From c163ecadece786f21fbf3db428a1bd4e1cc190f0 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Tue, 19 Nov 2024 17:44:26 +0900
Subject: [PATCH 01/14] Config meta.kr
---
pages/research/_meta.kr.json | 12 +++++++++++-
1 file changed, 11 insertions(+), 1 deletion(-)
diff --git a/pages/research/_meta.kr.json b/pages/research/_meta.kr.json
index 54045a4e5..8cc97befc 100644
--- a/pages/research/_meta.kr.json
+++ b/pages/research/_meta.kr.json
@@ -1,5 +1,15 @@
{
"llm-agents": "LLM Agents",
"rag": "RAG for LLMs",
- "trustworthiness-in-llms": "Trustworthiness in LLMs"
+ "llm-reasoning": "LLM 추론",
+ "rag-faithfulness": "RAG Faithfulness",
+ "llm-recall": "LLM In-Context Recall",
+ "rag_hallucinations": "RAG Reduces Hallucination",
+ "synthetic_data": "Synthetic Data",
+ "thoughtsculpt": "ThoughtSculpt",
+ "infini-attention": "Infini-Attention",
+ "guided-cot": "LM-Guided CoT",
+ "trustworthiness-in-llms": "Trustworthiness in LLMs",
+ "llm-tokenization": "LLM Tokenization",
+ "groq": "What is Groq?"
}
\ No newline at end of file
From 51f6ab872bb2ba2f2f2ae8e7d29f6071f1c131a8 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Tue, 19 Nov 2024 17:45:51 +0900
Subject: [PATCH 02/14] translated llm-reasoning into Korean
---
pages/research/llm-reasoning.kr.mdx | 39 +++++++++++++++++++++++++++++
1 file changed, 39 insertions(+)
create mode 100644 pages/research/llm-reasoning.kr.mdx
diff --git a/pages/research/llm-reasoning.kr.mdx b/pages/research/llm-reasoning.kr.mdx
new file mode 100644
index 000000000..76f5517df
--- /dev/null
+++ b/pages/research/llm-reasoning.kr.mdx
@@ -0,0 +1,39 @@
+# LLM Reasoning
+
+최근 몇 년간, 대형 언어 모델(LLM)은 다양한 작업에서 놀라운 성과를 이루며 빠르게 발전해왔습니다. 최근에는 LLM이 대규모로 확장되었을 때 추론 능력을 발휘할 잠재력을 지니고 있음을 보여주고 있습니다. 여러 종류의 추론(reasoning)은 지능의 핵심이지만 AI 모델이 이러한 능력을 어떻게 학습하고 활용하여 복잡한 문제를 해결하는지는 아직 완전히 규명되지 않았습니다. 이는 많은 연구소에서 큰 관심을 갖고 집중적으로 투자하고 있는 중요한 연구 분야입니다.
+
+## 파운데이션 모델로 추론하기
+[Sun et al. (2023)](https://arxiv.org/abs/2312.11562)는 최근 다양한 추론 작업에서 이루어진 최신 발전을 다룬 파운데이션 모델 기반 추론의 개요를 공개했습니다. 이 연구는 또한 멀티모달 모델과 자율 에이전트를 아우르는 보다 폭넓은 관점에서 추론을 조명하고 있습니다.
+
+추론 작업은 수학적 추론, 논리적 추론, 인과 추론, 시각적 추론 등 다양한 작업을 포함합니다. 아래 그림은 정렬(alignment) 훈련과 ICL(in-context learning) 등 파운데이션 모델을 위한 추론 기법을 포함하여, 해당 설문조사 논문에서 논의된 추론 작업의 개요를 보여줍니다.
+
+
+*그림 출처: [Sun et al., 2023](https://arxiv.org/pdf/2212.09597.pdf)*
+
+## LLM에서 추론은 어떻게 도출하는가?
+LLM에서의 추론은 다양한 프롬프트 기법을 통해 도출하고 강화할 수 있습니다. [Qiao et al. (2023)](https://arxiv.org/abs/2212.09597)은 추론 방법을 두 가지 주요 분야, 즉 추론 향상 전략(reasoning enhanced strategy)과 지식 향상 추론(knowledge enhancement reasoning)으로 구분했습니다. 추론 전략에는 프롬프트 엔지니어링, 프로세스 최적화, 외부 엔진 활용이 포함됩니다. 예를 들어, 단일 단계(single-stage) 프롬프팅 전략으로는 [Chain-of-Thought](https://www.promptingguide.ai/techniques/cot) 과 [Active-Prompt](https://www.promptingguide.ai/techniques/activeprompt)가 있습니다. 언어 모델 프롬프트를 통한 추론의 전체 분류 체계는 논문에서 확인할 수 있으며, 아래 그림에 요약되어 있습니다:
+
+
+*그림 출처: [Qiao et al., 2023](https://arxiv.org/pdf/2212.09597.pdf)*
+
+[Huang et al. (2023)]() 은 GPT-3와 같은 LLM에서 추론을 향상시키거나 도출하는 다양한 기법을 요약하여 설명합니다.
+
+이 기법들은 설명 데이터셋(explanation datasets)을 기반으로 훈련된 완전 지도(fully supervised) 파인튜닝 모델을 활용하는 것부터, 생각의 사슬(CoT), 문제 분할(problem decomposition), 컨텍스트 내 학습(ICL)과 같은 프롬프트 기법에 이르기까지 다양합니다. 아래는 논문에서 설명된 기법들의 요약입니다:
+
+
+*그림 출처: [Huang et al., 2023](https://arxiv.org/pdf/2212.10403.pdf)*
+
+## LLM이 추론하고 계획할 수 있을까?
+LLM이 추론과 계획을 할 수 있는지에 대해 논란이 많습니다. 추론과 계획 모두 로봇 공학이나 자율 에이전트와 같은 분야에서 LLM을 활용해 복잡한 애플리케이션을 구현하는 데 중요한 능력입니다. [Subbarao Kambhampati가 작성한 포지션 페이퍼 (2024)](https://arxiv.org/abs/2403.04121)는 LLM의 추론과 계획에 대해 논의합니다.
+
+저자의 결론을 요약하면 다음과 같습니다:
+
+> 제가 읽거나 검증해본 결과, LLM이 일반적으로 이해되는 방식으로 추론이나 계획을 수행한다고 믿을 만한 확실한 이유는 없었습니다, 대신 웹 스케일 훈련을 바탕으로 LLM이 수행하는 일은 보편적 검색의 한 형태이며, 이는 때때로 추론 능력으로 잘못 인식될 수 있다는 것이 제 주장입니다.
+
+## 출처
+
+- [Reasoning with Language Model Prompting: A Survey](https://arxiv.org/abs/2212.09597)
+- [Towards Reasoning in Large Language Models: A Survey](https://arxiv.org/abs/2212.10403)
+- [Can Large Language Models Reason and Plan?](https://arxiv.org/abs/2403.04121)
+- [Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key?](https://arxiv.org/abs/2402.18272v1)
+- [Awesome LLM Reasoning](https://github.com/atfortes/Awesome-LLM-Reasoning)
\ No newline at end of file
From cc5ac58926038dcbf8a9bf6555c6980d0b1e605d Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Tue, 19 Nov 2024 17:49:11 +0900
Subject: [PATCH 03/14] Modify title of llm-reasoning
---
pages/research/llm-reasoning.kr.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/pages/research/llm-reasoning.kr.mdx b/pages/research/llm-reasoning.kr.mdx
index 76f5517df..e6380b1c2 100644
--- a/pages/research/llm-reasoning.kr.mdx
+++ b/pages/research/llm-reasoning.kr.mdx
@@ -1,4 +1,4 @@
-# LLM Reasoning
+# LLM 추론
최근 몇 년간, 대형 언어 모델(LLM)은 다양한 작업에서 놀라운 성과를 이루며 빠르게 발전해왔습니다. 최근에는 LLM이 대규모로 확장되었을 때 추론 능력을 발휘할 잠재력을 지니고 있음을 보여주고 있습니다. 여러 종류의 추론(reasoning)은 지능의 핵심이지만 AI 모델이 이러한 능력을 어떻게 학습하고 활용하여 복잡한 문제를 해결하는지는 아직 완전히 규명되지 않았습니다. 이는 많은 연구소에서 큰 관심을 갖고 집중적으로 투자하고 있는 중요한 연구 분야입니다.
From 9bb09d33d3510635748c302a6b474779f0f1f7ac Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 09:51:26 +0900
Subject: [PATCH 04/14] Config meta file for research
---
pages/research/_meta.kr.json | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/pages/research/_meta.kr.json b/pages/research/_meta.kr.json
index 8cc97befc..287e0a651 100644
--- a/pages/research/_meta.kr.json
+++ b/pages/research/_meta.kr.json
@@ -2,7 +2,7 @@
"llm-agents": "LLM Agents",
"rag": "RAG for LLMs",
"llm-reasoning": "LLM 추론",
- "rag-faithfulness": "RAG Faithfulness",
+ "rag-faithfulness": "RAG 일관성",
"llm-recall": "LLM In-Context Recall",
"rag_hallucinations": "RAG Reduces Hallucination",
"synthetic_data": "Synthetic Data",
From afbbf212a81bf1e8627d4059fe99865b63a3a711 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 09:52:12 +0900
Subject: [PATCH 05/14] Translate rag-faithfulness in Korean
---
pages/research/rag-faithfulness.kr.mdx | 24 ++++++++++++++++++++++++
1 file changed, 24 insertions(+)
create mode 100644 pages/research/rag-faithfulness.kr.mdx
diff --git a/pages/research/rag-faithfulness.kr.mdx b/pages/research/rag-faithfulness.kr.mdx
new file mode 100644
index 000000000..6b741a67a
--- /dev/null
+++ b/pages/research/rag-faithfulness.kr.mdx
@@ -0,0 +1,24 @@
+# RAG 모델은 얼마나 일관적일까?
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/eEU1dWVE8QQ?si=b-qgCU8nibBCSX8H" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+새로운 논문인 [Wu et al. (2024)](https://arxiv.org/abs/2404.10198)는 RAG와 LLM의 선행 지식(internal prior) 간의 줄다리기를 정량화하는 것에 초점을 맞춥니다.
+
+이 논문은 질문응답을 위한 분석에서 GPT-4와 다른 LLM들을 중심으로 다룹니다.
+
+연구 결과, 올바르게 검색된(retrieved) 정보를 제공하면 모델의 실수를 대부분 수정할 수 있다고 밝혔습니다 (94% 정확도).
+
+
+*출처: [Wu et al. (2024)](https://arxiv.org/abs/2404.10198)*
+
+문서에 잘못된 값이 많고 LLM의 선행 지식(internal prior)이 약할 때, LLM은 잘못된 정보를 더 자주 언급하는 경향이 있습니다. 하지만 선행 지식이 강할수록 LLM은 잘못된 정보를 덜 선택하는 것으로 나타났습니다.
+
+또한 논문에서는 "모델의 선행 지식과 수정된 정보가 차이가 클수록, 모델이 이를 선호할 가능성이 낮아진다"고 보고하고 있습니다.
+
+많은 개발자와 기업들이 RAG 시스템을 실무에서 사용하고 있습니다. 따라서 이 연구는 지원 정보, 모순된 정보, 혹은 완전히 잘못된 정보가 포함될 수 있는 다양한 맥락에서 LLM을 사용할 때 리스크 평가의 중요성을 강조합니다.
From 5dc69a9a039daf2689d6df842614a75e4981a42d Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 10:45:29 +0900
Subject: [PATCH 06/14] Translate synthetic_data into Korean
---
pages/research/_meta.kr.json | 2 +-
pages/research/synthetic_data.kr.mdx | 19 +++++++++++++++++++
2 files changed, 20 insertions(+), 1 deletion(-)
create mode 100644 pages/research/synthetic_data.kr.mdx
diff --git a/pages/research/_meta.kr.json b/pages/research/_meta.kr.json
index 287e0a651..cb48be125 100644
--- a/pages/research/_meta.kr.json
+++ b/pages/research/_meta.kr.json
@@ -5,7 +5,7 @@
"rag-faithfulness": "RAG 일관성",
"llm-recall": "LLM In-Context Recall",
"rag_hallucinations": "RAG Reduces Hallucination",
- "synthetic_data": "Synthetic Data",
+ "synthetic_data": "합성 데이터",
"thoughtsculpt": "ThoughtSculpt",
"infini-attention": "Infini-Attention",
"guided-cot": "LM-Guided CoT",
diff --git a/pages/research/synthetic_data.kr.mdx b/pages/research/synthetic_data.kr.mdx
new file mode 100644
index 000000000..5a5e6d6e4
--- /dev/null
+++ b/pages/research/synthetic_data.kr.mdx
@@ -0,0 +1,19 @@
+# 언어 모델을 위한 합성 데이터(Synthetic Data)의 모범 사례와 핵심 교훈
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/YnlArBZJHY8?si=ZH3hFzwixUopxU5Z" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+이 [논문](https://arxiv.org/abs/2404.07503)은 은 Google DeepMind와 여러 공동 연구자가 발표한 합성 데이터에 대한 모범 사례와 이를 통해 얻은 주요 교훈들을 정리한 내용입니다.
+
+위 논문은 합성 데이터를 중심으로 응용 사례, 직면 과제, 그리고 향후 방향성을 다룹니다. 최근 AI 분야에서 합성 데이터를 활용한 혁신적인 발전을 고려했을때, 이 연구는 매우 중요한 의미를 가집니다.
+
+모델에 고품질 데이터를 더 많이 제공할수록 성능이 향상된다는 것은 이미 잘 알려진 사실입니다. 합성 데이터를 생성하는 것은 비교적 쉬운 일이지만, 그 품질을 보장하는 것이 진정한 도전 과제입니다.
+
+또한 논문은 합성 데이터를 다룰 때 필수적으로 고려해야 할 시힝인 품질, 사실성, 충실성, 편향 제거, 신뢰성, 개인정보 보호 등 다양한 주제에 대해 심도 있게 논의합니다.
+
+특히, 관련 연구 섹션에는 참고하기 좋은 자료들이 다수 포함되어 있어 연구자들에게 큰 도움이 될 것입니다.
From d7aa72b5ab46e2f9b55916fc773a4ac2fd166f2a Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 13:00:46 +0900
Subject: [PATCH 07/14] Translate llm-recall into Korean
---
pages/llm-recall.kr.mdx | 24 ++++++++++++++++++++++++
1 file changed, 24 insertions(+)
create mode 100644 pages/llm-recall.kr.mdx
diff --git a/pages/llm-recall.kr.mdx b/pages/llm-recall.kr.mdx
new file mode 100644
index 000000000..671eb1e61
--- /dev/null
+++ b/pages/llm-recall.kr.mdx
@@ -0,0 +1,24 @@
+# LLM In-Context Recall은 프롬프트 종속적이다
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/2cNO76lIZ4s?si=tbbdo-vnr56YQ077" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+이 새로운 [Machlab and Battle의 논문 (2024)](https://arxiv.org/abs/2404.08865)은 needle-in-a-haystack 테스트에 여러 LLM을 대입하여 in-context recall 성능을 측정했습니다.
+
+이는 다양한 LLM들이 사실을 떠올리는 범위와 깊이가 다르다는 것을 보여줍니다. 이를 통해 프롬프트의 작은 변화가 모델의 Recall 성능에 크게 영향을 준다는 것을 알 수 있습니다.
+
+
+*출처: [Machlab and Battle (2024)](https://arxiv.org/abs/2404.08865)*
+
+또한, 프롬프트 내용과 학습 데이터 간의 상호작용은 응답 품질을 저하시킬 수 있습니다.
+
+모델의 Recall 능력은 모델의 크기를 늘리거나, 어텐션 메커니즘을 향상시키거나, 다양한 학습 전략을 시도하거나 파인튜닝을 적용함으로써 개선될 수 있습니다.
+
+논문이 제시한 중요하고 실용적인 조언: "지속적인 평가를 통해 개별 유스케이스에 적합한 LLM을 선택하는 데 도움이 될 것이며, 기술이 계속 발전함에 따라 실제 응용 프로그램에서 그들의 영향력과 효율성을 극대화할 수 있을 것입니다."
+
+이 논문의 핵심 내용은 신중한 프롬프트 설계, 지속적인 평가 프로토콜 수립, 그리고 Recall과 효율성을 개선하기 위한 다양한 모델 향상 전략 테스트의 중요성입니다
From ff5153decf92a3445c5dedcaec0a5c2a515cb4fd Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 13:44:07 +0900
Subject: [PATCH 08/14] Translate llm-tokenization into Korean
---
pages/research/llm-tokenization.kr.mdx | 29 ++++++++++++++++++++++++++
1 file changed, 29 insertions(+)
create mode 100644 pages/research/llm-tokenization.kr.mdx
diff --git a/pages/research/llm-tokenization.kr.mdx b/pages/research/llm-tokenization.kr.mdx
new file mode 100644
index 000000000..eb46f761b
--- /dev/null
+++ b/pages/research/llm-tokenization.kr.mdx
@@ -0,0 +1,29 @@
+# LLM 토큰화 (Tokenization)
+
+Andrej Karpathy는 최근 대형 언어 모델(LLM) 토큰화에 관한 새로운 [강의](https://youtu.be/zduSFxRajkE?si=Hq_93DBE72SQt73V)를 발표했습니다. 토큰화는 LLM 훈련에서 중요한 부분을 차지하지만, 이는 자체 데이터셋과 알고리즘(예시., [바이트 페어 인코딩](https://en.wikipedia.org/wiki/Byte_pair_encoding))을 사용하여 토크나이저를 훈련하는 과정을 포함합니다..
+
+강의에서 Karpathy는 GPT 토크나이저를 처음부터 구현하는 방법을 가르칩니다. 또한 토큰화에서 비롯된 이상한 동작들에 대해서도 논의합니다.
+
+
+
+*그림 출처: https://youtu.be/zduSFxRajkE?t=6711*
+
+다음은 위 리스트를 텍스트로 옮긴 것입니다:
+
+- 왜 LLM은 단어를 정확히 쓸 수 없나요? 토큰화.
+- 왜 LLM은 문자열을 뒤집는 것 같은 매우 간단한 문자열 처리 작업을 할 수 없나요? 토큰화.
+- 왜 LLM은 영어가 아닌 언어(예: 일본어)에 약할까요? 토큰화.
+- 왜 LLM은 간단한 산술 연산을 잘하지 못하나요? 토큰화.
+- 왜 GPT-2는 Python 코드 작성에 불필요한 어려움을 겪었나요? 토큰화.
+- 왜 내 LLM은 "<endoftext>"라는 문자열을 만나면 갑자기 멈추나요? 토큰화.
+- 왜 "후행 공백(trailing whitespace)"에 대한 이상한 경고가 뜨나요? 토큰화.
+- 왜 LLM이 "SolidGoldMagikarp"에 대해 물어보면 깨지나요? 토큰화.
+- 왜 LLM을 사용할 때 JSON 대신 YAML을 선호해야 하나요? 토큰화.
+- 왜 LLM은 실제로는 E2E 언어 모델링이 아닌가요? 토큰화.
+- 고통의 진짜 근원은 무엇인가요? 토큰화.
+
+LLM의 신뢰성을 개선하려면 이러한 모델을 어떻게 프롬프트해야 하는지 이해하는 것이 중요하며, 이는 모델의 한계를 이해하는 것과도 관련이 있습니다. 추론 시 `max_tokens` 설정 외에는 토크나이저에 대해 특별히 중점을 두지 않지만, 좋은 프롬프트 엔지니어링은 프롬프트를 구성하거나 형식을 지정하는 방식처럼 토큰화에서 고유하게 발생하는 제약과 한계를 이해하는 것과 관련이 있습니다. 예를 들어, 약어나 개념을 정확하게 처리하지 못하거나 토큰화하지 않아 프롬프트가 제대로 작동하지 않는 경우가 있을 수 있습니다. 이는 많은 LLM 개발자와 연구자들이 간과하는 매우 흔한 문제입니다.
+
+토큰화에 유용한 도구로는 [Tiktokenizer](https://tiktokenizer.vercel.app/)가 있으며, 이 도구는 강의에서 시연 목적으로 실제로 사용됩니다.
+
+
From 3219a456f94f2ec8ee98d42527fb42568fb9f73f Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 14:06:36 +0900
Subject: [PATCH 09/14] Translate rag_hallucinations into Korean
---
pages/research/_meta.kr.json | 2 +-
pages/research/rag_hallucinations.kr.mdx | 19 +++++++++++++++++++
2 files changed, 20 insertions(+), 1 deletion(-)
create mode 100644 pages/research/rag_hallucinations.kr.mdx
diff --git a/pages/research/_meta.kr.json b/pages/research/_meta.kr.json
index cb48be125..0e2256fd8 100644
--- a/pages/research/_meta.kr.json
+++ b/pages/research/_meta.kr.json
@@ -4,7 +4,7 @@
"llm-reasoning": "LLM 추론",
"rag-faithfulness": "RAG 일관성",
"llm-recall": "LLM In-Context Recall",
- "rag_hallucinations": "RAG Reduces Hallucination",
+ "rag_hallucinations": "RAG는 환각(Hallucination)을 줄인다",
"synthetic_data": "합성 데이터",
"thoughtsculpt": "ThoughtSculpt",
"infini-attention": "Infini-Attention",
diff --git a/pages/research/rag_hallucinations.kr.mdx b/pages/research/rag_hallucinations.kr.mdx
new file mode 100644
index 000000000..e24bb247c
--- /dev/null
+++ b/pages/research/rag_hallucinations.kr.mdx
@@ -0,0 +1,19 @@
+# RAG를 통한 구조화된 출력(structured outputs)에서 환각(hallucination) 줄이기
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/TUL5guqZejw?si=Doc7lzyAY-SKr21L" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+ServiceNow의 연구자들은 최근 발표한 [새 논문](https://arxiv.org/abs/2404.08189)에서 구조화된 출력 작업을 위한 효율적인 RAG 시스템을 배포하는 방법에 대해 논의했습니다.
+
+
+
+RAG 시스템은 소형 언어 모델과 매우 작은 검색기(retriever)를 결합한 시스템입니다. 이 시스템은 제한된 자원 환경에서도 강력한 LLM 기반 시스템을 배포할 수 있게 해주며, 환각과 같은 문제를 완화하고 출력(output)의 신뢰성을 높이는 데 기여할 수 있음을 보여줍니다.
+
+이 논문은 자연어로 작성된 요구 사항을 JSON 형식으로 구성된 워크플로우로 변환하는 매우 유용한 기업용 응용 프로그램을 다룹니다. 이 작업을 통해 높은 생산성 뿐만 아니라 추가적인 최적화가 가능하다는 점도 주목해야 할 점입니다.(예: 추측적 디코딩(speculative decoding)을 사용하거나 JSON 대신 YAML을 사용하는 방식).
+
+이 논문은 실무에서 효과적으로 RAG 시스템을 개발하는 방법에 대한 유용한 통찰과 실질적인 조언을 제공합니다.
From 80bfeb34a021a48a10f7011c732f038ffbf85f0c Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 14:37:03 +0900
Subject: [PATCH 10/14] Translate infini-attention into Korean
---
pages/research/infini-attention.kr.mdx | 25 +++++++++++++++++++++++++
1 file changed, 25 insertions(+)
create mode 100644 pages/research/infini-attention.kr.mdx
diff --git a/pages/research/infini-attention.kr.mdx b/pages/research/infini-attention.kr.mdx
new file mode 100644
index 000000000..30882d33c
--- /dev/null
+++ b/pages/research/infini-attention.kr.mdx
@@ -0,0 +1,25 @@
+# 효율적인 무한 컨텍스트 트랜스포머
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/tOaTaQ8ZGRo?si=pFP-KiLe63Ppl9Pd" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+구글이 발표한 새로운 [논문](https://arxiv.org/abs/2404.07143) 닷-프로덕트 어텐션 레이어(dot-product attention layer)에 압축 메모리(compressive memory)를 통합하는 방식을 제안합니다.
+
+이 연구의 목표는 트랜스포머 기반 LLM이 한정적인 메모리 사용량과 계산 비용으로 무한히 긴 입력 데이터를 효과적으로 처리할 수 있도록 하는 것입니다.
+
+이들은 기존 어텐션 메커니즘에 압축 메모리 모듈을 통합한 새로운 어텐션 기법인 Infini-attention을 제안했습니다.
+
+
+
+이 모델은 마스킹 로컬 어텐션(masked local attention)과 장기 선형 어텐션(long-term linear attention)을 하나의 트랜스포머 블록에 통합합니다. 이를 통해 Infini-Transformer 모델은 길거나 짧은 범위의 컨텍스트 의존성을 모두 효율적으로 처리할 수 있습니다.
+
+이 접근법은 메모리를 114배 압축하면서도 문맥이 긴(long-context) 언어 모델링에서 기존 모델을 능가하는 성능을 보여줍니다!
+
+물론 10억 매개변수(1B) 크기의 LLM을 백만(1M) 토큰 길이(sequence)까지 확장 가능하며, 80억 매개변수(8B) 모델은 50만(500K) 토큰 길이의 책 요약 작업에서 새로운 최첨단(SoTA) 결과를 달성했다고 밝혔습니다.
+
+긴 문맥을 처리할 수 있는 LLM의 중요성이 점점 커지는 상황에서, 효과적인 메모리 시스템은 지금까지 LLM에서 볼 수 없었던 강력한 추론과 계획, 지속적 적응 그리고 새로운 능력을 열어줄 잠재력을 가지고 있습니다.
From 97c5b000777b8935b2168162127a22a0060f5c38 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 15:34:28 +0900
Subject: [PATCH 11/14] Translate thoughtsculpt into Korean
---
pages/research/thoughtsculpt.kr.mdx | 25 +++++++++++++++++++++++++
1 file changed, 25 insertions(+)
create mode 100644 pages/research/thoughtsculpt.kr.mdx
diff --git a/pages/research/thoughtsculpt.kr.mdx b/pages/research/thoughtsculpt.kr.mdx
new file mode 100644
index 000000000..e28da37e9
--- /dev/null
+++ b/pages/research/thoughtsculpt.kr.mdx
@@ -0,0 +1,25 @@
+# 중간 단계 수정(Intermediate Revision)과 LLM을 위한 검색을 통한 추론
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/13fr5m6ezOM?si=DH3XYfzbMsg9aeIx" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+[Chi et al. (2024)](https://arxiv.org/abs/2404.05966)의 연구는 컴포넌트로 쪼갤 수 있는 작업에 대해 일반적인 추론과 검색을 수행하는 접근법을 제시합니다.
+
+이 연구에서 제안한 그래프 기반 프레임워크인 THOUGHTSCULPT는 반복적인 자가 수정(self-revision) 기능을 포함하며, LLM이 서로 얽힌 사고의 네트워크를 구축할 수 있도록 합니다.
+
+Tree-of-thoughts와 같이 추론 과정을 트리 형태로 구성하는 다른 접근법들과 달리, 이 새로운 접근법은 몬테 카를로 트리 탐색(MCTS)을 활용하여 검색 공간(search space)을 효율적으로 탐색합니다.
+
+이 새로운 방법은 LLM 기반의 사고 평가자(thought evaluator)를 사용하여 잠재적인 부분적 출력(candidate partial outputs)에 대해 피드백을 제공합니다. 그런 다음 사고 생성자(thought generator) 컴포넌트는 잠재적 해결책을 생성합니다. 사고 평가자와 사고 생성자는 직면한 해결책을 개선하는 데 도움을 주는 확장 단계로 간주됩니다.
+
+
+
+마지막으로, 몬테카를로 트리 탐색(MCTS) 과정의 일환으로 작동하는 결정 시뮬레이터(decision simulator)는 연속적인 사고 흐름을 시뮬레이션하여 path의 잠재적 가치를 평가합니다.
+
+지속적인 사고 반복이 가능하기 때문에, THOUGHTSCULPT는 개방형 생성(open-ended generation), 다단계 추론(multip-step reasoning), 창의적 아이디어 발상과 같은 작업에 특히 적합합니다.
+
+이와 유사한 개념이나 검색 알고리즘을 사용해 LLM의 추론 능력과 복잡한 문제 해결, 계획을 처리하는 능력을 향상시키는 더 발전된 접근법들이 등장할 것입니다. 연구 트렌드를 잘 담아낸 기록적 가치가 있는 좋은 논문입니다.
From b2a463cf0ae688fbf5ecfc3bb8ab1642e88a467d Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 16:55:29 +0900
Subject: [PATCH 12/14] Translate groq into Korean
---
pages/research/groq.kr.mdx | 21 +++++++++++++++++++++
1 file changed, 21 insertions(+)
create mode 100644 pages/research/groq.kr.mdx
diff --git a/pages/research/groq.kr.mdx b/pages/research/groq.kr.mdx
new file mode 100644
index 000000000..17e3ac919
--- /dev/null
+++ b/pages/research/groq.kr.mdx
@@ -0,0 +1,21 @@
+# Groq란?
+
+[Groq](https://groq.com/)는 LLM 추론 솔루션 중 가장 빠른 성능을 자랑하는 것으로 최근 주목받고 있습니다. 응답 지연 시간(latency)을 줄이려는 LLM 실무자들의 관심이 쏟아지고 있고, 지연 시간은 실시간 AI 애플리케이션의 중요한 최적화 지표입니다. 이 분야에서 많은 기업들이 LLM 추론을 두고 경쟁하고 있습니다.
+
+Groq는 [Anyscale's LLMPerf Leaderboard](https://github.com/ray-project/llmperf-leaderboard)에서 현재 다른 주요 클라우드 제공업체들에 비해 18배 빠른 추론 성능을 보인다고 주장합니다. Groq는 최근 Meta AI의 Llama 2 70B와 Mixtral 8x7B 모델을 API를 통해 제공하고 있으며, 이 모델들은 Groq의 자체 하드웨어인 언어 처리 유닛(LPU) 기반의 추론 엔진에서 실행됩니다.
+
+Groq의 FAQ에 따르면, LPU는 각 단어가 계산되는 시간을 줄여서 빠른 텍스트 시퀀스 생성을 가능하게 한다고 합니다. LPU의 기술적 세부 사항과 이점에 대해선 ISCA를 수상한 [2020](https://wow.groq.com/groq-isca-paper-2020/)년과 [2022](https://wow.groq.com/isca-2022-paper/)년에 발표된 논문을 통해 더 자세히 알 수 있습니다.
+
+다음 차트는 Groq 모델의 속도와 가격을 보여줍니다:
+
+
+
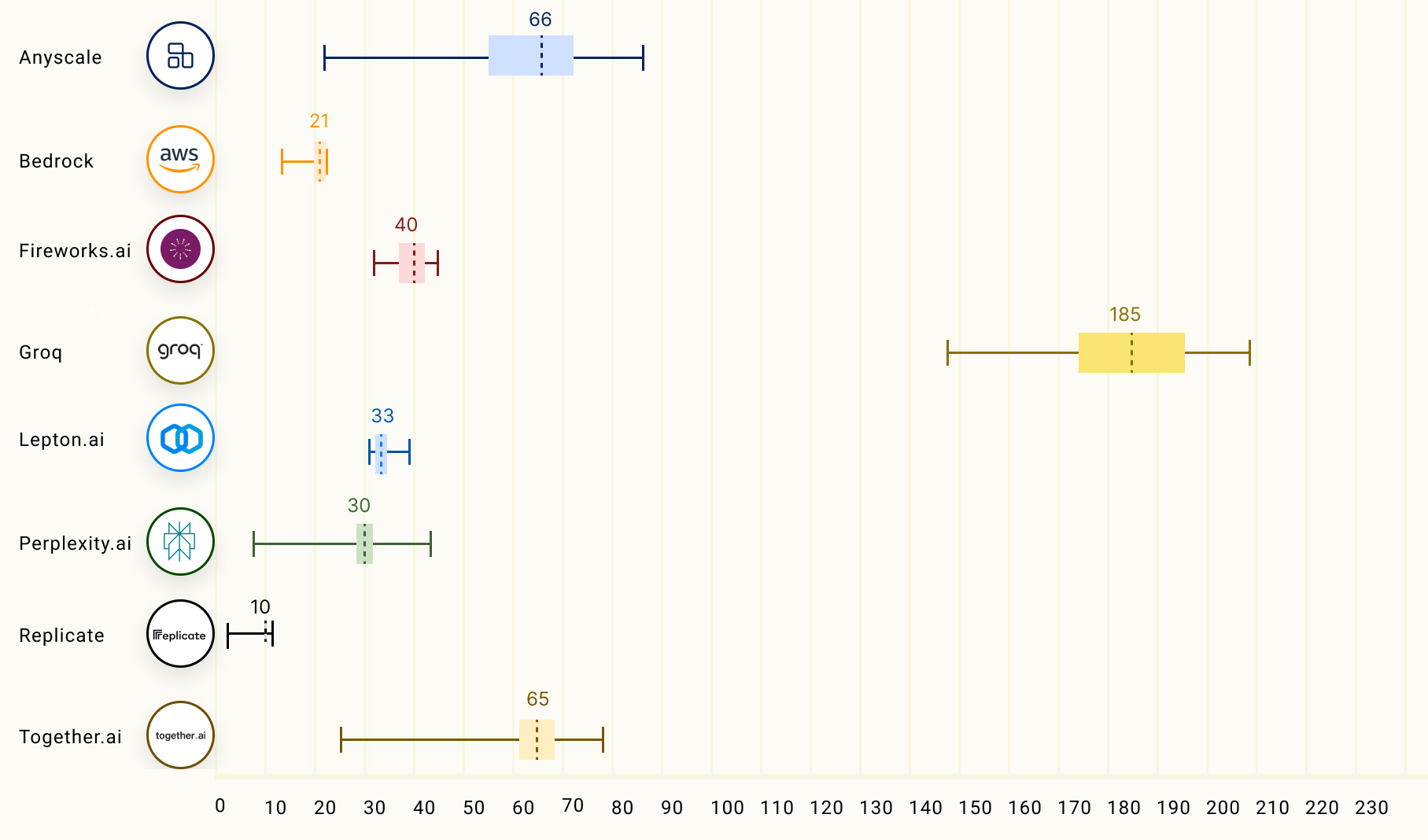
+다음 차트는 Llama 2 70B 모델에 대해 LLM 추론 제공업체들의 아웃풋 토큰 처리량(tokens/s)을 비교한 것입니다. 차트의 숫자들은 150개의 요청을 기반으로 한 평균 아웃풋 토큰 처리량을 나타냅니다.
+
+
+
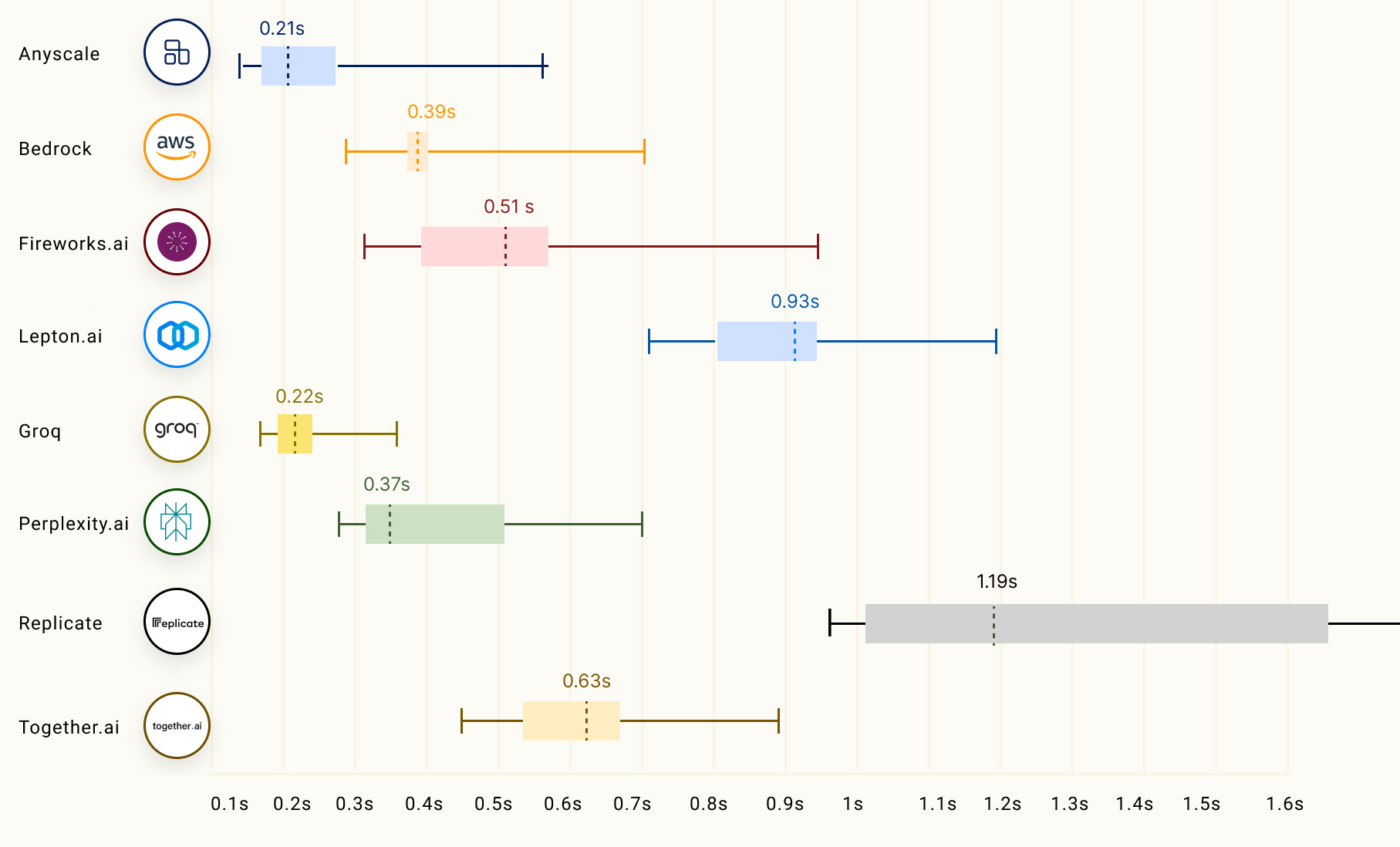
+LLM 추론에서 또 다른 중요한 요소는 첫 번째 토큰이 반환되는 시간을 뜻하는 'time to first token (TTFT)'입니다. 아래 차트는 다양한 LLM 추론 제공업체들의 TTFT 성능을 보여줍니다:
+
+
+
+Groq의 LLM 추론 성능에 대해서는 Anyscale의 LLMPerf Leaderboard인 [여기](https://wow.groq.com/groq-lpu-inference-engine-crushes-first-public-llm-benchmark/)에서 확인할 수 있습니다.
\ No newline at end of file
From d1d7591f32b12938d123f4db8db525fb3fcfc3f1 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 17:21:46 +0900
Subject: [PATCH 13/14] Translate guided-cot into Korean
---
pages/research/_meta.kr.json | 4 ++--
pages/research/guided-cot.kr.mdx | 26 ++++++++++++++++++++++++++
2 files changed, 28 insertions(+), 2 deletions(-)
create mode 100644 pages/research/guided-cot.kr.mdx
diff --git a/pages/research/_meta.kr.json b/pages/research/_meta.kr.json
index 0e2256fd8..513c39db1 100644
--- a/pages/research/_meta.kr.json
+++ b/pages/research/_meta.kr.json
@@ -8,8 +8,8 @@
"synthetic_data": "합성 데이터",
"thoughtsculpt": "ThoughtSculpt",
"infini-attention": "Infini-Attention",
- "guided-cot": "LM-Guided CoT",
+ "guided-cot": "언어 모델 주도 CoT",
"trustworthiness-in-llms": "Trustworthiness in LLMs",
"llm-tokenization": "LLM Tokenization",
- "groq": "What is Groq?"
+ "groq": "Groq란?"
}
\ No newline at end of file
diff --git a/pages/research/guided-cot.kr.mdx b/pages/research/guided-cot.kr.mdx
new file mode 100644
index 000000000..1c1e66f36
--- /dev/null
+++ b/pages/research/guided-cot.kr.mdx
@@ -0,0 +1,26 @@
+# 언어 모델 주도 생각의 사슬(Chain-of-Thought)
+
+import {Bleed} from 'nextra-theme-docs'
+
+<iframe width="100%"
+ height="415px"
+ src="https://www.youtube.com/embed/O3bl0qURONM?si=Hwdc_o0qHpw8QRsY" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+ allowFullScreen
+ />
+
+[Lee et al. (2024)](https://arxiv.org/abs/2404.03414)의 새 논문에서 소형 언어 모델(sLM)을 사용해 LLM의 추론 능력을 향상시키는 방법을 제안합니다.
+
+먼저, 이 방법은 대형 언어 모델이 생성한 rationales을 이용해 소형 언어 모델에 지식 증류(knowledge distillation)를 적용하여 추론 능력의 격차를 좁히는 것을 목표로 합니다.
+
+본질적으로, rationale은 경량화된 언어 모델에서 생성되며, 정답 예측은 고정된(frozen) 대형 언어 모델에 맡겨집니다. 자원 효율적인 이러한 접근 방식은 대형 모델을 파인 튜닝할 필요없는 대신 작은 언어 모델에 rationale 생성을 분담합니다.
+
+지식 증류된 언어 모델은 여러 rationales 지향적(rational-oriented)이고 작업 지향적(task-oriented)인 보상 신호를 사용한 강화 학습을 통해 더욱 최적화됩니다.
+
+
+*출처: https://arxiv.org/pdf/2404.03414.pdf*
+
+해당 프레임워크는 다단계 추출형 질문 응답(multi-hop extractive question answering)를 통해 테스트를 거쳤으며, 답 예측 정확도에서 모든 기준 모델을 능가합니다. 강화 학습은 생성된 rationales의 품질을 향상시켜 질문 응답 성능을 더욱 개선합니다.
+
+이 논문에서 제안한 언어 모델 주도 CoT 프롬프트 방식은 표준 프롬프트와 CoT 프롬프트를 모두 능가합니다. 자기 일관성 디코딩(self-consistency decoding) 또한 성능을 향상시킵니다.
+
+이 접근법은 rationales 생성에 있어 소형 언어 모델을 기발하게 활용한 예입니다. 언어 모델의 규모가 클수록 추론 능력에서 선호되는 경향을 감안하면 주목할 만한 결과입니다. 작업을 이렇게 분해(decomposing)하는 방식은 개발자들이 깊이 생각해볼 부분입니다. 모든 작업을 대형 모델이 해야 하는 것은 아닙니다. 파인 튜닝 시 최적화하려는 부분을 정확히 겨냥하고, 소형 언어 모델이 그것을 대신할 수 있는지 테스트해보는 것이 유용합니다.
\ No newline at end of file
From 563c5a05c0be30656b038ff03974a9eea0ca6780 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=EB=B0=B1=EC=A7=84=EC=A3=BC?= <100pearlcent@naver.com>
Date: Wed, 20 Nov 2024 17:45:34 +0900
Subject: [PATCH 14/14] Translate trustworthiness in llms into Korean
---
pages/research/_meta.kr.json | 2 +-
pages/research/trustworthiness-in-llms.kr.mdx | 62 ++++++++++++++++++-
2 files changed, 61 insertions(+), 3 deletions(-)
diff --git a/pages/research/_meta.kr.json b/pages/research/_meta.kr.json
index 513c39db1..7590d903f 100644
--- a/pages/research/_meta.kr.json
+++ b/pages/research/_meta.kr.json
@@ -9,7 +9,7 @@
"thoughtsculpt": "ThoughtSculpt",
"infini-attention": "Infini-Attention",
"guided-cot": "언어 모델 주도 CoT",
- "trustworthiness-in-llms": "Trustworthiness in LLMs",
+ "trustworthiness-in-llms": "LLM의 신뢰성",
"llm-tokenization": "LLM Tokenization",
"groq": "Groq란?"
}
\ No newline at end of file
diff --git a/pages/research/trustworthiness-in-llms.kr.mdx b/pages/research/trustworthiness-in-llms.kr.mdx
index 567a74309..053bfa98a 100644
--- a/pages/research/trustworthiness-in-llms.kr.mdx
+++ b/pages/research/trustworthiness-in-llms.kr.mdx
@@ -1,3 +1,61 @@
-# Trustworthiness in LLMs
+# LLM의 신뢰성
-This page needs a translation! Feel free to contribute a translation by clicking the `Edit this page` button on the right.
\ No newline at end of file
+import {Screenshot} from 'components/screenshot'
+
+import TRUSTLLM from '../../img/llms/trustllm.png'
+import TRUSTLLM2 from '../../img/llms/trust-dimensions.png'
+import TRUSTLLM3 from '../../img/llms/truthfulness-leaderboard.png'
+
+LLM을 활용한 애플리케이션은 건강과 금융 같은 고위험(high-stake) 분야에서 중요한 역할을 합니다. ChatGPT와 같은 LLM은 인간이 읽을 수 있는 응답을 생성하는 데 매우 능숙하지만, 사실성, 안전성, 개인정보 보호 등 여러 측면에서 신뢰할 수 있는 응답을 보장하지는 않습니다.
+
+[Sun et al. (2024)](https://arxiv.org/abs/2401.05561)은 최근 LLM의 신뢰성에 대한 포괄적인 연구를 제시하며, 신뢰성의 도전 과제, 벤치마크, 평가, 접근법 분석, 방향성 등에 대해 논의했습니다.
+
+현재 LLM을 실생활에 적용하는 데 있어 가장 큰 도전 과제 중 하나는 바로 신뢰성입니다. 이 연구에서는 8개의 차원에 걸쳐 신뢰할 수 있는 LLM을 위한 원칙을 제시하고, 6개의 차원(사실성, 안전성, 공정성, 견고성, 개인정보 보호, 기계 윤리)에 대한 벤치마크를 제안합니다.
+
+저자는 LLM의 신뢰성을 6가지 측면에서 평가할 수 있는 벤치마크를 제시했습니다:
+
+<Screenshot src={TRUSTLLM} alt="A benchmark of trustworthy large language models" />
+
+다음은 신뢰할 수 있는 LLM의 8개 차원의 정의입니다.
+
+<Screenshot src={TRUSTLLM2} alt="Dimensions of Trustworthy LLMs" />
+
+## 주요 결과
+
+이 연구에서는 TrustLLM을 사용해 16개의 주요 LLM을 평가했으며, 30개 이상의 데이터셋을 포함한 평가 결과를 보여줍니다. 다음은 평가에서 나온 주요 결과입니다:
+
+- 상용 LLM은 신뢰성 면에서 대부분의 오픈 소스 모델을 능가하는 반면, 일부 오픈 소스 모델이 차이를 좁혀가고 있습니다.
+- GPT-4와 Llama 2와 같은 모델은 고정관념적 발언을 확실하게 거부하고, 적대적인 공격에 대한 내성을 강화할 수 있습니다.
+- Llama 2와 같은 오픈 소스 모델은 신뢰성 측면에서 특별한 측정 도구 없이도 상용 모델과 비슷한 성과를 보입니다. 논문에서는 Llama 2와 같은 모델이 신뢰성에 과도하게 최적화되어 있어서 때때로 유용성을 해치는 결과를 초래하며, 무해한 프롬프트도 해로운 인풋으로 잘못 처리된다고 언급하고 있습니다.
+
+## 주요 통찰
+
+이 논문에서 다룬 다양한 신뢰성 차원에 대해 보고된 주요 통찰은 다음과 같습니다:
+
+- **신뢰성**: LLM은 훈련 데이터의 잡음, 사실이 아니거나 오래된 정보 때문에 신뢰성에서 어려움을 겪는 경우가 많습니다. 외부 지식원에 접근할 수 있는 LLM은 신뢰성에서 개선된 성과를 보입니다.
+
+- **안전성**: 오픈 소스 LLM은 일반적으로 탈옥, 유해성, 남용과 같은 안전성 측면에서 상용 모델에 뒤처집니다. 안전성 조치를 과도하게 취하지 않으면서 균형을 찾는 것이 도전 과제입니다.
+
+- **공정성**: 대부분의 LLM은 고정관념을 잘 판별하지 못합니다. GPT-4와 같은 고급 모델도 이 분야에서 약 65%의 정확도를 보입니다.
+
+- **견고성**: LLM의 견고성은 특히 열린 질문이나 분포 밖의 작업에서 상당한 변동성을 보입니다.
+
+- **개인정보 보호**: LLM은 개인정보 보호 규범을 인지하지만, 개인정보 처리 능력은 모델마다 크게 다릅니다. 예를 들어, 일부 모델은 Enron 이메일 데이터셋으로 테스트했을 때 정보 유출이 발생했습니다.
+
+- **기계 윤리**: LLM은 기본적인 도덕적 원칙을 이해합니다만 복잡한 윤리적 상황에서는 부족함이 있습니다.
+
+## LLM 신뢰성 리더보드
+
+저자들은 또한 [LLM 신뢰성 리더보드](https://trustllmbenchmark.github.io/TrustLLM-Website/leaderboard.html)를 공개하기도 했습니다. 예를 들어, 아래 표는 다양한 모델이 사실성 차원에서 어떻게 평가되는지를 보여줍니다. 웹사이트에서는 "더 신뢰할 수 있는 LLM은 ↑ 기호와 함께 메트릭 값이 높고, ↓ 기호가 붙으며 메트릭 값이 낮습니다."라고 설명하고 있습니다.
+
+<Screenshot src={TRUSTLLM3} alt="Trustworthiness Leaderboard for LLMs" />
+
+## 코드
+
+LLM의 신뢰성을 다양한 차원에서 평가할 수 있는 평가 키트가 담긴 GitHub 저장소도 제공합니다.
+
+소스 코드: https://github.com/HowieHwong/TrustLLM
+
+## 참고 문헌
+
+이미지 출처 / 논문: [TrustLLM: Trustworthiness in Large Language Models](https://arxiv.org/abs/2401.05561) (10 Jan 2024)
\ No newline at end of file