含通用功能可能带来的影响。例如,重试操作,这可能不安全,除非所有操作都是幂等的。
+- 另外,我们还要考虑允许应用服务和 Sidecar 的上下文传递的机制。 例如,包含 HTTP 请求标头以选择退出重试,或指定最大重试次数等等这样的信息交互。或是 Sidecar 告诉应用服务限流发生,或是远程服务不可用等信息,这样可以让应用服务和 Sidecar 配合得更好。
+- 我们要清楚 Sidecar 适用于什么样的场景,下面罗列几个。
+- 一个比较明显的场景是对老应用系统的改造和扩展。
+- 另一个是对由多种语言混合出来的分布式服务系统进行管理和扩展。
+- 其中的应用服务由不同的供应商提供。
+- 把控制和逻辑分离,标准化控制面上的动作和技术,从而提高系统整体的稳定性和可用性。也有利于分工——并不是所有的程序员都可以做好控制面上的开发的。
+- 我们还要清楚 Sidecar 不适用于什么样的场景,下面罗列几个。
+- 架构并不复杂的时候,不需要使用这个模式,直接使用 API Gateway 或者 Nginx 和 HAProxy 等即可。
+- 服务间的协议不标准且无法转换。
+- 不需要分布式的架构。
+
+# (补充)网关模式
+
+前面,我们讲了 Sidecar 和 Service Mesh 这两个设计模式,这两种设计模式都是在不侵入业务逻辑的情况下,把控制面(control plane)和数据面(data plane)的处理解耦分离。但是这两种模式都让我们的运维成本变得特别大,因为每个服务都需要一个 Sidecar,这让本来就复杂的分布式系统的架构就更为复杂和难以管理了。
+
+在谈 Service Mesh 的时候,我们提到了 Gateway。我个人觉得并不需要为每个服务的实例都配置上一个 Sidecar。其实,一个服务集群配上一个 Gateway 就可以了,或是一组类似的服务配置上一个 Gateway。
+
+这样一来,Gateway 方式下的架构,可以细到为每一个服务的实例配置上一个自己的 Gateway,也可以粗到为一组服务配置一个,甚至可以粗到为整个架构配置一个接入的 Gateway。于是,整个系统架构的复杂度就会变得简单可控起来。
+
+这张图展示了一个多层 Gateway 架构,其中有一个总的 Gateway 接入所有的流量,并分发给不同的子系统,还有第二级 Gateway 用于做各个子系统的接入 Gateway。可以看到,网关所管理的服务粒度可粗可细。通过网关,我们可以把分布式架构组织成一个星型架构,由网络对服务的请求进行路由和分发,也可以架构成像 Servcie Mesh 那样的网格架构,或者只是为了适配某些服务的 Sidecar……
+
+但是,我们也可以看到,这样一来,Sidecar 就不再那么轻量了,而且很有可能会变得比较重了。
+
+总的来说,Gateway 是一个服务器,也可以说是进入系统的唯一节点。这跟面向对象设计模式中的 Facade 模式很像。Gateway 封装内部系统的架构,并且提供 API 给各个客户端。它还可能有其他功能,如授权、监控、负载均衡、缓存、熔断、降级、限流、请求分片和管理、静态响应处理,等等。
+
+下面,我们来谈谈一个好的网关应该有哪些设计功能
+
+#### 网关模式设计
+
+一个网关需要有以下的功能。
+
+- **请求路由**。因为不再是 Sidecar 了,所以网关必需要有请求路由的功能。这样一来,对于调用端来说,也是一件非常方便的事情。因为调用端不需要知道自己需要用到的其它服务的地址,全部统一地交给 Gateway 来处理。
+- **服务注册**。为了能够代理后面的服务,并把请求路由到正确的位置上,网关应该有服务注册功能,也就是后端的服务实例可以把其提供服务的地址注册、取消注册。一般来说,注册也就是注册一些 API 接口。比如,HTTP 的 Restful 请求,可以注册相应的 `API` 的 `URI`、方法、`HTTP` 头。 这样,Gateway 就可以根据接收到的请求中的信息来决定路由到哪一个后端的服务上。
+- **负载均衡**。因为一个网关可以接多个服务实例,所以网关还需要在各个对等的服务实例上做负载均衡策略。简单的就直接是 round robin 轮询,复杂点的可以设置上权重进行分发,再复杂一点还可以做到 session 粘连。
+- **弹力设计**。网关还可以把弹力设计中的那些异步、重试、幂等、流控、熔断、监视等都可以实现进去。这样,同样可以像 Service Mesh 那样,让应用服务只关心自己的业务逻辑(或是说数据面上的事)而不是控制逻辑(控制面)
+- **安全方面**。SSL 加密及证书管理、Session 验证、授权、数据校验,以及对请求源进行恶意攻击的防范。错误处理越靠前的位置就是越好,所以,网关可以做到一个全站的接入组件来对后端的服务进行保护
+- **灰度发布**。网关完全可以做到对相同服务不同版本的实例进行导流,并还可以收集相关的数据。这样对于软件质量的提升,甚至产品试错都有非常积极的意义。
+- **API 聚合**。使用网关可将多个单独请求聚合成一个请求。在微服务体系的架构中,因为服务变小了,所以一个明显的问题是,客户端可能需要多次请求才能得到所有的数据。这样一来,客户端与后端之间的频繁通信会对应用程序的性能和规模产生非常不利的影响。于是,我们可以让网关来帮客户端请求多个后端的服务(有些场景下完全可以并发请求),然后把后端服务的响应结果拼装起来,回传给客户端(当然,这个过程也可以做成异步的,但这需要客户端的配合)。
+- **API 编排**。同样在微服务的架构下,要走完一个完整的业务流程,我们需要调用一系列 API,就像一种工作流一样,这个事完全可以通过网页来编排这个业务流程。我们可能通过一个 DSL 来定义和编排不同的 API,也可以通过像 AWS Lambda 服务那样的方式来串联不同的 API
+
+# Gateway、Sidecar 和 Service Mesh
+
+通过上面的描述,我们可以看到,网关、边车和 Service Mesh 是非常像的三种设计模式,很容易混淆。因此,我在这里想明确一下这三种设计模式的特点、场景和区别。
+
+首先,Sidecar 的方式主要是用来改造已有服务。我们知道,要在一个架构中实施一些架构变更时,需要业务方一起过来进行一些改造。然而业务方的事情比较多,像架构上的变更会低优先级处理,这就导致架构变更的 " 政治复杂度 " 太大。而通过 Sidecar 的方式,我们可以适配应用服务,成为应用服务进出请求的代理。这样,我们就可以干很多对于业务方完全透明的事情了。
+
+当 Sidecar 在架构中越来越多时,需要我们对 Sidecar 进行统一的管理。于是,我们为 Sidecar 增加了一个全局的中心控制器,就出现了我们的 Service Mesh。在中心控制器出现以后,我们发现,可以把非业务功能的东西全部实现在 Sidecar 和 Controller 中,于是就成了一个网格。业务方只需要把服务往这个网格中一放就好了,与其它服务的通讯、服务的弹力等都不用管了,像一个服务的 PaaS 平台。
+
+然而,Service Mesh 的架构和部署太过于复杂,会让我们运维层面上的复杂度变大。为了简化这个架构的复杂度,我认为 Sidecar 的粒度应该是可粗可细的,这样更为方便。但我认为,Gateway 更为适合,而且 Gateway 只负责进入的请求,不像 Sidecar 还需要负责对外的请求。因为 Gateway 可以把一组服务给聚合起来,所以服务对外的请求可以交给对方服务的 Gateway。于是,我们只需要用一个只负责进入请求的 Gateway 来简化需要同时负责进出请求的 Sidecar 的复杂度。
+
+总而言之,我觉得 Gateway 的方式比 Sidecar 和 Service Mesh 更好。当然,具体问题还要具体分析。
diff --git a/_posts/2022-10-05-test-markdown.md b/_posts/2022-10-05-test-markdown.md
new file mode 100644
index 000000000000..5e48cea18816
--- /dev/null
+++ b/_posts/2022-10-05-test-markdown.md
@@ -0,0 +1,366 @@
+---
+layout: post
+title: 工厂方法模式(Factory Method Pattern)与复杂对象的初始化
+subtitle: 将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口
+tags: [Microservices gateway ]
+---
+## 工厂方法模式(Factory Method Pattern)与复杂对象的初始化
+
+### 注意事项:
+
+- (1)工厂方法模式跟上一节讨论的建造者模式类似,都是**将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口**。两者在应用场景上稍有区别,建造者模式更常用于需要传递多个参数来进行实例化的场景。
+- (2)**代码可读性更好**。相比于使用C++/Java中的构造函数,或者Go中的`{}`来创建对象,工厂方法因为可以通过函数名来表达代码含义,从而具备更好的可读性。比如,使用工厂方法`productA := CreateProductA()`创建一个`ProductA`对象,比直接使用`productA := ProductA{}`的可读性要好
+- (3)**与使用者代码解耦**。很多情况下,对象的创建往往是一个容易变化的点,通过工厂方法来封装对象的创建过程,可以在创建逻辑变更时,避免**霰弹式修改**
+
+### 实现方式:
+
+- 工厂方法模式也有两种实现方式:
+- (1)提供一个工厂对象,通过调用工厂对象的工厂方法来创建产品对象;
+- (2)将工厂方法集成到产品对象中(C++/Java中对象的`static`方法,Go中同一`package`下的函数
+
+```
+package aranatest
+
+type Type uint8
+
+// 事件类型定义
+const (
+ Start Type = iota
+ End
+)
+
+// 事件抽象接口
+type Event interface {
+ EventType() Type
+ Content() string
+}
+
+// 开始事件,实现了Event接口
+type StartEvent struct {
+ content string
+}
+
+func (s *StartEvent) EventType() Type {
+ return Start
+}
+func (s *StartEvent) Content() string {
+ return "start"
+}
+
+// 结束事件,实现了Event接口
+type EndEvent struct {
+ content string
+}
+
+func (s *EndEvent) EventType() Type {
+ return End
+}
+
+func (s *EndEvent) Content() string {
+ return "end"
+
+}
+
+type factroy struct {
+}
+
+func (f *factroy) Create(b Type) Event {
+ switch b {
+ case Start:
+ return &StartEvent{}
+ case End:
+ return &EndEvent{}
+ default:
+ return nil
+ }
+
+}
+
+```
+
+- 工厂方法首先知道所有的产品类型,并且每个产品需要一个属性需要来标志,而且所有的产品需要统一返回一个接口类型,并且这些产品都需要实现这个接口,这个接口下面肯定有一个方法来获取产品的类型的参数。
+
+
+
+- 另外一种实现方法是:给每种类型提供一个工厂方法
+
+```
+package aranatest
+
+type Type uint8
+
+// 事件类型定义
+const (
+ Start Type = iota
+ End
+)
+
+// 事件抽象接口
+type Event interface {
+ EventType() Type
+ Content() string
+}
+
+// 开始事件,实现了Event接口
+type StartEvent struct {
+ content string
+}
+
+func (s *StartEvent) EventType() Type {
+ return Start
+}
+func (s *StartEvent) Content() string {
+ return "start"
+}
+
+// 结束事件,实现了Event接口
+type EndEvent struct {
+ content string
+}
+
+func (s *EndEvent) EventType() Type {
+ return End
+}
+
+func (s *EndEvent) Content() string {
+ return "end"
+
+}
+
+type factroy struct {
+}
+
+func (f *factroy) Create(b Type) Event {
+ switch b {
+ case Start:
+ return &StartEvent{}
+ case End:
+ return &EndEvent{}
+ default:
+ return nil
+ }
+
+}
+
+```
+
+```
+package aranatest
+
+import "testing"
+
+func TestProduct(t *testing.T) {
+ s := OfStart()
+ if s.GetContent() != "start" {
+ t.Errorf("get%s want %s", s.GetContent(), "start")
+ }
+
+ e := OfEnd()
+ if e.GetContent() != "end" {
+ t.Errorf("get%s want %s", e.GetContent(), "end")
+ }
+
+}
+
+```
+
+
+
+## 抽象工厂模式 和 单一职责原则的矛盾
+
+> 抽象工厂模式通过给工厂类新增一个抽象层解决了该问题,如上图所示,`FactoryA`和`FactoryB`都实现·抽象工厂接口,分别用于创建`ProductA`和`ProductB`。如果后续新增了`ProductC`,只需新增一个`FactoryC`即可,无需修改原有的代码;因为每个工厂只负责创建一个产品,因此也遵循了**单一职责原则**。
+
+考虑需要如下一个插件架构风格的消息处理系统,`pipeline`是消息处理的管道,其中包含了`input`、`filter`和`output`三个插件。我们需要实现根据配置来创建`pipeline` ,加载插件过程的实现非常适合使用工厂模式,其中`input`、`filter`和`output`三类插件的创建使用抽象工厂模式,而`pipeline`的创建则使用工厂方法模式。
+
+### 抽象工厂模式和工厂方法的使用情景
+
+```
+package main
+
+import (
+ "fmt"
+ "reflect"
+ "strings"
+)
+
+type factoryType int
+
+type Factory interface {
+ CreateSpecificPlugin(cfg string) Plugin
+}
+
+//工厂来源
+var factorys = map[factoryType]Factory{
+ 1: &InputFactory{},
+ 2: &FilterFactory{},
+ 3: &OutputFactory{},
+}
+
+type AbstructFactory struct {
+}
+
+func (a *AbstructFactory) CreateSpecificFactory(t factoryType) Factory {
+ return factorys[t]
+}
+
+type Plugin interface {
+}
+
+//-----------------------------------------
+//input 创建来源
+var (
+ inputNames = make(map[string]reflect.Type)
+)
+
+func inputNamesInit() {
+ inputNames["hello"] = reflect.TypeOf(HelloInput{})
+ inputNames["hello"] = reflect.TypeOf(DataInput{})
+}
+
+type InputFactory struct {
+}
+
+func (i *InputFactory) CreateSpecificPlugin(cfg string) Plugin {
+ t, _ := inputNames[cfg]
+ return reflect.New(t).Interface().(Plugin)
+
+}
+
+//存储这两个插件的接口
+type Input interface {
+ Plugin
+ Input() string
+}
+
+//具体插件
+type HelloInput struct {
+}
+
+func (h *HelloInput) Input() string {
+ return "msg:hello"
+}
+
+type DataInput struct {
+}
+
+func (d *DataInput) Input() string {
+ return "msg:data"
+}
+
+//---------------------------
+//filter 创建来源
+var (
+ filterNames = make(map[string]reflect.Type)
+)
+
+func filterNamesInit() {
+ filterNames["upper"] = reflect.TypeOf(UpperFilter{})
+ filterNames["lower"] = reflect.TypeOf(LowerFilter{})
+}
+
+type FilterFactory struct {
+}
+
+func (f *FilterFactory) CreateSpecificPlugin(cfg string) Plugin {
+ t, _ := filterNames[cfg]
+ return reflect.New(t).Interface().(Plugin)
+}
+
+//存储这两个插件的接口
+type Filter interface {
+ Plugin
+ Process(msg string) string
+}
+
+//具体插件
+type UpperFilter struct {
+}
+
+func (u *UpperFilter) Process(msg string) string {
+ return strings.ToUpper(msg)
+}
+
+type LowerFilter struct {
+}
+
+func (l *LowerFilter) Process(msg string) string {
+ return strings.ToLower(msg)
+}
+
+//------------------------------------------
+//outPut 创建来源
+var (
+ outputNames = make(map[string]reflect.Type)
+)
+
+func outPutNamesInit() {
+ outputNames["console"] = reflect.TypeOf(ConsoleOutput{})
+ outputNames["file"] = reflect.TypeOf(FileOutput{})
+
+}
+
+type OutputFactory struct {
+}
+
+func (o *OutputFactory) CreateSpecificPlugin(cfg string) Plugin {
+ t, _ := outputNames[cfg]
+ return reflect.New(t).Interface().(Plugin)
+}
+
+//存储这两个插件的接口
+type Output interface {
+ Plugin
+ Send(msg string)
+}
+
+//具体插件
+type ConsoleOutput struct {
+}
+
+func (c *ConsoleOutput) Send(msg string) {
+ fmt.Println(msg, " has been send to Console")
+}
+
+type FileOutput struct {
+}
+
+func (c *FileOutput) Send(msg string) {
+ fmt.Println(msg, " has been send File")
+}
+
+//管道
+type PipeLine struct {
+ Input Input
+ Filter Filter
+ Output Output
+}
+
+func (p *PipeLine) Exec() {
+ msg := p.Input.Input()
+ processedMsg := p.Filter.Process(msg)
+ p.Output.Send(processedMsg)
+}
+
+func main() {
+ inputNamesInit()
+ outPutNamesInit()
+ filterNamesInit()
+
+ //创建最顶层的抽象总工厂
+ a := AbstructFactory{}
+ inputfactory := a.CreateSpecificFactory(1)
+ filterfactory := a.CreateSpecificFactory(2)
+ outputfactory := a.CreateSpecificFactory(3)
+ inputPlugin := inputfactory.CreateSpecificPlugin("hello")
+ filterPlugin := filterfactory.CreateSpecificPlugin("upper")
+ outputPlugin := outputfactory.CreateSpecificPlugin("console")
+ p := PipeLine{
+ Input: inputPlugin.(Input),
+ Filter: filterPlugin.(Filter),
+ Output: outputPlugin.(Output),
+ }
+ p.Exec()
+}
+
+```
+
diff --git a/_posts/2022-10-06-test-markdown.md b/_posts/2022-10-06-test-markdown.md
new file mode 100644
index 000000000000..1784b943dd78
--- /dev/null
+++ b/_posts/2022-10-06-test-markdown.md
@@ -0,0 +1,58 @@
+---
+layout: post
+title: What is AppImage? And how to install and use it under ubuntu?
+subtitle: AppImage 是什么?以及如何在ubuntu下面安装与使用?
+tags: [ appImage]
+---
+# Linux Installation Instructions
+## AppImage
+layout: post
+title: AppImage 是什么?以及如何在ubuntu下面安装与使用?
+subtitle: Composing Methods
+
+tags: [ linux]
+---
+
+# Linux Installation Instructions
+
+## AppImage
+
+[Download the AppImage](https://github.com/marktext/marktext/releases/latest)
+
+1. `chmod +x appName.AppImage`
+2. `./appName.AppImage`
+3. Now you can execute app.
+
+### Installation
+
+You cannot really install an AppImage. It's a file which can run directly after getting executable permission. To integrate it into desktop environment, you can either create desktop entry manually **or** use [AppImageLauncher](https://github.com/TheAssassin/AppImageLauncher).
+
+#### Desktop file creation
+
+See [how to create desktop file in ubuntu ].https://www.maketecheasier.com/create-desktop-file-linux/
+
+
+
+#### AppImageLauncher integration
+
+You can integrate the AppImage into the system via [AppImageLauncher](https://github.com/TheAssassin/AppImageLauncher). It will handle the desktop entry automatically.
+
+### Uninstallation
+
+1. Delete AppImage file.
+2. Delete your desktop file if exists.
+3. Delete your user settings: `~/.config/appName`
+
+### Custom launch script
+
+1. Save AppImage somewhere. Let's say `~/bin/appname.AppImage`
+
+2. `chmod +x ~/bin/appname.AppImage`
+
+3. Create a launch script:
+
+ ```sh
+ #!/bin/bash
+ DESKTOPINTEGRATION=0 ~/bin/appname.AppImage
+ ```
+
diff --git a/_posts/2022-10-07-test-markdown.md b/_posts/2022-10-07-test-markdown.md
new file mode 100644
index 000000000000..bde8d5b54874
--- /dev/null
+++ b/_posts/2022-10-07-test-markdown.md
@@ -0,0 +1,547 @@
+---
+layout: post
+title: 迭代器模式与提供复杂数据结构查询的API
+subtitle: 迭代器模式主要用在访问对象集合的场景,能够向客户端隐藏集合的实现细节
+tags: [设计模式]
+---
+
+## 迭代器模式与提供复杂数据结构查询的API
+
+> 有时会遇到这样的需求,开发一个模块,用于保存对象;不能用简单的数组、列表,得是红黑树、跳表等较为复杂的数据结构;有时为了提升存储效率或持久化,还得将对象序列化;但必须给客户端提供一个易用的 API,**允许方便地、多种方式地遍历对象**,丝毫不察觉背后的数据结构有多复杂
+
+从描述可知,**迭代器模式主要用在访问对象集合的场景,能够向客户端隐藏集合的实现细节**。
+
+Java 的 Collection 家族、C++ 的 STL 标准库,都是使用迭代器模式的典范,它们为客户端提供了简单易用的 API,并且能够根据业务需要实现自己的迭代器,具备很好的可扩展性。
+
+## 场景上下文
+
+db 模块用来存储服务注册和监控信息,它的主要接口如下:
+
+```
+type Db interface {
+ CreateTable(t *Table) error
+ CreateTableIfNotExist(t *Table) error
+ DeleteTable(tableName string) error
+
+ Query(tableName string, primaryKey interface{}, result interface{}) error
+ Insert(tableName string, primaryKey interface{}, record interface{}) error
+ Update(tableName string, primaryKey interface{}, record interface{}) error
+ Delete(tableName string, primaryKey interface{}) error
+
+ ...
+}
+```
+
+从增删查改接口可以看出,它是一个 key-value 数据库,另外,为了提供类似关系型数据库的**按列查询**能力,我们又抽象出 `Table` 对象:
+
+```
+package db
+
+// demo/db/table.go
+
+import (
+ "errors"
+ //"fmt"
+ "reflect"
+ //"strings"
+)
+
+// Table 数据表定义
+type Table struct {
+ name string
+ recordType reflect.Type
+ records map[interface{}]record
+}
+
+func NewTable(name string) *Table {
+ return &Table{
+ name: name,
+ records: make(map[interface{}]record),
+ }
+}
+
+func (t *Table) WithType(recordType reflect.Type) *Table {
+ t.recordType = recordType
+ return t
+}
+func (t *Table) Insert(key interface{}, value interface{}) error {
+
+ if _, ok := t.records[key]; ok {
+ return errors.New("ErrPrimaryKeyConflict")
+ }
+ record, err := recordFrom(key, value)
+ if err != nil {
+ return err
+ }
+ t.records[key] = record
+ return nil
+
+}
+
+```
+
+```
+package db
+
+import (
+ "errors"
+ "fmt"
+ "reflect"
+ "strings"
+)
+
+// 因为数据库的每个表都存储着不同对象
+// 所以需要把类型存进去,根据类型创建自己需要的对象,再根据对象的属性,创建出表的每一列的属性
+// 其中,Table 底层用 map 存储对象数据,但并没有存储对象本身,而是从对象转换而成的 record
+type record struct {
+ primaryKey interface{}
+ fields map[string]int
+ values []interface{}
+}
+
+//从对象转化为 record
+func recordFrom(key interface{}, value interface{}) (r record, e error) {
+ defer func() {
+ if err := recover(); err != nil {
+ r = record{}
+ e = errors.New("ErrRecordTypeInvalid")
+ }
+ }()
+
+ vType := reflect.TypeOf(value)
+ fmt.Println("vType:", vType)
+ vVal := reflect.ValueOf(value)
+ fmt.Println("vVal:", vVal)
+
+ if vVal.Type().Kind() == reflect.Ptr {
+ vType = vType.Elem()
+ vVal = vVal.Elem()
+ }
+
+ record := record{
+ primaryKey: key,
+ fields: make(map[string]int, vVal.NumField()),
+ values: make([]interface{}, vVal.NumField()),
+ }
+ fmt.Println("vVal.NumField()", vVal.NumField())
+
+ for i := 0; i < vVal.NumField(); i++ {
+ fieldType := vType.Field(i)
+ fieldVal := vVal.Field(i)
+ name := strings.ToLower(fieldType.Name)
+ record.fields[name] = i
+ record.values[i] = fieldVal.Interface()
+ }
+
+ return record, nil
+
+}
+
+```
+
+```
+package db
+
+import (
+ "fmt"
+ "reflect"
+ "testing"
+)
+
+type testRegion struct {
+ Id int
+ Name string
+}
+
+func TestTable(t *testing.T) {
+ tableName := "testRegion"
+ table := NewTable(tableName).WithType((reflect.TypeOf(new(testRegion))))
+ table.Insert(2, &testRegion{Id: 2, Name: "beijing"})
+ fmt.Println(table.records)
+}
+
+```
+
+
+
+## 用迭代器实现
+
+```
+package db
+
+// demo/db/table.go
+
+import (
+ "errors"
+ //"fmt"
+ "math/rand"
+ "reflect"
+ "time"
+ //"strings"
+)
+
+// Table 数据表定义
+type Table struct {
+ name string
+ recordType reflect.Type
+ records map[interface{}]record
+ // 关键点: 持有迭代器工厂方法接口
+ iteratorFactory TableIteratorFactory
+}
+
+func NewTable(name string) *Table {
+ return &Table{
+ name: name,
+ records: make(map[interface{}]record),
+ }
+}
+
+func (t *Table) WithType(recordType reflect.Type) *Table {
+ t.recordType = recordType
+ return t
+}
+func (t *Table) Insert(key interface{}, value interface{}) error {
+
+ if _, ok := t.records[key]; ok {
+ return errors.New("ErrPrimaryKeyConflict")
+ }
+ record, err := recordFrom(key, value)
+ if err != nil {
+ return err
+ }
+ t.records[key] = record
+ return nil
+
+}
+
+// 关键点: 定义Setter方法,提供迭代器工厂的依赖注入
+func (t *Table) WithTableIteratorFactory(iteratorFactory TableIteratorFactory) *Table {
+ t.iteratorFactory = iteratorFactory
+ return t
+}
+
+// 关键点: 定义创建迭代器的接口,其中调用迭代器工厂完成实例化
+func (t *Table) Iterator() TableIterator {
+ return t.iteratorFactory.Create(t)
+}
+
+type Next func(interface{}) error
+type HasNext func() bool
+
+func (t *Table) ClosureIterator() (HasNext, Next) {
+ var records []record
+ for _, r := range t.records {
+ records = append(records, r)
+ }
+ rand.Seed(time.Now().UnixNano())
+ rand.Shuffle(len(records), func(i, j int) {
+ records[i], records[j] = records[j], records[i]
+ })
+ size := len(records)
+ cursor := 0
+ hasNext := func() bool {
+ return cursor < size
+ }
+ next := func(next interface{}) error {
+ record := records[cursor]
+ cursor++
+ if err := record.convertByValue(next); err != nil {
+ return err
+ }
+ return nil
+ }
+ return hasNext, next
+}
+
+```
+
+```
+package db
+
+// demo/db/iterator.go
+
+import (
+ "math/rand"
+ "sort"
+ "time"
+)
+
+type TableIterator interface {
+ HasNext() bool
+ Next(next interface{}) error
+}
+
+// 关键点: 定义迭代器接口的实现
+// tableIteratorImpl 迭代器接口公共实现类 用来实现遍历表
+type tableIteratorImpl struct {
+ // 关键点3: 定义一个集合存储待遍历的记录,这里的记录已经排序好或者随机打散
+ records []record
+ // 关键点4: 定义一个cursor游标记录当前遍历的位置
+ cursor int
+}
+
+// 关键点5: 在HasNext函数中的判断是否已经遍历完所有记录
+func (r *tableIteratorImpl) HasNext() bool {
+ return r.cursor < len(r.records)
+}
+
+// 关键点: 在Next函数中取出下一个记录,并转换成客户端期望的对象类型,记得增加cursor
+func (r *tableIteratorImpl) Next(next interface{}) error {
+ record := r.records[r.cursor]
+ r.cursor++
+ if err := record.convertByValue(next); err != nil {
+ return err
+ }
+ return nil
+}
+
+type TableIteratorFactory interface {
+ Create(table *Table) TableIterator
+}
+
+//创建迭代器的方式用工厂方法模式
+//工厂可以创建出两种具体的迭代器 randomTableIteratorFactory sortedTableIteratorFactory
+type randomTableIteratorFactory struct {
+}
+
+func NewRandomTableIteratorFactory() *randomTableIteratorFactory {
+ return &randomTableIteratorFactory{}
+}
+func (r *randomTableIteratorFactory) Create(table *Table) TableIterator {
+ var records []record
+ for _, r := range table.records {
+ records = append(records, r)
+ }
+ rand.Seed(time.Now().UnixNano())
+ rand.Shuffle(len(records), func(i, j int) {
+ records[i], records[j] = records[j], records[i]
+ })
+ return &tableIteratorImpl{
+ records: records,
+ cursor: 0,
+ }
+}
+
+type sortedTableIteratorFactory struct {
+ Comparator Comparator
+ //comparator Comparator
+}
+
+func NewSortedTableIteratorFactory(c Comparator) *sortedTableIteratorFactory {
+ return &sortedTableIteratorFactory{
+ Comparator: c,
+ }
+
+}
+
+func (s *sortedTableIteratorFactory) Create(table *Table) TableIterator {
+ var res []record
+ for _, r := range table.records {
+ res = append(res, r)
+ }
+ /* re := &records{
+ rs: res,
+ comparator: s.Comparator,
+ } */
+ sort.Sort(newrecords(res, s.Comparator))
+ return &tableIteratorImpl{
+ records: res,
+ cursor: 0,
+ }
+}
+
+type records struct {
+ rs []record
+ comparator Comparator
+}
+
+func newrecords(res []record, com Comparator) *records {
+ return &records{
+ rs: res,
+ comparator: com,
+ }
+
+}
+
+type Comparator func(i interface{}, j interface{}) bool
+
+//Len()
+func (r *records) Len() int {
+ return len(r.rs)
+}
+
+//Less(): 成绩将有低到高排序
+func (r *records) Less(i, j int) bool {
+ return r.comparator(r.rs[i].primaryKey, r.rs[j].primaryKey)
+}
+
+//Swap()
+func (r *records) Swap(i, j int) {
+ tmp := r.rs[i]
+ r.rs[i] = r.rs[j]
+ r.rs[j] = tmp
+}
+
+```
+
+```
+// demo/db/iterator_test.go
+package db
+
+import (
+ "fmt"
+ "reflect"
+ "testing"
+)
+
+func regionIdLess(i, j interface{}) bool {
+ id1, ok := i.(int)
+ if !ok {
+ return false
+ }
+ id2, ok := j.(int)
+ if !ok {
+ return false
+ }
+ return id1 < id2
+}
+
+func TestRandomTableIterator(t *testing.T) {
+ table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
+ WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdLess))
+ table.Insert(1, &testRegion{Id: 1, Name: "beijing"})
+ table.Insert(2, &testRegion{Id: 2, Name: "shanghai"})
+ table.Insert(3, &testRegion{Id: 3, Name: "guangdong"})
+ //根据table得到 一个存储 排好顺序切片 和指向index的 结构体
+ hasNext, next := table.ClosureIterator()
+
+ for i := 0; i < 3; i++ {
+ if !hasNext() {
+ t.Error("records size error")
+ }
+ region := new(testRegion)
+ if err := next(region); err != nil {
+ t.Error(err)
+ }
+ fmt.Printf("%+v\n", region)
+ }
+ if hasNext() {
+ t.Error("should not has next")
+ }
+
+}
+
+func TestSortTableIterator(t *testing.T) {
+ table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
+ WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdLess))
+ table.Insert(3, &testRegion{Id: 3, Name: "beijing"})
+ table.Insert(1, &testRegion{Id: 1, Name: "shanghai"})
+ table.Insert(2, &testRegion{Id: 2, Name: "guangdong"})
+ iter := table.Iterator()
+ region1 := new(testRegion)
+ iter.Next(region1)
+ if region1.Id != 1 {
+ t.Error("region1 sort failed")
+ }
+ region2 := new(testRegion)
+ iter.Next(region2)
+ if region2.Id != 2 {
+ t.Error("region2 sort failed")
+ }
+ region3 := new(testRegion)
+ iter.Next(region3)
+ if region3.Id != 3 {
+ t.Error("region3 sort failed")
+ }
+}
+
+```
+
+```
+
+// 需要用到的包
+// demo/db/record.go
+package db
+
+import (
+ "errors"
+ //"fmt"
+ "reflect"
+ "strings"
+)
+
+// 因为数据库的每个表都存储着不同对象
+// 所以需要把类型存进去,根据类型创建自己需要的对象,再根据对象的属性,创建出表的每一列的属性
+// 其中,Table 底层用 map 存储对象数据,但并没有存储对象本身,而是从对象转换而成的 record
+type record struct {
+ primaryKey interface{}
+ fields map[string]int
+ values []interface{}
+}
+
+//从对象转化为 record
+func recordFrom(key interface{}, value interface{}) (r record, e error) {
+ defer func() {
+ if err := recover(); err != nil {
+ r = record{}
+ e = errors.New("ErrRecordTypeInvalid")
+ }
+ }()
+
+ vType := reflect.TypeOf(value)
+ //fmt.Println("vType:", vType)
+ vVal := reflect.ValueOf(value)
+ //fmt.Println("vVal:", vVal)
+
+ if vVal.Type().Kind() == reflect.Ptr {
+ //fmt.Println("is ptr")
+ vType = vType.Elem()
+ //fmt.Println("vType:", vType)
+
+ vVal = vVal.Elem()
+ //fmt.Println("vVal:", vVal)
+
+ }
+
+ record := record{
+ primaryKey: key,
+ fields: make(map[string]int, vVal.NumField()),
+ values: make([]interface{}, vVal.NumField()),
+ }
+ //fmt.Println("vVal.NumField()", vVal.NumField())
+
+ for i := 0; i < vVal.NumField(); i++ {
+ fieldType := vType.Field(i)
+ //fmt.Println("fieldType :", fieldType)
+ fieldVal := vVal.Field(i)
+ //fmt.Println("fieldVal:", fieldVal)
+ name := strings.ToLower(fieldType.Name)
+ record.fields[name] = i
+ record.values[i] = fieldVal.Interface()
+ }
+
+ return record, nil
+
+}
+
+func (r record) convertByValue(result interface{}) (e error) {
+ defer func() {
+ if err := recover(); err != nil {
+ e = errors.New("ErrRecordTypeInvalid")
+ }
+ }()
+ rType := reflect.TypeOf(result)
+ rVal := reflect.ValueOf(result)
+ if rType.Kind() == reflect.Ptr {
+ rType = rType.Elem()
+ rVal = rVal.Elem()
+ }
+ for i := 0; i < rType.NumField(); i++ {
+ field := rVal.Field(i)
+ field.Set(reflect.ValueOf(r.values[i]))
+ }
+ return nil
+}
+
+```
+
diff --git a/_posts/2022-10-09-test-markdown.md b/_posts/2022-10-09-test-markdown.md
new file mode 100644
index 000000000000..04d4be8715cb
--- /dev/null
+++ b/_posts/2022-10-09-test-markdown.md
@@ -0,0 +1,973 @@
+---
+layout: post
+title: Go和Web
+subtitle: 迭代器模式主要用在访问对象集合的场景,能够向客户端隐藏集合的实现细节
+tags: [设计模式]
+---
+
+# go和Web
+
+## 1.Web开发
+
+> 因为 Go 的 `net/http` 包提供了基础的路由函数组合与丰富的功能函数。所以在社区里流行一种用 Go 编写 API 不需要框架的观点,在我们看来,如果的项目的路由在个位数、URI 固定且不通过 URI 来传递参数,那么确实使用官方库也就足够。但在复杂场景下,官方的 http 库还是有些力有不逮。例如下面这样的路由:
+
+> ```go
+> > GET /card/:id
+>
+> > POST /card/:id
+>
+> > DELTE /card/:id
+>
+> > GET /card/:id/name
+>
+> > GET /card/:id/relations
+> ```
+
+Go 的 Web 框架大致可以分为这么两类:
+
+1. Router 框架
+
+2. MVC 类框架
+
+在框架的选择上,大多数情况下都是依照个人的喜好和公司的技术栈。例如公司有很多技术人员是 PHP 出身,那么他们一定会非常喜欢像 beego 这样的框架,但如果公司有很多 C 程序员,那么他们的想法可能是越简单越好。比如很多大厂的 C 程序员甚至可能都会去用 C 语言去写很小的 CGI 程序,他们可能本身并没有什么意愿去学习 MVC 或者更复杂的 Web 框架,他们需要的只是一个非常简单的路由(甚至连路由都不需要,只需要一个基础的 HTTP 协议处理库来帮他省掉没什么意思的体力劳动)。Go 的 `net/http` 包提供的就是这样的基础功能,写一个简单的 `http echo server` 只需要 30s。
+
+```go
+package main
+
+import (
+
+"net/http"
+
+"io/ioutil"
+
+)
+
+func echo(wr http.ResponseWriter, r *http.Request) {
+
+msg, err := ioutil.ReadAll(r.Body)
+
+if err != nil {
+
+wr.Write([]byte("echo error"))
+
+return
+
+}
+
+
+
+writeLen, err := wr.Write(msg)
+
+if err != nil || writeLen != len(msg) {
+
+log.Println(err, "write len:", writeLen)
+
+}
+
+}
+
+
+
+func main() {
+
+http.HandleFunc("/", echo)
+
+err := http.ListenAndServe(":8080", nil)
+
+if err != nil {
+
+log.Fatal(err)
+
+}
+
+}
+```
+
+开源社区中一个 Kafka 监控项目中的做法:
+
+```go
+//Burrow: http_server.go
+
+func NewHttpServer(app *ApplicationContext) (*HttpServer, error) {
+
+...
+
+server.mux.HandleFunc("/", handleDefault)
+
+
+
+server.mux.HandleFunc("/burrow/admin", handleAdmin)
+
+
+
+server.mux.Handle("/v2/kafka", appHandler{server.app, handleClusterList})
+
+server.mux.Handle("/v2/kafka/", appHandler{server.app, handleKafka})
+
+server.mux.Handle("/v2/zookeeper", appHandler{server.app, handleClusterList})
+
+...
+
+}
+```
+
+```
+没有使用任何 router 框架,只使用了 `net/http`。只看上面这段代码似乎非常优雅,我们的项目里大概只有这五个简单的 URI,所以我们提供的服务就是下面这个样子:/
+
+/burrow/admin
+
+/v2/kafka
+
+/v2/kafka/
+
+/v2/zookeeper
+```
+
+进 `handleKafka()` 这个函数一探究竟:
+
+```go
+func handleKafka(app *ApplicationContext, w http.ResponseWriter, r *http.Request) (int, string) {
+
+pathParts := strings.Split(r.URL.Path[1:], "/")
+
+if _, ok := app.Config.Kafka[pathParts[2]]; !ok {
+
+return makeErrorResponse(http.StatusNotFound, "cluster not found", w, r)
+
+}
+
+if pathParts[2] == "" {
+
+// Allow a trailing / on requests
+
+return handleClusterList(app, w, r)
+
+}
+
+if (len(pathParts) == 3) || (pathParts[3] == "") {
+
+return handleClusterDetail(app, w, r, pathParts[2])
+
+}
+
+
+
+switch pathParts[3] {
+
+case "consumer":
+
+switch {
+
+case r.Method == "DELETE":
+
+switch {
+
+case (len(pathParts) == 5) || (pathParts[5] == ""):
+
+return handleConsumerDrop(app, w, r, pathParts[2], pathParts[4])
+
+default:
+
+return makeErrorResponse(http.StatusMethodNotAllowed, "request method not supported", w, r)
+
+}
+
+case r.Method == "GET":
+
+switch {
+
+case (len(pathParts) == 4) || (pathParts[4] == ""):
+
+return handleConsumerList(app, w, r, pathParts[2])
+
+case (len(pathParts) == 5) || (pathParts[5] == ""):
+
+// Consumer detail - list of consumer streams/hosts? Can be config info later
+
+return makeErrorResponse(http.StatusNotFound, "unknown API call", w, r)
+
+case pathParts[5] == "topic":
+
+switch {
+
+case (len(pathParts) == 6) || (pathParts[6] == ""):
+
+return handleConsumerTopicList(app, w, r, pathParts[2], pathParts[4])
+
+case (len(pathParts) == 7) || (pathParts[7] == ""):
+
+return handleConsumerTopicDetail(app, w, r, pathParts[2], pathParts[4], pathParts[6])
+
+}
+
+case pathParts[5] == "status":
+
+return handleConsumerStatus(app, w, r, pathParts[2], pathParts[4], false)
+
+case pathParts[5] == "lag":
+
+return handleConsumerStatus(app, w, r, pathParts[2], pathParts[4], true)
+
+}
+
+default:
+
+return makeErrorResponse(http.StatusMethodNotAllowed, "request method not supported", w, r)
+
+}
+
+case "topic":
+
+switch {
+
+case r.Method != "GET":
+
+return makeErrorResponse(http.StatusMethodNotAllowed, "request method not supported", w, r)
+
+case (len(pathParts) == 4) || (pathParts[4] == ""):
+
+return handleBrokerTopicList(app, w, r, pathParts[2])
+
+case (len(pathParts) == 5) || (pathParts[5] == ""):
+
+return handleBrokerTopicDetail(app, w, r, pathParts[2], pathParts[4])
+
+}
+
+case "offsets":
+
+// Reserving this endpoint to implement later
+
+return makeErrorResponse(http.StatusNotFound, "unknown API call", w, r)
+
+}
+
+
+
+// If we fell through, return a 404
+
+return makeErrorResponse(http.StatusNotFound, "unknown API call", w, r)
+
+}
+```
+
+> 因为默认的 `net/http` 包中的 `mux` 不支持带参数的路由,所以 Burrow 这个项目使用了非常蹩脚的字符串 `Split` 和乱七八糟的 `switch case` 来达到自己的目的,但却让本来应该很集中的路由管理逻辑变得复杂,散落在系统的各处,难以维护和管理。如果读者细心地看过这些代码之后,可能会发现其它的几个 `handler` 函数逻辑上较简单,最复杂的也就是这个 `handleKafka()`。而我们的系统总是从这样微不足道的混乱开始积少成多,最终变得难以收拾。
+
+> 根据我们的经验,简单地来说,只要的路由带有参数,并且这个项目的 API 数目超过了 10,就尽量不要使用 `net/http` 中默认的路由。在 Go 开源界应用最广泛的 router 是 httpRouter,很多开源的 router 框架都是基于 httpRouter 进行一定程度的改造的成果。关于 httpRouter 路由的原理,会在本章节的 router 一节中进行详细的阐释。
+
+> 开源界有这么几种框架,第一种是对 httpRouter 进行简单的封装,然后提供定制的中间件和一些简单的小工具集成比如 gin,主打轻量,易学,高性能。第二种是借鉴其它语言的编程风格的一些 MVC 类框架,例如 beego,
+
+## 2.请求路由
+
+在常见的 Web 框架中,router 是必备的组件。Go 语言圈子里 router 也时常被称为 `http` 的 multiplexer。在上一节中我们通过对 Burrow 代码的简单学习,已经知道如何用 `http` 标准库中内置的 mux 来完成简单的路由功能了。如果开发 Web 系统对路径中带参数没什么兴趣的话,用 `http` 标准库中的 `mux` 就可以。
+
+RESTful 是几年前刮起的 API 设计风潮,在 RESTful 中除了 GET 和 POST 之外,还使用了 HTTP 协议定义的几种其它的标准化语义。具体包括:
+
+```go
+const (
+ MethodGet = "GET"
+ MethodHead = "HEAD"
+ MethodPost = "POST"
+ MethodPut = "PUT"
+ MethodPatch = "PATCH" // RFC 5789
+ MethodDelete = "DELETE"
+ MethodConnect = "CONNECT"
+ MethodOptions = "OPTIONS"
+ MethodTrace = "TRACE"
+)
+```
+
+来看看 RESTful 中常见的请求路径:
+
+```go
+GET /repos/:owner/:repo/comments/:id/reactions
+
+POST /projects/:project_id/columns
+
+PUT /user/starred/:owner/:repo
+
+DELETE /user/starred/:owner/:repo
+```
+
+RESTful 风格的 API 重度依赖请求路径。会将很多参数放在请求 URI 中。除此之外还会使用很多并不那么常见的 HTTP 状态码
+
+如果我们的系统也想要这样的 URI 设计,使用标准库的 `mux` 显然就力不从心了。
+
+### 2.1 httprouter
+
+较流行的开源 go Web 框架大多使用 httprouter,或是基于 httprouter 的变种对路由进行支持。前面提到的 Github 的参数式路由在 httprouter 中都是可以支持的。
+
+因为 httprouter 中使用的是显式匹配,所以在设计路由的时候需要规避一些会导致路由冲突的情况,例如:
+
+```go
+conflict:
+GET /user/info/:name
+GET /user/:id
+
+no conflict:
+GET /user/info/:name
+POST /user/:id
+```
+
+##简单来讲的话,如果两个路由拥有一致的 http 方法 (指 `GET`、`POST`、`PUT`、`DELETE`) 和请求路径前缀,且在某个位置出现了 A 路由是 wildcard(指 `:id` 这种形式)参数,B 路由则是普通字符串,那么就会发生路由冲突。路由冲突会在初始化阶段直接 panic
+
+还有一点需要注意,因为 httprouter 考虑到字典树的深度,在初始化时会对参数的数量进行限制,所以在路由中的参数数目不能超过 255,否则会导致 httprouter 无法识别后续的参数。不过这一点上也不用考虑太多,毕竟 URI 是人设计且给人来看的,相信没有长得夸张的 URI 能在一条路径中带有 200 个以上的参数。
+
+除支持路径中的 wildcard 参数之外,httprouter 还可以支持 `*` 号来进行通配,不过 `*` 号开头的参数只能放在路由的结尾,例如下面这样:
+
+```go
+Pattern: /src/*filepath
+
+ /src/ filepath = ""
+ /src/somefile.go filepath = "somefile.go"
+ /src/subdir/somefile.go filepath = "subdir/somefile.go"
+
+```
+
+这种设计在 RESTful 中可能不太常见,主要是为了能够使用 httprouter 来做简单的 HTTP 静态文件服务器。
+
+除了正常情况下的路由支持,httprouter 也支持对一些特殊情况下的回调函数进行定制,例如 404 的时候:
+
+```go
+r := httprouter.New()
+r.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
+ w.Write([]byte("oh no, not found"))
+})
+
+```
+
+内部 panic 的时候:
+
+```go
+r.PanicHandler = func(w http.ResponseWriter, r *http.Request, c interface{}) {
+ log.Printf("Recovering from panic, Reason: %#v", c.(error))
+ w.WriteHeader(http.StatusInternalServerError)
+ w.Write([]byte(c.(error).Error()))
+}
+
+```
+
+目前开源界最为流行(star 数最多)的 Web 框架 [gin](https://github.com/gin-gonic/gin) 使用的就是 httprouter 的变种。
+
+
+
+### 2.2 原理
+
+#### 2.2.1
+
+httprouter 和众多衍生 router 使用的数据结构被称为压缩字典树(Radix Tree)。读者可能没有接触过压缩字典树,但对字典树(Trie Tree)应该有所耳闻。*图 5-1* 是一个典型的字典树结构:
+
+
+
+
+
+*图为字典树*
+
+字典树常用来进行字符串检索,例如用给定的字符串序列建立字典树。对于**目标字符串**,只要从根节点开始深度优先搜索,即可判断出该字符串是否曾经出现过,时间复杂度为 `O(n)`,**n 可以认为是目标字符串的长度**。为什么要这样做?字符串本身不像数值类型可以进行数值比较,两个字符串对比的时间复杂度取决于字符串长度。如果不用字典树来完成上述功能,要对历史字符串进行排序,再利用二分查找之类的算法去搜索,时间复杂度只高不低。可认为字典树是一种空间换时间的典型做法。
+
+普通的字典树有一个比较明显的缺点,就是每个字母都需要建立一个孩子节点,这样会导致字典树的层数比较深,压缩字典树相对好地平衡了字典树的优点和缺点。是典型的压缩字典树结构:
+
+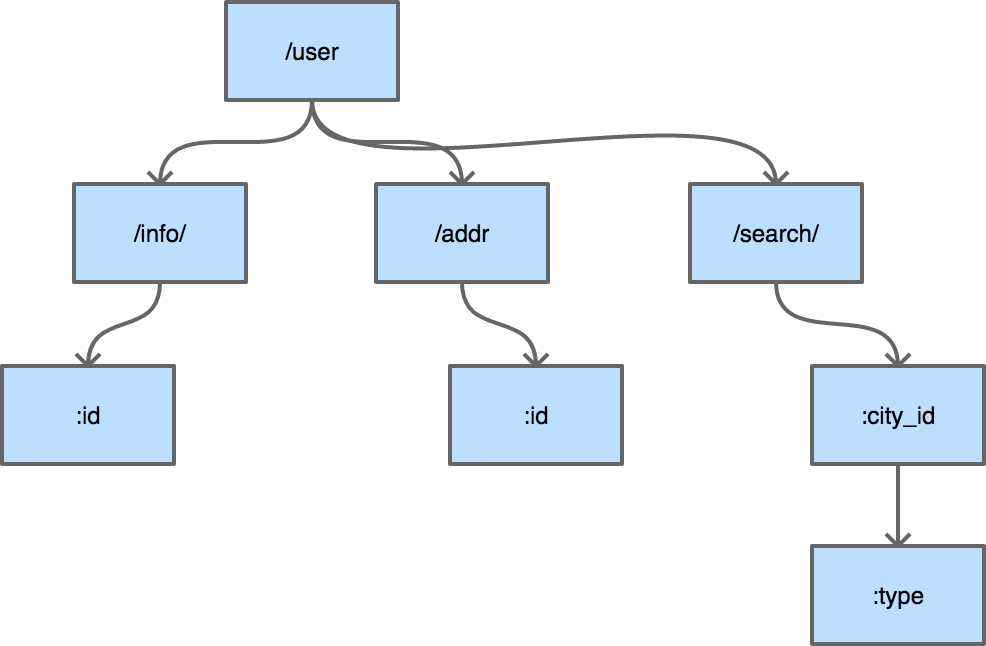
+
+*图为压缩字典树*
+
+每个节点上不只存储一个字母了,这也是压缩字典树中 “压缩” 的主要含义。使用压缩字典树可以减少树的层数,同时因为每个节点上数据存储也比通常的字典树要多,所以程序的局部性较好(一个节点的 path 加载到 cache 即可进行多个字符的对比),从而对 CPU 缓存友好。
+
+#### 2.2.2压缩字典树创建过程
+
+我们来跟踪一下 httprouter 中,一个典型的压缩字典树的创建过程,路由设定如下:
+
+```go
+PUT /user/installations/:installation_id/repositories/:repository_id
+
+GET /marketplace_listing/plans/
+GET /marketplace_listing/plans/:id/accounts
+GET /search
+GET /status
+GET /support
+
+补充路由:
+GET /marketplace_listing/plans/ohyes
+
+```
+
+最后一条补充路由是我们臆想的,除此之外所有 API 路由均来自于 `api.github.com`
+
+
+
+### 2.2.3 root 节点的创建
+
+```go
+// 略去了其它部分的 Router struct
+type Router struct{
+ // ...
+ trees map[string]*node
+ // ...
+}
+```
+
+`trees` 中的 `key` 即为 HTTP 1.1 的 RFC 中定义的各种方法,具体有:
+
+```
+GET
+HEAD
+OPTIONS
+POST
+PUT
+PATCH
+DELETE
+```
+
+每一种方法对应的都是一棵独立的压缩字典树,这些树彼此之间不共享数据。具体到我们上面用到的路由,`PUT` 和 `GET` 是两棵树而非一棵。
+
+简单来讲,某个方法第一次插入的路由就会导致对应字典树的根节点被创建,我们按顺序,先是一个 `PUT`:
+
+```go
+r := httprouter.New()
+r.PUT("/user/installations/:installation_id/repositories/:reposit", Hello)
+
+```
+
+这样 `PUT` 对应的根节点就会被创建出来。把这棵 `PUT` 的树画出来:
+
+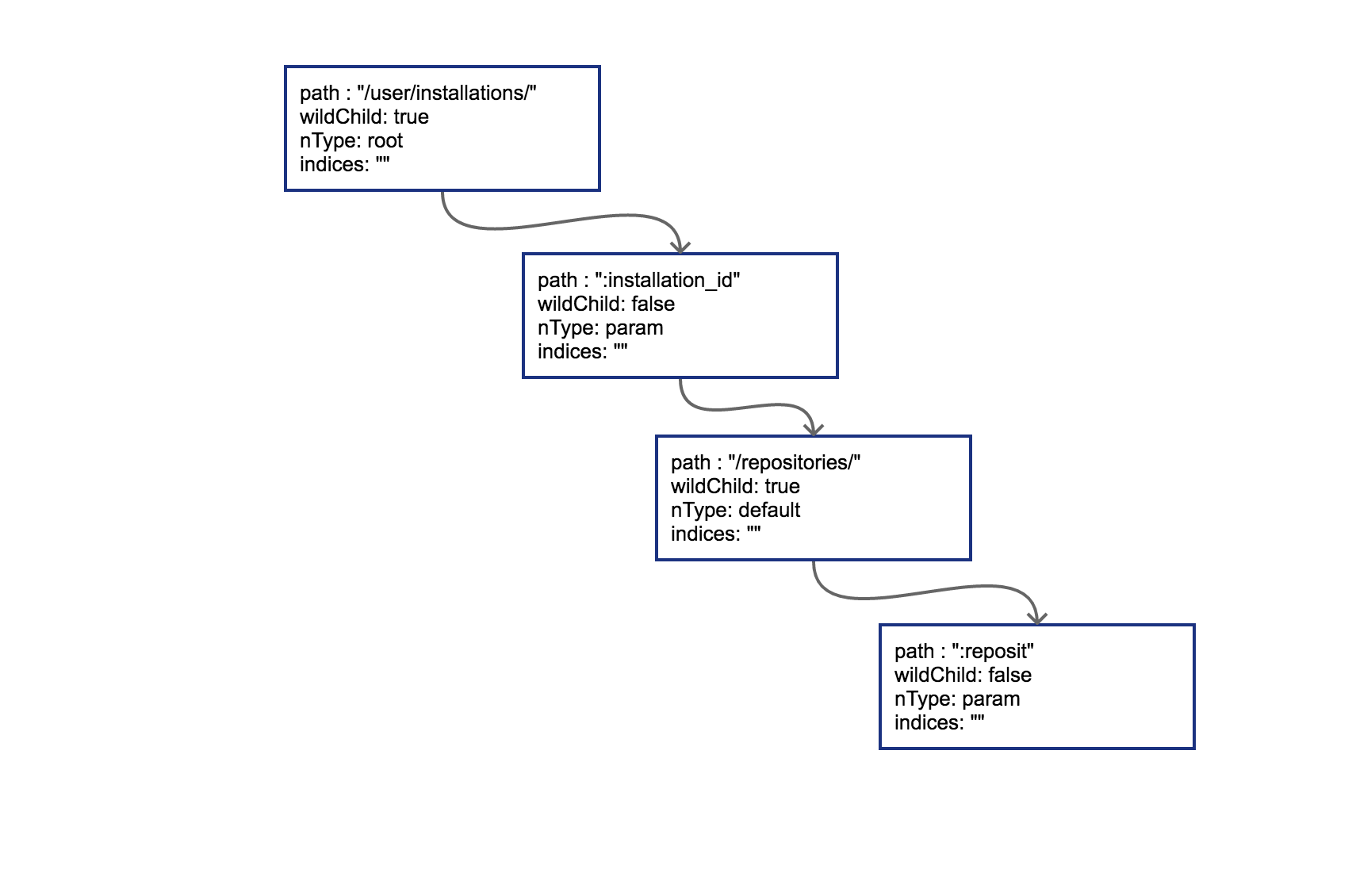
+
+*图为插入路由之后的压缩字典树*
+
+radix 的节点类型为 `*httprouter.node`,为了说明方便,我们留下了目前关心的几个字段:
+
+```go
+path: 当前节点对应的路径中的字符串
+
+wildChild: 子节点是否为参数节点,即 wildcard node,或者说 :id 这种类型的节点
+
+nType: 当前节点类型,有四个枚举值: 分别为 static/root/param/catchAll。
+ static // 非根节点的普通字符串节点
+ root // 根节点
+ param // 参数节点,例如 :id
+ catchAll // 通配符节点,例如 *anyway
+
+indices:子节点索引,当子节点为非参数类型,即本节点的 wildChild 为 false 时,会将每个子节点的首字母放在该索引数组。说是数组,实际上是个 string。
+
+
+```
+
+当然,`PUT` 路由只有唯一的一条路径。接下来,我们以后续的多条 GET 路径为例,讲解子节点的插入过程
+
+#### 2.2.4 子节点的插入
+
+当插入 `GET /marketplace_listing/plans` 时,类似前面 PUT 的过程,GET 树的结构如 *图 5-4*:
+
+
+
+
+
+*图为插入第一个节点的压缩字典树*
+
+因为第一个路由没有参数,path 都被存储到根节点上了。所以只有一个节点。
+
+然后插入 `GET /marketplace_listing/plans/:id/accounts`,新的路径与之前的路径有共同的前缀,且可以直接在之前叶子节点后进行插入,那么结果也很简单,插入后的树结构见 *图 5-5*:
+
+
+
+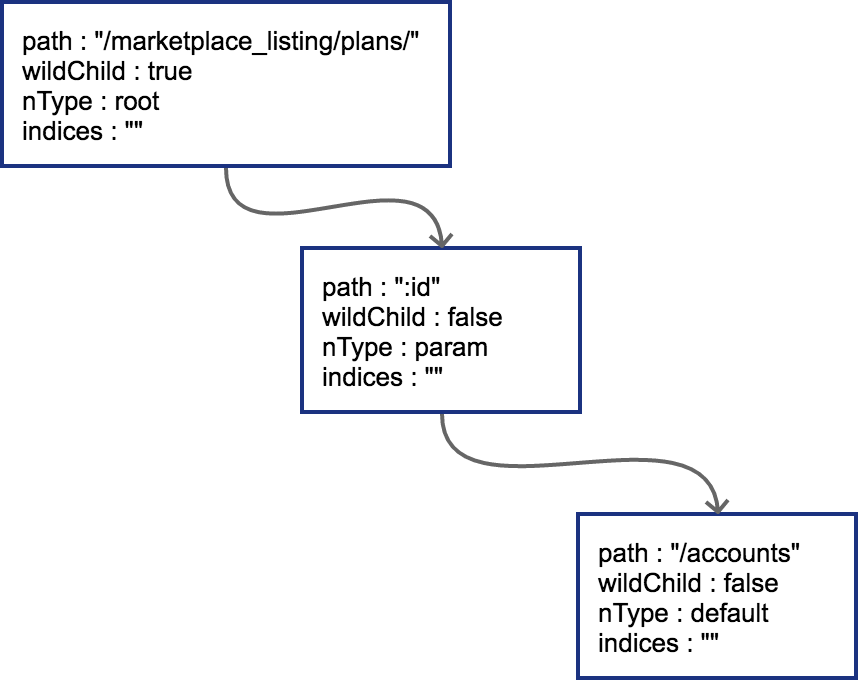
+
+
+
+
+
+*图为插入第二个节点的压缩字典树*
+
+由于 `:id` 这个节点只有一个字符串的普通子节点,所以 indices 还依然不需要处理。
+
+上面这种情况比较简单,新的路由可以直接作为原路由的子节点进行插入。实际情况不会这么美好。
+
+#### 2.2.5 边分裂
+
+接下来我们插入 `GET /search`,这时会导致树的边分裂,见 *图 5-6*。
+
+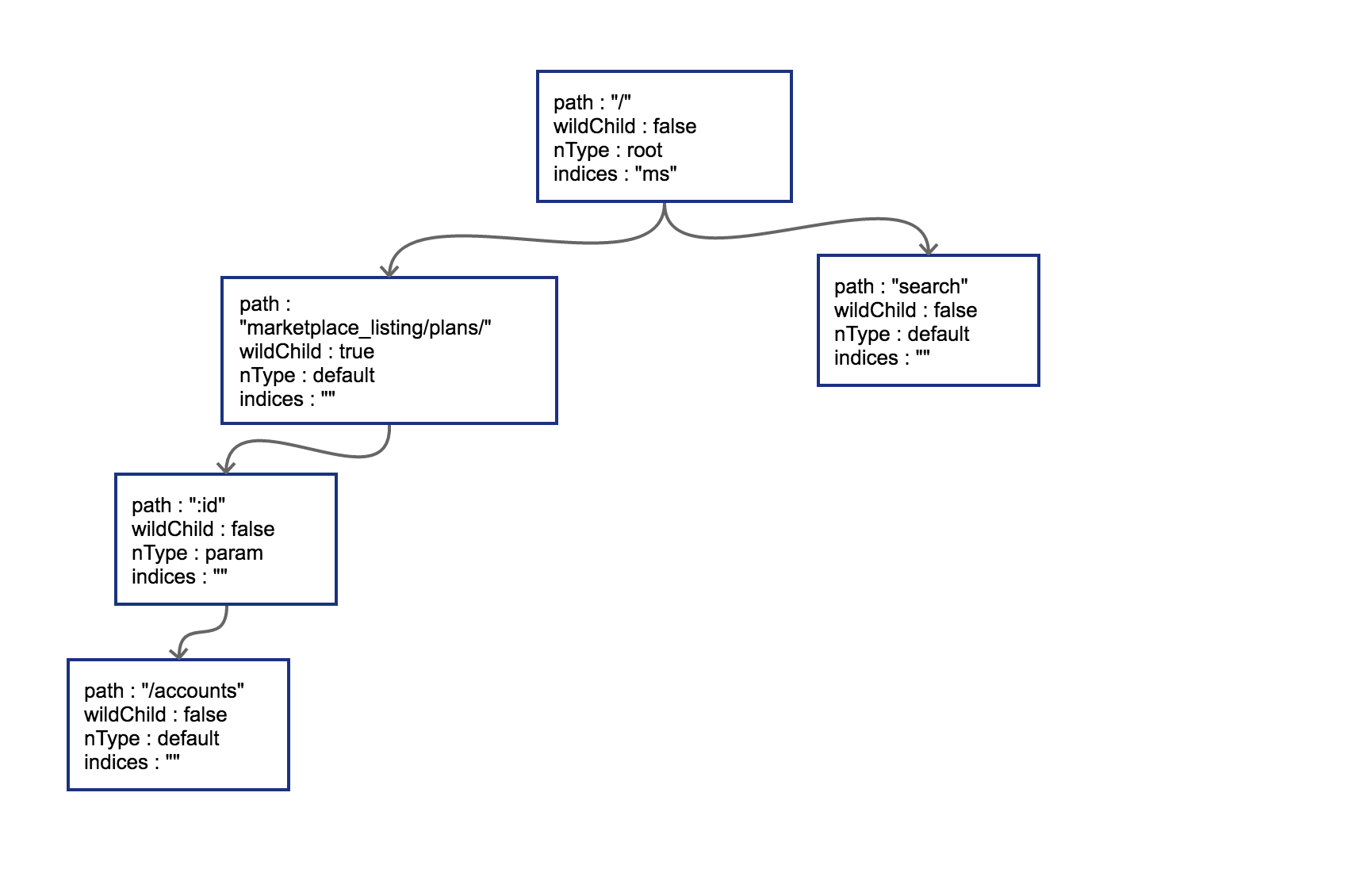
+
+
+
+*图为插入第三个节点,导致边分裂*
+
+原有路径和新的路径在初始的 `/` 位置发生分裂,这样需要把原有的 root 节点内容下移,再将新路由 `search` 同样作为子节点挂在 root 节点之下。这时候因为子节点出现多个,root 节点的 indices 提供子节点索引,这时候该字段就需要派上用场了。"ms" 代表子节点的首字母分别为 m(marketplace)和 s(search)。我们一口作气,把 `GET /status` 和 `GET /support` 也插入到树中。这时候会导致在 `search` 节点上再次发生分裂,最终结果见图
+
+*插入所有路由后的压缩字典树*
+
+
+
+#### 2.2.6 子节点冲突处理
+
+在路由本身只有字符串的情况下,不会发生任何冲突。只有当路由中含有 wildcard(类似 :id)或者 catchAll 的情况下才可能冲突。这一点在前面已经提到了。
+
+子节点的冲突处理很简单,分几种情况:
+
+1. 在插入 wildcard 节点时,父节点的 children 数组非空且 wildChild 被设置为 false。例如:`GET /user/getAll` 和 `GET /user/:id/getAddr`,或者 `GET /user/*aaa` 和 `GET /user/:id`。
+
+ > 解释:就是 `GET /user/:id/getAddr ` 和`GET /user/getAll`有相同的前缀, 如果在已经有`getAll`的情况下,插入 `:id `让他panic 就行。
+2. 在插入 wildcard 节点时,父节点的 children 数组非空且 wildChild 被设置为 true,但该父节点的 wildcard 子节点要插入的 wildcard 名字不一样。例如:`GET /user/:id/info` 和 `GET /user/:name/info`。
+3. 在插入 catchAll 节点时,父节点的 children 非空。例如:`GET /src/abc` 和 `GET /src/*filename`,或者 `GET /src/:id` 和 `GET /src/*filename`。
+4. 在插入 static 节点时,父节点的 wildChild 字段被设置为 true。
+5. 在插入 static 节点时,父节点的 children 非空,且子节点 nType 为 catchAll。
+
+只要发生冲突,都会在初始化的时候 panic。例如,在插入我们臆想的路由 `GET /marketplace_listing/plans/ohyes` 时,出现第 4 种冲突情况:它的父节点 `marketplace_listing/plans/` 的 wildChild 字段为 true。
+
+#### 2.2.2 树(随便写了个三叉树)
+
+> 因为写到这里的时候发现自己对于树并不是很熟,所以就写了练习补了一下......
+
+```go
+package structural
+
+import (
+ "errors"
+ "fmt"
+)
+//第一版写的(有点问题)
+
+type TreeNode struct {
+ Content string
+ SonNodes []*TreeNode
+ IsNilNode bool
+ IsEnd bool
+ // 个人觉得设置空节点标志更加的方便
+ // 当一个节点的儿子节点都是空节点时,意味着这个节点是叶子节点
+ // 当一个节点本身是空节点的时候,意味他在字典树里面占据了位置,却没有装东西,看起来就像不存在一样
+}
+
+func NewTreeNode(content string) *TreeNode {
+
+ t := &TreeNode{
+ Content: content,
+ // 限制一次最多可以有几个子节点
+ // 这里我们限制为三叉树
+ // 只有在明确知道树木是几叉树的情况下,我给一组数据
+ //(给定的数据是按照约定的顺序规则以切片的形式给出给出『有点像加密与解密』,然后为在拿到这组切片,按照约定的方式,把他们按照想要的格式存储与关联起来『把一个节点作为另外一个儿子节点的过程就是关联』)
+ SonNodes: []*TreeNode{
+ nil,
+ nil,
+ nil,
+ },
+ }
+ if content == "" {
+ t.IsNilNode = true
+ t.IsEnd = true
+ } else {
+ t.IsNilNode = false
+ }
+ return t
+}
+
+func (t *TreeNode) AddSonNodes(nodes []*TreeNode) error {
+ if t.IsNilNode {
+ return nil
+ } else {
+ t.SonNodes = append([]*TreeNode{}, nodes...)
+ return nil
+ }
+}
+
+// Root 节点不存储任何内容
+type DictionaryTree struct {
+ Root *Root
+ NodeNum int
+}
+
+// 表明根节点类型,对根节点类型进行限制
+type Root struct {
+ SonNodes *TreeNode
+}
+
+func NewRootNode() *Root {
+ return &Root{}
+}
+
+func (r *Root) AddSonNodes(nodes *TreeNode) {
+ r.SonNodes = nodes
+}
+
+func NewDictionaryTree(slice []string) *DictionaryTree {
+ d := &DictionaryTree{}
+ d.Root = NewRootNode()
+ if len(slice) < 3 {
+ return d
+ }
+
+ nodeptrSile := []*TreeNode{}
+ for i := 0; i < len(slice); i++ {
+ nodeptrSile = append(nodeptrSile, NewTreeNode(slice[i]))
+ }
+
+ d.Root.AddSonNodes(nodeptrSile[0])
+ layers := Getlayers(len(nodeptrSile), 3)
+ fmt.Printf("layers is %d\n", layers)
+ for i := 0; i < len(nodeptrSile); i++ {
+ n := []*TreeNode{nil, nil, nil}
+
+ if (i*3 + 1) <= len(nodeptrSile)-1 {
+ n[0] = nodeptrSile[i*3+1]
+ }
+ if (i*3 + 2) <= len(nodeptrSile)-1 {
+ n[1] = nodeptrSile[i*3+2]
+ }
+ if (i*3 + 3) <= len(nodeptrSile)-1 {
+ n[2] = nodeptrSile[i*3+3]
+ }
+ nodeptrSile[i].AddSonNodes(n)
+ if (nodeptrSile[i].SonNodes[0] == nil) && (nodeptrSile[i].SonNodes[1] == nil) && (nodeptrSile[i].SonNodes[2] == nil) {
+ nodeptrSile[i].IsEnd = true
+ }
+ }
+ d.NodeNum = len(slice)
+ return d
+}
+
+func Getlayers(nodesNum int, ratio int) int {
+ if ratio <= 0 {
+ return 0
+ }
+ i := 1
+ num := 1
+ for num < nodesNum {
+ num = num + i*ratio
+ i = i + 1
+ }
+ return i - 1
+}
+
+func (d *DictionaryTree) TraverseDictionaryTree() []string {
+ nodes := []*TreeNode{}
+ nodes = append(nodes, d.Root.SonNodes)
+ for i := 0; i < len(nodes); i++ {
+ if nodes[i].IsEnd {
+ continue
+ }
+ if nodes[i].IsNilNode {
+ continue
+ }
+
+ nodes = append(nodes, nodes[i].SonNodes...)
+
+ }
+ result := []string{}
+ for _, v := range nodes {
+ result = append(result, v.Content)
+ }
+ return result
+
+}
+
+func InterfaceToInt(i interface{}) (int, error) {
+ v, ok := i.(int)
+ if ok {
+ return v, nil
+ } else {
+ return 0, errors.New("interface type inputed can not be covered to int type")
+ }
+}
+
+func InterfaceToString(i interface{}) (string, error) {
+ v, ok := i.(string)
+ if ok {
+ return v, nil
+ } else {
+ return "", errors.New("interface type inputed can not be covered to string type")
+ }
+}
+
+```
+
+```go
+ package structural
+
+import (
+ "fmt"
+ "testing"
+)
+// 第一版的测试(有点问题)
+type Datas struct {
+ input []string
+ want []string
+}
+
+func TestTree(t *testing.T) {
+ input := []string{
+ "b",
+ "a", "i", "",
+ "g", "n", "t",
+ "g", "l", "t",
+ }
+ // 3 9 27
+ // 3n+3 3n+4 3n+5
+ datas := Datas{
+ input: input,
+ }
+ d := NewDictionaryTree(datas.input)
+ want := d.TraverseDictionaryTree()
+ fmt.Println("input:", datas.input)
+ fmt.Println("want:", want)
+ for k, v := range datas.input {
+ t.Run("test"+v, func(t *testing.T) {
+ if v != want[k] {
+ t.Errorf("get:%s ,want:%s", want[k], v)
+ }
+ })
+ }
+}
+
+```
+
+```go
+package structural
+
+import (
+ "errors"
+ "fmt"
+ "math"
+)
+// 第二版(正确)
+type TreeNode struct {
+ Content string
+ SonNodes []*TreeNode
+ IsNilNode bool
+ IsEnd bool
+ // 个人觉得设置空节点标志更加的方便
+ // 当一个节点的儿子节点都是空节点时,意味着这个节点是叶子节点
+ // 当一个节点本身是空节点的时候,意味他在字典树里面占据了位置,却没有装东西,看起来就像不存在一样
+}
+
+func NewTreeNode(content string) *TreeNode {
+ t := &TreeNode{
+ Content: content,
+ // 限制一次最多可以有几个子节点
+ // 这里我们限制为三叉树
+ // 只有在明确知道树木是几叉树的情况下,我给一组数据
+ //(给定的数据是按照约定的顺序规则以切片的形式给出给出『有点像加密与解密』,然后为在拿到这组切片,按照约定的方式,把他们按照想要的格式存储与关联起来『把一个节点作为另外一个儿子节点的过程就是关联』)
+ SonNodes: []*TreeNode{},
+ }
+ if content == "" {
+ t.IsNilNode = true
+ // 只有最后一层才是
+ } else {
+ t.IsNilNode = false
+ }
+ return t
+}
+
+func (t *TreeNode) AddSonNodes(nodes []*TreeNode) error {
+ // 是空节点但是不是叶子节点
+ if t.IsNilNode && !t.IsEnd {
+ t.SonNodes = append([]*TreeNode{}, []*TreeNode{
+ // 不是nil,而是
+ NewTreeNode(""),
+ NewTreeNode(""),
+ NewTreeNode(""),
+ }...)
+
+ }
+ // 每一个新建的节点最开始都是把它当作叶子节点
+ if t.IsNilNode {
+ t.SonNodes = append([]*TreeNode{}, nodes...)
+ return nil
+ } else {
+ t.SonNodes = append([]*TreeNode{}, nodes...)
+ return nil
+ }
+}
+
+// Root 节点不存储任何内容
+type DictionaryTree struct {
+ Root *Root
+ NodeNum int
+}
+
+// 表明根节点类型,对根节点类型进行限制
+type Root struct {
+ SonNodes []*TreeNode
+}
+
+func NewRootNode() *Root {
+ return &Root{}
+}
+
+func (r *Root) AddSonNodes(nodes []*TreeNode) {
+ r.SonNodes = append([]*TreeNode{}, nodes...)
+}
+
+func NewDictionaryTree(slice []string) *DictionaryTree {
+ d := &DictionaryTree{}
+ d.Root = NewRootNode()
+ if len(slice) < 3 {
+ return d
+ }
+
+ nodeptrSile := []*TreeNode{}
+ for i := 0; i < len(slice); i++ {
+ nodeptrSile = append(nodeptrSile, NewTreeNode(slice[i]))
+ }
+ d.Root.AddSonNodes([]*TreeNode{
+ nodeptrSile[0],
+ nodeptrSile[1],
+ nodeptrSile[2],
+ })
+
+ layers := Getlayers(len(nodeptrSile), 3)
+ fmt.Printf("layers is %d\n", layers)
+ //算出最后一层的下标
+
+ tag := (3 * (1 - math.Pow(3, float64(layers-1)))) / (-2)
+ fmt.Print("tag:", tag)
+
+ for i := 0; i < int(tag); i++ {
+ var left *TreeNode
+ var mid *TreeNode
+ var right *TreeNode
+ n := []*TreeNode{}
+ if (i*3 + 3) <= len(nodeptrSile)-1 {
+ left = nodeptrSile[i*3+3]
+ n = append(n, left)
+
+ //fmt.Print("child node 0 is ", n[0])
+ }
+ if (i*3 + 4) <= len(nodeptrSile)-1 {
+ mid = nodeptrSile[i*3+4]
+ n = append(n, mid)
+ //fmt.Print("child node 1 is ", n[1])
+ }
+ if (i*3 + 5) <= len(nodeptrSile)-1 {
+ right = nodeptrSile[i*3+5]
+ n = append(n, right)
+ //fmt.Print("child node 1 is ", n[1])
+ }
+ nodeptrSile[i].AddSonNodes(n)
+ }
+
+ d.NodeNum = len(slice)
+ return d
+}
+
+func Getlayers(nodesNum int, ratio int) int {
+ if ratio <= 0 {
+ return 0
+ }
+ i := 1
+ num := 3
+ for num < nodesNum {
+ num = num + i*ratio
+ i = i + 1
+ }
+ return i - 1
+}
+
+func (d *DictionaryTree) TraverseDictionaryTree() []string {
+ nodes := []*TreeNode{}
+ nodes = append(nodes, d.Root.SonNodes...)
+ for i := 0; i < len(nodes); i++ {
+ if nodes[i].IsEnd {
+ continue
+ }
+ // 就算是nil 节点,下面也还是有节点的,为了保证满,才能用下标阿
+ nodes = append(nodes, nodes[i].SonNodes...)
+
+ }
+ result := []string{}
+ for _, v := range nodes {
+ result = append(result, v.Content)
+ }
+ return result
+
+}
+
+func InterfaceToInt(i interface{}) (int, error) {
+ v, ok := i.(int)
+ if ok {
+ return v, nil
+ } else {
+ return 0, errors.New("interface type inputed can not be covered to int type")
+ }
+}
+
+func InterfaceToString(i interface{}) (string, error) {
+ v, ok := i.(string)
+ if ok {
+ return v, nil
+ } else {
+ return "", errors.New("interface type inputed can not be covered to string type")
+ }
+}
+
+```
+
+
+
+```go
+package structural
+
+import (
+ "fmt"
+ "testing"
+)
+// 第二版的测试(正确)
+
+type Datas struct {
+ input []string
+ want []string
+}
+
+func TestTree(t *testing.T) {
+ input := []string{
+ "b", "", "",
+ "a", "i", "",
+ //保证除了最后一层,其他层都是满的
+ "", "", "", "", "", "", "",
+ "g", "n", "t",
+ "g", "l", "t",
+ }
+ // 3 9 27
+ // 3n+3 3n+4 3n+5
+ datas := Datas{
+ input: input,
+ }
+ d := NewDictionaryTree(datas.input)
+ want := d.TraverseDictionaryTree()
+ fmt.Println("input:", datas.input)
+ fmt.Println("want:", want)
+ for k, v := range datas.input {
+ t.Run("test"+v, func(t *testing.T) {
+ if v != want[k] {
+ t.Errorf("get:%s ,want:%s", want[k], v)
+ }
+ })
+ }
+}
+```
+
+- 是三叉树,每个节点有三个孩子节点。
+- 根节点root 不存储任何数据。
+- 除了最后一层外,其他层都是满的,哪怕某个节点,它的三个孩子节点里面只有一个存储着真正的数据,那么其他孩子节点也要占据位置。
+
+
+
+
+
+
+
+
+
+## 3.中间件
+
+
+
+## 4.请求校验
+
+## 5.数据库
+
+## 6.服务流量限制
+
+## 7.Web项目结构化
+
+## 8.接口和表驱动开发
+
+## 9.灰度发布和A/B测试
diff --git a/_posts/2022-10-10-test-markdown.md b/_posts/2022-10-10-test-markdown.md
new file mode 100644
index 000000000000..bb0eeb783c9c
--- /dev/null
+++ b/_posts/2022-10-10-test-markdown.md
@@ -0,0 +1,88 @@
+---
+layout: post
+title: 哈佛的6堂独立思考课
+subtitle: 独立思考
+tags: [哈佛课程]
+---
+
+# 一些思考
+
+## 1.Lesson--建立自我意见
+
+> 为什么我们不擅长应对“突发状况?
+
+1. 思考需要练习
+2. 向自己提问,思考根据(为什么要选择它?)
+3. 比较选择,(为什么要选择 A,而不是 B?)
+4. 为什么 ABC 可以完成工作?
+5. 建立自我意见
+6. 确认自己对意见事情的理解程度(我到底懂了没?)
+7. 明白具体的疑惑点(疑惑的到底是哪个点?)
+8. 保持一个又依据的意见(观点)
+
+## 2.Lesson--深入理解
+
+> 思考不要停留在已有的东西(包括理所当然的认为是对的事情)
+
+1. 检验是否真正理解某个事情的方法
+2. 5 岁小孩都明白所说的
+3. 深入的理解“专业用语”表达的内核
+4. 翻译成英语讲出来
+5. 使用理解程度检查表
+6. 用 5w1h 反驳
+7. 用信号灯色记号笔来帮助思考
+8. 临时被人征求意见时提出好问题
+9. 提出好问题的 12 项原则:
+
+- “何时何地谁做了什么、怎么做”
+- 为了什么目的,为什么这么有把握
+- 对信息提问
+- 探究必要性
+- 引用相似但不同的例子
+- 检验模糊的用词
+- 确认事物的两面性
+- 询问契机、起因
+- 探究为什么是“现在”
+- 询问长期性发展
+- 以采访者的姿态追问背景
+
+## 3.Lesson--从多种角度看待问题,深入思考
+
+> 用“和自己不同的观点”思考
+
+1. 让思考更有深度的 4 个技巧
+
+- 站在不可忽略者的角度来思考
+- 以崭新的观点来获得不同角度的看法
+- 一人辩证法(设定另一个我,反驳自己的每个想法)
+- 通过反驳清单,重新审视意见
+- 意外状况如何判断——思考突发状况
+
+## 4.Lesson--预测将来会发生的事,决定现在应该采取的行动
+
+1. 预测未来的 4 个步骤
+2. 该方案如果成为现实,会发生什么,同时设想发展顺利与发展不顺利时的情况
+3. 成功时的情节和失败时的情节,思考有没有面对这两种情况时应采取的措施
+4. 思考该措施有没有实现的可能
+5. 思考该行动有没有现在执行的必要
+6. 是否有隐藏的前提
+7. 以肯定句式写下难以决断的行动
+8. 明确自己的目的,想想为什么要采取那个行动
+9. 写出有哪些方法可达成目的
+10. 预测可能获得的结果,写出发展顺利与不顺利的情况
+11. 删去“不合乎逻辑”或“不具现实性”的项目
+
+## 5.Lesson--“交换意见”的规则
+
+1. 世界上没有绝对正确的意见
+2. 重要的地方用不同的表达方式再三重复
+3. 问根据(这么说根据是什么?)
+4. 要反对就要提出“替代方案”
+
+## 6.Lesson--发现“问题”是“思考”的开始
+
+> 模糊不清的情绪中,藏着真正的想法
+
+1. 找到真正让自己重视的东西
+2. 不压抑那种感觉,承认它的存在
+3. 承认某事对自己来说很重要
diff --git a/_posts/2022-10-11-test-markdown.md b/_posts/2022-10-11-test-markdown.md
new file mode 100644
index 000000000000..c9f081c33882
--- /dev/null
+++ b/_posts/2022-10-11-test-markdown.md
@@ -0,0 +1,292 @@
+---
+layout: post
+title: Golang http.ListenAndServe()中的nil背后
+subtitle: http.ListenAndServe(":8000", nil)
+tags: [golang]
+---
+
+# DefaultServeMux
+
+## 1.`func ListenAndServe(addr string, handler Handler) error`
+
+> 该方法会执行标准的 socket 连接过程,bind -> listen -> accept,当 accept 时启动新的协程处理客户端 socket,调用 Handler.ServeHTTP() 方法,处理结束后返回响应。传入的 Handler 为 nil,会默认使用 DefaultServeMux 作为 Handler
+
+> http.HandleFunc() 就是给 DefaultServeMux 添加一条路由以及对应的处理函数
+
+> DefaultServeMux.ServeHTTP() 被调用时,则会查找路由并执行对应的处理函数
+
+> DefaultServeMux 的作用简单理解就是:路由注册『类似 middware.Use()』、路由匹配、请求处理。
+
+## 2.Gin 中的路由注册
+
+```go
+ r := gin.Default()
+ r.GET("/", func(c *gin.Context) {
+ c.String(200, "Hello World")
+ })
+ r.Run() // listen and serve on 0.0.0.0:8080
+```
+
+```go
+func (engine *Engine) Run(addr ...string) (err error) {
+ // ...
+ address := resolveAddress(addr)
+ debugPrint("Listening and serving HTTP on %s\n", address)
+ err = http.ListenAndServe(address, engine)
+ return
+}
+
+```
+
+> 可以发现 http.ListenAndServe() 方法使用了 engine 作为 Handler,『这里要求传入的是一个实现了 ServeHTTP 的实例』即 engine 取代 DefaultServeMux 了来处理路由注册、路由匹配、请求处理等任务。现在直接看 Engine.ServeHTTP()
+
+```go
+func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
+ // ...
+
+ engine.handleHTTPRequest(c)
+
+ // ...
+}
+```
+
+> engine.handleHTTPRequest(c) 通过路由匹配后得到了对应的 HandlerFunc 列表(表示注册的中间件或者路由处理方法,从这里可以看出所谓的中间件和路由处理方法其实是相同类型的。 然后调用 c.Next()开始处理责任链
+
+```go
+func (engine *Engine) handleHTTPRequest(c *Context) {
+ // ...
+
+ // Find root of the tree for the given HTTP method
+ t := engine.trees
+ for i, tl := 0, len(t); i < tl; i++ {
+ // ...
+ // Find route in tree
+ value := root.getValue(rPath, c.params, unescape)
+ if value.params != nil {
+ c.Params = *value.params
+ }
+ if value.handlers != nil {
+ // 这里就是责任链模式的变体
+ // 通过路由匹配后得到了对应的 HandlerFunc 列表
+ c.handlers = value.handlers
+ c.fullPath = value.fullPath
+ // 调用链上第一个实例的方法就会依次向下调用
+ c.Next()
+ c.writermem.WriteHeaderNow()
+ return
+ }
+ // ...
+ break
+ }
+
+ // ...
+}
+
+func (c *Context) Next() {
+ c.index++
+ for c.index < int8(len(c.handlers)) {
+ c.handlers[c.index](c)
+ c.index++
+ }
+}
+```
+
+## 3.简化版(理解简单)
+
+```go
+type HandlerFunc func(*Request)
+
+type Request struct {
+ url string
+ handlers []HandlerFunc
+ index int // 新增
+}
+
+func (r *Request) Use(handlerFunc HandlerFunc) {
+ r.handlers = append(r.handlers, handlerFunc)
+}
+
+// 新增
+func (r *Request) Next() {
+ r.index++
+ for r.index < len(r.handlers) {
+ r.handlers[r.index](r)
+ r.index++
+ }
+}
+
+// 修改
+func (r *Request) Run() {
+ //移动下标到初始的位置
+ r.index = -1
+ r.Next()
+}
+
+// 测试
+// 输出 1 2 3 11
+func main() {
+ r := &Request{}
+ r.Use(func(r *Request) {
+ fmt.Print(1, " ")
+ r.Next()
+ fmt.Print(11, " ")
+ })
+ r.Use(func(r *Request) {
+ fmt.Print(2, " ")
+ })
+ r.Use(func(r *Request) {
+ fmt.Print(3, " ")
+ })
+ r.Run()
+```
+
+> 首先在 Request 结构体中新增了 index 属性,用于记录当前执行到了第几个 HandlerFunc 然后新增 Next() 方法支持"手动调用责任链 "中之后的 HandlerFunc.另外需要注意的是,Gin 框架中 handlers 和 index 信息放在了 Context 里面
+
+```go
+type Context struct {
+ // ...
+ handlers HandlersChain
+ index int8
+
+ engine *Engine
+ // ...
+}
+```
+
+> 其中,HandlersChain 就是一个 HandlerFunc 切片
+
+```go
+type HandlerFunc func(*Context)
+type HandlersChain []HandlerFunc
+```
+
+## gorm 中的责任链模式
+
+> GORM 中增删改查都会涉及到责任链模式的使用,比如 Create()、Delete()、Update()、First() 等等,这里以 First() 为例
+
+```go
+func (db *DB) First(dest interface{}, conds ...interface{}) (tx *DB) {
+ // ...
+ return tx.callbacks.Query().Execute(tx)
+}
+```
+
+> tx.callbacks.Query() 返回 processor 对象,然后执行其 Execute() 方法
+
+```go
+func (cs *callbacks) Query() *processor {
+ return cs.processors["query"]
+}
+```
+
+```go
+func (p *processor) Execute(db *DB) *DB {
+ // ...
+
+ for _, f := range p.fns {
+ f(db)
+ }
+
+ // ...
+}
+```
+
+> 就是在这个位置调用了与操作类型绑定的处理函数。嗯?操作类型是啥意思?对应的处理函数又有哪些?想解决这几个问题,需要搞清楚 callbacks 的定义、初始化、注册。callbacks 定义如下
+
+```go
+type callbacks struct {
+ processors map[string]*processor
+}
+
+type processor struct {
+ db *DB
+ // ...
+ fns []func(*DB)
+ callbacks []*callback
+}
+
+type callback struct {
+ name string
+ // ...
+ handler func(*DB)
+ processor *processor
+}
+```
+
+> 注册完毕后,值类似这样
+
+```go
+/*
+// ---- callbacks 结构体属性 ----
+// processors
+{
+ "create": processorCreate,
+ "query": ...,
+ "update": ...,
+ "delete": ...,
+ "row": ...,
+ "raw": ...,
+} */
+// ---- processor 结构体属性(processorCreate) ----
+// callbacks 中有 3 个 callback
+/*
+{name: gorm:query, handler: Query}
+{name: gorm:preload, handler: Preload}
+{name: gorm:after_query, handler: AfterQuery}
+*/
+// fns 对应 3 个 callback 中的 handler,不过是排过序后的
+
+```
+
+> callbacks 在 callbacks.go/initializeCallbacks() 中进行初始化
+
+```go
+func initializeCallbacks(db *DB) *callbacks {
+ return &callbacks{
+ processors: map[string]*processor{
+ "create": {db: db},
+ "query": {db: db},
+ "update": {db: db},
+ "delete": {db: db},
+ "row": {db: db},
+ "raw": {db: db},
+ },
+ }
+}
+```
+
+> 在 callbacks/callbacks.go/RegisterDefaultCallbacks 中进行注册(为了简洁,所贴代码只保留了 query 类型的回调注册)
+
+```go
+func RegisterDefaultCallbacks(db *gorm.DB, config *Config) {
+ // ...
+ //db.Callback() 返回*callbacks指针,
+ queryCallback := db.Callback().Query()
+ queryCallback.Register("gorm:query", Query)
+ queryCallback.Register("gorm:preload", Preload)
+ queryCallback.Register("gorm:after_query", AfterQuery)
+ if len(config.QueryClauses) == 0 {
+ config.QueryClauses = queryClauses
+ }
+ queryCallback.Clauses = config.QueryClauses
+
+ // ...
+}
+```
+
+> 所谓操作类型是指增删改查等操作,比如 create、delete、update、query 等等;每种操作类型绑定多个处理函数,比如 query 绑定了 Query()、Preload()、AfterQuery() 方法,其中 Query() 是核心方法,Preload() 实现预加载,AfterQuery() 类似一种 Hook 机制。
+
+```go
+// Callback returns callback manager
+func (db *DB) Callback() *callbacks {
+ return db.callbacks
+}
+
+func (cs *callbacks) Query() *processor {
+ return cs.processors["query"]
+}
+
+func (p *processor) Register(name string, fn func(*DB)) error {
+ return (&callback{processor: p}).Register(name, fn)
+}
+```
diff --git a/_posts/2022-10-12-test-markdown.md b/_posts/2022-10-12-test-markdown.md
new file mode 100644
index 000000000000..5ba5284dfdbe
--- /dev/null
+++ b/_posts/2022-10-12-test-markdown.md
@@ -0,0 +1,75 @@
+---
+layout: post
+title: 什么是 CDN?
+subtitle: 地理分布的服务器组
+tags: [ CDN]
+---
+
+## 什么是 CDN?(核心:将带宽从源服务器卸载到 CDN 服务器)
+
+ 内容交付网络是一个地理分布的服务器组,经过优化以向最终用户交付静态内容。这种静态内容几乎可以是任何类型的数据,但 CDN 最常用于交付网页及其相关文件、流式视频和音频以及大型软件包。
+
+没有 CDN
+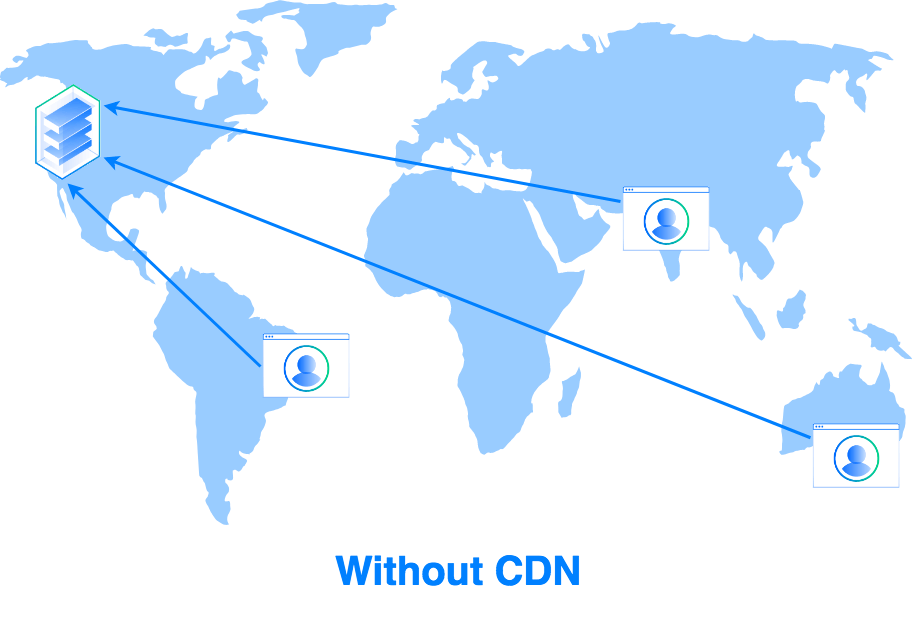
+有 CDN
+
+
+#### CDN 是由多个 POP 组成,每个 POP 是由多个边缘服务器组成,CDN 负责把请求路由到最近的边缘服务器
+
+CDN 由位于不同位置的多个接入点(PoP) 组成,每个接入点由多个边缘服务器组成,这些边缘服务器缓存来自您的源或主机服务器的资产。当用户访问您的网站并请求图像或 JavaScript 文件等静态资产时,他们的请求将由 CDN 路由到最近的边缘服务器,从中提供内容。如果边缘服务器没有缓存资产或缓存的资产已过期,CDN 将从附近的另一台 CDN 边缘服务器或您的源服务器获取并缓存最新版本。如果 CDN 边缘确实有您的资产的缓存条目(如果您的网站接收到适量的流量,大多数情况下都会发生这种情况),它会将缓存的副本返回给最终用户。
+
+## CDN 是如何工作的?
+
+当用户访问网站时,他们首先会收到来自 DNS 服务器的响应,其中包含您的主机 Web 服务器的 IP 地址。然后他们的浏览器请求网页内容,这些内容通常由各种静态文件组成,例如 HTML 页面、CSS 样式表、JavaScript 代码和图像。
+一旦推出 CDN 并将这些静态资产卸载到 CDN 服务器上,通过手动“推出”它们或让 CDN 自动“拉”资产(这两种机制都将在下一节中介绍),然后您可以指示您的 Web 服务器重写指向静态内容的链接,使这些链接现在指向由 CDN 托管的文件。如果您使用的是 WordPress 等 CMS,则可以使用 CDN Enabler 等第三方插件来实现此链接重写。
+
+缓存机制因 CDN 提供商而异,但通常它们的工作方式如下:
+
+当 CDN 收到对静态资产(例如 PNG 图像)的第一个请求时,它没有缓存资产,并且必须从附近的 CDN 边缘服务器或源服务器本身获取资产的副本。这称为缓存“未命中”.通常可以通过检查包含 X-Cache: MISS. 此初始请求将比未来请求慢,因为在完成此请求后,资产将被缓存在边缘。
+
+路由到此边缘位置的此资产的未来请求(缓存“命中”)现在将从缓存中提供服务,直到到期(通常通过 HTTP 标头设置)。这些响应将比初始请求快得多,从而显着减少用户的延迟并将 Web 流量卸载到 CDN 网络上。您可以通过检查 HTTP 响应标头来验证响应是否来自 CDN 缓存,该标头现在应该包含 X-Cache: HIT.
+
+## 推与拉 Zone
+
+#### 1.向 CDN 提供源服务器地址后重写指向静态资产的链接
+
+大多数 CDN 提供商提供两种缓存数据的方式:拉区和推送区。
+拉区涉及输入您的源服务器地址,并让 CDN 自动获取和缓存您站点上所有可用的静态资源。拉取区域通常用于交付经常更新的中小型 Web 资产,例如 HTML、CSS 和 JavaScript 文件。在向 CDN 提供您的源服务器地址后,下一步通常是重写指向静态资产的链接,以便它们现在指向 CDN 提供的 URL。从那时起,CDN 将处理您用户的传入资产请求,并根据需要从其地理分布的缓存和您的来源中提供内容。
+
+#### 2.数据上传到指定的存储桶或存储位置后 CDN 推送到分布式边缘服务器
+
+要使用 Push Zone,您需要将数据上传到指定的存储桶或存储位置,然后 CDN 会将其推送到其分布式边缘服务器队列上的缓存中。推送区域通常用于较大且不经常更改的文件,例如档案、软件包、PDF、视频和音频文件。
+
+## CDN 的好处
+
+#### 1.卸载静态资产将大大减少服务器的带宽使用量
+
+如果服务器的带宽容量已接近极限,卸载图像、视频、CSS 和 JavaScript 文件等静态资产将大大减少服务器的带宽使用量。内容交付网络是为提供静态内容而设计和优化的,客户端对该内容的请求将被路由到边缘 CDN 服务器并由其提供服务。这具有减少原始服务器负载的额外好处,因为它们随后以低得多的频率提供这些数据。
+
+#### 2.快速向用户交付内容
+
+如果用户群在地理上分散,并且流量的重要部分来自遥远的地理区域,则 CDN 可以通过在更靠近用户的边缘服务器上缓存静态资产来减少延迟。通过缩短用户与静态内容之间的距离,可以更快地向用户交付内容,并通过提高页面加载速度来改善他们的体验。
+
+对于主要服务于带宽密集型视频内容的网站而言,这些优势更加复杂,高延迟和慢加载时间更直接地影响用户体验和内容参与度。
+
+#### 3.管理流量高峰并避免停机
+
+CDN 允许通过跨大型分布式边缘服务器网络的负载平衡请求来处理大量流量峰值和突发。通过在交付网络上卸载和缓存静态内容,可以使用现有基础架构同时容纳更多用户。
+
+对于使用单个源服务器的网站,这些巨大的流量峰值通常会使系统不堪重负,从而导致计划外的中断和停机。将流量转移到高可用性和冗余的 CDN 基础架构上,旨在处理不同级别的 Web 流量,可以提高资产和内容的可用性。
+
+#### 4.减少源服务器上的负载来降低服务器成本
+
+由于提供静态内容通常占您带宽使用量的大部分,因此将这些资产卸载到内容交付网络可以大大减少您每月的基础设施支出。除了降低带宽成本外,CDN 还可以通过减少源服务器上的负载来降低服务器成本,从而使您现有的基础架构能够扩展。最后,一些 CDN 提供商提供固定价格的按月计费,允许您将可变的每月带宽使用量转变为稳定、可预测的经常性支出。
+
+#### 5.提高安全性
+
+CDN 的另一个常见用例是 DDoS 攻击缓解。许多 CDN 提供商包括监控和过滤对边缘服务器的请求的功能。这些服务分析网络流量中的可疑模式,阻止恶意攻击流量,同时继续允许信誉良好的用户流量通过。CDN 提供商通常提供各种 DDoS 缓解服务,从基础设施级别(OSI 第 3 层和第 4 层)的常见攻击保护到更高级的缓解服务和速率限制。
+
+此外,大多数 CDN 允许您配置完整的 SSL,以便您可以使用 CDN 提供的或自定义 SSL 证书加密 CDN 和最终用户之间的流量,以及 CDN 和源服务器之间的流量。
+
+#### 6.总结
+
+CDN 允许通过(吸收用户请求)并从(边缘缓存响应)来显着降低带宽使用量,从而降低带宽和基础设施成本。
+
+借助对 WordPress、Drupal、Django 和 Ruby on Rails 等主要框架的插件和第三方支持,以及 DDoS 缓解、完整 SSL、用户监控和资产压缩等附加功能,CDN 可以成为保护和优化高流量网站。
diff --git a/_posts/2022-10-13-test-markdown.md b/_posts/2022-10-13-test-markdown.md
new file mode 100644
index 000000000000..7b38a550f2e0
--- /dev/null
+++ b/_posts/2022-10-13-test-markdown.md
@@ -0,0 +1,1134 @@
+---
+layout: post
+title: 什么是 分布式?
+subtitle: 垂直伸缩和水平伸缩
+tags: [分布式]
+---
+
+## 1.分布式
+
+### 访问系统的用户过多带来的服务器崩溃
+
+> 当访问系统的用户越来越多,可是我们的系统资源有限,所以需要更多的 CPU 和内存去处理用户的计算请求,当然也就要求更大的网络带宽去处理数据的传输,也需要更多的磁盘空间存储数据。资源不够,消耗过度,服务器崩溃,系统也就不干活了,那么在这样的情况怎么处理?
+
+### 垂直伸缩(雅迪变特斯拉)
+
+> 提升单台服务器的计算处理能力来抵抗更大的请求访问量。比如使用更快频率的 CPU,更快的网卡,塞更多的磁盘等。其实这样的处理方式在电信,银行等企业比较常见,让摩托车变为小汽车,更强大的计算机。花钱买设备就完事了?
+
+ 单台服务器的计算处理能力是有限的,而且也会严重受到计算机硬件水平的制约
+
+#### 水平伸缩(多个雅典抵的上特斯拉)
+
+> 通过多台服务器构成(分布式集群)从而提升系统的整体处理能力。这里说到了分布式,那我们看看分布式的成长过程
+> 系统的技术架构是需求所驱动
+> 最初的单体系统:
+
+- 只需要部分用户访问(随着使用系统的用户越来越多,这时候关注的人越来越多,单台服务器扛不住了,关注的人觉得响应真慢)
+- 然后分离数据库和应用程序,部署在不同的服务器中,从 1 台服务器变为多台服务器,处理响应更快,内容也够干,(访问的用户呈指数增长,这多台服务器都有点扛不住了,怎么办?)
+- 然后加缓存,我们不每次从数据库中读取数据,而将应用程序需要的数据暂存在缓冲中。缓存呢,又分为本地缓存和分布式的缓存。分布式缓存,顾名思义,使用多台服务器构成集群,存储更多的数据并提供缓存服务,从而提升缓存的能力。(很多台的服务器单单存储很多的数据到内存中)
+- 系统越来越火,于是考虑将应用服务器也作为集群。
+
+## 2.缓存(提升系统的读操作性能)
+
+当用户访问网站时,他们首先会收到来自 DNS 服务器的响应,其中包含您的主机 Web 服务器的 IP 地址。然后他们的浏览器请求网页内容,这些内容通常由各种静态文件组成,例如 HTML 页面、CSS 样式表、JavaScript 代码和图像。
+一旦推出 CDN 并将这些静态资产卸载到 CDN 服务器上,通过手动“推出”它们或让 CDN 自动“拉”资产(这两种机制都将在下一节中介绍),然后您可以指示您的 Web 服务器重写指向静态内容的链接,使这些链接现在指向由 CDN 托管的文件。如果您使用的是 WordPress 等 CMS,则可以使用 CDN Enabler 等第三方插件来实现此链接重写。
+
+缓存机制因 CDN 提供商而异,但通常它们的工作方式如下:
+
+当 CDN 收到对静态资产(例如 PNG 图像)的第一个请求时,它没有缓存资产,并且必须从附近的 CDN 边缘服务器或源服务器本身获取资产的副本。这称为缓存“未命中”.通常可以通过检查包含 X-Cache: MISS. 此初始请求将比未来请求慢,因为在完成此请求后,资产将被缓存在边缘。
+
+路由到此边缘位置的此资产的未来请求(缓存“命中”)现在将从缓存中提供服务,直到到期(通常通过 HTTP 标头设置)。这些响应将比初始请求快得多,从而显着减少用户的延迟并将 Web 流量卸载到 CDN 网络上。您可以通过检查 HTTP 响应标头来验证响应是否来自 CDN 缓存,该标头现在应该包含 X-Cache: HIT.
+
+### 1.通读缓存
+
+- 应用程序和通读缓存沟通,如果通读缓存中没有需要的数据,是由通读缓存去数据源中获取数据。
+
+ > 数据存在于通读缓存中就直接返回。如果不存在于通读缓存,那么就访问数据源,同时将数据存放于缓存中。下次访问就直接从缓存直接获取。比较常见的为 CDN 和反向代理
+ > CDN 称为内容分发网络。想象我们京东购物的时候,假设我们在成都,如果买的东西在成都仓库有就直接给我们寄送过来,可能半天就到了,用户体验也非常好,就不用从北京再寄过来。同样的道理,用户就可以近距离获得自己需要的数据,既提高了响应速度,又节约了网络带宽和服务器资源
+ > 通过 CDN 等通读缓存可以降低服务器的负载能力
+
+### 2.旁路缓存
+
+- 应用程序从旁路缓存中读,如果不存在自己需要的数据,那么应用程序就去数据源负责把没有的数据拿到然后存储在旁路缓存中。
+
+ > 旁路缓存
+
+- 缓存缺点
+ - (过期失效)缓存知道自己返回的数据是正确的吗?(我缓存中的数据是从数据源中拿出的,但是缓存在返回数据的时候,数据源里面的数据是否被修改?数据源里面的数据被修改,那么我们相当于是返回了脏数据)
+- 解决办法:
+ - (失效通知)每次写入往缓存中间写入数据的时候,(记录写入数据的时间)(再设置一个固定的时间),每次读取数据的时候根据记录的这个数据的写入时间,判断数据是否过期,如果时间过期,缓存就重新从数据源里面读取数据。
+ - 当数据源的数据被修改的时候就一定要通知缓存清空
+- 缓存的意义?
+ - 存储热点数据,并且存储的数据被多次命中。
+
+## 3.异步架构(提升系统的写操作性能)
+
+> 缓存通常很难保证数据的持久性和一致性.我们通常不会将数据直接写入缓存中,而是写入 RDBMAS 等数据中,那如何提升系统的写操作性能呢?
+> 也就是说,数据库是专门用来做存储的。
+> 此时假设两个系统分别为 A,B,其中 A 系统依赖 B 系统,两者通信采用远程调用的方式,此时如果 B 系统出故障,很可能引起 A 系统出故障.(缓存不能保证数据的持久且唯一)
+
+### 1.消息队列
+
+#### 同步
+
+> 同步通常是当应用程序调用服务的时候,不得不阻塞等待服务期完成,此时 CPU 空闲比较浪费,直到返回服务结果后才会继续执行。
+
+- 特点:(阻塞并等待结果)(执行应用程序的线程阻塞 )
+- 问题:不能释放占用的系统资源,导致系统资源不足,影响系统性能
+- 问题:无法快速给用户响应结果
+
+> 那么什么情况下可以不用阻塞,释放占用的系统资源?
+
+#### 异步
+
+- **调用者将消息发送给消息队列直接返回** ,线程不需要得到发送结果,它只需要执行完就好。例如(用户注册)(在用户注册完毕,不论我们的服务器是否真的已经账号激活的邮件给用户,页面都会提示用户:“您的邮件已经发送成功!请注意查收”)往往只让用户等待接收邮件就好,而不是我们实际的代码等待我们的服务器真正发送给用户邮件的时候才给用户显示:“邮件已经发送成功”
+
+- **有专门的“消费消息的程序”从消息队列中取出数据并进行消费。** 远程服务出现故障,只会影响到" 消费消息的程序"
+
+##### 异步消费的方式
+
+- 点对点
+ > 对多生产者多消费者的情况:一个消息被一个消费者消费
+- 订阅消费
+ > 给消息队列设置主题。每个消费者只从对应的主题中消费,每个消费者按照自己的逻辑进行计算。在用户注册的时候,我们将注册信息放入“用户“主题中,消费者如果订阅了“用户“主题,就可以消费该信息进行自己的业务处理。举个例子:可能有"拿用户信息去构造短信消息的"消费者,也有“拿着用户信息去推广产品的“消费者,都可以根据自己业务逻辑进行数据处理。
+
+##### 异步消费的优点
+
+- 快速响应
+ > 不在需要等待。生产者将数据发送消息队列后,可继续往下执行,不虚等待耗时的消费处理
+- 削峰填谷
+ > 互联网产品会在不同的场景其并发请求量不同。互联网应用的访问压力随时都在变化,系统的访问高峰和低谷的并发压力可能也有非常大的差距。如果按照压力最大的情况部署服务器集群,那么服务器在绝大部分时间内都处于闲置状态。但利用消息队列,我们可以将需要处理的消息放入消息队列,而消费者可以控制消费速度,因此能够降低系统访问高峰时压力,而在访问低谷的时候还可以继续消费消息队列中未处理的消息,保持系统的资源利用率
+- 降低耦合
+
+> 如果调用是同步,如果调用是同步的,那么意味着调用者和被调用者必然存在依赖,一方面是代码上的依赖,应用程序需要依赖发送邮件相关的代码,如果需要修改发送邮件的代码,就必须修改应用程序,而且如果要增加新的功能
+
+那么目前主要的消息队列有哪些,其有缺点是什么?
+
+- 解耦!!
+ > 某个 A 系统与要提供数据系统产生耦合
+- 异步!!
+ > 用户一个点击,需要几个系统间的一系列反应,同时每一个系统肯都存在一定的耗时,那么可以使用 mq 对不同的系统进行发送命令,进行异步操作
+- 削峰!!
+ > (mysql 每秒 2000 个请求),超过就会卡死,峰取时在 MQ 中进行大量请求积压,处理器按照自己的最大处理能力取请求量,等请求期过后再把它消耗掉。
+
+## 4. 负载均衡
+
+
+
+> 一台机器扛不住了,需要多台机器帮忙,既然使用多台机器,就希望不要把压力都给一台机器,所以需要一种或者多种策略分散高并发的计算压力,从而引入负载均衡,那么到底是如何分发到不同的服务器的呢?
+
+### 负载均衡策略(基于负载均衡服务器-一个由很多普通的服务器组成的一个系统)
+
+> 在需要处理大量用户请求的时候,通常都会引入负载均衡器,将多台普通服务器组成一个系统,来完成高并发的请求处理任务。
+
+#### HTTP 重定向负载均衡
+
+也属于比较直接,当 HTTP 请求到达负载均衡服务器后,使用一套负载均衡算法计算到后端服务器的地址,然后将新的地址给用户浏览器
+
+先计算到应用服务器的 IP 地址,所以 IP 地址可能暴露在公网,既然暴露在了公网还有什么安全可言
+
+#### DNS 负载均衡
+
+用户通过浏览器发起 HTTP 请求的时候,DNS 通过对域名进行即系得到 IP 地址,用户委托协议栈的 IP 地址简历 HTTP 连接访问真正的服务器。这样(不同的用户进行域名解析将会获取不同的 IP 地址)从而实现负载均衡
+
+- 通过 DNS 解析获取负载均衡集群某台服务器的地址
+- 负载均衡服务器再一次获取某台应用服务器,这样子就不会将应用服务器的 IP 地址暴露在官网了
+
+#### 反向代理负载均衡
+
+反向代理服务器,服务器先看本地是缓存过,有直接返回,没有则发送给后台的应用服务器处理。
+
+#### IP 负载均衡
+
+IP 很明显是从网络层进行负载均衡。TCP./IP 协议栈是需要上下层结合的方式达到目标,当请求到达网络层的时候。负载均衡服务器对数据包中的 IP 地址进行转换,从而发送给应用服务器
+这个方案属于内核级别,如果数据比较小还好,但是大部分情况是图片等资源文件,这样负载均衡服务器会出现响应或者请求过大所带来的瓶颈
+
+#### 数据链路负载均衡
+
+它可以解决因为数据量他打而导致负载均衡服务器带宽不足这个问题。怎么实现的呢。它不修改数据包的 IP 地址,而是更改 mac 地址。(应用服务器和负载均衡服务器使用相同的虚拟 IP)
+
+### 负载均衡算法
+
+> 轮询,加权轮循, 随机,最少连接, 源地址散列
+
+> 前置的介绍
+
+```go
+// Peer 是一个后端节点
+type Peer interface {
+ String() string
+}
+
+// 选取(Next(factor))一个 Peer 时由调度者所提供的参考对象,Balancer 可能会将其作为选择算法工作的因素之一。
+type Factor interface {
+ Factor() string
+}
+
+// Factor的具体实现实现
+type FactorString string
+
+func (s FactorString) Factor() string {
+ return string(s)
+}
+
+// 负载均衡器 Balancer 持有一组 Peers 然后实现Next函数,得到一个后端节点和Constrainable(目前先当作没有看到它叭~) 当身为调度者时,想要调用 Next,却没有什么合适的“因素”提供的话,就提供 DummyFactor 好了。
+type BalancerLite interface {
+ Next(factor Factor) (next Peer, c Constrainable)
+}
+// Balancer 在选取(Next(factor))一个 Peer 时由调度者所提供的参考对象,Balancer 可能会将其作为选择算法工作的因素之一。
+type Balancer interface {
+ BalancerLite
+ //...more
+}
+
+```
+
+1. 轮询
+
+ 轮询很容易实现,将请求按顺序轮流分配到后台服务器上,均衡的对待每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
+ 适合场景:适合于应用服务器硬件都相同的情况
+ 
+ 为了保证轮询,必须记录上次访问的位置,为了让在并发情况下不出现问题,还必须在使用位置记录时进行加锁,很明显这种互斥锁增加了性能开销。
+
+```go
+package RoundRobin
+
+import (
+ "fmt"
+ Balancer "github.com/VariousImplementations/LoadBalancingAlgorithm"
+ "strconv"
+ "sync"
+ "sync/atomic"
+ "time"
+)
+
+type RoundRobin struct {
+ peers []Balancer.Peer
+ count int64
+ rw sync.RWMutex
+}
+
+// New 使用 Round-Robin 创建一个新的负载均衡器实例
+func New(opts ...Balancer.Opt) Balancer.Balancer {
+ return &RoundRobin{}
+}
+
+// RoundRobin 需要实现 Balancer接口下面的方法Balancer.Next() Balancer.Count() Balancer.Add() Balancer.Remove() Balancer.Clear()
+func (s *RoundRobin) Next(factor Balancer.Factor) (next Balancer.Peer, c Balancer.Constrainable) {
+ next = s.miniNext()
+ if fc, ok := factor.(Balancer.FactorComparable); ok {
+ next, c, _ = fc.ConstrainedBy(next)
+ } else if nested, ok := next.(Balancer.BalancerLite); ok {
+ next, c = nested.Next(factor)
+ }
+
+ return
+}
+
+// s.count 会一直增量上去,并不会取模
+// s.count 增量加1就是轮询的核心
+// 这样做的用意在于如果 peers 数组发生了少量的增减变化时,最终发生选择时可能会更模棱两可。
+// 但是!!!注意对于 Golang 来说,s.count 来到 int64.MaxValue 时继续加一会自动回绕到 0。
+// 这一特性和多数主流编译型语言相同,都是 CPU 所提供的基本特性
+// 核心的算法 s.count 对后端节点的列表长度取余
+func (s *RoundRobin) miniNext() (next Balancer.Peer) {
+ ni := atomic.AddInt64(&s.count, 1)
+ ni--
+ // 加入读锁
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ if len(s.peers) > 0 {
+ ni %= int64(len(s.peers))
+ next = s.peers[ni]
+ }
+ fmt.Printf("s.peers[%d] is be returned\n", ni)
+ return
+}
+func (s *RoundRobin) Count() int {
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ return len(s.peers)
+}
+
+func (s *RoundRobin) Add(peers ...Balancer.Peer) {
+ for _, p := range peers {
+ s.AddOne(p)
+ }
+}
+
+func (s *RoundRobin) AddOne(peer Balancer.Peer) {
+ if s.find(peer) {
+ return
+ }
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ s.peers = append(s.peers, peer)
+}
+
+func (s *RoundRobin) find(peer Balancer.Peer) (found bool) {
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ for _, p := range s.peers {
+ if Balancer.DeepEqual(p, peer) {
+ return true
+ }
+ }
+ return
+}
+
+func (s *RoundRobin) Remove(peer Balancer.Peer) {
+ // 加写锁
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ for i, p := range s.peers {
+ if Balancer.DeepEqual(p, peer) {
+ s.peers = append(s.peers[0:i], s.peers[i+1:]...)
+ return
+ }
+ }
+}
+
+func (s *RoundRobin) Clear() {
+ // 加写锁
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ s.peers = nil
+}
+
+func Client() {
+ // wg让主进程进行等待我所有的goroutinue 完成
+ wg := sync.WaitGroup{}
+ // 假设我们有20个不同的客户端(goroutinue)去调用我们的服务
+ wg.Add(20)
+ lb := &RoundRobin{
+ peers: []Balancer.Peer{
+ Balancer.ExP("172.16.0.10:3500"), Balancer.ExP("172.16.0.11:3500"), Balancer.ExP("172.16.0.12:3500"),
+ },
+ count: 0,
+ }
+ for i := 0; i < 10; i++ {
+ go func(t int) {
+ lb.Next(Balancer.DummyFactor)
+ wg.Done()
+ time.Sleep(2 * time.Second)
+ // 这句代码第一次运行后,读解锁。
+ // 循环到第二个时,读锁定后,这个goroutine就没有阻塞,同时读成功。
+ }(i)
+
+ go func(t int) {
+ str := "172.16.0." + strconv.Itoa(t) + ":3500"
+ lb.Add(Balancer.ExP(str))
+ fmt.Println(str + " is be added. ")
+ wg.Done()
+ // 这句代码让写锁的效果显示出来,写锁定下是需要解锁后才能写的。
+ time.Sleep(2 * time.Second)
+ }(i)
+ }
+
+ time.Sleep(5 * time.Second)
+ wg.Wait()
+}
+
+```
+
+```go
+package RoundRobin
+
+import "testing"
+
+func TestFormal(t *testing.T) {
+ Client()
+}
+
+```
+
+2. 加权轮循
+ 在轮询的基础上根据硬件配置不同,按权重分发到不同的服务器。
+ 适合场景:跟配置高、负载低的机器分配更高的权重,使其能处理更多的请求,而性能低、负载高的机器,配置较低的权重,让其处理较少的请求。
+ 
+
+3. 随机
+ 系统随机函数,根据后台服务器列表的大小值来随机选取其中一台进行访问。
+ 随着调用量的增大,客户端的请求可以被均匀地分派到所有的后端服务器上,其实际效果越来越接近于平均分配流量到后台的每一台服务器,也就是轮询法的效果。
+
+```go
+// 简单版实现
+import (
+ "errors"
+ "fmt"
+ "math/rand"
+ "strconv"
+)
+
+// 随机访问中需要什么来保证随机?
+type serverList struct {
+ ipList []string
+}
+
+func NewserverList(str ...string) *serverList {
+ return &serverList{
+ ipList: append([]string{}, str...),
+ }
+}
+
+func (s *serverList) AddIP(str ...string) {
+ s.ipList = append(s.ipList, str...)
+}
+
+func (s *serverList) GetIPLIst() []string {
+ return s.ipList
+}
+
+func (s *serverList) GetIP(i int) string {
+ return s.ipList[i]
+}
+
+
+func Random(str ...string) (string, error) {
+ serverList := NewserverList(str...)
+ r := rand.Int()
+ l := len(serverList.GetIPLIst())
+ fmt.Printf("len %d", l)
+ end := strconv.Itoa(r % l)
+ fmt.Printf("end %s\n", end)
+ for _, v := range serverList.GetIPLIst() {
+ test := v[len(v)-1:]
+ fmt.Println(test)
+ if test == end {
+ return v, nil
+ }
+
+ }
+ /*
+ return serverList.GetIP(end)
+ */
+ return "", errors.New("get ip error")
+}
+```
+
+```go
+// 测试函数
+import (
+ "fmt"
+ "testing"
+)
+
+func TestRadom(t *testing.T) {
+ re, err := Random(
+ "192.168.1.0",
+ "192.168.1.1",
+ "192.168.1.2",
+ "192.168.1.3",
+ "192.168.1.4",
+ "192.168.1.5",
+ "192.168.1.6",
+ "192.168.1.7",
+ "192.168.1.8",
+ "192.168.1.9",
+ )
+ if err != nil {
+ t.Error(err)
+ }
+ fmt.Println(re)
+}
+
+```
+
+```go
+// 另外一种实现
+import (
+ "fmt"
+ "github.com/Design-Pattern-Go-Implementation/go-design-pattern/Balancer"
+ mrand "math/rand"
+ "sync"
+ "sync/atomic"
+ "time"
+)
+
+type randomS struct {
+ peers []Balancer.Peer
+ count int64
+}
+
+// 实现通用的BalancerLite 接口
+func (s *randomS) Next(factor Balancer.Factor) (next Balancer.Peer, c Balancer.Constrainable) {
+ // 传入的factor实参我们并没有使用
+ // 只是随机的产生一个数字
+ l := int64(len(s.peers))
+ // 取余数得到下标
+ // 为什么要给count +随机范围中间的数字?
+ ni := atomic.AddInt64(&s.count, inRange(0, l)) % l
+ next = s.peers[ni]
+ return
+}
+
+var seededRand = mrand.New(mrand.NewSource(time.Now().UnixNano()))
+var seedmu sync.Mutex
+
+func inRange(min, max int64) int64 {
+ seedmu.Lock()
+ defer seedmu.Unlock()
+ //在某个范围内部生成随机数字,rand.Int(最大值- 最小值)+min
+ return seededRand.Int63n(max-min) + min
+}
+
+// 实现Peer 接口
+type exP string
+
+func (s exP) String() string {
+ return string(s)
+}
+
+func Random() {
+
+ lb := &randomS{
+ peers: []Balancer.Peer{
+ exP("172.16.0.7:3500"), exP("172.16.0.8:3500"), exP("172.16.0.9:3500"),
+ },
+ count: 0,
+ }
+ // map 用来记录我们实际的后端接口到底被调用了多少次
+ sum := make(map[Balancer.Peer]int)
+ for i := 0; i < 300; i++ {
+ // 这里直接使用默认的实现类的实例
+ // DummyFactor 是默认实例
+ p, _ := lb.Next(Balancer.DummyFactor)
+ sum[p]++
+ }
+
+ for k, v := range sum {
+ fmt.Printf("%v: %v\n", k, v)
+ }
+
+}
+```
+
+```go
+// 测试函数
+import "testing"
+
+func TestRandom(t *testing.T) {
+ Random()
+}
+
+```
+
+```go
+// 线程安全实现
+//正式的 random LB 的代码要比上面的核心部分还复杂一点点。原因在于我们还需要达成另外两个设计目标:
+import (
+ "fmt"
+ mrand "math/rand"
+ "strconv"
+ "sync"
+ "sync/atomic"
+ "time"
+
+ "github.com/Design-Pattern-Go-Implementation/go-design-pattern/Balancer"
+)
+
+var seedRand = mrand.New(mrand.NewSource(time.Now().Unix()))
+var seedMutex sync.Mutex
+
+func InRange(min, max int64) int64 {
+ seedMutex.Lock()
+ defer seedMutex.Unlock()
+ return seedRand.Int63n(max-min) + min
+}
+
+// New 使用 Round-Robin 创建一个新的负载均衡器实例
+func New(opts ...Balancer.Opt) Balancer.Balancer {
+ return (&randomS{}).Init(opts...)
+}
+
+type randomS struct {
+ peers []Balancer.Peer
+ count int64
+ rw sync.RWMutex
+}
+
+func (s *randomS) Init(opts ...Balancer.Opt) *randomS {
+ for _, opt := range opts {
+ opt(s)
+ }
+ return s
+}
+
+// 实现了Balancer.NexT()方法
+func (s *randomS) Next(factor Balancer.Factor) (next Balancer.Peer, c Balancer.Constrainable) {
+ next = s.miniNext()
+
+ if fc, ok := factor.(Balancer.FactorComparable); ok {
+ next, c, ok = fc.ConstrainedBy(next)
+ } else if nested, ok := next.(Balancer.BalancerLite); ok {
+ next, c = nested.Next(factor)
+ }
+
+ return
+}
+
+// 实现了Balancer.Count()方法
+func (s *randomS) Count() int {
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ return len(s.peers)
+}
+
+// 实现了Balancer.Add()方法
+func (s *randomS) Add(peers ...Balancer.Peer) {
+ for _, p := range peers {
+ // 判断要添加的元素是否存在,并且在添加元素的时候为s.peers 加锁
+ s.AddOne(p)
+ }
+}
+
+// 实现了Balancer.Remove()方法
+// 如果 s.peers 中间有和传入的peer相等的函数就那么就删除这个元素
+// 在删除这个元素的时候,
+func (s *randomS) Remove(peer Balancer.Peer) {
+ // 加写锁
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ for i, p := range s.peers {
+ if Balancer.DeepEqual(p, peer) {
+ s.peers = append(s.peers[0:i], s.peers[i+1:]...)
+ return
+ }
+ }
+}
+
+// 实现了Balancer.Clear()方法
+func (s *randomS) Clear() {
+ // 加写锁
+ // 对于Set() ,Delete(),Update()这类操作就一般都是加写锁
+ // 对于Get() 这类操作我们往往是加读锁,阻塞对同一变量的更改操作,但是读操作将不会受到影响
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ s.peers = nil
+}
+
+// 我们希望s在返回后端peers 节点的时候,在同一个时刻只能被一个线程拿到。
+// 所以需要对 s.peers进行加锁
+func (s *randomS) miniNext() (next Balancer.Peer) {
+ // 读锁定 写将被阻塞,读不会被锁定
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ l := int64(len(s.peers))
+ ni := atomic.AddInt64(&s.count, InRange(0, l)) % l
+ next = s.peers[ni]
+ fmt.Printf("s.peers[%d] is be returned\n", ni)
+ return
+}
+
+func (s *randomS) AddOne(peer Balancer.Peer) {
+ if s.find(peer) {
+ return
+ }
+ // 加了写锁
+ // 在更改s.peers的时候,其他的线程将不可以调用s.miniNext()读出和获得peer,其他的线程也不可以调用s.AddOne()对s.peers 进行添加操作
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ s.peers = append(s.peers, peer)
+ fmt.Printf(peer.String() + "is be appended!\n")
+}
+
+func (s *randomS) find(peer Balancer.Peer) (found bool) {
+ // 加读锁
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ for _, p := range s.peers {
+ if Balancer.DeepEqual(p, peer) {
+ return true
+ }
+ }
+ fmt.Printf("peer in s.peers is be found!\n")
+ return
+}
+
+func Client() {
+ // wg让主进程进行等待我所有的goroutinue 完成
+ wg := sync.WaitGroup{}
+ // 假设我们有20个不同的客户端(goroutinue)去调用我们的服务
+ wg.Add(20)
+ lb := &randomS{
+ peers: []Balancer.Peer{
+ Balancer.ExP("172.16.0.10:3500"), Balancer.ExP("172.16.0.11:3500"), Balancer.ExP("172.16.0.12:3500"),
+ },
+ count: 0,
+ }
+ for i := 0; i < 10; i++ {
+ go func(t int) {
+ lb.Next(Balancer.DummyFactor)
+ wg.Done()
+ time.Sleep(2 * time.Second)
+ // 这句代码第一次运行后,读解锁。
+ // 循环到第二个时,读锁定后,这个goroutine就没有阻塞,同时读成功。
+ }(i)
+
+ go func(t int) {
+ str := "172.16.0." + strconv.Itoa(t) + ":3500"
+ lb.Add(Balancer.ExP(str))
+ wg.Done()
+ // 这句代码让写锁的效果显示出来,写锁定下是需要解锁后才能写的。
+ time.Sleep(2 * time.Second)
+ }(i)
+ }
+
+ time.Sleep(5 * time.Second)
+ wg.Wait()
+}
+```
+
+```go
+// 测试函数
+import "testing"
+
+func TestFormal(t *testing.T) {
+ Client()
+}
+
+```
+
+4. 最少连接
+ 最全负载均衡:算法、实现、亿级负载解决方案详解-mikechen 的互联网架构
+ 记录每个服务器正在处理的请求数,把新的请求分发到最少连接的服务器上,因为要维护内部状态不推荐。
+ 
+
+```go
+
+```
+
+5. "源地址"散列(为什么需要源地址?保证同一个客户端得到的后端列表)
+ 根据服务消费者请求客户端的 IP 地址,通过哈希函数计算得到一个哈希值,将此哈希值和服务器列表的大小进行取模运算,得到的结果便是要访问的服务器地址的序号。
+ 适合场景:根据请求的来源 IP 进行 hash 计算,同一 IP 地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
+ 
+
+```go
+
+// HashKetama 是一个带有 ketama 组合哈希算法的 impl
+type HashKetama struct {
+ // default is crc32.ChecksumIEEE
+ hasher Hasher
+ // 负载均衡领域中的一致性 Hash 算法加入了 Replica 因子,计算 Peer 的 hash 值时为 peer 的主机名增加一个索引号的后缀,索引号增量 replica 次
+ // 也就是说一个 peer 的 拥有replica 个副本,n 台 peers 的规模扩展为 n x Replica 的规模,有助于进一步提高选取时的平滑度。
+ replica int
+ // 通过每调用一次Next()函数 ,往hashRing中添加一个计算出的哈希数值
+ // 从哈希列表中得到一个哈希值,然后立即得到该哈希值对应的后端的节点
+ hashRing []uint32
+ // 每个节点都拥有一个属于自己的hash值
+ // 每往hashRing 添加一个元素就,就往map中添加一个元素
+ keys map[uint32]Balancer.Peer
+ // 得到的节点状态是否可用
+ peers map[Balancer.Peer]bool
+ rw sync.RWMutex
+}
+
+// Hasher 代表可选策略
+type Hasher func(data []byte) uint32
+
+// New 使用 HashKetama 创建一个新的负载均衡器实例
+func New(opts ...Balancer.Opt) Balancer.Balancer {
+
+ return (&HashKetama{
+ hasher: crc32.ChecksumIEEE,
+ replica: 32,
+ keys: make(map[uint32]Balancer.Peer),
+ peers: make(map[Balancer.Peer]bool),
+ }).init(opts...)
+}
+
+// 典型的 “把不同参数类型的函数包装成为相同参数类型的函数”
+
+// WithHashFunc allows a custom hash function to be specified.
+// The default Hasher hash func is crc32.ChecksumIEEE.
+func WithHashFunc(hashFunc Hasher) Balancer.Opt {
+ return func(balancer Balancer.Balancer) {
+ if l, ok := balancer.(*HashKetama); ok {
+ l.hasher = hashFunc
+ }
+ }
+}
+
+// WithReplica allows a custom replica number to be specified.
+// The default replica number is 32.
+func WithReplica(replica int) Balancer.Opt {
+ return func(balancer Balancer.Balancer) {
+ if l, ok := balancer.(*HashKetama); ok {
+ l.replica = replica
+ }
+ }
+}
+
+// 让 HashKetama 指针穿过一系列的Opt函数
+func (s *HashKetama) init(opts ...Balancer.Opt) *HashKetama {
+ for _, opt := range opts {
+ opt(s)
+ }
+ return s
+}
+
+// Balancer.Factor本质是 string 类型
+// 调用Factor()转化为string 类型
+// 让 HashKetama实现了Balancer.Balancer接口是一个具体的负载均衡器
+// 所有的HashKetama都会接收类型为Balancer.Factor的实例,Balancer.Factor的实例
+func (s *HashKetama) Next(factor Balancer.Factor) (next Balancer.Peer, c Balancer.Constrainable) {
+ var hash uint32
+ // 生成哈希code
+ if h, ok := factor.(Balancer.FactorHashable); ok {
+ // 如果传入的是具体的实现了Balancer.FactorHashable接口的类
+ // 那么肯定实现了具体的HashCode()函数,调用就ok了
+ hash = h.HashCode()
+ } else {
+ // 如果只是传入了实现了父类接口的类的实例
+ // 调用hasher 处理父类实例
+ // factor.Factor() 把请求"https://abc.local/user/profile"
+ hash = s.hasher([]byte(factor.Factor()))
+ // s.hasher([]byte(factor.Factor()))本质是 crc32.ChecksumIEEE()函数处理得到的[]byte类型的string
+ // 所以重点是crc32.ChecksumIEEE()如何把[]byte转化wei hash code 的
+ // 哈希Hash,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。
+ // 不定长输入-->哈希函数-->定长的散列值
+ // 哈希算法的本质是对原数据的有损压缩
+ /* CRC检验原理实际上就是在一个p位二进制数据序列之后附加一个r位二进制检验码(序列),
+ 从而构成一个总长为n=p+r位的二进制序列;附加在数据序列之后的这个检验码与数据序列的内容之间存在着某种特定的关系。
+ 如果因干扰等原因使数据序列中的某一位或某些位发生错误,这种特定关系就会被破坏。因此,通过检查这一关系,就可以实现对数据正确性的检验
+ 注:仅用循环冗余检验 CRC 差错检测技术只能做到无差错接受(只是非常近似的认为是无差错的),并不能保证可靠传输
+ */
+ }
+
+ // 根据具体的策略得到下标
+ next = s.miniNext(hash)
+ if next != nil {
+ if fc, ok := factor.(Balancer.FactorComparable); ok {
+ next, c, _ = fc.ConstrainedBy(next)
+ } else if nested, ok := next.(Balancer.BalancerLite); ok {
+ next, c = nested.Next(factor)
+ }
+ }
+
+ return
+}
+
+// 已经有存储着一些哈希数值的切片
+// 产生哈希数值
+// 在切片中找到大于等于得到的哈希数值的元素
+// 该元素作为map的key一定可以找到一个节点
+
+func (s *HashKetama) miniNext(hash uint32) (next Balancer.Peer) {
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ // 得到的hashcode 去和 hashRing[i]比较
+ // sort.Search()二分查找 本质: 找到满足条件的最小的索引
+ /*
+ //golang 官方的二分写法 (学习一波)
+
+ func Search(n int, f func(int) bool) int {
+ // Define f(-1) == false and f(n) == true.
+ // Invariant: f(i-1) == false, f(j) == true.
+ i, j := 0, n
+ for i < j {
+ // avoid overflow when computing h
+ // 右移一位 相当于除以2
+ h := int(uint(i+j) >> 1)
+ // i ≤ h < j
+ if !f(h) {
+ i = h + 1 // preserves f(i-1) == false
+ } else {
+ j = h // preserves f(j) == true
+ }
+ }
+ // i == j, f(i-1) == false, and f(j) (= f(i)) == true => answer is i.
+ return i
+ }
+ */
+
+ // 在s.hashRing找到大于等于hash的hashRing的下标
+ ix := sort.Search(len(s.hashRing), func(i int) bool {
+ return s.hashRing[i] >= hash
+ })
+
+ // 当这个下标是最后一个下标时,相当于没有找到
+ if ix == len(s.hashRing) {
+ ix = 0
+ }
+
+ // 如果没有找到就返回s.hashRing的第一个元素
+ hashValue := s.hashRing[ix]
+
+ // s.keys 存储 peers 每一个 peers 都有一个hashValue 对应
+ // hashcode 对应 hashValue (被Slice存储)
+ // hashValue 对应节点 peer (被Map存储)
+ if p, ok := s.keys[hashValue]; ok {
+ if _, ok = s.peers[p]; ok {
+ next = p
+ }
+ }
+
+ return
+}
+
+/*
+在 Add 实现中建立了 hashRing 结构,
+它虽然是环形,但是是以数组和下标取模的方式来达成的。
+此外,keys 这个 map 解决从 peer 的 hash 值到 peer 的映射关系,今后(在 Next 中)就可以通过从 hashRing 上 pick 出一个 point 之后立即地获得相应的 peer.
+在 Next 中主要是在做 factor 的 hash 值计算,计算的结果在 hashRing 上映射为一个点 pt,如果不是恰好有一个 peer 被命中的话,就向后扫描离 pt 最近的 peer。
+
+*/
+func (s *HashKetama) Count() int {
+ s.rw.RLock()
+ defer s.rw.RUnlock()
+ return len(s.peers)
+}
+
+func (s *HashKetama) Add(peers ...Balancer.Peer) {
+ s.rw.Lock()
+ defer s.rw.Unlock()
+
+ for _, p := range peers {
+ s.peers[p] = true
+ for i := 0; i < s.replica; i++ {
+ hash := s.hasher(s.peerToBinaryID(p, i))
+ s.hashRing = append(s.hashRing, hash)
+ s.keys[hash] = p
+ }
+ }
+
+ sort.Slice(s.hashRing, func(i, j int) bool {
+ return s.hashRing[i] < s.hashRing[j]
+ })
+}
+
+func (s *HashKetama) peerToBinaryID(p Balancer.Peer, replica int) []byte {
+ str := fmt.Sprintf("%v-%05d", p, replica)
+ return []byte(str)
+}
+
+func (s *HashKetama) Remove(peer Balancer.Peer) {
+ s.rw.Lock()
+ defer s.rw.Unlock()
+
+ if _, ok := s.peers[peer]; ok {
+ delete(s.peers, peer)
+ }
+
+ var keys []uint32
+ var km = make(map[uint32]bool)
+ for i, p := range s.keys {
+ if p == peer {
+ keys = append(keys, i)
+ km[i] = true
+ }
+ }
+
+ for _, key := range keys {
+ delete(s.keys, key)
+ }
+
+ var vn []uint32
+ for _, x := range s.hashRing {
+ if _, ok := km[x]; !ok {
+ vn = append(vn, x)
+ }
+ }
+ s.hashRing = vn
+}
+
+func (s *HashKetama) Clear() {
+ s.rw.Lock()
+ defer s.rw.Unlock()
+ s.hashRing = nil
+ s.keys = make(map[uint32]Balancer.Peer)
+ s.peers = make(map[Balancer.Peer]bool)
+}
+
+```
+
+```go
+func TestHash(t *testing.T) {
+
+ h := int(uint(0+3) >> 1)
+ fmt.Print(h)
+
+}
+
+type ConcretePeer string
+
+func (s ConcretePeer) String() string {
+ return string(s)
+}
+
+var factors = []Balancer.FactorString{
+ "https://abc.local/user/profile",
+ "https://abc.local/admin/",
+ "https://abc.local/shop/item/1",
+ "https://abc.local/post/35719",
+}
+
+func TestHash1(t *testing.T) {
+ lb := New()
+ lb.Add(
+ ConcretePeer("172.16.0.7:3500"),
+ ConcretePeer("172.16.0.8:3500"),
+ ConcretePeer("172.16.0.9:3500"),
+ )
+ // 记录某个节点被调用的次数
+ sum := make(map[Balancer.Peer]int)
+ // 记录某个具体的节点被哪些ip地址访问过
+ hits := make(map[Balancer.Peer]map[Balancer.Factor]bool)
+ // 模拟不同时间三个ip 地址对服务端发起多次的请求
+ for i := 0; i < 300; i++ {
+ // ip 地址依次对服务端发起多次的请求
+ factor := factors[i%len(factors)]
+ // 把 ip 地址传进去得到具体的节点
+ peer, _ := lb.Next(factor)
+
+ sum[peer]++
+
+ if ps, ok := hits[peer]; ok {
+ // 判断该ip 地址是否之前访问过该节点
+ if _, ok := ps[factor]; !ok {
+ // 如果没有访问过则标志为访问过
+ ps[factor] = true
+ }
+ } else {
+ // 如过该节点对应的 (访问过该节点的map不存在)证明该节点一次都没有被访问过
+ // 那么创建map来 存储该ip地址已经被访问过
+ hits[peer] = make(map[Balancer.Factor]bool)
+ hits[peer][factor] = true
+ }
+ }
+
+ // results
+ total := 0
+ for _, v := range sum {
+ total += v
+ }
+
+ for p, v := range sum {
+ var keys []string
+ // p为节点
+ for fs := range hits[p] {
+ // 打印出每个节点被哪些ip地址访问过
+ if kk, ok := fs.(interface{ String() string }); ok {
+ keys = append(keys, kk.String())
+ } else {
+ keys = append(keys, fs.Factor())
+ }
+ }
+ fmt.Printf("%v\nis be invoked %v nums\nis be accessed by these [%v]\n", p, v, strings.Join(keys, ","))
+ }
+
+ lb.Clear()
+}
+
+func TestHash_M1(t *testing.T) {
+ lb := New()
+ lb.Add(
+ ConcretePeer("172.16.0.7:3500"),
+ ConcretePeer("172.16.0.8:3500"),
+ ConcretePeer("172.16.0.9:3500"),
+ )
+
+ var wg sync.WaitGroup
+ var rw sync.RWMutex
+ sum := make(map[Balancer.Peer]int)
+
+ const threads = 8
+ wg.Add(threads)
+
+ // 这个是最接近业务场景的因为是并发的请求
+ for x := 0; x < threads; x++ {
+ go func(xi int) {
+ defer wg.Done()
+ for i := 0; i < 600; i++ {
+ p, c := lb.Next(factors[i%3])
+ adder(p, c, sum, &rw)
+ }
+ }(x)
+ }
+ wg.Wait()
+ // results
+ for k, v := range sum {
+ fmt.Printf("Peer:%v InvokeNum:%v\n", k, v)
+ }
+}
+
+func TestHash2(t *testing.T) {
+ lb := New(
+ WithHashFunc(crc32.ChecksumIEEE),
+ WithReplica(16),
+ )
+ lb.Add(
+ ConcretePeer("172.16.0.7:3500"),
+ ConcretePeer("172.16.0.8:3500"),
+ ConcretePeer("172.16.0.9:3500"),
+ )
+ sum := make(map[Balancer.Peer]int)
+ hits := make(map[Balancer.Peer]map[Balancer.Factor]bool)
+
+ for i := 0; i < 300; i++ {
+ factor := factors[i%len(factors)]
+ peer, _ := lb.Next(factor)
+
+ sum[peer]++
+ if ps, ok := hits[peer]; ok {
+ if _, ok := ps[factor]; !ok {
+ ps[factor] = true
+ }
+ } else {
+ hits[peer] = make(map[Balancer.Factor]bool)
+ hits[peer][factor] = true
+ }
+ }
+ lb.Clear()
+}
+
+func adder(key Balancer.Peer, c Balancer.Constrainable, sum map[Balancer.Peer]int, rw *sync.RWMutex) {
+ rw.Lock()
+ defer rw.Unlock()
+ sum[key]++
+}
+
+
+```
+
+> 在早些年,没有区分微服务和单体应用的那些年,Hash 算法的负载均衡常常被当作神器,因为 session 保持经常是一个服务无法横向增长的关键因素,(这里就涉及到 Session 同步使得服务器可以横向扩展)而针对用户的 session-id 的 hash 值进行调度分配时,就能保证同样 session-id 的来源用户的 session 总是落到某一确定的后端服务器,从而确保了其 session 总是有效的。在 Hash 算法被扩展之后,很明显,可以用 客户端 IP 值,主机名,url 或者无论什么想得到的东西去做 hash 计算,只要得到了 hashCode,就可以应用 Hash 算法了。而像诸如客户端 IP,客户端主机名之类的标识由于其相同的 hashCode 的原因,所以对应的后端 peer 也能保持一致,这就是 session 年代 hash 算法显得重要的原因。
+
+> session 同步
+
+web 集群时 session 同步的 3 种方法
+
+1.利用数据库同步
+
+**利用数据库同步 session**用一个低端电脑建个数据库专门存放 web 服务器的 session,或者,把这个专门的数据库建在文件服务器上,用户访问 web 服务器时,会去这个专门的数据库 check 一下 session 的情况,以达到 session 同步的目的。
+
+把存放 session 的表和其他数据库表放在一起,如果 mysql 也做了集群了话,每个 mysql 节点都要有这张表,并且这张 session 表的数据表要实时同步。
+
+结论: 用数据库来同步 session,会加大数据库的负担,数据库本来就是容易产生瓶颈的地方,如果把 session 还放到数据库里面,无疑是雪上加霜。上面的二种方法,第一点方法较好,把放 session 的表独立开来,减轻了真正数据库的负担
+
+2.利用 cookie 同步 session
+
+**把 session 存在 cookie 里面里面** : session 是文件的形势存放在服务器端的,cookie 是文件的形势存在客户端的,怎么实现同步呢?方法很简单,就是把用户访问页面产生的 session 放到 cookie 里面,就是以 cookie 为中转站。访问 web 服务器 A,产生了 session 把它放到 cookie 里面了,访问被分配到 web 服务器 B,这个时候,web 服务器 B 先判断服务器有没有这个 session,如果没有,在去看看客户端的 cookie 里面有没有这个 session,如果也没有,说明 session 真的不存,如果 cookie 里面有,就把 cookie 里面的 sessoin 同步到 web 服务器 B,这样就可以实现 session 的同步了。
+
+说明:这种方法实现起来简单,方便,也不会加大数据库的负担,但是如果客户端把 cookie 禁掉了的话,那么 session 就无从同步了,这样会给网站带来损失;cookie 的安全性不高,虽然它已经加了密,但是还是可以伪造的。
+
+3.利用 memcache 同步 session(内存缓冲)
+
+**利用 memcache 同步 session** :memcache 可以做分布式,如果没有这功能,他也不能用来做 session 同步。他可以把 web 服务器中的内存组合起来,成为一个"内存池",不管是哪个服务器产生的 sessoin 都可以放到这个"内存池"中,其他的都可以使用。
+
+优点:以这种方式来同步 session,不会加大数据库的负担,并且安全性比用 cookie 大大的提高,把 session 放到内存里面,比从文件中读取要快很多。
+
+缺点:memcache 把内存分成很多种规格的存储块,有块就有大小,这种方式也就决定了,memcache 不能完全利用内存,会产生内存碎片,如果存储块不足,还会产生内存溢出。
+
+第三种方法,个人觉得第三种方法是最好的,推荐大家使用
+
+## 5. 数据存储
+
+> 公司存在的价值在于流量,流量需要数据,可想而知数据的存储,数据的高可用可说是公司的灵魂。那么改善数据的存储都有哪些手段或方法呢
+
+### 数据主从复制
+
+1.两个数据库存储一样的数据。其原理为当应用程序 A 发送更新命令到主服务器的时候,数据库会将这条命令同步记录到 Binlog 中,然后其他线程会从 Binlog 中读取并通过远程通讯的方式复制到另外服务器。服务器收到这更新日志后加入到自己 Relay Log 中,然后 SQL 执行线程从 Relay Log 中读取次日志并在本地数据库执行一遍,从而实现主从数据库同样的数据。详细步骤:1.master 将“改变/变化“记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);2.slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);3.slave 重做中继日志中的事件,将改变反映它自己的数据。
+
+2.MySQL 的 Binlog 日志是一种二进制格式的日志,Binlog 记录所有的 DDL 和 DML 语句(除了数据查询语句 SELECT、SHOW 等),以 Event 的形式记录,同时记录语句执行时间。Binlog 的用途:1.主从复制 想要做多机备份的业务,可以去监听当前写库的 Binlog 日志,同步写库的所有更改。2.数据恢复。因为 Binlog 详细记录了所有修改数据的 SQL,当某一时刻的数据误操作而导致出问题,或者数据库宕机数据丢失,那么可以根据 Binlog 来回放历史数据。 3.这种复制是: 某一台 Mysql 主机的数据复制到其它 Mysql 的主机(slaves)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。
+
+3..mysql 支持的复制类型:(1):基于语句的复制: 在主服务器上执行的 SQL 语句,在从服务器上执行同样的语句。MySQL 默认采用基于语句的复制,效率比较高。一旦发现没法精确复制时, 会自动选着基于行的复制。(2):基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从 mysql5.0 开始支持 (3.)混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
diff --git a/_posts/2022-10-14-test-markdown.md b/_posts/2022-10-14-test-markdown.md
new file mode 100644
index 000000000000..be1eeb6330cb
--- /dev/null
+++ b/_posts/2022-10-14-test-markdown.md
@@ -0,0 +1,149 @@
+---
+layout: post
+title: 安装 zookeeper (ubuntu 20.04)
+subtitle: 并运行单机的实例进行验证
+tags: [ubuntu zookeeper]
+---
+
+#### 1、安装 JDK
+
+```shelll
+$ sudo apt-get install openjdk-8-jre
+```
+
+#### 2、下载 zookeeper
+
+在官网下载
+or
+
+```shelll
+$ wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
+```
+
+#### 3、进入有 zookeeper-3.4.13.tar.gz 压缩包的目录,然后解压
+
+```shelll
+$ tar -xvf zookeeper-3.4.13.tar.gz
+```
+
+#### 4、移动解压的文件夹到安装目录
+
+安装的目录可以为任意,此处安装在/usr/local/zookeeper/ ,如果在 usr 目录下面没有 zookeeper 文件夹,需要先创建文件夹
+创建文件夹
+
+```shelll
+$ cd /usr/local
+$ mkdir zookeeper
+```
+
+然后回到有解压后的 zookeeper-3.4.13 文件夹的目录后的移动解压后的文件夹
+
+```shelll
+$ sudo mv zookeeper-3.4.13 /usr/local/zookeeper
+```
+
+#### 5、为 zookeeper 创建软链接
+
+为了方便以后 zookeeper 的版本更新,我们安装 zookeeper 的时候可以在同级目录下创建一个不带版本号的软链接,然后将其指向带 zookeeper 的真正目录
+即创建一个名为/usr/local/zookeeper/apache-zookeeper 的软链接向/usr/local/zookeeper/zookeeper-3.4.13,以后更新版本的话,只需要修改软链接的指向,而我们配置的环境变量都不需要做任何更改
+
+```shelll
+$ ln -s /usr/local/zookeeper/zookeeper-3.4.13 /usr/local/zookeeper/apache-zookeeper
+```
+
+#### 6、修改 PATH
+
+```shelll
+$ sudo vim /etc/profile
+```
+
+如果在这里报错,大概率是/etc/profile 文件只允许读,不允许用户写入,那么`sudo chmod 777 /etc/profile` `vim /etc/profile` 按 i 插入,按 Esc 退出编辑 ,按 Shift+:输入指令 例如:`:wq 保存文件并退出vi`
+
+新增下面两行
+
+```shelll
+# 此处使用刚刚创建的软链接
+$ export ZK_HOME=/usr/local/zookeeper/apache-zookeeper
+$ export PATH=$ZK_HOME/bin:$PATH
+```
+
+然后让刚才修改的 path 生效
+
+```shelll
+$ source /etc/profil
+```
+
+复制代码此时,zookeeper 的安装完成,启动一个单机版的测试一下
+
+#### 7、修改 zoo.cfg 文件
+
+zookeeper 启动时候,会读取 conf 文件夹下的 zoo.cfg 作为配置文件,因此,我们可以将源码提供的示例配置文件复制一个,做一些修改
+
+```shelll
+# 进入配置文件目录
+$ cd /usr/local/zookeeper/apache-zookeeper/conf
+
+# 复制示例配置文件
+cp zoo_sample.cfg zoo.cfg
+
+# 修改 zoo.cfg 配置文件
+vim zoo.cfg
+```
+
+修改数据存放位置 dataDir=/usr/local/zookeeper/data
+
+```shelll
+# The number of milliseconds of each tick
+tickTime=2000
+# The number of ticks that the initial
+# synchronization phase can take
+initLimit=10
+# The number of ticks that can pass between
+# sending a request and getting an acknowledgement
+syncLimit=5
+# the directory where the snapshot is stored.
+# do not use /tmp for storage, /tmp here is just
+# example sakes.
+
+
+# 只需要修改此处为zookeeper数据存放位置
+dataDir=/usr/local/zookeeper/data
+# the port at which the clients will connect
+clientPort=2181
+# the maximum number of client connections.
+# increase this if you need to handle more clients
+#maxClientCnxns=60
+#
+# Be sure to read the maintenance section of the
+# administrator guide before turning on autopurge.
+#
+# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
+#
+# The number of snapshots to retain in dataDir
+#autopurge.snapRetainCount=3
+# Purge task interval in hours
+# Set to "0" to disable auto purge feature
+#autopurge.purgeInterval=1
+
+```
+
+#### 8、开始运行并测试
+
+```shelll
+# 进入bin目录
+$ cd /usr/local/zookeeper/apache-zookeeper/bin
+
+# 执行启动命令
+$ ./zkServer.sh start
+
+ZooKeeper JMX enabled by default
+Using config: /usr/local/zookeeper/apache-zookeeper/bin/../conf/zoo.cfg
+Starting zookeeper ... STARTED
+
+# 查看状态
+$ ./zkServer.sh status
+ZooKeeper JMX enabled by default
+Using config: /usr/local/zookeeper/apache-zookeeper/bin/../conf/zoo.cfg
+Mode: standalone
+
+```
diff --git a/_posts/2022-10-15-test-markdown.md b/_posts/2022-10-15-test-markdown.md
new file mode 100644
index 000000000000..bbecb630d2ab
--- /dev/null
+++ b/_posts/2022-10-15-test-markdown.md
@@ -0,0 +1,246 @@
+---
+layout: post
+title: 分布式系统中的一致性问题
+subtitle: Zookeeper关于一致性问题的解决方案
+tags: [分布式]
+---
+
+# 分布式系统数据同步
+
+## 分布式系统中的一致性问题
+
+设计一个分布式系统必定会遇到一个问题—— 因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡 。这就是著名的 CAP 定理。
+
+简单来说:“当在消息的传播(散布)过程中,某个同学 A 已经知道了这个消息,但是抓到一个同学 B,问他们的情况,但这个同学回答不知道,那么说明整个班级系统出现了数据不一致的问题(因为 A 已经知道这个消息了)。而如果 B 他直接不回答(B 的内心:不可以告诉奥,因为我还不确定着这个消息是否被班级中的所有人知道,一个不被所有人知道的消息,我就不可以告诉),因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
+
+"系统的可用性问题":这里的可用性问题是指,当数据没有被同步到所有的机器上的时候,对于外界的请求,系统是不做出响应的。"这个就是 Eureka 的处理方式,它保证了 AP(可用性)
+为了解决数据一致性问题,下面要讲的具体是 ZooKeeper 的处理方式,它保证了 CP(数据一致性)出现了很多的一致性协议和算法。 2PC(两阶段提交),3PC(三阶段提交),Paxos 算法等等。
+
+### 1.一致性协议的目的(提供了消息传递的可靠通道)
+
+思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个家伙给劫持篡改了呢,对吧?
+
+这个时候就引申出一个概念—— 拜占庭将军问题 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的, 所以所有的一致性算法的 必要前提 就是安全可靠的消息通道。**
+
+### 2.分布式事务存在的问题?
+
+业务场景: "1.用户下订单--(发消息)--> 2.给该用户的账户增加积分"
+如果功能 1 仅仅是发送一个消息给功能 2,也不需要 2 给它回复,那么 1 就完全不知道 2 到底有没有收到消息,那么增加一个回复的过程,那么当积分系统收到消息后返回给订单系统一个 Response ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。所以我们所需要解决的是在分布式系统中,整个调用链中,我们所有服务的数据处理要么都成功要么都失败,即所有服务的 原子性问题 。
+
+### 3.具体的一致性协议--2PC(phase-commit)
+
+两阶段提交是一种保证分布式系统数据一致性的协议,现在很多数据库都是采用的两阶段提交协议来完成 分布式事务 的处理。
+在两阶段提交中,主要涉及到两个角色,分别是协调者和参与者。
+第一阶段:当要执行一个分布式事务的时候,事务发起者首先向协调者发起事务请求,然后协调者会给所有参与者发送 prepare 请求(其中包括事务内容)告诉参与者们需要执行事务了,如果能执行我发的事务内容那么就先执行但不提交,执行后请给我回复。然后参与者收到 prepare 消息后,他们会开始执行事务(但不提交),并将 Undo 和 Redo 信息记入事务日志中,之后参与者就向协调者反馈是否准备好了。第二阶段:第二阶段主要是协调者根据参与者反馈的情况来决定接下来是否可以进行事务的提交操作,即提交事务或者回滚事务。
+比如这个时候 所有的参与者 都返回了准备好了的消息,这个时候就进行事务的提交,协调者此时会给所有的参与者发送 Commit 请求 ,当参与者收到 Commit 请求的时候会执行前面执行的事务的 提交操作 ,提交完毕之后将给协调者发送提交成功的响应。
+而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 回滚事务的 rollback 请求,参与者收到之后将会 回滚它在第一阶段所做的事务处理 ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
+
+事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。:
+
+- 单点故障问题,如果协调者挂了那么整个系统都处于不可用的状态了。
+- 阻塞问题,即当协调者发送 prepare 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
+
+- 数据不一致问题,比如当第二阶段,协调者只发送了一部分的 commit 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
+
+### 4.具体的一致性协议--3PC(phase-commit)
+
+**CanCommit 阶段**:
+协调者向所有参与者发送 CanCommit 请求参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
+
+**PreCommit 阶段**:
+协调者根据参与者返回的响应来决定是否可以进行下面的 PreCommit 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 PreCommit 预提交请求,参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中 ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 任何一个 NO 的信息,或者 在一定时间内 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
+
+**DoCommit 阶段**:
+这个阶段其实和 2PC 的第二阶段差不多,如果协调者收到了所有参与者在 PreCommit 阶段的 YES 响应,那么协调者将会给所有参与者发送 DoCommit 请求,参与者收到 `DoCommit` 请求后则会进行事务的提交工作,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 PreCommit 阶段 收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应 ,那么就会进行中断请求的发送,参与者收到中断请求后则会 通过上面记录的回滚日志 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
+
+3PC 在很多地方进行了超时中断的处理,比如协调者在指定时间内为收到全部的确认消息则进行事务中断的处理,这样能 减少同步阻塞的时间 。还有需要注意的是,3PC 在 DoCommit 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交。为什么这么做呢?是因为这个时候我们肯定保证了在第一阶段所有的协调者全部返回了可以执行事务的响应,这个时候我们有理由相信其他系统都能进行事务的执行和提交,所以不管协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
+
+### 补充:为什么需要保持数据一致?
+
+而为什么要去解决数据一致性的问题?想想,如果一个秒杀系统将服务拆分成了下订单和加积分服务,这两个服务部署在不同的机器上了,万一在消息的传播过程中积分系统宕机了,总不能这边下了订单却没加积分吧?总得保证两边的数据需要一致吧?
+
+### 补充:分布式和集群的区别
+
+一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 一样 提供秒杀服务,这个时候就是 Cluster 集群 。但是!!!
+把一个秒杀服务 拆分成多个子服务 ,比如创建订单服务,增加积分服务,扣优惠券服务等等,然后我将这些子服务都部署在不同的服务器上 ,这个时候就是 Distributed 分布式 。
+
+### 5.`Paxos` 算法
+
+Paxos 算法是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一,其解决的问题就是在分布式系统中如何就某个值(决议)达成一致 。
+在 Paxos 中主要有三个角色,分别为 Proposer 提案者、Acceptor 表决者、Learner 学习者。Paxos 算法和 2PC 一样,也有两个阶段,分别为 Prepare 和 accept 阶段。
+
+**prepare 阶段(试探阶段)**
+
+> 每个 Proposer 提案者把全局唯一且自增的提案编号发送给所有的表决者
+> Proposer 提案者:负责提出 proposal,每个提案者在提出提案时都会首先获取到一个 具有全局唯一性的、递增的提案编号 N,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在第一阶段是只将提案编号发送给所有的表决者。
+> 每个 Acceptor 表决者接受(只接受提案 ID 比自己本地大的提案)某个 Proposer 提案者的提案后,记录该提案的 ID 到本地。
+> 每个 Acceptor 表决者批准提案的时候只返回最大编号的提案
+> Acceptor 表决者:每个表决者在 accept 某提案后,会将该提案编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个编号最大的提案,其编号假设为 maxN。每个表决者仅会 accept 编号大于自己本地 maxN 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 Proposer 。
+
+**accept 阶段**
+
+当一个提案被 Proposer 提出后,如果 Proposer 收到了超过半数的 Acceptor 的批准(Proposer 本身同意),那么此时 Proposer 会给所有的 Acceptor 发送真正的提案(可以理解为第一阶段为试探),这个时候 Proposer 就会发送提案的内容和提案编号。
+
+表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 accept 该提案(此时执行提案内容但不提交),随后将情况返回给 Proposer 。如果不满足则不回应或者返回 NO 。
+
+> acceptor 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要向未批准的 acceptor 发送提案内容和提案编号并让它无条件执行和提交,而对于前面已经批准过该提案的 acceptor 来说 仅仅需要发送该提案的编号 ,让 acceptor 执行提交就行了。
+> 而如果 Proposer 如果没有收到超过半数的 accept 那么它将会将 递增 该 Proposal 的编号,然后 重新进入 Prepare 阶段 。
+
+> 站在全局的角度去看:A 拿着一个 ID 去试探 B1、B2、B3、B4、B5 ,如果这个 ID 比 B1、B2、B3、B4、B5 存储的 ID 都小,在试探阶段首先在试探阶段 B1、B2、B3、B4、B5 中的 ID 不会被更新。表决阶段则不会通过。如果 这个 ID 大于 B1、B2、B3 ,那么首先在试探阶段 B1、B2、B3 中间最大的 ID 被该 ID 更新,然后在表决阶段通过,B1、B2、B3、B4、B5 的最大 ID 都被更新为该 ID,且更新内容。
+
+> 因为从一开始,保证了 B1、B2、B3、B4、B5 被更新的 ID 都是大于等于他们原来的 ID
+> 比如说,此时提案者 P1 提出一个方案 M1,完成了 Prepare 阶段的工作,这个时候 acceptor 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 Prepare 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 acceptor 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 Prepare 阶段,然后 acceptor ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 Prepare 阶段
+> 解决办法,保持提案者之间的互斥。
+
+# Zookeeper 对于一致性问题的解决
+
+总的来说就是:如何协调各个分布式组件,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统
+
+## `Zookeeper` 架构
+
+作为一个优秀高效且可靠的分布式协调框架,ZooKeeper 在解决分布式数据一致性问题时并没有直接使用 Paxos ,而是专门定制了一致性协议叫做 ZAB(ZooKeeper Automic Broadcast) 原子广播协议,该协议能够很好地支持 崩溃恢复 。
+
+## `ZAB` 中的三个角色
+
+和介绍 Paxos 一样,在介绍 ZAB 协议之前,我们首先来了解一下在 ZAB 中三个主要的角色,Leader 领导者、Follower 跟随者、Observer 观察者 。
+
+Leader :集群中 唯一的写请求处理者 ,能够发起投票(投票也是为了进行写请求)。
+
+Follower:能够接收客户端的请求,如果是读请求则可以自己处理,如果是写请求则要转发给 `Leader` 。在选举过程中会参与投票,有选举权和被选举权 。
+
+Observer :就是没有选举权和被选举权的 Follower 。
+
+在 ZAB 协议中对 zkServer(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 消息广播 和 崩溃恢复 。
+消息广播模式
+说白了就是 ZAB 协议是如何处理写请求的,上面我们不是说只有 Leader 能处理写请求嘛?那么我们的 Follower 和 Observer 是不是也需要 同步更新数据 呢?总不能数据只在 Leader 中更新了,其他角色都没有得到更新吧?
+
+#### Leader:
+
+第一步:Leader 将写请求 广播:
+肯定需要 Leader 将写请求 广播 出去呀,让 Leader 问问 Followers 是否同意更新,如果超过半数以上的同意那么就进行 Follower 和 Observer 的更新。
+
+> 要让 Follower 和 Observer 保证顺序性 。何为顺序性,比如我现在有一个写请求 A,此时 Leader 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 Follower F1 因为网络原因没有收到,而 Leader 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 产生数据不一致问题 。
+
+所以在 Leader 这端,它为每个其他的 zkServer 准备了一个 队列 ,采用先进先出的方式发送消息。由于协议是 **通过 TCP **来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
+除此之外,在 ZAB 中还定义了一个 全局单调递增的事务 ID ZXID ,它是一个 64 位 long 型,其中高 32 位表示 epoch 年代,低 32 位表示事务 id。epoch 是会根据 Leader 的变化而变化的,当一个 Leader 挂了,新的 Leader 上位的时候,年代(epoch)就变了。而低 32 位可以简单理解为递增的事务 id。
+
+定义这个的原因也是为了顺序性,每个 proposal 在 Leader 中生成后需要 通过其 ZXID 来进行排序 ,才能得到处理
+崩溃恢复模式
+
+##### Leader 选举算法
+
+说到崩溃恢复我们首先要提到 ZAB 中的 Leader 选举算法,当系统出现崩溃影响最大应该是 Leader 的崩溃,因为我们只有一个 Leader ,所以当 Leader 出现问题的时候我们势必需要重新选举 Leader 。
+Leader 选举可以分为两个不同的阶段,第一个是我们提到的 Leader 宕机需要重新选举,第二则是当 Zookeeper 启动时需要进行系统的 Leader 初始化选举。下面我先来介绍一下 ZAB 是如何进行初始化选举的。
+
+**Leader 宕机下面的重新选举:**
+
+当集群中有机器挂了,我们整个集群如何保证数据一致性?
+如果只是 Follower 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 Leader 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
+如果 Leader 挂了那就麻烦了,我们肯定需要先暂停服务变为 Looking 状态然后进行 Leader 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 **确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交** 和 **跳过那些已经被丢弃的提案**
+
+**确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交:**
+假设 Leader (server2) 发送 commit 请求,他发送给了 server3,然后要发给 server1 的时候突然挂了。这个时候重新选举的时候我们如果把 server1 作为 Leader 的话,那么肯定会产生数据不一致性,因为 server3 肯定会提交刚刚 server2 发送的 commit 请求的提案,而 server1 根本没收到所以会丢弃。,这个时候 server1 已经不可能成为 Leader 了,因为 server1 和 server3 进行投票选举的时候会比较 ZXID ,而此时 server3 的 ZXID 肯定比 server1 的大了。
+
+> Server2(leader) 发送 commit 请求给 Server1(成功) 发送 commit 请求给 Server3(失败)
+
+**跳过那些已经被丢弃的提案:**
+假设 Leader (server2) 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 Follower 要 commit 的请求,却在这个时候挂了,此时肯定要重新进行 Leader 的选举,比如说此时选 server1 为 Leader (这无所谓)。但是过了一会,这个 挂掉的 Leader 又重新恢复了 ,此时它肯定会作为 Follower 的身份进入集群中,需要注意的是刚刚 server2 已经同意提交了提案 N1,但其他 server 并没有收到它的 commit 信息,所以其他 server 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 该提案 N1 最终需要被抛弃掉 。
+
+> Server2(leader) 发送 commit 请求给 Server1(失败) 发送 commit 请求给 Server3(失败)
+> Server1(leader) Server2 变为(follower)但是之前的 commit 请求一次都没有发送成功,那么丢弃 commit 请求
+
+**Zookeeper 启动时的选举:**
+假设我们集群中有 3 台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 server1 ,它会首先 投票给自己 ,投票内容为服务器的 myid 和 ZXID ,因为初始化所以 ZXID 都为 0,此时 server1 发出的投票为 (1,0)。但此时 server1 的投票仅为 1,所以不能作为 Leader ,此时还在选举阶段所以整个集群处于 Looking 状态。
+接着 server2 启动了,它首先也会将投票选给自己(2,0),并将投票信息广播出去(server1 也会,只是它那时没有其他的服务器了),server1 在收到 server2 的投票信息后会将投票信息与自己的作比较。首先它会比较 ZXID ,ZXID 大的优先为 Leader,如果相同则比较 myid,myid 大的优先作为 Leader。所以此时 server1 发现 server2 更适合做 Leader,它就会将自己的投票信息更改为(2,0)然后再广播出去,之后 server2 收到之后发现和自己的一样无需做更改,并且自己的 投票已经超过半数 ,则 确定 server2 为 Leader,server1 也会将自己服务器设置为 Following 变为 Follower。整个服务器就从 Looking 变为了正常状态。
+当 server3 启动发现集群没有处于 Looking 状态时,它会直接以 Follower 的身份加入集群。
+还是前面三个 server 的例子,如果在整个集群运行的过程中 server2 挂了,那么整个集群会如何重新选举 Leader 呢?其实和初始化选举差不多。
+首先毫无疑问的是剩下的两个 Follower 会将自己的状态 从 Following 变为 Looking 状态 ,然后每个 server 会向初始化投票一样首先给自己投票(这不过这里的 zxid 可能不是 0 了,这里为了方便随便取个数字)。
+假设 server1 给自己投票为(1,99),然后广播给其他 server,server3 首先也会给自己投票(3,95),然后也广播给其他 server。server1 和 server3 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(zxid 大的优先,如果相同那么就 myid 大的优先)。这个时候 server1 收到了 server3 的投票发现没自己的合适故不变,server3 收到 server1 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 server1 收到了发现自己的投票已经超过半数就把自己设为 Leader,server3 也随之变为 Follower。
+
+## Zookeeper 实战——集群管理,分布式锁,Master 选举
+
+### Zookeeper 的数据模型
+
+zookeeper 数据存储结构与标准的 Unix 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 zookeeper 中没有文件系统中目录与文件的概念,而是 使用了 znode 作为数据节点 。znode 是 zookeeper 中的最小数据单元,每个 znode 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
+每个 znode 都有自己所属的 节点类型 和 节点状态。
+其中节点类型可以分为 持久节点、持久顺序节点、临时节点 和 临时顺序节点。
+
+持久节点:一旦创建就一直存在,直到将其删除。
+持久顺序节点:一个父节点可以为其子节点 维护一个创建的先后顺序 ,这个顺序体现在 节点名称 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
+临时节点:临时节点的生命周期是与 客户端会话 绑定的,会话消失则节点消失 。临时节点 只能做叶子节点 ,不能创建子节点。
+临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
+节点状态中包含了很多节点的属性比如 czxid 、mzxid 等等,在 zookeeper 中是使用 Stat 这个类来维护的。下面我列举一些属性解释。
+
+czxid:Created ZXID,该数据节点被 创建 时的事务 ID。
+mzxid:Modified ZXID,节点 最后一次被更新时 的事务 ID。
+ctime:Created Time,该节点被创建的时间。
+mtime: Modified Time,该节点最后一次被修改的时间。
+version:节点的版本号。
+cversion:子节点 的版本号。
+aversion:节点的 ACL 版本号。
+ephemeralOwner:创建该节点的会话的 sessionID ,如果该节点为持久节点,该值为 0。
+dataLength:节点数据内容的长度。
+numChildre:该节点的子节点个数,如果为临时节点为 0。
+pzxid:该节点子节点列表最后一次被修改时的事务 ID,注意是子节点的 列表 ,不是内容。
+
+### Zookeeper 的会话机制
+
+我想这个对于后端开发的朋友肯定不陌生,不就是 session 吗?只不过 zk 客户端和服务端是通过 TCP 长连接 维持的会话机制,其实对于会话来说可以理解为 保持连接状态 。
+在 zookeeper 中,会话还有对应的事件,比如 CONNECTION_LOSS 连接丢失事件 、SESSION_MOVED 会话转移事件 、SESSION_EXPIRED 会话超时失效事件 。
+
+### Zookeeper 的 ACL
+
+ACL 为 Access Control Lists ,它是一种权限控制。在 zookeeper 中定义了 5 种权限,它们分别为:
+
+CREATE :创建子节点的权限。
+READ:获取节点数据和子节点列表的权限。
+WRITE:更新节点数据的权限。
+DELETE:删除子节点的权限。
+ADMIN:设置节点 ACL 的权限。
+
+### Zookeeper 的 Watcher 机制
+
+Watcher 为事件监听器,是 zk 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 注册 指定的 watcher ,当服务端符合了 watcher 的某些事件或要求则会 向客户端发送事件通知 ,客户端收到通知后找到自己定义的 Watcher 然后 执行相应的回调方法 。
+
+- 客户端生成一个`Watcher`对象实例,该`Watcher`对象实例被客户端发送给后端,并被后端保存,当某种情况下,服务端触发该方法?
+
+```go
+type Client interface {
+ Create()Watcher
+ SendWatcher()Watcher
+}
+
+type Backend interface{
+ Accenpt(Watcher)
+ Invoke()
+ // Invoke 里面调用Watcher.Excute()
+}
+
+type Watcher interface{
+ Excute()
+}
+
+```
+
+### Zookeeper 的实战场景之--master
+
+Zookeeper 的强一致性,能够很好地在保证 在高并发的情况下保证节点创建的全局唯一性 (即无法重复创建同样的节点)。
+
+利用这个特性,我们可以 让多个客户端创建一个指定的节点 ,创建成功的就是 master。如果这个 master 挂了,master 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 watcher 机制,让其他不是 master 的节点监听节点的状态,子节点个数变了就代表 master 挂了,这个时候我们 触发回调函数进行重新选举 ,总的来说,我们可以完全 利用 临时节点、节点状态 和 watcher 来实现选主的功能。临时节点主要用来选举,节点状态和 watcher 可以用来判断 master 的活性和进行重新选举。
+
+### Zookeeper 的实战场景之--分布式锁
+
+分布式锁的实现方式有很多种,比如 Redis 、数据库 、zookeeper 等。个人认为 zookeeper 在实现分布式锁这方面是非常非常简单的。
+上面我们已经提到过了 zk 在高并发的情况下保证节点创建的全局唯一性,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。首先肯定是如何获取锁,因为创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,创建成功的就说明获取到了锁 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 watcher 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
+
+### Zookeeper 的实战场景之--命名服务
+
+如何给一个对象设置 ID,大家可能都会想到 UUID,但是 UUID 最大的问题就在于它太长。那么在条件允许的情况下,我们能不能使用 zookeeper 来实现呢?我们之前提到过 zookeeper 是通过 树形结构 来存储数据节点的,那也就是说,对于每个节点的 全路径,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的 ID 设置可以更加便于理解。
+
+### Zookeeper 的实战场景之--集群管理
+
+需求:需要知道整个集群中有多少机器在工作,我们想对及群众的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。而 zookeeper 天然支持的 watcher 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 watcher 进行状态监控和回调。
+
+### Zookeeper 的实战场景之--注册中心
+
+至于注册中心也很简单,我们同样也是让 服务提供者 在 zookeeper 中创建一个临时节点并且将自己的 ip、port、调用方式 写入节点,当 服务消费者 需要进行调用的时候会 通过注册中心找到相应的服务的地址列表(IP 端口什么的) ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然可以让消费者进行节点监听,我记得 Eureka 会先试错,然后再更新)。
diff --git a/_posts/2022-10-21-test-markdown.md b/_posts/2022-10-21-test-markdown.md
new file mode 100644
index 000000000000..e2641a19a870
--- /dev/null
+++ b/_posts/2022-10-21-test-markdown.md
@@ -0,0 +1,14 @@
+---
+layout: post
+title: Lifestyle
+subtitle: fifestyle
+tags: [life]
+---
+
+#### Lifestyle 2022.10.21
+
+- Coding, Adventure, Living
+
+#### Lifestyle 2023.10.21
+
+- Alive,Self
\ No newline at end of file
diff --git a/_posts/2022-10-22-test-markdown.md b/_posts/2022-10-22-test-markdown.md
new file mode 100644
index 000000000000..9d115fe1bc3d
--- /dev/null
+++ b/_posts/2022-10-22-test-markdown.md
@@ -0,0 +1,23 @@
+---
+layout: post
+title: Golang 切片和数组
+subtitle: Golang 的切片是对数组的封装,是个结构体,里面存储着指向数组的指针
+tags: [golang]
+---
+
+### 数组的长度是数组的类型的一部分
+
+[3]int [4]int 是不同的类型
+
+### golang 的切片是个结构体,含有指向数组的指针和数组的长度 以及容量
+
+```go
+type slice struct{
+ // 数组指针
+ array unsafe.Pointer
+ // 数组的长度
+ len int
+ // 数组的容量
+ cap int
+}
+```
diff --git a/_posts/2022-10-23-test-markdown.md b/_posts/2022-10-23-test-markdown.md
new file mode 100644
index 000000000000..625051b86db2
--- /dev/null
+++ b/_posts/2022-10-23-test-markdown.md
@@ -0,0 +1,7 @@
+---
+layout: post
+title: 什么是 scheduler?
+subtitle: Go 程序的执行由两层组成:Go Program,Runtime,即用户程序和运行时。它们之间通过函数调用来实现内存管理、channel 通信、goroutines 创建等功能。用户程序进行的系统调用都会被 Runtime 拦截,以此来帮助它进行调度以及垃圾回收相关的工作。
+tags: [golang]
+---
+
diff --git a/_posts/2022-10-24-test-markdown.md b/_posts/2022-10-24-test-markdown.md
new file mode 100644
index 000000000000..0ddb336bfd58
--- /dev/null
+++ b/_posts/2022-10-24-test-markdown.md
@@ -0,0 +1,115 @@
+---
+layout: post
+title: Important Factor For APP 软件开发人员要了解的十二个要素
+subtitle: 这套理论适用于任意语言和后端服务(数据库、消息队列、缓存等)开发的应用程序
+tags: [开发]
+---
+
+# 简介
+
+如今,软件通常会作为一种服务来交付,它们被称为网络应用程序,或软件即服务(SaaS)12-Factor 为构建如下的 SaaS 应用提供了方法论:
+
+- 使用标准化流程自动配置,从而使新的开发者花费最少的学习成本加入这个项目。
+- 在各个系统中提供最大的可移植性。(不受各个操作系统的限制)
+- 容易部署在云计算机上,从而节省资源
+- 开发环境和生产环境之间的差异降低到最小,并持续交付实施敏捷开发
+- 在开发流程不发生明显的变化下实现扩展、在架构不发生明显的变化下实现扩展、在工具不发生明显的变化下实现扩展
+
+## 1.One Codebase / Many Deploy 基准代码
+
+通常会使用版本控制系统加以管理,如 Git, Mercurial, Subversion。一份用来跟踪代码所有修订版本的数据库被称作 代码库(code repository, code repo, repo)。
+在类似 SVN 这样的集中式版本控制系统中,基准代码 就是指控制系统中的这一份代码库;而在 Git 那样的分布式版本控制系统中,基准代码 则是指最上游的那份代码库.
+基准代码和应用之间总是保持一一对应的关系:
+一旦有多个基准代码,就不能称为一个应用,而是一个分布式系统。分布式系统中的每一个组件都是一个应用,每一个应用可以分别使用 12-Factor 进行开发。
+多个应用共享一份基准代码是有悖于 12-Factor 原则的。解决方案是将共享的代码拆分为独立的类库,然后使用 依赖管理 策略去加载它们。尽管每个应用只对应一份基准代码,但可以同时存在多份部署。每份 部署 相当于运行了一个应用的实例。通常会有一个生产环境,一个或多个预发布环境。此外,每个开发人员都会在自己本地环境运行一个应用实例,这些都相当于一份部署。
+所有部署的基准代码相同,但每份部署可以使用其不同的版本。比如,开发人员可能有一些提交还没有同步至预发布环境;预发布环境也有一些提交没有同步至生产环境。但它们都共享一份基准代码,我们就认为它们只是相同应用的不同部署而已。
+
+## 2.显式声明依赖关系( dependency )
+
+> 显式声明依赖关系( dependency )
+> 通过打包系统安装的类库可以是系统级的(称之为 “site packages”),或仅供某个应用程序使用,部署在相应的目录中(称之为 “vendoring” 或 “bunding”)。规则下的应用程序不会隐式依赖系统级的类库.Ruby 的 Bundler 使用 Gemfile 作为依赖项声明清单,使用 bundle exec 来进行依赖隔离。Python 中则可分别使用两种工具 – Pip 用作依赖声明, Virtualenv 用作依赖隔离。显式声明依赖的优点之一是为新进开发者简化了环境配置流程。新进开发者可以检出应用程序的基准代码,安装编程语言环境和它对应的依赖管理工具,只需通过一个 构建命令 来安装所有的依赖项,即可开始工作。
+
+## 3.配置 在环境变量中存储配置
+
+应用的 配置 在不同 部署 (预发布、生产环境、开发环境等等)间会有很大差异。这其中包括:
+
+- 数据库,Memcached,以及其他 后端服务 的配置.
+- 第三方服务的证书,如 Amazon S3、Twitter 等
+- 每份部署特有的配置,如域名等
+
+有些应用在代码中使用常量保存配置,这与 12-Factor 所要求的代码和配置严格分离显然大相径庭。配置文件在各部署间存在大幅差异,代码却完全一致。
+
+一个解决方法是使用配置文件,但不把它们纳入版本控制系统,就像 Rails 的 config/database.yml 。这相对于在代码中使用常量已经是长足进步,但仍然有缺点:总是会不小心将配置文件签入了代码库;配置文件的可能会分散在不同的目录,并有着不同的格式,这让找出一个地方来统一管理所有配置变的不太现实。更糟的是,这些格式通常是语言或框架特定的。
+
+环境变量可以非常方便地在不同的部署间做修改,却不动一行代码;与配置文件不同,不小心把它们签入代码库的概率微乎其微;与一些传统的解决配置问题的机制(比如 Java 的属性配置文件)相比,环境变量与语言和系统无关。
+
+环境变量的粒度要足够小,且相对独立。它们永远也不会组合成一个所谓的“环境”,而是独立存在于每个部署之中。当应用程序不断扩展,需要更多种类的部署时,这种配置管理方式能够做到平滑过渡
+
+## 4.把后端服务(backing services)当作附加资源
+
+后端服务是指程序运行所需要的通过网络调用的各种服务,如数据库(MySQL,CouchDB),消息/队列系统(RabbitMQ,Beanstalkd),SMTP 邮件发送服务(Postfix),以及缓存系统(Memcached)。本地服务之外,应用程序有可能使用了第三方发布和管理的服务。
+
+**每个不同的后端服务是一份 资源** 。例如,一个 MySQL 数据库是一个资源,两个 MySQL 数据库(用来数据分区)就被当作是 2 个不同的资源。12-Factor 应用将这些数据库都视作 附加资源 ,这些资源和它们附属的部署保持松耦合。部署可以按需加载或卸载资源。例如,如果应用的数据库服务由于硬件问题出现异常,管理员可以从最近的备份中恢复一个数据库,卸载当前的数据库,然后加载新的数据库 – 整个过程都不需要修改代码。
+
+## 5.严格分离构建和运行
+
+基准代码 转化为一份部署(非开发环境)需要以下三个阶段:
+
+- 构建阶段 是指将代码仓库转化为可执行包的过程。构建时会使用指定版本的代码,获取和打包 依赖项,编译成二进制文件和资源文件。
+- 发布阶段 会将构建的结果和当前部署所需 配置 相结合,并能够立刻在运行环境中投入使用。
+- 运行阶段 (或者说“运行时”)是指针对选定的发布版本,在执行环境中启动一系列应用程序 进程。
+
+新的代码在部署之前,需要开发人员触发构建操作。但是,运行阶段不一定需要人为触发,而是可以自动进行。如服务器重启,或是进程管理器重启了一个崩溃的进程。因此,运行阶段应该保持尽可能少的模块,这样假设半夜发生系统故障而开发人员又捉襟见肘也不会引起太大问题。构建阶段是可以相对复杂一些的,因为错误信息能够立刻展示在开发人员面前,从而得到妥善处理。
+
+## 6.以一个或多个无状态进程运行应用
+
+简单的场景下,代码是一个独立的脚本,运行环境是开发人员自己的笔记本电脑,进程由一条命令行(例如 python my_script.py)。另外一个极端情况是,复杂的应用可能会使用很多 进程类型 ,也就是零个或多个进程实例。也就是我们运行的进程在执行的过程不考虑执行的内容需不需要保留给下一次操作。将来的请求多半会由其他进程来服务。
+
+**应用的进程必须无状态且无共享。** 任何需要持久化的数据都要存储在 后端服务内,比如数据库。需要共享的数据要存储在后端服务当中。
+一些互联网系统依赖于 “粘性 session”, 这是指将用户 session 中的数据缓存至某进程的内存中,(缓存用户的浏览器中间)
+Session 中的数据应该保存在诸如 Memcached 或 Redis 这样的带有过期时间的缓存中。
+
+## 7.通过端口绑定(Port binding)来提供服务
+
+互联网应用 通过端口绑定来提供服务,该服务将监听所有发送到这个端口请求。
+
+- 本地环境中,开发人员通过类似 http://localhost:5000/的地址来访问服务。在线上环境中,请求统一发送至公共域名而后路由至绑定了端口的网络进程。
+- 端口绑定这种方式 一个服务可以为另外一个服务提供后端服务。调用方将使用服务方提供的 URL.
+
+## 8.通过进程模型进行扩展
+
+应用的进程所具备的无共享,水平分区的特性 意味着添加并发会变得简单而稳妥。这些进程的类型以及每个类型中进程的数量就被称作 进程构成 。
+
+## 9.快速启动和优雅终止可最大化健壮性
+
+进程 是 易处理(disposable)的,意思是说它们可以瞬间开启或停止。这有利于快速、弹性的伸缩应用,迅速部署变化的 代码 或 配置 ,稳健的部署应用。进程应当追求 最小启动时间 。 理想状态下,进程从敲下命令到真正启动并等待请求的时间应该只需很短的时间。更少的启动时间提供了更敏捷的 发布 以及扩展过程,此外还增加了健壮性,因为进程管理器可以在授权情形下容易的将进程搬到新的物理机器上。
+
+对于普通进程来说 一旦接收 终止信号(SIGTERM) 就会优雅的终止 。网络进程的优雅终止是:**某个服务与某个端口绑定,那么终止的时候,该服务将拒绝所有发送到该端口的请求,直到把已经接收到的请求全部处理完毕后终止。**
+对于 worker 进程来说,**当前正在执行的所有任务全都回退到任务队列**。隐含的要求是:“任务应该是可以重复执行的”。实现主要是通过“把结果包装进入事务”
+
+## 10.尽可能的保持开发,预发布,线上环境相同
+
+从以往经验来看,开发环境(即开发人员的本地 部署)和线上环境(外部用户访问的真实部署)之间存在着很多差异。这些差异表现在以下三个方面:
+
+时间差异: 开发人员正在编写的代码可能需要几天,几周,甚至几个月才会上线。
+人员差异: 开发人员编写代码,运维人员部署代码。
+工具差异: 开发人员或许使用 Nginx,SQLite,OS X,而线上环境使用 Apache,MySQL 以及 Linux。
+
+持续部署 就必须缩小本地与线上差异。 再回头看上面所描述的三个差异:
+缩小时间差异:开发人员可以几小时,甚至几分钟就部署代码。
+缩小人员差异:开发人员不只要编写代码,更应该密切参与部署过程以及代码在线上的表现。
+缩小工具差异:尽量保证开发环境以及线上环境的一致性。像 Vagrant 这样轻量的虚拟环境就可以使得开发人员的本地环境与线上环境无限接近
+
+开发人员有时会觉得在本地环境中使用轻量的后端服务具有很强的吸引力,而那些更重量级的健壮的后端服务应该使用在生产环境。例如,本地使用 SQLite 线上使用 PostgreSQL;又如本地缓存在进程内存中而线上存入 Memcached。
+
+## 11.把日志当作事件流
+
+不应该试图去写或者管理日志文件。相反,每一个运行的进程都会直接的标准输出(stdout)事件流。在预发布或线上部署中,每个进程的输出流由运行环境截获,并将其他输出流整理在一起,然后一并发送给一个或多个最终的处理程序,用于查看或是长期存档。这些存档路径对于应用来说不可见也不可配置,而是完全交给程序的运行环境管理。类似 Logplex 和 Fluentd 的开源工具可以达到这个目的。这些事件流可以输出至文件,或者在终端实时观察。最重要的,输出流可以发送到 Splunk 这样的日志索引及分析系统,或 Hadoop/Hive 这样的通用数据存储系统.
+找出过去一段时间特殊的事件。
+图形化一个大规模的趋势,比如每分钟的请求量。
+根据用户定义的条件实时触发警报,比如每分钟的报错超过某个警戒线。
+
+## 12.后台管理任务当作一次性进程运行
+
+一次性管理进程应该和正常的 常驻进程 使用同样的环境。这些管理进程和任何其他的进程一样使用相同的 代码 和 配置 ,基于某个 发布版本 运行。后台管理代码应该随其他应用程序代码一起发布,从而避免同步问题。
+所有进程类型应该使用同样的 依赖隔离 技术。
diff --git a/_posts/2022-11-01-test-markdown.md b/_posts/2022-11-01-test-markdown.md
new file mode 100644
index 000000000000..af831b57563a
--- /dev/null
+++ b/_posts/2022-11-01-test-markdown.md
@@ -0,0 +1,79 @@
+---
+layout: post
+title: 多级反馈队列?
+subtitle: MLFQ
+tags: [golang]
+---
+
+### MLFQ 的基本规则:
+
+MLFQ 中有许多独立的队列(queue),每个队列有不同的优先级(priority level)。任何时刻,一个工作只能存在于一个队列中。MLFQ 总是优先执行较高优先级的工作(即在较高级队列中的工作)。
+
+MLFQ 调度策略的关键在于如何设置优先级。MLFQ 没有为每个工作指定不变的优先情绪而已,而是根据观察到的行为调整它的优先级。例如,如果一个工作不断放弃 CPU 去等待键盘输入,这是交互型进程的可能行为,MLFQ 因此会让它保持高优先级。相反,如果一个工作长时间地占用 CPU,MLFQ 会降低其优先级。通过这种方式,MLFQ 在进程运行过程中学习其行为,从而利用工作的历史来预测它未来的行为。
+这个算法的一个主要目标:
+如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确实是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。通过这种方式,MLFQ 近似于 SJF。
+
+看一个有 I/O 的例子:
+如果进程在时间片用完之前主动放弃 CPU,则保持它的优先级不变。'这条规则的意图很简单:假设交互型工作中有大量的 I/O 操作(比如等待用户的键盘或鼠标输入),它会在时间片用完之前放弃 CPU。在这种情况下,我们不想处罚它,只是保持它的优先级不变。交互型工作 B(用灰色表示)每执行 1ms 便需要进行 I/O 操作,它与长时间运行的工作 A(用黑色表示)竞争 CPU。MLFQ 算法保持 B 在最高优先级,因为 B 总是让出 CPU。如果 B 是交互型工作,MLFQ 就进一步实现了它的目标,让交互型工作快速运行。
+
+饥饿(starvation)问题:
+如果系统有“太多”交互型工作,就会不断占用 CPU,(因为他的优先级没有发生改变)导致长工作永远无法得到 CPU(它们饿死了)。即使在这种情况下,我们希望这些长工作也能有所进展。
+
+愚弄调度程序(game the scheduler):
+其次,聪明的用户会重写程序,愚弄调度程序(game the scheduler)。愚弄调度程序指的是用一些卑鄙的手段欺骗调度程序,让它给远超公平的资源。上述算法对如下的攻击束手无策:进程在时间片用完之前,调用一个 I/O 操作(比如访问一个无关的文件),从而主动释放 CPU。如此便可以保持在高优先级,占用更多的 CPU 时间。做得好时(比如,每运行 99%的时间片时间就主动放弃一次 CPU),工作可以几乎独占 CPU。
+
+至此,我们得到了 MLFQ 的两条基本规则。
+
+#### 规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
+
+意味着高优先级的队列的任务比低优先级队列的任务要先执行。
+
+#### 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
+
+意味着同一级队列的任务交替轮流按照先来先执行的原则交替执行。
+
+**存在的问题:低优先级队列的任务将被饿死**
+(每次新到到达的任务 CPU 假设它是短作业且优先级别比较高)
+Q8 队列源源不断的有新的任务到来执行,那么低优先级队列的任务将被饿死。
+
+#### 基础版规则 3:刚进入的任务放在最高优先级(最上层队列)。
+
+#### 基础版规则 4a:工作用完整个时间片后,降低其优先级(移入下一个队列)。
+
+#### 基础版规则 4b:如果工作在其时间片以内主动释放 CPU,则优先级不变。
+
+**存在的问题:当某个任务每次都执行到 CPU 分配给他的时间片的 99%的时候,主动放弃 CPU 永远使得自己占据着最高优先级的队列,而且如果他自身就需要很长的时间,那么低优先级队列的任务将被饿死。**
+
+#### 进阶版规则 4:任务用完这层队列分配给它的最大的时间配额时,无论中间主动放弃了多少次 CPU,都把该任务降低优先级(移入下一个队列)。
+
+为 MLFQ 的每层队列提供更完善的 CPU 计时方式(accounting)。调度程序应该记录一个进程在某一层中消耗的总时间,而不是在调度时重新计时。只要进程用完了自己的配额,就将它降到低一优先级的队列中去。不论它是一次用完的,还是拆成很多次用完。
+
+#### 规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
+
+避免饥饿问题。要让 CPU 密集型工作也能取得一些进展(即使不多),我们能做些什么?
+
+周期性地提升(boost)所有工作的优先级。可以有很多方法做到,但我们就用最简单的:将所有工作扔到最高优先级队列。于是有了新规则。
+
+**其他存在的问题:配置多少个级别的队列?每个队列的时间额度配比怎么设置大小?多久提升一次进程的优先级?**
+
+### MLFQ 的变体:
+
+#### 1.支持不同队列可变的时间片长
+
+高优先级队列通常只有较短的时间片(比如 10ms 或者更少),因而这一层的交互工作可以更快地切换。低优先级队列中更多的是 CPU 密集型工作,配置更长的时间片会取得更好的效果。
+Solaris 的 MLFQ 实现(时分调度类 TS)很容易配置。它提供了一组表来决定进程在其生命周期中如何调整优先级,每层的时间片多大,以及多久提升一个工作的优先级[。管理员可以通过这些表,让调度程序的行为方式不同。该表默认有 60 层队列,时间片长度从 20ms(最高优先级),到几百 ms(最低优先级),每一秒左右提升一次进程的优先级。其他一些 MLFQ 调度程序没用表,甚至没用本章中讲到的规则,有些采用数学公式来调整优先级。例如,FreeBSD 调度程序(4.3 版本),会基于当前进程使用了多少 CPU,通过公式计算某个工作的当前优先级。另外,使用量会随时间衰减,这提供了期望的优先级提升,但与这里描述方式不同。阅读 Epema 的论文,他漂亮地概括了这种使用量衰减(decay-usage)算法及其特征。
+
+最后,许多调度程序有一些我们没有提到的特征。例如,有些调度程序将最高优先级队列留给操作系统使用,因此通常的用户工作是无法得到系统的最高优先级的。有些系统允许用户给出优先级设置的建议(advice),比如通过命令行工具 nice,可以增加或降低工作的优先级(稍微),从而增加或降低它在某个时刻运行的机会。操作系统很少知道什么策略对系统中的单个进程和每个进程算是好的,因此提供接口并允许用户或管理员给操作系统一些提示(hint)常常很有用。我们通常称之为建议(advice),因为操作系统不一定要关注它,但是可能会将建议考虑在内,以便做出更好的决定。这种用户建议的方式在操作系统中的各个领域经常十分有用,包括调度程序(通过 nice)、内存管理(madvise),以及文件系统(通知预取和缓存)。
+一组优化的 MLFQ 规则。为了方便查阅,我们重新列在这里。
+
+### 总结
+
+#### 规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
+
+#### 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
+
+#### 规则 3:工作进入系统时,放在最高优先级(最上层队列)。
+
+#### 规则 4:当每个任务完成自己在该层被分配到的时间分额时,就会降低优先级。(无论中间主动放弃了多少次 CPU)。
+
+#### 规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
diff --git a/_posts/2022-11-02-test-markdown.md b/_posts/2022-11-02-test-markdown.md
new file mode 100644
index 000000000000..8fb868435217
--- /dev/null
+++ b/_posts/2022-11-02-test-markdown.md
@@ -0,0 +1,436 @@
+---
+layout: post
+title: 进程?线程?
+subtitle: 以及PCB 的组织方式
+tags: [操作系统]
+---
+
+### PCB 具体包含什么信息?
+
+进程描述信息:
+
+- 进程标志符
+- 用户标志符
+
+进程控制和管理
+
+- 进程的当前状态 new ready running waiting blocked
+- 进程德优先级
+
+资源【分配的清单
+
+- 有关内存地址空间或者虚拟地址的空间信息
+- 所打开的文件列表
+- 所使用的 I/O 设备信息
+
+CPU 相关信息
+
+- CPU 中间各个寄存器的值,当进程被切换的时候,CPU 的状态信息都会被 PCB 当中
+
+### PCB 的组织方式
+
+链表
+
+- 相同状态的进程链在一起,组成各种队列
+- 所有处于就绪状态的进程链在⼀起,称为就绪队列
+- 所有因等待某事件⽽处于等待状态的进程链在⼀起就组成各种阻塞队列
+- 对于运⾏队列在单核 CPU 系统中则只有⼀个运⾏指针了,因为单核 CPU 在某个时间,只能运⾏⼀个程序
+
+索引⽅式
+它的⼯作原理:
+
+- 将同⼀状态的进程组织在⼀个索引表中,索引表项指向相应的 PCB,不同状态对应不同的索引表。
+- ⼀般会选择链表,因为可能⾯临进程创建,销毁等调度导致进程状态发⽣变化,所以链表能够更加灵活的插⼊和删除.
+
+### 进程的控制
+
+#### 01 创建进程
+
+操作系统允许⼀个进程创建另⼀个进程,⽽且允许⼦进程继承⽗进程所拥有的资源,当⼦进程被终⽌时,其在⽗进程处继承的资源应当还给⽗进程。同时,终⽌⽗进程时同时也会终⽌其所有的⼦进程。
+
+- 为新进程分配⼀个唯⼀的进程标识号,并申请⼀个空⽩的 PCB,PCB 是有限的,若申请失败则创建失败; **new ---> error**
+
+- 为进程分配资源,此处如果资源不⾜,进程就会进⼊等待状态,以等待资源;初始化 PCB;**new ---> waiting**
+
+- 如果进程的调度队列能够接纳新进程,那就将进程插⼊到就绪队列,等待被调度运⾏;**new---> ready**
+
+#### 02 终⽌进程
+
+进程可以有 3 种终⽌⽅式:正常结束、异常结束以及外界⼲预(信号 kill 掉)。
+终⽌进程的过程如下:
+
+- 查找需要终⽌的进程的 PCB;
+- 如果处于执⾏状态,则⽴即终⽌该进程的执⾏,然后将 CPU 资源分配给其他进程;
+- 如果其还有⼦进程,则应将其所有⼦进程终⽌;
+- 将该进程所拥有的全部资源都归还给⽗进程或操作系统;
+- 将其从 PCB 所在队列中删除;
+
+### 03 阻塞进程
+
+当进程需要等待某⼀事件完成时,它可以调⽤阻塞语句把⾃⼰阻塞等待。⽽⼀旦被阻塞等待,它只能由另⼀个进程唤醒。
+
+阻塞进程的过程如下:
+
+- 找到将要被阻塞进程标识号对应的 PCB;
+- 如果该进程为运⾏状态,则保护其现场,将其状态转为阻塞状态,停⽌运⾏;
+- 将该 PCB 插⼊到阻塞队列中去;
+
+#### 04 唤醒进程
+
+进程由「运⾏」转变为「阻塞」状态是由于进程必须等待某⼀事件的完成,所以处于阻塞状态的进程是绝对不可能叫醒⾃⼰的。
+如果某进程正在等待 I/O 事件,需由别的进程发消息给它,则只有当该进程所期待的事件出现时,才由发现者进程⽤唤醒语句叫醒它。
+唤醒进程的过程如下:
+
+- 在该事件的阻塞队列中找到相应进程的 PCB;
+- 将其从阻塞队列中移出,并置其状态为就绪状态;
+- 把该 PCB 插⼊到就绪队列中,等待调度程序调度;
+- 进程的阻塞和唤醒是⼀对功能相反的语句,如果某个进程调⽤了阻塞语句,则必有⼀个与之对应的唤醒语句。
+
+#### 05 上下⽂切换
+
+各个进程之间是共享 CPU 资源的,在不同的时候进程之间需要切换,让不同的进程可以在 CPU 执⾏,那么这个⼀个进程切换到另⼀个进程运⾏,称为进程的上下⽂切换各个进程之间是共享 CPU 资源的,在不同的时候进程之间需要切换,让不同的进程可以在 CPU 执⾏,那么这个⼀个进程切换到另⼀个进程运⾏,称为进程的上下⽂切换。在详细说进程上下⽂切换前,我们先来看看
+
+###### CPU 上下⽂切换
+
+> CPU 的程序计数器和 CPU 寄存器 指导 CPU 执行命令,所以是 CPU 的上下文
+
+⼤多数操作系统都是多任务,通常⽀持⼤于 CPU 数量的任务同时运⾏。实际上,这些任务并不是同时运⾏的,只是因为系统在很短的时间内,让各个任务分别在 CPU 运⾏,于是就造成同时运⾏的错觉。任务是交给 CPU 运⾏的,那么在每个任务运⾏前,CPU 需要知道任务从哪⾥加载,⼜从哪⾥开始运⾏。
+所以,操作系统需要事先帮 CPU 设置好 CPU 寄存器和程序计数器。
+
+CPU 寄存器是 CPU 内部⼀个容量⼩,但是速度极快的内存(缓存)。我举个例⼦,寄存器像是的⼝袋,内存像的书包,硬盘则是家⾥的柜⼦,如果的东⻄存放到⼝袋,那肯定是⽐从书包或家⾥柜⼦取出来要快的多。
+再来,程序计数器则是⽤来存储 CPU 正在执⾏的指令位置、或者即将执⾏的下⼀条指令位置。所以说,CPU 寄存器和程序计数是 CPU 在运⾏任何任务前,所必须依赖的环境,这些环境就叫做 CPU 上下⽂。
+
+**操作系统是多任务,CPU 在一段时间内执行不同的任务,在不同的任务之间进行切换,就需要操作系统为 CPU 设置好程序计数器和 CPU 寄存器,记录 CPU 把每个任务执行到什么程度,这么才能在任务切换的时候恢复现场。由操作系统调度的。**
+
+###### 进程的上下⽂切换
+
+> 进程是由内核管理和调度的,所以进程的切换只能发⽣在内核态。进程的上下⽂切换不仅包含了虚拟内存、栈、全局变量等⽤户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。通常,会把交换的信息保存在进程的 PCB,
+
+进程上下⽂切换有哪些场景?
+
+- 为了保证所有进程可以得到公平调度,CPU 时间被划分为⼀段段的时间⽚,这些时间⽚再被轮流分配给各个进程。这样,当某个进程的时间⽚耗尽了,进程就从运⾏状态变为就绪状态,系统从就绪队列选择另外⼀个进程运⾏;
+
+- 进程在系统资源不⾜(⽐如内存不⾜)时,要等到资源满⾜后才可以运⾏,这个时候进程也会被挂起,并由系统调度其他进程运⾏;
+- 当进程通过睡眠函数 sleep 这样的⽅法将⾃⼰主动挂起时,⾃然也会重新调度;
+ 当有优先级更⾼的进程运⾏时,为了保证⾼优先级进程的运⾏,当前进程会被挂起,由⾼优先级进程来运⾏;
+- 发⽣硬件中断时,CPU 上的进程会被中断挂起,转⽽执⾏内核中的中断服务程序;
+ **进程的切换中保存虚拟内存,栈,全局变量等用户空间的资源,也包括内核堆栈,虚拟内存,寄存器,并且把交换的资源保存在进程的 PCB 当中,当要运行另外一个进程的时候,从这个进程的 PCB 当中取出该进程的上下文,然后恢复大 CPU 当中,使得这个进程可以继续执行。**
+ 进程切换:
+ 进程 1 ——>进程 1 的上下文保存 ——>加载进程 2 的上下文 ——>进程 2
+ **进程的切换是由内核管理和调度**
+
+###### 为什么使用线程
+
+线程在早期的操作系统中都是以进程作为独⽴运⾏的基本单位,直到后⾯,计算机科学家们⼜提出了更⼩的能独⽴运⾏的基本单位,也就是线程。
+
+```go
+func main(){
+ for{
+ Read()
+ }
+}
+```
+
+```go
+func main(){
+ for{
+ Decompress()
+ }
+}
+```
+
+```go
+func main(){
+ for{
+ Play()
+ }
+}
+```
+
+存在的问题:进程之间如何通信,共享数据?
+维护进程的系统开销较⼤,如创建进程时,分配资源、建⽴ PCB;终⽌进程时,回收资源、撤销 PCB;进程切换时,保存当前进程的状态信息.
+
+那到底如何解决呢?需要有⼀种新的实体,满⾜以下特性:
+实体之间可以并发运⾏;
+实体之间共享相同的地址空间;
+
+这个新的实体,就是线程( Thread ),线程之间可以并发运⾏且共享相同的地址空间。
+
+###### 线程是什么?
+
+**线程是进程当中的⼀条执⾏流程。**
+同⼀个进程内多个线程之间可以共享代码段、数据段、打开的⽂件等资源,但每个线程各⾃都有⼀套独⽴的寄存器和栈,这样可以确保线程的控制流是相对独⽴的。
+线程的优点:
+⼀个进程中可以同时存在多个线程;
+各个线程之间可以并发执⾏;
+各个线程之间可以共享地址空间和⽂件等资源;
+线程的缺点:
+当进程中的⼀个线程崩溃时,会导致其所属进程的所有线程崩溃。
+举个例⼦,对于游戏的⽤户设计,则不应该使⽤多线程的⽅式,否则⼀个⽤户挂了,会影响其他同个进程的线程。
+**线程并发运行,共享地址空间和文件资源**
+
+###### 线程与进程的⽐较?
+
+
+> 传统的进程有两个基本属性 :可拥有资源的独立单位;可独立调度和分配的基本单位。引 入线程的原因是进程在创建、撤销和切换中,系统必须为之付出较大的时空开销,故在系统中 设置的进程数目不宜过 多,进程切换的频率不宜太高,这就限制 了并发程度的提高。引入线程 后,将传统进程的两个基本属性分开,线程作为调度和分配的基本单位,进程作为独立分配资源的单位。用户可以通过创建线程来完成任务,以减少程序并发执行时付出的时空开销。
+
+**线程是调度的基本单位,进程是资源拥有的基本单位,操作系统的任务调度,本质上的调度对象是线程,进程只是给了县城虚拟内存,全局变量等资源**
+线程与进程最⼤的区别在于:线程是调度的基本单位,⽽进程则是资源拥有的基本单位。操作系统的任务调度,实际上的调度对象是线程,⽽进程只是给线程提供了虚拟
+内存、全局变量等资源。
+
+线程与进程的⽐较如下:
+
+**进程是资源分配的基本单位**,**线程是 CPU 调度的基本单位**;进程拥有⼀个完整的资源平台,⽽线程只独享必不可少的资源,如寄存器和栈;线程同样具有就绪、阻塞、执⾏三种基本状态,同样具有状态之间的转换关系;线程能减少并发执⾏的时间和空间开销;
+**进程拥有一个完整的资源平台,而线程只拥有必不可少的资源。线程同样具有就绪,阻塞,执行三种状态**
+
+对于,线程相⽐进程能减少开销,体现在:
+
+- **进程的创建,需要资源管理的信息** 进程标志符号,用户标志符号,进程的当前状态,进程的当前优先级,虚拟内存地址,文件列表,IO 设备的信息,CPU 中间各个寄存器的值。
+- **因为线程拥有的资源更少,所以终止的更快**
+- 同一个进程内的线程**线程切换比 CPU 切换更加的快速** 线程都具有相同的虚拟地址,相同的页表,进程切换的过程中,切换页表的开销比较大。
+- 线程之间的**数据传递不需要经过内核\***,同一个进程内的各个线程之间共享内存。
+
+###### 线程的上下文切换
+
+**进程是资源分配的基本单位**
+**线程是 CPU 调度的基本单位**
+
+- 当进程只有一个线程时,进程==线程
+- 当进程有多个线程时,这些进程线程,共享 **虚拟内存、全局变量**
+- 所以两个线程不是属于同⼀个进程,则切换的过程就跟进程上下⽂切换⼀样;
+- 当两个线程是属于同⼀个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据,寄存器等不共享的资源。
+
+###### 线程的三种实现方式
+
+**用户线程**
+用户空间实现的线程,由用户的线程库进行管理
+
+**内核线程**
+内核中实现的线程,内核管理的线程
+
+**轻量级线程**
+在内核中用来支持用户线程
+
+###### 用户线程和内核线程的关系
+
+**多对 1**
+多个⽤户线程对应同⼀个内核线程
+
+**1 对 1**
+⼀个⽤户线程对应⼀个内核线程
+**多 对 多**
+第三种是多对多的关系,也就是多个⽤户线程对应到多个内核线程
+
+###### 怎么理解用户线程?
+
+**操作系统看不到 TCP,只能看到 PCB。TCB 是由用户态的线程管理库**
+**用户线程的创建,终止,调度是由用户态的线程管理库来实现,操作系统不直接参与。**
+
+⽤户线程是基于⽤户态的线程管理库来实现的,那么线程控制块(Thread Control Block,TCB) 也是在库⾥⾯来实现的,对于操作系统⽽⾔是看不到这个 TCB 的,它只能看到整个进程的 PCB。⽤户线程的整个线程管理和调度,操作系统是不直接参与的,⽽是由⽤户级线程库函数来完成线程的管理,包括线程的创建、终⽌、同步和调度等。
+⽤户级线程的模型,也就类似前⾯提到的多对⼀的关系,即多个⽤户线程对应同⼀个内核线程
+
+用户空间:
+
+```go
+
+type ThreadControlBlock struct{
+ ID int
+}
+
+type ThreadsTable struct{
+ Threads []ThreadControlBlock
+}
+
+type ProcessControlBlock struct{
+ ID int
+ ThreadsTable ThreadsTable
+}
+
+```
+
+内核空间:
+
+```go
+
+type ProcessControlBlock struct{
+ ID int
+}
+
+type ProcessesTable struct{
+ Processes []ProcessControlBlock
+}
+```
+
+⽤户线程的优点:
+
+- 每个进程都需要有它私有的线程控制块(TCB)列表,⽤来跟踪记录它各个线程状态信息(PC、栈指针、寄存器),TCB 由⽤户级线程库函数来维护,可⽤于不⽀持线程技术的操作系统;
+- ⽤户线程的切换也是由线程库函数来完成的,⽆需⽤户态与内核态的切换,所以速度特别快;
+
+⽤户线程的缺点:
+
+- 由于操作系统不参与线程的调度,如果⼀个线程发起了系统调⽤⽽阻塞,那进程所包含的
+ ⽤户线程都不能执⾏了。
+- **用户态的线程没有办法去打断同一个进程下的另外一个线程,只能等待另外一个线程主动的交出 CPU 的使用权**当⼀个线程开始运⾏后,除⾮它主动地交出 CPU 的使⽤权,否则它所在的进程当中的其他线程⽆法运⾏,因为⽤户态的线程没法打断当前运⾏中的线程它没有这个特权,只有操作系统才有,但是⽤户线程不是由操作系统管理的。
+
+###### 怎么理解内核线程?
+
+**内核线程是由操作系统创建,终止,管理的**
+内核线程是由操作系统管理的,线程对应的 TCB ⾃然是放在操作系统⾥的,这样线程的创建、终⽌和管理都是由操作系统负责。
+内核线程的模型,也就类似前⾯提到的⼀对⼀的关系,即⼀个⽤户线程对应⼀个内核线程,内核线程的优点:
+在⼀个进程当中,如果某个内核线程发起系统调⽤⽽被阻塞,并不会影响其他内核线程的运⾏;分配给线程,多线程的进程获得更多的 CPU 运⾏时间;
+内核线程的缺点
+在⽀持内核线程的操作系统中,由内核来维护进程和线程的上下⽂信息,如 PCB 和 TCB;
+线程的创建、终⽌和切换都是通过系统调⽤的⽅式来进⾏,因此对于系统来说,系统开销⽐较⼤;
+轻量级进程(Light-weight process , LWP)是内核⽀持的⽤户线程,⼀个进程可有⼀个或
+
+###### 怎么理解轻量级线程?
+
+**内核支持的用户线程,一个轻量级线程和一个内核线程一一对应。也就是每一个 LWP 都是由一个内核线程提供支持**
+**LWP 只能被由内核管理,内核像调度普通进程那样调度 LWP**
+**LWP 与普通进程的区别就是:只有一个最小的上下文执行信息和调度程序所需的统计信息**
+**一个进程就代表程序的一个实例,LWP 代表程序的执行线程,一个执行线程不需要那么多的状态信息**
+**LWP 可以使用用户线程的。**
+
+多个 LWP,每个 LWP 是跟内核线程⼀对⼀映射的,也就是 LWP 都是由⼀个内核线程⽀持。轻量级进程(Light-weight process , LWP)是内核⽀持的⽤户线程,⼀个进程可有⼀个或多个 LWP,每个 LWP 是跟内核线程⼀对⼀映射的,也就是 LWP 都是由⼀个内核线程⽀持。
+
+LWP 与⽤户线程的对应关系就有三种:
+1 : 1 ,即⼀个 LWP 对应 ⼀个⽤户线程;
+N : 1 ,即⼀个 LWP 对应多个⽤户线程;
+M : N ,即多个 LMP 对应多个⽤户线程;
+
+```go
+
+type LWPandUserThread struct{
+ ID int
+ UserThreads []UserThread
+}
+
+type UserThread struct{
+ ID int
+}
+
+func Test(){
+ LWPANDKernelThread:= map[string]string{
+ "LWP1":"KernelThread1",
+ "LWP2":"KernelThread2",
+ "LWP3":"KernelThread3",
+ "LWP4":"KernelThread4",
+ }
+ LWPANDUSERTHREAD := []LWPandUserThread {
+ LWPandUserThread {
+ ID: 1,
+ UserThreads: []UserThread{UserThread{1},UserThread{2},UserThread{3}},
+ },
+ LWPandUserThread {
+ ID: 2,
+ UserThreads: []UserThread{UserThread{4},UserThread{5},UserThread{6}},
+ },
+ LWPandUserThread {
+ ID: 3,
+ UserThreads: []UserThread{UserThread{7},UserThread{8},UserThread{9}},
+ },
+ LWPandUserThread {
+ ID: 4,
+ UserThreads: []UserThread{UserThread{10},UserThread{11},UserThread{12}},
+ },
+ LWPandUserThread {
+ ID: 5,
+ UserThreads: []UserThread{UserThread{10},UserThread{11},UserThread{12}},
+ },
+ }
+}
+
+```
+
+1 : 1 模式
+⼀个用户线程对应到⼀个 LWP 再对应到⼀个内核线程,如上图的进程 4,属于此模型。
+优点:实现并⾏,当⼀个 LWP 阻塞,不会影响其他 LWP;
+缺点:每⼀个⽤户线程,就产⽣⼀个内核线程,创建线程的开销较⼤。
+
+N : 1 模式
+多个⽤户线程对应⼀个 LWP 再对应⼀个内核线程,如上图的进程 2,线程管理是在⽤户空间完成的,此模式中⽤户的线程对操作系统不可⻅。
+优点:⽤户线程要开⼏个都没问题,且上下⽂切换发⽣⽤户空间,切换的效率较⾼;
+缺点:⼀个⽤户线程如果阻塞了,则整个进程都将会阻塞,另外在多核 CPU 中,是没办法充分利⽤ CPU 的。
+
+M : N 模式
+根据前⾯的两个模型混搭⼀起,就形成 M:N 模型,该模型提供了两级控制,⾸先多个⽤户线程对应到多个 LWP,LWP 再⼀⼀对应到内核线程
+
+优点:综合了前两种优点,⼤部分的线程上下⽂发⽣在⽤户空间,且多个线程⼜可以充分利⽤多核 CPU 的资源。
+
+#### 06 调度程序(scheduler)
+
+进程都希望⾃⼰能够占⽤ CPU 进⾏⼯作,那么这涉及到前⾯说过的进程上下⽂切换。⼀旦操作系统把进程切换到运⾏状态,也就意味着该进程占⽤着 CPU 在执⾏,但是当操作系把进程切换到其他状态时,那就不能在 CPU 中执⾏了,于是操作系统会选择下⼀个要运⾏的进程。选择⼀个进程运⾏这⼀功能是在操作系统中完成的,通常称为调度程序(scheduler)
+什么时候调度进程,或以什么原则来调度进程呢?
+
+###### 调度时机
+
+在进程的⽣命周期中,当进程从⼀个运⾏状态到另外⼀状态变化的时候,其实会触发⼀次调度。⽐如,以下状态的变化都会触发操作系统的调度:
+从就绪态 -> 运⾏态:当进程被创建时,会进⼊到就绪队列,操作系统会从就绪队列选择⼀个进程运⾏;
+从运⾏态 -> 阻塞态:当进程发⽣ I/O 事件⽽阻塞时,操作系统必须另外⼀个进程运⾏;
+从运⾏态 -> 结束态:当进程退出结束后,操作系统得从就绪队列选择另外⼀个进程运⾏;
+因为,这些状态变化的时候,操作系统需要考虑是否要让新的进程给 CPU 运⾏,或者是否让当前进程从 CPU 上退出来⽽换另⼀个进程运⾏。
+
+###### 调度算法的两类
+
+如果硬件时钟提供某个频率的周期性中断,那么可以根据如何处理时钟中断把调度算法分为两类:
+**⾮抢占式调度算法**
+挑选⼀个进程,然后让该进程运⾏直到被阻塞,或者直到该进程退出,才会调⽤另外⼀个进程,也就是说不会理时钟中断这个事情。
+
+**时间⽚机制下的抢占式调度算法**
+挑选⼀个进程,然后让该进程只运⾏某段时间,如果在该时段结束时,该进程仍然在运⾏时,则会把它挂起,接着调度程序从就绪队列挑选另外⼀个进程。这种抢占式调度处理,需要在时间间隔的末端发⽣时钟中断,以便把 CPU 控制返回给调度程序进⾏调度,也就是常说的时间⽚机制。
+
+###### 调度原则
+
+原则⼀:**某个任务被阻塞后 CPU 可以去执行别的任务。**如果运⾏的程序,发⽣了 I/O 事件的请求,那 CPU 使⽤率必然会很低,因为此时进程在阻塞等待硬盘的数据返回。这样的过程,势必会造成 CPU 突然的空闲。所以,为了提⾼ CPU 利⽤率,在这种发送 I/O 事件致使 CPU 空闲的情况下,调度程序需要从就绪队列中选择⼀个进程来运⾏。
+
+原则⼆:**某个任务时间很长时,CPU 要权衡一下,到底是先执行时间长的,还是执行时间短的任务。**有的程序执⾏某个任务花费的时间会⽐较⻓,如果这个程序⼀直占⽤着 CPU,会造成系统吞吐量(CPU 在单位时间内完成的进程数量)的降低。所以,要提⾼系统的吞吐率,调度程序要权衡⻓任务和短任务进程的运⾏完成数量。
+
+原则三:**使得某些任务的等待时间尽可能的小。**从进程开始到结束的过程中,实际上是包含两个时间,分别是进程运⾏时间和进程等待时间,这两个时间总和就称为周转时间。进程的周转时间越⼩越好,如果进程的等待时间很⻓⽽运⾏时间很短,那周转时间就很⻓,这不是我们所期望的,调度程序应该避免这种情况发⽣。
+
+原则四:**就绪队列中的任务等待时间等待时间尽可能的小。**处于就绪队列的进程,也不能等太久,当然希望这个等待的时间越短越好,这样可以使得进程更快的在 CPU 中执⾏。所以,就绪队列中进程的等待时间也是调度程序所需要考虑的原则。
+
+原则五:**IO 设备的响应时间尽可能的短。**对于⿏标、键盘这种交互式⽐较强的应⽤,我们当然希望它的响应时间越快越好,否则就会影响⽤户体验了。所以,对于交互式⽐较强的应⽤,响应时间也是调度程序需要考虑的原则。
+
+总结:
+
+- **CPU 的利用率**使得 CPU 变忙。(对应第一条,CPU 可以去执行别的任务)
+- **系统吞吐率:单位时间内完成的进程的数量**对应第二条,CPU 权衡短作业和长作业
+- **周转时间**:运行和阻塞的时间越小越好
+- **等待时间**:不是阻塞状态的时间,在就绪队列的时间
+- **响应时间:**:⽤户提交请求到系统第⼀次产⽣响应所花费的时间,在交互式系统中,响应时间是衡量调度算法好坏的主要标准。
+
+###### 调度算法
+
+单核 CPU 系统中常⻅的调度算法
+**01 ⾮抢占式的先来先服务(First Come First Seved, FCFS):**
+每次从就绪队列选择最先进⼊队列的进程,然后⼀直运⾏,直到进程退出或被阻塞,才会继续从队列中选择第⼀个进程接着运⾏。**对⻓作业有利**(长作业可以一次性执行完)适⽤于 CPU 繁忙型作业的系统,⽽不适⽤于 I/O 繁忙型作业的系统。
+
+**02 最短作业优先(Shortest Job First, SJF):**
+调度算法同样也是顾名思义,它会优先选择运⾏时间最短的进程来运⾏,这有助于提⾼系统的吞吐量。显然对⻓作业不利
+
+**03 ⾼响应⽐优先调度算法:**
+(Highest Response Ratio Next, HRRN)调度算法主要是权衡了短作业和⻓作业。每次进⾏进程调度时,先计算「响应⽐优先级」,然后把「响应⽐优先级」最⾼的进程投⼊运⾏,「响应⽐优先级」的计算公式。
+如果两个进程的「等待时间」相同时,「要求的服务时间」越短,「响应⽐」就越⾼,这样短作业的进程容易被选中运⾏;
+如果两个进程「要求的服务时间」相同时,「等待时间」越⻓,「响应⽐」就越⾼,这就兼顾到了⻓作业进程,因为进程的响应⽐可以随时间等待的增加⽽提⾼,当其等待时间⾜够⻓时,其响应⽐便可以升到很⾼,从⽽获得运⾏的机会;
+**04 时间⽚轮转调度算法:**
+每个进程被分配⼀个时间段,称为时间⽚(Quantum),即允许该进程在该时间段中运⾏。如果时间⽚⽤完,进程还在运⾏,那么将会把此进程从 CPU 释放出来,并把 CPU 分配给另外⼀个进程;如果该进程在时间⽚结束前阻塞或结束,则 CPU ⽴即进⾏切换。
+
+**05 最⾼优先级调度算法:**
+前⾯的「时间⽚轮转算法」做了个假设,即让所有的进程同等重要,也不偏袒谁,⼤家的运⾏时间都⼀样。
+但是,对于多⽤户计算机系统就有不同的看法了,它们希望调度是有优先级的,即希望调度程序能从就绪队列中选择最⾼优先级的进程进⾏运⾏,这称为最⾼优先级(Highest PriorityFirst , HPF)调度算法。进程的优先级可以分为,静态优先级和动态优先级:静态优先级:创建进程时候,就已经确定了优先级了,然后整个运⾏时间优先级都不会变化;动态优先级:根据进程的动态变化调整优先级,⽐如如果进程运⾏时间增加,则降低其优先级,如果进程等待时间(就绪队列的等待时间)增加,则升⾼其优先级,也就是随着时间的推移增加等待进程的优先级。
+该算法也有两种处理优先级⾼的⽅法,⾮抢占式和抢占式:
+⾮抢占式:当就绪队列中出现优先级⾼的进程,运⾏完当前进程,再选择优先级⾼的进程。
+抢占式:当就绪队列中出现优先级⾼的进程,当前进程挂起,调度优先级⾼的进程运⾏。
+
+**06 多级反馈队列调度算法:**
+多级反馈队列(Multilevel Feedback Queue)调度算法是「时间⽚轮转算法」和「最⾼优先级算法」的综合和发展。
+「多级」表示有多个队列,每个队列优先级从⾼到低,同时优先级越⾼时间⽚越短。
+「反馈」表示如果有新的进程加⼊优先级⾼的队列时,⽴刻停⽌当前正在运⾏的进程,转⽽去运⾏优先级⾼的队列;
+
+它是如何⼯作的:
+设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从⾼到低,同时优先级越
+⾼时间⽚越短;
+新的进程会被放⼊到第⼀级队列的末尾,按**先来先服务**的原则排队等待被调度,如果在第⼀级队列规定的时间⽚没运⾏完成,则将其转⼊到第⼆级队列的末尾,以此类推,直⾄完成;
+当较⾼优先级的队列为空,才调度较低优先级的队列中的进程运⾏。如果进程运⾏时,有新进程进⼊较⾼优先级的队列,则停⽌当前运⾏的进程并将其移⼊到原队列末尾,接着让较⾼优先级的进程运⾏;
+
+可以发现,对于短作业可能可以在第⼀级队列很快被处理完。对于⻓作业,如果在第⼀级队列处理不完,可以移⼊下次队列等待被执⾏,虽然等待的时间变⻓了,但是运⾏时间也变更⻓了,所以该算法很好的兼顾了⻓短作业,同时有较好的响应时间。
diff --git a/_posts/2022-11-03-test-markdown.md b/_posts/2022-11-03-test-markdown.md
new file mode 100644
index 000000000000..902a2c60b148
--- /dev/null
+++ b/_posts/2022-11-03-test-markdown.md
@@ -0,0 +1,1986 @@
+---
+layout: post
+title: rpcx 学习
+subtitle: RPC vs RESTful
+tags: [Microservices rpc]
+---
+
+# Part 1
+
+1.RESTful 是通过 http 方法操作资源 Rpc 操作的是方法和过程,要操作的是方法对象 2. RESTful 的客户端和服务端是解耦的。Rpc 的客户端是紧密耦合的。 3. Resful 执行的是对资源的操作 CURD 如果是张三的成绩加 3。这个特定目地的操作在 Resful 下不直观,但是在 RPC 下是 Student.Increment(Name,Score)的方法供给客户端口调用。4 .RESTful 的 Request -Response 模型是阻塞。(http1.0 和 http1.1, http 2.0 没这个问题),发送一个请求后只有等到 response 返回才能发送第二个请求 (有些 http server 实现了 pipeling 的功能,但不是标配), RPC 的实现没有这个限制。
+
+在当今用户和资源都是大数据大并发的趋势下,一个大规模的公司不可能使用一个单体程序提供所有的功能,微服务的架构模式越来越多的被应用到产品的设计和开发中, 服务和服务之间的通讯也越发的重要, 所以 RPC 不失是一个解决服务之间通讯的好办法, 本书给大家介绍 Go 语言的 RPC 的开发实践。
+
+## 1. RPC vs RESTful 的不同之处
+
+RPC 的消息传输可以通过 TCP、UDP 或者 HTTP 等,所以有时候我们称之为 RPC over TCP、 RPC over HTTP。RPC 通过 HTTP 传输消息的时候和 RESTful 的架构是类似的,但是也有不同。
+
+首先我们比较 RPC over HTTP 和 RESTful。
+
+首先 RPC 的客户端和服务器端是紧耦合的,客户端需要知道调用的过程的名字,过程的参数以及它们的类型、顺序等。一旦服务器更改了过程的实现, 客户端的实现很容易出问题。RESTful 基于 http 的语义操作资源,参数的顺序一般没有关系,也很容易的通过代理转换链接和资源位置,从这一点上来说,RESTful 更灵活。
+
+其次,它们操作的对象不一样。 RPC 操作的是方法和过程,它要操作的是方法对象。 RESTful 操作的是资源(resource),而不是方法。
+
+第三,RESTful 执行的是对资源的操作,增加、查找、修改和删除等,主要是 CURD,所以如果要实现一个特定目的的操作,比如为名字姓张的学生的数学成绩都加上 10 这样的操作, RESTful 的 API 设计起来就不是那么直观或者有意义。在这种情况下, RPC 的实现更有意义,它可以实现一个 Student.Increment(Name, Score) 的方法供客户端调用。
+
+我们再来比较一下 RPC over TCP 和 RESTful。 如果我们直接使用 socket 实现 RPC,除了上面的不同外,我们可以获得性能上的优势。
+
+RPC over TCP 可以通过长连接减少连接的建立所产生的花费,在调用次数非常巨大的时候(这是目前互联网公司经常遇到的情况,大并发的情况下),这个花费影响是非常巨大的。 当然 RESTful 也可以通过 keep-alive 实现长连接, 但是它最大的一个问题是它的 request-response 模型是阻塞的 (http1.0 和 http1.1, http 2.0 没这个问题), 发送一个请求后只有等到 response 返回才能发送第二个请求 (有些 http server 实现了 pipeling 的功能,但不是标配), RPC 的实现没有这个限制
+
+## 2. 实现一个 Service
+
+```go
+import "context"
+
+type Args struct {
+ A int
+ B int
+}
+
+type Reply struct {
+ C int
+}
+
+type Arith int
+
+func (t *Arith) Mul(ctx context.Context, args *Args, reply *Reply) error {
+ reply.C = args.A * args.B
+ return nil
+}
+```
+
+编写 RPC 服务的时候,相当于抽取 RESTful 下的这个函数的逻辑:
+
+```go
+// requests.LoginByPhoneRequest{}
+type LoginByPhoneRequest struct {
+ Phone string `json:"phone,omitempty" valid:"phone"`
+ Password string `json:"password,omitempty" valid:"password"`
+}
+
+// LoginByPhone 手机登录
+func LoginByPhone(c *gin.Context) {
+ // 1. 验证表单
+ request := requests.LoginByPhoneRequest{}
+
+ if err := c.Bind(&request); err != nil {
+ response.Error(c, err, "请求失败")
+ return
+ }
+
+ // 2. 尝试登录
+ user, err := AttemptLoginByPhone(request.Phone, request.Password)
+
+ if err != nil {
+ // 失败,显示错误提示
+ response.Error(c, err, "账号不存在或密码错误")
+ } else {
+ // 登录成功
+ token := jwt.NewJWT().IssueToken(user.GetStringID(), user.Name)
+
+ response.JSON(c, gin.H{
+ "token": token,
+ })
+ }
+}
+
+```
+
+改造上面的这个逻辑:
+
+```go
+import "context"
+
+type LoginRequest struct {
+ Phone string
+ Password string
+}
+
+type TokenResponse struct {
+ Token string
+ Error string
+}
+
+type UserLogin int
+
+// 传如请求的指针和响应的指针当然还有上下文
+func (t *UserLogin) Mul(ctx context.Context, args *LoginRequest, reply *TokenResponse) error {
+
+ user, err := AttemptLoginByPhone(args.A ,args.B)
+ if err != nil {
+ // 失败,显示错误提示
+ reply.Error="Password and Phone wrong"
+ return err
+ } else {
+ // 登录成功
+ reply.Tokentoken := jwt.NewJWT().IssueToken(user.GetStringID(), user.Name)
+ return nil
+ }
+}
+```
+
+UserLogin 是一个 Go 类型,并且它有一个方法 Mul。 方法 Mul 的 第 1 个参数是 context.Context。 方法 Mul 的 第 2 个参数是 args, args 包含了请求的数据 Phone 和 Password。 方法 Mul 的 第 3 个参数是 reply, reply 是一个指向了 TokenResponse 结构体的指针。 方法 Mul 的 返回类型是 error (可以为 nil)。 方法 Mul 把 输入的 Phone 和 Password 经过校验和加密后得到结果 赋值到 TokenResponse.Token
+
+现在已经定义了一个叫做 UserLogin 的 service, 并且为它实现了 Mul 方法。 下一步骤中, 我们将会继续介绍如何把这个服务注册给服务器,并且如何用 client 调用它。
+
+## 2. 实现 Server
+
+```go
+ s:=server.NewServer()
+ s.RegisterName("UserLogin",new(UserLogin),"")
+ s.Serve("tcp",":8972")
+```
+
+对于服务端我们仅仅是注册写好的服务,然后让服务端的实例在某个端口运行就好了
+
+## 3. 实现 Client
+
+```go
+ // #1
+ d:=client.NewPeer2PeerDiscovery("tcp@"+*addr,"")
+
+ // #2
+ xclient:= client.NewXClient("UserLogin",client.Failtry,client.RandomSelect,d,client.DefaultOption)
+ defer client.Close()
+
+ // #3
+ u:=&UserLogin{
+ Phone:"12345678909",
+ Password:"123456"
+ }
+ // #4
+ r:=&TokenResponse{}
+
+ // #5
+ err:=xclient.Call(context.Background(),"Mul",u,r)
+ if err!=nil{
+ log.Fatalf("Failed to call: %v",err)
+ }
+
+ log.Printf("token is =",r.Token)
+```
+
+服务端需要做的事情是:
+
+- #1 定义客户端服务发现的方式,这里使用最简单的 `Peer2PeerDiscovery`点对点,客户端直连服务端来获取服务地址(详见下面的服务发现的两种方式之客户端发现)
+
+- #2 定义客户端在调用失败的情况下需要做什么,定义客户端如果在有多台服务器实例提供同样服务的情况下,如何选择服务器实例
+
+- #3 定义了被初始化的请求,携带着参数
+
+- #4 定义了被初始化的响应,未携带数据,数据在服务端被调用后得到.定义了响应对象, 默认值是 0 值, 事实上 rpcx 会通过它来知晓返回结果的类型,然后把结果反序列化到这个对象
+
+- #5 调用远程同步的服务并同步结果。
+
+实现一个异步的 Client
+
+```go
+ // #1
+ d:=client.NewPeer2PeerDiscovery("tcp@"+*addr,"")
+
+ // #2
+ xclient:= client.NewXClient("UserLogin",client.Failtry,client.RandomSelect,d,client.DefaultOption)
+ defer client.Close()
+
+ // #3
+ args:=&UserLogin{
+ Phone:"12345678909",
+ Password:"123456"
+ }
+ // #4
+ reply:=&TokenResponse{}
+
+ // #5
+ call:=xclient.Go(context.Background(),"Mul",u,r,nil)
+ if err!=nil{
+ log.Fatalf("Failed to call: %v",err)
+ }
+ replyCall:=<- call
+ if replyCall.Error != nil {
+ log.Fatalf("failed to call: %v", replyCall.Error)
+ } else {
+ log.Printf("%d * %d = %d", args.Phone, args.Password, reply.C)
+ }
+```
+
+必须使用 xclient.Go 来替换 xclient.Call, 然后把结果返回到一个 channel 里。可以从 chnanel 里监听调用结果。
+
+补充:服务发现的方式有两种,客户端发现和服务端发现。
+
+## 服务发现的两种方式
+
+### 1.客户端发现:
+
+客户端负责 **确认可用的服务实例的网络位置**和**请求负载均衡**客户端查询服务注册中心(service registry 它是可用服务实例的数据库)之后利用负载均衡选择可用的服务实例并发出请求。
+**客户端直接请求注册中心**
+
+[!]("https://872026152-files.gitbook.io/~/files/v0/b/gitbook-legacy-files/o/assets%2F-LAinv8dInYi41sSnmWu%2F-LAinzxGnqu1h1CS4HMv%2F-LAio3JT-MDSprzYLyYP%2F4-2.png?generation=1524425067386073&alt=media")
+
+关键词:
+**服务实例在注册中心启动的时候被注册,实例终止的时候被注册中心移除**
+**服务实例和注册中心之间采用心跳机制实时刷新服务实例的信息。**
+**为每一种编程语言实现客户端的服务发现逻辑。**
+服务实例的网络位置在服务注册中心启动时被注册。当实例终止时,它将从服务注册中心中移除。通常使用心跳机制周期性地刷新服务实例的注册信息.
+Netflix OSS 提供了一个很好的客户端发现模式示例。Netflix Eureka 是一个服务注册中心,它提供了一组用于管理服务实例注册和查询可用实例的 REST API。Netflix Ribbon 是一个 IPC 客户端,可与 Eureka 一起使用,用于在可用服务实例之间使请求负载均衡。该模式相对比较简单,除了服务注册中心,没有其他移动部件。此外,由于客户端能发现可用的服务实例,因此可以实现智能的、特定于应用的负载均衡决策,比如使用一致性哈希。该模式的一个重要缺点是它将客户端与服务注册中心耦合在一起。必须为使用的每种编程语言和框架实现客户端服务发现逻辑。
+
+### 2. 服务端发现:
+
+关键词:
+**每个主机上运行一个代理,代理是服务端发现的负载均衡器,客户端通过代理使用主机的 IP 地址和分配的端口号来路由请求,然后代理透明的把请求转发到具体的服务实例上面。往往负载均衡器由部署环境提供,否则还是要引入一个组件,进行设置和管理。**
+**客户端请求路由,路由请求注册中心**
+客户端通过负载均衡器向服务发出请求。负载均衡器查询服务注册中心并将每个请求路由到可用的服务实例。与客户端发现一样,服务实例由服务注册中心注册与销毁。AWS Elastic Load Balancer(ELB)是一个服务端发现路由示例。ELB 通常用于均衡来自互联网的外部流量负载。然而,还可以使用 ELB 来均衡虚拟私有云(VPC)内部的流量负载。客户端通过 ELB 使用其 DNS 名称来发送请求(HTTP 或 TCP)。ELB 均衡一组已注册的 Elastic Compute Cloud(EC2)实例或 EC2 Container Service(ECS)容器之间的流量负载。这里没有单独可见的服务注册中心。相反,EC2 实例与 ECS 容器由 ELB 本身注册。
+
+HTTP 服务器和负载均衡器(如 NGINX Plus 和 NGINX)也可以作为服务端发现负载均衡器。例如,此博文描述了使用 Consul Template 动态重新配置 NGINX 反向代理。Consul Template 是一个工具,可以从存储在 Consul 服务注册中心中的配置数据中定期重新生成任意配置文件。每当文件被更改时,它都会运行任意的 shell 命令。在列举的博文描述的示例中,Consul Template 会生成一个 nginx.conf 文件,该文件配置了反向代理,然后通过运行一个命令告知 NGINX 重新加载配置。更复杂的实现可以使用其 HTTP API 或 DNS 动态重新配置 NGINX Plus。
+
+某些部署环境(如 Kubernetes 和 Marathon)在群集中的每个主机上运行着一个代理。这些代理扮演着服务端发现负载均衡器角色。为了向服务发出请求,客户端通过代理使用主机的 IP 地址和服务的分配端口来路由请求。之后,代理将请求透明地转发到在集群中某个运行的可用服务实例。
+
+服务端发现模式有几个优点与缺点。该模式的一大的优点是其把发现的细节从客户端抽象出来。客户端只需向负载均衡器发出请求。这消除了为服务客户端使用的每种编程语言和框架都实现发现逻辑的必要性。另外,如上所述,一些部署环境免费提供此功能。然而,这种模式存在一些缺点。除非负载均衡器由部署环境提供,否则需要引入这个高可用系统组件,并进行设置和管理。
+
+## 服务注册中心
+
+关键词:
+
+**存储了服务实例网络位置的数据库。**
+
+服务注册中心(service registry)是服务发现的一个关键部分。它是一个包含了服务实例网络位置的数据库。服务注册中心必须是高可用和最新的。虽然客户端可以缓存从服务注册中心获得的网络位置,但该信息最终会过期,客户端将无法发现服务实例。因此,服务注册中心使用了复制协议(replication protocol)来维护一致性的服务器集群组成。
+
+**Netflix Eureka 组侧中心的做法是提供用于注册和查询的 REST API**
+如之前所述,Netflix Eureka 是一个很好的服务注册中心范例。它提供了一个用于注册和查询服务实例的 REST API。**服务实例使用 POST 请求注册**其网络位置。它必须每隔 30 秒**使用 PUT 请求来刷新**其注册信息。通过使用 HTTP **DELETE 请求或实例注册超时来移除**注册信息。正如所料,客户端可以使用 HTTP **GET 请求来检索**已注册的服务实例。
+
+Netflix 通过在每个 Amazon EC2 可用区中运行一个或多个 Eureka 服务器来实现高可用。每个 Eureka 服务器都运行在有一个 弹性 IP 地址的 EC2 实例上。DNS TEXT 记录用于存储 Eureka 集群配置,这是一个从可用区到 Eureka 服务器的网络位置列表的映射。当 Eureka 服务器启动时,它将会查询 DNS 以检索 Eureka 群集配置,查找其对等体,并为其分配一个未使用的弹性 IP 地址。
+Eureka 客户端 — 服务与服务客户端 — 查询 DNS 以发现 Eureka 服务器的网络位置。客户端优先使用相同可用区中的 Eureka 服务器,如果没有可用的,则使用另一个可用区的 Eureka 服务器。
+
+其他的服务注册中心:
+
+**etcd:**
+一个用于**共享配置**和服务发现的高可用、**分布式**和一致的**键值存储**。使用了 etcd 的两个著名项目分别为 Kubernetes 和 Cloud Foundry。
+
+**Consul:**
+一个用于发现和**配置服务**的工具。它**提供了一个 API**,可用于客户端注册与发现服务。Consul 可对服务进行健康检查,以确定服务的可用性。
+
+**Apache ZooKeeper**
+一个被广泛应用于分布式应用的高性能协调服务。Apache ZooKeeper 最初是 Hadoop 的一个子项目,但现在已经成为一个独立的顶级项目。
+另外,如之前所述,部分系统如 Kubernetes、Marathon 和 AWS,没有明确的服务注册中心。相反,服务注册中心只是基础设施的一个内置部分。
+
+## 服务注册的两种方式
+
+### 1.自注册
+
+当使用自注册模式时,服务实例负责在服务注册中心注册和注销自己。此外,如果有必要,服务实例将通过发送心跳请求来防止其注册信息过期。
+
+该方式的一个很好的范例就是 Netflix OSS Eureka 客户端。Eureka 客户端负责处理服务实例注册与注销的所有方面。实现了包括服务发现在内的多种模式的 Spring Cloud 项目可以轻松地使用 Eureka 自动注册服务实例。只需在 Java Configuration 类上应用 @EnableEurekaClient 注解即可。自注册模式有好有坏。一个好处是它相对简单,不需要任何其他系统组件。然而,主要缺点是它将服务实例与服务注册中心耦合。必须为服务使用的每种编程语言和框架都实现注册代码。
+
+### 2.第三方注册
+
+**服务注册器要么轮询部署环境 或者 订阅事件来跟踪运行的实例集**
+当使用第三方注册模式时,服务实例不再负责向服务注册中心注册自己。相反,该工作将由被称为服务注册器(service registrar)的另一系统组件负责。服务注册器通过轮询部署环境或订阅事件来跟踪运行实例集的变更情况。当它检测到一个新的可用服务实例时,它会将该实例注册到服务注册中心。此外,服务注册器可以注销终止的服务实例。
+
+开源的 Registrator 项目是一个很好的服务注册器示例。它可以自动注册和注销作为 Docker 容器部署的服务实例。注册器支持多种服务注册中心,包括 etcd 和 Consul。
+另一个服务注册器例子是 NetflixOSS Prana。其主要用于非 JVM 语言编写的服务,它是一个与服务实例并行运行的附加应用。Prana 使用了 Netflix Eureka 来注册和注销服务实例。
+
+服务注册器在部分部署环境中是一个内置组件。Autoscaling Group 创建的 EC2 实例可以自动注册到 ELB。Kubernetes 服务能够自动注册并提供发现。第三方注册模式同样有好有坏。一个主要的好处是服务与服务注册中心之间解耦。不需要为开发人员使用的每种编程语言和框架都实现服务注册逻辑。相反,仅需要在专用服务中以集中的方式处理服务实例注册。
+
+该模式的一个缺点是,除非部署环境内置,否则同样需要引入这样一个高可用的系统组件,并进行设置和管理。
+
+总结:
+在微服务应用中,运行的服务实例集会动态变更。实例有动态分配的网络位置。因此,为了让客户端向服务发出请求,它必须使用服务发现机制。
+服务发现的关键部分是服务注册中心。服务注册中心是一个可用服务实例的数据库。服务注册中心提供了管理 API 和查询 API 的功能。服务实例通过使用管理 API 从服务注册中心注册或者注销。系统组件使用查询 API 来发现可用的服务实例。
+
+有两种主要的服务发现模式:客户端发现与服务端发现。在使用了客户端服务发现的系统中,客户端查询服务注册中心,选择一个可用实例并发出请求。在使用了服务端发现的系统中,客户端通过路由进行请求,路由将查询服务注册中心,并将请求转发到可用实例。
+
+# Part2
+
+## rpcx Service
+
+作为服务提供者,首先需要定义服务。 当前 rpcx 仅支持 可导出的 methods (方法) 作为服务的函数。 (see 可导出) 并且这个可导出的方法必须满足以下的要求:
+
+必须是可导出类型的方法
+
+- 接受 3 个参数,第一个是 context.Context 类型
+- 其他 2 个都是可导出(或内置)的类型。
+- 第 3 个参数是一个指针
+- 有一个 error 类型的返回值
+
+```go
+type UserLogin int
+
+// 传如请求的指针和响应的指针当然还有上下文
+func (t *UserLogin) Mul(ctx context.Context, args *LoginRequest, reply *TokenResponse) error {
+
+ user, err := AttemptLoginByPhone(args.A ,args.B)
+ if err != nil {
+ // 失败,显示错误提示
+ reply.Error="Password and Phone wrong"
+ return err
+ } else {
+ // 登录成功
+ reply.Tokentoken := jwt.NewJWT().IssueToken(user.GetStringID(), user.Name)
+ return nil
+ }
+}
+```
+
+可以使用 RegisterName 来注册 rcvr 的方法,这里这个服务的名字叫做 name。 如果使用 Register, 生成的服务的名字就是 rcvr 的类型名。 可以在注册中心添加一些元数据供客户端或者服务管理者使用。例如 weight、geolocation、metrics。
+
+```go
+func (s *Server) Register(rcvr interface{}, metadata string) error
+func (s *Server) Register(rcvr interface{}, metadata string) error
+```
+
+这里是一个实现了 Mul 方法的例子:
+
+```go
+import "context"
+
+type Args struct {
+ A int
+ B int
+}
+
+type Reply struct {
+ C int
+}
+
+type Arith int
+
+func (t *Arith) Mul(ctx context.Context, args *Args, reply *Reply) error {
+ reply.C = args.A * args.B
+ return nil
+}
+```
+
+在这个例子中,可以定义 Arith 为 struct{} 类型, 它不会影响到这个服务。 也可以定义 args 为 Args, 也不会产生影响。
+
+## rpcx Server
+
+关键词:
+**写完服务后暴露服务请求,需要启动一个 TCP 或者 UDP 服务器来监听请求**
+在定义完服务后,会想将它暴露出去来使用。应该通过启动一个 TCP 或 UDP 服务器来监听请求。
+
+服务器支持以如下这些方式启动,监听请求和关闭:
+
+```go
+ func NewServer(options ...OptionFn) *Server
+ func (s *Server) Close() error
+ func (s *Server) RegisterOnShutdown(f func())
+ func (s *Server) Serve(network, address string) (err error)
+ func (s *Server) ServeHTTP(w http.ResponseWriter, req *http.Request)
+```
+
+首先应使用 NewServer 来创建一个服务器实例。
+其次可以调用 Serve 或者 ServeHTTP 来监听请求。ServeHTTP 将服务通过 HTTP 暴露出去。Serve 通过 TCP 或 UDP 协议与客户端通信
+
+服务器包含一些字段(有一些是不可导出的):
+
+```go
+type Server struct {
+ Plugins PluginContainer
+ // AuthFunc 可以用来鉴权
+ AuthFunc func(ctx context.Context, req *protocol.Message, token string) error
+ // 包含过滤后或者不可导出的字段
+}
+```
+
+Plugins 包含了服务器上所有的插件。我们会在之后的章节介绍它。
+
+AuthFunc 是一个可以检查客户端是否被授权了的鉴权函数。我们也会在之后的章节介绍它
+rpcx 提供了 3 个 OptionFn 来设置启动选项:
+
+```go
+ func WithReadTimeout(readTimeout time.Duration) OptionFn
+ func WithTLSConfig(cfg *tls.Config) OptionFn
+ func WithWriteTimeout(writeTimeout time.Duration) OptionFn
+```
+
+rpcx 支持如下的网络类型:
+
+tcp: 推荐使用
+http: 通过劫持 http 连接实现
+unix: unix domain sockets
+reuseport: 要求 SO_REUSEPORT socket 选项, 仅支持 Linux kernel 3.9+
+quic: support quic protocol
+kcp: sopport kcp protocol
+
+一个服务器的示例代码:
+
+```go
+package main
+
+import (
+ "flag"
+
+ example "github.com/rpcx-ecosystem/rpcx-examples3"
+ "github.com/smallnest/rpcx/server"
+)
+
+var (
+ addr = flag.String("addr", "localhost:8972", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ s := server.NewServer()
+ //s.RegisterName("Arith", new(example.Arith), "")
+ s.Register(new(example.Arith), "")
+ s.Serve("tcp", *addr)
+}
+```
+
+## rpcx Client
+
+客户端使用和服务同样的通信协议来发送请求和获取响应。
+
+```go
+type Client struct {
+ Conn net.Conn
+
+ Plugins PluginContainer
+ // 包含过滤后的或者不可导出的字段
+}
+```
+
+Conn 代表客户端与服务器之前的连接。 Plugins 包含了客户端启用的插件。
+有这些方法
+
+```go
+ func (client *Client) Call(ctx context.Context, servicePath, serviceMethod string, args interface{}, reply interface{}) error
+ func (client *Client) Close() error
+ func (c *Client) Connect(network, address string) error
+ func (client *Client) Go(ctx context.Context, servicePath, serviceMethod string, args interface{}, reply interface{}, done chan *Call) *Call
+ func (client *Client) IsClosing() bool
+ func (client *Client) IsShutdown() bool
+```
+
+Call 代表对服务同步调用。客户端在收到响应或错误前一直是阻塞的。 然而 Go 是异步调用。它返回一个指向 Call 的指针, 可以检查 \*Call 的值来获取返回的结果或错误。
+Close 会关闭所有与服务的连接。他会立刻关闭连接,不会等待未完成的请求结束。
+IsClosing 表示客户端是关闭着的并且不会接受新的调用。 IsShutdown 表示客户端不会接受服务返回的响应。
+
+> Client uses the default CircuitBreaker (circuit.NewRateBreaker(0.95, 100)) to handle errors. This is a poplular rpc error handling style. When the error rate hits the threshold, this service is marked unavailable in 10 second window. You can implement your customzied CircuitBreaker.
+
+Client 使用默认的 CircuitBreaker (circuit.NewRateBreaker(0.95, 100)) 来处理错误。这是 rpc 处理错误的普遍做法。当出错率达到阈值, 这个服务就会在接下来的 10 秒内被标记为不可用。也可以实现自己的 CircuitBreaker。
+下面是客户端的例子:
+
+```go
+ client := &Client{
+ option: DefaultOption,
+ }
+
+ err := client.Connect("tcp", addr)
+ if err != nil {
+ t.Fatalf("failed to connect: %v", err)
+ }
+ defer client.Close()
+
+ args := &Args{
+ A: 10,
+ B: 20,
+ }
+
+ reply := &Reply{}
+ err = client.Call(context.Background(), "Arith", "Mul", args, reply)
+ if err != nil {
+ t.Fatalf("failed to call: %v", err)
+ }
+
+ if reply.C != 200 {
+ t.Fatalf("expect 200 but got %d", reply.C)
+ }
+```
+
+## rpcx XClient
+
+XClient 是对客户端的封装,增加了一些服务发现和服务治理的特性。
+
+```go
+type XClient interface {
+ SetPlugins(plugins PluginContainer)
+ ConfigGeoSelector(latitude, longitude float64)
+ Auth(auth string)
+
+ Go(ctx context.Context, serviceMethod string, args interface{}, reply interface{}, done chan *Call) (*Call, error)
+ Call(ctx context.Context, serviceMethod string, args interface{}, reply interface{}) error
+ Broadcast(ctx context.Context, serviceMethod string, args interface{}, reply interface{}) error
+ Fork(ctx context.Context, serviceMethod string, args interface{}, reply interface{}) error
+ Close() error
+}
+```
+
+SetPlugins 方法可以用来设置 Plugin 容器, Auth 可以用来设置鉴权 token。
+ConfigGeoSelector 是一个可以通过地址位置选择器来设置客户端的经纬度的特别方法。
+一个 XCLinet 只对一个服务负责,它可以通过 serviceMethod 参数来调用这个服务的所有方法。如果想调用多个服务,必须为每个服务创建一个 XClient。
+一个应用中,一个服务只需要一个共享的 XClient。它可以被通过 goroutine 共享,并且是协程安全的。
+Go 代表异步调用, Call 代表同步调用。
+XClient 对于一个服务节点使用单一的连接,并且它会缓存这个连接直到失效或异常。
+
+## rpcx 服务发现
+
+rpcx 支持许多服务发现机制,也可以实现自己的服务发现。
+
+- Peer to Peer: 客户端直连每个服务节点。
+- Peer to Multiple: 客户端可以连接多个服务。服务可以被编程式配置。
+- Zookeeper: 通过 zookeeper 寻找服务。
+- Etcd: 通过 etcd 寻找服务。
+- Consul: 通过 consul 寻找服务。
+- mDNS: 通过 mDNS 寻找服务(支持本地服务发现)。
+- In process: 在同一进程寻找服务。客户端通过进程调用服务,不走 TCP 或 UDP,方便调试使用。
+
+下面是一个同步的 rpcx 例子
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ example "github.com/rpcx-ecosystem/rpcx-examples3"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr = flag.String("addr", "localhost:8972", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+}
+```
+
+## rpcx Client 的服务治理 (失败模式与负载均衡)
+
+在一个大规模的 rpc 系统中,有许多服务节点提供同一个服务。客户端如何选择最合适的节点来调用呢?如果调用失败,客户端应该选择另一个节点或者立即返回错误?这里就有了故障模式和负载均衡的问题。
+rpcx 支持 故障模式:
+
+- Failfast:如果调用失败,立即返回错误
+- Failover:选择其他节点,直到达到最大重试次数
+- Failtry:选择相同节点并重试,直到达到最大重试次数
+
+对于负载均衡(对应前面讲的:服务端发现模式和客户端发现模式下,如果是客户端发现模式那么需要给客户端传递一个负载均衡器,如果是服务端发现模式,那么代理就是的负载均衡器),rpcx 提供了许多选择器:
+
+- Random: 随机选择节点
+- Roundrobin: 使用 roundrobin 算法选择节点
+- Consistent hashing: 如果服务路径、方法和参数一致,就选择同一个节点。使用了非常快的 jump consistent hash 算法。
+- Weighted: 根据元数据里配置好的权重(weight=xxx)来选择节点。类似于 nginx 里的实现(smooth weighted algorithm)
+ Network quality: 根据 ping 的结果来选择节点。网络质量越好,该节点被选择的几率越大。
+- Geography: 如果有多个数据中心,客户端趋向于连接同一个数据机房的节点。
+- Customized Selector: 如果以上的选择器都不适合,可以自己定制选择器。例如一个 rpcx 用户写过它自己的选择器,他有 2 个数据中心,但是这些数据中心彼此有限制,不能使用 Network quality 来检测连接质量。
+
+```go
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, client.NewPeer2PeerDiscovery("tcp@"+*addr2, ""), client.DefaultOption)
+```
+
+注意看这里:一个客户端需要了
+
+- 一个提供服务发现的对象**client.NewPeer2PeerDiscovery("tcp@"+\*addr2, "")**
+- 一个负均衡器的对象 **client.RandomSelect**
+- 一个支持发生故障后的对象 **client.Failtry**
+ 再再再总结亿遍:
+ 需要“服务发现的方式“的对象 ,“负载均衡选择器”的对象,“故障处理“的对象
+
+完整的例子:
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ example "github.com/rpcx-ecosystem/rpcx-examples3"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr2 = flag.String("addr", "localhost:8972", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d := client.NewPeer2PeerDiscovery("tcp@"+*addr2, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ reply := &example.Reply{}
+ call, err := xclient.Go(context.Background(), "Mul", args, reply, nil)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ replyCall := <-call.Done
+ if replyCall.Error != nil {
+ log.Fatalf("failed to call: %v", replyCall.Error)
+ } else {
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+}
+```
+
+## rpcx Client 的广播与群发
+
+XClient 接口下的方法
+
+```go
+ Broadcast(ctx context.Context, serviceMethod string, args interface{}, reply interface{}) error
+ Fork(ctx context.Context, serviceMethod string, args interface{}, reply interface{}) error
+```
+
+Broadcast 表示向所有服务器发送请求,只有所有服务器正确返回时才会成功。此时 FailMode 和 SelectMode 的设置是无效的。请设置超时来避免阻塞。
+Fork 表示向所有服务器发送请求,只要任意一台服务器正确返回就成功。此时 FailMode 和 SelectMode 的设置是无效的。
+可以使用 NewXClient 来获取一个 XClient 实例。
+
+```go
+func NewXClient(servicePath string, failMode FailMode, selectMode SelectMode, discovery ServiceDiscovery, option Option) XClient
+```
+
+NewXClient 必须使用服务名称作为第一个参数, 然后是 failmode、 selector、 discovery 等其他选项。
+
+# Part3 Transport
+
+> rpcx 的 Transport
+
+rpcx 可以通过 TCP、HTTP、UnixDomain、QUIC 和 KCP 通信。也可以使用 http 客户端通过网关或者 http 调用来访问 rpcx 服务。
+
+### TCP
+
+这是最常用的通信方式。高性能易上手。可以使用 TLS 加密 TCP 流量。
+服务端使用 tcp 做为网络名并且**在注册中心注册了名为 serviceName/tcp@ipaddress:port 的服务**。
+
+```go
+s.Serve("tcp", *addr)
+ // 点对点采用Tcp通信
+ d := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+```
+
+### HTTP Connect
+
+**如果想要使用 HttpConnect 方法,那么应该使用网关**
+可以发送 HTTP CONNECT 方法给 rpcx 服务器。 Rpcx 服务器会劫持这个连接然后将它作为 TCP 连接来使用。 需要注意,客户端和服务端并不使用 http 请求/响应模型来通信,他们仍然使用二进制协议。
+
+网络名称是 http, 它注册的格式是 serviceName/http@ipaddress:port。
+
+HTTP Connect 并不被推荐。 TCP 是第一选择。
+
+**如果想使用 http 请求/响应 模型来访问服务,应该使用网关或者 http_invoke。**
+
+### Unixdomain
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr = flag.String("addr", "/tmp/rpcx.socket", "server address")
+)
+
+func main() {
+ flag.Parse()
+ // 点对点采用Unixdomain通信
+ d, _ := client.NewPeer2PeerDiscovery("unix@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+}
+```
+
+### QUIC
+
+```go
+//go run -tags quic client.go
+package main
+
+import (
+ "context"
+ "crypto/tls"
+ "crypto/x509"
+ "flag"
+ "fmt"
+ "io/ioutil"
+ "log"
+ "time"
+
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr = flag.String("addr", "127.0.0.1:8972", "server address")
+)
+
+type Args struct {
+ A int
+ B int
+}
+
+type Reply struct {
+ C int
+}
+
+func main() {
+ flag.Parse()
+
+ // CA
+ caCertPEM, err := ioutil.ReadFile("../ca.pem")
+ if err != nil {
+ panic(err)
+ }
+
+ roots := x509.NewCertPool()
+ ok := roots.AppendCertsFromPEM(caCertPEM)
+ if !ok {
+ panic("failed to parse root certificate")
+ }
+
+ conf := &tls.Config{
+ // InsecureSkipVerify: true,
+ RootCAs: roots,
+ }
+
+ option := client.DefaultOption
+ option.TLSConfig = conf
+
+ d, _ := client.NewPeer2PeerDiscovery("quic@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, option)
+ defer xclient.Close()
+
+ args := &Args{
+ A: 10,
+ B: 20,
+ }
+
+ start := time.Now()
+ for i := 0; i < 100000; i++ {
+ reply := &Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+ t := time.Since(start).Nanoseconds() / int64(time.Millisecond)
+
+ fmt.Printf("tps: %d calls/s\n", 100000*1000/int(t))
+}
+
+```
+
+其余的 ca.key 和 ca.pem 以及 ca.srl 文件暂且省略
+
+### KCP
+
+KCP 是一个快速并且可靠的 ARQ 协议。
+
+网络名称是 kcp。
+
+当使用 kcp 的时候,必须设置 Timeout,利用 timeout 保持连接的检测。因为 kcp-go 本身不提供 keepalive/heartbeat 的功能,当服务器宕机重启的时候,原有的连接没有任何异常,只会 hang 住,我们只能依靠 Timeout 避免 hang 住。
+
+```go
+//go run -tags kcp client.go
+package main
+
+import (
+ "context"
+ "crypto/sha1"
+ "flag"
+ "fmt"
+ "log"
+ "net"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+ kcp "github.com/xtaci/kcp-go"
+ "golang.org/x/crypto/pbkdf2"
+)
+
+var (
+ addr = flag.String("addr", "localhost:8972", "server address")
+)
+
+const cryptKey = "rpcx-key"
+const cryptSalt = "rpcx-salt"
+
+func main() {
+ flag.Parse()
+
+ pass := pbkdf2.Key([]byte(cryptKey), []byte(cryptSalt), 4096, 32, sha1.New)
+ bc, _ := kcp.NewAESBlockCrypt(pass)
+ option := client.DefaultOption
+ option.Block = bc
+
+ d, _ := client.NewPeer2PeerDiscovery("kcp@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RoundRobin, d, option)
+ defer xclient.Close()
+
+ // plugin
+ cs := &ConfigUDPSession{}
+ pc := client.NewPluginContainer()
+ pc.Add(cs)
+ xclient.SetPlugins(pc)
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ start := time.Now()
+ for i := 0; i < 10000; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+ //log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+ dur := time.Since(start)
+ qps := 10000 * 1000 / int(dur/time.Millisecond)
+ fmt.Printf("qps: %d call/s", qps)
+}
+
+type ConfigUDPSession struct{}
+
+func (p *ConfigUDPSession) ConnCreated(conn net.Conn) (net.Conn, error) {
+ session, ok := conn.(*kcp.UDPSession)
+ if !ok {
+ return conn, nil
+ }
+
+ session.SetACKNoDelay(true)
+ session.SetStreamMode(true)
+ return conn, nil
+}
+```
+
+### reuseport
+
+网络名称是 reuseport。
+
+它使用 tcp 协议并且在 linux/uxix 服务器上开启 SO_REUSEPORT socket 选项。
+
+```go
+//go run -tags reuseport client.go
+
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr = flag.String("addr", "localhost:8972", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")
+
+ option := client.DefaultOption
+
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, option)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(time.Second)
+ }
+
+}
+```
+
+### TLS
+
+```go
+package main
+
+import (
+ "context"
+ "crypto/tls"
+ "flag"
+ "log"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr = flag.String("addr", "localhost:8972", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")
+
+ option := client.DefaultOption
+
+ conf := &tls.Config{
+ InsecureSkipVerify: true,
+ }
+
+ option.TLSConfig = conf
+
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, option)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+}
+```
+
+# Part 4 注册中心 (rpcx 是典型的两种服务发现模式下的--服务端发现)
+
+> 注册中心 和 服务端 耦合
+
+(如果是采用点对点的方式实际上是没有注册中心的 ,客户端直接得到唯一的服务器的地址,连接服务。在系统扩展时,可以进行一些更改,服务器不需要进行更多的配置 客户端使用 Peer2PeerDiscovery 来设置该服务的网络和地址。而且由于只有有一个节点,因此选择器是不可用的。`d := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")` `xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)`)服务端可以采用自注册和第三方注册的方式进行注册。
+
+rpcx 会自动将服务的信息比如服务名,监听地址,监听协议,权重等注册到注册中心,同时还会定时的将服务的吞吐率更新到注册中心。如果服务意外中断或者宕机,注册中心能够监测到这个事件,它会通知客户端这个服务目前不可用,在服务调用的时候不要再选择这个服务器。
+
+客户端初始化的时候会从注册中心得到服务器的列表,然后根据不同的路由选择选择合适的服务器进行服务调用。 同时注册中心还会通知客户端某个服务暂时不可用
+通常客户端会选择一个服务器进行调用。
+
+## Peer2Peer
+
+- Peer to Peer: 客户端直连每个服务节点。(实际上没有注册中心)
+
+```go
+ d := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+```
+
+注意:rpcx 使用 network @ Host: port 格式表示一项服务。在 network 可以 tcp , http ,unix ,quic 或 kcp。该 Host 可以所主机名或 IP 地址。NewXClient 必须使用服务名称作为第一个参数,然后使用 failmode selector,discovery 和其他选项。
+
+## MultipleServers
+
+- Peer to Multiple: 客户端可以连接多个服务。服务可以被编程式配置。(实际上也没有注册中心,那么具体是怎么做的?
+ 假设我们有固定的几台服务器提供相同的服务,我们可以采用这种方式。如果有多个服务但没有注册中心.可以用编码的方式在客户端中配置服务的地址。 服务器不需要进行更多的配置。)
+
+```go
+ d := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+```
+
+上面的方式只能访问一台服务器,假设我们有固定的几台服务器提供相同的服务,我们可以采用这种方式。如果有多个服务但没有注册中心.可以用编码的方式在客户端中配置服务的地址。 服务器不需要进行更多的配置。客户端使用 MultipleServersDiscovery 并仅设置该服务的网络和地址。必须在 MultipleServersDiscovery 中设置服务信息和元数据。如果添加或删除了某些服务,可以调用 MultipleServersDiscovery.Update 来动态
+
+```go
+func (d *MultipleServersDiscovery) Update(pairs []*KVPair)
+```
+
+## Zookeeper
+
+- Zookeeper: 通过 zookeeper 寻找服务。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ cclient "github.com/rpcxio/rpcx-zookeeper/client"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ zkAddr = flag.String("zkAddr", "localhost:2181", "zookeeper address")
+ basePath = flag.String("base", "/rpcx_test", "prefix path")
+)
+
+func main() {
+ flag.Parse()
+ // 更改服务发现为--客户端发现之--从Zookeeper 发现
+ d, _ := cclient.NewZookeeperDiscovery(*basePath, "Arith", []string{*zkAddr}, nil)
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ time.Sleep(1e9)
+ }
+
+}
+```
+
+**某个服务实例对客户端无应答案**
+Apache ZooKeeper 是 Apache 软件基金会的一个软件项目,他为大型分布式计算提供开源的分布式配置服务、**同步服务**和命名注册。 ZooKeeper 曾经是 Hadoop 的一个子项目,但现在是一个独立的顶级项目。ZooKeeper 的架构通过冗余服务实现高可用性。因此,如果第一次无应答,客户端就可以询问另一台 ZooKeeper 主机。ZooKeeper 节点将它们的数据存储于一个分层的命名空间,非常类似于一个文件系统或一个前缀树结构。客户端可以在节点读写,从而以这种方式拥有一个共享的配置服务。更新是全序的。
+
+使用 ZooKeeper 的公司包括 Rackspace、雅虎和 eBay,以及类似于象 Solr 这样的开源企业级搜索系统。
+
+ZooKeeper Atomic Broadcast (ZAB)协议是一个类似 Paxos 的协议,但也有所不同。
+
+Zookeeper 一个应用场景就是服务发现,这在 Java 生态圈中得到了广泛的应用。Go 也可以使用 Zookeeper,尤其是在和 Java 项目混布的情况。
+
+## Etcd
+
+- Etcd: 通过 etcd 寻找服务。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ etcd_client "github.com/rpcxio/rpcx-etcd/client"
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ etcdAddr = flag.String("etcdAddr", "localhost:2379", "etcd address")
+ basePath = flag.String("base", "/rpcx_test", "prefix path")
+)
+
+func main() {
+ flag.Parse()
+ // // 更改服务发现为--客户端发现之--从etcd 发现
+ d, _ := etcd_client.NewEtcdDiscovery(*basePath, "Arith", []string{*etcdAddr}, false, nil)
+ xclient := client.NewXClient("Arith", client.Failover, client.RoundRobin, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Printf("failed to call: %v\n", err)
+ time.Sleep(5 * time.Second)
+ continue
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(5 * time.Second)
+ }
+}
+```
+
+## Consul
+
+- Consul: 通过 consul 寻找服务。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ cclient "github.com/rpcxio/rpcx-consul/client"
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ consulAddr = flag.String("consulAddr", "localhost:8500", "consul address")
+ basePath = flag.String("base", "/rpcx_test", "prefix path")
+)
+
+func main() {
+ flag.Parse()
+ // 更改服务发现为--客户端发现之--从consul 发现
+ d, _ := cclient.NewConsulDiscovery(*basePath, "Arith", []string{*consulAddr}, nil)
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Printf("ERROR failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ time.Sleep(1e9)
+ }
+
+}
+```
+
+## mDNS
+
+- mDNS: 通过 mDNS 寻找服务(支持本地服务发现)。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ basePath = flag.String("base", "/rpcx_test/Arith", "prefix path")
+)
+
+func main() {
+ flag.Parse()
+ // 更改服务发现为--客户端发现之--从mDNS发现
+ d, _ := client.NewMDNSDiscovery("Arith", 10*time.Second, 10*time.Second, "")
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+}
+```
+
+## In process
+
+- In process: 在同一进程寻找服务。客户端通过进程调用服务,不走 TCP 或 UDP,方便调试使用。
+
+```go
+func main() {
+ flag.Parse()
+
+ s := server.NewServer()
+ addRegistryPlugin(s)
+
+ s.RegisterName("Arith", new(example.Arith), "")
+
+ go func() {
+ s.Serve("tcp", *addr)
+ }()
+ // 更改服务发现为--客户端发现之--从process中发现
+ d := client.NewInprocessDiscovery()
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 100; i++ {
+
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ }
+}
+
+func addRegistryPlugin(s *server.Server) {
+
+ r := client.InprocessClient
+ s.Plugins.Add(r)
+}
+
+```
+
+# Part 5 失败模式
+
+在分布式架构中, 如 SOA 或者微服务架构,不能担保服务调用如所预想的一样好。有时候服务会宕机、网络被挖断、网络变慢等,所以需要容忍这些状况。
+
+rpcx 支持四种调用失败模式,用来处理服务调用失败后的处理逻辑, 可以在创建 XClient 的时候设置它。
+
+FailMode 的设置仅仅对同步调用有效(XClient.Call), 异步调用用,这个参数是无意义的。
+
+## Failfast
+
+**直接返回错误**
+在这种模式下, 一旦调用一个节点失败, rpcx 立即会返回错误。 注意这个错误不是业务上的 Error, 业务上服务端返回的 Error 应该正常返回给客户端,这里的错误可能是网络错误或者服务异常。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server1 address")
+ addr2 = flag.String("addr2", "tcp@localhost:9981", "server2 address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ option := client.DefaultOption
+ option.Retries = 10
+ xclient := client.NewXClient("Arith", client.Failfast, client.RandomSelect, d, option)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Printf("failed to call: %v", err)
+ } else {
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+
+ }
+}
+```
+
+## Failover
+
+**选择另外一个节点进行尝试,直到达到最大的尝试次数**
+
+在这种模式下, rpcx 如果遇到错误,它会尝试调用另外一个节点, 直到服务节点能正常返回信息,或者达到最大的重试次数。 重试测试 Retries 在参数 Option 中设置, 缺省设置为 3。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server1 address")
+ addr2 = flag.String("addr2", "tcp@localhost:9981", "server2 address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ option := client.DefaultOption
+ option.Retries = 10
+ xclient := client.NewXClient("Arith", client.Failover, client.RandomSelect, d, option)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Printf("failed to call: %v", err)
+ } else {
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+
+ time.Sleep(time.Second)
+ }
+}
+```
+
+## Failtry
+
+**选择该节点进行尝试,直到尝试的次数达到最大。**
+在这种模式下, rpcx 如果调用一个节点的服务出现错误, 它也会尝试,但是还是选择这个节点进行重试, 直到节点正常返回数据或者达到最大重试次数。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server1 address")
+ addr2 = flag.String("addr2", "tcp@localhost:9981", "server2 address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ option := client.DefaultOption
+ option.Retries = 10
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, option)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Printf("failed to call: %v", err)
+ } else {
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+
+ }
+}
+```
+
+## Failbackup
+
+**也是选择另外一个节点,只要节点中有一个调用成功,那么就算调用成功。**
+在这种模式下, 如果服务节点在一定的时间内不返回结果, rpcx 客户端会发送相同的请求到另外一个节点, 只要这两个节点有一个返回, rpcx 就算调用成功。
+
+这个设定的时间配置在 Option.BackupLatency 参数中。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr = flag.String("addr", "localhost:8972", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewPeer2PeerDiscovery("tcp@"+*addr, "")
+ xclient := client.NewXClient("Arith", client.Failbackup, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 1; i < 100; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ }
+
+}
+```
+
+# Part 6 Fork
+
+如果是在 failbackup 模式下,服务节点不能返回结果的时候,将会发送相同请求到另外一个节点,但是在 fork 下,会**向所有的服务节点发送请求**
+
+```go
+func main() {
+ // ...
+
+ xclient := client.NewXClient("Arith", client.Failover, client.RoundRobin, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+ reply := &example.Reply{}
+ err := xclient.Fork(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ time.Sleep(1e9)
+ }
+
+}
+```
+
+# Part 7 广播 broadcast
+
+Broadcast 是 XClient 的一个方法, 可以将一个请求发送到这个服务的所有节点。 如果所有的节点都正常返回,没有错误的话, Broadcast 将返回其中的一个节点的返回结果。 如果有节点返回错误的话,Broadcast 将返回这些错误信息中的一个。
+
+```go
+func main() {
+ //......
+
+ xclient := client.NewXClient("Arith", client.Failover, client.RoundRobin, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for {
+ reply := &example.Reply{}
+ err := xclient.Broadcast(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+ time.Sleep(1e9)
+ }
+
+}
+```
+
+# Part 8 路由
+
+实际的场景中,我们往往为同一个服务部署多个节点,便于大量并发的访问,节点的集合可能在同一个数据中心,也可能在多个数据中心。
+
+客户端该如何选择一个节点呢? rpcx 通过 Selector 来实现路由选择, 它就像一个负载均衡器,帮助选择出一个合适的节点。
+rpcx 提供了多个路由策略算法,可以在创建 XClient 来指定。
+注意,这里的路由是针对 ServicePath 和 ServiceMethod 的路由。
+
+## 随机
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server address")
+ addr2 = flag.String("addr2", "tcp@localhost:8973", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ xclient := client.NewXClient("Arith", client.Failtry, client.RandomSelect, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(time.Second)
+ }
+}
+```
+
+## 轮询
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server address")
+ addr2 = flag.String("addr2", "tcp@localhost:8973", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ xclient := client.NewXClient("Arith", client.Failtry, client.RoundRobin, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(time.Second)
+ }
+
+}
+```
+
+## WeightedRoundRobin
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server address")
+ addr2 = flag.String("addr2", "tcp@localhost:8973", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1, Value: "weight=7"},
+ {Key: *addr2, Value: "weight=3"},
+ })
+ xclient := client.NewXClient("Arith", client.Failtry, client.WeightedRoundRobin, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(time.Second)
+ }
+
+}
+```
+
+使用 Nginx 平滑的基于权重的轮询算法。
+比如如果三个节点 a、b、c 的权重是{ 5, 1, 1 }, 这个算法的调用顺序是 { a, a, b, a, c, a, a }, 相比较 { c, b, a, a, a, a, a }, 虽然权重都一样,但是前者更好,不至于在一段时间内将请求都发送给 a。
+上游:平滑加权循环平衡。
+对于像 { 5, 1, 1 } 这样的边缘情况权重,我们现在生成 { a, a, b, a, c, a, a }
+序列而不是先前产生的 { c, b, a, a, a, a, a }。
+
+算法执行 2 步:
+
+- 每个节点,用它们的当前值加上它们自己的权重。
+- 选择当前值最大的节点为选中节点,并把它的(只有被选中的节点才会减少)当前值减去所有节点的权重总和。
+
+在 { 5, 1, 1 } 权重的情况下,这给出了以下序列
+当前重量的:
+
+ 0 0 0(初始状态)
+
+ 5 1 1(已选) // -2 1 1 分别加 5 1 1
+ -2 1 1
+
+ 3 2 2(已选) // -4 2 2 分别加 5 1 1
+ -4 2 2
+
+ 1 3 3(选择 b) // 1 -4 3 分别加 5 1 1
+ 1 -4 3
+
+ 6 -3 4(一个选择) // -1 -3 4 分别加 5 1 1
+ -1 -3 4
+
+ 4 -2 5(选择 c) // 4 -2 -2 分别加 5 1 1
+ 4 -2 -2
+
+ 9 -1 -1(一个选择) // 2 -1 -1 分别加 5 1 1
+ 2 -1 -1
+
+ 7 0 0(一个选定的) //
+ 0 0 0
+
+```go
+package SmoothWeightRoundRobin
+
+import (
+ "strings"
+)
+
+type Node struct {
+ Name string
+ Current int
+ Weight int
+}
+
+// 一次负载均衡的选择 找到最大的节点,把最大的节点减去权重量和
+// 算法的核心是current 记录找到权重最大的节点,这个节点的权重-总权重
+// 然后在这个基础上的切片 他们的状态是 现在的权重状态+最初的权重状态
+func SmoothWeightRoundRobin(nodes []*Node) (best *Node) {
+ if len(nodes) == 0 {
+ return nil
+ }
+ weightnum := 0
+ for k, v := range nodes {
+ weightnum = weightnum + v.Weight
+ if k == 0 {
+ best = v
+ }
+ if v.Current > best.Current {
+ best = v
+ }
+ }
+ for _, v := range nodes {
+ if strings.Compare(v.Name, best.Name) == 0 {
+ v.Current = v.Current - weightnum + v.Weight
+ } else {
+ v.Current = v.Current + v.Weight
+ }
+ }
+
+ return best
+}
+
+```
+
+测试函数
+
+```go
+package SmoothWeightRoundRobin
+
+import (
+ "fmt"
+ "testing"
+)
+
+func TestSmoothWeight(t *testing.T) {
+ nodes := []*Node{
+ {"a", 0, 5},
+ {"b", 0, 1},
+ {"c", 0, 1},
+ }
+ for i := 0; i < 7; i++ {
+ best := SmoothWeightRoundRobin(nodes)
+ if best != nil {
+ fmt.Println(best.Name)
+ }
+ }
+
+}
+
+```
+
+## 网络质量优先
+
+首先客户端会基于 ping(ICMP)探测各个节点的网络质量,越短的 ping 时间,这个节点的权重也就越高。但是,我们也会保证网络较差的节点也有被调用的机会。
+
+假定 t 是 ping 的返回时间, 如果超过 1 秒基本就没有调用机会了:
+
+weight=191 if t <= 10
+weight=201 -t if 10 < t <=200
+weight=1 if 200 < t < 1000
+weight=0 if t >= 1000
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server address")
+ addr2 = flag.String("addr2", "tcp@baidu.com:8080", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1},
+ {Key: *addr2},
+ })
+ xclient := client.NewXClient("Arith", client.Failtry, client.WeightedICMP, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(time.Second)
+ }
+
+}
+```
+
+## 一致性哈希
+
+使用 JumpConsistentHash 选择节点, 相同的 servicePath, serviceMethod 和 参数会路由到同一个节点上。 JumpConsistentHash 是一个快速计算一致性哈希的算法,但是有一个缺陷是它不能删除节点,如果删除节点,路由就不准确了,所以在节点有变动的时候它会重新计算一致性哈希。
+
+```go
+package main
+
+import (
+ "context"
+ "flag"
+ "log"
+ "time"
+
+ example "github.com/rpcxio/rpcx-examples"
+ "github.com/smallnest/rpcx/client"
+)
+
+var (
+ addr1 = flag.String("addr1", "tcp@localhost:8972", "server address")
+ addr2 = flag.String("addr2", "tcp@localhost:8973", "server address")
+)
+
+func main() {
+ flag.Parse()
+
+ d, _ := client.NewMultipleServersDiscovery([]*client.KVPair{
+ {Key: *addr1, Value: ""},
+ {Key: *addr2, Value: ""},
+ })
+ xclient := client.NewXClient("Arith", client.Failtry, client.ConsistentHash, d, client.DefaultOption)
+ defer xclient.Close()
+
+ args := &example.Args{
+ A: 10,
+ B: 20,
+ }
+
+ for i := 0; i < 10; i++ {
+ reply := &example.Reply{}
+ err := xclient.Call(context.Background(), "Mul", args, reply)
+ if err != nil {
+ log.Fatalf("failed to call: %v", err)
+ }
+
+ log.Printf("%d * %d = %d", args.A, args.B, reply.C)
+
+ time.Sleep(time.Second)
+ }
+
+}
+```
+
+go 实现一致性哈希
+使用 hash 得到对应的服务器进行轮询,它符合以下特点:
+
+- 单调性
+- 平衡性
+- 分散性
+
+```go
+
+```
+
+## 地理位置优先
+
+如果我们希望的是客户端会优先选择离它最新的节点, 比如在同一个机房。 如果客户端在北京, 服务在上海和美国硅谷,那么我们优先选择上海的机房。
+
+它要求服务在注册的时候要设置它所在的地理经纬度。
+
+如果两个服务的节点的经纬度是一样的, rpcx 会随机选择一个。
+
+```go
+func (c *xClient) ConfigGeoSelector(latitude, longitude float64)
+```
+
+## 定制路由规则
+
+如果上面内置的路由规则不满足的需求,可以参考上面的路由器自定义自己的路由规则。
+
+曾经有一个网友提到, 如果调用参数的某个字段的值是特殊的值的话,他们会把请求路由到一个指定的机房。这样的需求就要求自己定义一个路由器,只需实现实现下面的接口:
+
+```go
+type Selector interface {
+ Select(ctx context.Context, servicePath, serviceMethod string, args interface{}) string
+ UpdateServer(servers map[string]string)
+}
+```
diff --git a/_posts/2022-11-09-test-markdown.md b/_posts/2022-11-09-test-markdown.md
new file mode 100644
index 000000000000..09dacf248324
--- /dev/null
+++ b/_posts/2022-11-09-test-markdown.md
@@ -0,0 +1,604 @@
+---
+layout: post
+title: Gin 中的设计模式?
+subtitle: 设计模式
+tags: [设计模式]
+---
+
+# Gin 中的设计模式
+
+> 项目链接 https://github.com/gin-gonic/gin
+
+### 1.责任链模式
+
+##### Example 1
+
+**定义:**
+
+> https://github.com/gin-gonic/gin/blob/aefae309a4fc197ce5d57cd8391562b6d2a63a95/gin.go#L47
+
+```go
+// HandlerFunc defines the handler used by gin middleware as return value.
+type HandlerFunc func(*Context)
+
+// HandlersChain defines a HandlerFunc slice.
+type HandlersChain []HandlerFunc
+```
+
+```go
+// Engine 是框架的实例,它包含复用器、中间件和配置设置。
+// 通过使用 New() 或 Default() 创建一个 Engine 实例
+
+type Engine struct {
+ RouterGroup
+ RedirectTrailingSlash bool
+ RedirectFixedPath bool
+ HandleMethodNotAllowed bool
+ ForwardedByClientIP bool
+ AppEngine bool
+ UseRawPath bool
+ RemoveExtraSlash bool
+ RemoteIPHeaders []string
+ TrustedPlatform string
+ MaxMultipartMemory int64
+ ContextWithFallback bool
+ delims render.Delims
+ secureJSONPrefix string
+ HTMLRender render.HTMLRender
+ FuncMap template.FuncMap
+ allNoRoute HandlersChain
+ allNoMethod HandlersChain
+ noRoute HandlersChain
+ noMethod HandlersChain
+ pool sync.Pool
+ trees methodTrees
+ maxParams uint16
+ maxSections uint16
+ trustedProxies []string
+ trustedCIDRs []*net.IPNet
+}
+
+```
+
+```go
+// Default returns an Engine instance with the Logger and Recovery middleware already attached.
+func Default() *Engine {
+ debugPrintWARNINGDefault()
+ engine := New()
+ engine.Use(Logger(), Recovery())
+ return engine
+}
+```
+
+```go
+func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes {
+ engine.RouterGroup.Use(middleware...)
+ engine.rebuild404Handlers()
+ engine.rebuild405Handlers()
+ return engine
+}
+```
+
+```go
+// Use adds middleware to the group, see example code in GitHub.
+func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes {
+ group.Handlers = append(group.Handlers, middleware...)
+ return group.returnObj()
+}
+```
+
+```go
+func (group *RouterGroup) returnObj() IRoutes {
+ if group.root {
+ return group.engine
+ }
+ return group
+}
+```
+
+### 2.迭代器模式
+
+```go
+// Routes returns a slice of registered routes, including some useful information, such as:
+// the http method, path and the handler name.
+func (engine *Engine) Routes() (routes RoutesInfo) {
+ for _, tree := range engine.trees {
+ routes = iterate("", tree.method, routes, tree.root)
+ }
+ return routes
+}
+
+func iterate(path, method string, routes RoutesInfo, root *node) RoutesInfo {
+ path += root.path
+ if len(root.handlers) > 0 {
+ handlerFunc := root.handlers.Last()
+ routes = append(routes, RouteInfo{
+ Method: method,
+ Path: path,
+ Handler: nameOfFunction(handlerFunc),
+ HandlerFunc: handlerFunc,
+ })
+ }
+ for _, child := range root.children {
+ routes = iterate(path, method, routes, child)
+ }
+ return routes
+}
+```
+
+### 3.单例模式
+
+##### Example 1
+
+**定义且初始化:**
+
+> https://github.com/gin-gonic/gin/blob/master/mode.go
+
+```
+// DefaultWriter 是 Gin 用于调试输出的默认 io.Writer // 中间件输出,如 Logger() 或 Recovery()。
+var DefaultWriter io.Writer = os.Stdout
+```
+
+**使用:**
+
+> https://github.com/gin-gonic/gin/blob/master/logger.go
+
+```go
+// Logger instances a Logger middleware that will write the logs to gin.DefaultWriter.
+// By default, gin.DefaultWriter = os.Stdout.
+func Logger() HandlerFunc {
+ return LoggerWithConfig(LoggerConfig{})
+}
+
+// LoggerWithConfig instance a Logger middleware with config.
+func LoggerWithConfig(conf LoggerConfig) HandlerFunc {
+ formatter := conf.Formatter
+ if formatter == nil {
+ formatter = defaultLogFormatter
+ }
+
+ out := conf.Output
+ if out == nil {
+
+ //******************************
+ out = DefaultWriter
+ //********************************
+ }
+
+ notlogged := conf.SkipPaths
+
+ isTerm := true
+
+ if w, ok := out.(*os.File); !ok || os.Getenv("TERM") == "dumb" ||
+ (!isatty.IsTerminal(w.Fd()) && !isatty.IsCygwinTerminal(w.Fd())) {
+ isTerm = false
+ }
+
+ var skip map[string]struct{}
+
+ if length := len(notlogged); length > 0 {
+ skip = make(map[string]struct{}, length)
+
+ for _, path := range notlogged {
+ skip[path] = struct{}{}
+ }
+ }
+
+ return func(c *Context) {
+ // Start timer
+ start := time.Now()
+ path := c.Request.URL.Path
+ raw := c.Request.URL.RawQuery
+
+ // Process request
+ c.Next()
+
+ // Log only when path is not being skipped
+ if _, ok := skip[path]; !ok {
+ param := LogFormatterParams{
+ Request: c.Request,
+ isTerm: isTerm,
+ Keys: c.Keys,
+ }
+
+ // Stop timer
+ param.TimeStamp = time.Now()
+ param.Latency = param.TimeStamp.Sub(start)
+
+ param.ClientIP = c.ClientIP()
+ param.Method = c.Request.Method
+ param.StatusCode = c.Writer.Status()
+ param.ErrorMessage = c.Errors.ByType(ErrorTypePrivate).String()
+
+ param.BodySize = c.Writer.Size()
+
+ if raw != "" {
+ path = path + "?" + raw
+ }
+
+ param.Path = path
+
+ fmt.Fprint(out, formatter(param))
+ }
+ }
+}
+```
+
+##### Example 2
+
+**定义且初始化:**
+
+> https://github.com/gin-gonic/gin/blob/master/mode.go
+
+```go
+// DefaultErrorWriter 是 Gin 用来调试错误的默认 io.Writer
+var DefaultErrorWriter io.Writer = os.Stderr
+```
+
+**使用:**
+
+> https://github.com/gin-gonic/gin/blob/master/recovery.go
+
+```go
+// Recovery returns a middleware that recovers from any panics and writes a 500 if there was one.
+func Recovery() HandlerFunc {
+ return RecoveryWithWriter(DefaultErrorWriter)
+}
+
+// CustomRecovery returns a middleware that recovers from any panics and calls the provided handle func to handle it.
+func CustomRecovery(handle RecoveryFunc) HandlerFunc {
+ return RecoveryWithWriter(DefaultErrorWriter, handle)
+}
+
+// RecoveryWithWriter returns a middleware for a given writer that recovers from any panics and writes a 500 if there was one.
+func RecoveryWithWriter(out io.Writer, recovery ...RecoveryFunc) HandlerFunc {
+ if len(recovery) > 0 {
+ return CustomRecoveryWithWriter(out, recovery[0])
+ }
+ return CustomRecoveryWithWriter(out, defaultHandleRecovery)
+}
+```
+
+##### Example 3
+
+**定义:**
+
+> https://github.com/gin-gonic/gin/blob/master/mode.go
+
+```go
+var (
+ ginMode = debugCode
+ modeName = DebugMode
+)
+```
+
+**初始化:**
+
+> https://github.com/gin-gonic/gin/blob/master/mode.go
+
+```go
+// SetMode sets gin mode according to input string.
+func SetMode(value string) {
+ if value == "" {
+ if flag.Lookup("test.v") != nil {
+ value = TestMode
+ } else {
+ value = DebugMode
+ }
+ }
+
+ switch value {
+ case DebugMode:
+ ginMode = debugCode
+ case ReleaseMode:
+ ginMode = releaseCode
+ case TestMode:
+ ginMode = testCode
+ default:
+ panic("gin mode unknown: " + value + " (available mode: debug release test)")
+ }
+
+ modeName = value
+}
+```
+
+**使用:**
+
+```go
+// IsDebugging returns true if the framework is running in debug mode.
+// Use SetMode(gin.ReleaseMode) to disable debug mode.
+func IsDebugging() bool {
+ return ginMode == debugCode
+}
+```
+
+##### Example 4
+
+**定义且初始化:**
+
+> https://github.com/gin-gonic/gin/blob/master/internal/json/jsoniter.go
+
+```go
+var (
+ // Marshal is exported by gin/json package.
+ Marshal = json.Marshal
+ // Unmarshal is exported by gin/json package.
+ Unmarshal = json.Unmarshal
+ // MarshalIndent is exported by gin/json package.
+ MarshalIndent = json.MarshalIndent
+ // NewDecoder is exported by gin/json package.
+ NewDecoder = json.NewDecoder
+ // NewEncoder is exported by gin/json package.
+ NewEncoder = json.NewEncoder
+)
+```
+
+**使用:**
+
+> https://github.com/gin-gonic/gin/blob/master/errors.go
+
+```go
+import (
+ "fmt"
+ "reflect"
+ "strings"
+ // 在这里导入定义的单例
+ "github.com/gin-gonic/gin/internal/json"
+)
+// Error represents a error's specification.
+type Error struct {
+ Err error
+ Type ErrorType
+ Meta any
+}
+
+// MarshalJSON implements the json.Marshaller interface.
+func (msg *Error) MarshalJSON() ([]byte, error) {
+ return json.Marshal(msg.JSON())
+}
+
+type errorMsgs []*Error
+
+// MarshalJSON implements the json.Marshaller interface.
+func (a errorMsgs) MarshalJSON() ([]byte, error) {
+ return json.Marshal(a.JSON())
+}
+```
+
+##### Example 5
+
+**定义:**(典型的单例模式,且高并发安全)
+
+> https://github.com/gin-gonic/gin/blob/master/ginS/gins.go
+
+```go
+package ginS
+
+import (
+ "html/template"
+ "net/http"
+ "sync"
+ "github.com/gin-gonic/gin"
+)
+var once sync.Once
+var internalEngine *gin.Engine
+```
+
+**初始化:**
+
+> https://github.com/gin-gonic/gin/blob/master/ginS/gins.go
+
+```go
+// 提供给一个方法供给外界调用,但实际都是得到的同一个变量
+func engine() *gin.Engine {
+ once.Do(func() {
+ internalEngine = gin.Default()
+ })
+ return internalEngine
+}
+```
+
+**使用:**
+
+> https://github.com/gin-gonic/gin/blob/master/ginS/gins.go
+
+```go
+// 在这里不同的函数调用engine()方法,但始终得到的是同一个变量 internalEngine
+// LoadHTMLGlob is a wrapper for Engine.LoadHTMLGlob.
+func LoadHTMLGlob(pattern string) {
+ // 本质是调用internalEngine.LoadHTMLGlob(pattern)
+ engine().LoadHTMLGlob(pattern)
+}
+
+// LoadHTMLFiles is a wrapper for Engine.LoadHTMLFiles.
+func LoadHTMLFiles(files ...string) {
+ // 本质是调用internalEngine.LoadHTMLFiles(files...)
+ engine().LoadHTMLFiles(files...)
+}
+
+// SetHTMLTemplate is a wrapper for Engine.SetHTMLTemplate.
+func SetHTMLTemplate(templ *template.Template) {
+ // 本质是调用internalEngine.SetHTMLTemplate(templ)
+ engine().SetHTMLTemplate(templ)
+}
+
+// NoRoute adds handlers for NoRoute. It returns a 404 code by default.
+func NoRoute(handlers ...gin.HandlerFunc) {
+ // 本质是调用internalEngine.NoRoute(handlers...)
+ engine().NoRoute(handlers...)
+}
+
+// NoMethod is a wrapper for Engine.NoMethod.
+func NoMethod(handlers ...gin.HandlerFunc) {
+ // 本质是调用internalEngine.NoMethod(handlers...)
+ engine().NoMethod(handlers...)
+}
+
+// Group creates a new router group. You should add all the routes that have common middlewares or the same path prefix.
+// For example, all the routes that use a common middleware for authorization could be grouped.
+func Group(relativePath string, handlers ...gin.HandlerFunc) *gin.RouterGroup {
+ // 本质是调用internalEngine.Group(relativePath, handlers...)
+ return engine().Group(relativePath, handlers...)
+}
+```
+
+### 4.装饰模式
+
+##### Example 1
+
+**定义:**
+
+> https://github.com/gin-gonic/gin/blob/master/ginS/gins.go
+>
+> https://github.com/gin-gonic/gin/blob/master/gin.go
+
+```go
+// LoadHTMLGlob is a wrapper for Engine.LoadHTMLGlob.
+// 装饰器
+func LoadHTMLGlob(pattern string) {
+ engine().LoadHTMLGlob(pattern)
+}
+
+// LoadHTMLGlob loads HTML files identified by glob pattern
+// and associates the result with HTML renderer.
+// 被装饰器装饰的方法
+func (engine *Engine) LoadHTMLGlob(pattern string) {
+ left := engine.delims.Left
+ right := engine.delims.Right
+ templ := template.Must(template.New("").Delims(left, right).Funcs(engine.FuncMap).ParseGlob(pattern))
+
+ if IsDebugging() {
+ debugPrintLoadTemplate(templ)
+ engine.HTMLRender = render.HTMLDebug{Glob: pattern, FuncMap: engine.FuncMap, Delims: engine.delims}
+ return
+ }
+
+ engine.SetHTMLTemplate(templ)
+}
+
+
+
+// LoadHTMLFiles is a wrapper for Engine.LoadHTMLFiles.
+// 装饰器
+func LoadHTMLFiles(files ...string) {
+ engine().LoadHTMLFiles(files...)
+}
+
+// LoadHTMLFiles loads a slice of HTML files
+// and associates the result with HTML renderer.
+// 被装饰器装饰的方法
+func (engine *Engine) LoadHTMLFiles(files ...string) {
+ if IsDebugging() {
+ engine.HTMLRender = render.HTMLDebug{Files: files, FuncMap: engine.FuncMap, Delims: engine.delims}
+ return
+ }
+
+ templ := template.Must(template.New("").Delims(engine.delims.Left, engine.delims.Right).Funcs(engine.FuncMap).ParseFiles(files...))
+ engine.SetHTMLTemplate(templ)
+}
+
+
+
+// SetHTMLTemplate is a wrapper for Engine.SetHTMLTemplate.
+// 装饰器
+func SetHTMLTemplate(templ *template.Template) {
+ engine().SetHTMLTemplate(templ)
+}
+
+// SetHTMLTemplate associate a template with HTML renderer.
+// 被装饰器装饰的方法
+func (engine *Engine) SetHTMLTemplate(templ *template.Template) {
+ if len(engine.trees) > 0 {
+ debugPrintWARNINGSetHTMLTemplate()
+ }
+
+ engine.HTMLRender = render.HTMLProduction{Template: templ.Funcs(engine.FuncMap)}
+}
+
+
+
+// NoMethod is a wrapper for Engine.NoMethod.
+// 装饰器
+func NoMethod(handlers ...gin.HandlerFunc) {
+ engine().NoMethod(handlers...)
+}
+
+// NoMethod sets the handlers called when Engine.HandleMethodNotAllowed = true.
+// 被装饰器装饰的方法
+func (engine *Engine) NoMethod(handlers ...HandlerFunc) {
+ engine.noMethod = handlers
+ engine.rebuild405Handlers()
+}
+
+
+```
+
+### 5.外观模式
+
+##### Example 1
+
+**定义:**
+
+> https://github.com/gin-gonic/gin/blob/master/internal/bytesconv/bytesconv.go
+
+```go
+
+package bytesconv
+
+import (
+ "unsafe"
+)
+
+// StringToBytes converts string to byte slice without a memory allocation.
+func StringToBytes(s string) []byte {
+ return *(*[]byte)(unsafe.Pointer(
+ &struct {
+ string
+ Cap int
+ }{s, len(s)},
+ ))
+}
+
+// BytesToString converts byte slice to string without a memory allocation.
+func BytesToString(b []byte) string {
+ return *(*string)(unsafe.Pointer(&b))
+}
+```
+
+##### Example 2
+
+> https://github.com/gin-gonic/gin/blob/master/render/msgpack.go
+
+**定义:**
+
+```go
+package render
+
+import (
+ "net/http"
+ // 这是一个高性能、功能丰富的惯用 Go 1.4+ 编解码器/编码库,适用于二进制和文本格式:binc、msgpack、cbor、json 和 simple。在这里是使用了其他的包并进行了封装
+ "github.com/ugorji/go/codec"
+)
+// WriteMsgPack writes MsgPack ContentType and encodes the given interface object.
+func WriteMsgPack(w http.ResponseWriter, obj any) error {
+ writeContentType(w, msgpackContentType)
+ var mh codec.MsgpackHandle
+ return codec.NewEncoder(w, &mh).Encode(obj)
+}
+
+```
+
+**使用:**
+
+```go
+// WriteContentType (MsgPack) writes MsgPack ContentType.
+func (r MsgPack) WriteContentType(w http.ResponseWriter) {
+ writeContentType(w, msgpackContentType)
+}
+
+// Render (MsgPack) encodes the given interface object and writes data with custom ContentType.
+func (r MsgPack) Render(w http.ResponseWriter) error {
+ return WriteMsgPack(w, r.Data)
+}
+
+```
diff --git a/_posts/2022-11-11-test-markdown.md b/_posts/2022-11-11-test-markdown.md
new file mode 100644
index 000000000000..8d76b5b4d54a
--- /dev/null
+++ b/_posts/2022-11-11-test-markdown.md
@@ -0,0 +1,216 @@
+---
+layout: post
+title: 虚拟内存管理?
+subtitle: 进程拥有独立的虚拟地址,由操作系统负责把虚拟地址映射到真实的物理地址上
+tags: [操作系统]
+---
+
+## 虚拟内存管理
+
+## 引⽤了绝对物理地址会带来冲突
+
+单⽚机是没有操作系统的,所以每次写完代码,都需要借助⼯具把程序烧录进去,这样程序才能跑起来。另外,单⽚机的 CPU 是直接操作内存的「物理地址」。在这种情况下,要想在内存中同时运⾏两个程序是不可能的。如果第⼀个程序在 2000 的位置写⼊⼀个新的值,将会擦掉第⼆个程序存放在相同位置上的所有内容,所以同时运⾏两个程序是根本⾏不通的,这两个程序会⽴刻崩溃。
+
+### 操作系统是如何解决这个问题呢?
+
+**进程拥有独立的虚拟地址,由操作系统负责把虚拟地址映射到真实的物理地址上**
+
+我们可以把进程所使⽤的地址「隔离」开来,即让操作系统为每个进程分配独⽴的⼀套「虚拟地址」,⼈⼈都有,⼤家⾃⼰玩⾃⼰的地址就⾏,互不⼲涉。但是有个前提每个进程都不能访问物理地址,⾄于虚拟地址最终怎么落到物理内存⾥,对进程来说是透明的,操作系统已经把这些都安排的明明⽩⽩了。
+我们程序所使⽤的内存地址叫做虚拟内存地址(Virtual Memory Address)
+实际存在硬件⾥⾯的空间地址叫物理内存地址(Physical Memory Address)
+
+**操作系统通过 MMU 把虚拟地址转化为实际的物理地址。**
+操作系统引⼊了虚拟内存,进程持有的虚拟地址会通过 CPU 芯⽚中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存,如下图所示:
+
+### 操作系统是如何管理虚拟地址与物理地址之间的关系?
+
+#### Memory Segmentation 内存分段下的映射
+
+分段机制下,虚拟地址和物理地址是如何映射的?
+程序是由若⼲个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就⽤分段(Segmentation)的形式把这些段分离出来。
+分段机制下的虚拟地址由两部分组成,段选择⼦和段内偏移量。
+
+- **段选择⼦就保存在段寄存器⾥⾯**。段选择⼦⾥⾯最重要的是段号,⽤作段表的索引。段表⾥⾯保存的是这个段的基地址、段的界限和特权等级等。
+- **虚拟地址中的段内偏移量位于 0 和段界限之间**,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
+
+具体的做法:
+每个虚拟地址,都划分为段选择和段偏移两部分,给出每段的大小,1kb =1024 个字节 1024 个字节的地址范围 1024 转化为二进制 2^10 (2 的 10 次方)(1 00000 00000)
+
+所以需要 11 位 那么一个两个字节的地址,可以 00000 00000000000 段选择子 5 位, 偏移 11 位 ,根据段选择子找到物理段号,根据物理段号可以找到段基地址 ,段偏移不变。
+
+ 逻辑段号 段基地址 段界限
+ 0 1000 1000
+ 1 6000 500
+ 2 3000 3000
+ 3 7000 1000
+
+值得注意的是:虚拟地址也要按照程序的性质分段 ,虚拟地址也是按照不规则的段大小来分段的。 比如代码段大小是 1000 数据段大小 500 堆大小是 3000 栈大小 1000 每个程序分到的段数是固定的。如果是分页,每个程序的分到的总页数不定的。
+
+**逻辑段号 ---物理段号---物理段号---物理段号对应的基地址+逻辑段偏移**
+**逻辑页号 ---物理页号---物理页号---物理页号\*页大小+逻辑段偏移**
+分段的办法很好,解决了程序本身不需要关⼼具体的物理内存地址的问题,但它也有⼀些不⾜之处:
+
+- 内存碎片
+- 内存交换效率低
+
+分段为什么会产⽣内存碎⽚的问题?
+
+游戏占⽤了 512MB 内存、浏览器占⽤了 128MB 内存、⾳乐占⽤了 256 MB 内存
+这个时候,如果我们关闭了浏览器,则空闲内存还有 1024 - 512 - 256 = 256MB。如果这个 256MB 不是连续的,被分成了两段 128 MB 内存,这就会导致没有空间再打开⼀个 200MB 的程序。
+外部内存碎⽚,也就是产⽣了多个不连续的⼩物理内存,导致新的程序⽆法被装载;
+内部内存碎⽚,程序所有的内存都被装载到了物理内存,但是这个程序有部分的内存可能并不是很常使⽤,这也会导致内存的浪费;
+
+**解决外部内存碎⽚**的问题就是**内存交换**。可以把⾳乐程序占⽤的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存⾥。不过再读回的时候,我们不能装载回原来的位置,⽽是紧紧跟着那已经被占⽤了的 512MB 内存后⾯。这样就能空缺出连续的 256MB 空间,于是新的 200MB 程序就可以装载进来。这个内存交换空间,在 Linux 系统⾥,也就是我们常看到的 Swap 空间,这块空间是从硬盘划分出来的,⽤于内存与硬盘的空间交换。
+
+分段为什么会导致内存交换效率低的问题?
+分段的方式产生内存碎片,因为有内存碎片,需要 Swap ,Swap 频繁的内外存交换。
+对于多进程的系统来说,⽤分段的⽅式,内存碎⽚是很容易产⽣的,产⽣了内存碎⽚,那不得不重新 Swap 内存区域,这个过程会产⽣性能瓶颈。
+为了解决内存分段的**内存碎⽚**和**内存交换效率低**的问题,就出现了内存分⻚
+
+#### Memory Segmentation 内存分页下的映射
+
+分段的好处就是能产⽣连续的内存空间,但是会出现内存碎⽚和内存交换的空间太⼤的问题。要解决这些问题,那么就要想出能少出现⼀些内存碎⽚的办法。另外,当需要进⾏内存交换的时候,让需要交换写⼊或者从磁盘装载的数据更少⼀点,这样就可以解决问题了。这个办法,也就是内存分⻚(Paging)。分⻚是把整个**虚拟和物理内存**空间切成⼀段段**固定尺⼨**的⼤⼩。这样⼀个连续并且尺⼨固定的内存空间,我们叫⻚(Page)。在 Linux 下,每⼀⻚的⼤⼩为 4KB 。
+内存分页的关键词:“固定的页面大小,不固定的页面个数 ”,那么某个程序如果产生了逻辑内存碎片,那么一定会产生物理内存碎片,但是这个物理内存碎片不会超过一个页面的大小。而且由逻辑地址切割得到的不同的页面,可以映射到不同的物理页面。
+在 Linux 下,每⼀⻚的⼤⼩为 4KB(2^12 次方)也就是页偏移需要 13 个位置(1 0000 0000 0000 ),还有三个位置,111 表示可以分的最大页数不可以超过这个数值。 64 位系统下面 2^(64-13) 表示可以划分的最大页数。
+
+**分页维护可变长的页表,分段维护固定长的页表**
+
+#### MMU 使用页表来把虚拟地址转化为实际的物理地址
+
+⻚表是存储在内存⾥的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的⼯作。
+
+#### 分⻚是怎么解决分段的内存碎⽚、内存交换效率低的问题?
+
+- 内存释放以页为单位
+ 由于内存空间都是预先划分好的,也就不会像分段会产⽣间隙⾮常⼩的内存,这正是分段会产⽣内存碎⽚的原因。⽽采⽤了分⻚,那么释放的内存都是以⻚为单位释放的,也就不会产⽣⽆法给进程使⽤的⼩内存。
+- 释放(还出)不经常使用的内存页面
+ 操作系统会把其他正在运⾏的进程中的「最近没被使⽤」的内存⻚⾯给释放掉。也就是暂时写在硬盘上,称为换出(Swap Out)⼀旦需要的时候,再加载进来,称为换⼊(Swap In)。所以,⼀次性写⼊磁盘的也只有少数的⼀个⻚或者⼏个⻚,不会花太多时间,内存交换的效率就相对⽐较⾼。
+- 换出和换入磁盘每次也仅仅只是几页(Linux 下,每⼀⻚的⼤⼩为 4KB(2^12 次方))
+
+在分⻚机制下,虚拟地址分为两部分,⻚号和⻚内偏移。⻚号作为⻚表的索引,⻚表包含物理⻚每⻚所在物理内存的基地址,这个基地址与⻚内偏移的组合就形成了物理内存地址,⻅下图。
+
+ 逻辑页号 物理页号 物理的基地址
+ 0 1000 1000
+ 1 6000 500
+ 2 3000 3000
+ 3 7000 1000
+
+总结⼀下,对于⼀个内存地址转换,其实就是这样三个步骤:
+
+- 把虚拟地址切分成页号 和逻辑偏移量
+- 逻辑页号- 物理页号- 物理的基础地址+逻辑偏移
+
+#### 分⻚有什么缺陷吗?
+
+- **每一页的内存很小,导致虚拟内存切割后得到的页数很多,页数很多,那么需要更多的字节来存储,每一个页都需要这个一个存储的字节,导致需要很多字节来存储。**
+
+**每个进程实际划分得到的页数**
+**整个虚拟地址对应的页数 需要 x 字节来存储,比如 4GB 被划分为 2 ^20 次方个页,0 ~ 2^20 次方这个需要 4 个字节来存储**
+**每个虚拟页都需要这 4 个字节**
+**实际进程的页数 乘以 4 乘以 实际进程得到的页数=总的需要的字节**
+因为操作系统是可以同时运⾏⾮常多的进程的,每页面的大小又很小那这不就意味着⻚表会⾮常的庞⼤。在 32 位的环境下,虚拟地址空间共有 4GB,假设⼀个⻚的⼤⼩是 4KB(2^12),那么就需要⼤约 100 万 (2^20) 个⻚,每个「⻚表项」需要 4 个字节⼤⼩来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储⻚表。这 4MB ⼤⼩的⻚表,看起来也不是很⼤。但是要知道每个进程都是有⾃⼰的虚拟地址空间的,也就说都有⾃⼰的⻚表那么, 100 个进程的话,就需要 400MB 的内存来存储⻚表,这是⾮常⼤的内存了,更别说 64 位的环境了。
+
+我们把这个 100 多万个「⻚表项」的单级⻚表再分⻚,将⻚表(⼀级⻚表)分为 1024 个⻚表(⼆级⻚表),每个表(⼆级⻚表)中包含 1024 个「⻚表项」,形成⼆级分⻚。如下图
+拿出 10 位 (这 10 位足够代表 1024 个页面) 再拿出 10 位(这 10 也足够代表 1024 个页面) 那么如何巧用这两张表表示更大的页数量
+
+分了⼆级表,映射 4GB 地址空间就需要 4KB(⼀级⻚表)+ 4MB(⼆级⻚表)的内存,这样占⽤空间不是更⼤了吗
+其实我们应该换个⻆度来看问题,还记得计算机组成原理⾥⾯⽆处不在的局部性原理么?
+每个进程都有 4GB 的虚拟地址空间,⽽显然对于⼤多数程序来说,其使⽤到的空间远未达到 4GB,因为会存在部分对应的⻚表项都是空的,根本没有分配,对于已分配的⻚表项,如果存在最近⼀定时间未访问的⻚表,在物理内存紧张的情况下,操作系统会将⻚⾯换出到硬盘,也就是说不会占⽤物理内存。如果使⽤了⼆级分⻚,⼀级⻚表就可以覆盖整个 4GB 虚拟地址空间,但如果某个⼀级⻚表的⻚表项没有被⽤到,也就不需要创建这个⻚表项对应的⼆级⻚表了,即可以在需要时才创建⼆级⻚表。做个简单的计算,假设只有 20% 的⼀级⻚表项被⽤到了,那么⻚表占⽤的内存空间就只有 4KB(⼀级⻚表) + 20% \* 4MB(⼆级⻚表)= 0.804MB ,这对⽐单级⻚表的 4MB 是不是⼀个巨⼤的节约?
+那么为什么不分级的⻚表就做不到这样节约内存呢?
+我们从⻚表的性质来看,保存在内存中的⻚表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在⻚表中找不到对应的⻚表
+项,计算机系统就不能⼯作了。所以⻚表⼀定要覆盖全部虚拟地址空间,不分级的⻚表就需要有 100 多万个⻚表项来映射,⽽⼆级分⻚则只需要 1024 个⻚表项(此时⼀级⻚表覆盖到了全部虚拟地址空间,⼆级⻚表在需要时创建)。
+我们把⼆级分⻚再推⼴到多级⻚表,就会发现⻚表占⽤的内存空间更少了,这⼀切都要归功
+于对局部性原理的充分应⽤。对于 64 位的系统,两级分⻚肯定不够了,就变成了四级⽬录,分别是:
+全局⻚⽬录项 PGD(Page Global Directory);
+上层⻚⽬录项 PUD(Page Upper Directory);
+中间⻚⽬录项 PMD(Page Middle Directory);
+⻚表项 PTE(Page Table Entry)
+
+**TLB** CPU 里面的缓存
+**MMU 通过 TLB(一个在内存中间的缓存)来把逻辑地址转化为物理地址**
+多级⻚表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了⼏道转换的⼯序,这显然就降低了这俩地址转换的速度,也就是带来了时间上的开销。程序是有局部性的,即在⼀段时间内,整个程序的执⾏仅限于程序中的某⼀部分。相应地,
+执⾏所访问的存储空间也局限于某个内存区域.我们就可以利⽤这⼀特性,把最常访问的⼏个⻚表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯⽚中,加⼊了⼀个专⻔存放程序最常访问的⻚表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为⻚表缓存、转址旁路缓存、快表等。
+在 CPU 芯⽚⾥⾯,封装了内存管理单元(Memory Management Unit)芯⽚,它⽤来完成地
+址转换和 TLB 的访问与交互。有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的⻚表。TLB 的命中率其实是很⾼的,因为程序最常访问的⻚就那么⼏个。
+
+段⻚式内存管理实现的⽅式:
+
+- 先将程序划分为多个有逻辑意义的段,也就是前⾯提到的分段机制;
+- 接着再把每个段划分为多个⻚,也就是对分段划分出来的连续空间,再划分固定⼤⼩的⻚;
+ 这样,地址结构就由段号、段内⻚号和⻚内位移三部分组成。⽤于段⻚式地址变换的数据结构是每⼀个程序⼀张段表,每个段⼜建⽴⼀张⻚表,段表中的地址是⻚表的起始地址,⽽⻚表中的地址则为某⻚的物理⻚号,如图所示:
+ **段⻚式内存管理**
+ 内存分段和内存分⻚并不是对⽴的,它们是可以组合起来在同⼀个系统中使⽤的,那么组合起来后,通常称为段⻚式内存管理
+
+段⻚式地址变换中要得到物理地址须经过三次内存访问:
+
+- 第⼀次访问段表,得到⻚表起始地址;
+- 第⼆次访问⻚表,得到物理⻚号;
+- 第三次将物理⻚号与⻚内位移组合,得到物理地址。
+ 可⽤软、硬件相结合的⽅法实现段⻚式地址变换,这样虽然增加了硬件成本和系统开销,但提⾼了内存的利⽤率。
+
+### Linux 内存管理
+
+那么,Linux 操作系统采⽤了哪种⽅式来管理内存呢?
+在回答这个问题前,我们得先看看 Intel 处理器的发展历史。
+早期 Intel 的处理器从 80286 开始使⽤的是段式内存管理。但是很快发现,光有段式内存管理⽽没有⻚式内存管理是不够的,这会使它的 X86 系列会失去市场的竞争⼒。因此,在不久以后的 80386 中就实现了对⻚式内存管理。也就是说,80386 除了完成并完善从 80286 开始的段式内存管理的同时还实现了⻚式内存管理。但是这个 80386 的⻚式内存管理设计时,没有绕开段式内存管理,⽽是建⽴在段式内存管理的基础上,这就意味着,⻚式内存管理的作⽤是在由**段式内存管理所映射⽽成的地址上再加上⼀层地址映射。**
+由于此时由段式内存管理映射⽽成的地址不再是“物理地址”了,Intel 就称之为“线性地址”(也称虚拟地址)。于是,段式内存管理先将逻辑地址映射成线性地址,然后再由⻚式内存管理将线性地址映射成物理地址。
+
+这⾥说明下逻辑地址和线性地址:
+
+- 程序所使⽤的地址,通常是没被段式内存管理映射的地址,称为逻辑地址;
+- 通过段式内存管理映射的地址,称为线性地址,也叫虚拟地址;
+- 逻辑地址是「段式内存管理」转换前的地址
+- 线性地址则是「⻚式内存管理」转换前的地址。
+
+Linux 内存主要采⽤的是⻚式内存管理,但同时也不可避免地涉及了段机制。
+这主要是上⾯ Intel 处理器发展历史导致的,因为 Intel X86 CPU ⼀律对程序中使⽤的地址先进⾏段式映射,然后才能进⾏⻚式映射。既然 CPU 的硬件结构是这样,Linux 内核也只好服从 Intel 的选择。
+但是事实上,Linux 内核所采取的办法是使段式映射的过程实际上不起什么作⽤。也就是说,“上有政策,下有对策”,若惹不起就躲着⾛.Linux 系统中的每个段都是从 0 地址开始的整个 4GB 虚拟空间(32 位环境下),也就是所有的段的起始地址都是⼀样的。这意味着,Linux 系统中的代码,包括操作系统本身的代码和应⽤程序代码,所⾯对的地址空间都是线性地址空间(虚拟地址),这种做法相当于屏蔽了处理器中的逻辑地址概念,段只被⽤于访问控制和内存保护。
+
+在 Linux 操作系统中,虚拟地址空间的内部⼜被分为内核空间和⽤户空间两部分,不同位数的系统,地址空间的范围也不同。⽐如最常⻅的 32 位和 64 位系统,
+32 位系统的内核空间占⽤ 1G ,位于最⾼处,剩下的 3G 是⽤户空间;
+64 位系统的内核空间和⽤户空间都是 128T ,分别占据整个内存空间的最⾼和最低处,剩下的中间部分是未定义的。再来说说,内核空间与⽤户空间的区别:
+
+- 进程在⽤户态时,只能访问⽤户空间内存;
+- 只有进⼊内核态后,才可以访问内核空间的内存;
+ 虽然每个进程都各⾃有独⽴的虚拟内存,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很⽅便地访问内核空间内存。
+
+⽤户空间内存,从低到⾼分别是 7 种不同的内存段:
+
+- 程序⽂件段,包括⼆进制可执⾏代码;
+- 已初始化数据段,包括静态常量;
+- 未初始化数据段,包括未初始化的静态变量;
+- 堆段,包括动态分配的内存,从低地址开始向上增⻓;
+- ⽂件映射段,包括动态库、共享内存等,从低地址开始向上增⻓(跟硬件和内核版本有关);
+- 栈段,包括局部变量和函数调⽤的上下⽂等。栈的⼤⼩是固定的,⼀般是 8 MB 。当然系统也提供了参数,以便我们⾃定义⼤⼩;
+ 在这 7 个内存段中,堆和⽂件映射段的内存是动态分配的。⽐如说,使⽤ C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和⽂件映射段动态分配内存。
+
+### 一条 Load 指令的执行过程:
+
+1. 在 CPU ⾥访问⼀条 Load M 指令,然后 CPU 会去找 M 所对应的⻚表项。
+2. 如果该⻚表项的状态位是「有效的」,那 CPU 就可以直接去访问物理内存了,如果状态位是「⽆效的」,则 CPU 则会发送缺⻚中断请求。
+3. 操作系统收到了缺⻚中断,则会执⾏缺⻚中断处理函数,先会查找该⻚⾯在磁盘中的⻚⾯的位置。
+4. 找到磁盘中对应的⻚⾯后,需要把该⻚⾯换⼊到物理内存中,但是在换⼊前,需要在物理内存中找空闲⻚,如果找到空闲⻚,就把⻚⾯换⼊到物理内存中。
+5. ⻚⾯从磁盘换⼊到物理内存完成后,则把⻚表项中的状态位修改为「有效的」。
+6. 最后,CPU 重新执⾏导致缺⻚异常的指令。
+ ⻚表项通常有如下图的字段:
+ 页号 物理页号 状态位 访问字段 修改位 硬盘地址
+
+- 状态位:⽤于表示该⻚是否有效,也就是说是否在物理内存中,供程序访问时参考
+- ⽤于记录该⻚在⼀段时间被访问的次数,供⻚⾯置换算法选择出⻚⾯时参考
+- 修改位:表示该⻚在调⼊内存后是否有被修改过,由于内存中的每⼀⻚都在磁盘上保留⼀份副本,因此,如果没有修改,在置换该⻚时就不需要将该⻚写回到磁盘上以减少系统的开销;如果已经被修改,则将该⻚重写到磁盘上,以保证磁盘中所保留的始终是最新的副本。
+
+- 硬盘地址:⽤于指出该⻚在硬盘上的地址,通常是物理块号,供调⼊该⻚时使⽤。
+ 总结一下: 需要记录的信息有:1.是否在内存、(如果不在内存)2.在硬盘中间的地址、3.该资源被加载在内存之后是否被修改(如果被修改则需要记录并在操作结束之后返回把修改后的数据写入到硬盘)、4,该资源被调入内存多少次数(用来记录资源的使用率,便于当内存满了的时候,从中不经常使用的资源,并把该资源所占用的内存的位置腾出来)
+
+### 总结:
+
+- 操作系统为每个进程分配独立且一样的虚拟地址空间。(一样的虚拟地址映射到不同的物理地址)
+- 当进程很多,物理内存不够用时,通过**内存交换技术**把不经常用的内存放到硬盘里(换出),需要的时候(换入)
+- 虚拟地址的映射由 MMU 来完成,具体的方式由两种 (分段)和(分页)
+- 分段 是根据程序的特性把代码分成不同大小的属性段 同时每段是连续的内存空间,虚拟地址拥有固定的段数,段大小不定 ,正是因为每段的大小不一定,导致了内存碎片问题和内存交换效率低的问题。
+- 分页 是把虚拟地址空间大小和物理空间大小分成了相同大小的页面。在 Linux 系统,每一页的大小是 4KB 由于分了页,不会产生内存碎片,并且换入和换出也仅仅是几页的事情。
+- 为了解决分页带来的:页表太大的问题,有多级页表,解决了空间上的问题,但是 CPU 在寻址的过程,有很大的时间开销,那么在 CPU 中间设置了一个缓存, 是 TLB 缓存最长被访问的页表项。
+
+Linux 系统主要采⽤了分⻚管理,但是由于 Intel 处理器的发展史,Linux 系统⽆法避免分段管理。于是 Linux 就把所有段的基地址设为 0 ,也就意味着所有程序的地址空间都是线性地址空间(虚拟地址),相当于屏蔽了 CPU 逻辑地址的概念,所以段只被⽤于访问控制和内存保护。
+
+另外,Linxu 系统中虚拟空间分布可分为⽤户态和内核态两部分,其中⽤户态的分布:代码段、全局变量、BSS、函数栈、堆内存、映射区。
diff --git a/_posts/2022-11-12-test-markdown.md b/_posts/2022-11-12-test-markdown.md
new file mode 100644
index 000000000000..8bfd9054cdae
--- /dev/null
+++ b/_posts/2022-11-12-test-markdown.md
@@ -0,0 +1,118 @@
+---
+layout: post
+title: Pods, Nodes, Containers, and Clusters?
+subtitle:
+tags: [Professional English Course Presitation]
+---
+
+# Pods, Nodes, Containers, and Clusters
+
+Kubernetes is quickly becoming the new standard for deploying and managing software in the cloud. With all the power Kubernetes provides, however, comes a steep learning curve. As a newcomer, trying to parse the can be overwhelming. There are many different pieces that make up the system, and it can be hard to tell which ones are relevant for your use case. This blog post will provide a simplified view of Kubernetes, but it will attempt to give a high-level overview of the most important components and how they fit together.
+
+First, lets look at how hardware is represented
+
+Kubernetes 正迅速成为在云中部署和管理软件的新标准。然而,Kubernetes 提供的所有功能带来了陡峭的学习曲线。作为一个新手,尝试解析可能会让人不知所措。系统由许多不同的部分组成,很难判断哪些部分与您的用例相关。这篇博文将提供 Kubernetes 的简化视图,但它将尝试对最重要的组件以及它们如何组合在一起进行高级概述。
+
+首先,让我们看看硬件是如何表示的
+
+## Nodes
+
+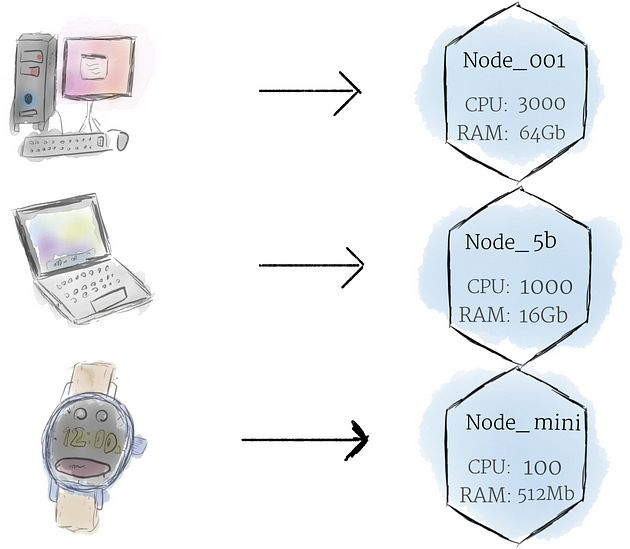
+
+A node is the smallest unit of computing hardware in Kubernetes. It is a representation of a single machine in your cluster. In most production systems, a node will likely be either a physical machine in a datacenter, or virtual machine hosted on a cloud provider like Google Cloud Platform Don’t let conventions limit you, however; in theory, you can make a node out of almost anything
+
+节点 是 Kubernetes 中计算硬件的最小单位。它是集群中单台机器的表示。在大多数生产系统中,节点可能是数据中心中的物理机,或者是托管在像 Google Cloud Platform 这样的云提供商上的虚拟机。但是,不要让约定限制您;理论上,几乎可以用任何东西制作一个节点。
+
+Thinking of a machine as a “node” allows us to insert a layer of abstraction. Now, instead of worrying about the unique characteristics of any individual machine, we can instead simply view each machine as a set of CPU and RAM resources that can be utilized. In this way, any machine can substitute any other machine in a Kubernetes cluster.
+
+将机器视为“节点”允许我们插入一个抽象层。现在,我们不必担心任何单个机器的独特特性,而是可以简单地将每台机器视为一组可以利用的 CPU 和 RAM 资源。这样,任何机器都可以替代 Kubernetes 集群中的任何其他机器。
+
+## The Cluster
+
+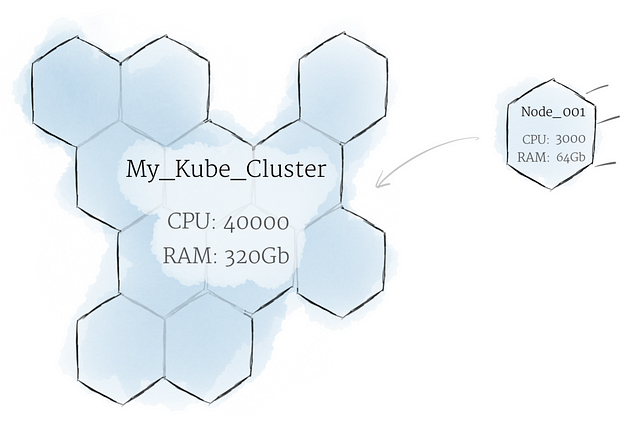
+
+Although working with individual nodes can be useful, it’s not the Kubernetes way. In general, you should think about the cluster as a whole, instead of worrying about the state of individual nodes.
+
+尽管使用单个节点可能很有用,但这不是 Kubernetes 的方式。一般来说,您应该将集群视为一个整体,而不是担心各个节点的状态。
+
+In Kubernetes, nodes pool together their resources to form a more powerful machine. When you deploy programs onto the cluster, it intelligently handles distributing work to the individual nodes for you. If any nodes are added or removed, the cluster will shift around work as necessary. It shouldn’t matter to the program, or the programmer, which individual machines are actually running the code.
+
+在 Kubernetes 中,节点将它们的资源汇集在一起,形成更强大的机器。当您将程序部署到集群上时,它会智能地为您将工作分配到各个节点。如果添加或删除任何节点,集群将根据需要转移工作。对于程序或程序员来说,哪些机器实际运行代码应该无关紧要。
+
+## Persistent Volumes
+
+Because programs running on your cluster aren’t guaranteed to run on a specific node, data can’t be saved to any arbitrary place in the file system. If a program tries to save data to a file for later, but is then relocated onto a new node, the file will no longer be where the program expects it to be. For this reason, the traditional local storage associated to each node is treated as a temporary cache to hold programs, but any data saved locally can not be expected to persist.
+
+因为集群上运行的程序不能保证在特定节点上运行,所以数据不能保存到文件系统中的任意位置。如果程序试图将数据保存到文件中以备后用,但随后被重新定位到新节点,则该文件将不再位于程序期望的位置。因此,传统的与每个节点关联的本地存储被视为临时缓存来保存程序,但任何保存在本地的数据都不能指望持久化。
+
+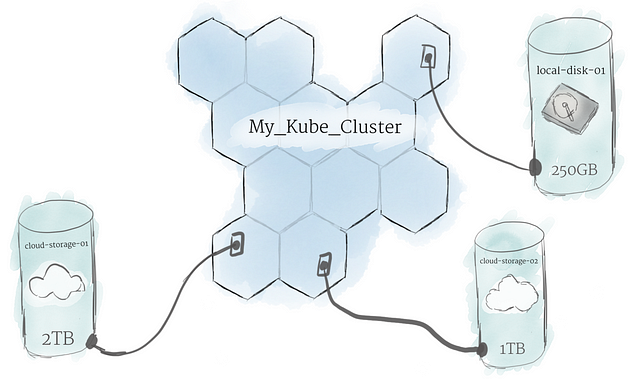
+
+To store data permanently, Kubernetes uses Persistent Volumes While the CPU and RAM resources of all nodes are effectively pooled and managed by the cluster, persistent file storage is not. Instead, local or cloud drives can be attached to the cluster as a Persistent Volume. This can be thought of as plugging an external hard drive in to the cluster. Persistent Volumes provide a file system that can be mounted to the cluster, without being associated with any particular node.
+
+为了永久存储数据,Kubernetes 使用 Persistent Volumes 虽然所有节点的 CPU 和 RAM 资源都由集群有效地汇集和管理,但持久性文件存储却不是。相反,本地或云驱动器可以作为持久卷附加到集群。这可以被认为是将外部硬盘驱动器插入集群。持久卷提供了一个可以挂载到集群的文件系统,而不与任何特定节点相关联。
+
+# Software
+
+## Containers
+
+
+
+Programs running on Kubernetes are packaged as **Linux containers** Containers are a widely accepted standard, so there are already many pre-built images that can be deployed on Kubernetes.
+
+在 Kubernetes 上运行的程序被打包为**Linux 容器**容器是一种被广泛接受的标准,因此已经有很多预构建的镜像可以部署在 Kubernetes 上。
+
+Containerization allows you to create self-contained Linux execution environments. Any program and all its dependencies can be bundled up into a single file and then shared on the internet. Anyone can download the container and deploy it on their infrastructure with very little setup required.
+
+容器化允许您创建自包含的 Linux 执行环境。任何程序及其所有依赖项都可以捆绑到一个文件中,然后在 Internet 上共享。任何人都可以下载容器并将其部署在他们的基础设施上,只需很少的设置。
+
+Multiple programs can be added into a single container, but you should limit yourself to one process per container if at all possible. It’s better to have many small containers than one large one. If each container has a tight focus, updates are easier to deploy and issues are easier to diagnose.
+
+可以将多个程序添加到单个容器中,但如果可能的话,您应该将自己限制为每个容器一个进程。拥有多个小容器总比拥有一个大容器好。如果每个容器都有一个紧密的关注点,更新更容易部署,问题也更容易诊断。
+
+## Pods
+
+
+
+Unlike other systems you may have used in the past, Kubernetes doesn’t run containers directly; instead it wraps one or more containers into a higher-level structure called a [pod](https://kubernetes.io/docs/concepts/workloads/pods/pod/). Any containers in the same pod will share the same resources and local network. Containers can easily communicate with other containers in the same pod as though they were on the same machine while maintaining a degree of isolation from others.
+
+与您过去可能使用过的其他系统不同,Kubernetes 不直接运行容器。相反,它将一个或多个容器包装到称为 pod 的更高级别的结构中。同一个 pod 中的任何容器都将共享相同的资源和本地网络。容器可以轻松地与同一个 pod 中的其他容器进行通信,就像它们在同一台机器上一样,同时保持与其他容器的一定程度的隔离。
+
+Pods are used as the unit of replication in Kubernetes. If your application becomes too popular and a single pod instance can’t carry the load, Kubernetes can be configured to deploy new replicas of your pod to the cluster as necessary. Even when not under heavy load, it is standard to have multiple copies of a pod running at any time in a production system to allow load balancing and failure resistance.
+
+Pod 被用作 Kubernetes 中的复制单元。如果您的应用程序变得过于流行并且单个 pod 实例无法承载负载,则可以将 Kubernetes 配置为根据需要将您的 pod 的新副本部署到集群中。即使不是在重负载下,在生产系统中随时运行多个 Pod 副本也是标准的,以实现负载平衡和抗故障。
+
+Pods can hold multiple containers, but you should limit yourself when possible. Because pods are scaled up and down as a unit, all containers in a pod must scale together, regardless of their individual needs. This leads to wasted resources and an expensive bill. To resolve this, pods should remain as small as possible, typically holding only a main process and its tightly-coupled helper containers (these helper containers are typically referred to as “side-cars”).
+
+Pod 可以容纳多个容器,但您应该尽可能限制自己。由于 pod 是作为一个单元进行扩展和缩减的,因此 pod 中的所有容器必须一起扩展,无论它们的个人需求如何。这会导致资源浪费和昂贵的账单。为了解决这个问题,pod 应该尽可能小,通常只包含一个主进程及其紧密耦合的辅助容器(这些辅助容器通常称为“side-cars”)。
+
+## Deployments
+
+
+
+Although pods are the basic unit of computation in Kubernetes, they are not typically directly launched on a cluster. Instead, pods are usually managed by one more layer of abstraction: the **deployment**
+
+尽管 Pod 是 Kubernetes 中的基本计算单元,但它们通常不会直接在集群上启动。相反,Pod 通常由另一层抽象管理:**部署**
+
+A deployment’s primary purpose is to declare how many replicas of a pod should be running at a time. When a deployment is added to the cluster, it will automatically spin up the requested number of pods, and then monitor them. If a pod dies, the deployment will automatically re-create it.
+
+部署的主要目的是声明一次应该运行多少个 pod 副本。当部署添加到集群时,它会自动启动请求数量的 pod,然后监控它们。如果 pod 死亡,部署将自动重新创建它。
+
+Using a deployment, you don’t have to deal with pods manually. You can just declare the desired state of the system, and it will be managed for you automatically.
+
+使用部署,您不必手动处理 pod。您只需声明系统所需的状态,它将自动为您管理。
+
+## Ingress
+
+
+
+Using the concepts described above, you can create a cluster of nodes, and launch deployments of pods onto the cluster. There is one last problem to solve, however: allowing external traffic to your application.
+
+使用上述概念,您可以创建节点集群,并将 pod 部署到集群上。然而,还有最后一个问题需要解决:允许外部流量进入您的应用程序。
+
+By default, Kubernetes provides isolation between pods and the outside world. If you want to communicate with a service running in a pod, you have to open up a channel for communication. This is referred to as ingress.
+
+默认情况下,Kubernetes 提供 pod 和外部世界之间的隔离。如果要与运行在 pod 中的服务进行通信,则必须打开通信通道。这被称为入口。
+
+There are multiple ways to add ingress to your cluster. The most common ways are by adding either an [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) controller, or a [LoadBalancer](https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/). The exact tradeoffs between these two options are out of scope for this post, but you must be aware that ingress is something you need to handle before you can experiment with Kubernetes.
+
+有多种方法可以向集群添加入口。最常见的方法是添加[Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/)控制器或[LoadBalancer](https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/)。这两个选项之间的确切权衡超出了本文的范围,但您必须意识到,在您尝试 Kubernetes 之前,您需要处理入口。
diff --git a/_posts/2022-11-19-test-markdown.md b/_posts/2022-11-19-test-markdown.md
new file mode 100644
index 000000000000..608ea660502a
--- /dev/null
+++ b/_posts/2022-11-19-test-markdown.md
@@ -0,0 +1,356 @@
+---
+layout: post
+title: 可用性测试报告怎么写?
+subtitle:
+tags: [IO]
+---
+# 可用性测试报告
+
+## 1.项目介绍
+
+#### 『研究背景』:
+
+这是是一款GPS功能的健身跟踪app,让忙碌的人能够迅速制定运动目标和朋友一起完成。当我第一次开始使用app时为精心设计的用户界面感到惊喜。作为一个健身爱好者和产品设计师,我决定看看是否有任何我可以做的以改善用户体验
+
+#### 『研究对象和范围』:
+
+运动板块:快速打卡片各项运动
+
+社区模块:快速发布动态
+
+饮食模块:食物热量、体重管理
+
+个人模块:修改信息,快速注销。快速退出
+
+健身课程模块:快速跟练、快速退出
+
+一共5个板块
+
+#### 『研究方法』:
+
+可用性质测试及问卷打分
+
+## 2.测试执行概述
+
+#### 条件设备:
+
+地点:华中师范大学南湖校区 N526教室
+
+硬件:笔记本电脑
+
+#### 被测试的目标用户基本信息:
+
+人数:20人
+
+受访对象:在其他健身平台有过健身打卡、体重管理、饮食管理等相关经历的人
+
+29岁以下39% 30~39岁以下47% 40~49岁以下13% 50岁以下7%
+
+30~49岁以上的用户目的性比较强,希望快速完成目标,更加在意处理问题的效率
+
+29岁以下用户,细致认真,会进行比较个挑选。
+
+#### 测试流程:
+
+| (1.)与用户沟通,介绍环境 |
+| -------------------------- |
+| (2.)签订保密协议 |
+| (3.)介绍测试内容 |
+| (4.)用户填写个人信息 |
+| (5.)测试,任务后问卷 |
+| (6.)测试后问卷 |
+| (7.)填写数据 |
+
+
+
+#### 测试时间安排:
+
+| 时间段 | 计划内容 |
+| ------------ | -------------------------- |
+| 11.5~11.10 | 确定小组成员,做测试前准备 |
+| 11.10~11.13 | 招募用户 |
+| 11.16~11.17 | 测试并进行数据分析 |
+| 11.18~11.20 | 测试报告 |
+
+
+
+| 用户 | 时间 |
+| ---- | ---- |
+| | |
+| | |
+| | |
+| | |
+
+
+
+##### 任务卡片1:登陆注册修改密码
+
+> 场景描述:
+>
+> 假如您是一名准备开始减肥的人士,准备在暑假减肥10斤。
+>
+> 任务列表:
+>
+> 1.根据任务卡片提供的帐号和密码,完成登陆操作。
+>
+> (帐号:15102769214)密码:7777
+>
+> 2.修改账户密码
+>
+> 3.退出
+
+##### 任务卡片2:制定健身计划
+
+> 场景描述:
+>
+> 假如您是一名准备开始减肥的人士,准备在暑假减肥10斤。
+>
+> 任务列表:
+>
+> 1.开始跑步
+>
+> 2.查看自己今天一共跑了多少公里
+>
+> 3.查看自己今天跑的公里大概是多少的热量
+>
+> 4.查看其他的健身运动,比如瑜伽
+>
+> 5.查看自己练习瑜伽练习了多长时间
+>
+> 6.开始练习的时候发布弹幕
+
+##### 任务卡片3:制定饮食计划
+
+> 场景描述:
+>
+> 假如您是一名准备开始减肥的人士,准备在暑假减肥10斤。
+>
+> 任务列表:
+>
+> 1.记录早、中、晚饮食消耗的热量
+>
+> 2.查询一下一碗米饭的热量
+>
+> 3.制定自己早、中、晚饮食消耗的热量的目标
+>
+> 4.根据自己的体重查找适合自己的饮食推荐组合
+
+##### 任务卡片4:与其他用户进行互动
+
+> 场景描述:
+>
+> 假如您是喜欢社交的人,希望看到自己发布的动态并和其他人交朋友
+>
+> 任务列表:
+>
+> 1.发布一条动态:选择相册的一张照片,配文:减肥第一天。
+>
+> 2.查看其他用户发布的动态
+>
+> 3.点赞其他用户发布的动态
+>
+> 4.评论其他用户发布的动态
+>
+> 5.关注一个自己感兴趣的用户
+>
+> 6.给刚刚关注的用户发送一条消息,向她询问她的健身计划
+
+##### 任务卡片5:查询历史动态
+
+> 场景描述:
+>
+> 假如您某天心情不好,不想让粉丝看到自己发布过的某条动态
+>
+> 1.看一下自己都发布过哪些动态
+>
+> 2.删除一条自己发布过的动态
+>
+> 3.删除自己发布过的动态下面的其他用户的评论
+>
+> 4.将自己曾经发布过的某条动态设置为仅自己可见
+
+##### 任务卡片6:帐号管理
+
+> 1.退出帐号
+>
+> 2.重新登陆后注销帐号
+
+#####
+
+### 测试的任务
+
+通过用户自身对产品的使用过程的回顾,探究用户在各个业务旅程场景钟家的痛点和需求
+
+### 测试任务的脚本
+
+#### 独立任务:
+
+1. 夏天来了,想要在穿好看的裙子或者是展示出强壮的腹肌,想要在一个月内减肥15斤,该怎么做?
+2. 想要看看上一个月哪些天都运动,哪些天又没有?
+3. 想要发布一则自己健身的动态?
+4. 想要看看谁关注了?
+5. 想要记录的跑步里程,该怎么做?
+6. 想要看看曾经发布过的历史动态,该怎么做?
+7. 看上一周都运动了多长时间,该怎么做?
+8. 想要看看自己都关注了谁,该怎么做?
+9. 想要跟着专业的健身课程训练,该怎么做?
+
+## 3.测试过程记录
+
+#### 过程记录文档
+
+
+
+#### 任务卡片
+
+
+
+#### 主持人记录表格
+
+| 所属板块 | 问题描述 | 问题类型 | 发生频率 | 其他 |
+| -------- | -------- | -------- | -------- | ---- |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+
+
+
+可用性测量维度
+
+> 根据需要获得的信息,结合常见用户体验评估指标,针对下列指标进行有效度量:**易用性**(effectiveness):用户完成从【发现 — 选择 — 使用】过程中,操作的精确性。**任务效率(efficiency):**用户完成运动打卡、用户互动、发布动态、填写个人信息、查询运动历史记录所耗的时间和跳出率。**满意度(satisfaction)**:利用评分得出用户使用这款健身产品各项功能的接受程度和完成效果。
+
+
+
+##### **HEART模型(用户行为-定量分析)**
+
+| 任务完成率 | 任务时间 | 任务步骤 | 出错发生 |
+| ---------- | -------- | -------- | -------- |
+| | | | |
+| | | | |
+| | | | |
+| | | | |
+| | | | |
+| | | | |
+| | | | |
+
+具体调查表格
+
+1.对动态发布功能打分
+
+| 调研纬度 | 非常不满意 | 不满意 | 一般 | 满意 | 非常满意 |
+| -------------- | ---------- | ------ | ---- | ---- | -------- |
+| 美观度 | | | | | |
+| 操作的难易程度 | | | | | |
+| 重复使用的意愿 | | | | | |
+
+2.对课程跟练功能打分
+
+| 调研纬度 | 非常不满意 | 不满意 | 一般 | 满意 | 非常满意 |
+| -------------- | ---------- | ------ | ---- | ---- | -------- |
+| 美观度 | | | | | |
+| 操作的难易程度 | | | | | |
+| 重复使用的意愿 | | | | | |
+
+3.对课程跟练功能打分
+
+| 调研纬度 | 非常不满意 | 不满意 | 一般 | 满意 | 非常满意 |
+| -------------- | ---------- | ------ | ---- | ---- | -------- |
+| 美观度 | | | | | |
+| 操作的难易程度 | | | | | |
+| 重复使用的意愿 | | | | | |
+
+4.对课程跟练功能打分
+
+| 调研纬度 | 非常不满意 | 不满意 | 一般 | 满意 | 非常满意 |
+| -------------- | ---------- | ------ | ---- | ---- | -------- |
+| 美观度 | | | | | |
+| 操作的难易程度 | | | | | |
+| 重复使用的意愿 | | | | | |
+
+5.对课程跟练功能打分
+
+| 调研纬度 | 非常不满意 | 不满意 | 一般 | 满意 | 非常满意 |
+| -------------- | ---------- | ------ | ---- | ---- | -------- |
+| 美观度 | | | | | |
+| 操作的难易程度 | | | | | |
+| 重复使用的意愿 | | | | | |
+
+
+
+
+
+##### **LIFT模型(用户行为-定性分析)**
+
+| 是否符合用户需求? | 是否方便用户解读? | 是否为用户态度带来正面影响? | 是否为用户态度带来负面影响? | 是否为方便用户形成决策? |
+| ------------------ | ------------------ | ---------------------------- | ---------------------------- | ------------------------ |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+
+
+
+1.是否在其他平台使用过类似的健身APP?
+
+2.在什么场景下使用?
+
+3.平时使用什么方式来管理自己的体重?
+
+4.觉得哪些功能使用起来不方便又困难?
+
+5.跟练课程时,会感到不方便吗?
+
+
+
+##### **NPS&满意度(用户态度-定量分析)**
+
+| 满意程度如何? | 是否再次使用? | 是否推荐给别人使用? | 易用程度如何? | 美观度如何? |
+| -------------- | -------------- | -------------------- | -------------- | ------------ |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+| | | | | |
+
+
+
+##### **设计评估满意度(用户感知-定性+定量分析)**
+
+| 是否符合品牌调性? | 是否符合用户偏好习惯? | 是否传递了设计初衷心? | 是否提高了效率? | 是否促进了转化? | 是否能被记忆? |
+| ------------------ | ---------------------- | ---------------------- | ---------------- | ---------------- | -------------- |
+| | | | | | |
+| | | | | | |
+| | | | | | |
+| | | | | | |
+| | | | | | |
+| | | | | | |
+| | | | | | |
+
+
+
+
+
+### 测试材料
+
+
+
+## 4.测试后问卷分析
+
+
+
+## 5.可用性问题总计分析
+
+
+
+## 6.总结
+
+
diff --git a/_posts/2022-11-20-test-markdown.md b/_posts/2022-11-20-test-markdown.md
new file mode 100644
index 000000000000..3367df440045
--- /dev/null
+++ b/_posts/2022-11-20-test-markdown.md
@@ -0,0 +1,183 @@
+---
+layout: post
+title: 设备管理?
+subtitle:
+tags: [IO]
+---
+
+# 设备管理
+
+## 1.设备控制器
+
+为了屏蔽设备的差异,每个设备都有一个(设备控制器)的组件,比如硬盘-『硬盘控制器』『显示器有视频控制器』因为这些控制器都很清楚的知道对应设备的⽤法和功能,所以 CPU 是通过设备控制器来和设备打交道的。
+
+#### 设备控制器李有什么?
+
+1.有芯片,用来执行自己的逻辑, 2.有寄存器,用来和 CPU 进行通信 3.有数据缓冲区
+
+#### 操作系统是怎么做的?
+
+操作系统是怎么做的? 1.写入寄存器。操作系统通过写入寄存器来操作设备发送数据,接收数据,开启和关闭寄存器,或者执行其他的操作。 2.读取寄存器。操作系统通过读取寄存器来了解设备的状态,判断设备是否准备好了接收新的命令。
+
+#### 设备控制器里有哪些寄存器?
+
+设备控制器有三类寄存器: 1.状态寄存器 2.命令寄存器 3.数据寄存器
+CPU 通过**读写设备控制器**的**寄存器**来控制设备,这可比 CPU 直接控制输入输出设备要方便很多。
+
+#### 输入输出设备分为哪些类?
+
+输入输出设备分为两大类: 1.块设备 (把数据存储在固定大小的块中间,每个块都有自己的地址)设备,USB 是常见的块设备。 2.字符设备(以字符为单位接受或者发送一个字符流,字符设备是不可以寻址,也没有任何的寻址操作,鼠标是常见的字符设备。)
+
+#### 设备控制器里面的数据缓冲区和控制寄存器如何通信(CPU 让他们进行通信)
+
+1.端口 I/O
+每个寄存器被分配一个 I/O 端口,通过特殊的汇编命令操作这些寄存器. 2.内存映射
+所有的控制寄存器映射到内存空间,像读写内存那样读写数据缓冲区。
+
+## 2.I/0 控制方式
+
+每种设备都有⼀个设备控制器,这个设备控制器相当于一个**小型 CPU**,他可以独立处理一些事。
+问题:CPU 发送一个指令给设备,让设备控制器去读取设备的数据,那么设备控制器读完的时候如何通知 CPU?
+
+#### CPU 通过『轮询等待』判断设备控制器是否读完
+
+CPU 一直查询设备控制器里面的寄存器的状态,直到状态标记完成。很明显,这种
+⽅式⾮常的傻⽠,它会占⽤ CPU 的全部时间
+
+#### 硬件的中断控制器通过 『中断』去通知 CPU 已经读完
+
+> 设备有 1.设备控制器 2.中断控制器
+> 一般硬件都有一个**硬件的中断控制器**,当任务完成,触发硬件的中断控制器,中断控制器通知 CPU,一个中断产⽣了,CPU 需要停下当前⼿⾥的事情来处理中断。
+
+> 中断控制器的两种中断 :1.软中断。代码调⽤ INT 指令触发 2.硬件中断。硬件通过中断控制器触发的
+
+#### 『DMA 控制器』硬件支持 使得设备在没有 CPU 参与的情况下自行的把 I/O 数据放到内存
+
+但中断的⽅式对于频繁读写数据的磁盘,并不友好,这样 CPU 容易经常被打断,会占⽤ CPU ⼤量的时间。对于这⼀类设备的问题的解决⽅法是使⽤ DMA(Direct MemoryAccess) 功能,它可以使得设备在 CPU 不参与的情况下,能够⾃⾏完成把设备 I/O 数据放⼊到内存。那要实现 DMA 功能要有 「DMA 控制器」硬件的⽀持。
+DMA 工作方式如下:
+
+- CPU 对 DMA 控制器下指令,告诉它想读取多少的数据,读完的数据放在内存的某个地方
+- DMA 控制器 向磁盘控制器发出指令,通知磁盘控制器从磁盘读取数据到磁盘内部的缓冲区,接着磁盘控制器把缓冲区的数据传输到内存
+- 磁盘控制器 把数据传输到内存, 磁盘控制器 向地址总线发出确认成功的信号给 DMA 控制器
+- DMA 控制器 接收到信号,然后 DMA 控制器发中断通知 CPU 指令已经完成
+- CPU 现在可以使用内存中的数据了。
+ 可以看到, CPU 当要读取磁盘数据的时候,只需给 DMA 控制器发送指令,然后返回去做其他事情,当磁盘数据拷⻉到内存后,DMA 控制机器通过中断的⽅式,告诉 CPU 数据已经准备好了,可以从内存读数据了。仅仅在传送开始和结束时需要 CPU ⼲预。
+
+## 3.设备驱动程序
+
+设备控制器**屏蔽设备**的细节,设备驱动程序**屏蔽设备控制器**的差异。因为设备控制器的寄存器、缓冲区的使用模式都是不同的,所以为了屏蔽『设备控制器』的差异,引入了设备驱动程序。
+设备控制器不属于操作系统范畴,属于硬件。设备驱动程序属于操作系统。
+
+#### 设备驱动程序是什么?
+
+『设备驱动程序』调用『设备控制器』的方法来实现操作物理设备,『设备驱动程序』处理中断,并根据中断类型调用中
+『设备驱动程序』是『操作系统』面向设备的『设备控制器』的代码,驱动程序发出指令才能操作设备控制器。不同的设备控制器虽然功能不同,但是,**设备驱动程序会提供统一的接口给操作系统**,不同的设备驱动程序,以相同的方式接入操作系统。
+
+#### 设备驱动程序响应设备控制器发出的中断,并根据中断类型调用相应的中断处理程序
+
+设备驱动程序初始化的时候,注册一个该设备的中断处理函数。
+
+#### 中断处理程序的处理流程
+
+1.设备如果准备好数据,则通过中断控制器向 CPU 发送中断请求 2.保护被中断进程的处理函数 3.转⼊相应的设备中断处理函数 4.进行中断处理 5.恢复被中断进程的上下文
+
+```go
+type InterruptHandle func (){}
+// 设备控制器材
+type EquipmentControl struct{
+ CPU *CPU
+ InterruptHandle InterruptHandle
+}
+
+func NewEquipmentControl()*EquipmentControl{
+ return &EquipmentControl{}
+}
+
+// 发出中断
+func (e *EquipmentControl) Interrupt(){
+ e.CPU.SaveContext()
+ // 按道理来说应该是通过设备的驱动程序来调用这个处理函数,而不是设备控制器
+ e.InterruptHandle()
+ e.CPU.RecoverContext()
+}
+
+// 模拟CPU
+type CPU struct{
+
+}
+
+func (c *CPU )SaveContext(){
+
+}
+func (c *CPU )RecoverContext(){
+
+}
+
+
+func Test(){
+ NewEquipmentControl().Interrupt()
+}
+
+
+```
+
+## 4.通用块层
+
+对于块设备,为了减少不同块设备的差异带来的影响,Linux 通过⼀个统⼀的通⽤块层,来管理不同的**块设备**。(还记得设备的两大类吗?块设备和字符设备)
+通⽤块层是处于⽂件系统和磁盘驱动中间的⼀个**块设备抽象层**,它主要有两个功能: 1.向上为文件系统和应用程序,提供访问块设备的标准接口,向下把不同的磁盘设备都抽象成统一的块设备,并且在内核层面提供一个框架来管理这些设备。 2.通用块层把来自**文间系统**和**应用程序**请求排队,接着对队列重新排序、请求合并、也就是 I/O 调度,主要是为了磁盘的读写效率。
+
+#### 5 个 I/O 调度算法
+
+- 没有调度算法
+- 先⼊先出调度算法
+- 完全公平调度算法
+- 优先级调度
+- 最终期限调度算法
+
+第⼀种,没有调度算法,是的,没听错,它不对⽂件系统和应⽤程序的 I/O 做任何处理,这种算法常⽤在**虚拟机 I/O 中**,此时磁盘 I/O 调度算法交由物理机系统负责。
+
+第⼆种,**先⼊先出 I/O 调度**算法,这是最简单的 I/O 调度算法,先进⼊ I/O 调度队列的 I/O 请求先发⽣。『那个进程的 I/O 请求先进入,先执行哪个』
+
+第三种,**完全公平 I/O 调度**算法,⼤部分系统都把这个算法作为默认的 I/O 调度器,它为每个进程维护了⼀个 I/O 调度队列,并按照**时间⽚来均匀分布每个进程的 I/O 请求**。『时间片均匀的分布在每个进程的 I/O 请求中』
+
+第四种,**优先级 I/O 调度**算法,顾名思义,优先级⾼的 I/O 请求先发⽣, 它适⽤于运⾏⼤量进程的系统,像是桌⾯环境、多媒体应⽤等。
+
+第五种,**最终期限 I/O 调度**算法,分别为读、写请求创建了不同的 I/O 队列,这样可以提⾼机械磁盘的吞吐量,并确保达到最终期限的请求被优先处理,适⽤于在 I/O 压⼒⽐较⼤的场景,⽐如数据库等。『两个 I/0 请求队列』
+
+## 5.存储系统 I/0 软件分层
+
+前⾯说到了不少东⻄,设备、设备控制器、驱动程序、通⽤块层,现在再结合⽂件系统原理,我们来看看 Linux 存储系统的 I/O 软件分层。
+可以把 Linux 存储系统的 I/O 由上到下可以分为三个层次,分别是⽂件系统层、通⽤块层、设备层。他们整个的层次关系如下图:
+用户空间 ------- 用户程序
+内核空间 -------文件系统接口
+虚拟文件系统
+文件系统(ext4 nfs)
+页缓存
+通用块层
+块设备 I/0 调度层
+块设备驱动程序
+物理硬件 ------块设备中断控制
+块设备控制
+磁盘设备
+
+- ⽂件系统层,包括虚拟⽂件系统和其他⽂件系统的具体实现,它向上为应⽤程序统⼀提供了标准的⽂件访问接⼝,向下会通过通⽤块层来存储和管理磁盘数据。
+- 通⽤块层,包括块设备的 I/O 队列和 I/O 调度器,它会对⽂件系统的 I/O 请求进⾏排队,再通过 I/O 调度器,选择⼀个 I/O 发给下⼀层的设备层。
+
+- 设备层,包括硬件设备、设备控制器和驱动程序,负责最终物理设备的 I/O 操作
+ 有了⽂件系统接⼝之后,不但可以通过⽂件系统的命令⾏操作设备,也可以通过应⽤程序,调⽤ read 、 write 函数,就像读写⽂件⼀样操作设备,所以说设备在 Linux 下,也只是⼀个特殊的⽂件。
+- 但是,除了读写操作,还需要有检查特定于设备的功能和属性。于是,需要 ioctl 接⼝,它表示输⼊输出控制接⼝,是⽤于配置和修改特定设备属性的通⽤接⼝。
+- 另外,存储系统的 I/O 是整个系统最慢的⼀个环节,所以 Linux 提供了不少缓存机制来提⾼ I/O 的效率。为了提⾼⽂件访问的效率,会使⽤⻚缓存、索引节点缓存、⽬录项缓存等多种缓存机制,⽬的是为了减少对块设备的直接调⽤。为了提⾼块设备的访问效率, 会使⽤缓冲区,来缓存块设备的数据。
+
+## 6.键盘敲⼊字⺟时,期间发⽣了什么?
+
+1. 键盘控制器扫描输入数据,并将其缓冲在键盘控制器的寄存器中
+2. 键盘控制器通过总线给 CPU 发送中断请求。
+3. CPU 收到中断请求后,操作系统会保存被中断进程的 CPU 上下⽂,
+4. CPU 通过调用键盘的驱动程序调用键盘的中断处理函数(键盘的中断处理程序是在键盘驱动程序初始化时注册的,然后通过键盘驱动程序 调⽤键盘的中断处理程序。 )
+5. 中断处理函数从键盘控制器的寄存器**读取**扫描码,然后根据扫描码找到⽤户在键盘输⼊的字符,如果输入的字符是显示字符,那么扫描码翻译成对应显示字符的 ASCII 码
+6. 中断处理函数**把数据放到**「读缓冲区队列」
+7. 显示设备的驱动程序会定时从「读缓冲区队列」**读取数据**放到「写缓冲
+ 区队列」
+8. 显示设备的驱动程序把「写缓冲区队列」的数据⼀个⼀个写⼊到显示设备的控制器的寄存器中的数据缓冲区,最后将这些数据显示在屏幕⾥.
+
+**中断处理程序负责把键盘控制器的数据读出并放到读缓冲队列,然后显示设备从读缓冲队列读出数据,写入数据到显示设备的寄存器。**显示出结果后,恢复被中断进程的上下⽂。
diff --git a/_posts/2022-11-21-test-markdown.md b/_posts/2022-11-21-test-markdown.md
new file mode 100644
index 000000000000..cb22a8dab174
--- /dev/null
+++ b/_posts/2022-11-21-test-markdown.md
@@ -0,0 +1,1568 @@
+---
+layout: post
+title: DUBBO中的设计模式?
+subtitle:
+tags: [设计模式]
+---
+
+# DUBBO 中的设计模式
+
+Dubbo 框架设计概览
+
+## 1.抽象工厂模式
+
+```java
+@SPI("javassist")
+public interface ProxyFactory {
+
+ // 针对consumer端,创建出代理对象
+ @Adaptive({Constants.PROXY_KEY})
+ T getProxy(Invoker invoker) throws RpcException;
+
+ // 针对consumer端,创建出代理对象
+ @Adaptive({Constants.PROXY_KEY})
+ T getProxy(Invoker invoker, boolean generic) throws RpcException;
+
+ // 针对provider端,将服务对象包装成一个Invoker对象
+ @Adaptive({Constants.PROXY_KEY})
+ Invoker getInvoker(T proxy, Class type, URL url) throws RpcException;
+}
+
+
+```
+
+```java
+
+public abstract class AbstractProxyFactory implements ProxyFactory {
+ private static final Class[] INTERNAL_INTERFACES = new Class[]{
+ EchoService.class, Destroyable.class
+ };
+
+ private static final ErrorTypeAwareLogger logger = LoggerFactory.getErrorTypeAwareLogger(AbstractProxyFactory.class);
+
+ @Override
+ public T getProxy(Invoker invoker) throws RpcException {
+ return getProxy(invoker, false);
+ }
+
+ @Override
+ public T getProxy(Invoker invoker, boolean generic) throws RpcException {
+ // when compiling with native image, ensure that the order of the interfaces remains unchanged
+ LinkedHashSet> interfaces = new LinkedHashSet<>();
+ ClassLoader classLoader = getClassLoader(invoker);
+
+ String config = invoker.getUrl().getParameter(INTERFACES);
+ if (StringUtils.isNotEmpty(config)) {
+ String[] types = COMMA_SPLIT_PATTERN.split(config);
+ for (String type : types) {
+ try {
+ interfaces.add(ReflectUtils.forName(classLoader, type));
+ } catch (Throwable e) {
+ // ignore
+ }
+
+ }
+ }
+
+ Class realInterfaceClass = null;
+ if (generic) {
+ try {
+ // find the real interface from url
+ String realInterface = invoker.getUrl().getParameter(Constants.INTERFACE);
+ realInterfaceClass = ReflectUtils.forName(classLoader, realInterface);
+ interfaces.add(realInterfaceClass);
+ } catch (Throwable e) {
+ // ignore
+ }
+
+ if (GenericService.class.equals(invoker.getInterface()) || !GenericService.class.isAssignableFrom(invoker.getInterface())) {
+ interfaces.add(com.alibaba.dubbo.rpc.service.GenericService.class);
+ }
+ }
+
+ interfaces.add(invoker.getInterface());
+ interfaces.addAll(Arrays.asList(INTERNAL_INTERFACES));
+
+ try {
+ return getProxy(invoker, interfaces.toArray(new Class[0]));
+ } catch (Throwable t) {
+ if (generic) {
+ if (realInterfaceClass != null) {
+ interfaces.remove(realInterfaceClass);
+ }
+ interfaces.remove(invoker.getInterface());
+
+ logger.error(PROXY_UNSUPPORTED_INVOKER, "", "", "Error occur when creating proxy. Invoker is in generic mode. Trying to create proxy without real interface class.", t);
+ return getProxy(invoker, interfaces.toArray(new Class[0]));
+ } else {
+ throw t;
+ }
+ }
+ }
+
+ public abstract T getProxy(Invoker invoker, Class[] types);
+}
+
+```
+
+```java
+public class JavassistProxyFactory extends AbstractProxyFactory {
+ private static final ErrorTypeAwareLogger logger = LoggerFactory.getErrorTypeAwareLogger(JavassistProxyFactory.class);
+ private final JdkProxyFactory jdkProxyFactory = new JdkProxyFactory();
+
+ @Override
+ @SuppressWarnings("unchecked")
+ public T getProxy(Invoker invoker, Class[] interfaces) {
+ try {
+ return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
+ } catch (Throwable fromJavassist) {
+ // try fall back to JDK proxy factory
+ try {
+ T proxy = jdkProxyFactory.getProxy(invoker, interfaces);
+ logger.error(PROXY_FAILED_JAVASSIST, "", "", "Failed to generate proxy by Javassist failed. Fallback to use JDK proxy success. " +
+ "Interfaces: " + Arrays.toString(interfaces), fromJavassist);
+ return proxy;
+ } catch (Throwable fromJdk) {
+ logger.error(PROXY_FAILED_JAVASSIST, "", "", "Failed to generate proxy by Javassist failed. Fallback to use JDK proxy is also failed. " +
+ "Interfaces: " + Arrays.toString(interfaces) + " Javassist Error.", fromJavassist);
+ logger.error(PROXY_FAILED_JAVASSIST, "", "", "Failed to generate proxy by Javassist failed. Fallback to use JDK proxy is also failed. " +
+ "Interfaces: " + Arrays.toString(interfaces) + " JDK Error.", fromJdk);
+ throw fromJavassist;
+ }
+ }
+ }
+}
+```
+
+```java
+/**
+ * JdkRpcProxyFactory
+ */
+public class JdkProxyFactory extends AbstractProxyFactory {
+
+ @Override
+ @SuppressWarnings("unchecked")
+ public T getProxy(Invoker invoker, Class[] interfaces) {
+ return (T) Proxy.newProxyInstance(invoker.getInterface().getClassLoader(), interfaces, new InvokerInvocationHandler(invoker));
+ }
+
+ @Override
+ public Invoker getInvoker(T proxy, Class type, URL url) {
+ return new AbstractProxyInvoker(proxy, type, url) {
+ @Override
+ protected Object doInvoke(T proxy, String methodName,
+ Class[] parameterTypes,
+ Object[] arguments) throws Throwable {
+ Method method = proxy.getClass().getMethod(methodName, parameterTypes);
+ return method.invoke(proxy, arguments);
+ }
+ };
+ }
+
+}
+```
+
+在 RPC 框架中,客户端发送请求和服务端执行请求的过程都是由代理类来完成的。客户端的代理对象叫做 Client Stub,服务端的代理对象叫做 Server Stub。
+
+在 Dubbo 中用了 ProxyFactory 来创建这 2 个相关的对象,有两种实现一种是基于 jdk 动态代理,一种是基于 javaassist
+
+## 2.**适配器模式**
+
+Dubbo 可以支持多个日志框架,每个日志框架的实现都有对应的 Adapter 类,为什么要搞 Adapter 类呢,因为 Dubbo 中日志接口 Logger 用的是自己的,而实现类是引入的。但这些日志实现类的等级和 Dubbo 中定义的日志等级并不完全一致,例如 JdkLogger 中并没有 trace 和 debug 这个等级,所以要用 Adapter 类把 Logger 中的等级对应到实现类中的合适等级。
+
+```java
+/**
+ * Logger provider
+ */
+@SPI(scope = ExtensionScope.FRAMEWORK)
+public interface LoggerAdapter {
+
+ Logger getLogger(Class key);
+
+ Logger getLogger(String key);
+
+ Level getLevel();
+
+ void setLevel(Level level);
+
+ File getFile();
+
+ void setFile(File file);
+}
+```
+
+```java
+public class Log4jLoggerAdapter implements LoggerAdapter {
+
+ private File file;
+
+ @SuppressWarnings("unchecked")
+ public Log4jLoggerAdapter() {
+ try {
+ org.apache.log4j.Logger logger = LogManager.getRootLogger();
+ if (logger != null) {
+ Enumeration appenders = logger.getAllAppenders();
+ if (appenders != null) {
+ while (appenders.hasMoreElements()) {
+ Appender appender = appenders.nextElement();
+ if (appender instanceof FileAppender) {
+ FileAppender fileAppender = (FileAppender) appender;
+ String filename = fileAppender.getFile();
+ file = new File(filename);
+ break;
+ }
+ }
+ }
+ }
+ } catch (Throwable t) {
+ }
+ }
+
+ private static org.apache.log4j.Level toLog4jLevel(Level level) {
+ if (level == Level.ALL) {
+ return org.apache.log4j.Level.ALL;
+ }
+ if (level == Level.TRACE) {
+ return org.apache.log4j.Level.TRACE;
+ }
+ if (level == Level.DEBUG) {
+ return org.apache.log4j.Level.DEBUG;
+ }
+ if (level == Level.INFO) {
+ return org.apache.log4j.Level.INFO;
+ }
+ if (level == Level.WARN) {
+ return org.apache.log4j.Level.WARN;
+ }
+ if (level == Level.ERROR) {
+ return org.apache.log4j.Level.ERROR;
+ }
+ // if (level == Level.OFF)
+ return org.apache.log4j.Level.OFF;
+ }
+
+ private static Level fromLog4jLevel(org.apache.log4j.Level level) {
+ if (level == org.apache.log4j.Level.ALL) {
+ return Level.ALL;
+ }
+ if (level == org.apache.log4j.Level.TRACE) {
+ return Level.TRACE;
+ }
+ if (level == org.apache.log4j.Level.DEBUG) {
+ return Level.DEBUG;
+ }
+ if (level == org.apache.log4j.Level.INFO) {
+ return Level.INFO;
+ }
+ if (level == org.apache.log4j.Level.WARN) {
+ return Level.WARN;
+ }
+ if (level == org.apache.log4j.Level.ERROR) {
+ return Level.ERROR;
+ }
+ // if (level == org.apache.log4j.Level.OFF)
+ return Level.OFF;
+ }
+
+ @Override
+ public Logger getLogger(Class key) {
+ return new Log4jLogger(LogManager.getLogger(key));
+ }
+
+ @Override
+ public Logger getLogger(String key) {
+ return new Log4jLogger(LogManager.getLogger(key));
+ }
+
+ @Override
+ public Level getLevel() {
+ return fromLog4jLevel(LogManager.getRootLogger().getLevel());
+ }
+
+ @Override
+ public void setLevel(Level level) {
+ LogManager.getRootLogger().setLevel(toLog4jLevel(level));
+ }
+
+ @Override
+ public File getFile() {
+ return file;
+ }
+
+ @Override
+ public void setFile(File file) {
+
+ }
+
+}
+```
+
+```java
+public class JdkLoggerAdapter implements LoggerAdapter {
+
+ private static final String GLOBAL_LOGGER_NAME = "global";
+
+ private File file;
+
+ public JdkLoggerAdapter() {
+ try {
+ InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream("logging.properties");
+ if (in != null) {
+ LogManager.getLogManager().readConfiguration(in);
+ } else {
+ System.err.println("No such logging.properties in classpath for jdk logging config!");
+ }
+ } catch (Throwable t) {
+ System.err.println("Failed to load logging.properties in classpath for jdk logging config, cause: " + t.getMessage());
+ }
+ try {
+ Handler[] handlers = java.util.logging.Logger.getLogger(GLOBAL_LOGGER_NAME).getHandlers();
+ for (Handler handler : handlers) {
+ if (handler instanceof FileHandler) {
+ FileHandler fileHandler = (FileHandler) handler;
+ Field field = fileHandler.getClass().getField("files");
+ File[] files = (File[]) field.get(fileHandler);
+ if (files != null && files.length > 0) {
+ file = files[0];
+ }
+ }
+ }
+ } catch (Throwable t) {
+ }
+ }
+
+ private static java.util.logging.Level toJdkLevel(Level level) {
+ if (level == Level.ALL) {
+ return java.util.logging.Level.ALL;
+ }
+ if (level == Level.TRACE) {
+ return java.util.logging.Level.FINER;
+ }
+ if (level == Level.DEBUG) {
+ return java.util.logging.Level.FINE;
+ }
+ if (level == Level.INFO) {
+ return java.util.logging.Level.INFO;
+ }
+ if (level == Level.WARN) {
+ return java.util.logging.Level.WARNING;
+ }
+ if (level == Level.ERROR) {
+ return java.util.logging.Level.SEVERE;
+ }
+ // if (level == Level.OFF)
+ return java.util.logging.Level.OFF;
+ }
+
+ private static Level fromJdkLevel(java.util.logging.Level level) {
+ if (level == java.util.logging.Level.ALL) {
+ return Level.ALL;
+ }
+ if (level == java.util.logging.Level.FINER) {
+ return Level.TRACE;
+ }
+ if (level == java.util.logging.Level.FINE) {
+ return Level.DEBUG;
+ }
+ if (level == java.util.logging.Level.INFO) {
+ return Level.INFO;
+ }
+ if (level == java.util.logging.Level.WARNING) {
+ return Level.WARN;
+ }
+ if (level == java.util.logging.Level.SEVERE) {
+ return Level.ERROR;
+ }
+ // if (level == java.util.logging.Level.OFF)
+ return Level.OFF;
+ }
+
+ @Override
+ public Logger getLogger(Class key) {
+ return new JdkLogger(java.util.logging.Logger.getLogger(key == null ? "" : key.getName()));
+ }
+
+ @Override
+ public Logger getLogger(String key) {
+ return new JdkLogger(java.util.logging.Logger.getLogger(key));
+ }
+
+ @Override
+ public Level getLevel() {
+ return fromJdkLevel(java.util.logging.Logger.getLogger(GLOBAL_LOGGER_NAME).getLevel());
+ }
+
+ @Override
+ public void setLevel(Level level) {
+ java.util.logging.Logger.getLogger(GLOBAL_LOGGER_NAME).setLevel(toJdkLevel(level));
+ }
+
+ @Override
+ public File getFile() {
+ return file;
+ }
+
+ @Override
+ public void setFile(File file) {
+
+ }
+
+}
+```
+
+```java
+
+public class Slf4jLoggerAdapter implements LoggerAdapter {
+
+ private Level level;
+ private File file;
+
+ @Override
+ public Logger getLogger(String key) {
+ return new Slf4jLogger(org.slf4j.LoggerFactory.getLogger(key));
+ }
+
+ @Override
+ public Logger getLogger(Class key) {
+ return new Slf4jLogger(org.slf4j.LoggerFactory.getLogger(key));
+ }
+
+ @Override
+ public Level getLevel() {
+ return level;
+ }
+
+ @Override
+ public void setLevel(Level level) {
+ this.level = level;
+ }
+
+ @Override
+ public File getFile() {
+ return file;
+ }
+
+ @Override
+ public void setFile(File file) {
+ this.file = file;
+ }
+
+}
+```
+
+```java
+public class JclLoggerAdapter implements LoggerAdapter {
+
+ private Level level;
+ private File file;
+
+ @Override
+ public Logger getLogger(String key) {
+ return new JclLogger(LogFactory.getLog(key));
+ }
+
+ @Override
+ public Logger getLogger(Class key) {
+ return new JclLogger(LogFactory.getLog(key));
+ }
+
+ @Override
+ public Level getLevel() {
+ return level;
+ }
+
+ @Override
+ public void setLevel(Level level) {
+ this.level = level;
+ }
+
+ @Override
+ public File getFile() {
+ return file;
+ }
+
+ @Override
+ public void setFile(File file) {
+ this.file = file;
+ }
+
+}
+```
+
+```java
+public class Log4j2LoggerAdapter implements LoggerAdapter {
+
+ private Level level;
+
+ public Log4j2LoggerAdapter() {
+
+ }
+
+ private static org.apache.logging.log4j.Level toLog4j2Level(Level level) {
+ if (level == Level.ALL) {
+ return org.apache.logging.log4j.Level.ALL;
+ }
+ if (level == Level.TRACE) {
+ return org.apache.logging.log4j.Level.TRACE;
+ }
+ if (level == Level.DEBUG) {
+ return org.apache.logging.log4j.Level.DEBUG;
+ }
+ if (level == Level.INFO) {
+ return org.apache.logging.log4j.Level.INFO;
+ }
+ if (level == Level.WARN) {
+ return org.apache.logging.log4j.Level.WARN;
+ }
+ if (level == Level.ERROR) {
+ return org.apache.logging.log4j.Level.ERROR;
+ }
+ return org.apache.logging.log4j.Level.OFF;
+ }
+
+ private static Level fromLog4j2Level(org.apache.logging.log4j.Level level) {
+ if (level == org.apache.logging.log4j.Level.ALL) {
+ return Level.ALL;
+ }
+ if (level == org.apache.logging.log4j.Level.TRACE) {
+ return Level.TRACE;
+ }
+ if (level == org.apache.logging.log4j.Level.DEBUG) {
+ return Level.DEBUG;
+ }
+ if (level == org.apache.logging.log4j.Level.INFO) {
+ return Level.INFO;
+ }
+ if (level == org.apache.logging.log4j.Level.WARN) {
+ return Level.WARN;
+ }
+ if (level == org.apache.logging.log4j.Level.ERROR) {
+ return Level.ERROR;
+ }
+ return Level.OFF;
+ }
+
+ @Override
+ public Logger getLogger(Class key) {
+ return new Log4j2Logger(LogManager.getLogger(key));
+ }
+
+ @Override
+ public Logger getLogger(String key) {
+ return new Log4j2Logger(LogManager.getLogger(key));
+ }
+
+ @Override
+ public Level getLevel() {
+ return level;
+ }
+
+ @Override
+ public void setLevel(Level level) {
+ this.level = level;
+ }
+
+ @Override
+ public File getFile() {
+ return null;
+ }
+
+ @Override
+ public void setFile(File file) {
+ }
+}
+```
+
+## 3.工厂方法模式
+
+#### Example1:
+
+Dubbo 可以对结果进行缓存,缓存的策略有很多种,一种策略对应一个缓存工厂类
+
+```java
+@SPI("lru")
+public interface CacheFactory {
+
+ @Adaptive("cache")
+ Cache getCache(URL url, Invocation invocation);
+
+}
+```
+
+```java
+
+@Deprecated
+public abstract class AbstractCacheFactory implements CacheFactory {
+
+ private final ConcurrentMap caches = new ConcurrentHashMap();
+
+ @Override
+ public Cache getCache(URL url, Invocation invocation) {
+ url = url.addParameter(METHOD_KEY, invocation.getMethodName());
+ String key = url.toFullString();
+ Cache cache = caches.get(key);
+ if (cache == null) {
+ caches.put(key, createCache(url));
+ cache = caches.get(key);
+ }
+ return cache;
+ }
+
+ protected abstract Cache createCache(URL url);
+
+ @Override
+ public org.apache.dubbo.cache.Cache getCache(org.apache.dubbo.common.URL url, org.apache.dubbo.rpc.Invocation invocation) {
+ return getCache(new URL(url), new Invocation.CompatibleInvocation(invocation));
+ }
+}
+```
+
+```java
+public class ExpiringCacheFactory extends AbstractCacheFactory {
+ /**
+ * Takes url as an method argument and return new instance of cache store implemented by JCache.
+ * @param url url of the method
+ * @return ExpiringCache instance of cache
+ */
+ @Override
+ protected Cache createCache(URL url) {
+ return new ExpiringCache(url);
+ }
+}
+```
+
+```java
+public class JCacheFactory extends AbstractCacheFactory {
+
+ /**
+ * Takes url as an method argument and return new instance of cache store implemented by JCache.
+ * @param url url of the method
+ * @return JCache instance of cache
+ */
+ @Override
+ protected Cache createCache(URL url) {
+ return new JCache(url);
+ }
+
+}
+```
+
+```java
+public class ThreadLocalCacheFactory extends AbstractCacheFactory {
+
+ /**
+ * Takes url as an method argument and return new instance of cache store implemented by ThreadLocalCache.
+ * @param url url of the method
+ * @return ThreadLocalCache instance of cache
+ */
+ @Override
+ protected Cache createCache(URL url) {
+ return new ThreadLocalCache(url);
+ }
+}
+```
+
+```java
+public class LruCacheFactory extends AbstractCacheFactory {
+
+ /**
+ * Takes url as an method argument and return new instance of cache store implemented by LruCache.
+ * @param url url of the method
+ * @return ThreadLocalCache instance of cache
+ */
+ @Override
+ protected Cache createCache(URL url) {
+ return new LruCache(url);
+ }
+
+}
+```
+
+```java
+public class LfuCacheFactory extends AbstractCacheFactory {
+
+ /**
+ * Takes url as an method argument and return new instance of cache store implemented by LfuCache.
+ * @param url url of the method
+ * @return ThreadLocalCache instance of cache
+ */
+ @Override
+ protected Cache createCache(URL url) {
+ return new LfuCache(url);
+ }
+}
+```
+
+#### Example2:
+
+> 注册中心组件的工厂方法模式
+
+##### dubbo 的注册中心组件的产品体系
+
+抽象产品:Registry,AbstractRegistry,FailbackRegistry 等
+
+具体产品:ZookeeperRegistry,NacosRegistry,MulticastRegistry 等
+
+注册中心的核心抽象产品是 Registry 接口。
+
+按照一般的设计思路,复杂的系统中,接口之下是抽象类,这个组件也是一样的思路,提供了一个 AbstractRegistry 抽象类。
+
+对于 dubbo 里面的注册中心,在 AbstractRegistry 抽象类之下,又增加了一层,FailbackRegistry,用于实现注册中心的注册,订阅,查询,通知等方法的重试,实现故障恢复机制。
+
+它里面联合使用了模板方法和工厂方法模式。
+
+##### 注册中心组件的工厂体系
+
+抽象工厂:RegistryFactory,AbstractRegistryFactory
+
+工厂方法(模板方法):Registry getRegistry(URL url);
+
+具体工厂:ZookeeperRegistryFactory,NacosRegistryFactory,MulticastRegistryFactory 等
+
+##### getRegistry 方法
+
+AbstractRegistryFactory 的注册中心组件的抽象工厂,它里面的 getRegistry 方法,既是工厂方法模式里面的工厂方法,又是模板方法模式里面的模板方法,这个模板方法里面,调用了这个类里面的另外一个抽象方法 createRegistry(), 各个具体工厂,只需要根据自己的情况,实现各自的 createRegistry()方法,即可实现工作方法模式。
+
+```java
+/**
+ * AbstractRegistryFactory. (SPI, Singleton, ThreadSafe)
+ *
+ * @see org.apache.dubbo.registry.RegistryFactory
+ */
+public abstract class AbstractRegistryFactory implements RegistryFactory, ScopeModelAware {
+
+ @Override
+ public Registry getRegistry(URL url) {
+ if (registryManager == null) {
+ throw new IllegalStateException("Unable to fetch RegistryManager from ApplicationModel BeanFactory. " +
+ "Please check if `setApplicationModel` has been override.");
+ }
+
+ Registry defaultNopRegistry = registryManager.getDefaultNopRegistryIfDestroyed();
+ if (null != defaultNopRegistry) {
+ return defaultNopRegistry;
+ }
+
+ url = URLBuilder.from(url)
+ .setPath(RegistryService.class.getName())
+ .addParameter(INTERFACE_KEY, RegistryService.class.getName())
+ .removeParameter(TIMESTAMP_KEY)
+ .removeAttribute(EXPORT_KEY)
+ .removeAttribute(REFER_KEY)
+ .build();
+ String key = createRegistryCacheKey(url);
+ Registry registry = null;
+ boolean check = url.getParameter(CHECK_KEY, true) && url.getPort() != 0;
+ // Lock the registry access process to ensure a single instance of the registry
+ registryManager.getRegistryLock().lock();
+ try {
+ // double check
+ // fix https://github.com/apache/dubbo/issues/7265.
+ defaultNopRegistry = registryManager.getDefaultNopRegistryIfDestroyed();
+ if (null != defaultNopRegistry) {
+ return defaultNopRegistry;
+ }
+ registry = registryManager.getRegistry(key);
+ if (registry != null) {
+ return registry;
+ }
+ //create registry by spi/ioc
+ registry = createRegistry(url);
+ if (check && registry == null) {
+ throw new IllegalStateException("Can not create registry " + url);
+ }
+
+ if (registry != null) {
+ registryManager.putRegistry(key, registry);
+ }
+ } catch (Exception e) {
+ if (check) {
+ throw new RuntimeException("Can not create registry " + url, e);
+ } else {
+ LOGGER.warn("Failed to obtain or create registry ", e);
+ }
+ } finally {
+ // Release the lock
+ registryManager.getRegistryLock().unlock();
+ }
+
+ return registry;
+ }
+
+
+ protected abstract Registry createRegistry(URL url);
+
+}
+```
+
+总结:dubbo 框架里面的注册中心组件,它里面实现了一个非常典型的工厂方法模式,配合模板方法模式,实现了注册中心的扩展。当需要扩展新的注册中心时,只需要增加一个新的具体工厂类,继承抽象产品 AbstractRegistryFactory,实现它里面的 createRegistry()即可。是联合工厂方法模式和模板方法模式。
+
+## 4.装饰者
+
+Dubbo 中网络传输层用到了 Netty,当我们用 Netty 开发时,一般都是写多个 ChannelHandler,然后将这些 ChannelHandler 添加到 ChannelPipeline 上,就是典型的责任链模式
+
+#### Example1:
+
+但是 Dubbo 考虑到有可能替换网络框架组件,所以整个请求发送和请求接收的过程全部用的都是装饰者模式。即只有 NettyServerHandler 实现的接口是 Netty 中的 ChannelHandler,剩下的接口实现的是 Dubbo 中的 ChannelHandler
+
+如下是服务端消息接收会经过的 ChannelHandler
+
+```java
+/**
+ * NettyServerHandler.
+ */
+@io.netty.channel.ChannelHandler.Sharable
+public class NettyServerHandler extends ChannelDuplexHandler {
+ private static final Logger logger = LoggerFactory.getLogger(NettyServerHandler.class);
+ /**
+ * the cache for alive worker channel.
+ *
+ */
+ private final Map channels = new ConcurrentHashMap<>();
+
+ private final URL url;
+
+ private final ChannelHandler handler;
+
+ public NettyServerHandler(URL url, ChannelHandler handler) {
+ if (url == null) {
+ throw new IllegalArgumentException("url == null");
+ }
+ if (handler == null) {
+ throw new IllegalArgumentException("handler == null");
+ }
+ this.url = url;
+ this.handler = handler;
+ }
+
+ public Map getChannels() {
+ return channels;
+ }
+
+ @Override
+ public void channelActive(ChannelHandlerContext ctx) throws Exception {
+ NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
+ if (channel != null) {
+ channels.put(NetUtils.toAddressString((InetSocketAddress) ctx.channel().remoteAddress()), channel);
+ }
+ handler.connected(channel);
+
+ if (logger.isInfoEnabled()) {
+ logger.info("The connection of " + channel.getRemoteAddress() + " -> " + channel.getLocalAddress() + " is established.");
+ }
+ }
+
+ @Override
+ public void channelInactive(ChannelHandlerContext ctx) throws Exception {
+ NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
+ try {
+ channels.remove(NetUtils.toAddressString((InetSocketAddress) ctx.channel().remoteAddress()));
+ handler.disconnected(channel);
+ } finally {
+ NettyChannel.removeChannel(ctx.channel());
+ }
+
+ if (logger.isInfoEnabled()) {
+ logger.info("The connection of " + channel.getRemoteAddress() + " -> " + channel.getLocalAddress() + " is disconnected.");
+ }
+ }
+
+ @Override
+ public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
+ NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
+ handler.received(channel, msg);
+ // trigger qos handler
+ ctx.fireChannelRead(msg);
+ }
+
+
+ @Override
+ public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
+ super.write(ctx, msg, promise);
+ NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
+ handler.sent(channel, msg);
+ }
+
+ @Override
+ public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
+ // server will close channel when server don't receive any heartbeat from client util timeout.
+ if (evt instanceof IdleStateEvent) {
+ NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
+ try {
+ logger.info("IdleStateEvent triggered, close channel " + channel);
+ channel.close();
+ } finally {
+ NettyChannel.removeChannelIfDisconnected(ctx.channel());
+ }
+ }
+ super.userEventTriggered(ctx, evt);
+ }
+
+ @Override
+ public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
+ throws Exception {
+ NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
+ try {
+ handler.caught(channel, cause);
+ } finally {
+ NettyChannel.removeChannelIfDisconnected(ctx.channel());
+ }
+ }
+
+}
+```
+
+```java
+public interface ChannelHandler {
+
+ void handlerAdded(ChannelHandlerContext ctx) throws Exception;
+
+ void handlerRemoved(ChannelHandlerContext ctx) throws Exception;
+
+ void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception;
+
+ @Inherited
+ @Documented
+ @Target(ElementType.TYPE)
+ @Retention(RetentionPolicy.RUNTIME)
+ @interface Sharable {
+
+ }
+
+}
+
+```
+
+#### Example2:
+
+```java
+@SPI(value = "dubbo", scope = ExtensionScope.FRAMEWORK)
+public interface Protocol {
+ /**
+ * Get default port when user doesn't config the port.
+ *
+ * @return default port
+ */
+ int getDefaultPort();
+
+ @Adaptive
+ Exporter export(Invoker invoker) throws RpcException;
+
+ @Adaptive
+ Invoker refer(Class type, URL url) throws RpcException;
+
+ void destroy();
+
+ default List getServers() {
+ return Collections.emptyList();
+ }
+}
+```
+
+ProtocolFilterWrapper 类是对 Protocol 类的修饰。DUBBO 是通过 SPI 机制实现装饰器模式,我们以 Protocol 接口进行分析,首先分析装饰器类,抽象装饰器核心要点是实现了 Component 并且组合一个 Component 对象。
+
+```java
+
+/**
+ * ListenerProtocol
+ */
+@Activate(order = 100)
+public class ProtocolFilterWrapper implements Protocol {
+
+ private final Protocol protocol;
+
+ public ProtocolFilterWrapper(Protocol protocol) {
+ if (protocol == null) {
+ throw new IllegalArgumentException("protocol == null");
+ }
+ this.protocol = protocol;
+ }
+
+ @Override
+ public int getDefaultPort() {
+ return protocol.getDefaultPort();
+ }
+
+ @Override
+ public Exporter export(Invoker invoker) throws RpcException {
+ if (UrlUtils.isRegistry(invoker.getUrl())) {
+ return protocol.export(invoker);
+ }
+ FilterChainBuilder builder = getFilterChainBuilder(invoker.getUrl());
+ return protocol.export(builder.buildInvokerChain(invoker, SERVICE_FILTER_KEY, CommonConstants.PROVIDER));
+ }
+
+ private FilterChainBuilder getFilterChainBuilder(URL url) {
+ return ScopeModelUtil.getExtensionLoader(FilterChainBuilder.class, url.getScopeModel()).getDefaultExtension();
+ }
+
+ @Override
+ public Invoker refer(Class type, URL url) throws RpcException {
+ if (UrlUtils.isRegistry(url)) {
+ return protocol.refer(type, url);
+ }
+ FilterChainBuilder builder = getFilterChainBuilder(url);
+ return builder.buildInvokerChain(protocol.refer(type, url), REFERENCE_FILTER_KEY, CommonConstants.CONSUMER);
+ }
+
+ @Override
+ public void destroy() {
+ protocol.destroy();
+ }
+
+ @Override
+ public List getServers() {
+ return protocol.getServers();
+ }
+
+}
+```
+
+在配置文件中配置装饰器
+
+```java
+filter=org.apache.dubbo.rpc.protocol.ProtocolFilterWrapper
+listener=org.apache.dubbo.rpc.protocol.ProtocolListenerWrapper
+```
+
+通过 SPI 机制加载扩展点时会使用装饰器装饰具体构件:
+
+```java
+public class ReferenceConfig extends AbstractReferenceConfig {
+
+ private static final Protocol refprotocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
+
+ private T createProxy(Map map) {
+ if (isJvmRefer) {
+ URL url = new URL(Constants.LOCAL_PROTOCOL, Constants.LOCALHOST_VALUE, 0, interfaceClass.getName()).addParameters(map);
+ invoker = refprotocol.refer(interfaceClass, url);
+ if (logger.isInfoEnabled()) {
+ logger.info("Using injvm service " + interfaceClass.getName());
+ }
+ }
+ }
+}
+```
+
+最终生成 refprotocol 为如下对象:
+
+```java
+ProtocolFilterWrapper(ProtocolListenerWrapper(InjvmProtocol))
+```
+
+## 5.责任链模式
+
+#### Dubbo 的调用链
+
+#### Example1:
+
+代理对象(Client Stub 或者 Server Stub)在执行的过程中会执行所有 Filter 的 invoke 方法,但是这个实现方法是对对象不断进行包装,看起来非常像装饰者模式,但是基于方法名和这个 Filter 的功能,我更觉得这个是责任链模式
+
+```java
+private static Invoker buildInvokerChain(final Invoker invoker, String key, String group) {
+ Invoker last = invoker;
+ // 获取自动激活的扩展类
+ List filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
+ if (!filters.isEmpty()) {
+ for (int i = filters.size() - 1; i >= 0; i--) {
+ final Filter filter = filters.get(i);
+ final Invoker next = last;
+ last = new Invoker() {
+
+ // 省略部分代码
+
+ @Override
+ public Result invoke(Invocation invocation) throws RpcException {
+ // filter 不断的套在 Invoker 上,调用invoke方法的时候就会执行filter的invoke方法
+ Result result = filter.invoke(next, invocation);
+ if (result instanceof AsyncRpcResult) {
+ AsyncRpcResult asyncResult = (AsyncRpcResult) result;
+ asyncResult.thenApplyWithContext(r -> filter.onResponse(r, invoker, invocation));
+ return asyncResult;
+ } else {
+ return filter.onResponse(result, invoker, invocation);
+ }
+ }
+
+ };
+ }
+ }
+ return last;
+}
+```
+
+#### Example2:
+
+生产者和消费者最终执行对象都是过滤器链路最后一个节点,整个链路包含多个过滤器进行业务处理。
+
+```text
+生产者过滤器链路
+EchoFilter > ClassloaderFilter > GenericFilter > ContextFilter > TraceFilter > TimeoutFilter > MonitorFilter > ExceptionFilter > AbstractProxyInvoker
+
+消费者过滤器链路
+ConsumerContextFilter > FutureFilter > MonitorFilter > DubboInvoker
+```
+
+ProtocolFilterWrapper 作为链路生成核心通过匿名类方式构建过滤器链路,我们以消费者构建过滤器链路为例:
+
+```java
+public class ProtocolFilterWrapper implements Protocol {
+ private static Invoker buildInvokerChain(final Invoker invoker, String key, String group) {
+
+ // invoker = DubboInvoker
+ Invoker last = invoker;
+
+ // 查询符合条件过滤器列表
+ List filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
+ if (!filters.isEmpty()) {
+ for (int i = filters.size() - 1; i >= 0; i--) {
+ final Filter filter = filters.get(i);
+ final Invoker next = last;
+
+ // 构造一个简化Invoker
+ last = new Invoker() {
+ @Override
+ public Class getInterface() {
+ return invoker.getInterface();
+ }
+
+ @Override
+ public URL getUrl() {
+ return invoker.getUrl();
+ }
+
+ @Override
+ public boolean isAvailable() {
+ return invoker.isAvailable();
+ }
+
+ @Override
+ public Result invoke(Invocation invocation) throws RpcException {
+ // 构造过滤器链路
+ Result result = filter.invoke(next, invocation);
+ if (result instanceof AsyncRpcResult) {
+ AsyncRpcResult asyncResult = (AsyncRpcResult) result;
+ asyncResult.thenApplyWithContext(r -> filter.onResponse(r, invoker, invocation));
+ return asyncResult;
+ } else {
+ return filter.onResponse(result, invoker, invocation);
+ }
+ }
+
+ @Override
+ public void destroy() {
+ invoker.destroy();
+ }
+
+ @Override
+ public String toString() {
+ return invoker.toString();
+ }
+ };
+ }
+ }
+ return last;
+ }
+
+ @Override
+ public Invoker refer(Class type, URL url) throws RpcException {
+ // RegistryProtocol不构造过滤器链路
+ if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {
+ return protocol.refer(type, url);
+ }
+ Invoker invoker = protocol.refer(type, url);
+ return buildInvokerChain(invoker, Constants.REFERENCE_FILTER_KEY, Constants.CONSUMER);
+ }
+}
+```
+
+## 6.建造者模式
+
+```java
+
+@SPI(value = "default", scope = APPLICATION)
+public interface FilterChainBuilder {
+ /**
+ * build consumer/provider filter chain
+ */
+ Invoker buildInvokerChain(final Invoker invoker, String key, String group);
+
+ ClusterInvoker buildClusterInvokerChain(final ClusterInvoker invoker, String key, String group);
+
+
+}
+```
+
+```java
+@Activate
+public class DefaultFilterChainBuilder implements FilterChainBuilder {
+
+ /**
+ * build consumer/provider filter chain
+ */
+ @Override
+ public Invoker buildInvokerChain(final Invoker originalInvoker, String key, String group) {
+ Invoker last = originalInvoker;
+ URL url = originalInvoker.getUrl();
+ List moduleModels = getModuleModelsFromUrl(url);
+ List filters;
+ if (moduleModels != null && moduleModels.size() == 1) {
+ filters = ScopeModelUtil.getExtensionLoader(Filter.class, moduleModels.get(0)).getActivateExtension(url, key, group);
+ } else if (moduleModels != null && moduleModels.size() > 1) {
+ filters = new ArrayList<>();
+ List directors = new ArrayList<>();
+ for (ModuleModel moduleModel : moduleModels) {
+ List tempFilters = ScopeModelUtil.getExtensionLoader(Filter.class, moduleModel).getActivateExtension(url, key, group);
+ filters.addAll(tempFilters);
+ directors.add(moduleModel.getExtensionDirector());
+ }
+ filters = sortingAndDeduplication(filters, directors);
+
+ } else {
+ filters = ScopeModelUtil.getExtensionLoader(Filter.class, null).getActivateExtension(url, key, group);
+ }
+
+ if (!CollectionUtils.isEmpty(filters)) {
+ for (int i = filters.size() - 1; i >= 0; i--) {
+ final Filter filter = filters.get(i);
+ final Invoker next = last;
+ last = new CopyOfFilterChainNode<>(originalInvoker, next, filter);
+ }
+ return new CallbackRegistrationInvoker<>(last, filters);
+ }
+
+ return last;
+ }
+
+}
+```
+
+## 7.模板方法
+
+模板方法模式定义一个操作中的算法骨架,一般使用抽象类定义算法骨架。抽象类同时定义一些抽象方法,这些抽象方法延迟到子类实现,这样子类不仅遵守了算法骨架约定,也实现了自己的算法。既保证了规约也兼顾灵活性。这就是用抽象构建框架,用实现扩展细节。
+
+DUBBO 源码中有一个非常重要的核心概念 Invoker,我的理解是执行器或者说一个可执行对象,能够根据方法的名称、参数得到相应执行结果。
+
+```java
+public abstract class AbstractInvoker implements Invoker {
+
+ @Override
+ public Result invoke(Invocation inv) throws RpcException {
+ RpcInvocation invocation = (RpcInvocation) inv;
+ invocation.setInvoker(this);
+ if (attachment != null && attachment.size() > 0) {
+ invocation.addAttachmentsIfAbsent(attachment);
+ }
+ Map contextAttachments = RpcContext.getContext().getAttachments();
+ if (contextAttachments != null && contextAttachments.size() != 0) {
+ invocation.addAttachments(contextAttachments);
+ }
+ if (getUrl().getMethodParameter(invocation.getMethodName(), Constants.ASYNC_KEY, false)) {
+ invocation.setAttachment(Constants.ASYNC_KEY, Boolean.TRUE.toString());
+ }
+ RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
+
+ try {
+ return doInvoke(invocation);
+ } catch (InvocationTargetException e) {
+ Throwable te = e.getTargetException();
+ if (te == null) {
+ return new RpcResult(e);
+ } else {
+ if (te instanceof RpcException) {
+ ((RpcException) te).setCode(RpcException.BIZ_EXCEPTION);
+ }
+ return new RpcResult(te);
+ }
+ } catch (RpcException e) {
+ if (e.isBiz()) {
+ return new RpcResult(e);
+ } else {
+ throw e;
+ }
+ } catch (Throwable e) {
+ return new RpcResult(e);
+ }
+ }
+
+ protected abstract Result doInvoke(Invocation invocation) throws Throwable;
+}
+```
+
+AbstractInvoker 作为抽象父类定义了 invoke 方法这个方法骨架,并且定义了 doInvoke 抽象方法供子类扩展,例如子类**InjvmInvoker**、**DubboInvoker**各自实现了 doInvoke 方法。
+
+InjvmInvoker 是本地引用,调用时直接从本地暴露生产者容器获取生产者 Exporter 对象即可。
+
+```java
+class InjvmInvoker extends AbstractInvoker {
+
+ @Override
+ public Result doInvoke(Invocation invocation) throws Throwable {
+ Exporter exporter = InjvmProtocol.getExporter(exporterMap, getUrl());
+ if (exporter == null) {
+ throw new RpcException("Service [" + key + "] not found.");
+ }
+ RpcContext.getContext().setRemoteAddress(Constants.LOCALHOST_VALUE, 0);
+ return exporter.getInvoker().invoke(invocation);
+ }
+}
+```
+
+DubboInvoker 相对复杂一些,需要考虑同步异步调用方式,配置优先级,远程通信等等。
+
+```java
+public class DubboInvoker extends AbstractInvoker {
+
+ @Override
+ protected Result doInvoke(final Invocation invocation) throws Throwable {
+ RpcInvocation inv = (RpcInvocation) invocation;
+ final String methodName = RpcUtils.getMethodName(invocation);
+ inv.setAttachment(Constants.PATH_KEY, getUrl().getPath());
+ inv.setAttachment(Constants.VERSION_KEY, version);
+ ExchangeClient currentClient;
+ if (clients.length == 1) {
+ currentClient = clients[0];
+ } else {
+ currentClient = clients[index.getAndIncrement() % clients.length];
+ }
+ try {
+ boolean isAsync = RpcUtils.isAsync(getUrl(), invocation);
+ boolean isAsyncFuture = RpcUtils.isReturnTypeFuture(inv);
+ boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
+
+ // 超时时间方法级别配置优先级最高
+ int timeout = getUrl().getMethodParameter(methodName, Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
+ if (isOneway) {
+ boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
+ currentClient.send(inv, isSent);
+ RpcContext.getContext().setFuture(null);
+ return new RpcResult();
+ } else if (isAsync) {
+ ResponseFuture future = currentClient.request(inv, timeout);
+ FutureAdapter