Releases: UKPLab/sentence-transformers
v2.6.0 - Embedding Quantization, GISTEmbedLoss
This release brings embedding quantization: a way to heavily speed up retrieval & other tasks, and a new powerful loss function: GISTEmbedLoss.
Install this version with
pip install sentence-transformers==2.6.0
Embedding Quantization
Embeddings may be challenging to scale up, which leads to expensive solutions and high latencies. However, there is a new approach to counter this problem; it entails reducing the size of each of the individual values in the embedding: Quantization. Experiments on quantization have shown that we can maintain a large amount of performance while significantly speeding up computation and saving on memory, storage, and costs.
To be specific, using binary quantization may result in retaining 96% of the retrieval performance, while speeding up retrieval by 25x and saving on memory & disk space with 32x. Do not underestimate this approach! Read more about Embedding Quantization in our extensive blogpost.
Binary and Scalar Quantization
Two forms of quantization exist at this time: binary and scalar (int8). These quantize embedding values from float32 into binary and int8, respectively. For Binary quantization, you can use the following snippet:
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2a. Encode some text using "binary" quantization
binary_embeddings = model.encode(
["I am driving to the lake.", "It is a beautiful day."],
precision="binary",
)
# 2b. or, encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
binary_embeddings = quantize_embeddings(embeddings, precision="binary")References:
GISTEmbedLoss
GISTEmbedLoss, as introduced in Solatorio (2024), is a guided variant of the more standard in-batch negatives (MultipleNegativesRankingLoss) loss. Both loss functions are provided with a list of (anchor, positive) pairs, but while MultipleNegativesRankingLoss uses anchor_i and positive_i as positive pair and all positive_j with i != j as negative pairs, GISTEmbedLoss uses a second model to guide the in-batch negative sample selection.
This can be very useful, because it is plausible that anchor_i and positive_j are actually quite semantically similar. In this case, GISTEmbedLoss would not consider them a negative pair, while MultipleNegativesRankingLoss would. When finetuning MPNet-base on the AllNLI dataset, these are the Spearman correlation based on cosine similarity using the STS Benchmark dev set (higher is better):

The blue line is MultipleNegativesRankingLoss, whereas the grey line is GISTEmbedLoss with the small all-MiniLM-L6-v2 as the guide model. Note that all-MiniLM-L6-v2 by itself does not reach 88 Spearman correlation on this dataset, so this is really the effect of two models (mpnet-base and all-MiniLM-L6-v2) reaching a performance that they could not reach separately.
Soft save_to_hub Deprecation
Most codebases that allow for pushing models to the Hugging Face Hub adopt a push_to_hub method instead of a save_to_hub method, and now Sentence Transformers will follow that convention. The push_to_hub method will now be the recommended approach, although save_to_hub will continue to exist for the time being: it will simply call push_to_hub internally.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-mpnet-base-v2")
...
# Train the model
model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=dev_evaluator,
epochs=num_epochs,
evaluation_steps=1000,
warmup_steps=warmup_steps,
)
# Push the model to Hugging Face
model.push_to_hub("tomaarsen/mpnet-base-nli-stsb")All changes
- Add GISTEmbedLoss by @avsolatorio in #2535
- [
feat] Add 'get_config_dict' method to GISTEmbedLoss for better model cards by @tomaarsen in #2543 - Enable saving modules as pytorch_model.bin by @CKeibel in #2542
- [
deprecation] Deprecatesave_to_hubin favor ofpush_to_hub; add safe_serialization support topush_to_hubby @tomaarsen in #2544 - Fix SentenceTransformer encode documentation return type default (numpy vectors) by @CKeibel in #2546
- [
docs] Update return docstring of encode_multi_process by @tomaarsen in #2548 - [
feat] Add binary & scalar embedding quantization support to Sentence Transformers by @tomaarsen in #2549
New Contributors
- @avsolatorio made their first contribution in #2535
- @CKeibel made their first contribution in #2542
Full Changelog: v2.5.1...v2.6.0
Contributors
Assets 2
v2.5.1 - fix CrossEncoder.rank bug with default top_k
This is a patch release to fix a bug in CrossEncoder.rank that caused the last value to be discarded when using the default top_k=-1.
CrossEncoder.rank patch:
from sentence_transformers.cross_encoder import CrossEncoder
# Pre-trained cross encoder
model = CrossEncoder("cross-encoder/stsb-distilroberta-base")
# We want to compute the similarity between the query sentence
query = "A man is eating pasta."
# With all sentences in the corpus
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
# We rank all sentences in the corpus for the query
ranks = model.rank(query, corpus)
# Print the scores
print("Query:", query)
for rank in ranks:
print(f"{rank['score']:.2f}\t{corpus[rank['corpus_id']]}")Query: A man is eating pasta.
0.67 A man is eating food.
0.34 A man is eating a piece of bread.
0.08 A man is riding a horse.
0.07 A man is riding a white horse on an enclosed ground.
0.01 The girl is carrying a baby.
0.01 Two men pushed carts through the woods.
0.01 A monkey is playing drums.
0.01 A woman is playing violin.
0.01 A cheetah is running behind its prey.
Previously, the lowest score document would be removed from the output.
All changes
- [
examples] Update model repo_id in 2dMatryoshka example by @tomaarsen in #2515 - [
feat] Add get_config_dict to new Matryoshka2dLoss & AdaptiveLayerLoss by @tomaarsen in #2516 - [
chore] Update to ruff 0.3.0; update ruff.toml by @tomaarsen in #2517 - [
example] Don't always normalize the embeddings in clustering example by @tomaarsen in #2520 - Fix CrossEncoder.rank default value for
top_kby @xenova in #2518
New Contributors
Full Changelog: v2.5.0...v2.5.1
Contributors
Assets 2
v2.5.0 - 2D Matryoshka & Adaptive Layer models, CrossEncoder (re)ranking
This release brings two new loss functions, a new way to (re)rank with CrossEncoder models, and more fixes
Install this version with
pip install sentence-transformers==2.5.0
2D Matryoshka & Adaptive Layer models (#2506)
Embedding models are often encoder models with numerous layers, such as 12 (e.g. all-mpnet-base-v2) or 6 (e.g. all-MiniLM-L6-v2). To get embeddings, every single one of these layers must be traversed. 2D Matryoshka Sentence Embeddings (2DMSE) revisits this concept by proposing an approach to train embedding models that will perform well when only using a selection of all layers. This results in faster inference speeds at relatively low performance costs.
For example, using Sentence Transformers, you can train an Adaptive Layer model that can be sped up by 2x at a 15% reduction in performance, or 5x on GPU & 10x on CPU for a 20% reduction in performance. The 2DMSE paper highlights scenarios where this is superior to using a smaller model.
Training
Training with Adaptive Layer support is quite elementary: rather than applying some loss function on only the last layer, we also apply that same loss function on the pooled embeddings from previous layers. Additionally, we employ a KL-divergence loss that aims to make the embeddings of the non-last layers match that of the last layer. This can be seen as a fascinating approach of knowledge distillation, but with the last layer as the teacher model and the prior layers as the student models.
For example, with the 12-layer microsoft/mpnet-base, it will now be trained such that the model produces meaningful embeddings after each of the 12 layers.
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, AdaptiveLayerLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = AdaptiveLayerLoss(model=model, loss=base_loss)- Reference:
AdaptiveLayerLoss
Additionally, this can be combined with the MatryoshkaLoss such that the resulting model can be reduced both in the number of layers, but also in the size of the output dimensions. See also the Matryoshka Embeddings for more information on reducing output dimensions. In Sentence Transformers, the combination of these two losses is called Matryoshka2dLoss, and a shorthand is provided for simpler training.
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, Matryoshka2dLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = Matryoshka2dLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])- Reference:
Matryoshka2dLoss
Performance Results
Results
Let's look at the performance that we may be able to expect from an Adaptive Layer embedding model versus a regular embedding model. For this experiment, I have trained two models:
- tomaarsen/mpnet-base-nli-adaptive-layer: Trained by running adaptive_layer_nli.py with microsoft/mpnet-base.
- tomaarsen/mpnet-base-nli: A near identical model as the former, but using only
MultipleNegativesRankingLossrather thanAdaptiveLayerLosson top ofMultipleNegativesRankingLoss. I also use microsoft/mpnet-base as the base model.
Both of these models were trained on the AllNLI dataset, which is a concatenation of the SNLI and MultiNLI datasets. I have evaluated these models on the STSBenchmark test set using multiple different embedding dimensions. The results are plotted in the following figure:
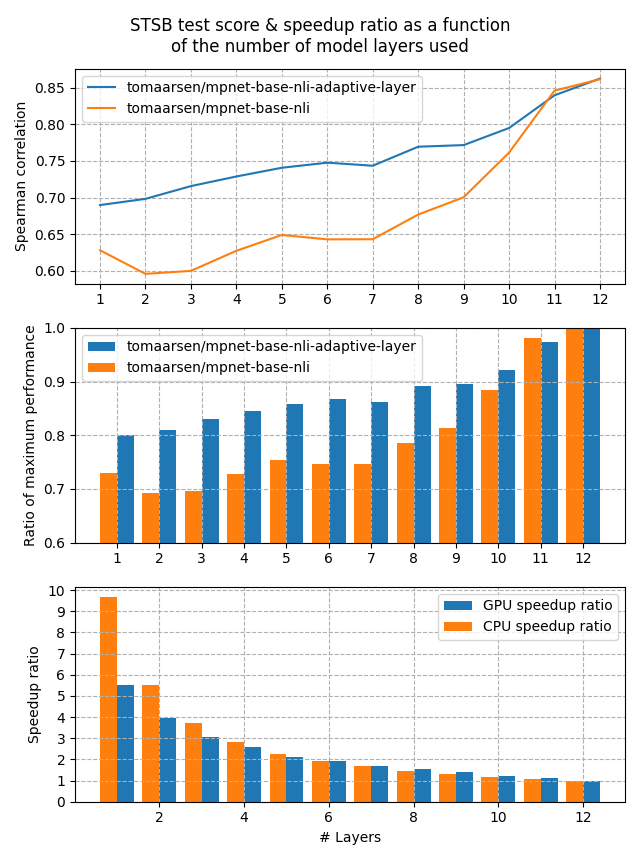
The first figure shows that the Adaptive Layer model stays much more performant when reducing the number of layers in the model. This is also clearly shown in the second figure, which displays that 80% of the performance is preserved when the number of layers is reduced all the way to 1.
Lastly, the third figure shows the expected speedup ratio for GPU & CPU devices in my tests. As you can see, removing half of the layers results in roughly a 2x speedup, at a cost of ~15% performance on STSB (~86 -> ~75 Spearman correlation). When removing even more layers, the performance benefit gets larger for CPUs, and between 5x and 10x speedups are very feasible with a 20% loss in performance.
Inference
Inference
After a model has been trained using the Adaptive Layer loss, you can then truncate the model layers to your desired layer count. Note that this requires doing a bit of surgery on the model itself, and each model is structured a bit differently, so the steps are slightly different depending on the model.
First of all, we will load the model & access the underlying transformers model like so:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("tomaarsen/mpnet-base-nli-adaptive-layer")
# We can access the underlying model with `model[0].auto_model`
print(model[0].auto_model)MPNetModel(
(embeddings): MPNetEmbeddings(
(word_embeddings): Embedding(30527, 768, padding_idx=1)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): MPNetEncoder(
(layer): ModuleList(
(0-11): 12 x MPNetLayer(
(attention): MPNetAttention(
(attn): MPNetSelfAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(k): Linear(in_features=768, out_features=768, bias=True)
(v): Linear(in_features=768, out_features=768, bias=True)
(o): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(intermediate): MPNetIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): MPNetOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(relative_attention_bias): Embedding(32, 12)
)
(pooler): MPNetPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
This output will differ depending on the model. We will look for the repeated layers in the encoder. For this MPNet model, this is stored under model[0].auto_model.encoder.layer. Then we can slice the model to only keep the first few layers to speed up the model:
new_num_layers = 3
model[0].auto_model.encoder.layer = model[0].auto_model.encoder.layer[:new_num_layers]Then we can run inference with it using SentenceTransformers.encode.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer("tomaarsen/mpnet-base-nli-adaptive-layer")
new_num_layers = 3
model[0].auto_model.encoder.layer = model[0].auto_model.encoder.layer[:new_num_layers]
embeddings = model.encode(
[
"The weather is so nice!",
"It's so sunny outside!",
"He drove to the stadium.",
]
)
# Similarity of the first sentence with the other two
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7761, 0.1655]])
# compared to tensor([[ 0.7547, -0.0162]]) for the full modelAs you can see, the similarity between the related sentences is much higher than the unrelated sentence, despite only using 3 layers. Feel free to copy this script locally, modify the new_num_layers, and observe the difference in similarities.
Extra information:
Example training scripts:
- adaptive_layer_nli.py
- adaptive_layer_sts.py
- 2d_matryoshka_nli.py
- [2d_matryoshka_sts.py](https://github.com/UKPLab/sentence-transfo...
Contributors
Assets 2
v2.4.0 - Matryoshka models, SOTA loss functions, prompt templates, INSTRUCTOR support
This release introduces numerous notable features that are well worth learning about!
Install this version with
pip install sentence-transformers==2.4.0
MatryoshkaLoss (#2485)
Dense embedding models typically produce embeddings with a fixed size, such as 768 or 1024. All further computations (clustering, classification, semantic search, retrieval, reranking, etc.) must then be done on these full embeddings. Matryoshka Representation Learning revisits this idea, and proposes a solution to train embedding models whose embeddings are still useful after truncation to much smaller sizes. This allows for considerably faster (bulk) processing.
Training
Training using Matryoshka Representation Learning (MRL) is quite elementary: rather than applying some loss function on only the full-size embeddings, we also apply that same loss function on truncated portions of the embeddings. For example, if a model has an embedding dimension of 768 by default, it can now be trained on 768, 512, 256, 128, 64 and 32. Each of these losses will be added together, optionally with some weight:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])- Reference:
MatryoshkaLoss
Inference
Inference
After a model has been trained using a Matryoshka loss, you can then run inference with it using SentenceTransformers.encode. You must then truncate the resulting embeddings, and it is recommended to renormalize the embeddings.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
]
)
embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7839, 0.4933]])As you can see, the similarity between the search query and the correct document is much higher than that of an unrelated document, despite the very small matryoshka dimension applied. Feel free to copy this script locally, modify the matryoshka_dim, and observe the difference in similarities.
Note: Despite the embeddings being smaller, training and inference of a Matryoshka model is not faster, not more memory-efficient, and not smaller. Only the processing and storage of the resulting embeddings will be faster and cheaper.
Extra information:
Example training scripts:
CoSENTLoss (#2454)
CoSENTLoss was introduced by Jianlin Su, 2022 as a drop-in replacement of CosineSimilarityLoss. Experiments have shown that it produces a stronger learning signal than CosineSimilarityLoss.
from sentence_transformers import SentenceTransformer, losses
from sentence_transformers.readers import InputExample
model = SentenceTransformer('bert-base-uncased')
train_examples = [
InputExample(texts=['My first sentence', 'My second sentence'], label=1.0),
InputExample(texts=['My third sentence', 'Unrelated sentence'], label=0.3)
]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size)
train_loss = losses.CoSENTLoss(model=model)You can update training_stsbenchmark.py by replacing CosineSimilarityLoss with CoSENTLoss & you can observe the improved performance.
AnglELoss (#2471)
AnglELoss was introduced in Li and Li, 2023. It is an adaptation of the CoSENTLoss, and also acts as a strong drop-in replacement of CosineSimilarityLoss. Compared to CoSENTLoss, AnglELoss uses a different similarity function which aims to avoid vanishing gradients.
Like with CoSENTLoss, you can use it just like CosineSimilarityLoss.
from sentence_transformers import SentenceTransformer, losses
from sentence_transformers.readers import InputExample
model = SentenceTransformer('bert-base-uncased')
train_examples = [
InputExample(texts=['My first sentence', 'My second sentence'], label=1.0),
InputExample(texts=['My third sentence', 'Unrelated sentence'], label=0.3)
]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size)
train_loss = losses.AnglELoss(model=model)You can update training_stsbenchmark.py by replacing CosineSimilarityLoss with AnglELoss & you can observe the improved performance.
Prompt Templates (#2477)
Some models require using specific text prompts to achieve optimal performance. For example, with intfloat/multilingual-e5-large you should prefix all queries with query: and all passages with passage: . Another example is BAAI/bge-large-en-v1.5, which performs best for retrieval when the input texts are prefixed with Represent this sentence for searching relevant passages: .
Sentence Transformer models can now be initialized with prompts and default_prompt_name parameters:
promptsis an optional argument that accepts a dictionary of prompts with prompt names to prompt texts. The prompt will be prepended to the input text during inference. For example,model = SentenceTransformer( "intfloat/multilingual-e5-large", prompts={ "classification": "Classify the following text: ", "retrieval": "Retrieve semantically similar text: ", "clustering": "Identify the topic or theme based on the text: ", }, ) # or model.prompts = { "classification": "Classify the following text: ", "retrieval": "Retrieve semantically similar text: ", "clustering": "Identify the topic or theme based on the text: ", }
default_prompt_nameis an optional argument that determines the default prompt to be used. It has to correspond with a prompt name fromprompts. IfNone, then no prompt is used by default. For example,model = SentenceTransformer( "intfloat/multilingual-e5-large", prompts={ "classification": "Classify the following text: ", "retrieval": "Retrieve semantically similar text: ", "clustering": "Identify the topic or theme based on the text: ", }, default_prompt_name="retrieval", ) # or model.default_prompt_name="retrieval"
Both of these parameters can also be specified in the config_sentence_transformers.json file of a saved model. That way, you won't have to specify these options manually when loading. When you save a Sentence Transformer model, these options will be automatically saved as well.
During inference, prompts can be applied in a few different ways. All of these scenarios result in identical texts being embedded:
- Explicitly using the
promptoption inSentenceTransformer.encode:embeddings = model.encode("How to bake a strawberry cake", prompt="Retrieve semantically similar text: ")
- Explicitly using the
prompt_nameoption inSentenceTransformer.encodeby relying on the prompts loaded from a) initialization or b) the model config.embeddings = model.encode("How to bake a strawberry cake", prompt_name="retrieval")
- If
promptnorprompt_nameare specified inSentenceTransformer.encode, then the prompt specified bydefault_prompt_namewill be applied. If it isNone, then no prompt will be applied.embeddings = model.encode("How to bake a strawberry cake")
Instructor support (#2477)
Some INSTRUCTOR models, such as [hkunlp/instructor-large](ht...
Contributors
Assets 2
v2.3.1 - Patch for local models with Normalize modules
This releases patches a niche bug when loading a Sentence Transformer model which:
- is local
- uses a
Normalizemodule as specified inmodules.json - does not contain the directory specified in the model configuration
This only occurs when a model with Normalize is downloaded from the Hugging Face hub and then later used locally.
See #2458 and #2459 for more details.
Release highlights
- Don't require loading files for Normalize by @tomaarsen (#2460)
Full Changelog: v2.3.0...v2.3.1
Contributors
Assets 2
v2.3.0 - Bug fixes, improved model loading & Cached MNRL
This release focuses on various bug fixes & improvements to keep up with adjacent works like transformers and huggingface_hub. These are the key changes in the release:
Pushing models to the Hugging Face Hub (#2376)
Prior to Sentence Transformers v2.3.0, saving models to the Hugging Face Hub may have resulted in various errors depending on the versions of the dependencies. Sentence Transformers v2.3.0 introduces a refactor to save_to_hub to resolve these issues.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
...
model.save_to_hub("tomaarsen/all-MiniLM-L6-v2-quora")pytorch_model.bin: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 90.9M/90.9M [00:06<00:00, 13.7MB/s]
Upload 1 LFS files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:07<00:00, 7.11s/it]
Model Loading
Efficient model loading (#2345)
Recently, transformers has shifted towards using safetensors files as their primary model file formats. Additionally, various other file formats are commonly used, such as PyTorch (pytorch_model.bin), Rust (rust_model.ot), Tensorflow (tf_model.h5) and ONNX (model.onnx).
Prior to Sentence Transformers v2.3.0, almost all files of a repository would be downloaded, even if theye are not strictly required. Since v2.3.0, only the strictly required files will be downloaded. For example, when loading sentence-transformers/all-MiniLM-L6-v2 which has its model weights in three formats (pytorch_model.bin, rust_model.ot, tf_model.h5), only pytorch_model.bin will be downloaded. Additionally, when downloading intfloat/multilingual-e5-small with two formats (model.safetensors, pytorch_model.bin), only model.safetensors will be downloaded.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")Downloading modules.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 349/349 [00:00<?, ?B/s]
Downloading (…)ce_transformers.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 116/116 [00:00<?, ?B/s]
Downloading README.md: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 10.6k/10.6k [00:00<?, ?B/s]
Downloading (…)nce_bert_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 53.0/53.0 [00:00<?, ?B/s]
Downloading config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 612/612 [00:00<?, ?B/s]
Downloading pytorch_model.bin: 100%|█████████████████████████████████████████████████████████████████████████████████████| 90.9M/90.9M [00:06<00:00, 15.0MB/s]
Downloading tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████| 350/350 [00:00<?, ?B/s]
Downloading vocab.txt: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 232k/232k [00:00<00:00, 1.37MB/s]
Downloading tokenizer.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 466k/466k [00:00<00:00, 4.61MB/s]
Downloading (…)cial_tokens_map.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 112/112 [00:00<?, ?B/s]
Downloading 1_Pooling/config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████| 190/190 [00:00<?, ?B/s]
Note
This release updates the default cache location from ~/.cache/torch/sentence_transformers to the default cache location of transformers, i.e. ~/.cache/huggingface. You can still specify custom cache locations via the SENTENCE_TRANSFORMERS_HOME environment variable or the cache_folder argument.
Additionally, by supporting newer versions of various dependencies (e.g. huggingface_hub), the cache format changed. A consequence is that the old cached models cannot be used in v2.3.0 onwards, and those models need to be redownloaded. Once redownloaded, an airgapped machine can load the model like normal despite having no internet access.
Loading custom models (#2398)
This release brings models with custom code to Sentence Transformers through trust_remote_code, such as jinaai/jina-embeddings-v2-base-en.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer("jinaai/jina-embeddings-v2-base-en", trust_remote_code=True)
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
print(cos_sim(embeddings[0], embeddings[1]))
# => tensor([[0.9341]])Loading specific revisions (#2419)
If an embedding model is ever updated, it would invalidate all of the embeddings that you have created with the prior version of that model. We promise to never update the weights of any sentence-transformers/... model, but we cannot offer this guarantee for models by the community.
That is why this version introduces a revision keyword, allowing you to specify exactly which revision or branch you'd like to load:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-small-en-v1.5", revision="982532469af0dff5df8e70b38075b0940e863662")
# or a branch:
model = SentenceTransformer("BAAI/bge-small-en-v1.5", revision="main")Soft deprecation of use_auth_token, use token instead (#2376)
Following updates from transformers & huggingface_hub, Sentence Transformers now recommends that you use the token argument to provide your Hugging Face authentication token to download private models.
from sentence_transformers import SentenceTransformer
# new:
model = SentenceTransformer("tomaarsen/all-mpnet-base-v2", token="hf_...")
# old, still works, but throws a warning to upgrade to "token"
model = SentenceTransformer("tomaarsen/all-mpnet-base-v2", use_auth_token="hf_...")Note
The recommended way to include your Hugging Face authentication token is to run huggingface-cli login & paste your User Access Token from your Hugging Face Settings. See these docs for more information. Then, you don't have to include the token argument at all; it'll be automatically read from your filesystem.
Device patch (#2351)
Prior to this release, SentenceTransformers.device would not always correspond to the device on which embeddings were computed, or on which a model gets trained. This release brings a few fixes:
SentenceTransformers.devicenow always corresponds to the device that the model is on, and on which it will do its computations.- Models are now immediately moved to their specified device, rather than lazily whenever the model is being used.
SentenceTransformers.to(...),SentenceTransformers.cpu(),SentenceTransformers.cuda(), etc. will now work as expected, rather than being ignored.
Cached Multiple Negatives Ranking Loss (CMNRL) (#1759)
MultipleNegativesRankingLoss (MNRL) is a powerful loss function that is commonly applied to train embedding models. It uses in-batch negative sampling to produce a large number of negative pairs, allowing the model to receive a training signal to push the embeddings of this pair apart. It is commonly shown that a larger batch size results in better performing models (Qu et al., 2021, Li et al., 2023), but a larger batch size requires more VRAM in practice.
To counteract that, @kwang2049 has implemented a slightly modified GradCache technique that is able to separate the batch computation into mini-batches without any reduction in training quality. This allows the common practitioner to train with competitive batch sizes, e.g. 65536!
The downside is that training with Cached MNRL (CMNRL) is roughly 2 to 2.4 times slower than using normal MNRL.
CachedMultipleNegativesRankingLoss is a drop-in replacement for MultipleNegativesRankingLoss, but with a new mini_batch_size argument. I recommend trying out CMNRL with a large batch size and a fairly small mini_batch_size - the larger mini batch size that will fit into memory.
from sentence_transformers import SentenceTransformer, losses, InputExample
from torch.utils.data import DataLoader
model = SentenceTransformer("distilbert-base-uncased")
train_examples = [
InputExample(texts=['Anchor 1', 'Positive 1']),
InputExample(texts=['Anchor 2', 'Positive 2']),
]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=1024) # Here we can try much larger batch sizes!
train_loss = losses.CachedMultipleNegativesRankingLoss(model=model, mini_batch_size = 32)
model.fit([(t...Contributors
Assets 2
v2.2.2 - Bugfix huggingface_hub for Python 3.6
huggingface_hub dropped support in version 0.5.0 for Python 3.6
This release fixes the issue so that huggingface_hub with version 0.4.0 and Python 3.6 can still be used.
v2.2.1 - Update huggingface_hub & fixes
Version 0.8.1 of huggingface_hub introduces several changes that resulted in errors and warnings. This version of sentence-transformers fixes these issues.
Further, several improvements have been added / merged:
util.community_detectionwas improved: 1) It works in a batched mode to save memory, 2) Overlapping clusters are no longer dropped but removed by overlapping items, 3) The parameterinit_max_sizewas removed and replaced by a heuristic to estimate the max size of clusters- #1581 the training dataset names can be saved in the model card
- #1426 fix the text summarization example
- #1487 Rekursive sentence-transformers models are now possible
- #1522 Private models can now be loaded
- #1551 DataLoaders can now have workers
- #1565 Models are just checked on the hub if they don't exist in the cache. Fixes issues with connectivity issues
- #1591 Example added how to stream encode larger datasets
v2.2.0 - T5 Encoder & Private models
T5
You can now use the encoder from T5 to learn text embeddings. You can use it like any other transformer model:
from sentence_transformers import SentenceTransformer, models
word_embedding_model = models.Transformer('t5-base', max_seq_length=256)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])See T5-Benchmark results - the T5 encoder is not the best model for learning text embeddings models. It requires quite a lot of training data and training steps. Other models perform much better, at least in the given experiment with 560k training triplets.
New Models
The models from the papers Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models and Large Dual Encoders Are Generalizable Retrievers have been added:
- gtr-t5-base
- gtr-t5-large
- gtr-t5-xl
- gtr-t5-xxl
- sentence-t5-base
- sentence-t5-large
- sentence-t5-xl
- sentence-t5-xxl
For benchmark results, see https://seb.sbert.net
Private Models
Thanks to #1406 you can now load private models from the hub:
model = SentenceTransformer("your-username/your-model", use_auth_token=True)v2.1.0 - New Loss Functions
This is a smaller release with some new features
MarginMSELoss
MarginMSELoss is a great method to train embeddings model with the help of a cross-encoder model. The details are explained here: MSMARCO - MarginMSE Training
You pass your training data in the format:
InputExample(texts=[query, positive, negative], label=cross_encoder.predict([query, positive])-cross_encoder.predict([query, negative])MultipleNegativesSymmetricRankingLoss
MultipleNegativesRankingLoss computes the loss just in one way: Find the correct answer for a given question.
MultipleNegativesSymmetricRankingLoss also computes the loss in the other direction: Find the correct question for a given answer.
Breaking Change: CLIPModel
The CLIPModel is now based on the transformers model.
You can still load it like this:
model = SentenceTransformer('clip-ViT-B-32')Older SentenceTransformers versions are now longer able to load and use the 'clip-ViT-B-32' model.
Added files on the hub are automatically downloaded
PR #1116 checks if you have all files in your local cache or if there are added files on the hub. If this is the case, it will automatically download them.
SentenceTransformers.encode() can return all values
When you set output_value=None for the encode method, all values (token_ids, token_embeddings, sentence_embedding) will be returned.