链表,使用“链子”将数据组合起来,这里的链子指的就是引用或者指针。链子存储在哪里呢?节点(Node)中,我们把节点封装在类中。即
class Node{
E e;
Node next;
}也就形成了这样的数据结构

上面就是链表,同动态数组不同,链表才算是真正的动态。
动态数组
- 优点:具备随机访问能力,直接根据地址寻址一步完成
- 缺点:不具备真正的动态性,底层依然依靠固定容量的数组
链表
- 优点:具有真正的动态性,完全根据用户的数据建立节点
- 缺点:缺少了随机访问能力,不适合应对查询元素频繁的场景
由于设计链表类的时候,节点作为链表存储数据的核心。那么节点类就要作为链表类的子类,所以具体的Java实现如下:
public class LinkedList<E> {
private class Node{ //
public Node(E e, Node node) {
this.e = e;
this.next = node;
}
public Node(E e) {
this(e, null);
}
public Node() {
this(null, null);
}
@Override
public String toString() {
return e.toString();
}
E e;
Node next;
}
}几乎所有的数据结构的实现都避免不了增删改查四中基本操作,下面分别实现一下。
写在前面: 为了更优化添加元素或者删除中对头结点的另外操作,这里我引入虚拟头结点(dummyNode)。
增加元素最基本的操作就是向某一个“索引”位置添加元素。
步骤:
- 找到要插入位置的前一个节点pre
- 新增节点,并指向pre节点的下一个节点
- 将pre节点指向新的节点
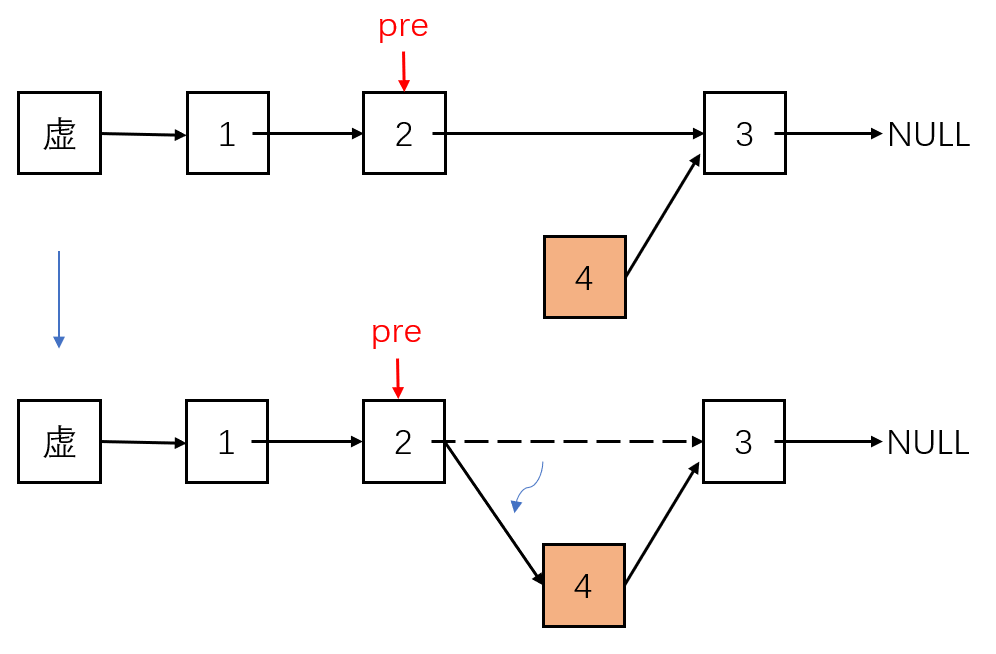
程序实现
public void add(int index, E e) {
if (index < 0 || index > size) //越界判断
throw new IllegalArgumentException("add is error, index need index < 0 || index > size ");
table pre = dummyHead; //起始从虚头开始
for (int i = 0; i < index; ++i) //找到插入位置的前一个节点
pre = pre.next;
pre.next = new table(e, pre.next);
size++;
}步骤:
- 找到索引位置的前一个节点pre
- pre节点指向pre节点的下一节点的下一个节点
- 断开待删除节点与其下一个节点的连接,删除的节点会被内存管理机制自动销毁
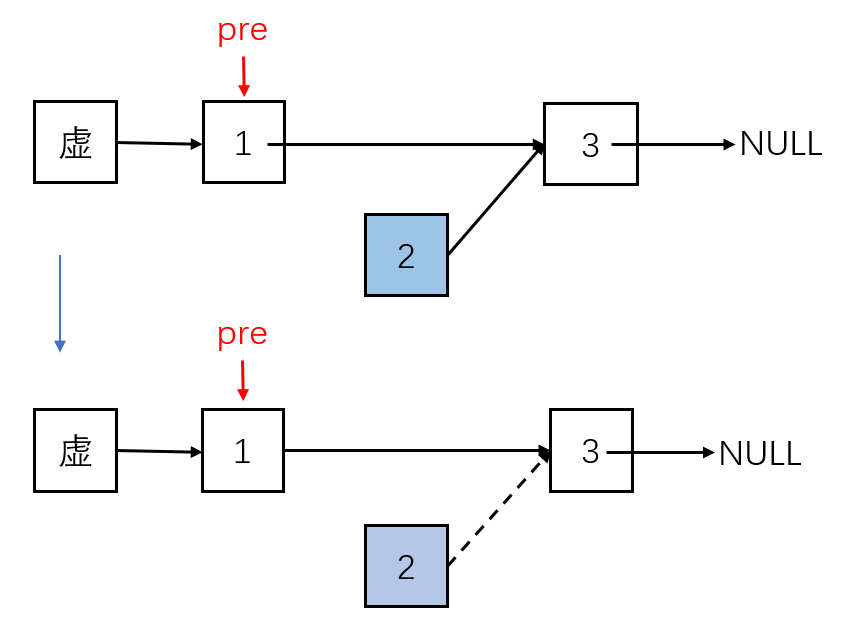
程序实现:
public E remove(int index){
if (index < 0 || index > size)
throw new IllegalArgumentException("set is error, index need index < 0 || index > size ");
table pre = dummyHead;
for (int i = 0; i < index; ++i) //找到待删除节点的前一个节点
pre = pre.next;
size--;
table retNode = pre.next; //保存待删除节点,后面还要返回
pre.next = retNode.next;
retNode.next = null; //断开连接
return retNode.e;
}写在后面: 在某些场景中,我们并不需要保留这个节点,为了使代码更加简洁易懂我们可以做以下处理。
这种可以应用在LeetCode中,因为在代码执行完成以后,所有都会被销毁。
public void remove(int index){
if (index < 0 || index > size)
throw new IllegalArgumentException("set is error, index need index < 0 || index > size ");
table pre = dummyHead;
for (int i = 0; i < index; ++i)
pre = pre.next;
size--;
pre.next = pre.next.next; //直接删除
}改变元素就比较简单,直接找到位置进行更改元素就可以。同增加元素和删除元素不同,改变元素不需找到前一个位置,所以起始位置就是虚拟头节点的下一个位置。
程序实现:
public void set(int index, E e) {
if (index < 0 || index > size)
throw new IllegalArgumentException("set is error, index need index < 0 || index > size ");
table pre = dummyHead.next; //起始位置
for (int i = 0; i < index; ++i) //找到元素
pre = pre.next;
pre.e = e; //改变元素
}和其他数据结构相同,包含三种查询。
- find(E e) 查询元素e所在位置
- contains(E e) 查询是否包含元素,同find代码逻辑相同
- get(int index) 查询index位置上的元素
/** 是否包含元素 **/
public boolean contains(E e) {
table currentTable = dummyHead.next;
while (currentTable != null) {
if (currentTable.e == e)
return true;
currentTable = currentTable.next;
}
return false;
}
/** 查找元素所在位置 **/
public int find(E e) {
int index = 0;
table currentTable = dummyHead.next;
while (currentTable != null) {
if (currentTable.e == e)
return index;
index++;
currentTable = currentTable.next;
}
return -1;
}
/** 查询index位置的元素 **/
public E get(int index) {
if (index < 0 || index > size)
throw new IllegalArgumentException("get is error, index need index < 0 || index > size ");
table pre = dummyHead.next;
for (int i = 0; i < index; ++i)
pre = pre.next;
return pre.e;
}对于链表来说,最大的优势在于其动态性,所以在头部进行的所有操作时间复杂度最低O(1)级别,其他位置的操作均与索引位置位置有关(因为要先找到要操作的位置)。由此特性,我们可以清楚的看出,用链表实现栈的数据结构再合适不过啦。
更多精彩内容,大家可以转到我的主页:曲怪曲怪
关注我的微信公众号:TeaUrn
或者扫描下方二维码进行关注。我在那里等你哦!
