![]()
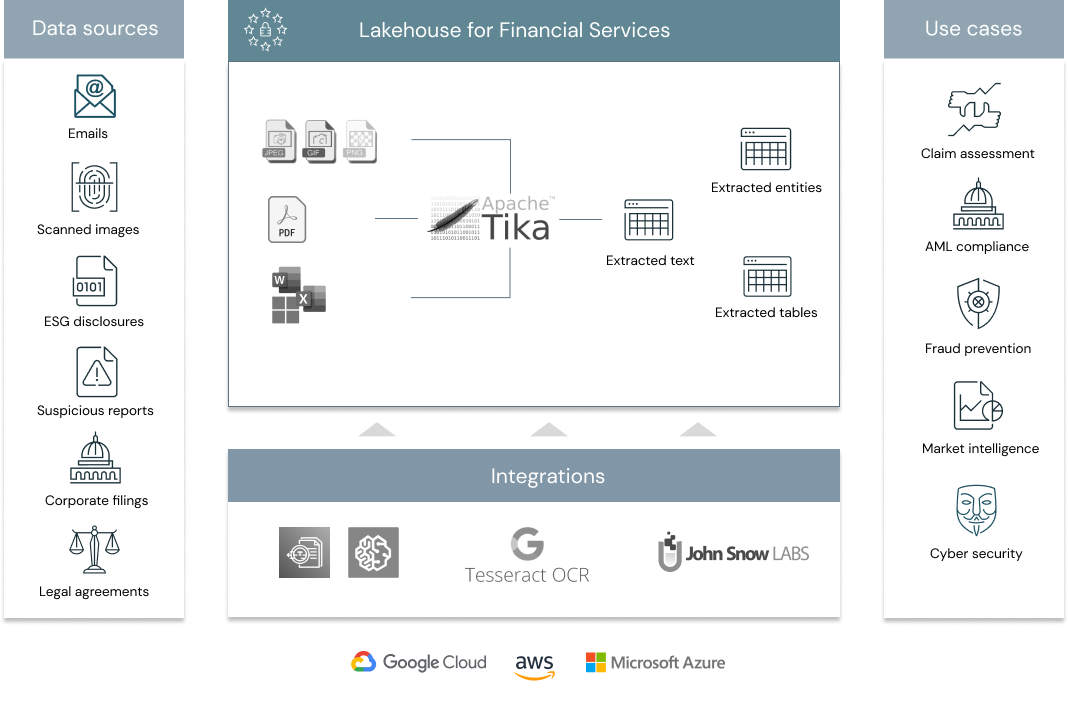
Digitization of documents with Tika on Databricks : The volume of available data is growing by the second. About 64 zettabytes was created or copied last year, according to IDC, a technology market research firm. By 2025, this number will grow to an estimated 175 zetabytes, and it is becoming increasingly granular and difficult to codify, unify, and centralize. And though more financial services institutions (FSIs) are talking about big data and using technology to capture more data than ever, Forrester reports that 70% of all data within an enterprise still goes unused for analytics. The open source nature of Lakehouse for Financial Services makes it possible for bank compliance officers, insurance underwriting agents or claim adjusters to combine latest technologies in optical character recognition (OCR) and natural language processing (NLP) in order to transform any financial document, in any format, into valuable data assets. The Apache Tika toolkit detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF). Combined with Tesseract, the most commonly used OCR technology, there is literally no limit to what files we can ingest, store and exploit for analytics / operation purpose. In this solution, we will use our newly released spark input format tika-ocr to extract text from PDF reports available online
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| unidecode | Text processing | GNU | https://github.com/avian2/unidecode |
| pdf2image | PDF parser | MIT | https://github.com/Belval/pdf2image |
| beautifulsoup4 | Web scraper | MIT | https://www.crummy.com/software/BeautifulSoup/ |
| PyPDF2 | PDF parser | BSD | https://pypi.org/project/PyPDF2 |
| tika-ocr | Spark input format | Databricks | https://github.com/databrickslabs/tika-ocr |
| tesseract-ocr | OCR library | Apache2 | https://github.com/tesseract-ocr |
| poppler-utils | Image transformation | MIT | https://github.com/skmetaly/poppler-utils |