You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
尽管神经网络在图像识别、自然语言等很多领域大放异彩,但回到表格数据的数据挖掘任务中,树模型才是低调王者,如论文《Tabular Data: Deep Learning is Not All You Need》提及的:深度学习可能不是解决所有机器学习问题的灵丹妙药,通过树模型在处理表格数据时性能与神经网络相当(甚至优于神经网络),而且树模型易于训练使用,有较好的可解释性。
一、Deep Learning is Not All You Need
尽管神经网络在图像识别、自然语言等很多领域大放异彩,但回到表格数据的数据挖掘任务中,树模型才是低调王者,如论文《Tabular Data: Deep Learning is Not All You Need》提及的: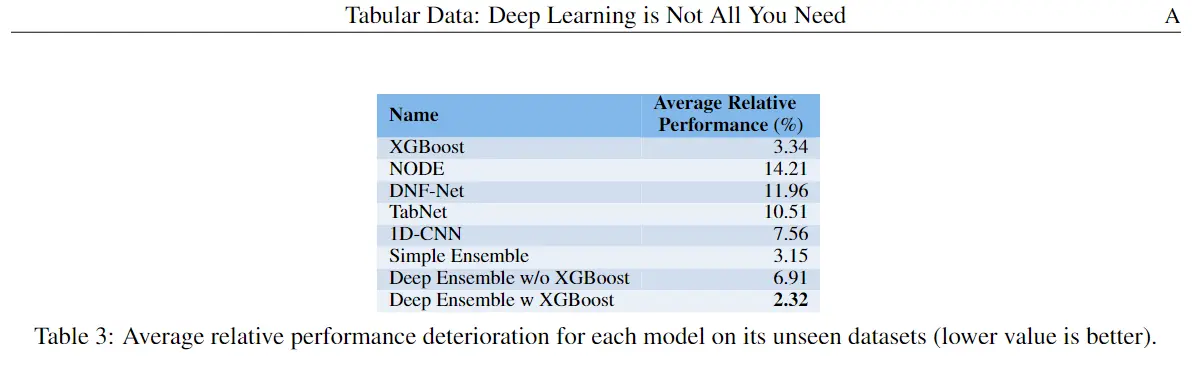 深度学习可能不是解决所有机器学习问题的灵丹妙药,通过树模型在处理表格数据时性能与神经网络相当(甚至优于神经网络),而且树模型易于训练使用,有较好的可解释性。
深度学习可能不是解决所有机器学习问题的灵丹妙药,通过树模型在处理表格数据时性能与神经网络相当(甚至优于神经网络),而且树模型易于训练使用,有较好的可解释性。
二、树模型的使用
对于决策树等模型的使用,通常是要到scikit-learn、xgboost、lightgbm等机器学习库调用, 这和深度学习库是独立割裂的,不太方便树模型与神经网络的模型融合。
一个好消息是,Google 开源了 TensorFlow 决策森林(TF-DF),为基于树的模型和神经网络提供统一的接口,可以直接用TensorFlow调用树模型。决策森林(TF-DF)简单来说就是用TensorFlow封装了常用的随机森林(RF)、梯度提升(GBDT)等算法,其底层算法是基于C++的 Yggdrasil 决策森林 (YDF)实现的。
三、TensorFlow构建GBDT实践
TF-DF安装很简单
pip install -U tensorflow_decision_forests,有个遗憾是目前只支持Linux环境,如果本地用不了将代码复制到 Google Colab 试试~TD-DF 一个非常方便的地方是它不需要对数据进行任何预处理。它会自动处理数字和分类特征,以及缺失值,我们只需要将df转换为 TensorFlow 数据集,如下一些超参数设定:
模型方面的树的一些常规超参数,类似于scikit-learn的GBDT
此外,还有带有正则化(dropout、earlystop)、损失函数(focal-loss)、效率方面(goss基于梯度采样)等优化方法:
构建模型、编译及训练,一步到位:
GBDT等树模型还有另外一个很大的优势是解释性,这里TF-DF也有实现。
模型情况及特征重要性可以通过
print(model_tf.summary())打印出来,特征重要性支持了几种不同的方法评估:
MEAN_MIN_DEPTH指标。 平均最小深度越小,较低的值意味着大量样本是基于此特征进行分类的,变量越重要。

NUM_NODES指标。它显示了给定特征被用作分割的次数,类似split。此外还有其他指标就不一一列举了。
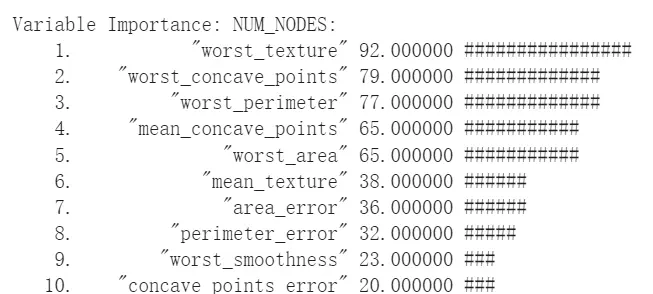
我们还可以打印出模型的具体决策的树结构,通过运行
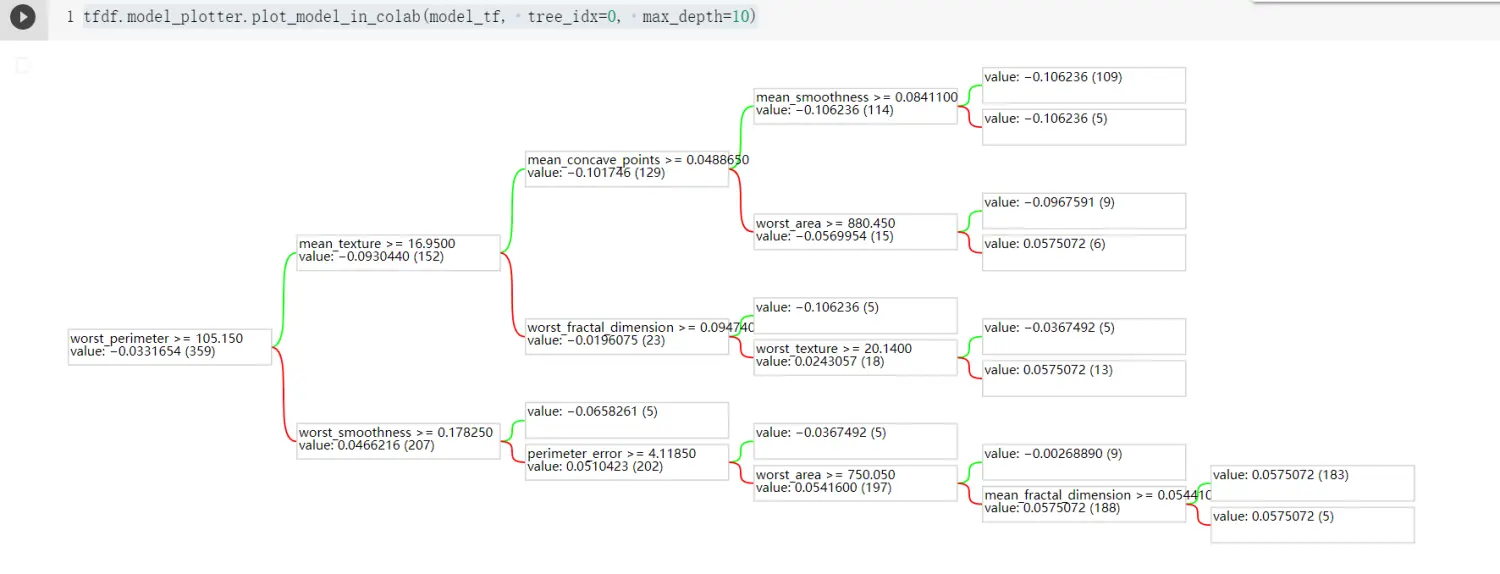
tfdf.model_plotter.plot_model_in_colab(model_tf, tree_idx=0, max_depth=10),整个过程还是比较清晰的。小结
基于TensorFlow的TF-DF的树模型方法,我们可以方便训练树模型(特别对于熟练TensorFlow框架的同学),更进一步,也可以与TensorFlow的神经网络模型做效果对比、树模型与神经网络模型融合、利用异构模型先特征表示学习再输入模型(如GBDT+DNN、DNN embedding+GBDT),进一步了解可见如下参考文献。
The text was updated successfully, but these errors were encountered: